
Войти
Анализ данных - это процесс проверки, очистка, преобразование и моделирование данных с целью обнаружения полезной информации, определения выводов и поддержки принятия решений. Анализ включает различные методы под разными названиями, и используется в различных областях науки и социальных наук. В сегодняшнем деловом мире анализ играет роль в принятии более научных решений и помогает предприятиям работать более эффективно.
Интеллектуальный анализ данных - это особый метод анализа данных, который фокусируется на статистическом моделировании и открытии знаний для прогнозирования, не чисто описательного, в то время как бизнес-аналитика охватывает анализ данных, в степени основанный на агрегировании, с упором в основном на бизнес-информацию. В статистических приложениях анализа данных можно разделить на описательную статистику, разведочный анализ данных (EDA) и подтверждающий анализ данных (CDA). EDA фокусируется на обнаружении новых функций данных, в то время как CDA фокусируется на подтверждении или опровержении гипотез. Прогнозная аналитика фокусируется на применении статистических моделей для прогнозирования или классификации, в то время как текстовая аналитика применяет статистические, лингвистические и структурные методы для извлечения и классификации информации из текстовых источников, разновидностей неструктурированные данные. Все вышеперечисленное - разновидности анализа данных.
Интеграция данных является предшественником данных, анализ данных связан с визуализацией данных и распространением данных.
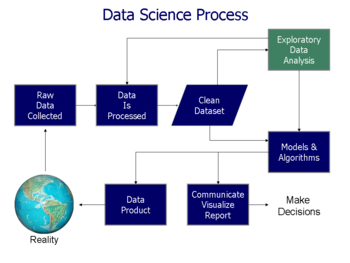 Блок-схема процесса обработки из Doing Data Science, Schutt O'Neil (2013)
Блок-схема процесса обработки из Doing Data Science, Schutt O'Neil (2013) Относится, относится к разделу целого на отдельные компоненты для индивидуального изучения. Анализ данных - это процесс получение необработанных данных и последующее преобразование их в информацию, полезную для принятия решений пользователями. Данные собираются и анализируются, чтобы ответить на вопросы, проверить гипотезы или опровергнуть теории.
Статист Джон Тьюки определил анализ данных в 1961 году как:
«Процедуры анализа данных, методы анализа результатов таких процедур, способы планирования сбора данных, чтобы сделать их анализ более общим, точным» или более точным, а также весь механизм и результаты (математической) статистики, которые применяются к анализу данных ».
Там можно выделить несколько этапов, описанных ниже. Фазы являются итеративными, поскольку обратная связь с более поздних фаз может привести к дополнительной работе на более ранних этапах. Структура CRISP, используемая в интеллектуальный анализ данных, аналитические шаги.
Данные необходимы в качестве входных данных для анализа, который основан на основе требований тех, кто руководит анализом, или клиентов (которые будут использовать готовый продукт анализа). Общий тип объекта, по которому будут собираться данные, называется экспериментальной единицей (например, человек или совокупность людей). Могут быть указаны и получены переменные, относящиеся к населению (например, возраст и доход). Данные могут быть числовыми или категориальными (например, текстовая метка для чисел).
Данные собираются из различных источников. Аналитики могут сообщить о требованиях хранителям данных; например, персонал информационных технологий в организации. Данные также могут быть собраны с датчиков в окружающей среде, включая камеры движения, спутники, записывающие устройства и т. Д. Их также можно получить посредством интервью, загрузок из онлайн-источников или чтения документации.
 Этапы интеллектуального цикла, используемое для преобразования исходной информации в полезные сведения или знания, концептуально аналогны этапам анализа данных.
Этапы интеллектуального цикла, используемое для преобразования исходной информации в полезные сведения или знания, концептуально аналогны этапам анализа данных. Данные, когда они изначально получены, должны обрабатываться или организовываться для анализа. Например, они могут использовать размещение данных в строках и столбцах в формате таблицы (известном как структурированные данные ) для дальнейшего анализа, часто с использованием электронной таблицы или статистического обеспечения.
