
Войти
 Рост и оцифровка глобальной емкости хранения информации
Рост и оцифровка глобальной емкости хранения информации Большие данные - это область, в которой рассматриваются способы анализа, систематического извлечения информации или иного обращения с наборами данных, которые слишком велики или сложная задача, которую нужно решить с помощью традиционного обработки данных прикладного программного обеспечения. Данные с большим количеством наблюдений (строки) предлагают большую статистическую мощность, тогда как данные с более высокой сложностью (больше атрибутов или столбцов) могут привести к более высокому коэффициенту ложного обнаружения. Проблемы с большими данными включают сбор данных, хранение данных, анализ данных, поиск, совместное использование, передачу, визуализация, запрос, обновление, конфиденциальность информации и источник данных. Первоначально большие данные были связаны с тремя ключевыми понятиями: объем, разнообразие и скорость. Когда мы обрабатываем большие данные, мы можем не брать выборку, а просто наблюдать и отслеживать, что происходит. Поэтому большие данные часто включают данные, размеры которых превышают возможности традиционного программного обеспечения для обработки в приемлемые сроки и приемлемые затраты.
Текущее использование термина «большие данные» имеет тенденцию относиться к использованию прогнозной аналитики, анализа поведения пользователей или некоторых других методов расширенного анализа данных, извлекающих ценность из данные, и редко до определенного размера набора данных. «Нет никаких сомнений в том, что объем доступных сейчас данных действительно велик, но это не самая важная характеристика этой новой экосистемы данных». Анализ наборов данных может найти новые корреляции для «выявления тенденций в бизнесе, предотвращения болезней, борьбы с преступностью и так далее». Ученые, руководители предприятий, практикующие врачи, представители рекламы и правительства в одинаковой степени часто сталкиваются с трудностями при работе с большими наборами данных в таких областях, как поиск в Интернете, финтех, городская информатика и бизнес-информатика. Ученые сталкиваются с ограничениями в работе e-Science, включая метеорологию, геномику, коннектомику, комплексное физическое моделирование, биологию и исследования окружающей среды.
Наборы данных быстро растут, в определенной степени потому, что они все чаще собираются дешевыми и многочисленными информационными устройствами Интернета вещей, такими как мобильные устройства, воздушные (дистанционное зондирование ), журналы программного обеспечения, камеры, микрофоны, считыватели радиочастотной идентификации (RFID) и сети беспроводных датчиков. Технологические возможности хранения информации на душу населения в мире примерно удваивались каждые 40 месяцев с 1980-х годов; с 2012 года каждый день генерируется 2,5 эксабайт (2,5 × 2 байта) данных. Основываясь на прогнозе отчета IDC, прогнозировалось, что глобальный объем данных вырастет экспоненциально с 4,4 зеттабайт до 44 зеттабайт в период с 2013 по 2020 год. К 2025 году IDC прогнозирует, что объем данных составит 163 зеттабайта данные. Один из вопросов для крупных предприятий - определить, кто должен владеть инициативами в области больших данных, влияющими на всю организацию.
Системы управления реляционными базами данных, настольные статистические данные и программные пакеты, используемые для визуализации данных, часто имеют трудности с обработкой большие данные. Для работы может потребоваться «массово параллельное программное обеспечение, работающее на десятках, сотнях или даже тысячах серверов». То, что квалифицируется как «большие данные», зависит от возможностей пользователей и их инструментов, а расширение возможностей делает большие данные постоянно меняющейся целью. «Для некоторых организаций, впервые сталкивающихся с объемом данных в сотни гигабайт, может возникнуть необходимость пересмотреть варианты управления данными. Для других могут потребоваться десятки или сотни терабайт, прежде чем размер данных станет существенным фактором. "
Этот термин используется с 1990-х годов, причем некоторые отдают должное Джону Маши за популяризацию этого термина. Большие данные обычно включают наборы данных с размерами, превышающими возможности обычно используемых программных инструментов для сбора, обработки, управления и обработки данных в течение приемлемого времени. Философия больших данных охватывает неструктурированные, полуструктурированные и структурированные данные, однако основное внимание уделяется неструктурированным данным. «Размер» больших данных - это постоянно меняющаяся цель, по состоянию на 2012 год он составлял от нескольких десятков терабайт до многих зеттабайт данных. Для больших данных требуется набор методов и технологий с новыми формами интеграции, чтобы раскрыть информацию из наборов данных, которые разнообразны, сложны и имеют большой масштаб.
«Разнообразие», «достоверность» и различные другие «V» добавляются некоторыми организациями для его описания, и это пересмотр оспаривается некоторыми отраслевыми властями.
