
Войти
| Часть серии о |
| Искусственный интеллект |
|---|
 |
| Основные цели |
| Подходы |
| Философия |
| История |
| Технология |
| Глоссарий |
|
Машинное обучение ( ML) - это изучение компьютерных алгоритмов, которые могут автоматически улучшаться благодаря опыту и использованию данных. Это рассматривается как часть искусственного интеллекта. Алгоритмы машинного обучения создают модель на основе выборочных данных, известных как « обучающие данные », чтобы делать прогнозы или решения, не будучи явно запрограммированными на это. Алгоритмы машинного обучения используются в самых разных приложениях, таких как медицина, фильтрация электронной почты, распознавание речи и компьютерное зрение, где сложно или невозможно разработать традиционные алгоритмы для выполнения необходимых задач.
Подмножество машинного обучения тесно связано с вычислительной статистикой, которая фокусируется на прогнозировании с использованием компьютеров; но не все машинное обучение - это статистическое обучение. Изучение математической оптимизации предоставляет методы, теорию и прикладные области в области машинного обучения. Интеллектуальный анализ данных - это смежная область исследования, в которой основное внимание уделяется исследовательскому анализу данных посредством обучения без учителя. Некоторые реализации машинного обучения используют данные и нейронные сети таким образом, чтобы имитировать работу биологического мозга. В применении к бизнес-задачам машинное обучение также называется прогнозной аналитикой.
Алгоритмы обучения работают на том основании, что стратегии, алгоритмы и выводы, которые хорошо работали в прошлом, вероятно, продолжат хорошо работать и в будущем. Эти выводы могут быть очевидными, например, «поскольку солнце вставало каждое утро в течение последних 10 000 дней, оно, вероятно, взойдет и завтра утром». Они могут иметь нюансы, например: «X% семейств имеют географически отдельные виды с цветовыми вариантами, поэтому существует Y% вероятности, что существуют неоткрытые черные лебеди ».
Программы машинного обучения могут выполнять задачи, даже не будучи запрограммированными на это явным образом. Он включает в себя обучение компьютеров на предоставленных данных для выполнения определенных задач. Для простых задач, возложенных на компьютеры, можно запрограммировать алгоритмы, сообщающие машине, как выполнять все шаги, необходимые для решения данной проблемы; со стороны компьютера никакого обучения не требуется. Для более сложных задач человеку может быть сложно вручную создать необходимые алгоритмы. На практике может оказаться более эффективным помочь машине разработать свой собственный алгоритм, чем заставлять программистов указывать каждый необходимый шаг.
Дисциплина машинного обучения использует различные подходы к обучению компьютеров выполнению задач, для которых нет полностью удовлетворительного алгоритма. В случаях, когда существует огромное количество возможных ответов, один из подходов состоит в том, чтобы пометить некоторые из правильных ответов как действительные. Затем их можно использовать в качестве обучающих данных для компьютера, чтобы улучшить алгоритм (ы), который он использует для определения правильных ответов. Например, для обучения системы задаче распознавания цифровых символов часто используется набор рукописных цифр MNIST.
Термин машинное обучение был придуман в 1959 году Артуром Самуэлем, американским сотрудником IBM и пионером в области компьютерных игр и искусственного интеллекта. Также в этот период использовался синоним самообучающиеся компьютеры. Репрезентативной книгой исследований машинного обучения в 1960-х годах была книга Нильссона об обучающих машинах, посвященная в основном машинному обучению для классификации шаблонов. Интерес, связанный с распознаванием образов, сохранялся и в 1970-х годах, как это описали Дуда и Харт в 1973 году. В 1981 году был представлен отчет об использовании обучающих стратегий, согласно которым нейронная сеть учится распознавать 40 символов (26 букв, 10 цифр и 4 специальных символа.) с компьютерного терминала.
Том М. Митчелл дал широко цитируемое, более формальное определение алгоритмов, изучаемых в области машинного обучения: «Считается, что компьютерная программа учится на опыте E в отношении некоторого класса задач T и показателя производительности P, если ее производительность при выполнении задач в T, измеряемом P, улучшается с опытом E ". Это определение задач, связанных с машинным обучением, предлагает принципиально рабочее определение, а не определение области в когнитивных терминах. Это следует за предложением Алана Тьюринга в его статье « Вычислительные машины и интеллект », в которой был задан вопрос «Могут ли машины думать?» заменяется вопросом «Могут ли машины делать то, что можем делать мы (как мыслящие сущности)?».
Современное машинное обучение преследует две цели: одна - классифицировать данные на основе разработанных моделей, другая - делать прогнозы будущих результатов на основе этих моделей. Гипотетический алгоритм, специфичный для классификации данных, может использовать компьютерное зрение родинок в сочетании с контролируемым обучением, чтобы обучить его классифицировать раковые родинки. Где как, алгоритм машинного обучения для торговли акциями может информировать трейдера о будущих потенциальных прогнозах.
 Машинное обучение как подполе ИИ
Машинное обучение как подполе ИИ  Часть машинного обучения как подполе ИИ или часть ИИ как подполе машинного обучения
Часть машинного обучения как подполе ИИ или часть ИИ как подполе машинного обучения Как научное направление машинное обучение выросло из поисков искусственного интеллекта. На заре искусственного интеллекта как академической дисциплины некоторые исследователи были заинтересованы в том, чтобы машины учились на данных. Они попытались подойти к проблеме с помощью различных символических методов, а также с помощью того, что тогда называлось « нейронными сетями »; в основном это были перцептроны и другие модели, которые позже были обнаружены как переизобретения обобщенных линейных моделей статистики. Также использовались вероятностные рассуждения, особенно в автоматизированной медицинской диагностике.