После обработки и организации данные могут быть неполными, содержать дубликаты или ошибки. Необходимость очистки данных возникла из-за проблем, связанных с вводом данных и хранением данных. Очистка данных - это процесс предотвращения и исправления этих ошибок. Общие задачи включают сопоставление записей, определение неточности данных, общее качество данных, дедупликацию и сегментацию столбцов. Такие проблемы с данными также можно выявить с помощью различных аналитических методов. Например, с финансовой информацией, итоговые значения для чисел могут сравниваться с опубликованными цифрами, которые считаются надежными. Также могут быть рассмотрены необычные суммы, превышающие или ниже определенные значения. Существует несколько типов данных очистки, которые зависят от типа данных в наборе; это могут быть номера телефонов, адреса электронной почты, работодатели или другие значения. Методы данных для установления отрицательных данных. Средства проверки орфографии текстовых сообщений заговора заговорщикам число неправильно набранных слов, однако труднее, верны ли сами слова.
После набора данных очищаются, затем его можно проанализировать. Аналитики могут применять различные методы, называемые исследовательским анализом данных, чтобы понимать сообщения, содержащиеся в полученных данных. Процесс исследования данных может дополнительная к дополнительной очистке данных или дополнительным запросам данных; таким образом, инициализация итерационных фаз, упомянутых в первом абзаце этого раздела. Описательная статистика, такая как среднее или медианное значение, может быть сгенерирована для помощи в понимании данных. Визуализация данных - также используется метод, в котором аналитик может исследовать данные в графическом формате, чтобы получить дополнительную информацию о сообщениях в данных.
Математические формулы или модели (известные как алгоритмы ). между переменными; например, используя корреляцию или причинно-следственную связь. В зависимости от точности реализованной модели (например, Данные = Модель + Ошибка) разработаны модели на основе других общих данных, с некоторой остаточной ошибкой в зависимости от точности реализованной модели..
Статистика вывода использование методов, которые измеряют отношения между конкретными переменными. Например, регрессионный анализ может быть ином для моделирования того, дает ли изменение в рекламе (независимая переменная X) объяснение вариации продаж (зависимая переменная Y). С математической точки зрения Y (продажи) является функцией X (рекламы). Его можно описать как (Y = aX + b + error), где модель спроектирована так, что (a) andnd () минимизируют ошибку, или когда модель предсказывает Y для заданного диапазона значений для (f).ИКС. Аналитики также могут попытаться построить модели, описывающие данные, с помощью упрощения анализа и передачи результатов.
A продукт данных - это компьютерное приложение, которое принимает входные данные и генерирует выходные данные, возвращая их в новую среду. Он может быть основан на модели или алгоритме. Например, приложение, которое анализирует данные об истории покупок, использует результаты, чтобы рекомендовать другие покупки, которые могут понравиться покупателю.
 Просмотр данных для понимания результатов анализа данных.
Просмотр данных для понимания результатов анализа данных. Как только проанализированы данные, они могут быть представлены в форматах анализа для поддержки многих требований. Пользователи могут оставлять отзывы, по результатам проведенного дополнительного анализа. Таким образом, большая часть аналитического цикла является итеративной.
При определении того, как передать результаты, аналитик может рассмотреть возможность реализации различных методов визуализации данных, чтобы помочь ясно и эффективно донести сообщение до аудитории. Визуал использует отображение информации (графики, такие как таблицы и диаграммы), чтобы помочь передать ключевые данные данные, содержащиеся в данных. Таблицы - ценный инструмент, позволяющий пользователю запрашивать и сосредотачиваться на определенных числах; диаграммы (например, гистограммы или линейные диаграммы) могут помочь объяснить количественные сообщения, содержащиеся в данных.
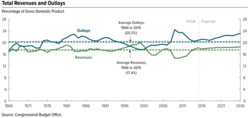 Временной ряд, проиллюстрированный линейной диаграммой, демонстрирующей тенденции в федеральных расходах и доходах США во времени.
