
Войти
В статистика, логистика модель (или модель логита ) используется для моделирования вероятности существования определенного класса или события, например, пройден / не пройден, выиграл / проиграл, жив / мертв или здоров / болен. Это может быть расширено для моделирования нескольких классов событий, таких как определение наличия на изображении кошки, собаки, льва и т. Д. Каждому обнаруживаемому на изображении объекту будет присвоена вероятность от 0 до 1 с суммой, равной единице.
Логистическая регрессия - это статистическая модель, которая в своей базовой форме использует логистическую функцию для моделирования двоичной зависимой переменной, хотя существует множество более сложных расширений. В регрессионном анализе, логистическая регрессия (или логит-регрессия ) - это оценка параметров логистической модели (форма двоичная регрессия ). Математически бинарная логистическая модель имеет зависимую переменную с двумя возможными значениями, например годен / не годен, которая представлена индикаторной переменной , где два значения помечены как «0» и «1». В логистической модели логарифм-шансы (логарифм от шансов ) для значения с меткой «1» представляет собой линейную комбинацию одной или нескольких независимых переменных («предикторов»); каждая независимая переменная может быть двоичной переменной (два класса, кодируемых индикаторной переменной) или непрерывной переменной (любое действительное значение). Соответствующая вероятность значения, помеченного «1», может варьироваться от 0 (обязательно значение «0») до 1 (безусловно, значение «1»), отсюда и маркировка; функция, которая преобразует логарифмические шансы в вероятность, является логистической функцией, отсюда и название. единица измерения для логарифмической шкалы шансов называется логит, от log istic un it, отсюда и альтернативные названия. Можно также использовать аналогичные модели с другой сигмовидной функцией вместо логистической функции, например, пробит-модель ; определяющей характеристикой логистической модели является то, что увеличение одной из независимых переменных мультипликативно увеличивает шансы данного результата с постоянной скоростью, при этом каждая независимая переменная имеет свой собственный параметр; для двоичной зависимой переменной это обобщает отношение шансов.
. В модели двоичной логистической регрессии зависимая переменная имеет два уровня (категориальный ). Выходы с более чем двумя значениями моделируются с помощью полиномиальной логистической регрессии и, если несколько категорий упорядочены, с помощью порядковой логистической регрессии (например, порядковый номер пропорционального шанса логистическая модель). Сама модель логистической регрессии просто моделирует вероятность выхода с точки зрения входных данных и не выполняет статистическую классификацию (это не классификатор), хотя ее можно использовать для создания классификатора, например, путем выбора порогового значения. значение и классификация входных данных с вероятностью выше порогового значения как один класс, ниже порогового значения как другой; это обычный способ создания бинарного классификатора . Коэффициенты обычно не вычисляются с помощью выражения в замкнутой форме, в отличие от линейного метода наименьших квадратов ; см. § Примерка модели. Логистическая регрессия как общая статистическая модель была первоначально разработана и популяризирована в первую очередь Джозефом Берксоном, начиная с Берксона (1944) harvtxt error: no target: CITEREFBerkson1944 (help ), где он придумал "логит"; см. § История.
Логистическая регрессия используется в различных областях, включая машинное обучение, большинство областей медицины и социальных наук. Например, шкала оценки травм и тяжести травм (TRISS ), которая широко используется для прогнозирования смертности травмированных пациентов, была первоначально разработана Бойдом и др. с использованием логистической регрессии. Многие другие медицинские шкалы, используемые для оценки степени тяжести состояния пациента, были разработаны с использованием логистической регрессии. Логистическая регрессия может использоваться для прогнозирования риска развития данного заболевания (например, диабет ; ишемическая болезнь сердца ) на основе наблюдаемых характеристик пациента (возраст, пол, индекс массы тела, результаты различных анализов крови и т. д.). Другой пример может заключаться в том, чтобы предсказать, проголосует ли непальский избиратель за Конгресс Непала, Коммунистическую партию Непала или любую другую партию, на основании возраста, дохода, пола, расы, государства проживания, голосов на предыдущих выборах и т. Д. используется в инженерии, особенно для прогнозирования вероятности отказа данного процесса, системы или продукта. Он также используется в приложениях маркетинга, таких как прогнозирование склонности клиента к покупке продукта или прекращению подписки и т. Д. В экономике его можно использовать для прогнозирования вероятности того, что человек выбрав работу, и бизнес-приложение должно было бы прогнозировать вероятность того, что домовладелец не сможет выполнить свои обязательства по ипотеке . Условные случайные поля, расширение логистической регрессии для последовательных данных, используются в обработке естественного языка.
Давайте попробуем понять логистическую регрессию, рассмотрев логистическую модель с заданными параметрами, а затем увидев, как можно оценить коэффициенты на основе данных. Рассмотрим модель с двумя предикторами, 







Мы можем восстановить шансы, возведя в степень логарифмические шансы:
 .
.С помощью простых алгебраических манипуляций вероятность того, что
 .
.Приведенная выше формула показывает, что как только 

Мы рассмотрим пример с 




где
Это можно интерпретировать следующим образом:
- y- перехватить. Это логарифм события, что , когда предикторы  . Возведя в степень, мы можем увидеть, что когда вероятность того, что от 1 до 1000 или
. Возведя в степень, мы можем увидеть, что когда вероятность того, что от 1 до 1000 или  . Точно так же вероятность события, что , когда можно вычислить как
. Точно так же вероятность события, что , когда можно вычислить как  .означает, что увеличение на 1 увеличивает логарифмические шансы на
.означает, что увеличение на 1 увеличивает логарифмические шансы на  . Таким образом, если увеличивается на 1, шансы того, что увеличиваются на коэффициент
. Таким образом, если увеличивается на 1, шансы того, что увеличиваются на коэффициент  . Обратите внимание, что вероятность из также увеличилась, но не настолько, насколько увеличились шансы.означает, что увеличение на 1 увеличивает журнал -odds по
. Обратите внимание, что вероятность из также увеличилась, но не настолько, насколько увеличились шансы.означает, что увеличение на 1 увеличивает журнал -odds по  . Таким образом, если увеличивается на 1, шансы того, что увеличиваются на коэффициент
. Таким образом, если увеличивается на 1, шансы того, что увеличиваются на коэффициент  Обратите внимание, как влияние на логарифмические шансы вдвое больше, чем эффект , но влияние на шансы в 10 раз больше. Но влияние на вероятность из не в 10 раз больше, это только влияние на шансы В 10 раз больше.
Обратите внимание, как влияние на логарифмические шансы вдвое больше, чем эффект , но влияние на шансы в 10 раз больше. Но влияние на вероятность из не в 10 раз больше, это только влияние на шансы В 10 раз больше.Чтобы оценить параметры
Чтобы ответить на следующий вопрос:
Группа из 20 студентов тратит от 0 до 6 часов на подготовку к экзамену. Как количество часов, потраченных на обучение, влияет на вероятность сдачи студентом экзамена?
Причина использования логистической регрессии для этой проблемы заключается в том, что значения зависимой переменной, пройден и не пройден, хотя и представлены «1» и «0», не являются количественными числами. Если проблема была изменена таким образом, что результат «прошел / не прошел» был заменен оценкой 0–100 (количественные числа), то можно было использовать простой регрессионный анализ .
В таблице показано количество часов, потраченных каждым студентом на обучение, а также его прохождение (1) или неудача (0).
| Часы | 0,50 | 0,75 | 1,00 | 1,25 | 1,50 | 1,75 | 1,75 | 2,00 | 2,25 | 2,50 | 2,75 | 3,00 | 3,25 | 3,50 | 4,00 | 4,25 | 4,50 | 4,75 | 5,00 | 5,50 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Пройдено | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
График показывает вероятность сдачи экзамена в зависимости от количества часов обучения, с кривой логистической регрессии, подобранной к данным.
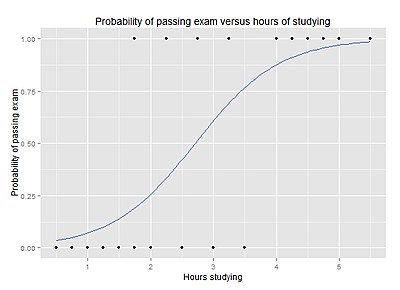 График кривой логистической регрессии, показывающий вероятность сдачи экзамена по сравнению с часами обучения.
График кривой логистической регрессии, показывающий вероятность сдачи экзамена по сравнению с часами обучения. Анализ логистической регрессии дает следующий результат.
| Коэффициент | Стандартная ошибка | z- значение | P-значение (Wald) | |
|---|---|---|---|---|
| Intercept | -4.0777 | 1,7610 | −2,316 | 0,0206 |
| Часы | 1,5046 | 0,6287 | 2,393 | 0,0167 |
Вывод показывает, что количество часов обучения в значительной степени связано с вероятностью сдачи экзамена (