Однако усиление акцента на логическом подходе, основанном на знаниях, привело к разрыву между ИИ и машинным обучением. Вероятностные системы страдали от теоретических и практических проблем сбора и представления данных. К 1980 году экспертные системы стали доминировать в искусственном интеллекте, и статистика перестала быть популярной. Работа над символическим / основанным на знаниях обучением продолжалась в рамках ИИ, что привело к индуктивному логическому программированию, но более статистические исследования теперь выходили за рамки собственно ИИ, в области распознавания образов и поиска информации. ИИ и информатика отказались от исследований нейронных сетей примерно в то же время. Эта линия также была продолжена за пределами области AI / CS как « коннекционизм » исследователями из других дисциплин, включая Хопфилда, Рамельхарта и Хинтона. Их главный успех пришел к середине 1980-х годов, когда был изобретен метод обратного распространения ошибки.
Машинное обучение (ML), реорганизованное в отдельную область, начало процветать в 1990-х годах. Область изменила свою цель с создания искусственного интеллекта на решение решаемых проблем практического характера. Он сместил акцент с символических подходов, унаследованных от ИИ, на методы и модели, заимствованные из статистики и теории вероятностей.
По состоянию на 2020 год многие источники продолжают утверждать, что машинное обучение остается под областью ИИ. Основное разногласие заключается в том, является ли машинное обучение частью ИИ, поскольку это будет означать, что любой, кто использует машинное обучение, может утверждать, что использует ИИ. Другие придерживаются мнения, что не весь ML является частью AI, тогда как только «интеллектуальное» подмножество ML является частью AI.
На вопрос, в чем разница между ML и AI, отвечает Джудея Перл в книге «Почему». Соответственно, ML учится и прогнозирует на основе пассивных наблюдений, тогда как AI подразумевает, что агент взаимодействует с окружающей средой, чтобы учиться и предпринимать действия, которые увеличивают его шансы на успешное достижение своих целей.
В машинном обучении и интеллектуальном анализе данных часто используются одни и те же методы и они значительно перекрываются, но в то время как машинное обучение фокусируется на прогнозировании, основанном на известных свойствах, полученных из обучающих данных, интеллектуальный анализ данных фокусируется на обнаружении (ранее) неизвестных свойств в данных (это этап анализа открытия знаний в базах данных). В интеллектуальном анализе данных используется множество методов машинного обучения, но с разными целями; с другой стороны, машинное обучение также использует методы интеллектуального анализа данных как «обучение без учителя» или как этап предварительной обработки для повышения точности обучения. Большая часть путаницы между этими двумя исследовательскими сообществами (у которых часто есть отдельные конференции и отдельные журналы, за исключением ECML PKDD ) происходит из-за основных допущений, с которыми они работают: в машинном обучении производительность обычно оценивается с точки зрения способности воспроизводить известные знания, в то время как при обнаружении знаний и интеллектуальном анализе данных (KDD) ключевой задачей является обнаружение ранее неизвестных знаний. Неинформированный (неконтролируемый) метод, оцениваемый на основе известных знаний, будет легко уступать другим контролируемым методам, в то время как в типичной задаче KDD контролируемые методы не могут использоваться из-за недоступности обучающих данных.
Машинное обучение также тесно связано с оптимизацией : многие задачи обучения формулируются как минимизация некоторой функции потерь на обучающем наборе примеров. Функции потерь выражают несоответствие между прогнозами обучаемой модели и фактическими экземплярами проблемы (например, при классификации нужно присвоить экземплярам метку, а модели обучены правильно предсказывать заранее назначенные метки набора Примеры).
Разница между оптимизацией и машинным обучением проистекает из цели обобщения: в то время как алгоритмы оптимизации могут минимизировать потери на обучающем наборе, машинное обучение связано с минимизацией потерь на невидимых выборках. Характеристика обобщения различных алгоритмов обучения является активной темой текущих исследований, особенно для алгоритмов глубокого обучения.
Машинное обучение и статистика - тесно связанные области с точки зрения методов, но разные по своей основной цели: статистика делает выводы о населении на основе выборки, а машинное обучение находит обобщаемые модели прогнозирования. По словам Майкла И. Джордана, идеи машинного обучения, от методологических принципов до теоретических инструментов, имеют долгую предысторию в статистике. Он также предложил термин « наука о данных» в качестве заполнителя для обозначения общего поля.
Лео Брейман выделил две парадигмы статистического моделирования: модель данных и алгоритмическую модель, где «алгоритмическая модель» в большей или меньшей степени означает алгоритмы машинного обучения, такие как случайный лес.
Некоторые статистики переняли методы машинного обучения, что привело к созданию комбинированной области, которую они называют статистическим обучением.
Основная цель учащегося - обобщить свой опыт. Обобщение в этом контексте - это способность обучающейся машины точно выполнять новые, невидимые примеры / задачи после изучения набора обучающих данных. Примеры обучения исходят из некоторого, как правило, неизвестного распределения вероятностей (которое считается репрезентативным для пространства вхождений), и учащийся должен построить общую модель этого пространства, которая позволяет ему производить достаточно точные прогнозы в новых случаях.
Вычислительный анализ алгоритмов машинного обучения и их производительности - это раздел теоретической информатики, известный как теория вычислительного обучения. Поскольку обучающие наборы конечны, а будущее неопределенно, теория обучения обычно не дает гарантий производительности алгоритмов. Вместо этого довольно распространены вероятностные границы производительности. Разложение диагонально-дисперсия является одним из способов количественного обобщения ошибки.
Для лучшей производительности в контексте обобщения сложность гипотезы должна соответствовать сложности функции, лежащей в основе данных. Если гипотеза менее сложна, чем функция, то модель не соответствует данным. Если сложность модели увеличивается в ответ, то ошибка обучения уменьшается. Но если гипотеза слишком сложна, то модель подвержена переобучению, и обобщение будет хуже.