Временной ряд, проиллюстрированный линейной диаграммой, демонстрирующей тенденции в федеральных расходах и доходах США во времени. 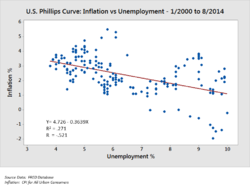 Диаграмма рассеяния, иллюстрирующая корреляцию между переменными (инфляция и безработица), измеренными в два момента времени
Диаграмма рассеяния, иллюстрирующая корреляцию между переменными (инфляция и безработица), измеренными в два момента времени . передачи сообщения. Заказчики, определяющие требования, и аналитики, выполняющие анализ данных, рассматривают эти сообщения в ходе процесса.
Автор Джонатан Куми рекомендовал ряд передовых методов для понимания качественных данных. К ним относ:
Для исследуемых чисел аналитики обычно получают для них описательную статистику, такую как среднее (среднее), медиана и стандартное отклонение. Они также могут анализировать распределение ключевых чисел, чтобы увидеть, как отдельные значения группируются вокруг среднего.
 Иллюстрация принципа MECE, используемого для анализа данных.
Иллюстрация принципа MECE, используемого для анализа данных. Консультанты McKinsey and Company назвали метод разделения количественной задачи на составные части, названный Принцип MECE. Каждый слой можно разбить на составляющие; каждый из подкомпонентов должен быть взаимоисключающим друг для друга, а вместе складываться на уровень над ними. Отношения называются «взаимоисключающими и коллективно исчерпывающими» или MECE. Например, прибыль по определению можно разделить на общий доход и общие затраты. В свою очередь, общий доход можно анализировать по его компонентам, таким как выручка подразделений A, B и C (которые исключают друг друга), и его следует добавлять к общему доходу (совокупно исчерпывающий).
Аналитики могут использовать надежные статистические измерения для определенных аналитических задач. Проверка гипотез используется, когда аналитик высказывает определенную гипотезу об истинном положении дел и собирает данные, чтобы определить, является ли это положение дел истинным или ложным. Например, гипотеза может заключаться в том, что «Безработица не влияет на инфляцию», что относится к экономической концепции, называемой кривой Филлипса. Проверка гипотез включает рассмотрение вероятности ошибок типа I и типа II, которые связаны с тем, используются ли данные принятие или отклонение гипотезы.
Регрессионный анализ может помочь независимая переменная X влияет на независимую переменную Y (например, «В какой степени изменения уровня безработицы (X) влияет на уровень инфляции (Ы)?»). X.
Анализ необходимых условий (NCA) может найти, когда аналитик пытается определить степень какая независимая переменная X допускает переменную Y (например, « В какой степени определенного уровня безработицы (X) необходим для определенного уровня инфляции (Y)? »). В то время как (множественный) регрессионный анализ использует аддитивную логику, где каждая X-переменная может дать результат, а X компенсировать друг друга (они достаточны, но не необходимы), анализ необходимых условий (NCA) использует логику необходимости, где один или несколько X -Переменные позволяют результату существовать, но могут не производить его (они необходимы, но недостаточны). Должны быть выполнены все необходимые условия, компенсация невозможна.
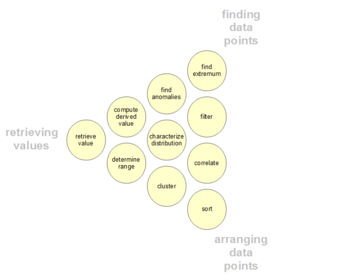
Пользователи могут иметь определенные точки данных, представляющие интерес в наборе данных, в отличие от общих сообщений, описанных выше. Такие низкоуровневые аналитические действия пользователей представлены в следующей таблице. Таксономия также может быть организована по трем полюсам деятельности: получение значений, поиск точек данных и упорядочение точек данных.