Один дополнительный час обучения, по оценкам, увеличит логарифмические шансы успешного прохождения экзамена на 1,5046, поэтому умножение шансов на прохождение экзамена на 
Например, для студента, который учится 2 часа, ввод значения 

Аналогично, для студента, который учится 4 часа, оценочная вероятность сдача экзамена составляет 0,87:

В этой таблице показана вероятность сдачи экзамена для нескольких значений часов обучения.
| Часы. учебы | Сдача экзамена | ||
|---|---|---|---|
| Журналы | Запросы | Вероятность | |
| 1 | −2,57 | 0,076 ≈ 1: 13,1 | 0,07 |
| 2 | −1,07 | 0,34 ≈ 1: 2,91 | 0,26 |
| 3 | 0,44 | 1,55 | 0,61 |
| 4 | 1,94 | 6,96 | 0,87 |
| 5 | 3,45 | 31,4 | 0,97 |
Результат анализа логистической регрессии дает p -значение 
Логистическая регрессия может быть биномиальной, порядковой или полиномиальной. Биномиальная или двоичная логистическая регрессия имеет дело с ситуациями, в которых наблюдаемый результат для зависимой переменной может иметь только два возможных типа: «0» и «1» (которые могут представлять, например, «мертвый» vs. «жив» или «победа» против «проигрыша»). Полиномиальная логистическая регрессия имеет дело с ситуациями, в которых результат может иметь три или более возможных типа (например, «болезнь A» против «болезни B» против «болезни C»), которые не упорядочены. Порядковая логистическая регрессия имеет дело с упорядоченными зависимыми переменными.
В бинарной логистической регрессии результат обычно кодируется как «0» или «1», поскольку это приводит к наиболее простой интерпретации. Если конкретный наблюдаемый результат для зависимой переменной является заслуживающим внимания возможным результатом (называемым «успехом», «экземпляром» или «случаем»), он обычно кодируется как «1», а противоположный результат (называемый «сбой» или «неэкземпляр» или «не случай») как «0». Двоичная логистическая регрессия используется для прогнозирования шансов наличия случая на основе значений независимых переменных (предикторов). Шансы определяются как вероятность того, что конкретный исход является случаем, деленный на вероятность того, что это не случай.
Как и другие формы регрессионного анализа, логистическая регрессия использует одну или несколько переменных-предикторов, которые могут быть непрерывными или категориальными. Однако, в отличие от обычной линейной регрессии, логистическая регрессия используется для прогнозирования зависимых переменных, которые принимают принадлежность к одной из ограниченного числа категорий (рассматривая зависимую переменную в биномиальном случае как результат Бернулли. испытание ), а не непрерывный результат. Учитывая эту разницу, предположения линейной регрессии нарушаются. В частности, остатки не могут быть нормально распределены. Кроме того, линейная регрессия может делать бессмысленные прогнозы для двоичной зависимой переменной. Что необходимо, так это способ преобразования двоичной переменной в непрерывную, которая может принимать любое реальное значение (отрицательное или положительное). Для этого биномиальная логистическая регрессия сначала вычисляет шансы события, происходящего для разных уровней каждой независимой переменной, а затем берет свой логарифм, чтобы создать непрерывный критерий как преобразованную версию зависимая переменная. Логарифм шансов - это логит вероятности, логит определяется следующим образом:
Хотя зависимая переменная в логистической регрессии Бернулли, логит неограниченного масштаба. Логит-функция - это функция связи в таком виде обобщенной линейной модели, то есть

Y - это распределенная Бернулли переменная ответа, а x - переменная-предиктор; значения β - линейные параметры.
Затем логит вероятности успеха подбирается для предикторов. Прогнозируемое значение логита преобразуется обратно в прогнозируемые шансы с помощью обратного натурального логарифма - экспоненциальной функции . Таким образом, хотя наблюдаемая зависимая переменная в бинарной логистической регрессии представляет собой переменную 0 или 1, логистическая регрессия оценивает шансы, как непрерывную переменную, того, что зависимая переменная является «успехом». В некоторых приложениях все, что нужно, - это ставки. В других случаях требуется конкретный прогноз типа «да» или «нет» для определения того, является ли зависимая переменная «успехом»; это категориальное предсказание может быть основано на вычисленных шансах на успех, при этом предсказанные шансы выше некоторого выбранного значения отсечения переводятся в предсказание успеха.
Предположение о линейных эффектах предиктора можно легко ослабить с помощью таких методов, как сплайн-функции.
Логистическая регрессия измеряет взаимосвязь между категориальной зависимой переменной и одну или несколько независимых переменных путем оценки вероятностей с использованием логистической функции , которая является кумулятивной функцией распределения логистического распределения. Таким образом, он обрабатывает тот же набор проблем, что и пробит-регрессия, используя аналогичные методы, причем последний использует вместо этого кумулятивную кривую нормального распределения. Эквивалентно, в интерпретации скрытых переменных этих двух методов, первый предполагает стандартное логистическое распределение ошибок, а второй - стандартное нормальное распределение ошибок.
Логистический регрессию можно рассматривать как частный случай обобщенной линейной модели и, таким образом, аналог линейной регрессии. Однако модель логистической регрессии основана на совершенно иных предположениях (о взаимосвязи между зависимыми и независимыми переменными) от предположений линейной регрессии. В частности, ключевые различия между этими двумя моделями можно увидеть в следующих двух особенностях логистической регрессии. Во-первых, условное распределение 
Логистическая регрессия является альтернативой методу Фишера 1936 года, линейному дискриминантному анализу. Если допущения линейного дискриминантного анализа верны, обусловленность может быть отменена для получения логистической регрессии. Однако обратное неверно, поскольку логистическая регрессия не требует многомерного нормального допущения дискриминантного анализа.
Логистическая регрессия может пониматься просто как нахождение 

где 
Соответствующая скрытая переменная: 



 Рисунок 1. Стандартная логистическая функция
Рисунок 1. Стандартная логистическая функция  ; обратите внимание, что
; обратите внимание, что  для всех
для всех  .
.Объяснение логистической регрессии можно начать с объяснения стандартной логистической функции . Логистическая функция - это сигмовидная функция, которая принимает любой реальный ввод 


График логистической функции на t-интервале (−6,6) показан на рисунке 1.
Предположим, что

И общая логистическая функция 

В логистической модели 




Теперь мы можем определить функцию logit (логарифм шансов) как обратную 

и, что то же самое, после возведения в степень обе стороны мы имеем шансы:

В приведенных выше уравнениях используются следующие члены:
 - логит-функция. Уравнение для
- логит-функция. Уравнение для  показывает, что logit (т. Е. Логарифм шансов или натуральный логарифм шансы) эквивалентно выражению линейной регрессии.
показывает, что logit (т. Е. Логарифм шансов или натуральный логарифм шансы) эквивалентно выражению линейной регрессии. обозначает натуральный логарифм.- вероятность того, что зависимая переменная соответствует случаю, при некоторой линейной комбинации предикторов. Формула для показывает, что вероятность того, что зависимая переменная равна случаю, равна значению логистической функции выражения линейной регрессии. Это важно, поскольку показывает, что значение выражения линейной регрессии может изменяться от отрицательной до положительной бесконечности, и все же после преобразования результирующее выражение для вероятности находится в диапазоне от 0 до 1.
обозначает натуральный логарифм.- вероятность того, что зависимая переменная соответствует случаю, при некоторой линейной комбинации предикторов. Формула для показывает, что вероятность того, что зависимая переменная равна случаю, равна значению логистической функции выражения линейной регрессии. Это важно, поскольку показывает, что значение выражения линейной регрессии может изменяться от отрицательной до положительной бесконечности, и все же после преобразования результирующее выражение для вероятности находится в диапазоне от 0 до 1. - отрезок из уравнения линейной регрессии (значение критерий, когда предиктор равен нулю).
- отрезок из уравнения линейной регрессии (значение критерий, когда предиктор равен нулю). - коэффициент регрессии, умноженный на некоторое значение предиктора.
- коэффициент регрессии, умноженный на некоторое значение предиктора. обозначает экспоненциальную функцию.
обозначает экспоненциальную функцию.Шансы зависимой переменной, равной случаю (при некоторой линейной комбинации
Итак, мы определяем шансы зависимой переменной, равные случаю (при некоторой линейной комбинации

Для непрерывной независимой переменной шансы соотношение может быть определено как:

Эта экспоненциальная зависимость дает интерпретацию для 

Для двоичной независимой переменной отношение шансов определяется как 
Если есть несколько независимых переменных, приведенное выше выражение 


Опять же, более традиционные уравнения:

и

где обычно 
Логистическая регрессия - важный алгоритм машинного обучения. Цель состоит в том, чтобы смоделировать вероятность того, что случайная величина
Рассмотрим обобщенную линейную модель функция, параметризованная с помощью 

Следовательно,

и поскольку 



Как правило, логарифм правдоподобия максимизируется,

which is maximized using optimization techniques such as gradient descent.
Assuming the 
![{\displaystyle {\begin{aligned}\lim \limits _{N\rightarrow +\infty }N^{-1}\sum _{i=1}^{N}\log \Pr(y_{i}\mid x_{i};\theta)=\sum _{x\in {\mathcal {X}}}\sum _{y\in {\mathcal {Y}}}\Pr(X=x,Y=y)\log \Pr(Y=y\mid X=x;\theta)\\[6pt]={}\sum _{x\in {\mathcal {X}}}\sum _{y\in {\mathcal {Y}}}\Pr(X=x,Y=y)\left(-\log {\frac {\Pr(Y=y\mid X=x)}{\Pr(Y=y\mid X=x;\theta)}}+\log \Pr(Y=y\mid X=x)\right)\\[6pt]={}-D_{\text{KL}}(Y\parallel Y_{\theta })-H(Y\mid X)\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9b300972d40831096c1ab7bdf34338a71eca96d9)
where 

A widely used rule of thumb, the "one in ten rule ", states that logistic regression models give stable values for the explanatory variables if based on a minimum of about 10 events per explanatory variable (EPV); где событие обозначает случаи, относящиеся к менее частой категории в зависимой переменной. Thus a study designed to use 

Другие получили результаты, которые не согласуются с вышеизложенным, с использованием других критериев. Полезным критерием является то, будет ли подобранная модель, как ожидается, достичь той же прогностической дискриминации в новой выборке, которую она достигла в образце для разработки модели. Для этого критерия может потребоваться 20 событий для каждой переменной-кандидата. Кроме того, можно утверждать, что 96 наблюдений необходимы только для оценки точки пересечения модели с достаточной точностью, чтобы предел ошибки в прогнозируемых вероятностях составлял ± 0,1 при уровне достоверности 0,95.
Коэффициенты регрессии обычно оцениваются с использованием оценки максимального правдоподобия. В отличие от линейной регрессии с нормально распределенными остатками, невозможно найти выражение в замкнутой форме для значений коэффициентов, которые максимизируют функцию правдоподобия, поэтому вместо этого следует использовать итерационный процесс; например метод Ньютона. Этот процесс начинается с предварительного решения, его немного изменяют, чтобы посмотреть, можно ли его улучшить, и повторяют это изменение до тех пор, пока улучшения не прекратятся, после чего процесс считается сходимым.
В некоторых случаях, модель может не достичь сходимости. Несходимость модели указывает на то, что коэффициенты не имеют смысла, поскольку итерационный процесс не смог найти подходящие решения. Неспособность сойтись может произойти по ряду причин: наличие большого отношения предикторов к случаям, мультиколлинеарность, разреженность или полное разделение.
В приложениях машинного обучения, где логистические регрессия используется для двоичной классификации, MLE минимизирует функцию потерь перекрестной энтропии .
Двоичная логистическая регрессия (

![{\displaystyle \mathbf {w} ^{T}=[\beta _{0},\beta _{1},\beta _{2},\ldots ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/daccbf84c2c936e0559016491efe98eaf0eca430)
![{\displaystyle \mathbf {x} (i)=[1,x_{1}(i),x_{2}(i),\ldots ]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c8fc5f11bdd42f672417a3f4e44b3a4e5be28faa)



где 
![{\displaystyle {\boldsymbol {\mu }}=[\mu (1),\mu (2),\ldots ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/800927e9be36f4cac166a68862c04234cffd67b8)

Матрица регрессора и ![{\displaystyle \mathbf {y} (i)=[y(1),y(2),\ldots ]^{T}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/33cbd315328b6ccfc7f216d65e39f92a8ec48694)
Качество соответствия в моделях линейной регрессии обычно измеряется с использованием R. Поскольку у этого нет прямого аналога в логистической регрессии, вместо него можно использовать различные методы, включая следующие.
В линейном регрессионном анализе рассматривается разделение дисперсии с помощью вычислений суммы квадратов - дисперсия критерия по существу делится на дисперсию учитывается предикторами и остаточной дисперсией. В анализе логистической регрессии отклонение используется вместо вычисления суммы квадратов. Отклонение аналогично вычислению суммы квадратов в линейной регрессии и является мерой отсутствия соответствия данным в модели логистической регрессии. Когда доступна «насыщенная» модель (модель с теоретически идеальным соответствием), отклонение рассчитывается путем сравнения данной модели с насыщенной моделью. Это вычисление дает критерий отношения правдоподобия :

В приведенном выше уравнении D представляет отклонение и ln представляет собой натуральный логарифм. Логарифм этого отношения правдоподобия (отношение подобранной модели к насыщенной модели) даст отрицательное значение, следовательно, потребуется отрицательный знак. Можно показать, что D соответствует приблизительному распределению хи-квадрат. Меньшие значения указывают на лучшее соответствие, поскольку подобранная модель меньше отклоняется от насыщенной модели. При оценке по распределению хи-квадрат незначительные значения хи-квадрат указывают на очень небольшую необъяснимую дисперсию и, следовательно, хорошее соответствие модели. И наоборот, значительное значение хи-квадрат указывает на то, что значительная величина дисперсии необъяснима.
Когда насыщенная модель недоступна (общий случай), отклонение вычисляется просто как −2 · (логарифмическая вероятность подобранной модели), и ссылка на логарифмическую вероятность насыщенной модели может быть удалена из всех это следует без вреда.
Два показателя отклонения особенно важны в логистической регрессии: нулевое отклонение и отклонение модели. Нулевое отклонение представляет собой разницу между моделью только с точкой пересечения (что означает «без предикторов») и насыщенной моделью. Отклонение модели представляет собой разницу между моделью с хотя бы одним предиктором и насыщенной моделью. В этом отношении нулевая модель обеспечивает основу для сравнения моделей предикторов. Учитывая, что отклонение является мерой разницы между данной моделью и насыщенной моделью, меньшие значения указывают на лучшее соответствие. Таким образом, чтобы оценить вклад предиктора или набора предикторов, можно вычесть отклонение модели из нулевого отклонения и оценить разницу по a 
Пусть
![{\displaystyle {\begin{aligned}D_{\text{null}}=-2\ln {\frac {\text{likelihood of null model}}{\text{likelihood of the saturated model}}}\\[6pt]D_{\text{fitt ed}}=-2\ln {\frac {\text{likelihood of fitted model}}{\text{likelihood of the saturated model}}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d85ab8f60a3e7685815b132b3a80d03d26d9745a)
Тогда разница обоих составляет:
![{\ displaystyle {\ begin {align} D _ {\ text {null}} - D _ {\ text {fit}} = - 2 \ left (\ ln {\ frac {\ text {вероятность нулевая модель}} {\ text {вероятность насыщенной модели}}} - \ ln {\ frac {\ text {вероятность подобранной модели}} {\ text {вероятность появления s насыщенная модель}}} \ right) \\ [6pt] = - 2 \ ln {\ frac {\ left ({\ dfrac {\ text {вероятность нулевой модели}} {\ text {вероятность насыщенной модели}} } \ right)} {\ left ({\ dfrac {\ text {вероятность подобранной модели}} {\ text {вероятность насыщенной модели}}} \ right)}} \\ [6pt] = - 2 \ ln {\ frac {\ text {вероятность нулевой модели}} {\ text {вероятность соответствия модели}}}. \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bd851b7e234a5483dbb21da9fff7d9d2419e3e3e)
Если отклонение модели значительно меньше нулевого отклонения, то можно сделать вывод, что предиктор или набор предикторов значительно улучшили соответствие модели. Это аналогично F-критерию, используемому в анализе линейной регрессии для оценки значимости прогноза.
В линейной регрессии для оценки используется множественная корреляция в квадрате. степень согласия, поскольку она представляет собой долю дисперсии критерия, которая объясняется предикторами. В логистическом регрессионном анализе нет согласованной аналогичной меры, но есть несколько конкурирующих мер, каждая из которых имеет ограничения.
На этой странице рассматриваются четыре наиболее часто используемых индекса и один менее часто используемый:
R²Lопределяется Коэном:

Это наиболее аналогичный показатель квадрату множественных корреляций в линейной регрессии. Он представляет собой пропорциональное уменьшение отклонения, при котором отклонение рассматривается как мера отклонения, аналогичная, но не идентичная дисперсии в анализе линейной регрессии. Одним из ограничений отношения правдоподобия R² является то, что оно не связано монотонно с отношением шансов, а это означает, что оно не обязательно увеличивается по мере увеличения отношения шансов и не обязательно уменьшается по мере уменьшения отношения шансов.
R²CS- альтернативный индекс качества соответствия, связанный со значением R² из линейной регрессии. Он задается следующим образом:
![{\displaystyle {\begin{aligned}R_{\text{CS}}^{2}=1-\left({\frac {L_{0}}{L_{M}}}\right)^{2/n}\\[5pt]=1-e^{2(\ln(L_{0})-\ln(L_{M}))/n}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8d7fd894a2491abc493151c9aecafec2bb3cd9b8)
где L M и {{mvar | L 0 } - вероятности для подгоняемой модели и нулевой модели соответственно. Индекс Кокса и Снелла проблематичен, поскольку его максимальное значение составляет 
R²Nобеспечивает корректировку R² Кокса и Снеллиуса, так что максимальное значение равно 1. Тем не менее, коэффициенты Кокса и Снелла и отношение правдоподобия R²s показывают большее соответствие друг с другом, чем любой из них с коэффициентом Нагелькерке R2. Конечно, это может быть не так для значений, превышающих 0,75, поскольку индекс Кокса и Снелла ограничен этим значением. Отношение правдоподобия R² часто предпочтительнее альтернатив, поскольку оно наиболее аналогично R² в линейной регрессии, не зависит от базовой ставки (R² Кокса и Снелла и Нагелькерке увеличиваются по мере увеличения доли случаев от 0 до 0,5) и варьируется от 0 до 1.
R²McF определяется как

и предпочтительнее R² CS пользователя Allison. Тогда два выражения R² McF и R² CS связаны соответственно соотношением
![{\displaystyle {\begin{matrix}R_{\text{CS}}^{2}=1-\left({\dfrac {1}{L_{0}}}\right)^{\frac {2(R_{\text{McF}}^{2})}{n}}\\[1.5em]R_{\text{McF}}^{2}=-{\dfrac {n}{2}}\cdot {\dfrac {\ln(1-R_{\text{CS}}^{2})}{\ln L_{0}}}\end{matrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0f5537e92777913de25ddaa5b8909c8e7f008ccf)
Однако сейчас Эллисон предпочитает R² T, который является относительно новым показателем, разработанным Tjur. Его можно рассчитать в два этапа:
A слово предостережения при интерпретации статистики псевдо-R². Причина, по которой эти индексы соответствия называются псевдо-R², заключается в том, что они не представляют пропорционального уменьшения ошибки, как это делает R² в линейной регрессии. Линейная регрессия предполагает гомоскедастичность, что дисперсия ошибки одинакова для всех значений критерия. Логистическая регрессия всегда будет гетероскедастической - дисперсии ошибок различаются для каждого значения прогнозируемой оценки. Для каждого значения прогнозируемой оценки будет свое значение пропорционального уменьшения ошибки. Следовательно, неуместно думать о R² как о пропорциональном сокращении ошибки в универсальном смысле логистической регрессии.
Тест Хосмера – Лемешоу использует статистику теста, которая асимптотически следует 
После подбора модели исследователи, вероятно, захотят изучить вклад отдельных предикторов. Для этого они захотят изучить коэффициенты регрессии. В линейной регрессии коэффициенты регрессии представляют изменение критерия для каждого изменения единицы в предикторе. Однако в логистической регрессии коэффициенты регрессии представляют изменение логита для каждого изменения единицы в предикторе. Учитывая, что логит не является интуитивно понятным, исследователи, вероятно, сосредоточатся на влиянии предсказателя на экспоненциальную функцию коэффициента регрессии - отношения шансов (см. определение ). В линейной регрессии значимость коэффициента регрессии оценивается путем вычисления t-критерия. В логистической регрессии существует несколько различных тестов, предназначенных для оценки значимости отдельного предиктора, в первую очередь тест отношения правдоподобия и статистика Вальда.
Рассмотренный выше тест отношения правдоподобия для оценки соответствия модели также является рекомендуемой процедурой для оценки вклада отдельных «предикторов» в данную модель.. В случае модели с одним предиктором, просто сравнивают отклонение модели предиктора с отклонением от нулевой модели на распределении хи-квадрат с одной степенью свободы. Если модель предиктора имеет значительно меньшее отклонение (c.f хи-квадрат с использованием разницы в степенях свободы двух моделей), то можно сделать вывод, что существует значимая связь между "предиктором" и результатом. Хотя некоторые общие статистические пакеты (например, SPSS) действительно предоставляют статистику теста отношения правдоподобия, без этого требовательного к вычислениям теста было бы труднее оценить вклад отдельных предикторов в случае множественной логистической регрессии. Чтобы оценить вклад отдельных предикторов, можно ввести предикторы иерархически, сравнивая каждую новую модель с предыдущей, чтобы определить вклад каждого предиктора. Статистики спорят о целесообразности так называемых «пошаговых» процедур. Есть опасения, что они могут не сохранить номинальные статистические свойства и могут ввести в заблуждение.
В качестве альтернативы, при оценке вклада отдельных предикторов в данную модель, можно исследовать значимость статистика Вальда. Статистика Вальда, аналогичная t-критерию линейной регрессии, используется для оценки значимости коэффициентов. Статистика Вальда представляет собой отношение квадрата коэффициента регрессии к квадрату стандартной ошибки коэффициента и асимптотически распределяется как распределение хи-квадрат.