Помимо пределов производительности, теоретики обучения изучают временную сложность и осуществимость обучения. В теории вычислительного обучения вычисление считается выполнимым, если оно может быть выполнено за полиномиальное время. Есть два вида результатов временной сложности. Положительные результаты показывают, что определенный класс функций можно изучить за полиномиальное время. Отрицательные результаты показывают, что некоторые классы нельзя изучить за полиномиальное время.
Подходы к машинному обучению традиционно делятся на три широкие категории в зависимости от характера «сигнала» или «обратной связи», доступного системе обучения:
 Опорных векторы машина Контролируемая модель обучения, которая делит данные в регионы разделены линейной границей. Здесь линейная граница отделяет черные кружки от белых.
Опорных векторы машина Контролируемая модель обучения, которая делит данные в регионы разделены линейной границей. Здесь линейная граница отделяет черные кружки от белых. Алгоритмы контролируемого обучения создают математическую модель набора данных, который содержит как входные, так и желаемые выходы. Эти данные известны как обучающие данные и состоят из набора обучающих примеров. Каждый обучающий пример имеет один или несколько входов и желаемый выход, также известный как контрольный сигнал. В математической модели каждый обучающий пример представлен массивом или вектором, иногда называемым вектором признаков, а обучающие данные представлены матрицей. С помощью итеративной оптимизации в качестве целевой функции, охраняемого обучение алгоритмов обучения функции, которые могут быть использованы для прогнозирования выхода, связанный с новыми входами. Оптимальная функция позволит алгоритму правильно определять выходные данные для входных данных, которые не были частью обучающих данных. Говорят, что алгоритм, который со временем повышает точность своих результатов или прогнозов, научился выполнять эту задачу.
Типы алгоритмов контролируемого обучения включают активное обучение, классификацию и регрессию. Алгоритмы классификации используются, когда выходные данные ограничены ограниченным набором значений, а алгоритмы регрессии используются, когда выходы могут иметь любое числовое значение в пределах диапазона. Например, для алгоритма классификации, который фильтрует электронные письма, входом будет входящее электронное письмо, а выходом будет имя папки, в которую будет сохранено электронное письмо.
Изучение подобия - это область машинного обучения с учителем, тесно связанная с регрессией и классификацией, но цель состоит в том, чтобы учиться на примерах с использованием функции подобия, которая измеряет, насколько похожи или связаны два объекта. У него есть приложения для ранжирования, системы рекомендаций, визуального отслеживания личности, проверки лица и проверки говорящего.
Алгоритмы неконтролируемого обучения берут набор данных, который содержит только входные данные, и находят в них структуру, например группировку или кластеризацию точек данных. Следовательно, алгоритмы учатся на тестовых данных, которые не были помечены, классифицированы или категоризированы. Вместо того, чтобы реагировать на обратную связь, алгоритмы неконтролируемого обучения выявляют общие черты в данных и реагируют на наличие или отсутствие таких общих черт в каждой новой части данных. Центральное применение обучения без учителя - это оценка плотности в статистике, например, определение функции плотности вероятности. Хотя обучение без учителя охватывает другие области, включающие обобщение и объяснение функций данных.
Кластерный анализ - это распределение набора наблюдений в подмножества (называемые кластерами), так что наблюдения в одном кластере похожи по одному или нескольким заранее заданным критериям, в то время как наблюдения, полученные из разных кластеров, не похожи. Различные методы кластеризации делают разные предположения о структуре данных, часто определяемой некоторой метрикой сходства и оцениваемой, например, по внутренней компактности или сходству между членами одного и того же кластера, а разделение - разницей между кластерами. Другие методы основаны на предполагаемой плотности и связности графов.
Полу-контролируемое обучение находится между неконтролируемым обучением (без каких-либо помеченных данных обучения) и контролируемым обучением (с полностью маркированными данными обучения). В некоторых обучающих примерах отсутствуют обучающие метки, но многие исследователи машинного обучения обнаружили, что немаркированные данные при использовании вместе с небольшим количеством помеченных данных могут значительно повысить точность обучения.
При обучении со слабым учителем ярлыки обучения шумные, ограниченные или неточные; однако эти метки часто дешевле получить, что приводит к более эффективным обучающим выборкам.
Обучение с подкреплением является областью машинного обучения касается того, как программное обеспечение, агенты должны принимать меры в среде так, чтобы максимизировать некоторое представление о совокупной награды. Благодаря своей общности, поле изучаются во многих других областях, такие, как теория игр, теория управления, исследование операций, теория информации, моделирование на основе оптимизация, многоагентные системы, роя интеллект, статистика и генетические алгоритмы. В машинном обучении среда обычно представлена как марковский процесс принятия решений (MDP). Многие алгоритмы обучения с подкреплением используют методы динамического программирования. Алгоритмы обучения с подкреплением не предполагают знания точной математической модели MDP и используются, когда точные модели невозможны. Алгоритмы обучения с подкреплением используются в автономных транспортных средствах или при обучении игре против человеческого противника.
Снижение размерности - это процесс уменьшения количества рассматриваемых случайных величин путем получения набора основных переменных. Другими словами, это процесс уменьшения размера набора функций, также называемый «количеством функций». Большинство методов уменьшения размерности можно рассматривать как удаление или извлечение признаков. Одним из популярных методов уменьшения размерности является анализ главных компонент (PCA). PCA включает в себя изменение данных более высокой размерности (например, 3D) на меньшее пространство (например, 2D). Это приводит к меньшему размеру данных (2D вместо 3D) при сохранении всех исходных переменных в модели без изменения данных. Гипотеза многообразия предполагает, что наборы данных большой размерности лежат вдоль многообразий низкой размерности, и многие методы уменьшения размерности делают это предположение, что приводит к области изучения многообразия и регуляризации многообразия.