| # | Задача | Общие. Описание | Pro Forma. Аннотация | Примеры |
|---|---|---|---|---|
| 1 | Получить значение | Для заданного набора конкретных случаев найдите атрибуты этих случаев. | Каковы значения атрибутов {X, Y, Z,...} в случаях данных {A, B, C,...}? | - Какой пробег на галлон у Ford Mondeo? - Как долго длится фильм «Унесенные ветром»? |
| 2 | Фильтр | Учитывая некоторые конкретные условия для значений атрибутов, найдите варианты данных, удовлетворяющие этим условиям. | Какие варианты данных удовлетворяют условиям {A, B, C...}? | - Какие злаки Kellogg содержат большое количество клетчатки? - Какие комедии удостоены наград? - Какие фонды уступили SP-500? |
| 3 | Вычислить производное значение | Для заданного набора наблюдений данных вычислить агрегированное числовое представление этих наблюдений. | Какое значение имеет функция агрегирования F для данного набора S наблюдений данных? | - Какая в среднем калорийность злаков Post? - Каков валовой доход всех магазинов вместе взятых? - Сколько сейчас производителей автомобилей? |
| 4 | Найти экстремум | Найти случаи данных, обладающие экстремальным значением атрибута в пределах его диапазона в наборе данных. | Каковы верхние / нижние N случаев данных по отношению к атрибуту A? | - Какой автомобиль с самым высоким MPG? - Какой режиссер / фильм получил больше всего наград? - У какого фильма Marvel Studios самая последняя дата выхода? |
| 5 | Сортировка | Для заданного набора случаев данных ранжируйте их по некоторой порядковой метрике. | Каков порядок сортировки набора S случаев данных в соответствии с их значением атрибута A? | - Заказать автомобили по весу. - Оцените крупы по калорийности. |
| 6 | Определить диапазон | Учитывая набор вариантов данных и интересующий атрибут, найдите диапазон значений в наборе. | Каков диапазон значений атрибута A в наборе S вариантов данных? | - Какой диапазон длин пленки? - Каков диапазон мощности автомобиля? - Какие актрисы есть в наборе данных? |
| 7 | Охарактеризуйте распределение | Дайте набор вариантов данных и интересующий количественный атрибут, охарактеризуйте распределение значений этого атрибута по набору. | Каково распределение значений атрибута A в наборе S случаев данных? | - Каково распределение углеводов в злаках? - Каков возрастной состав покупателей? |
| 8 | Найти аномалии | Выявить любые аномалии в заданном наборе случаев данных в отношении заданного отношения или ожидания, например статистические выбросы. | Какие варианты данных в наборе S вариантов данных имеют неожиданные / исключительные значения? | - Существуют ли исключения из взаимосвязи между мощностью и ускорением? - Есть ли выбросы в белке? |
| 9 | Кластер | Для заданного набора вариантов данных найдите кластеры с похожими значениями атрибутов. | Какие варианты данных в наборе S вариантов данных аналогичны по значению для атрибутов {X, Y, Z,...}? | - Существуют ли группы злаков с одинаковым содержанием жира / калорий / сахара? - Есть ли скопление пленкитипичной длины? |
| 10 | Корреляция | Задав набор вариантов данных и два атрибута, определите полезные отношения между значениями этих атрибутов. | Какова корреляция между атрибутами X и Y в заданном наборе S случаев данных? | - Есть ли корреляция между углеводами и жирами? - Есть ли корреляция между страной происхождения и MPG? - Есть ли у разных половительный способ оплаты? - Есть ли тенденция увеличения продолжительности фильмов с годами? |
| 11 | Контекстуализация | Учитывая набор случаев, контекстную релевантность данных для пользователей. | Какие варианты данных в наборе S вариантов данных релевантны контексту текущего пользователя? | - Существуют ли группы ресторанов, в которых есть еда, основанная на моем текущем потреблении калорий? |
Препятствия на пути к эффективному анализу могут существовать среди аналитиков, выполняющих анализ данных или среди аудитории. Отличить факты от мнения, когнитивные предубеждения и неумелость - все это проблемы для надежного анализа данных.
анализ требует соответствующих фактов, чтобы ответить на вопросы, поддержать заключение или формальное мнение или проверить гипотезы. Факты по определению неопровержимы, а это означает, что любой человек, участвующий в них, должен иметь возможность согласиться с ними. Например, в августе 2010 года Бюджетное управление Конгресса (CBO) подсчитало, что продление налоговых сокращений Буша 2001 и 2003 годов на период 2011–2020 годов добавит примерно 3,3 триллиона долларов к долг. Каждый должен быть в состоянии согласиться с тем, что на самом деле это то, что сообщила CBO; они все могут изучить отчет. Это факт. Согласны или не согласны люди с CBO - их собственное мнение.
В качестве другого примера аудитора публичной компании должен прийти к официальному мнению о том, является ли финансовая отчетность публично торгуемых корпораций «достоверной во всех существенных отношениях». Это требует расширенного анализа фактических данных и доказательств, подтверждающих их мнение. При переходе от фактов к мнению всегда существует вероятность того, что мнение является ошибочным.
Существует множество когнитивных предубеждений, которые могут отрицательно повлиять на анализ. Например, предвзятость подтверждения - это тенденция искать или интерпретировать информацию таким образом, чтобы подтвердить предубественным образом. Кроме того, люди могут дискредитировать информацию, не подтверждающую их взгляды.
Аналитики могут быть специально обучены, чтобы знать об этих предубеждениях и способах их преодоления. В своей книге «Психология анализа интеллекта» бывший аналитик ЦРУ Ричардс Хойер написал, что аналитикам следует четко очерчивать свои предположения и цепочки умозаключений, а также указывать степень и источник неопределенности, основанные с выводами. Он делал упор на процедуры, помогающие выявлять и обсуждать альтернативные точки зрения.
Эффективные аналитики, как правило, владеют множеством численных методов. Однако аудитория может не обладать такой грамотностью в отношении цифр или навыков счета ; их называют бесчисленными. Лица, передающие данные, могут также пытаться в заблуждение или дезинформировать, используя плохие числовые методы.
Например, рост или уменьшение числа может не быть ключевым фактором. Более важным может быть число относительно другого числа, например, размер государственных доходов или расходов относительно размера экономики (ВВП) или сумма затрат относительно дохода в корпоративной финансовой отчетности. Этот численный метод называется нормализацией или общим размером. Аналитики используют множество таких методов, будь то поправка на инфляцию (т. Е. Сравнение реальных и номинальных данных) или с учетом роста населения, демографии и т. Д. Аналитики применяют различные методы обработки различных сообщений, описанных в разделе выше.
Аналитики также могут анализировать данные при различных предположениях или сценариях. Например, когда аналитики выполняют анализ финансовой отчетности, они часто изменяют финансовую отчетность, исходя из других допущений, чтобы помочь прийти к оценке будущего денежного потока, которую они дисконтируют до приведенной стоимости на основе некоторой процентной ставки для определения стоимости компании или ее акций. Точно так же CBO анализирует влияние различных вариантов политики на доходы, расходы и дефицит правительства, создавая альтернативные сценарии будущего для ключевых мер мер.
Для прогнозирования энергопотребления в зданиих можно использовать подход аналитики данных. Различные этапы процесса анализа данных выполняются для реализации управления и управления ресурсами здания, включая отопление, вентиляцию, кондиционирование, освещение и безопасность, выполняются автоматически, имитируя потребности пользователей и оптимизируя ресурсы. как энергия и время.
Аналитика - это «широкое использование данных, статистического и количественного анализа, пояснительных и прогнозных моделей, а также управления на основе фактов для принятия решений и действий». Это подмножество бизнес-аналитики, которое представляет собой набор технологий и процессов, использующих данные для понимания и анализа эффективности бизнеса.
 Аналитическая деятельность пользователей визуализации данных
Аналитическая деятельность пользователей визуализации данных В образовании большинство преподавателей имеют доступ к системе данных с целью анализа данных об учащихся. Эти системы данных представляют данные преподавателям в формате данных, отпускаемых без рецепта (встраивание этикеток, дополнительной и справочной системы, а также ключевых решений по упаковке / отображению и содержанию), чтобы повысить точность преподавателей. анализ данных.
Этот раздел содержит довольно технические объяснения, которые могут помочь практикам, но выходят за рамки типичного объема статьи в Википедии.
Наиболее важное различие между этапом анализа исходных данных и этапом основного анализа заключается в том, что во время анализа исходных данных человек воздерживается от любого анализа, направлен на получение ответа на исходное исследование. вопрос. На этапе первичного анализа данных руководствуются четырьмя вопросами:
Качество данных следует проверять как можно раньше. Качество данных можно использовать способами, используя различные виды анализа: подсчет частоты, описательная (среднее, стандартное отклонение, медиана), нормальность (асимметрия, экс, частотные гистограммы), n: переменные сравниваются со схемами кодирования внешних переменных. к набору и, возможно, исправлены, если схемы кодирования не сопоставимы.
Выбор анализа для оценки качества данных на этапе анализа исходных данных зависит от анализов, которые будут проводиться на этапе основного анализа.
Качество измерительных инструментов следует проверять только на этапе анализа данных, когда это не является предметом внимания или исследовательским вопросом исследования. Следует, соответствует ли структура средств измерений, проверить данную в литературе.
Есть два способа измерения: [ПРИМЕЧАНИЕ: кажется, что указан только один способ]
После оценки качества и измерений можно принять решение о вменении недостающих данных или выполнении начальных преобразований одного или нескольких чисел, хотя это также можно сделать на этапе основного анализа.. Возможные преобразования числа:
Следует проверить успешность процедуры рандомизации, например, проверив, одинаково ли распределены фоновые и основные переменные внутри и между группами.. Если в исследовании не требовалось или не использовалась процедура рандомизации, следует проверить успешность неслучайной выборки, например, путем проверки того, представлен ли в выборке все подгруппы представляющей совокупности.. Другие возможные данные следует проверить исправления:
В любом отчете или статье структура выборки должна быть точно описана.. Параметры выборки данных можно оценить, посмотрев на этапе основного анализа:
На заключительном этапе результатов первоначального анализа документируется, и необходимые, предпочтительные и возможные корректирующие действия.. Кроме того, должен быть уточнен или переписан исходный план анализа основных данных.. Для этого можно и нужно принять несколько решений относительно анализа данных:
На этапе анализа исходных данных можно использовать несколько анализов:
Важно принимать во внимание уровни измерения переменных для анального Например, для каждого уровня доступны специальные статистические методы:
Нелинейный анализ часто необходим, когда данные записываются из нелинейной системы. Нелинейные системы могут проявлять сложные динамические эффекты, включая бифуркации, хаос, гармоники и субгармоники, которые нельзя проанализировать простыми линейными методами. Нелинейный анализ данных тесно связан с идентификацией нелинейной системы.
На этапе основного анализа выполняется анализ, направленный на ответ на вопрос исследования, а также любой другой соответствующий анализ, необходимый для написания первый проект отчета об исследовании.
На этапе основного анализа может быть применен исследовательский или подтверждающий подход. Обычно подход определяется до сбора данных. В исследовательском анализе перед анализом данных не формулируется четкая гипотеза, и в данных ведется поиск моделей, которые хорошо описывают данные. В подтверждающем анализе проверяются четкие гипотезы о данных.
Исследовательский анализ данных следует интерпретировать осторожно. При одновременном тестировании нескольких моделей существует высокая вероятность при обнаружении хотя бы одного из них значимым, но это может быть связано с ошибкой типа 1. Важно всегда корректировать уровень значимости при тестировании нескольких моделей, например, с помощью поправки Бонферрони. Кроме того, не следует сопровождать исследовательский анализ подтверждающим анализом того же набора данных. Исследовательский анализ используется для поиска идей для теории, но не для проверки этой теории. Если в наборе данных обнаружена исследовательская модель, которая подтверждает подтверждающим анализом данных, том же наборе данных может просто означать, что результаты подтверждающего анализа связаны с той же ошибкой типа 1, которая привела к исследовательской модели в первую очередь. Таким образом, подтверждающий анализ не будет более информативным, чем исходный исследовательский анализ.
Важно получить представление о том, насколько обобщаем результаты результатов. Хотя это часто бывает трудно проверить, можно посмотреть на стабильность результатов. Являются ли результаты надежными и воспроизводимыми? Есть два основных способа сделать это.
Среди известных программ для анализа данных:
Различные компании или организации проводят конкурсы по анализу данных, чтобы побудить исследователей использовать свои данные или решить вопрос с помощью анализа данных. Вот несколько известных международных конкурсов по анализу данных.
| В Викиверсии есть обучающие ресурсы по Анализ данных |