Распределение вероятностей
БетаФункция плотности вероятности  |
Кумулятивная функция распределения 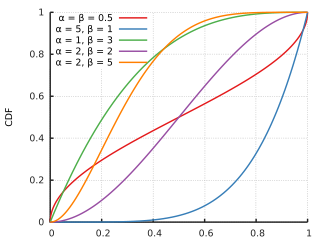 |
| Обозначение | Бета (α, β) |
|---|
| Параметры | α>0 форма (действительная ). β>0 форма (реальный ) |
|---|
| Поддержка | ![{\ displaystyle x \ in [0,1] \!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/09601f74a28f3e2cad381be1a915ab0c02fe39c6) или или  |
|---|
| PDF |  . где . где  и и  - это Гамма-функция. - это Гамма-функция. |
|---|
| CDF | 
(регуляризованная неполна я бета-функция ) |
|---|
| Среднее | ![\ operatorname {E} [X] = \ frac {\ alpha} {\ alpha + \ beta} \!](https://wikimedia.org/api/rest_v1/media/math/render/svg/3905662ceed484cba5580951e29eda96f4d2605e) . . ![\ operatorname {E} [\ ln X] = \ psi (\ alpha) - \ psi (\ alpha + \ beta) \!](https://wikimedia.org/api/rest_v1/media/math/render/svg/de67df996fa33237ab7f415e7edc9fa8e71997a0) .. .. ![{\ displaystyle \ operatorname {E} [X \, \ ln X] = {\ frac {\ alpha} {\ alpha + \ beta}} \, \ left [\ psi (\ alpha +1) - \ psi (\ alpha + \ beta +1) \ right] \!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/50106a787db7d72ce3066a5a3238813cffebcc2e) . (см. функция дигаммы и раздел: Геометрический средний) . (см. функция дигаммы и раздел: Геометрический средний) |
|---|
| Медиана | ![\begin{matrix}I_{\frac{1}{2}}^{[-1]}(\alpha,\beta)\text{ (in general) }\\[0.5em] \approx \frac{ \alpha - \tfrac{1}{3} }{ \alpha + \beta - \tfrac{2}{3} }\text{ for }\alpha, \beta>1 \ end {matrix}]( https: // wikimedia.org/api/rest_v1/media/math/render/svg/ af887ef0331cde970dad14ad670cf3592334f845 ) |
|---|
| Режим |  для α, β>1 для α, β>1
любое значение в  для α, β = 1 для α, β = 1
{0, 1} (бимодальный) для α, β < 1
0 для α ≤ 1, β>1 1 для α>1, β ≤ 1 |
|---|
| Дисперсия | ![\ operatorname {var} [X] = \ frac {\ alpha \ beta} {(\ альфа + \ бета) ^ 2 (\ альфа + \ бета + 1)} \!](https://wikimedia.org/api/rest_v1/media/math/render/svg/f90a6ad61b4b436749ca37a6c2a1aa077b032ce3) . . ![\ operatorname {var} [\ ln X] = \ psi_1 (\ alpha) - \ psi_1 (\ alpha + \ beta) \!](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4941f45412823abd34d3befea7f8fbf544135e4) . (см. тригамма-функция и раздел: Геометрическая дисперсия) . (см. тригамма-функция и раздел: Геометрическая дисперсия) |
|---|
| Асимметрия |  |
|---|
| Пример. эксцесс | ![\ frac {6 [(\ alpha - \ beta) ^ 2 (\ alpha + \ beta + 1) - \ alpha \ beta (\ альфа + \ бета + 2)]} {\ альфа \ бета (\ альфа + \ бета + 2) (\ альфа + \ бета + 3)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eea65a8d7c9e00ba6299b727eab679117776f41e) |
|---|
| Энтропия | ![\ begin {matrix} \ ln \ Beta (\ alpha, \ beta) - (\ alpha-1) \ psi (\ alpha) - (\ beta- 1) \ psi (\ beta) \\ [0.5em] + (\ alpha + \ beta-2) \ psi (\ alpha + \ beta) \ end {matrix}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4c89e36ccbf7522eba17d6e5ddb267e7cef46b8e) |
|---|
| MGF |  |
|---|
| CF |  (см. конфлюэнтная гипергеометрическая функция ) (см. конфлюэнтная гипергеометрическая функция ) |
|---|
| информация Фишера | ![{\ displaystyle {\ begin {bmatrix} \ operatorname {var} [\ ln X] \ operatorname {cov} [\ ln X, \ ln (1-X)] \\\ operatorname {cov} [\ ln X, \ ln (1-X)] \ operatorname {var} [\ ln (1-X)] \ end {bmatrix}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/881f91af0ab1d6bf3809a4ed6ca9e6384544292f) . см. раздел: информационная матрица Фишера . см. раздел: информационная матрица Фишера |
|---|
| Метод моментов | ![{\ displaystyle \ alpha = \ left ({\ frac {E [X] (1-E [X])} {V [X]}} - 1 \ right) E [X ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d2b596a180ef813a0baa1d6f2063950e20da1f62) . . ![{\ displaystyle \ beta = \ left ({\ frac {E [X] (1-E [X ])} {V [X]}} - 1 \ right) (1-E [X])}](https://wikimedia.org/api/rest_v1/media/math/render/svg/05ace15e23f6ac9be43eea861f44c018fd3d00de) |