Были разработаны другие подходы, которые не вписываются в эту тройную категоризацию, и иногда в одной и той же системе машинного обучения используется более одного. Например, тематическое моделирование, мета-обучение.
По состоянию на 2020 год глубокое обучение стало доминирующим подходом для большей части текущей работы в области машинного обучения.
Самообучение как парадигма машинного обучения была представлена в 1982 году вместе с нейронной сетью, способной к самообучению, названной поперечным адаптивным массивом (CAA). Это обучение без внешнего вознаграждения и без внешнего совета учителя. Алгоритм самообучения CAA перекрестным образом вычисляет как решения о действиях, так и эмоции (чувства) в отношении последствий ситуаций. Система управляется взаимодействием познания и эмоций. Алгоритм самообучения обновляет матрицу памяти W = || w (a, s) || таким образом, что на каждой итерации выполняется следующая процедура машинного обучения:
In situation s perform an action a; Receive consequence situation s’; Compute emotion of being in consequence situation v(s’); Update crossbar memory w’(a,s) = w(a,s) + v(s’).
Это система только с одним входом, ситуацией s и только одним выходом, действием (или поведением) a. Нет ни отдельного подкрепления, ни совета из среды. Ценность обратного распространения (вторичное подкрепление) - это эмоция по отношению к ситуации последствий. CAA существует в двух средах: одна - это поведенческая среда, в которой он ведет себя, а другая - генетическая среда, откуда он изначально и только один раз получает начальные эмоции по поводу ситуаций, с которыми он может столкнуться в поведенческой среде. После получения вектора генома (видов) из генетической среды CAA обучается целенаправленному поведению в среде, которая содержит как желательные, так и нежелательные ситуации.
Несколько алгоритмов обучения направлены на обнаружение лучшего представления входных данных, предоставляемых во время обучения. Классические примеры включают анализ главных компонентов и кластерный анализ. Алгоритмы изучения функций, также называемые алгоритмами обучения представлению, часто пытаются сохранить информацию во входных данных, но также преобразовать ее таким образом, чтобы сделать ее полезной, часто в качестве этапа предварительной обработки перед выполнением классификации или прогнозов. Этот метод позволяет реконструировать входные данные, поступающие из неизвестного распределения, генерирующего данные, при этом не обязательно сохраняя верность конфигурациям, которые неправдоподобны в этом распределении. Это заменяет ручную разработку функций и позволяет машине как изучать функции, так и использовать их для выполнения определенной задачи.
Изучение функций может быть контролируемым или неконтролируемым. При обучении с учителем функции изучаются с использованием помеченных входных данных. Примеры включают искусственные нейронные сети, многослойные персептроны и контролируемое изучение словаря. При неконтролируемом обучении функций функции изучаются с немаркированными входными данными. Примеры включают изучение словаря, анализ независимых компонентов, автоэнкодеры, матричную факторизацию и различные формы кластеризации.
Алгоритмы обучения многообразию пытаются сделать это при ограничении, заключающемся в том, что изученное представление является низкоразмерным. Алгоритмы разреженного кодирования пытаются сделать это при том ограничении, что изученное представление является разреженным, что означает, что математическая модель имеет много нулей. Алгоритмы обучения мультилинейных подпространств нацелены на изучение низкоразмерных представлений непосредственно из тензорных представлений многомерных данных без преобразования их в многомерные векторы. Алгоритмы глубокого обучения обнаруживают несколько уровней представления или иерархию функций с более высокоуровневыми, более абстрактными функциями, определенными в терминах (или генерирующих) функций более низкого уровня. Утверждалось, что интеллектуальная машина - это машина, которая изучает представление, которое выделяет основные факторы вариации, объясняющие наблюдаемые данные.
Функциональное обучение мотивировано тем фактом, что задачи машинного обучения, такие как классификация, часто требуют ввода, который математически и вычислительно удобно обрабатывать. Однако реальные данные, такие как изображения, видео и сенсорные данные, не поддались попыткам алгоритмического определения конкретных характеристик. Альтернативой является обнаружение таких функций или представлений путем изучения, не полагаясь на явные алгоритмы.
Изучение разреженного словаря - это метод обучения функции, в котором обучающий пример представлен как линейная комбинация базисных функций и считается разреженной матрицей. Этот метод является NP-трудным и трудно решаемым приблизительно. Популярным эвристическим методом изучения разреженного словаря является алгоритм K-SVD. Редкое изучение словаря применялось в нескольких контекстах. При классификации проблема состоит в том, чтобы определить класс, к которому принадлежит ранее невидимый обучающий пример. Для словаря, в котором каждый класс уже создан, новый обучающий пример связан с классом, который лучше всего редко представлен соответствующим словарем. Редкое изучение словаря также применяется для уменьшения шума изображения. Ключевая идея состоит в том, что чистый фрагмент изображения может быть редко представлен словарем изображений, а шум - нет.
В интеллектуальном анализе данных обнаружение аномалий, также известное как обнаружение выбросов, представляет собой идентификацию редких элементов, событий или наблюдений, вызывающих подозрения, поскольку они значительно отличаются от большинства данных. Обычно аномальные элементы представляют собой такие проблемы, как банковское мошенничество, структурный дефект, медицинские проблемы или ошибки в тексте. Аномалии называются выбросами, новинками, шумом, отклонениями и исключениями.
В частности, в контексте обнаружения злоупотреблений и сетевых вторжений интересными объектами часто являются не редкие объекты, а неожиданные всплески бездействия. Этот шаблон не соответствует общему статистическому определению выброса как редкого объекта, и многие методы обнаружения выбросов (в частности, неконтролируемые алгоритмы) не работают с такими данными, если они не были агрегированы надлежащим образом. Вместо этого алгоритм кластерного анализа может обнаруживать микрокластеры, образованные этими шаблонами.