Хотя несколько статистических пакетов (например, SPSS, SAS) сообщают статистику Вальда для оценки вклада отдельных предикторов, статистика Вальда имеет ограничения. Когда коэффициент регрессии велик, стандартная ошибка коэффициента регрессии также имеет тенденцию быть больше, увеличивая вероятность ошибки типа II. Статистика Вальда также имеет тенденцию к смещению, когда данные скудны.
Предположим, случаи редки. Тогда мы могли бы пожелать отбирать их чаще, чем их распространенность в популяции. Например, предположим, что есть заболевание, которым страдает 1 человек из 10 000, и для сбора данных нам необходимо пройти полное обследование. Проведение тысяч медицинских осмотров здоровых людей для получения данных только по нескольким больным может оказаться слишком дорогостоящим. Таким образом, мы можем оценить большее количество больных, возможно, все редкие исходы. Это также ретроспективная выборка, или, что то же самое, ее называют несбалансированными данными. Как показывает практический опыт, выборка контролей с частотой, в пять раз превышающей количество наблюдений, даст достаточные контрольные данные.
Логистическая регрессия уникальна тем, что ее можно оценивать на несбалансированных данных, а не на случайно выбранных данных, и по-прежнему дают правильные оценки коэффициентов влияния каждой независимой переменной на результат. То есть, если мы сформируем логистическую модель из таких данных, если модель верна для генеральной совокупности, все параметры

где 

Существуют различные эквивалентные спецификации логистической регрессии, которые вписываются в разные типы более общих моделей. Эти разные спецификации позволяют делать разные полезные обобщения.
Базовая настройка логистической регрессии выглядит следующим образом. Нам дан набор данных, содержащий N точек. Каждая точка i состоит из набора из m входных переменных x 1, i... x m, i (также называемых независимых переменных, переменных-предикторов, функций, или атрибуты) и двоичной выходной переменной Y i (также известной как зависимая переменная, переменная ответа, выходная переменная или класс), т.е. может принимать только два возможных значения: 0 (часто означает «нет» или «неудача») или 1 (часто означает «да» или «успех»). Целью логистической регрессии является использование набора данных для создания модели прогнозирования переменной результата.
Некоторые примеры:
Как и в линейной регрессии, предполагается, что переменные результата Y i зависят от независимых переменных x 1, i... x m, i.
Как показано выше в приведенных выше примерах, поясняющие переменные могут быть любого типа : вещественные, двоичные, категориальные и т. Д. Основное различие между непрерывными переменными (такими как доход, возраст и кровяное давление ) и дискретные переменные (например, пол или раса). Дискретные переменные, относящиеся к более чем двум возможным вариантам выбора, обычно кодируются с использованием фиктивных переменных (или индикаторных переменных ), то есть отдельные независимые переменные, принимающие значение 0 или 1, создаются для каждого возможного значение дискретной переменной, где 1 означает «переменная имеет данное значение», а 0 означает «переменная не имеет этого значения».
Например, четырехсторонняя дискретная переменная группы крови с возможными значениями «A, B, AB, O» может быть преобразована в четыре отдельные двусторонние фиктивные переменные, » is-A, is-B, is-AB, is-O ", где только один из них имеет значение 1, а все остальные имеют значение 0. Это позволяет сопоставить отдельные коэффициенты регрессии для каждого возможного значения дискретная переменная. (В таком случае только три из четырех фиктивных переменных независимы друг от друга в том смысле, что, как только значения трех переменных известны, четвертая определяется автоматически. Таким образом, необходимо кодировать только три из четырех возможностей в качестве фиктивных переменных. Это также означает, что когда все четыре возможности закодированы, общая модель не может быть идентифицируемой при отсутствии дополнительных ограничений, таких как ограничение регуляризации. Теоретически это может вызвать проблемы, но в действительности почти все модели логистической регрессии снабжены ограничениями регуляризации.)
Формально результаты Y i описываются как данные с распределением Бернулли, где каждый результат определяется ненаблюдаемой вероятностью p i, которая специфична для данного результата, но связана с независимыми переменными. Это может быть выражено в любой из следующих эквивалентных форм:
![{\ displaystyle {\ begin {align} Y_ {i} \ mid x_ {1, i}, \ ldots, x_ {m, i} \ \ sim \ operatorname {Bernoulli} (p_ {i}) \\\ operatorname {\ mathcal {E}} [Y_ {i} \ mid x_ {1, i}, \ ldots, x_ {m, i}] = p_ {i} \\\ Pr (Y_ {i} = y \ mid x_ {1, i}, \ ldots, x_ {m, i}) = {\ begin {cases} p_ {i} {\ text {if}} y = 1 \\ 1-p_ {i} {\ text {if}} y = 0 \ end {case}} \\\ Pr (Y_ {i} = y \ mid x_ {1, i}, \ ldots, x_ {m, i}) = p_ {i} ^ {y} (1-p_ {i}) ^ {(1-y)} \ end {выровнено }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/60a58e896d8e9edcbf146709ae5be055e2a1a838)
Значения этих четыре строки:
Основная идея логистической регрессии заключается в использовании механизм, уже разработанный для линейной регрессии путем моделирования вероятности p i с использованием функции линейного предиктора, то есть линейной комбинации пояснительной переменные и набор коэффициентов регрессии, которые относятся к рассматриваемой модели, но одинаковы для всех испытаний. Функция линейного предиктора 

где 
Модель обычно принимают в более компактном виде:
Это позволяет записать функцию линейного предиктора следующим образом:

используя обозначение для скалярное произведение между двумя векторами.
Конкретная модель, используемая логистической регрессией, которая отличает ее от стандартной линейной регрессии и от других типов регрессионного анализа, используемый для результатов с двоичным значением, - это способ связи вероятности конкретного результата с функцией линейного предиктора:
![{\displaystyle \operatorname {logit} (\operatorname {\mathcal {E}} [Y_{i}\mid x_{1,i},\ldots,x_{m,i}])=\operatorname {logit} (p_{i})=\ln \left({\frac {p_{i}}{1-p_{i}}}\right)=\beta _{0}+\beta _{1}x_{1,i}+\cdots +\beta _{m}x_{m,i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2389d119a0c95c1f52b98396ac9762de04067bdd)
Написано с использованием более компактной записи, описанной выше, это:
![{\displaystyle \operatorname {logit} (\operatorname {\mathcal {E}} [Y_{i}\mid \mathbf {X} _{i}])=\operatorname {logit} (p_{i})=\ln \left({\frac {p_{i}}{1-p_{i}}}\right)={\boldsymbol {\beta }}\cdot \mathbf {X} _{i}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/66290b1bc5ddfd2fc7fc2971372a79ba65e28f89)
Эта формулировка выражает логистическую регрессию как тип обобщенной линейной модели, которая прогнозирует переменные с различными типами распределений вероятностей путем подгонки линейной функции-предиктора вышеуказанной формы к некоторому виду произвольное преобразование ожидаемого значения переменной.
Интуиция для преобразования с использованием функции логита (натуральный логарифм шансов) была объяснена выше. Он также имеет практический эффект преобразования вероятности (которая ограничена от 0 до 1) в переменную, которая находится в диапазоне 
Обратите внимание, что и вероятности p i, и коэффициенты регрессии не наблюдаются, и средства их определения не являются частью самой модели. Обычно они определяются какой-либо процедурой оптимизации, например оценка максимального правдоподобия, которая находит значения, которые наилучшим образом соответствуют наблюдаемым данным (т. Е. Дают наиболее точные прогнозы для уже наблюдаемых данных), обычно при условии регуляризации условий, которые стремятся исключить маловероятные значения, например чрезвычайно большие значения для любого из коэффициентов регрессии. Использование условия регуляризации эквивалентно выполнению максимальной апостериорной (MAP) оценки, расширению максимальной вероятности. (Регуляризация чаще всего выполняется с использованием регуляризующей функции в квадрате, что эквивалентно помещению гауссовского априорного распределения с нулевым средним для коэффициентов, но другие регуляризаторы также возможно.) Независимо от того, используется ли регуляризация, обычно невозможно найти решение в закрытой форме; вместо этого должен использоваться итеративный численный метод, такой как итеративно перевывешенный метод наименьших квадратов (IRLS) или, что чаще в наши дни, квазиньютоновский метод, такой как L -BFGS метод.
Интерпретация оценок параметра β j заключается в аддитивном влиянии на логарифм шансов для изменения единицы в независимой переменной j. В случае дихотомической объясняющей переменной, например, пол 
Эквивалентная формула использует обратную логит-функцию, которая является логистической функцией, то есть:
![{\displaystyle \operatorname {\mathcal {E}} [Y_{i}\mid \mathbf {X} _{i}]=p_{i}=\operatorname {logit} ^{-1}({\boldsymbol {\beta }}\cdot \mathbf {X} _{i})={\frac {1}{1+e^{-{\boldsymbol {\beta }}\cdot \mathbf {X} _{i}}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/74c2849bc48454b0a177375d2c69c557ffd2836d)
Формулу также можно записать как распределение вероятностей (в частности, используя функцию массы вероятности ):

