Переменная, представляющая случайное явление
В вероятности и статистике, случайная величина, случайная величина, случайная переменная или стохастическая переменная неформально описывается как переменная, значения которой зависят от результатов случайное явление. Формальная математическая обработка случайных величин - тема теории вероятностей. В этом контексте под случайной величиной понимается измеримая функция, определенная в вероятностном пространстве, которая отображает пространство выборки на действительные числа.
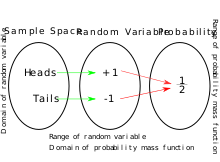
Этот график показывает, как случайная величина является функцией от всех возможных результатов до реальных значений. Он также показывает, как случайная величина используется для определения функций вероятности и массы.
Возможные значения случайной величины могут представлять возможные результаты еще не проведенного эксперимента или возможные результаты прошлого эксперимента, который уже существовал. значение является неопределенным (например, из-за неточных измерений или квантовой неопределенности ). Они также могут концептуально представлять либо результаты «объективно» случайного процесса (такого как бросание кубика), либо «субъективную» случайность, являющуюся результатом неполного знания величины. Значение вероятностей, приписываемых потенциальным значениям случайной величины, не является частью самой теории вероятностей, а вместо этого связано с философскими аргументами по интерпретации вероятности. Математика работает одинаково, независимо от конкретной интерпретации.
В качестве функции случайная величина должна быть измеримой, что позволяет назначать вероятности наборам ее потенциальных значений. Часто результаты зависят от некоторых физических переменных, которые нельзя предсказать. Например, при подбрасывании справедливой монеты конечный результат орла или решки зависит от неопределенных физических условий, поэтому наблюдаемый результат является неопределенным. Монета могла зацепиться за трещину в полу, но такая возможность исключается из рассмотрения.
область случайной величины называется пространством выборки. Он интерпретируется как набор возможных исходов случайного явления. Например, в случае подбрасывания монеты рассматриваются только два возможных исхода, а именно орел или решка.
Случайная величина имеет распределение вероятностей, которое определяет вероятность борелевских подмножеств ее диапазона. Случайные переменные могут быть дискретными, то есть принимать любое из указанного конечного или счетного списка значений (имеющего счетный диапазон), наделенного функцией вероятностной массы что характерно для распределения вероятностей случайной величины; или непрерывный, принимающий любое числовое значение в интервале или совокупности интервалов (имеющих неисчислимый диапазон) с помощью функции плотности вероятности, которая является характеристикой распределения вероятностей случайной величины; или их смесь.
Две случайные величины с одинаковым распределением вероятностей могут отличаться по своей связи или независимости от других случайных величин. Реализации случайной величины, то есть результаты случайного выбора значений в соответствии с функцией распределения вероятностей переменной, называются случайными переменными.
Содержание
- 1 Определение
- 1.1 Стандартный случай
- 1.2 Расширения
- 2 Функции распределения
- 3 Примеры
- 3.1 Дискретная случайная величина
- 3.1.1 Бросок монеты
- 3.1.2 Бросок кости
- 3.2 Непрерывная случайная величина
- 3.3 Смешанный тип
- 4 Теоретико-мерное определение
- 4.1 Случайные величины с действительным знаком
- 5 Моменты
- 6 Функции случайных величин
- 6.1 Пример 1
- 6.2 Пример 2
- 6.3 Пример 3
- 6.4 Пример 4
- 7 Некоторые свойства
- 8 Эквивалентность случайных величин
- 8.1 Равенство в распределении
- 8.2 Почти гарантированное равенство
- 8.3 Равенство
- 9 Сходимость
- 10 См. Также
- 11 Ссылки
- 11.1 Встроенные ссылки
- 11.2 Литература
- 12 Внешние ссылки
Определение
A случайная величина - это измеримая функция  из набора возможных результатов
из набора возможных результатов  до измеримого пространства
до измеримого пространства  . Техническое аксиоматическое определение требует, чтобы было пространством выборки тройки вероятностей
. Техническое аксиоматическое определение требует, чтобы было пространством выборки тройки вероятностей  (см. Определение из теории меры). Случайная величина часто обозначается заглавными римскими буквами, например
(см. Определение из теории меры). Случайная величина часто обозначается заглавными римскими буквами, например  ,
,  ,
,  ,
,  .
.
Вероятность того, что примет значение в измеримом наборе  записывается как
записывается как