В определении 2018 года говорится: «Большие данные - это то место, где используются инструменты параллельных вычислений необходимо для обработки данных », и отмечает:« Это представляет собой отчетливое и четко определенное изменение в используемой информатике с помощью теорий параллельного программирования и потерю некоторых гарантий и возможностей, обеспечиваемых реляционной моделью Кодда."
растущая зрелость концепции более четко очерчивает разницу между «большими данными» и «Business Intelligence ":
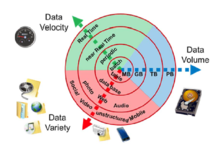 Показывает рост основных характеристик больших данных, таких как объем, скорость и разнообразие
Показывает рост основных характеристик больших данных, таких как объем, скорость и разнообразие Большие данные можно описать следующими характеристиками:
Другими важными характеристиками больших данных являются:
 = all) фиксируется или записывается или нет.
= all) фиксируется или записывается или нет.Репозитории больших данных существовали во многих формах, часто создаваемые корпорациями с особыми потребностями. Коммерческие поставщики исторически предлагали параллельные системы управления базами данных для больших данных, начиная с 1990-х годов. В течение многих лет WinterCorp публиковала самый крупный отчет о базе данных.
Teradata Corporation в 1984 году выпустила на рынок систему параллельной обработки DBC 1012. Системы Teradata были первыми, кто в 1992 году сохранил и проанализировал 1 терабайт данных. Объем жестких дисков в 1991 году составлял 2,5 ГБ, поэтому определение больших данных постоянно развивается в соответствии с законом Крайдера. Компания Teradata установила первую систему на основе РСУБД петабайтного класса в 2007 году. По состоянию на 2017 год установлено несколько десятков реляционных баз данных Teradata петабайтного класса, самая большая из которых превышает 50 ПБ. До 2008 года системы были на 100% структурированными реляционными данными. С тех пор Teradata добавила неструктурированные типы данных, включая XML, JSON и Avro.
В 2000 году компания Seisint Inc. (теперь LexisNexis Risk Solutions ) разработала распределенную платформу на основе C ++ для обработки данных и запросов, известную как HPCC Systems. платформа. Эта система автоматически разделяет, распределяет, хранит и доставляет структурированные, полуструктурированные и неструктурированные данные на несколько стандартных серверов. Пользователи могут писать конвейеры обработки данных и запросы на декларативном языке программирования потоков данных, называемом ECL. Аналитики данных, работающие в ECL, не обязаны заранее определять схемы данных и могут сосредоточиться на конкретной проблеме, изменяя данные наилучшим образом по мере разработки решения. В 2004 году LexisNexis приобрела Seisint Inc. и их платформу высокоскоростной параллельной обработки и успешно использовала эту платформу для интеграции систем данных Choicepoint Inc., когда они приобрели эту компанию в 2008 году. В 2011 году системная платформа HPCC была открыта под Лицензия Apache v2.0.
ЦЕРН и другие физические эксперименты собирали наборы больших данных в течение многих десятилетий, обычно анализируемые с помощью высокопроизводительных вычислений, а не архитектур с уменьшением карты, обычно подразумеваемых текущим движением «больших данных».
В 2004 году Google опубликовал статью о процессе под названием MapReduce, в котором используется аналогичная архитектура. Концепция MapReduce предоставляет модель параллельной обработки, и была выпущена соответствующая реализация для обработки огромных объемов данных. С помощью MapReduce запросы разделяются и распределяются по параллельным узлам и обрабатываются параллельно (этап Map). Затем результаты собираются и доставляются (этап уменьшения). Фреймворк оказался очень успешным, поэтому другие захотели повторить алгоритм. Таким образом, реализация платформы MapReduce была принята проектом с открытым исходным кодом Apache под названием Hadoop. Apache Spark был разработан в 2012 году в ответ на ограничения в Парадигма MapReduce, поскольку она добавляет возможность настраивать множество операций (а не только сопоставление с последующим сокращением).
MIKE2.0 - это открытый подход к управлению информацией, который признает необходимость внесения изменений в связи с последствиями для больших данных, указанными в статье под названием «Предложение решений для больших данных». Методология обращается к обработке больших данных с точки зрения полезных перестановок источников данных, сложности во взаимосвязи и сложности удаления (или изменения) отдельных записей.
Исследования 2012 г. показали, что многоуровневая архитектура является одним из вариантов решения проблем, связанных с большими данными. Распределенная параллельная архитектура распределяет данные по множеству серверов; Эти среды параллельного выполнения могут значительно повысить скорость обработки данных. Этот тип архитектуры вставляет данные в параллельную СУБД, в которой реализовано использование фреймворков MapReduce и Hadoop. Этот тип инфраструктуры обеспечивает прозрачность вычислительной мощности для конечного пользователя за счет использования внешнего сервера приложений.
озеро данных позволяет организации сместить акцент с централизованного управления к общей модели, чтобы реагировать на меняющуюся динамику управления информацией. Это позволяет быстро разделить данные в озеро данных, тем самым сокращая накладные расходы.