|---|
В теории вероятностей и статистика, бета-распределение представляет собой семейство непрерывных распределений вероятностей, определенные на интервале [0, 1] , параметры двумя положительными определены, обозначаемые α и β, которые появляются как показатели случайной величины и управляют распределением. Обобщение на несколько величин называется распределением Дирихле.
Бета-распределение было применено для моделирования поведения случайных величин, ограниченных интервалами конечной длины в широком спектре дисциплин.
В байесовском выводе бета-распределение представляет собой сопряженное априорное распределение вероятностей для Бернулли, биномиального, отрицательное биномиальное <708ное>и геометрическое распределения. Бета-модель является подходящей моделью для случайного поведения и пропорций.
Обсуждаемая здесь формулировка бета-распределения также известна как бета-распределение первого типа, тогда как бета-распределение второго типа является альтернативным названием для бета-простого распределения.
Содержание
- 1 Определения
- 1.1 Функция вероятности плотности
- 1.2 Кумулятивная функция распределения
- 1.3 Альтернативные параметры распределения
- 1.3.1 Два параметра
- 1.3.1.1 Среднее и размер выборки
- 1.3.1.2 Режим и свойство
- 1.3.1.3 Среднее значение (частота аллелей) и генетическое расстояние (Райта) между двумя популяциями
- 1.3.1.4 Среднее значение и дисперсия
- 1.3.2 Четыре параметра
- 2 Свойства
- 2.1 Меры центральной тенденции
- 2.1.1 Мода
- 2.1.2 Медиана
- 2.1.3 Среднее
- 2.1.4 Среднее геометрическое
- 2.1.5 Гармоническое среднее
- 2.2 Меры статистическая дисперсия
- 2.2.1 Дисперсия
- 2.2.2 Геометрическая дисперсия и ковариация
- 2.2.3 Средн ее абсолютное отклонение около среднего
- 2.2.4 Средняя абсолютная разница
- 2. 3 Асимметрия
- 2.4 эксцесс
- 2.5 Характеристическая функция
- 2.6 Другие моменты
- 2.6.1 Производящая функция момента
- 2.6.2 Высшие моменты
- 2.6.3 Моменты преобразованных случайных величин
- 2.6.3.1 Моменты линейно преобразованных, произведенных и инвертированных случайных величин
- 2.6.3.2 Моменты логарифмически преобразованных случайных величин
- 2.7 Количество информации (энтропия)
- 2.8 Взаимосвязи между статистическими показателями
- 2.8.1 Среднее, мода и медианное соотношение
- 2.8.2 Среднее, ограниченное среднее и гармоническое среднее соотношение
- 2.8.3 эксцесс, ограниченный квадратом асимметрии
- 2.9 Симметрия
- 2.10 Геометрия функции плотности вероятности
- 2.10.1 Точки перегиба
- 2.10.2 Формы
- 2.10.2.1 Симметричные (α = β)
- 2.10.2.2 Перекос (α ≠ β)
- 3 Связанные распределения
- 3.1 Преобразования
- 3.2 Особые и предельные случаи
- 3.3 Получено из других распределений
- 3.4 Комбинация с другими дистрибутивами
- 3.5 Составление с другими распределителями
- 3.6 Обобщения
- 4 Статистический вывод
- 4.1 Оценка параметров
- 4.1.1 Метод моментов
- 4.1.1.1 Два неизвестных других
- 4.1.1.2 Четыре неизвестных параметра
- 4.1.2 Максимальное правдоподобие
- 4.1.2.1 Два неизвестных параметра
- 4.1.2.2 Четыре неизвестных параметра
- 4.1.3 Информационная матрица Fisher
- 4.1.3.1 Два руководства
- 4.1.3.2 Четыре параметра
- 4.2 Байесовский вывод
- 4.2.1 Правило следовать
- 4.2.2 Байесовская априорная вероятность (бета (1,1))
- 4.2.3 Априорная вероятность Холдейна ( бета (0,0))
- 4.2.4 Априорная вероятность Джеффриса (бета (1 / 2,1 / 2) для распределения Бернулли или биномиального распределения)
- 4.2.5 Влияние различных вариантов априорной вероятности на апостериорное бета-распределение
- 5 Возникновение и приложения
- 5.1 Статистика заказов
- 5.2 Субъективная логика
- 5.3 Вейвлет-анализ
- 5.4 Управление проектом: моделирование затрат и расписания
- 6 Вычислительные методы
- 6.1 Генерация бета-распределения случайные переменные
- 7 История
- 8 Ссылки
- 9 Внешние ссылки
Определения
Функция плотности вероятности