Стандартный случай
Во многих случаях имеет вещественное значение, т. Е.  . В некоторых контекстах термин случайный элемент (см. расширения) используется для обозначения случайной величины не этой формы.
. В некоторых контекстах термин случайный элемент (см. расширения) используется для обозначения случайной величины не этой формы.
Когда изображение (или диапазон) является счетным, случайная величина называется дискретная случайная величина, и ее распределение является дискретным распределением вероятностей, то есть может быть описано с помощью функции массы вероятности, которая присваивает вероятность каждому значению в изображении . Если изображение бесконечно бесконечно (обычно это интервал ), то называется непрерывной случайной величиной . В частном случае, когда это абсолютно непрерывный, его распределение может быть описано с помощью функции плотности вероятности, которая присваивает вероятности интервалам; в частности, каждая отдельная точка обязательно должна иметь нулевую вероятность для абсолютно непрерывной случайной величины. Не все непрерывные случайные величины абсолютно непрерывны, распределение смеси является одним из таких контрпримеров; такие случайные величины не могут быть описаны плотностью вероятности или функцией массы вероятности.
Любая случайная величина может быть описана ее кумулятивной функцией распределения, которая описывает вероятность того, что случайная величина будет меньше или равна определенному значению.
Расширения
Термин «случайная величина» в статистике традиционно ограничивается случаем вещественных значений (). В этом случае структура действительных чисел позволяет определять такие величины, как ожидаемое значение и дисперсия случайной величины, ее кумулятивная функция распределения, и моменты его распределения.
Однако приведенное выше определение действительно для любого измеримого пространства значений. Таким образом, можно рассматривать случайные элементы других наборов , например случайные логические значения, категориальные значения, сложными числа, векторы, матрицы, последовательности, деревья, наборы, фигур, коллекторы и функции. Затем можно конкретно указать случайную переменную типа type или -значная случайная величина.
Эта более общая концепция случайного элемента особенно полезна в таких дисциплинах, как теория графов, машинное обучение, естественный язык. обработка и другие области в дискретной математике и информатике, где часто интересуют моделирование случайных вариаций нечисловых структур данных. В некоторых случаях, тем не менее, удобно представлять каждый элемент , используя одно или несколько действительных чисел. В этом случае случайный элемент может дополнительно быть представлен как вектор вещественных случайных величин (все они определены в одном и том же базовом вероятностном пространстве , что позволяет различным случайным величинам коварировать ). Например:
- Случайное слово может быть представлено как случайное целое число, которое служит индексом в словаре возможных слов. В качестве альтернативы его можно представить как случайный индикаторный вектор, длина которого равна размеру словаря, где единственными значениями положительной вероятности являются
 ,
,  ,
,  , а позиция 1 указывает слово.
, а позиция 1 указывает слово. - Случайное предложение заданной длины
 может быть представлен как вектор из случайных слов.
может быть представлен как вектор из случайных слов. - A случайный граф на заданном вершины могут быть представлены как матрица случайных величин
 , значения которой задают матрицу смежности случайного графа.
, значения которой задают матрицу смежности случайного графа. - A случайная функция
 может быть представлена как набор случайных величин
может быть представлена как набор случайных величин  , задавая значения функции при различных s указывает
, задавая значения функции при различных s указывает  в области определения функции. - обычные случайные величины с действительным знаком при условии, что функция является действительной. Например, случайный процесс является случайной функцией времени, случайный вектор - случайной функцией некоторого набора индексов, например
в области определения функции. - обычные случайные величины с действительным знаком при условии, что функция является действительной. Например, случайный процесс является случайной функцией времени, случайный вектор - случайной функцией некоторого набора индексов, например  и random field представляет собой случайную функцию для любого набора (обычно времени, пространства или дискретного набора).
и random field представляет собой случайную функцию для любого набора (обычно времени, пространства или дискретного набора).
Функции распределения
Если случайная величина  определена в вероятностном пространстве задано, мы можем задать такие вопросы, как "Насколько вероятно, что значение равно 2? ". Это то же самое, что вероятность события
определена в вероятностном пространстве задано, мы можем задать такие вопросы, как "Насколько вероятно, что значение равно 2? ". Это то же самое, что вероятность события  , которое часто записывается как
, которое часто записывается как  или
или  для краткости.
для краткости.
Запись всех этих вероятностей выходных диапазонов действительной случайной величины дает распределение вероятностей для . Распределение вероятностей "забывает" о конкретном вероятностном пространстве, используемом для определения , и записывает только вероятности различных значений . Такое распределение вероятностей всегда можно уловить с помощью его кумулятивной функции распределения