Отчет 2011 Глобального института McKinsey характеризует основные компоненты и экосистему большого следующие данные:
Многомерные большие данные также могут быть представлены как Кубы данных OLAP или, математически, тензоры. Системы баз данных с массивами предназначены для обеспечения хранения и поддержки запросов высокого уровня для этого типа данных. Дополнительные технологии, применяемые к большим данным, включают эффективные тензорные вычисления, такие как многолинейное подпространственное обучение., Базы данных с массовой параллельной обработкой (MPP ), приложения на основе поиска, интеллектуальный анализ данных, распределенные файловые системы, распределенный кеш (например, пакетный буфер и Memcached ), распределенные базы данных, облачная и инфраструктура на основе HPC (приложения, хранилища и вычислительные ресурсы) и Интернет. Несмотря на то, что было разработано много подходов и технологий, по-прежнему сложно проводить машинное обучение с большими данными.
Некоторые MPP реляционные базы данных могут хранить петабайты данных и управлять ими. Подразумевается возможность загружать, отслеживать, создавать резервные копии и оптимизировать использование больших таблиц данных в СУБД.
DARPA Программа анализа топологических данных ищет фундаментальную структуру массивных наборов данных, а в 2008 году технология стала публичной с запуском компании под названием Ayasdi.
Практики процессов анализа больших данных, как правило, враждебно относятся к более медленному общему хранилищу, предпочитая хранилище с прямым подключением (DAS ) в различных формах - от твердотельного накопителя (SSD ) до диска большой емкости SATA, скрытого внутри узлов параллельной обработки. Архитектура общего хранилища - сеть хранения данных (SAN) и сетевое хранилище (NAS) - воспринимается как относительно медленная, сложная и дорогая архитектура. Эти качества несовместимы с системами анализа больших данных, которые процветают за счет производительности системы, стандартной инфраструктуры и низкой стоимости.
Доставка информации в реальном времени или почти в реальном времени - одна из определяющих характеристик аналитики больших данных. Таким образом, по возможности избегают задержек. Данные в памяти с прямым подключением или на диске в порядке - данные в памяти или на другом конце соединения FC SAN - нет. Стоимость SAN в масштабе, необходимом для аналитических приложений, намного выше, чем другие методы хранения.
У общего хранилища есть как преимущества, так и недостатки в аналитике больших данных, но практики анализа больших данных по состоянию на 2011 год не одобряли его.
 Шина, обернутая SAP Большие данные, припаркованные за пределами IDF13.
Шина, обернутая SAP Большие данные, припаркованные за пределами IDF13.Большие данные настолько увеличили спрос на специалистов по управлению информацией, что Software AG, Oracle Corporation, IBM, Microsoft, SAP, EMC, HP и Dell потратили более 15 миллиардов долларов на компании-разработчики программного обеспечения, специализирующиеся на управлении данными и аналитика. В 2010 году эта отрасль стоила более 100 миллиардов долларов и росла почти на 10 процентов в год: примерно в два раза быстрее, чем бизнес программного обеспечения в целом.
Развитые страны все чаще используют технологии с интенсивным использованием данных. В мире насчитывается 4,6 миллиарда абонентов мобильных телефонов, и от 1 до 2 миллиардов человек имеют доступ к Интернету. Между 1990 и 2005 годами более 1 миллиарда человек во всем мире вошли в средний класс, что означает, что больше людей стали более грамотными, что, в свою очередь, привело к росту информации. Эффективная способность мира для обмена информацией через телекоммуникационные сети составляла 281 петабайт в 1986 году, 471 петабайт в 1993 году, 2,2 эксабайта в 2000 году, 65 эксабайт в 2007 году и прогнозы к 2014 году объем интернет-трафика составит 667 эксабайт в год. Согласно одной из оценок, одна треть хранимой в мире информации находится в форме буквенно-цифрового текста и данных неподвижных изображений, что является наиболее полезным форматом для большинства приложений с большими данными. Это также показывает потенциал еще неиспользованных данных (то есть в форме видео- и аудиоконтента).
Хотя многие поставщики предлагают готовые решения для больших данных, эксперты рекомендуют разрабатывать собственные решения, специально адаптированные для решения текущей проблемы компании, если компания обладает достаточными техническими возможностями.
Использование и внедрение больших данных в государственные процессы позволяет повысить эффективность с точки зрения затрат, производительности и инноваций, но не лишено недостатков. Анализ данных часто требует, чтобы несколько частей правительства (центрального и местного) работали в сотрудничестве и создавали новые инновационные процессы для достижения желаемого результата.
CRVS (регистрация актов гражданского состояния и демографическая статистика ) собирает все свидетельства о статусе от рождения до смерти. CRVS - это источник больших данных для правительств.