Существуют три широкие категории методов обнаружения аномалий. Методы неконтролируемого обнаружения аномалий обнаруживают аномалии в немаркированном наборе тестовых данных в предположении, что большинство экземпляров в наборе данных являются нормальными, путем поиска экземпляров, которые кажутся наименее подходящими для остальной части набора данных. Для контролируемых методов обнаружения аномалий требуется набор данных, который был помечен как «нормальный» и «ненормальный», и включает обучение классификатора (ключевым отличием от многих других задач статистической классификации является несбалансированный характер обнаружения выбросов). Методы полууправляемого обнаружения аномалий создают модель, представляющую нормальное поведение из заданного набора данных для нормального обучения, а затем проверяют вероятность того, что модель будет сгенерирована тестовым экземпляром.
В развивающей робототехнике, как и в случае с людьми, они выполняют сервальные задачи и управляются компьютерами, часть вычислений и алгоритм обучения роботов, алгоритмы обучения роботов генерируют свои собственные последовательности обучения, также известные как учебные программы, для совокупного приобретения новых навыков посредством самостоятельного исследования. и социальное взаимодействие с людьми. Эти роботы используют такие механизмы наведения, как активное обучение, созревание, моторная синергия и имитация.
Обучение правилам ассоциации - это основанный на правилах метод машинного обучения для обнаружения взаимосвязей между переменными в больших базах данных. Он предназначен для выявления строгих правил, обнаруженных в базах данных, с использованием некоторой степени «интересности».
Машинное обучение на основе правил - это общий термин для любого метода машинного обучения, который определяет, изучает или развивает «правила» для хранения, манипулирования или применения знаний. Определяющей характеристикой алгоритма машинного обучения, основанного на правилах, является идентификация и использование набора реляционных правил, которые в совокупности представляют знания, полученные системой. Это контрастирует с другими алгоритмами машинного обучения, которые обычно определяют особую модель, которую можно универсально применить к любому экземпляру, чтобы сделать прогноз. Подходы к машинному обучению на основе правил включают в себя обучающие системы классификаторов, обучение ассоциативным правилам и искусственную иммунную систему.
На основе концепции сильных правил, Ракеш Агравал, Томаш Имиелински и Арун Свами введены ассоциативные правила для выявления закономерностей между продуктами в данной транзакции крупномасштабной записанного пунктом-продажи (POS) система в супермаркетах. Например, правило, обнаруженное в данных о продажах супермаркета, указывает на то, что, если покупатель покупает лук и картофель вместе, он, вероятно, также купит мясо для гамбургеров. Такая информация может использоваться в качестве основы для принятия решений о маркетинговых мероприятиях, таких как рекламные цены или размещение продуктов. В дополнение к анализу рыночной корзины, ассоциативные правила сегодня используются в таких областях приложений, как анализ использования веб-ресурсов, обнаружение вторжений, непрерывное производство и биоинформатика. В отличие от анализа последовательности, изучение ассоциативных правил обычно не учитывает порядок элементов ни внутри транзакции, ни между транзакциями.
Изучение системы классификаторов (ЛВП) представляют собой семейство алгоритмов машинного обучения на основе правил, которые сочетают в себе компонент обнаружения, как правило, в генетический алгоритм, с компонентом обучения, выполняя либо под наблюдением обучения, обучения с подкреплением, или неконтролируемого обучения. Они стремятся идентифицировать набор контекстно-зависимых правил, которые коллективно хранят и применяют знания по частям, чтобы делать прогнозы.
Индуктивное логическое программирование (ILP) - это подход к изучению правил с использованием логического программирования в качестве унифицированного представления для входных примеров, базовых знаний и гипотез. С учетом кодирования известных фоновых знаний и набора примеров, представленных в виде логической базы данных фактов, система ILP выведет гипотетическую логическую программу, которая влечет за собой все положительные и никакие отрицательные примеры. Индуктивное программирование - это смежная область, которая рассматривает любой язык программирования для представления гипотез (а не только логическое программирование), например, функциональные программы.
Индуктивное логическое программирование особенно полезно в биоинформатике и обработке естественного языка. Гордон Плоткин и Эхуд Шапиро заложили первоначальную теоретическую основу для индуктивного машинного обучения в логической среде. Шапиро построил свою первую реализацию (систему вывода моделей) в 1981 году: программу на языке Prolog, которая индуктивно выводила логические программы из положительных и отрицательных примеров. Термин индуктивный здесь относится к философской индукции, предлагающей теорию для объяснения наблюдаемых фактов, а не к математической индукции, доказывающей свойство для всех членов хорошо упорядоченного множества.
Выполнение машинного обучения включает в себя создание модели, которая обучается на некоторых обучающих данных, а затем может обрабатывать дополнительные данные для прогнозирования. Для систем машинного обучения использовались и исследовались различные типы моделей.
 Искусственная нейронная сеть - это взаимосвязанная группа узлов, подобная обширной сети нейронов в головном мозге. Здесь каждый круговой узел представляет собой искусственный нейрон, а стрелка представляет собой соединение между выходом одного искусственного нейрона и входом другого.
Искусственная нейронная сеть - это взаимосвязанная группа узлов, подобная обширной сети нейронов в головном мозге. Здесь каждый круговой узел представляет собой искусственный нейрон, а стрелка представляет собой соединение между выходом одного искусственного нейрона и входом другого. Искусственные нейронные сети (ИНС) или коннекционистские системы - это вычислительные системы, смутно вдохновленные биологическими нейронными сетями, составляющими мозг животных. Такие системы «учатся» выполнять задачи, рассматривая примеры, как правило, без программирования каких-либо правил для конкретных задач.