, а также иногда с использованием функции плотности вероятности,  . В терминах теории меры мы используем случайную величину , чтобы «продвинуть» меру
. В терминах теории меры мы используем случайную величину , чтобы «продвинуть» меру  на до меры на
на до меры на  . Базовое вероятностное пространство - это техническое устройство, используемое для гарантии существования случайных величин, иногда для их построения, и для определения таких понятий, как корреляция и зависимость. или независимость на основе совместного распределения двух или более случайных величин в одном вероятностном пространстве. На практике часто пространство полностью удаляется и просто ставится мера на , который присваивает меру 1 всей действительной прямой, т. е. работает с распределениями вероятностей вместо случайных величин. См. Статью о функциях квантилей для более полной разработки.
. Базовое вероятностное пространство - это техническое устройство, используемое для гарантии существования случайных величин, иногда для их построения, и для определения таких понятий, как корреляция и зависимость. или независимость на основе совместного распределения двух или более случайных величин в одном вероятностном пространстве. На практике часто пространство полностью удаляется и просто ставится мера на , который присваивает меру 1 всей действительной прямой, т. е. работает с распределениями вероятностей вместо случайных величин. См. Статью о функциях квантилей для более полной разработки.
Примеры
Дискретная случайная величина
В эксперименте человек может быть выбран случайным образом, и одной случайной величиной может быть рост человека. Математически случайная величина интерпретируется как функция, которая сопоставляет человека с ростом человека. Со случайной величиной связано распределение вероятностей, которое позволяет вычислить вероятность того, что высота находится в любом подмножестве возможных значений, таких как вероятность того, что высота составляет от 180 до 190 см, или вероятность того, что высота либо меньше более 150 или более 200 см.
Другой случайной величиной может быть количество детей человека; это дискретная случайная величина с неотрицательными целыми числами. Он позволяет вычислять вероятности для отдельных целочисленных значений - функции массы вероятности (PMF) - или для наборов значений, включая бесконечные наборы. Например, интересующим событием может быть «четное количество детей». Как для конечных, так и для бесконечных наборов событий их вероятности могут быть найдены путем сложения PMF элементов; то есть вероятность четного числа детей равна бесконечной сумме  .
.
В таких примерах, как эти, пространство выборки часто подавляется, так как это математически сложно описать, а возможные значения случайных величин затем рассматриваются как пространство выборки. Но когда две случайные величины измеряются в одном и том же пространстве выборки результатов, например, рост и количество детей, вычисляемых для одних и тех же случайных людей, легче отслеживать их взаимосвязь, если признается, что приходят и рост, и количество детей. от одного и того же случайного человека, например, чтобы можно было задать вопросы о том, коррелированы ли такие случайные величины или нет.
Если  - счетные наборы действительных чисел,
- счетные наборы действительных чисел,  и
и  , затем
, затем  - дискретная функция распределения. Здесь
- дискретная функция распределения. Здесь  для
для
Подбрасывание монеты
Возможные результаты для одного подбрасывание монеты можно описать пробелом  . Мы можем ввести случайную величину с действительным знаком , которая моделирует выплату в 1 доллар за успешную ставку на решку следующим образом:
. Мы можем ввести случайную величину с действительным знаком , которая моделирует выплату в 1 доллар за успешную ставку на решку следующим образом:
![{\ displaystyle Y (\ omega) = {\ begin {cases} 1, {\ text {if}} \ omega = {\ text {Heads}}, \\ [6pt] 0, {\ text {if}} \ omega = {\ text {tails}}. \ end {cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2d200c2fc4177e66d480e649540dd91347a4b0be)
Если монета является честной монетой, Y имеет функцию массы вероятности  определяется выражением:
определяется выражением:
![{\ displaystyle f_ {Y} (y) = {\ begin {case} {\ tfrac {1} {2}}, {\ text {if}} y = 1, \\ [6pt] {\ tfrac {1 } {2}}, {\ text {if}} y = 0, \ end {cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dc8892016fc9589bd86b7845a45d4882dddbbada)
Бросок кубиков