Исследования по эффективному использованию информационных и коммуникационных технологий в целях развития (также известные как ICT4D) показывают, что технологии больших данных могут внести важный вклад, но также представляют уникальные проблемы для Международное развитие. Достижения в области анализа больших данных предлагают рентабельные возможности для улучшения принятия решений в важнейших областях развития, таких как здравоохранение, занятость, экономическая производительность, преступность, безопасность и стихийные бедствия и ресурсы управление. Кроме того, данные, создаваемые пользователями, открывают новые возможности для передачи голоса неслышимому. Однако давние проблемы для развивающихся регионов, такие как неадекватная технологическая инфраструктура и нехватка экономических и человеческих ресурсов, усугубляют существующие проблемы с большими данными, такие как конфиденциальность, несовершенная методология и проблемы совместимости.
Большие данные Аналитика помогла улучшить здравоохранение, предоставляя персонализированную медицину и предписывающую аналитику, вмешательство в клинические риски и прогнозную аналитику, сокращение потерь и вариативности ухода, автоматизированную внешнюю и внутреннюю отчетность по данным пациентов, стандартизированные медицинские термины и реестры пациентов, а также фрагментированные точечные решения. Некоторые области улучшения более желательны, чем реализованы на самом деле. Уровень данных, генерируемых в системах здравоохранения, нетривиален. С появлением мобильного здравоохранения, электронного здравоохранения и носимых технологий объем данных будет продолжать расти. Сюда входят данные электронных медицинских карт, данные изображений, данные пациентов, данные датчиков и другие формы данных, которые трудно обрабатывать. В настоящее время существует еще большая потребность в таких средах, чтобы уделять больше внимания качеству данных и информации. «Большие данные очень часто означают« грязные данные », и доля неточностей данных увеличивается с ростом объема данных». Осмотр человека в масштабе больших данных невозможен, и службы здравоохранения остро нуждаются в интеллектуальных инструментах для контроля точности и достоверности и обработки пропущенной информации. Хотя обширная информация в сфере здравоохранения теперь представлена в электронном виде, она подходит под зонтик больших данных, поскольку большая часть информации неструктурирована и трудна в использовании. Использование больших данных в здравоохранении создало серьезные этические проблемы, начиная от рисков для прав личности, конфиденциальности и автономии до прозрачности и доверия.
Большие данные в исследованиях в области здравоохранения особенно многообещающи с точки зрения исследовательских биомедицинских исследований, поскольку анализ на основе данных может продвигаться вперед быстрее, чем исследования, основанные на гипотезах. Затем тенденции, наблюдаемые при анализе данных, можно проверить в традиционных последующих биологических исследованиях, основанных на гипотезах, и, в конечном итоге, в клинических исследованиях.
Связанная подобласть приложений, которая в значительной степени полагается на большие данные в области здравоохранения, - это компьютерная диагностика в медицине. Достаточно вспомнить, что, например, для мониторинга эпилепсии принято ежедневно создавать от 5 до 10 ГБ данных. Точно так же одно несжатое изображение груди томосинтез в среднем содержит 450 МБ данных. Это лишь некоторые из множества примеров, когда компьютерная диагностика использует большие данные. По этой причине большие данные были признаны одной из семи ключевых проблем, которые системы компьютерной диагностики должны преодолеть, чтобы выйти на новый уровень производительности.
A Исследование McKinsey Global Institute выявило нехватку 1,5 миллиона высококвалифицированных специалистов и менеджеров по обработке данных и ряда университетов, включая Университет Теннесси и Калифорнийский университет в Беркли., создали магистерские программы для удовлетворения этого спроса. Частные учебные лагеря также разработали программы для удовлетворения этого спроса, включая бесплатные программы, такие как The Data Incubator, или платные программы, такие как General Assembly. В конкретной области маркетинга Ведель и Каннан подчеркивают одну из проблем, заключающуюся в том, что у маркетинга есть несколько поддоменов (например, реклама, продвижение по службе, разработка продуктов, брендинг), которые используют разные типы данных. Поскольку универсальные аналитические решения нежелательны, бизнес-школы должны готовить менеджеров по маркетингу к тому, чтобы они обладали обширными знаниями обо всех различных методах, используемых в этих поддоменах, чтобы получить общую картину и эффективно работать с аналитиками.
Чтобы понять, как носитель использует большие данные, сначала необходимо предоставить некоторый контекст в механизме, используемом для медиапроцесса. Ник Кулдри и Джозеф Туроу предположили, что практикующие в СМИ и рекламе подходят к большим данным как к множеству действенных точек информации о миллионах людей. Похоже, что отрасль отходит от традиционного подхода к использованию определенных средств массовой информации, таких как газеты, журналы или телешоу, и вместо этого обращается к потребителям с помощью технологий, которые достигают целевой аудитории в оптимальное время в оптимальных местах. Конечная цель состоит в том, чтобы служить или передать сообщение или контент, который (с точки зрения статистики) соответствует мышлению потребителя. Например, издательская среда все чаще адаптирует сообщения (рекламные объявления) и контент (статьи) для обращения к потребителям, которые были получены исключительно с помощью различных интеллектуального анализа данных.