Вышеуказанное модель имеет эквивалентную формулировку как модель со скрытыми переменными. Эта формулировка является общей в теории моделей дискретного выбора и упрощает распространение на некоторые более сложные модели с множественными коррелированными вариантами выбора, а также сравнение логистической регрессии с тесно связанной пробит-моделью ..
Представьте себе, что для каждого испытания i существует непрерывная скрытая переменная Yi(т.е. ненаблюдаемая случайная величина ), которая распределяется следующим образом:

где

т.е. скрытая переменная может быть записана непосредственно в терминах функции линейного предсказания и аддитивной случайной переменной ошибки, которая распределяется в соответствии со стандартным логистическим распределением.
Тогда Y i можно рассматривать как индикатор того, является ли эта скрытая переменная положительной:

Выбор моделирования конкретной переменной ошибки y со стандартным логистическим распределением, а не с общим логистическим распределением с произвольными значениями местоположения и масштаба, кажется ограничивающим, но на самом деле это не так. Следует иметь в виду, что мы можем сами выбирать коэффициенты регрессии и очень часто можем использовать их для компенсации изменений параметров распределения переменной ошибки. Например, распределение переменных логистической ошибки с ненулевым параметром местоположения μ (который устанавливает среднее значение) эквивалентно распределению с нулевым параметром местоположения, где μ добавлен к коэффициенту пересечения. Обе ситуации дают одно и то же значение для Y i независимо от настроек независимых переменных. Точно так же произвольный параметр масштабирования s эквивалентен установке параметра масштабирования на 1 и последующему делению всех коэффициентов регрессии на s. В последнем случае результирующее значение Y i будет в s раз меньше, чем в первом случае, для всех наборов независимых переменных, но, что важно, оно всегда будет оставаться на той же стороне 0, и, следовательно, приводят к тому же выбору Y i.
(Обратите внимание, что это предсказывает, что несоответствие параметра масштаба не может быть перенесено в более сложные модели, где доступно более двух вариантов.)
Оказывается, эта формулировка в точности эквивалентна к предыдущей, сформулированной в терминах обобщенной линейной модели и без каких-либо скрытых переменных. Это можно показать следующим образом, используя тот факт, что кумулятивная функция распределения (CDF) стандартного логистического распределения является логистической функцией , которая является обратной логит-функции , т.е.
Тогда:
![{\displaystyle {\begin{aligned}\Pr(Y_{i}=1\mid \mathbf {X} _{i})=\Pr(Y_{i}^{\ast }>0 \ mid \ mathbf {X} _ {i}) \\ [5pt] = \ Pr ({\ boldsymbol {\ beta}} \ cdot \ mathbf {X} _ {i} + \ varepsilon>0) \\ [5pt] = \ Pr (\ varepsilon>- {\ boldsymbol {\ beta}} \ cdot \ mathbf { X} _ {i}) \\ [5pt] = \ Pr (\ varepsilon <{\boldsymbol {\beta }}\cdot \mathbf {X} _{i}){\text{(because the logistic distribution is symmetric)}}\\[5pt]=\operatorname {logit} ^{-1}({\boldsymbol {\beta }}\cdot \mathbf {X} _{i})\\[5pt]=p_{i}{\text{(see above)}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d9f767289fb1baf367d01371bafd39857ac05c3)
Эта формулировка - стандартная для моделей дискретного выбора - проясняет взаимосвязь между логистической регрессией («логит модель ") и пробит-модель, в которой используется переменная ошибки, распределенная в соответствии с переход к стандартному нормальному распределению вместо стандартного логистического распределения. Как логистическое, так и нормальное распределения симметричны базовой унимодальной форме «колоколообразной кривой». Единственное отличие состоит в том, что логистическое распределение имеет несколько более тяжелые хвосты, что означает, что оно менее чувствительно к внешним данным (и, следовательно, несколько более надежно для моделирования неверных спецификаций или ошибочных данных)..
Еще одна формулировка использует две отдельные скрытые переменные:

где

где EV 1 (0,1) - стандартный тип 1 распределение экстремальных значений : т.е.

Тогда

Эта модель имеет отдельную скрытую переменную и отдельную набор коэффициентов регрессии для каждого возможного результата зависимой переменной. Причина этого разделения заключается в том, что оно позволяет легко расширить логистическую регрессию на многозначные категориальные переменные, как в модели полиномиального логита. модели, естественно моделировать каждый возможный результат, используя другой набор коэффициентов регрессии. Также возможно мотивировать каждую из отдельных скрытых переменных как теоретическую полезность, связанную с выполнением соответствующего выбора, и, таким образом, мотивировать логистическую регрессию с точки зрения теории полезности (с точки зрения полезности t Согласно теории, рациональный субъект всегда выбирает выбор с наибольшей связанной полезностью.) Это подход, используемый экономистами при формулировании моделей дискретного выбора, поскольку он обеспечивает теоретически прочную основу и облегчает интуитивное понимание модели, что, в свою очередь, упрощает рассмотрение различных видов расширений. (См. Пример ниже.)
Выбор распределения экстремальных значений типа 1 кажется довольно произвольным, но он заставляет математику работать, и может быть возможно оправдать его использование через теория рационального выбора.
Оказывается, что эта модель эквивалентна предыдущей модели, хотя это кажется неочевидным, поскольку теперь существует два набора коэффициентов регрессии и переменных ошибок, а переменные ошибок имеют разные распространение. Фактически, эта модель сводится непосредственно к предыдущей со следующими заменами:


Интуиция для это происходит из-за того, что, поскольку мы выбираем на основе максимального из двух значений, имеет значение только их разница, а не точные значения - и это эффективно удаляет одну степень свободы. Другой важный факт заключается в том, что разница двух переменных типа 1 с распределением экстремальных значений является логистическим распределением, то есть 
![{\displaystyle {\begin{aligned}\Pr(Y_{i}=1\mid \mathbf {X} _{i})={}\Pr \left(Y_{i}^{1\ast }>Y_ {i} ^ {0 \ ast} \ mid \ mathbf {X} _ {i} \ right) \\ [5pt] = {} \ Pr \ left (Y_ {i} ^ {1 \ ast} -Y_ {i} ^ {0 \ ast}>0 \ mid \ mathbf {X} _ {i} \ right) \\ [5pt] = {} \ Pr \ left ({\ boldsymbol {\ beta}} _ {1} \ cdot \ mathbf {X} _ {i} + \ varepsilon _ {1} - \ left ({\ boldsymbol {\ beta}} _ {0} \ cdot \ mathbf {X} _ {i} + \ varepsilon _ {0 } \ right)>0 \ right) \\ [5pt] = {} \ Pr \ left (({\ boldsymbol {\ beta}} _ {1} \ cdot \ mathbf {X} _ {i} - { \ boldsymbol {\ быть ta}} _ {0} \ cdot \ mathbf {X} _ {i}) + (\ varepsilon _ {1} - \ varepsilon _ {0})>0 \ right) \\ [5pt] = {} \ Pr (({\ boldsymbol {\ beta}} _ {1} - {\ boldsymbol {\ beta}} _ {0}) \ cdot \ mathbf {X} _ {i} + (\ varepsilon _ {1} - \ varepsilon _ {0})>0) \\ [5pt] = {} \ Pr (({\ boldsymbol {\ beta}} _ {1} - {\ boldsymbol {\ beta}} _ {0}) \ cdot \ mathbf {X} _ {i} + \ varepsilon>0) {\ text {(replace}} \ varepsilon {\ text {как указано выше)}} \\ [5pt] = {} \ Pr ({ \ boldsymbol {\ beta}} \ cdot \ mathbf {X} _ {i} + \ varepsilon>0) {\ text {(replace}} {\ boldsymbol {\ beta}} {\ text {как указано выше)}} \\ [5pt] = {} \ Pr (\ varepsilon>- {\ boldsymbol {\ beta}} \ cdot \ mathbf {X} _ {i}) {\ text {(теперь такая же, как в модели выше)} } \\ [5pt] = {} \ Pr (\ varepsilon <{\boldsymbol {\beta }}\cdot \mathbf {X} _{i})\\[5pt]={}\operatorname {logit} ^{-1}({\boldsymbol {\beta }}\cdot \mathbf {X} _{i})\\[5pt]={}p_{i}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be3b57ca6773ef745cdfd82367611e9394215f9e)
В качестве примера рассмотрим выборы на уровне провинции, где выбор делается между правоцентристской партией и левой центристская партия и сепаратистская партия (например, Parti Québécois, которая хочет, чтобы Квебек отделился от Канады ). Затем мы использовали бы три скрытые переменные, по одной для каждого выбора. Затем, в соответствии с теорией полезности, мы можем интерпретировать скрытые переменные как выражающие полезность, которая возникает в результате принятия каждого из вариантов выбора. Мы также можем интерпретировать коэффициенты регрессии как показывающие силу, которую связанный фактор (т. Е. Объясняющая переменная) имеет в содействии полезности, или, точнее, количество, на которое изменение единицы в объясняющей переменной изменяет полезность данного выбора. Избиратель может ожидать, что правоцентристская партия снизит налоги, особенно для богатых. Это не дало бы людям с низким доходом никакой выгоды, то есть никаких изменений в полезности (поскольку они обычно не платят налоги); принесет умеренную выгоду (то есть несколько больше денег или умеренное повышение полезности) для людей среднего уровня; принесет значительные выгоды людям с высокими доходами. С другой стороны, можно ожидать, что левоцентристская партия повысит налоги и компенсирует их повышением благосостояния и другой помощью для нижних и средних классов. Это принесет значительную положительную пользу людям с низким доходом, возможно, слабую пользу людям со средним доходом и значительную отрицательную пользу людям с высокими доходами. Наконец, сепаратистская партия не будет предпринимать никаких прямых действий в отношении экономики, а просто отделится. Избиратель с низким или средним доходом может в основном не ожидать от этого явной выгоды или убытка от полезности, но избиратель с высоким доходом может ожидать отрицательной полезности, поскольку он / она, вероятно, будет владеть компаниями, которым будет труднее вести бизнес. такая среда и, вероятно, потеряете деньги.
Эти интуиции можно выразить следующим образом:
| Центр-справа | В центре-слева | Сецессионист | |
|---|---|---|---|
| Высокий доход | сильный + | сильный - | сильный - |
| средний доход | умеренный + | слабый + | нет |
| малообеспеченный | нет | сильный + | нет |
Это ясно показывает что
Еще одна формулировка объединяет описанную выше формулировку двусторонних латентных переменных с исходной формулировкой выше без латентных переменных и в процессе обеспечивает ссылку на одну из стандартных формулировок полиномиального логита.
Здесь, вместо записи logit вероятностей p i в качестве линейного предиктора мы разделяем линейный предиктор на два, по одному для каждого из двух результатов:

Обратите внимание, что были введены два отдельных набора коэффициентов регрессии, просто как в модели с двусторонней скрытой переменной, и два уравнения представляют собой форму, которая записывает логарифм связанной вероятности в качестве линейного предиктора с дополнительным членом 
![{\displaystyle {\begin{aligned}\Pr(Y_{i}=0)={\frac {1}{Z}}e^{{\boldsymbol {\beta }}_{0}\cdot \mathbf {X} _{i}}\\[5pt]\Pr(Y_{i}=1)={\frac {1}{Z}}e^{{\boldsymbol {\beta }}_{1}\cdot \mathbf {X} _{i}}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6e1e2a04fd15f2e5617c0606a7644fe719823960)
В этой форме ясно, что цель Z - гарантировать, что результирующее распределение по Y i действительно будет распределение вероятностей, т. е. сумма равна 1. Это означает, что Z - это просто сумма всех ненормированных вероятностей, и при делении каждой вероятности на Z вероятности становятся «нормализованными ». То есть:

, и в результате получаются уравнения
![{\ displaystyle {\ begin {align} \ Pr (Y_ { i} = 0) = {\ frac {e ^ {{\ boldsymbol {\ beta}} _ {0} \ cdot \ mathbf {X} _ {i}}} {e ^ {{\ boldsymbol {\ beta} } _ {0} \ cdot \ mathbf {X} _ {i}} + e ^ {{\ boldsymbol {\ beta}} _ {1} \ cdot \ mathbf {X} _ {i}}}} \\ [ 5pt] \ Pr (Y_ {i} = 1) = {\ frac {e ^ {{\ boldsymbol {\ beta}} _ {1} \ cdot \ mathbf {X} _ {i}}} {e ^ { {\ boldsymbol {\ beta}} _ {0} \ cdot \ mathbf {X} _ {i}} + e ^ {{\ boldsymbol {\ beta}} _ {1} \ cdot \ mathbf {X} _ {i }}}}. \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1fa489d73be139142872ddccccecd567635525d5)
Или обычно:

Это ясно показывает, как обобщить эту формулировку к более чем двум исходам, как в полиномиальный логит. Обратите внимание, что эта общая формулировка является в точности функцией softmax, как в

Чтобы доказать, что это эквивалентно предыдущей модели, обратите внимание, что указанная выше модель является завышенной, в что 


![{\displaystyle {\begin{aligned}\Pr(Y_{i}=1)={\frac {e^{({\boldsymbol {\beta }}_{1}+\mathbf {C})\cdot \mathbf {X} _{i}}}{e^{({\boldsymbol {\beta }}_{0}+\mathbf {C})\cdot \mathbf {X} _{i}}+e^{({\boldsymbol {\beta }}_{1}+\mathbf {C})\cdot \mathbf {X} _{i}}}}\\[5pt]={\frac {e^{{\boldsymbol {\beta }}_{1}\cdot \mathbf {X} _{i}}e^{\mathbf {C} \cdot \mathbf {X} _{i}}}{e^{{\boldsymbol {\beta }}_{0}\cdot \mathbf {X} _{i}}e^{\mathbf {C} \cdot \mathbf {X} _{i}}+e^{{\boldsymbol {\beta }}_{1}\cdot \mathbf {X} _{i}}e^{\mathbf {C} \cdot \mathbf {X} _{i}}}}\\[5pt]={\frac {e^{\mathbf {C} \cdot \mathbf {X} _{i}}e^{{\boldsymbol {\beta }}_{1}\cdot \mathbf {X} _{i}}}{e^{\mathbf {C} \cdot \mathbf {X} _{i}}(e^{{\boldsymbol {\beta }}_{0}\cdot \mathbf {X} _{i}}+e^{{\boldsymbol {\beta }}_{1}\cdot \mathbf {X} _{i}})}}\\[5pt]={\frac {e^{{\boldsymbol {\beta }}_{1}\cdot \mathbf {X} _{i}}}{e^{{\boldsymbol {\beta }}_{0}\cdot \mathbf {X} _{i}}+e^{{\boldsymbol {\beta }}_{1}\cdot \mathbf {X} _{i}}}}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4f545a36890435f35e006242acda552c8f62dcd0)
В результате мы можем упростить дело и восстановить идентифицируемость, выбрав произвольное значение для одного из двух векторов. Мы решили установить 

и поэтому

, что показывает, что эта формулировка действительно эквивалентна предыдущей формулировке. (Как и в формулировке двусторонней скрытой переменной, любые настройки, где
Обратите внимание, что большинство методов лечения модели полиномиального логита начинается либо с расширения «лог-линейная» формулировка, представленная здесь, или формулировка двусторонней скрытой переменной, представленная выше, поскольку обе ясно показывают способ, которым модель может быть расширена для многосторонних результатов. В целом представление со скрытыми переменными более распространено в эконометрике и политологии, где господствуют модели дискретного выбора и теория полезности, в то время как "лог-линейная" формулировка здесь более распространена в информатике, например машинное обучение и обработка естественного языка.
Модель имеет эквивалентную формулировку