Если пробел представляет собой набор возможных чисел, брошенных на двух кубиках, и интересующая случайная величина представляет собой сумму S чисел на двух игральных костях, тогда S представляет собой дискретную случайную величину, распределение которой описывается функцией массы вероятности , построенной здесь как высота столбцов изображения.
Случайная величина может также может использоваться для описания процесса бросания игральных костей и возможных результатов. Наиболее очевидное представление для случая двух игральных костей - взять набор пар чисел n 1 и n 2 из {1, 2, 3, 4, 5, 6} (представляющие числа на двух кубиках) как пробел. Общее количество выпавших чисел (сумма чисел в каждой паре) тогда является случайной величиной X, заданной функцией, которая преобразует пару в сумму:

и (если кости справедливые ) имеет вероятностную массу функция ƒ X определяется как:

Непрерывная случайная величина
Формально непрерывная случайная величина - это случайная величина, чья кумулятивная функция распределения везде непрерывна. Нет «пробелов », которые соответствовали бы числам, которые имеют конечную вероятность появления. Вместо этого непрерывные случайные величины почти никогда не принимают точно заданное значение c (формально  ), но существует положительная вероятность того, что его значение будет лежать в определенных интервалах, которые могут быть сколь угодно малыми. Непрерывные случайные величины обычно допускают функции плотности вероятности (PDF), которые характеризуют их CDF и меры вероятности ; такие распределения также называются абсолютно непрерывными ; но некоторые непрерывные распределения являются сингулярным или сочетанием абсолютно непрерывной части и особой части.
), но существует положительная вероятность того, что его значение будет лежать в определенных интервалах, которые могут быть сколь угодно малыми. Непрерывные случайные величины обычно допускают функции плотности вероятности (PDF), которые характеризуют их CDF и меры вероятности ; такие распределения также называются абсолютно непрерывными ; но некоторые непрерывные распределения являются сингулярным или сочетанием абсолютно непрерывной части и особой части.
Примером непрерывной случайной величины может служить счетчик, который может выбирать горизонтальное направление. Тогда значения, принимаемые случайной величиной, являются направлениями. Мы могли бы представить эти направления в виде севера, запада, востока, юга, юго-востока и т. Д. Однако обычно удобнее сопоставить пространство выборки со случайной величиной, которая принимает значения, которые являются действительными числами. Это можно сделать, например, сопоставив направление с пеленгом в градусах по часовой стрелке от севера. Затем случайная переменная принимает значения, которые являются действительными числами из интервала [0, 360), причем все части диапазона «равновероятны». В этом случае X = угол поворота. Любое действительное число имеет нулевую вероятность быть выбранным, но положительная вероятность может быть присвоена любому диапазону значений. Например, вероятность выбора числа в [0, 180] составляет ⁄ 2. Вместо того чтобы говорить о функции массы вероятности, мы говорим, что плотность вероятности X равна 1/360. Вероятность подмножества [0, 360) может быть вычислена путем умножения меры набора на 1/360. В общем, вероятность набора для данной непрерывной случайной величины может быть вычислена путем интегрирования плотности по данному набору.
Более формально, для любого интервала ![{\ textstyle I = [a, b] = \ {x \ in \ mathbb {R}: a \ leq x \ leq b \}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6a291b85e1772a1749a65c841769efcec2931376) , случайная величина
, случайная величина ![{\ displaystyle X_ {I} \ sim \ operatorname {U} (I) = \ operatorname {U} [a, b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e796af5f27ecaec3fdf010383da162a4d29ea04d) называется «непрерывной однородной случайной величиной» (CURV), если вероятность того, что он принимает значение в подынтервале , зависит только от длины подынтервала. Это означает, что вероятность того, что
называется «непрерывной однородной случайной величиной» (CURV), если вероятность того, что он принимает значение в подынтервале , зависит только от длины подынтервала. Это означает, что вероятность того, что  попадет в любой подинтервал
попадет в любой подинтервал ![{\ displaystyle [c, d] \ substeq [a, b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/32c4b90060cfad2522da60caeab608de43226f6e) пропорционально длине подынтервала, то есть, если a ≤ c ≤ d ≤ b, у него
пропорционально длине подынтервала, то есть, если a ≤ c ≤ d ≤ b, у него
![{\ Displaystyle \ Pr \ le ft (X_ {I} \ in [c, d] \ right) = {\ frac {dc} {ba}} \ Pr \ left (X_ {I} \ in I \ right) = {\ frac {dc} { ba}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5eb5ff901ae3292273a3c9b43745abceadf82ca9)
где последнее равенство является результатом аксиома унитарности вероятности. Дается функция плотности вероятности кривой ![{\ displaystyle X \ sim \ operatorname {U} [a, b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8a2c5c9c387a71f6b8511c8360740aed05476755) индикаторной функцией своего интервала поддержки, нормированного на длину интервала:
индикаторной функцией своего интервала поддержки, нормированного на длину интервала:

Особый интерес представляет равномерное распределение на
единичном интервале ![[0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)
. Образцы любого желаемого
распределения вероятностей 
могут быть созданы путем вычисления
функции квантиля для
на
случайно сгенерированном числе, равномерно распределенном на единичном интервале. При этом используются свойства
кумулятивных функций распределения, которые являются объединяющей структурой для всех случайных величин.
Смешанный тип
A смешанная случайная величина - это случайная величина, кумулятивная функция распределения которой не является ни кусочно-постоянной (дискретная случайная величина), ни везде -непрерывный. Его можно реализовать как сумму дискретной случайной величины и непрерывной случайной величины; в этом случае CDF будет средневзвешенным значением CDF компонентных переменных.
Пример случайной переменной смешанного типа будет основан на эксперименте, в котором подбрасывается монета и вертушка вращается только в том случае, если в результате подбрасывания монеты выпали решки. Если результат - решка, X = -1; в противном случае X = значение счетчика, как в предыдущем примере. Существует вероятность ⁄ 2 того, что эта случайная величина будет иметь значение -1. Другие диапазоны значений будут иметь половину вероятностей последнего примера.
В большинстве случаев каждое распределение вероятностей на действительной прямой представляет собой смесь дискретной части, единственной части и абсолютно непрерывной части; см. теорему Лебега о разложении § Уточнение. Дискретная часть сосредоточена на счетном множестве, но это множество может быть плотным (как множество всех рациональных чисел).
Теоретико-мерное определение
Наиболее формальное, аксиоматическое определение случайной величины связано с теорией меры. Непрерывные случайные переменные определяются с помощью наборов чисел, а также функций, которые отображают такие наборы на вероятности. Из-за различных трудностей (например, парадокса Банаха – Тарского ), которые возникают, если такие множества недостаточно ограничены, необходимо ввести так называемую сигма-алгебру для ограничения возможных множеств. по которым могут быть определены вероятности. Обычно используется такая особая сигма-алгебра, борелевская σ-алгебра, которая позволяет определять вероятности для любых наборов, которые могут быть получены либо непосредственно из непрерывных интервалов чисел, либо с помощью конечного или счетно бесконечное число объединений и / или пересечений таких интервалов.
Теоретико-мерное определение выглядит следующим образом.
Пусть  будет вероятностным пространством и
будет вероятностным пространством и  a измеримое пространство. Тогда -значная случайная величина является измеримой функцией , что означает, что для каждого подмножества
a измеримое пространство. Тогда -значная случайная величина является измеримой функцией , что означает, что для каждого подмножества  , его прообраз
, его прообраз  где
где  . Это определение позволяет нам измерить любое подмножество в целевом пространстве, глядя на его прообраз, который по предположению измерим.
. Это определение позволяет нам измерить любое подмножество в целевом пространстве, глядя на его прообраз, который по предположению измерим.
В более интуитивных терминах член является возможным результатом, членом  - измеримое подмножество возможных результатов, функция дает вероятность каждого такого измеримого подмножества, представляет набор значений, которые может принимать случайная величина (например, набор действительных чисел), и член
- измеримое подмножество возможных результатов, функция дает вероятность каждого такого измеримого подмножества, представляет набор значений, которые может принимать случайная величина (например, набор действительных чисел), и член  - это «хорошо управляемое» (измеримое) подмножество (тех, для которых может быть определена вероятность). Тогда случайная величина представляет собой функцию от любого результата к количеству, так что результаты, ведущие к любому полезному подмножеству величин для случайной величины, имеют четко определенную вероятность.
- это «хорошо управляемое» (измеримое) подмножество (тех, для которых может быть определена вероятность). Тогда случайная величина представляет собой функцию от любого результата к количеству, так что результаты, ведущие к любому полезному подмножеству величин для случайной величины, имеют четко определенную вероятность.
Когда является топологическим пространством, тогда наиболее распространенным выбором является σ-алгебра - это борелевская σ-алгебра  , которая представляет собой σ-алгебру, сгенерированную совокупностью всех открытых множеств в . В таком случае случайная величина со значением называется -значная случайная величина . Более того, когда пробел является действительной линией , тогда такой вещественный случайная величина называется просто случайной величиной .
, которая представляет собой σ-алгебру, сгенерированную совокупностью всех открытых множеств в . В таком случае случайная величина со значением называется -значная случайная величина . Более того, когда пробел является действительной линией , тогда такой вещественный случайная величина называется просто случайной величиной .
случайными величинами с действительными значениями
В этом случае пространство наблюдения - это набор действительных чисел. Напомним, - это вероятностное пространство. Для реального пространства наблюдения функция  является случайной величиной с действительным знаком, если
является случайной величиной с действительным знаком, если