Channel 4, британский общественная телекомпания, лидер в области больших данных и анализа данных.
Медицинские страховые компании собирают данные о социальных «детерминантах здоровья», таких как продукты питания и потребление телевидения, семейное положение, размер одежды и покупательские привычки, на основании которых они делают прогнозы относительно затрат на здоровье, чтобы выявлять проблемы со здоровьем у своих клиентов. Спорный вопрос, используются ли эти прогнозы в настоящее время для ценообразования.
Большие данные и IoT работают вместе. Данные, извлеченные из устройств IoT, обеспечивают отображение взаимосвязи устройств. Такие сопоставления использовались медиаиндустрией, компаниями и правительствами для более точного нацеливания на свою аудиторию и повышения эффективности СМИ. Интернет вещей также все чаще используется как средство сбора сенсорных данных, и эти сенсорные данные используются в медицине, производстве и транспортировке.
Кевин Эштон, эксперт по цифровым инновациям, которому приписывают создание этого термина, дает определение Интернету вещей в этой цитате: «Если бы у нас были компьютеры, которые знали бы все, что нужно знать о вещах, - используя данные, которые они собирали без каких-либо помогите нам - мы сможем отслеживать и подсчитывать все, что значительно сокращает потери, потери и затраты. Мы бы знали, когда что-то нужно было заменить, отремонтировать или отозвать, и были ли они свежими или устаревшими ».
Особенно с 2015 года большие данные стали заметными в рамках бизнес-операций как инструмент, помогающий сотрудникам работать более эффективно и оптимизировать сбор и распространение информационные технологии (IT). Использование больших данных для решения проблем ИТ и сбора данных на предприятии называется аналитика ИТ-операций (ITOA). Применяя принципы больших данных к концепциям машинного интеллекта и глубоких вычислений, ИТ-отделы могут прогнозировать потенциальные проблемы и предлагать решения еще до того, как они возникнут. В это время компании ITOA также начали играть важную роль в управлении системами, предлагая платформы, объединяющие отдельные разрозненные хранилища данных и генерирующие понимание всей системы, а не изолированные карманы данных.
Примеры использования больших данных в государственных услугах:
С помощью спортивных датчиков можно использовать большие данные для улучшения тренировок и понимания участников соревнований. Также можно прогнозировать победителей в матче, используя аналитика больших данных. Можно также предсказать будущую производительность игроков. Таким образом, ценность и заработная плата игроков определяется данными, собранными в течение сезона.
В гонках Формулы-1 гоночные автомобили с сотнями генераторов генерируют терабайты данных. Эти датчики собирают данные от давления в шинах до эффективности сжигания топлива. На основании полученных данных инженеры и аналитики данных решают, следует ли вносить коррективы, чтобы выиграть гонку. Кроме того, используя большие данные, гоночные команды пытаются заранее предсказать время, когда они закончат гонку, на основе модели с использованием данных, собранных за сезон.
В течение Пандемия COVID-19 использовались большие данные, как способ минимизировать воздействие болезни. Важное применение больших данных о минимизации распространения вируса, выявление случаев и разработки методов лечения.
Правительство использовали большие данные для зараженных людей, чтобы минимизировать распространение. Первыми участниками стали Китай, Тайвань, Южная Корея и Израиль.
Шифрованный поиск и формирование кластеров в целом Данные былианы в марте 2014 года Американским общественным инженером образования. Гаутам Сивах, участвовавший в работе Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института (MIT), доктор Амир Эсмаилпур из Исследовательской группы UNH исследовали ключевые особенности больших данных, таких как формирование кластеров и их взаимосвязь. Они настроены на безопасность больших данных и ориентации терминала на различных типах данных в зашифрованном виде в облачном интерфейсе. Более того, они предложили подход к определению техники кодирования для продвижения по ускоренному поиску по зашифрованному тексту, ведущему к повышению безопасности больших данных.
В марте 2012 года Белый дом объявил о национальной «Инициативе по большим данным». который состоял из шести федеральных департаментов и агентств, выделенных более 200 миллионов долларов на исследовательские проекты по большим данным.
Инициатива включала грант национального научного фонда «Экспедиции в области вычислений» в размере 10 миллионов на 5 лет для AMPLab в университете Калифорнии, Беркли. AMPLab также получил средства от DARPA и более десятка промышленных спонсоров и использует большие данные для решения широкого круга проблем, от прогнозирования пробок на дорогах до борьбы с раком.
Большие данные Белого дома Инициатива также включает обязательство Министерства энергетики США за 5 лет для создания масштабируемого управления, анализа и визуализации (SDAV) под руководством Национальной лаборатории Лоуренса Беркли Министерства энергетики. Институт SDAV призван объединить опыт шести национальных лабораторий и семи университетов для разработки новых инструментов, которые помогут ученым управлять и визуализировать данные на суперкомпьютерах Департамента.
В мае 2012 года штат США Массачусетс объявил об инициативе Massachusetts Big Data Initiative, которая обеспечивает финансирование правительства и частных компаний различных исследовательских учреждений. Массачусетский технологический институт размещает Центр науки и технологий Intel для больших данных в Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института, объединяя правительственное, корпоративное и институциональное финансирование и исследования.
Европейская комиссия финансирует двухлетний публично-частный форум по большим данным в рамках своей Седьмой рамочной программы для вовлечения компаний, ученых и других сторон в обсуждение вопросов больших данных. Проект направлен на определение стратегии с точки зрения исследований и инноваций, которая будет определять вспомогательные действия Европейской комиссии по успешному внедрению экономических данных. Результаты этого проекта будут использованы в качестве исходных данных для Horizon 2020, их следующая рамочной программы.
. В марте 2014 года британское правительство объявило об основании Института Алана Тьюринга, назван в честь компьютерного пионера и взломщика кода, который будет посвящен новым способам сбора и анализа больших наборов данных.
В кампусе Университета Ватерлоо в Стратфорде Канадский опыт открытых данных (CODE) В День вдохновения участники периали, как использование визуализации данных может повысить понимание и привлекательность наборов больших данных и передать их историю всему миру.
Вычислительные социальные науки - любой может использовать интерфейс прикладного программирования (API), предоставляющий большие данные держатели, такие как Google и Twitter, для проведения исследований в области социальных и поведенческих наук. Часто эти API-выплаты бесплатно. Тобиас Прейс и др. использовали данные Google Trends, чтобы использовать данные пользователей Интернета из стран с более высоким валовым внутренним продуктом (ВВП) на душу населения с большей вероятностью будут искать информацию о будущем, чем информацию о прошлом. Результаты показывают, что между поведением в Интернете и реальными экономическими показателями может быть связь. Авторы исследования изучили журналы запросов Google, составленные по составлению объема поисков на предстоящий год ('2011') к объему поисков за предыдущий год ('2009'), который они называют 'будущим индексом ориентации '. Они сравнили индекс ориентации на будущее с ВВП на душу населения в каждой стране и представили сильную тенденцию к увеличению ВВП в странах, где пользователи Google больше интересуются будущим. Результаты намекают, что может существовать между экономическим прогрессом страны и поведением ее граждан в поисках информации, наблюдаемой в больших данных.
Тобиас Прейс и его коллеги Хелен Сюзанна Моут и Х. Юджин Стэнли представил метод определения онлайн-предвестников фондового рынка с использованием стратегий, основанных на данных об объеме поиска, предоставленных Google Trends. Их анализ Google объем поиска по 98 терминам финансовой релевантности, опубликованный в Научные отчеты, показывает, что увеличение объема поиска по финансово релевантным поисковым запросам, как правило, предшествует большим потерям на финансовых рынках..
Большие наборы данных связаны с алгоритмическими проблемами, которые раньше не существовало. Следовательно, существует потребность в коренном изменении способов обработки.
Семинары по алгоритму для современных массивов данных (MMDS) собирают компьютерных, ученых, статистиков, математиков и специалистов по анализу данных для обсуждения алгоритмических проблем большого масштаба. данные. Что касается больших данных, следует помнить, что такие понятия величины относительны. Как сказано: «Если прошлое может быть ориентиром, то сегодняшние большие данные, скорее всего, не будут считаться таковыми в ближайшем будущем».
Важный вопрос исследования о больших наборах данных можно спросить, нужно ли вам просмотреть полные данные, чтобы сделать выводы о свойствах, или это достаточно хороший образец. Само название «большие данные» содержит термин, связанный с размером, и это важная характеристика больших данных. Но Выборка (статистика) позволяет выбрать правильные точки данных из большего набора данных для оценки всей совокупности. Например, создается около 600 миллионов твитов. Нужно ли смотреть на все, чтобы определить темы, которые обсуждаются в течение дня? Обязательно ли просматривать все твиты, чтобы определять настроения по каждой из тем? При производстве различных сенсорных данных, таких как акустика, вибрация, давление, ток, напряжение и данные контроллера, доступны через короткие промежутки времени. Для прогнозирования времени простоя может не потребоваться просмотр всех данных, но может быть достаточно выборки. Большие данные можно разбить по различным категориям точек данных, такими как демографические, психографические, поведенческие и транзакционные данные. Имея большие наборы точек данных, маркетологи могут создать и использовать более индивидуализированные сегменты потребителей для более стратегического таргетинга.
Была проделана некоторая работа над алгоритмами выбора для больших данных. Была получена теоретическая формулировка выборки данных Twitter.
Критика парадигмы больших данных бывает двух видов: те, которые ставят под сомнение последствия самого подхода, и те, кто ставит под сомнение последствия самого подхода, и те, кто ставит под сомнение так, как это делается сейчас. Один из подходов к этой критике - это область исследования критических данных.
«Ключевые проблемы являются тем, что мы мало знаем об основных эмпирических микропроцессах, которые приводят к появлению типичных сетей». характеристики больших данных ». В своей критике Снайдерс, Мацат и Рейпс отмечают, что часто делаются очень сильные предположения о математических свойствах, которые вообще не отражают то, что действительно происходит на уровне микропроцессов. Марк Грэхем подвергся критике их утверждение Криса Андерсона о том, что большие данные означают конец теории: особое внимание уделяется идее о, что большие данные всегда должны быть контекстуализированы в социальном, экономическом и политическом контексте.. Даже на то, что компании предоставляют восьми- и девятизначные суммы, чтобы получить представление об поступающей информации, поступающей от поставщиков и клиентов, менее 40% сотрудников достаточно зрелые процессы и навыки для этого. Чтобы преодолеть этот дефицит понимания, большие данные независимо от того, насколько они всеобъемлющи или хорошо проанализированы, должны соответствовать «серьезным суждением», согласно статье в Harvard Business Review.
Во многом в том же направлении он имеет, что было указано, что решения, основанные на анализе больших данных неизбежно «принимаются миром, как это было в прошлом или в лучшем случае, как оно есть сейчас». Основываясь на большом количестве данных о прошлом опыте, алгоритмы могут предсказывать будущее развитие, если будущее на прошлое. Если динамика системы будущего изменится (если это не стационарный процесс ), прошлое мало что может сказать о будущем. Чтобы делать прогнозы в меняющихся условиях окружающей среды, необходимо иметь полное представление о динамике системы, что требует теории. В ответ на эту критику Алемани Оливер и Вэйр служат использовать «абдуктивное рассуждение в качестве первого шага в процессе исследования, чтобы привнести контекст в цифровые следы потребителя и вызвать новых теорий». Кроме того, было предложено объединить подходы к большим данным с компьютерным моделированием, таким как агентные модели и сложные системы. Агентные модели становятся все лучше в прогнозировании результатов социальных задач даже неизвестных сценариев будущего с помощью компьютерного моделирования, основанного на наборе взаимозависимых алгоритмов. Наконец, использование многомерных методов, которые исследуют скрытую структуру данных, таких как факторный анализ и кластерный анализ, оказались полезными в качестве аналитических подходов, которые выходят далеко за рамки двунаправленного анализа. различные подходы (кросс-таблицы), обычно используется с небольшими наборами данных.
В медицине и биологии традиционных научных подходов основаны на экспериментировании. Для этих подходов ограничивающими факторами являются соответствующие данные, которые могут подтвердить или опровергнуть исходную гипотезу. В настоящее время в бионауках принят новый постулат: информация, предоставляемая в огромных объемах (omics ) без предварительной гипотезы, дополнительных, а иногда и необходимых традиционным подходом, основанным на экспериментах. В массовых подходах ограничивающим фактором является формулировка гипотезы для объяснения данных. Логика поиска отличается на противоположную, и необходимо учитывать пределы индукции («Слава и философии скандал», CD Broad, 1926).
Защитники конфиденциальности нарушены угрозы конфиденциальной информации, выраженная в увеличении объема хранения и интеграции личной информации ; Группы выпустили различные рекомендации по политике. Неправильное больших больших расходов на использование средств массовой информации и даже правительство отменить доверие почти всем фундаментальным институтам, поддерживающим общество.
Наиф Аль-Родхан утверждает, что новый вид общественного договора необходимы для индивидуальных свобод в контексте данных и гигантских корпораций, владеющих огромными объемами информации. Использование больших данных следует контролировать и лучше регулировать на внутреннем и международном уровнях. Барокас и Ниссенбаум утверждают, что одним из способов защиты людей является информирование о типах информации, о том, кому она передается, при каких ограничениях и для каких целей.