ИНС - это модель, основанная на наборе связанных единиц или узлов, называемых « искусственными нейронами », которые в общих чертах моделируют нейроны в биологическом мозге. Каждое соединение, как синапсы в биологическом мозге, может передавать информацию, «сигнал», от одного искусственного нейрона к другому. Искусственный нейрон, который получает сигнал, может обработать его, а затем передать сигнал дополнительным искусственным нейронам, подключенным к нему. В обычных реализациях ИНС сигнал в соединении между искусственными нейронами является действительным числом, а выходной сигнал каждого искусственного нейрона вычисляется некоторой нелинейной функцией суммы его входных сигналов. Связи между искусственными нейронами называются «ребрами». Искусственные нейроны и ребра обычно имеют вес, который корректируется по мере обучения. Вес увеличивает или уменьшает силу сигнала в соединении. Искусственные нейроны могут иметь такой порог, что сигнал отправляется только в том случае, если совокупный сигнал пересекает этот порог. Обычно искусственные нейроны объединены в слои. Разные слои могут выполнять разные виды преобразований на своих входах. Сигналы проходят от первого слоя (входной) к последнему (выходному), возможно, после многократного прохождения слоев.
Первоначальная цель подхода ИНС заключалась в том, чтобы решать проблемы так же, как это делает человеческий мозг. Однако со временем внимание переключилось на выполнение конкретных задач, что привело к отклонениям от биологии. Искусственные нейронные сети использовались для решения множества задач, включая компьютерное зрение, распознавание речи, машинный перевод, фильтрацию социальных сетей, настольные игры и видеоигры, а также медицинскую диагностику.
Глубокое обучение состоит из нескольких скрытых слоев в искусственной нейронной сети. Этот подход пытается смоделировать то, как человеческий мозг обрабатывает свет и звук в зрение и слух. Некоторые успешные применения глубокого обучения - это компьютерное зрение и распознавание речи.
При обучении по дереву решений дерево решений используется в качестве модели прогнозирования для перехода от наблюдений за элементом (представленных в ветвях) к выводам о целевом значении элемента (представленных в листьях). Это один из подходов к прогнозному моделированию, используемых в статистике, интеллектуальном анализе данных и машинном обучении. Модели деревьев, в которых целевая переменная может принимать дискретный набор значений, называются деревьями классификации; в этих древовидных структурах листья представляют метки классов, а ветви представляют соединения функций, которые ведут к этим меткам классов. Деревья решений, в которых целевая переменная может принимать непрерывные значения (обычно действительные числа ), называются деревьями регрессии. При анализе решений дерево решений может использоваться для визуального и явного представления решений и принятия решений. При интеллектуальном анализе данных дерево решений описывает данные, но результирующее дерево классификации может быть входом для принятия решения.
Машины опорных векторов (SVM), также известные как сети опорных векторов, представляют собой набор связанных контролируемых методов обучения, используемых для классификации и регрессии. По заданному набору обучающих примеров, каждый из которых помечен как принадлежащий к одной из двух категорий, алгоритм обучения SVM строит модель, которая предсказывает, попадает ли новый пример в ту или иную категорию. Алгоритм SVM обучения является не- вероятностным, двоичный, линейный классификатора, хотя методы, таких как масштабирование Platt EXIST использовать SVM в вероятностной настройке классификации. Помимо выполнения линейной классификации, SVM могут эффективно выполнять нелинейную классификацию, используя так называемый трюк с ядром, неявно отображая свои входные данные в пространственные объекты большой размерности.
 Иллюстрация линейной регрессии на наборе данных.
Иллюстрация линейной регрессии на наборе данных. Регрессионный анализ включает в себя большое количество статистических методов для оценки взаимосвязи между входными переменными и связанными с ними характеристиками. Наиболее распространенной формой является линейная регрессия, когда рисуется одна линия, которая наилучшим образом соответствует заданным данным в соответствии с математическим критерием, таким как обычный метод наименьших квадратов. Последний часто расширяется с помощью методов регуляризации (математики) для смягчения переобучения и смещения, как в регрессии гребня. При решении нелинейных задач модели перехода включают полиномиальную регрессию (например, используемую для подбора линии тренда в Microsoft Excel), логистическую регрессию (часто используемую в статистической классификации ) или даже регрессию ядра, которая вводит нелинейность за счет использования преимущества от трюка ядра неявно карту входных переменных в многомерном пространстве.
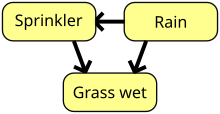 Простая байесовская сеть. Дождь влияет на включение дождевателя, а дождь и дождеватель влияют на то, будет ли трава влажной.
Простая байесовская сеть. Дождь влияет на включение дождевателя, а дождь и дождеватель влияют на то, будет ли трава влажной. Байесовская сеть, сеть убеждений или направленная ациклическая графическая модель - это вероятностная графическая модель, которая представляет набор случайных величин и их условную независимость с направленным ациклическим графом (DAG). Например, байесовская сеть может представлять вероятностные отношения между болезнями и симптомами. Учитывая симптомы, сеть может использоваться для вычисления вероятности наличия различных заболеваний. Существуют эффективные алгоритмы, выполняющие выводы и обучение. Байесовские сети, моделирующие последовательности переменных, таких как речевые сигналы или белковые последовательности, называются динамическими байесовскими сетями. Обобщения байесовских сетей, которые могут представлять и решать проблемы принятия решений в условиях неопределенности, называются диаграммами влияния.
Генетический алгоритм (ГА) - это алгоритм поиска и эвристический метод, который имитирует процесс естественного отбора, используя такие методы, как мутация и кроссовер, для создания новых генотипов в надежде найти хорошие решения данной проблемы. В машинном обучении генетические алгоритмы использовались в 1980-х и 1990-х годах. И наоборот, методы машинного обучения использовались для повышения производительности генетических и эволюционных алгоритмов.
