
Войти
В статистике, исследовательский анализ данных - это подход к анализу наборы данных для резюмирования их основных характеристик, часто с помощью визуальных методов. Статистическая модель может использоваться или нет, но в первую очередь EDA предназначена для того, чтобы увидеть, что данные могут сказать нам, помимо формального моделирования или задачи проверки гипотез. Джон Тьюки способствовал исследовательскому анализу данных, чтобы побудить статистиков изучить данные и, возможно, сформулировать гипотезы, которые могут привести к сбору новых данных и экспериментам. EDA отличается от анализа исходных данных (IDA), который более узко фокусируется на проверке допущений, необходимых для подгонки модели и проверки гипотез, а также на обработке недостающих значений и выполнении преобразований переменных по мере необходимости. EDA включает IDA.
Тьюки определил анализ данных в 1961 году как: «Процедуры анализа данных, методы интерпретации результатов таких процедур, способы планирования сбора данных, чтобы сделать его анализ проще, точнее или точнее, а также все механизмы и результаты (математической) статистики, которые применяются к анализу данных ».
Поддержка Тьюки EDA способствовала развитию статистических вычислений пакеты, особенно S в Bell Labs. Язык программирования S вдохновил системы 'S'-PLUS и R. В этом семействе сред статистических вычислений были значительно улучшены возможности динамической визуализации, что позволило статистикам идентифицировать выбросы, тенденции и закономерности в данных, которые заслуживают дальнейшего изучения.
EDA Тьюки был связан с двумя другими разработками в статистической теории : надежной статистикой и непараметрической статистикой, оба из которых пытались снизить чувствительность статистических выводов об ошибках при формулировании статистических моделей. Тьюки предложил использовать пятизначную сводку числовых данных - два крайних значения (максимум и минимум ), медиана и квартили - поскольку эти медиана и квартили, являющиеся функциями эмпирического распределения, определены для всех распределений, в отличие от среднего и стандартное отклонение ; кроме того, квартили и медиана более устойчивы к наклонному или распределению с тяжелым хвостом, чем традиционные итоги (среднее и стандартное отклонение). Пакеты S, S-PLUS и R включали подпрограммы, использующие статистику передискретизации, такие как jackknife Кенуя и Тьюки и bootstrap Эфрона <41.>, которые непараметрически и устойчивы (для многих задач).
Исследовательский анализ данных, надежная статистика, непараметрическая статистика и развитие языков статистического программирования облегчили работу статистиков над научными и инженерными проблемами. К таким проблемам относились производство полупроводников и понимание сетей связи, которые волновали Bell Labs. Эти статистические разработки, отстаиваемые Тьюки, были разработаны, чтобы дополнить аналитическую теорию проверки статистических гипотез, в частности лапласовскую традицию, делающую упор на экспоненциальные семейства..
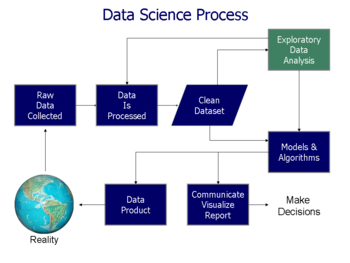 Блок-схема процесса науки о данных
Блок-схема процесса науки о данных Джон У. Тьюки написал книгу «Исследовательский анализ данных» в 1977 году. Тьюки считал, что в статистике слишком много внимания уделяется проверке статистических гипотез (подтверждающий анализ данных); больший акцент необходимо сделать на использовании данных для предложения гипотез для проверки. В частности, он считал, что смешение двух типов анализа и использование их на одном и том же наборе данных может привести к систематическому смещению из-за проблем, присущих проверке гипотез, предлагаемых данными.
Цели EDA:
Многие методы EDA были адаптированы для данных горное дело. Они также преподаются молодым студентам как способ приобщить их к статистическому мышлению.
Существует ряд инструментов, которые полезны для EDA, но EDA характеризуется в большей степени по отношению к выбранным методам.
Типичными графическими методами, используемыми в EDA, являются:
Типичные количественные методы:
Многие идеи EDA восходят к более ранним авторам, например:
В рамках курса Открытого университета Статистика в обществе (MDST 242) вышеуказанные идеи были объединены с работой Готфрида Нётер, которая представила статистический вывод посредством подбрасывания монеты и медианного теста.
Результаты EDA ортогональны задаче первичного анализа. Для иллюстрации рассмотрим пример из Cook et al. где задача анализа состоит в том, чтобы найти переменные, которые наилучшим образом предсказывают чаевые официанту за ужином. В данных, собранных для этой задачи, доступны следующие переменные: сумма чаевых, общий счет, пол плательщика, раздел для курящих / некурящих, время суток, день недели и размер вечеринки. Задача первичного анализа решается путем подбора регрессионной модели, в которой показатель чаевых является переменной отклика. Соответствующая модель:
, которая говорит о том, что по мере увеличения размера обеда на одного человека (что приводит к увеличению счета), ставка чаевых будет уменьшаться на 1 %.
Однако изучение данных обнаруживает другие интересные особенности, не описанные в этой модели.
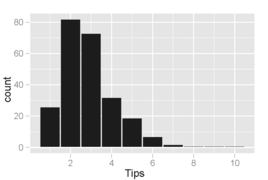
Гистограмма суммы чаевых, где ячейки покрывают приращение в 1 доллар. Распределение значений искажено вправо и одномодально, как это обычно бывает при распределении небольших неотрицательных величин.

Гистограмма суммы чаевых, где ячейки покрывают приращение 0,10 доллара США. Наблюдается интересный феномен: пики возникают при суммах в целый доллар и полдоллара, что вызвано тем, что клиенты выбирают круглые числа в качестве чаевых. Такое поведение характерно и для других типов покупок, таких как бензин.

Точечная диаграмма между чаевыми и счетами. Точки под линией соответствуют чаевым, которые ниже ожидаемой (для данной суммы счета), а точки над линией выше ожидаемых. Мы могли бы ожидать увидеть тесную положительную линейную связь, но вместо этого увидим вариацию , которая увеличивается с размером чаевых. В частности, в правом нижнем углу больше точек далеко от линии, чем в верхнем левом, что указывает на то, что больше клиентов очень дешевы, чем очень щедрые.

Диаграмма разброса чаевых и счета, разделенных по полу плательщика и статусу раздела для курящих. На вечеринках для курящих гораздо больше вариантов советов, которые они дают. Мужчины, как правило, платят (несколько) более высокие счета, а некурящие женщины, как правило, очень часто дают чаевые (с тремя заметными исключениями, показанными в выборке).
То, что можно узнать из графиков, отличается от того, что проиллюстрировано регрессионной моделью, даже несмотря на то, что эксперимент не был разработан для исследования каких-либо других тенденций. Паттерны, обнаруженные при изучении данных, предполагают гипотезы об опрокидывании, которые, возможно, не ожидались заранее и которые могут привести к интересным последующим экспериментам, в которых гипотезы формально формулируются и проверяются путем сбора новых данных.