«V» -модель больших данных согласованной, поскольку она сосредоточена вокруг вычислительной масштабируемости и не имеет потерь в отношении восприимчивости и понятности информации. Это к структуре, которая представляет приложение больших данных в соответствии с:
Большие наборы данных анализировались вычислительными машинами на протяжении более века, включая аналитику переписи населения США, выполненную ударом IBM -карточные машины, которые вычисляли статистику, включая средние и дисперсии населения по всему континенту. В последние десятилетия в ходе научных экспериментов, таких как ЦЕРН, были получены данные в масштабах, аналогичных нынешним коммерческим «большим данным». Однако научные эксперименты, как правило, анализируют свои данные с использованием специализированных специализированных высокопроизводительных вычислительных (суперкомпьютерных) кластеров и сетей, а не облаков дешевых обычных компьютеров, как в нынешней коммерческой волне, что подразумевает разница как в культуре, так и в стеке технологий.
Ульф-Дитрих Рейпс и Уве Мацат писали в 2014 году, что большие данные стали «модой» в научных исследованиях. Исследователь Дана Бойд выразила озабоченность по поводу использования больших данных в науке, игнорируя такие принципы, как выбор репрезентативной выборки, слишком озабоченная обработкой огромных объемов данных. Такой подход может тем или иным образом привести к смещению результатов смещения. Интеграция разнородных ресурсов данных - одни из которых можно рассматривать как большие данные, а другие нет - представляет собой огромные логистические, а также аналитические проблемы, но многие исследователи утверждают, что такая интеграция, вероятно, представляет собой наиболее многообещающие новые рубежи в науке. В провокационной статье «Критические вопросы для больших данных» авторы называют большие данные частью мифологии : «большие наборы данных предлагают более высокую форму интеллекта и знаний [...] с аурой правда, объективность и точность ». Пользователи больших данных часто «теряются в огромном количестве цифр», а «работа с большими данными по-прежнему является субъективной, и то, что они определяют количественно, не обязательно имеет более точное отношение к объективной истине». Последние разработки в области бизнес-аналитики, такие как упреждающая отчетность, особенно нацелены на повышение удобства использования больших данных за счет автоматической фильтрации бесполезных данных и корреляций. Большие структуры полны ложных корреляций либо из-за не причинных совпадений (закон действительно больших чисел ), либо исключительно из-за природы большой случайности (теория Рамсея ), либо из-за наличия не -включенные факторы, поэтому надежда первых экспериментаторов заставить большие базы данных цифр «говорить за себя» и произвести революцию в научных методах ставится под сомнение.
Анализ больших данных часто поверхностен по сравнению с анализом меньших данных наборы. Во многих проектах с большими данными не происходит анализа больших данных, но проблема заключается в извлечении, преобразовании, загрузке части предварительной обработки данных.
Большие данные - это модное слово и «расплывчатый термин», но в то же время «одержимость» предпринимателями, консультантами, учеными и СМИ. Витрины больших данных, такие как Google Flu Trends, в последние годы не давали хороших прогнозов, поскольку количество вспышек гриппа было завышено в два раза. Точно так же награды Академии и прогнозы на выборах, основанные исключительно на Twitter, чаще были ошибочными, чем запланированными. Большие данные часто создают те же проблемы, что и небольшие данные; добавление дополнительных данных не решает проблемы смещения, но может подчеркнуть другие проблемы. В частности, такие источники данных, как Twitter, не являются репрезентативными для населения в целом, и результаты, полученные из таких источников, могут привести к неправильным выводам. Переводчик Google, основанный на статистическом анализе текста с большими данными, отлично справляется с переводом веб-страниц. Однако результаты в специализированных областях могут быть существенно искажены. С другой стороны, большие данные могут также создавать новые проблемы, такие как проблема множественных сравнений : одновременное тестирование большого набора гипотез может привести к множеству ложных результатов, которые по ошибке кажутся значительными. Иоаннидис утверждал, что «большинство опубликованных результатов исследований ложны» по существу из-за одного и того же эффекта: когда многие научные группы и исследователи проводят множество экспериментов (т. Е. Обрабатывают большой объем научных данных, хотя и не с помощью технологии больших данных), вероятность «Значимый» результат, являющийся ложным, быстро растет, тем более, когда публикуются только положительные результаты. Кроме того, результаты аналитики больших данных настолько хороши, насколько хороша модель, на которой они основаны. Например, большие данные с разной степенью успеха принимали участие в попытке предсказать результаты президентских выборов в США в 2016 году.
Большие данные использовались для контроля и наблюдения такими организациями, как правоохранительные органы и корпорации. Из-за менее заметного характера надзора на основе данных по сравнению с традиционным методом контроля, возражения против контроля за большими данными возникают с меньшей вероятностью. Согласно книге Сары Брейн «Наблюдение за большими данными: пример полицейской деятельности», работа полиции с большими данными может воспроизводить существующее социальное неравенство тремя способами:
Если эти потенциальные проблемы не будут исправлены или урегулированы, эффекты контроля над большими данными будут продолжать формировать социальные иерархии. Брейн также отмечает, что сознательное использование контроля над большими данными может предотвратить превращение предубеждений на индивидуальном уровне в институциональные.