Обычно для хорошей работы модели машинного обучения требуют большого количества данных. Обычно при обучении модели машинного обучения необходимо собрать большую репрезентативную выборку данных из обучающей выборки. Данные из обучающего набора могут быть такими же разнообразными, как корпус текста, набор изображений и данные, собранные от отдельных пользователей службы. При обучении модели машинного обучения следует остерегаться переобучения. Обученные модели, полученные на основе предвзятых данных, могут приводить к искаженным или нежелательным прогнозам. Алгоритмическая ошибка - это потенциальный результат не полностью подготовленных данных для обучения.
Федеративное обучение - это адаптированная форма распределенного искусственного интеллекта для обучения моделей машинного обучения, которая децентрализует процесс обучения, позволяя сохранять конфиденциальность пользователей, не отправляя их данные на централизованный сервер. Это также увеличивает эффективность за счет децентрализации процесса обучения на многих устройствах. Например, Gboard использует федеративное машинное обучение для обучения моделей прогнозирования поисковых запросов на мобильных телефонах пользователей без необходимости отправлять отдельные поисковые запросы обратно в Google.
Есть много приложений для машинного обучения, в том числе:
В 2006 году поставщик медиа-услуг Netflix провел первый конкурс « Netflix Prize », чтобы найти программу, которая лучше прогнозирует предпочтения пользователей и повышает точность существующего алгоритма рекомендаций фильмов Cinematch как минимум на 10%. Совместная команда, состоящая из исследователей из ATamp;T Labs -Research в сотрудничестве с командами Big Chaos и Pragmatic Theory, построила ансамблевую модель, чтобы выиграть Гран-при в 2009 году за 1 миллион долларов. Вскоре после присуждения приза Netflix осознал, что рейтинги зрителей не являются лучшими показателями их моделей просмотра («все является рекомендацией»), и соответствующим образом изменили свой механизм рекомендаций. В 2010 году The Wall Street Journal писала о компании Rebellion Research и их использовании машинного обучения для прогнозирования финансового кризиса. В 2012 году один из основателей Sun Microsystems, Винод Косла, предсказал, что 80% рабочих мест медицинских врачей будут потеряны в течение следующих двух десятилетий в автоматизированной машине обучения медицинского диагностического программного обеспечения. В 2014 году сообщалось, что алгоритм машинного обучения был применен в области истории искусства для изучения картин изобразительного искусства и что он, возможно, выявил ранее не признанное влияние среди художников. В 2019 году Springer Nature опубликовала первую исследовательскую книгу, созданную с помощью машинного обучения. В 2020 году технология машинного обучения использовалась для постановки диагноза и помощи исследователям в разработке лекарства от COVID-19. Машинное обучение в последнее время применяется для прогнозирования экологического поведения человека. В последнее время технология машинного обучения также применяется для оптимизации производительности смартфона и температурного режима на основе взаимодействия пользователя с телефоном.
Хотя машинное обучение способствовало преобразованию в некоторых областях, программы машинного обучения часто не дают ожидаемых результатов. Причин тому множество: отсутствие (подходящих) данных, отсутствие доступа к данным, предвзятость данных, проблемы с конфиденциальностью, плохо выбранные задачи и алгоритмы, неправильные инструменты и люди, нехватка ресурсов и проблемы с оценкой.
В 2018 году беспилотный автомобиль Uber не смог обнаружить пешехода, который погиб в результате столкновения. Попытки использовать машинное обучение в здравоохранении с системой IBM Watson не увенчались успехом даже после многих лет и миллиардов вложенных долларов.
Машинное обучение использовалось в качестве стратегии для обновления данных, связанных с систематическим обзором, и увеличения нагрузки на рецензентов, связанной с ростом биомедицинской литературы. Несмотря на то, что он улучшился с помощью обучающих наборов, он еще не разработан в достаточной степени, чтобы снизить рабочую нагрузку без ограничения необходимой чувствительности для самих исследований результатов.
В частности, подходы к машинному обучению могут страдать от различных искажений данных. Система машинного обучения, специально обученная для текущих клиентов, может быть не в состоянии предсказать потребности новых групп клиентов, которые не представлены в данных обучения. При обучении на данных, созданных руками человека, машинное обучение может улавливать конституционные и бессознательные предубеждения, уже существующие в обществе. Было показано, что языковые модели, полученные на основе данных, содержат человеческие предубеждения. Было обнаружено, что системы машинного обучения, используемые для оценки криминального риска, предвзято относятся к чернокожим. В 2015 году фотографии Google часто помечали чернокожих людей как горилл, а в 2018 году это все еще не было решено, но, как сообщается, Google все еще использовал обходной путь для удаления всех горилл из данных обучения и, таким образом, не мог распознавать настоящих горилл в все. Подобные проблемы с распознаванием небелых людей были обнаружены во многих других системах. В 2016 году Microsoft протестировала чат-бота, который учился у Twitter, и быстро освоил расистские и сексистские выражения. Из-за таких проблем эффективное использование машинного обучения может занять больше времени, чтобы внедрить его в других областях. Забота о справедливости машинного обучения, то есть уменьшении предвзятости в машинном обучении и продвижении его использования на благо человека, все чаще выражается учеными в области искусственного интеллекта, в том числе Фей-Фей Ли, который напоминает инженерам, что «В ИИ нет ничего искусственного... Это вдохновленный людьми, он создается людьми и, что наиболее важно, влияет на людей. Это мощный инструмент, который мы только начинаем понимать, и это огромная ответственность ».
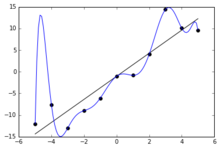 Синяя линия может быть примером переобучения линейной функции из-за случайного шума.
Синяя линия может быть примером переобучения линейной функции из-за случайного шума. Использование плохой, слишком сложной теории, приспособленной для соответствия всем прошлым обучающим данным, называется переобучением. Многие системы пытаются уменьшить переобучение, вознаграждая теорию в соответствии с тем, насколько хорошо она соответствует данным, но наказывая теорию в соответствии с ее сложностью.