Это определение является частным случаем из вышеперечисленного, поскольку набор ![\ {(- \ infty, r ]: р \ in \ mathbb {R} \}](https://wikimedia.org/api/rest_v1/media/math/render/svg/70d40dbc8dd41bbe90d6242042f72e62bafea8f9) порождает борелевскую σ-алгебру на множестве действительных чисел, и достаточно проверить измеримость на любом порождающем множестве. Здесь мы можем доказать измеримость на этом порождающем множестве, используя тот факт, что
порождает борелевскую σ-алгебру на множестве действительных чисел, и достаточно проверить измеримость на любом порождающем множестве. Здесь мы можем доказать измеримость на этом порождающем множестве, используя тот факт, что ![\ {\ omega: X (\ omega) \ leq r \} = X ^ {- 1} ((- \ infty, r ])](https://wikimedia.org/api/rest_v1/media/math/render/svg/967b79350e615a40cee0dd0102fee55bfb3c5d3d) .
.
Моменты
Распределение вероятностей случайной величины часто характеризуется небольшим количеством параметров, которые также имеют практическую интерпретацию.Например, часто достаточно знать, каково ее «среднее значение». Это зафиксировано математической концепцией ожидаемого значения случайной величины, обозначаемой ![\ operatorname {E} [X]](https://wikimedia.org/api/rest_v1/media/math/render/svg/44dd294aa33c0865f58e2b1bdaf44ebe911dbf93) , и также называется первый момент. В общем,
, и также называется первый момент. В общем, ![{\ displaystyle \ operatorname {E} [f (X)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c407e0dfff7f7d09b8a81f9ccc2f078bffa783ea) не равно
не равно ![{\ displaystyle f (\ operatorname {E} [X])}](https://wikimedia.org/api/rest_v1/media/math/render/svg/358c53d63b891b58814383d8beba46f69695632f) . Как только "среднее значение" известно, можно спросить, насколько далеко от этого среднего значения обычно находятся значения , вопрос, на который отвечает дисперсия и стандартное отклонение случайной величины. можно интуитивно рассматривать как среднее значение, полученное из бесконечной совокупности, члены которой являются частными оценками .
. Как только "среднее значение" известно, можно спросить, насколько далеко от этого среднего значения обычно находятся значения , вопрос, на который отвечает дисперсия и стандартное отклонение случайной величины. можно интуитивно рассматривать как среднее значение, полученное из бесконечной совокупности, члены которой являются частными оценками .
Математически это известно как (обобщенная) проблема моментов : для данного класса случайных величин найдите коллекцию  таких функций, что ожидаемые значения
таких функций, что ожидаемые значения ![{\ displaystyle \ operatorname {E} [f_ { i} (X)]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0e4e5f5f0c5d751d4d1bf63dea54ff9765683a53) полностью охарактеризовать распределение случайной величины .
полностью охарактеризовать распределение случайной величины .
Моменты могут только быть определенным для действительных функций от случайных величин (или комплексных значений и т. д.). Если случайная величина сама имеет действительное значение, то могут быть взяты моменты самой переменной, которые эквивалентны моментам тождественной функции  случайной величины. Однако даже для случайных величин с ненастоящими значениями могут быть взяты моменты действительных функций этих переменных. Например, для категориальной случайной величины X, которая может принимать номинальные значения «красный», «синий» или «зеленый», функция с действительным знаком
случайной величины. Однако даже для случайных величин с ненастоящими значениями могут быть взяты моменты действительных функций этих переменных. Например, для категориальной случайной величины X, которая может принимать номинальные значения «красный», «синий» или «зеленый», функция с действительным знаком ![[X = {\ text {green}}]](https://wikimedia.org/api/rest_v1/media/math/render/svg/e41a3122d8561d29d90be48b6c1fb0f94d8e2a81) можно построить; здесь используется скобка Айверсона, и он имеет значение 1, если имеет значение «зеленый», в противном случае - 0. Затем можно определить ожидаемое значение и другие моменты этой функции.
можно построить; здесь используется скобка Айверсона, и он имеет значение 1, если имеет значение «зеленый», в противном случае - 0. Затем можно определить ожидаемое значение и другие моменты этой функции.
Функции случайных величин
Новая случайная величина Y может быть определена с помощью применения действительной измеримой по Борелю функции  к результатам вещественной случайной величины . То есть
к результатам вещественной случайной величины . То есть  . кумулятивная функция распределения для тогда равна
. кумулятивная функция распределения для тогда равна