Эту функциональную форму обычно называют однослойной перцептроном или однослойной искусственной нейронной сетью. Однослойная нейронная сеть вычисляет непрерывный результат вместо пошаговой функции . Производная p i по X = (x 1,..., x k) вычисляется из общей формы:

где f (X) - аналитический функция в X. При таком выборе однослойная нейронная сеть идентична модели логистической регрессии. Эта функция имеет непрерывную производную, что позволяет использовать ее в обратном распространении. Эта функция также является предпочтительной, потому что ее производная легко вычисляется:

Тесно связанная модель предполагает, что каждое i связано не с одним испытанием Бернулли, а с n iнезависимыми одинаково распределенными испытаниями, где наблюдение Y i - это количество наблюдаемых успехов (сумма отдельных случайных величин, распределенных по Бернулли), и, следовательно, следует биномиальному распределению :

Примером этого распределения является доля семян (p i), которые прорастают после посадки n i.
В терминах ожидаемых значений эта модель выражается следующим образом:
![{\displaystyle p_{i}=\operatorname {\mathcal {E}} \left[\left.{\frac {Y_{i}}{n_{i}}}\,\right|\,\mathbf {X} _{i}\right]\,,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0123cbc81b998479d4519f00a89ba3d5ba1bfcc5)
, так что
![{\displaystyle \operatorname {logit} \left(\operatorname {\mathcal {E}} \left[\left.{\frac {Y_{i}}{n_{i}}}\,\right|\,\mathbf {X} _{i}\right]\right)=\operatorname {logit} (p_{i})=\ln \left({\frac {p_{i}}{1-p_{i}}}\right)={\boldsymbol {\beta }}\cdot \mathbf {X} _{i}\,,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bdb8db87748853ad7609116b81d41ab7ecaad708)
Или, что эквивалентно:

Эта модель может быть адаптирована с использованием тех же методов, что и описанная выше более базовая модель.
 Сравнение логистической функции с масштабированной обратной пробит-функцией (т.е. CDF нормального распределения ), сравнивая
Сравнение логистической функции с масштабированной обратной пробит-функцией (т.е. CDF нормального распределения ), сравнивая  vs.
vs.  , что делает уклоны одинаковыми в начале координат. Это показывает более тяжелые хвосты логистического распределения.
, что делает уклоны одинаковыми в начале координат. Это показывает более тяжелые хвосты логистического распределения. В контексте байесовской статистики предшествующие распределения обычно помещаются в коэффициенты регрессии, обычно в форма гауссовых распределений. В логистической регрессии не существует сопряженного предшествующего функции правдоподобия . Когда байесовский вывод был выполнен аналитически, это затрудняло вычисление апостериорного распределения, за исключением очень малых измерений. Однако теперь автоматическое программное обеспечение, такое как OpenBUGS, JAGS, PyMC3 или Stan, позволяет вычислять эти апостериорные компоненты с помощью моделирования, поэтому о супружестве не вызывает беспокойства. Однако, когда размер выборки или количество параметров велико, полное байесовское моделирование может быть медленным, и люди часто используют приближенные методы, такие как вариационные байесовские методы и распространение математических ожиданий.
Подробная история логистической регрессии приведена в Cramer (2002). Логистическая функция была разработана как модель роста населения и названа «логистической» Пьером Франсуа Ферхюльстом в 1830-х и 1840-х годах под руководством Адольфа Кетле ; подробнее см. Логистическая функция § История. В своей самой ранней статье (1838 г.) Ферхюльст не уточнил, как он подгоняет кривые к данным. В своей более подробной статье (1845) Ферхюльст определил три параметра модели, заставив кривую проходить через три наблюдаемые точки, что дало плохие прогнозы.
Логистическая функция была независимо разработана в химии как модель автокатализ (Вильгельм Оствальд, 1883). Автокаталитическая реакция - это реакция, в которой один из продуктов сам по себе является катализатором той же реакции, в то время как подача одного из реагентов является фиксированной. Это естественным образом приводит к логистическому уравнению по той же причине, что и рост населения: реакция является самоусиливающейся, но ограниченной.
Логистическая функция была независимо заново открыта как модель роста населения в 1920 году Раймондом Перлом и Лоуэллом Ридом, опубликованным как Pearl Reed (1920). ошибка harvtxt: нет цели: CITEREFPearlReed1920 (help ), что привело к его использованию в современной статистике. Первоначально они не знали о работе Ферхюльста и предположительно узнали о ней от Л. Гюстав дю Паскье, но они не поверили ему и не приняли его терминологию. Удный Юле в 1925 году признал приоритет Verhulst, и термин «логистика» был возрожден и с тех пор используется. Перл и Рид сначала применили модель к населению Соединенных Штатов, а также сначала подогнали кривую, проведя ее через три точки; как и в случае с Verhulst, это снова дало плохие результаты.
В 1930-х годах пробит-модель была разработана и систематизирована Честером Иттнером Блиссом, который ввел термин «пробит». "в Bliss (1934) harvtxt error: нет цели: CITEREFBliss1934 (help ), и John Gaddum в Gaddum (1933) Ошибка harvtxt: нет цели: CITEREFGaddum1933 (help ), и модель соответствует оценке максимального правдоподобия по Рональду А. Фишеру в Fisher (1935) ошибка harvtxt: нет цели: CITEREFFisher1935 (help ), как дополнение к работе Блисс. Пробит-модель в основном использовалась в биопроб, и ей предшествовали более ранние работы, датированные 1860 годом; см. Пробит-модель § История. Пробит-модель повлияла на последующее развитие логит-модели, и эти модели конкурировали друг с другом.
Логистическая модель, вероятно, впервые была использована в качестве альтернативы пробит-модели в биотесте Эдвином Бидвеллом Уилсоном и его ученица Джейн Вустер в Wilson Worcester (1943). Однако разработка логистической модели в качестве общей альтернативы пробит-модели была в основном связана с работой Джозефа Берксона на протяжении многих десятилетий, начиная с Berkson (1944) harvtxt error: нет цели: CITEREFBerkson1944 (help ), где он придумал "logit" по аналогии с "probit" и продолжил до Berkson (1951) harvtxt error: no target: CITEREFBerkson1951 (помощь ) и последующие годы. Логит-модель изначально отвергалась как уступающая пробит-модели, но «постепенно достигла равенства с логит-моделью», особенно в период с 1960 по 1970 г. К 1970 году логит-модель достигла паритета с пробит-моделью, которая использовалась в статистических журналах, а затем превзошел его. Эта относительная популярность была обусловлена принятием логита за пределами биотеста, а не вытеснением пробита в рамках биотеста, и его неформальным использованием на практике; Популярность логита объясняется вычислительной простотой, математическими свойствами и универсальностью логит-модели, что позволяет использовать ее в различных областях.
За это время были внесены различные усовершенствования, в частности, Дэвидом Коксом, поскольку in Cox (1958).
Модель полиномиального логита была представлена независимо в Cox (1966) и Thiel (1969), что значительно расширило область применения и популярность модели логита. В 1973 году Дэниел Макфадден связал полиномиальный логит с теорией дискретного выбора, в частности, аксиомой выбора Люса, показывая, что полиномиальный логит следует из предположения независимость от нерелевантных альтернатив и интерпретация вероятностей альтернатив как относительных предпочтений; это дало теоретическую основу для логистической регрессии.
Существует большое количество расширений:
Большинство статистических программ может выполнять бинарную логистическую регрессию.
glm в пакете статистики (с использованием family = binomial)lrmв rms пакете gm_logisticдля быстрой и тяжелые вычисления с использованием крупномасштабных данных.Logit в модуле Statsmodels.LogisticRegression в модуле Scikit-learn.LogisticRegressor в модуле TensorFlow.mnrfitв (с «неправильным» кодом 2 вместо 0)fminunc / fmincon, fitglm, mnrfit, fitclinear, mleмогут выполнять логистическую регрессию.Примечательно, что пакет расширения статистики Microsoft Excel не включает его.
| Викиверситет содержит обучающие ресурсы о логистической регрессии |