Учащиеся также могут разочаровать, «усвоив неправильный урок». Игрушечный пример: классификатор изображений, обученный только изображениям коричневых лошадей и черных кошек, может сделать вывод, что все коричневые пятна, скорее всего, принадлежат лошадям. Пример из реальной жизни состоит в том, что, в отличие от людей, современные классификаторы изображений часто не выносят суждений в первую очередь на основе пространственных отношений между компонентами изображения, и они изучают отношения между пикселями, которые люди не замечают, но которые все же коррелируют с изображениями изображений. определенные типы реальных объектов. Изменение этих шаблонов на легитимном изображении может привести к появлению «состязательных» изображений, которые система неправильно классифицирует.
Состязательные уязвимости также могут привести к нелинейным системам или из-за нестандартных возмущений. Некоторые системы настолько хрупкие, что изменение одного пикселя-противника предсказуемо приводит к ошибочной классификации.
Классификация моделей машинного обучения может быть подтверждена с помощью методов оценки точности, таких как метод удержания, который разделяет данные на обучающий и тестовый набор (обычно 2/3 обучающего набора и 1/3 обозначения набора тестов) и оценивает производительность обучающей модели. на тестовом наборе. Для сравнения, метод K-кратной перекрестной проверки случайным образом разбивает данные на K подмножеств, а затем выполняется K экспериментов, каждый, соответственно, с учетом 1 подмножества для оценки и оставшихся K-1 подмножеств для обучения модели. Помимо методов удержания и перекрестной проверки, для оценки точности модели можно использовать бутстрап, который отбирает n экземпляров с заменой из набора данных.
В дополнение к общей точности исследователи часто сообщают о чувствительности и специфичности, имея в виду истинно положительную частоту (TPR) и истинно отрицательную частоту (TNR) соответственно. Точно так же исследователи иногда сообщают о частоте ложных срабатываний (FPR), а также о частоте ложноотрицательных результатов (FNR). Однако эти коэффициенты представляют собой коэффициенты, которые не раскрывают своих числителей и знаменателей. Общая характеристика срабатывания (ТОС) является эффективным методом, чтобы выразить диагностическую способность модели. TOC показывает числители и знаменатели ранее упомянутых скоростей, таким образом, TOC предоставляет больше информации, чем обычно используемые рабочие характеристики приемника (ROC) и связанная с ними площадь ROC под кривой (AUC).
Машинное обучение ставит множество этических вопросов. Системы, которые обучены на наборах данных, собранных с ошибками, могут демонстрировать эти предубеждения при использовании ( алгоритмическое смещение ), тем самым оцифровывая культурные предрассудки. Например, в 1988 году Комиссия Великобритании по расовому равенству обнаружила, что медицинская школа Св. Георгия использовала компьютерную программу, обученную на основе данных предыдущего приемного персонала, и эта программа отклонила почти 60 кандидатов, которые оказались либо женщинами, либо не имели -Европейски звучащие имена. Использование данных о найме на работу от фирмы с расистской политикой приема на работу может привести к тому, что система машинного обучения будет дублировать предвзятость, оценивая кандидатов на работу по сходству с предыдущими успешными кандидатами. Таким образом, ответственный сбор данных и документирование алгоритмических правил, используемых системой, является важной частью машинного обучения.
ИИ может быть хорошо оснащен для принятия решений в технических областях, которые в значительной степени полагаются на данные и историческую информацию. Эти решения основаны на объективности и логической аргументации. Поскольку человеческие языки содержат предубеждения, машины, обученные языковым корпусам, обязательно также изучат эти предубеждения.
Другие формы этических проблем, не связанные с личными предубеждениями, наблюдаются в сфере здравоохранения. Специалисты в области здравоохранения опасаются, что эти системы могут быть разработаны не в интересах общества, а как машины, приносящие доход. Это особенно верно в Соединенных Штатах, где существует давняя этическая дилемма улучшения здравоохранения, но также и увеличения прибыли. Например, алгоритмы могут быть разработаны для предоставления пациентам ненужных тестов или лекарств, в которых владельцы алгоритмов владеют долями. Машинное обучение в сфере здравоохранения может предоставить профессионалам дополнительный инструмент для диагностики, лечения и планирования путей выздоровления пациентов, но для этого необходимо устранить эти предубеждения.
С 2010-х годов достижения как в алгоритмах машинного обучения, так и в компьютерном оборудовании привели к созданию более эффективных методов обучения глубоких нейронных сетей (особая узкая подобласть машинного обучения), которые содержат множество уровней нелинейных скрытых единиц. К 2019 году графические процессоры ( GPU ), часто с улучшениями, специфичными для ИИ, вытеснили ЦП в качестве доминирующего метода обучения крупномасштабного коммерческого облачного ИИ. OpenAI оценил объем аппаратных вычислений, используемых в крупнейших проектах глубокого обучения от AlexNet (2012 г.) до AlphaZero (2017 г.), и обнаружил, что объем требуемых вычислений увеличился в 300000 раз, а график тренда времени удвоения составил 3,4 месяца.
Физическая нейронная сеть или Neuromorphic компьютер представляет собой тип искусственной нейронной сети, в которой электрический регулируемый материал используется для эмуляции функции нейронной синапсе. «Физическая» нейронная сеть используется, чтобы подчеркнуть зависимость от физического оборудования, используемого для имитации нейронов, в отличие от программных подходов. В более общем смысле этот термин применим к другим искусственным нейронным сетям, в которых мемристор или другой электрически регулируемый материал сопротивления используется для имитации нейронного синапса.
Программные пакеты, содержащие различные алгоритмы машинного обучения, включают следующее:

