
Войти
Факторный анализ - это статистический метод, используемый для описания изменчивости наблюдаемых, коррелировали переменные с точки зрения меньшего количества ненаблюдаемых чисел, называемые факторами . Например, возможно, что вариации многомерных чисел в основном отражают вариации двух ненаблюдаемых (лежащих в основе) переменных. Факторный анализ ищет такие совместные вариации в ответ на ненаблюдаемые скрытые переменные. Наблюдаемые переменные модели изменяются как линейные комбинации дополнительных факторов плюс термины «ошибка ». Факторный анализ направлен на поиск независимых скрытых чисел.
Теория, лежащая в основе методов факторного анализа, заключается в том, что информацию, полученную о взаимозависимости между наблюдаемыми переменными, можно использовать позже, чтобы сократить набор в наборе данных. Факторный анализ обычно используется в биологии, психометрии, личностных теориях, маркетинге, продуктом, опыте операций и финансы. Это может помочь дело с набором данных, в которых имеется большое количество чисел, которые, как считается, отражают меньшее количество основных / скрытых чисел. Используется один из наиболее используемых методов взаимозависимости, когда используется набор систематических методов взаимозависимости, который используется в том, чтобы выявить скрытые факторы взаимозависимости.
Факторный анализ связан с анализом главных компонентов (PCA), но они не идентичны. В этой области существуют большие разногласия по различию между двумя методами (см. Раздел разведочный факторный анализ по с анализом компонентов ниже). PCA можно рассматривать как более базовую версию исследовательского факторного анализа (EFA), который был разработан в первые дни до появления высокоскоростных компьютеров. И PCA, и факторный анализ использования уменьшения размера набора данных, но подходы, используемые для этого, различны для этих двух методов. Факторный анализ разработан с помощью методов некоторых ненаблюдаемых факторов, тогда PCA напрямую не решает эту задачу; в лучшем случае PCA дает приближение к желаемым факторам. С точки зрения исследовательского анализа, собственные значения PCA - это завышенные нагрузки компонентов, т. Е. Загрязненные дисперсией ошибок.
Предположим, у нас есть набор 


Предположим, что для некоторых неизвестных констант 





Здесь, 

В терминах матрицы мы имеем

Если у нас есть 






Также мы наложим следующие предположения на
и  независимы.
независимы. (E is Expectation )
(E is Expectation ) (Cov - это матрица кросс-ковариаций, чтобы убедиться, что факторы не коррелированы).
(Cov - это матрица кросс-ковариаций, чтобы убедиться, что факторы не коррелированы).Любое решение приведенного выше набора уравнения после ограничений для
Предположим, что 

и, следовательно, из условий, наложенных на

или, установив 

Обратите внимание, что для любой ортогональной матрицы 


Предположим, что у психолога есть гипотеза о двух лучших интеллекта, «вербальный интеллект» и «математический» »» »Доказательства гипотезы ищутся в оценках экзаменов по каждой из 10 различных академических областей 1000 студентов, ни один студент выбирается случайным образом из большого совокупности, Гипотеза психолога может сказать, что для каждой из 10 академических средних балл по группе всех студентов, разделяющих некоторую пару значений вербального и математического «интеллекта», в константе умножается на их уровень вербальный интеллект плюс еще одно постоянное умножение на их уровне математического интеллекта, то линейная естьная комбинация этих двух «факторов». Выполняются предмета, на умножаются два вида интеллекта, чтобы получить ожидаемый результат, постулируются гипотезой как одинаковые для всех уровней пар интеллекта и называются "факторной нагрузкой" по этой теме. Например, гипотеза может утверждать, что прогнозируемые средние способности студента в области астрономии равны
числа 10 и 6 - факторы нагрузки, связанные с астрономией. Другие учебные предметы могут иметь другие факторы нагрузки.
Два человека с одинаковыми степенями вербального и математического интеллекта могут иметь разные измеряемые способности в астрономии, потому что индивидуальные способности отличаются от средних способностей (предсказанных выше) и из-за самой самой. Такое значение составляет то, что в совокупности называется "ошибкой" - определенным термином, обозначающим статистически значимое, указывает индивидуум при измерении или прогнозируемом уровне статистического интеллекта ошибки (см. и остатки в статистике ).
Наблюдаемые данные, которые входят в факторный анализ, будут учитываться 10 баллов каждого из 1000 студентов, всего 10 000 чисел. Факторные нагрузки и уровни интеллекта каждого студента должны быть выведены из данных.
В следующих областях будут обозначаться индексированными переменными. Индексы "Subject" будут обозначены буквами 

















где выборочное среднее:

, а выборочная дисперсия определяется как:

Тогда модель факторного анализа для этой конкретной выборки:

или, более кратко:

где
 - это "вербальный интеллект" студента,
- это "вербальный интеллект" студента, - это "математический интеллект" студента,
- это "математический интеллект" студента, - факторные нагрузки для th subject, для
- факторные нагрузки для th subject, для  .
.В нотации матрица мы имеем

Обратите внимание на это, для которой «вербальный интеллект» - первый компонент в каждом столбце

где 




Обратите внимание, что Это затрудняет интерпретацию факторов. См. Недостатки ниже. В этом конкретном примере, если мы не знаем, что два типа интеллекта не коррелируют, мы не можем интерпретировать эти два фактора как два разных типа интеллекта. Даже если они не коррелируют, мы не можем сказать, какой фактор соответствует вербальному интеллекту, а какой соответствует математическому интеллекту без сторонних аргументов.
Значения нагрузок 


Термин слева - 


Образцы данных 

![{\ displaystyle \ varepsilon ^ {2} = \ sum _ {a \ neq b} \ left [\ sum _ {i} z_ {ai} z_ {bi} - \ sum _ {p} \ ell _ {ap} \ ell _ {bp} \ right] ^ {2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8f6ff4549535ef5b18bdda0564011adf5aa23fcc)
Это эквивалентно минимизации недиагональных компонентов ковариации ошибок, которые уравнены модели ожидаемые значения, равные нулю. Это должно контрастировать с анализом главного компонента, который пытается минимизировать среднеквадратичную ошибку всех остатков. До высокоскоростных компьютеров большие направляющие на поиск приближенных решений, особенно при использовании методов упрощения задач, давая сокращенная матрицу корреляции. Затем это было использовано для оценки факторов и нагрузок. С появлением высокоскоростных компьютеров проблема минимизации может быть решена итеративно с достаточной скоростью, а общности вычисляются в процессе, а не требуются заранее. Алгоритм MinRes особенно подходит для решения проблем, но это невозможно сделать этим средством решения этой проблемы.
Если разрешено коррелировать коэффициенты решения (как, например, в «oblimin» вращении), то соответствующая математическая модель использует координаты перекоса, а не ортогональные координаты.
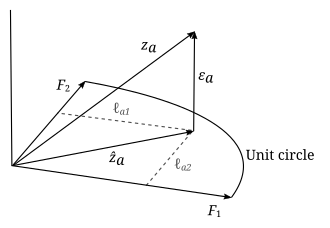 Геометрическая интерпретация параметров факторного анализа 3 респондентов на вопрос «а». «Ответ» представлен единичным вектором
Геометрическая интерпретация параметров факторного анализа 3 респондентов на вопрос «а». «Ответ» представлен единичным вектором  , который проецируется на плоскость, определяемую двумя ортонормированными векторами
, который проецируется на плоскость, определяемую двумя ортонормированными векторами  и
и  . Вектор проекции равен
. Вектор проекции равен  , а ошибка
, а ошибка  перпендикулярно плоскости, так что
перпендикулярно плоскости, так что  . Вектор проекции может быть представлен в терминах векторов множителей как
. Вектор проекции может быть представлен в терминах векторов множителей как  . Квадрат длины проекции - это общность:
. Квадрат длины проекции - это общность:  . Если был нанесен другой вектор данных
. Если был нанесен другой вектор данных  , косинус угла между и будет
, косинус угла между и будет  : запись в корреляционной матрице. (Адаптировано из Harman Рис. 4.3)
: запись в корреляционной матрице. (Адаптировано из Harman Рис. 4.3) Параметр и переменным фактором можно дать геометрическую интерпретацию. Данные (



и независимость факторов и ошибок: 

, а ошибки - это от границы этой проецируемой точки до точек данных и перпендикулярны гиперплоскости. Цель факторного анализа - найти гиперплоскость, которая в некотором смысле «лучше всего» подходит к данным, поэтому не имеет значения, как выбираются факторы анализа, которые определяют эту гиплоерпскость, если они независимы и лежат в гиперплоскости. Мы можем указать их как ортогональные, так и нормальные (
Векторы данных 
 .
.Цель факторного анализа состоит в том, чтобы выбрать аппроксимирующую гиперплоскость так, чтобы сокращенная матрица диагональных элементов воспроизводила матрицу корреляции как можно ближе, за отдельными отдельными элементов корреляционной матрицы, как известно, имеют единичную стоимость. Другими словами, цель состоит в том, чтобы как можно точнее воспроизвести взаимные корреляции в данных. В частности, для аппроксимирующей гиперплоскости среднеквадратичная ошибка недиагональных компонентов

должен быть минимизирован, и это достигается путем минимизации его относительно набора ортонормированных факторов-векторов. Видно, что

Член справа - это просто ковариация ошибок. В модели ковариация ошибок указывается как диагональная матрица, и поэтому вышеупомянутая задача дает "соответствие соответствие" модели: она дает выборочную оценку ковариации, которая дает ошибки недиагональные компоненты. минимизированы в среднеквадратическом смысле. Видно, что поскольку 

Большие значения указывают на то, что аппроксимирующая общность гиперплоскость довольно точно воспроизводит корреляционную матрицу. Средние значения факторов также должны быть ограничены равными нулю, из чего следует, что средние значения ошибок также будут равны нулю.
Исследовательский факторный анализ (EFA) используется для сложных факторов между элементами и элементами группы, которые являются частью единых концепций. Исследователь не делает никаких априорных предположений о взаимосвязях между факторами.
Подтверждающий факторный анализ (CFA) - более сложный подход, который проверяет гипотезу о том, что элементы связаны с конкретными факторами. CFA использует моделирование структурным уравнением для тестирования измерений, при нагрузке на факторы позволяет оценить взаимосвязь между наблюдаемыми и ненаблюдаемыми переменными. Подходы к моделированию структурным уравнением могут быть погрешность измерения и менее ограничительным, чем оценка методом наименьших квадратов. Гипотетические модели проверяются на фактических данных, и анализируют характеристики наблюдаемых переменных (факторов), а также корреляцию между скрытыми переменными.
Главный компонент Анализ (PCA) - широко используемый метод экстракции факторов, который является первым этапом EFA. Веса факторов вычисляется для извлечения максимально возможной дисперсии, при этом последующее разложение на множители продолжается до тех пор, пока не останется значимой дисперсии. Затем факторную модель необходимо повернуть для анализа.
Канонический факторный анализ, также называемый каноническим факторингом Рао, - это другой метод вычисления той же модели, что и PCA, который использует метод главной оси. Канонический факторный анализ ищет факторы, которые имеют самую высокую корреляцию с наблюдаемыми переменными. На канонический факторный анализ не влияет произвольное масштабирование данных.
Анализ общих факторов, также называемый анализом основных факторов (PFA) или факторингом по главной оси (PAF), ищет наименьшее количество факторов, которые могут вызвать общую дисперсию (корреляцию) набора чисел.
Факторинг изображения основан на матрице корреляции прогнозируемые числа, а не на фактических числах, где каждая переменная прогнозируется на основе другого использования множественной регрессии.
Альфа-факторинг основан на максимизировании надежности факторов, предполагаемая, что переменные выбираются случайным образом из множества чисел. Все другие методы предполагают выбор времени и фиксированные переменные.
Факторная регрессионная модель - это комбинаторная модель факторной модели и регрессионной модели; или, альтернативно, ее можно рассматривать как гибридную факторную модель, факторы, которые частично известны.
Факторные нагрузки: Общность - это стандартизированная внешняя нагрузка элемента. По аналогии с r -квадратом Пирсона, возведенная в квадратную нагрузку представляет собой процент отклонения в этой индикаторной переменной, объясняемой этим фактором. Чтобы получить процент дисперсии всех чисел, учитываемых факторов, сложите сумму возведенных в квадрат факторных нагрузок для этого фактора (столбец) и разделите на количество факторов. (Обратите внимание, что количество величин равно сумме их дисперсия, как дисперсия стандартизованной переменной 1.) Это то же самое, что и деление собственного значения фактора на количество величин.
Интерпретация факторных нагрузок: согласно одному практическому правилу в подтверждающих параметрах нагрузки должно быть 0,7 или выше, чтобы подтвердить соответствующие независимые переменные, уровни априори, конкретным фактором, основанным на том, что уровень 0, 7 соответствует примерно дисперсии показателя объясняемой данным фактором. Таким образом, исследователи, используемые в некоторых центральных исследовательских целях, используют более низкий уровень, такие как 0,4 для некоторых факторов и 0,25 для других факторов. В любом случае факторные нагрузки следует интерпретировать в теории теории, а не с помощью произвольных уровней отсечения.
При наклонном повороте можно исследовать как матрицу шаблона, так и матрицу структуры. Матрица структуры - это просто матрица факторной нагрузки, как при ортогональном вращении, представляющая дисперсию измеряемой переменной, объясняющую фактор как на основе уникальных, так и общих вкладов. Матрица шаблонов, напротив, содержит коэффициенты, которые представляют просто уникальные вклады. Чем больше факторов, тем ниже коэффициенты структуры, как правило, поскольку будет объяснено больше общих вкладов в дисперсию. Для наклонного вращения исследователь смотрит как на коэффициенты структуры, так и на коэффициенты структуры, приписывая метку фактору. Принципы наклонного вращения могут быть выведены как из перекрестной энтропии, так и из ее двойной энтропии.
Общая информация: сумма возведенных в квадратный факторных нагрузок для всех факторов для данной переменной (строки) представляет собой дисперсию этой переменной, учитывающую все факторы. Общность измеряет процент вариации данной модели, объясняемой всеми факторами вместе.
Ложные решения: если общность превышает 1.0, существует ложное решение, которое может отражать слишком маленькую выборку или выбор извлекать слишком много или слишком мало факторов.
Уникальная изменчивость альтернативы минус ее общность.
Собственные значения / характеристики корни: Собственные значения измеряют степень вариации в общей выборке, учитываем каждый фактор. Отношение собственных значений - это отношение к факторам по отношению к переменным. Фактор может быть проигнорирован как менее важный, чем факторы с более высокими собственными значениями.
Извлечение сумм квадратов нагрузок: Начальные собственные значения и собственные значения после извлечения (перечисленные SPSS как «Извлечение сумм квадратов загрузок») такие же для извлечения PCA, но для других методов извлечения собственные значения после извлечения будут ниже чем их первоначальные аналоги. SPSS также печатает «Суммы вращения квадратов нагрузок», и даже для PCA эти собственные значения будут отличаться от исходных и извлеченных собственных значений, хотя их сумма будет такой же.
Факторные оценки (также называемые компонентными оценками в PCA): это оценки каждого случая (строки) по каждому фактору (столбцу). Чтобы вычислить факторную оценку для данного случая для данного фактора, нужно взять стандартизированную оценку случая по каждой переменной, умножить на соответствующие нагрузки переменной для данного фактора и суммировать эти продукты. Вычисление оценок факторов позволяет искать выбросы факторов. Кроме того, факторные оценки могут использоваться в качестве переменных при последующем моделировании. (Объясняется с помощью PCA, а не с точки зрения факторного анализа).
Исследователи хотят избежать таких субъективных или произвольных критериев удержания факторов, как «это имело смысл для меня». Для решения этой проблемы был разработан ряд объективных методов, позволяющих пользователям определить подходящий набор решений для исследования. Методы могут не совпадать. Например, параллельный анализ может предложить 5 факторов, в то время как MAP Велисера предлагает 6, поэтому исследователь может запросить 5- и 6-факторные решения и обсудить каждое с точки зрения их связи с внешними данными и теорией.
Параллельный анализ Хорна (PA): метод моделирования на основе Монте-Карло, который сравнивает наблюдаемые собственные значения с значениями, полученными из некоррелированных нормальных переменных. Фактор или компонент сохраняется, если связанное собственное значение больше 95-го процентиля распределения собственных значений, полученных из случайных данных. PA является одним из наиболее часто рекомендуемых правил для определения количества компонентов, которые необходимо сохранить, но многие программы не включают эту опцию (заметным исключением является R ). Тем не менее, Formann предоставил как теоретические, так и эмпирические доказательства того, что его применение во многих случаях может быть неприемлемым, поскольку на его эффективность значительно влияют размер выборки, различение предметов, и тип коэффициента корреляции.
MAP-тест Велисера (1976), как описано Кортни (2013), «включает полный анализ основных компонентов с последующим исследованием серии матриц частичных корреляций» (стр. 397 (хотя обратите внимание, что эта цитата не встречается в Velicer (1976), и номер цитируемой страницы находится за пределами страниц цитаты). Квадрат корреляции для Шага «0» (см. Рисунок 4) - это средний квадрат недиагональной корреляции для непартифицированных корреляционная матрица. На шаге 1 первый главный компонент и связанные с ним элементы разделяются. После этого средний квадрат недиагональной корреляции для последующей корреляционной матрицы затем вычисляется для шага 1. На шаге 2 первые два главных компонента s разделяются, и снова вычисляется результирующая недиагональная корреляция среднего квадрата. Вычисление Действия выполняются для k минус один шаг (k представляет собой общее количество в матрице). После этого выстраиваются все средние квадраты корреляций для каждого шага, и номер шага в анализе, который приводит к самому низкому среднему квадрату частичной корреляции, определяет количество компонентов или факторов, которые необходимо сохранить. С помощью этих средств системы сохраняются до тех пор, пока дисперсия в корреляционной матрице систематической дисперсии, отличие от дисперсии остатка или ошибки. Хотя методологически метод MAP схож с анализом главных компонентов, он показал себя достаточно хорошо при параметрах, которые необходимо сохранить в нескольких исследованиях моделирования. Эта процедура доступна через пользовательский интерфейс SPSS, а также через пакет mental для языка программирования R.
Критерий Кайзера: правило Кайзера заключается в отбрасывании всех компонентов с собственными значениями ниже 1.0 - это собственное значение, равное информации, приходящейся на средний отдельный элемент. Критерий Кайзера является значением по умолчанию в SPSS и большинством статистических программ, но не рекомендуется при использовании в качестве единственного критерия положения фактора фактора, поскольку он имеет тенденцию к избыточному извлечению факторов. Был создан вариант этого метода, в котором исследователь вычисляет доверительные интервалы для каждого собственного значения и используются только те факторы, у которых доверительный интервал больше 1.0.
График осыпи : тест осыпи Кеттелла отображает компоненты оси X и соответствующие значения как по оси Y. При вправо к более поздним компонентам собственные значения уменьшаются. Когда прекращается прекращается и кривая изгибается в сторону менее того спуска, тест на осыпи Кеттелла требует опускать все остальные компоненты после того, который начинается в локте. Это правило иногда критикуют за то, что оно поддается контролируемому исследователем "обману ". То есть, поскольку выбор «изгиба» может быть субъективным, поскольку кривая имеет несколько изгибов или является гладкой кривой, исследователь может испытать соблазн установить пороговое значение для числа факторов, требуемых его программой исследования.
Критерии объяснения дисперсии: некоторые исследователи просто используют изменение количества факторов, чтобы учесть 90% (иногда 80%). Если цель исследователя подчеркивает экономию (объяснение дисперсии с помощью минимального количества факторов), критерий может составлять всего 50%.
Байесовский подход, основанный на индийском буфете, возвращает распределение вероятностей по вероятному количеству скрытых факторов.
Выход без вращения максимизирует дисперсию, учитываемую первым и последующими факторами, и заставляет факторы быть ортогональными. «Большая часть элементов, используемых, как правило, загружается на ранние факторы». Вращение для того, чтобы сделать вывод более понятным, за счет поиска так называемой «простые структуры»: схемы нагрузки, при которой каждый элемент сильно нагружается по одному из факторов и намного слабее по другим факторам. Вращения могут быть ортогональными или наклонными (позволяющими соотносить факторы).
Вращение Varimax - это ортогональное вращение факторных факторов для максимизации дисперсии квадратов нагрузок фактора (столбца) по всем переменным (строкам) в факторной матрице, что позволяет дифференцировать исходный переменные по извлеченным факторам. Каждый фактор будет иметь либо большую, либо малую нагрузку какой-либо конкретный вариант. Решение Varimax дает результаты, которые максимально упрощают оценку каждой модели с помощью одного фактора. Это наиболее распространенный вариант вращения. Однако ортогональность (то есть независимость) факторов является нереалистичным предположением. Наклонные вращения включают ортогональное вращение, и по этой причине они вращаются предпочтительным методом. Учет факторов, которые коррелируют друг с другом, применимы в психометрических исследованиях, поскольку отношения и интеллектуальные способности, как правило, коррелируют, поскольку во многих ситуациях было нереалистично предположить мнение.
Ротация Quartimax является ортогональной альтернативной, которая сводит к минимуму количества факторов, необходимых для объяснения каждой переменной. "Этот тип нагрузки". Такая факторная структура обычно не помогает целям исследования.
Ротация Equimax - это компромисс между критериями варимакса и квартимакса.
Прямое вращение облимина является стандартным методом, когда требуется неортогональное (наклонное) решение, то есть такое, в котором коэффициенты могут быть коррелированы. Это приводит к более высоким собственным значениям, но уменьшит интерпретируемость факторов. См. Ниже.
Вращение Promax - это альтернативный метод неортогонального (наклонного) вращения, который в вычислительном быстрее, чем метод прямого наклона, и поэтому иногда используется для очень больших наборов данных.
Факторный анализ высшего порядка - это статистический метод, состоящий из повторяющихся шагов факторного анализа - факторный анализ повернутых факторов. Его заслуга в том, чтобы дать возможность исследователю увидеть модель изучаемых явлений. Чтобы интерпретировать результаты, следует либо перемножить первичное число матриц шаблонов множителей более высокого порядка (Gorsuch, 1983), либо, возможно, применить вращение Varimax к результату (Thompson, 1990) или с С помощью решения Шмида-Леймана (SLS, Schmid Leiman, 1957, также известное как преобразование Шмида-Леймана), которое приписывает вариацию от первичных факторов к факторам второго порядка.
Чарльз Спирман был первым психологом, который обсудил общий факторный анализ, и сделал это в своей статье 1904 года. Он предоставил немного деталей о его методх и был посвящен однофакторным моделям. Он обнаружил, что одна общая умственная способность, или g, лежит в основе и формируется когнитивными средствами, как бы, не связанные друг с другом предметы имеют положительную корреляцию, что привело его к постулату. способности человека.
Первоначальное факторного анализа с множественными факторами развития дано Луи Терстоуном 1930 г. в двух статьях в начале-х годов, кратко изложенных в его книге 1935 года Вектор разума. Терстон представил несколько важных концепций факторного анализа, включая общность, уникальность и ротацию. Он выступал за "простую структуру" и разработал методы ротации, которые можно было бы использовать как способ достижения таких структур.
В методологии Q Стивенсон, ученик Спирмена, различает Анализ R-фактора, ориентированный на изучение межиндивидуальных различий, и анализ Q-фактора, ориентированный на субъективные внутрииндивидуальные различия.
Раймонд Кеттелл был решительным сторонним анализатором и психометрии и использовал многофакторную теорию Терстона для объяснения интеллекта. Кеттел также разработал «осыпной» тест и коэффициенты сходства.
Факторный анализ используется для использования «факторов», которые объясняют разнообразие различных тестов. Например, исследование интеллекта показало, что люди, получившие высокий балл в тесте на вербальные способности, также хороши в других тестах, требующих вербальных способностей. Исследователи объяснили это использование метода анализа одного фактора, называемого вербальным интеллектом, который представляет собой степень, в которой кто-то может решать, связанный с вербальными навыками.
Факторный анализ в психологии чаще всего ассоциируется с исследованиями интеллекта. Тем не менее, он также использовался для поиска факторов в широком диапазоне областей, таких как личность, отношения, убеждения и т. Д. Он связан с психометрикой, поскольку он может оценивать валидность инструмента, определяя, инструмент действительно измеряет постулируемые факторы.