Если функция  обратима ( т.е. существует
обратима ( т.е. существует  , где
, где  равно 's обратная функция ) и либо увеличивается, либо уменьшается, тогда предыдущее отношение может быть расширено для получения
равно 's обратная функция ) и либо увеличивается, либо уменьшается, тогда предыдущее отношение может быть расширено для получения

С помощью те же гипотезы обратимости , предполагая также дифференцируемость, связь между функциями плотности вероятности может быть найдена путем дифференцирования обоих стороны приведенного выше выражения по отношению к  , чтобы получить
, чтобы получить

Если нет обратимости , но каждый допускает не более чем счетное количество корней ( то есть конечное или счетное бесконечное число  таких, что
таких, что  ), то предыдущая связь между функциями плотности вероятности может быть обобщена с помощью
), то предыдущая связь между функциями плотности вероятности может быть обобщена с помощью

где  , согласно теореме об обратной функции. Формулы для плотностей не требуют увеличения .
, согласно теореме об обратной функции. Формулы для плотностей не требуют увеличения .
В теории измерения, аксиоматический подход к вероятности, если случайная величина на и измеримая функция по Борелю , тогда также является случайной величиной на , поскольку композиция измеримых функций также измерима. (Однако это не обязательно верно, если измеримо по Лебегу.) Та же процедура, которая позволила выйти из вероятностного пространства  до
до  можно использовать для получения распределения .
можно использовать для получения распределения .
Пример 1
Пусть будет действительным -значная, непрерывная случайная величина и пусть  .
.

Если  , то
, то  , поэтому
, поэтому

If  , тогда
, тогда

поэтому

Пример 2
Предположим, - случайная величина с кумулятивным распределением

где  - фиксированный параметр. Рассмотрим случайную величину
- фиксированный параметр. Рассмотрим случайную величину  Тогда
Тогда

Последнее выражение может быть вычислено в терминах кумулятивного распределения  итак
итак
![{\ displaystyle {\ begin {align} F_ {Y} (y) = 1-F_ {X} (- \ log (e ^ {y} -1)) \\ [5pt ] = 1 - {\ frac {1} {(1 + e ^ {\ log (e ^ {y} -1)}) ^ {\ theta}}} \\ [5pt] = 1 - {\ frac {1} {(1 + e ^ {y} -1) ^ {\ theta}}} \\ [5pt] = 1-e ^ {- y \ theta}. \ End {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f4909911022c68c07e09a3cd4722e9c60b62a4f3)
что является кумулятивным распределением функция (CDF) экспоненциального распределения.
Пример 3
Предположим, что - случайная величина с стандартное нормальное распределение, плотность которого равна

Рассмотрим случайную величину  Мы можем найти плотность, используя приведенную выше формулу для замены переменных:
Мы можем найти плотность, используя приведенную выше формулу для замены переменных:

В этом случае изменение не монотонно, потому что каждое значение имеет два соответствующих значения (одно положительное и отрицательное). Однако из-за симметрии обе половины будут преобразовываться одинаково, т.е.

Обратное преобразование:

и его производная равна

Тогда

Это распределение хи-квадрат с одним степень свободы.
Пример 4
Предположим, - случайная величина с нормальным распределением, плотность которой равна

Рассмотрим случайную величину Мы можем найти плотность, используя приведенную выше формулу для замены переменных:
В этом случае изменение не монотонное, потому что каждое значение имеет два соответствующих значения (одно положительное и отрицательное). В отличие от предыдущего примера, в этом случае, однако, нет симметрии, и мы должны вычислить два различных члена:

Обратное преобразование:

и его производная

Тогда

Это нецентральное распределение хи-квадрат с одной степенью свободы.
Некоторые свойства
- Вероятностное распределение суммы двух независимых случайных величин представляет собой свертку каждого из их распределений.
- Распределения вероятностей не являются векторным пространством - они не замыкаются под линейными комбинациями, поскольку они не сохраняют неотрицательность или полный интеграл 1 - но они закрываются под выпуклой комбинацией, таким образом образуя выпуклое подмножество пространства функций (или мер).
Эквивалентность случайных величин
Существует несколько различных смыслов, в которых случайные величины могут считаться эквивалентными. Две случайные величины могут быть равными, почти наверняка или равными по распределению.
В порядке возрастания силы точное определение этих понятий эквивалентности дается ниже.
Равенство в распределении
Если пространство выборки является подмножеством вещественной линии, случайные величины X и Y равны в распределении (обозначается  ), если они имеют одинаковые функции распределения:
), если они имеют одинаковые функции распределения:

Чтобы быть равными в распределении, случайные величины нет необходимости определять в одном и том же вероятностном пространстве. Две случайные величины, имеющие равные производящие функции момента, имеют одинаковое распределение. Это обеспечивает, например, полезный метод проверки равенства некоторых функций независимых, одинаково распределенных (IID) случайных величин. Однако функция создания момента существует только для распределений, которые имеют определенное преобразование Лапласа.
Почти наверняка равенство
Две случайные величины X и Y равны почти наверняка (обозначено  ) тогда и только тогда, когда вероятность того, что они различны, равна ноль :
) тогда и только тогда, когда вероятность того, что они различны, равна ноль :

Для всех практических целей теории вероятностей это понятие эквивалентности так же сильно, как фактическое равенство. Ему соответствует следующее расстояние:

где "ess sup" представляет существенную верхнюю грань в смысле теории меры.
Равенство
Наконец, две случайные величины X и Y равны, если они равны как функции на их измеримом пространстве :

Это понятие обычно наименее полезно в теории вероятностей, поскольку на практике и в теории лежащее в основе пространство измерений в эксперименте редко описывается явным образом или даже может быть охарактеризовано.
Сходимость
Важной темой математической статистики является получение результатов сходимости для определенных последовательностей случайных величин; например, закон больших чисел и центральная предельная теорема.
. Существуют различные смыслы, в которых последовательность  случайных величин может сходиться к случайной величине . Они объясняются в статье о сходимости случайных величин.
случайных величин может сходиться к случайной величине . Они объясняются в статье о сходимости случайных величин.
См. Также
 Математический портал
Математический портал
Ссылки
Встроенные цитаты
Литература
Внешние ссылки

 Этот график показывает, как случайная величина является функцией от всех возможных результатов до реальных значений. Он также показывает, как случайная величина используется для определения функций вероятности и массы.
Этот график показывает, как случайная величина является функцией от всех возможных результатов до реальных значений. Он также показывает, как случайная величина используется для определения функций вероятности и массы.  Если пробел представляет собой набор возможных чисел, брошенных на двух кубиках, и интересующая случайная величина представляет собой сумму S чисел на двух игральных костях, тогда S представляет собой дискретную случайную величину, распределение которой описывается функцией массы вероятности , построенной здесь как высота столбцов изображения.
Если пробел представляет собой набор возможных чисел, брошенных на двух кубиках, и интересующая случайная величина представляет собой сумму S чисел на двух игральных костях, тогда S представляет собой дискретную случайную величину, распределение которой описывается функцией массы вероятности , построенной здесь как высота столбцов изображения.