Факторный анализ - часто используется метод в межкультурных исследованиях. Он служит для обслуживания . Услуги. Наиболее известными моделями измерений измерений являются модели, разработанные Гиртом Хофстеде, Рональдом Инглхартом, Кристианом Вельзелем, Шаломом Шварцем и Майклом Минковым.
В то как EFA и PCA рассматривает как синонимичные методы в некоторых областях статистики, это подвергалось критике. Факторный анализ «имеет дело с предположением о лежащей в основе структуры: [он] предполагает, что ковариация вызывает наблюдаемые условия одного или нескольких скрытых факторов (факторов), которые оказывают влияние на эти наблюдаемые переменные». Напротив, PCA не предполагает и не зависит от такой основной причинно-следственной связи. Исследователи утверждали, что есть объективные преимущества между этими двумя методами, означать, что есть объективные преимущества от предпочтений одного другого на основе аналитической цели. Если факторная модель сформулирована неправильно или предположения не выполняются, то факторный анализ даст анализ ошибочные результаты. Факторный анализ успешно применяется там, где адекватное понимание системы позволяет правильно определить исходную модель. PCA использует математическое преобразование исходных данных без каких-либо предположений о форме ковариационной матрицы. Целью PCA является определение линейных комбинаций исходных чисел и выбор нескольких, которые можно использовать для обобщения набора данных без большого количества информации.
Fabrigar et al. al. (1999) рассматривают ряд причин, по которому PCA не эквивалентен факторному анализу:
Факторный анализ учитывает случайную ошибку, которая присуща измерению, тогда как PCA этого не делает. так. Этот момент проиллюстрирован Брауном (2009), указывает, что в отношении корреляционных матриц, участвующих в вычислениях:
«В PCA 1,00s помещаются по диагонали, что означает, что вся дисперсия в матрице учитывается (включая дисперсию, уникальную для каждой переменной, дисперсии, общей для числа, и дисперсии ошибок). Таким образом, по определению. Напротив, в ОДВ общности помещаются в диагональный означает, что должна учитываться только дисперсия, которая является общей с другими переменными (исключая дисперсию, уникальную для каждой переменной, и дисперсию ошибки). Таким образом, по определению, это будет только дисперсия, которая является общей для переменной ».
— Браун (2009), Анализ основных компонентов и исследовательский факторный анализ - Определения, определения различия и выбор этой причиныПо причине Браун (2009) рекомендует использовать факторный анализ, когда существуют теоретические представления о взаимосвязях между переменными, как ПК использовать, если целью исследователя является изучение закономерностей в своих данных.
Различия между PCA и факторным анализом (FA) дополнительно проиллюстрированы Suhr (2009):
.
Основные шаги:
Этап сбора данных обычно выполняется профессионалами в области маркетинговых исследований. Вопросы опроса просят респондента оценить образец продукта или описания концепций продукта по ряду атрибутов. Выбирается от пяти до двадцати атрибутов. Они могут включать в себя такие вещи, как простота использования, вес, точность, долговечность, цветность, цена или размер. Выбранные атрибуты будут различаться в зависимости от изучаемого продукта. Тот же вопрос задается обо всех продуктах в исследовании. Данные для нескольких продуктов кодируются и вводятся в статистическую программу, такую как R, SPSS, SAS, Stata, STATISTICA, JMP и СИСТАТ.
В ходе анализа будут выделены основные факторы, объясняющие данные, с использованием матрицы ассоциаций. Факторный анализ - это метод взаимозависимости. Рассматривается полный набор взаимозависимых отношений. Нет спецификации зависимых переменных, независимых переменных или причинно-следственной связи. Факторный анализ предполагает, что все рейтинговые данные по различным атрибутам могут быть сокращены до нескольких важных измерений. Это сокращение возможно, потому что некоторые атрибуты могут быть связаны друг с другом. Рейтинг, присвоенный одному атрибуту, частично является результатом влияния других атрибутов. Статистический алгоритм разбивает рейтинг (так называемый исходный балл) на различные компоненты и реконструирует частичные баллы в баллы основных факторов. Степень корреляции между исходной необработанной оценкой и окончательной факторной оценкой называется факторной нагрузкой.
Факторный анализ также широко используется в физических науках, таких как геохимия, гидрохимия, астрофизика и космология, а также в биологических науках, таких как экология, молекулярная биология, нейробиология и биохимия.
При управлении качеством подземных вод важно связать пространственное распределение различных химических параметров с различные возможные источники, которые имеют разные химические сигнатуры. Например, сульфидный рудник может быть связан с высоким уровнем кислотности, растворенными сульфатами и переходными металлами. Эти сигнатуры могут быть идентифицированы как факторы с помощью факторного анализа в режиме R, а расположение возможных источников может быть предложено путем контурирования оценок факторов.
В геохимии разные факторы могут соответствовать разным минеральных ассоциаций и, следовательно, минерализации.
Факторный анализ может использоваться для обобщения данных с высокой плотности олигонуклеотидов ДНК-микрочипов на уровень датчика для Affymetrix GeneChips. В этом случае латентная переменная соответствует концентрации РНК в образце.
Факторный анализ был реализован в нескольких программах статистического анализа с 1980-х годов:
| На Викискладе есть средства массовой информации, связанные с факторным анализом. |