Анимация бета-распределения для различных значений его параметров.
функция плотности вероятности (pdf) бета-распределения для 0 ≤ x ≤ 1 и параметров α, β>0 представляет собой степенную функцию переменной x и его отражение (1 - x) следующим образом:
![{\displaystyle {\begin{aligned}f(x;\alpha,\beta)=\mathrm {constant} \cdot x^{\alpha -1}(1-x)^{\beta -1}\\[3pt]={\frac {x^{\alpha -1}(1-x)^{\beta -1}}{\displaystyle \int _{0}^{1}u^{\alpha -1}(1-u)^{\beta -1}\,du}}\\[6pt]={\frac {\Gamma (\alpha +\beta)}{\Gamma (\alpha)\Gamma (\beta)}}\,x^{\alpha -1}(1-x)^{\beta -1}\\[6pt]={\frac {1}{\mathrm {B} (\alpha,\beta)}}x^{\alpha -1}(1-x)^{\beta -1}\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5fc18388353b219c482e8e35ca4aae808ab1be81)
где Γ ( z) - это гамма-функция. бета-функция,  , является константой нормализации, чтобы риск, что общая вероятность равна 1. В приведенное выше уравнение x является реализацией - фактически имевшим место текущим периодом - случайного процесса X.
, является константой нормализации, чтобы риск, что общая вероятность равна 1. В приведенное выше уравнение x является реализацией - фактически имевшим место текущим периодом - случайного процесса X.
Это определение включает оба конца x = 0 и x = 1, что согласуется с определениями для других непрерывных распределений, поддерживаемых в ограниченном интервале, которые являются частными случаями бета-распределения, например распределение арксинуса , и согласуется с местами авторами, такими как N. Л. Джонсон и С. Коц. Однако включение x = 0 и x = 1 не работает для α, β < 1; accordingly, several other authors, including W. Feller, следует исключить концы x = 0 и x = 1 (так, чтобы два конца не были частями определения функции плотности) и вместо этого рассмотрите 0 < x < 1.
Несколько авторов, включая Н. Л. Джонсон и С. Коц, используйте символы p и q (вместо α и β) для параметров формы бета-распределения, напоминающие символы, традиционно используемые для параметров распределения Бернулли, потому что бета-версия распределения приближается к распределению Бернулли в пределе, когда оба варианта формы α и β приближаются к значению нуля.
Далее случайная величина X с бета-распределением параметров α и β будет обозначаться следующим образом:

Другие обозначения для бета-распределенных случайных величин, используемые в статистической литературе:  и
и  .
.
Кумулятивная функция распределения

CDF для симметричного бета-распределения в зависимости от x и α = β
CDF для искаженного бета-распределения в зависимости от x и β = 5α
кумулятивная функция распределения равна

где  - неполная бета-функция и
- неполная бета-функция и  - это регуляризованная неполная бета-функция.
- это регуляризованная неполная бета-функция.
.
Альтернативные параметры
Два параметра
Среднее и размер выборки
Бета-распределение также может быть повторно параметризовано в терминах его среднего μ (0 < μ < 1) and the addition of both shape parameters ν = α + β>0 (стр. 83). Обозначая αPosterior и βPosterior параметры апостериорного бета-распределения, полученного в результате применения теоремы Байеса к биномиальной функции правдоподобия и априорной вероятности, интерпретации обоих параметров формы как размер выборки = ν = α · Posterior + β · Апостериорная верна только для априорной вероятности Холдейна Бета (0,0). В частности, для байесовского (однородного) предшествующего бета (1,1) правильной интерпретацией будет размер выборки = α · задний + β задний - 2 или ν = (размер выборки) + 2. Конечно, для размера выборки намного больше чем 2, р азница между этими двумя априорными числами становится незначительной. (Подробнее см. Байесовский вывод.) В остальной части этой статьи ν = α + β будет называться «размером выборки», но следует помнить, строго говоря, «размер выборки» биномиальной функции правдоподобия только При использовании бета-версии Холдейна (0,0) до теоремы Байеса.
Эта параметризация может быть полезна при оценке байесовских параметров. Например, можно провести тест нескольким людям. ≤ 1), что является статистикой является среднее значение этого распределения. Параметры среднего и размера связаны с определенными параметрами α и β через
- α = μν, β = (1 - μ) ν
Под этой параметризацией можно использовать неинформативная априорная вероятность по сравнению со средним и нечеткая априорная вероятность (например, экспоненциальное или гамма-распределение) по положительным действительным значениям для размера выборки, если они и априорные данные и / или убеждения подтверждают это.
Режим и свойство
Режим и «свойство»  также могут быть используются для расчета параметров бета-распределения.
также могут быть используются для расчета параметров бета-распределения.

Среднее (частота аллелей) и (Райта) генетические расстояния между двумя популяциями
Модель Болдинга - Николса - это двухпараметрическая параметризация бета-распределения, используемая в популяционной генетике. Это статистическое описание частоты аллелей в компонентах подразделяемой популяции:

где  и
и
См. Статьи Модель Болдинга - Николса, F-статистика, индекс фиксации и коэффициент взаимосвязи, для дальнейшая информация.
Среднее значение и дисперсия
Решение системы (связанных) уравнений, приведенных в предыдущих разделах, в виде уравнений для среднего и дисперсии бета-распределения в конечных исходных α и β, параметрах α и β можно выразить через среднее (μ) и дисперсию (var):

Эта параметризация бета-распределения может к более интуитивному пониманию, чем то, которое основано на исходных параметрах α и β. Например, выражая моду, асимметрию, избыточный эксцесс и дифференциальную энтропию в виде среднего и дисперсии:






Четыре параметра
Бета-структура с двумя действующими элементами [0,1] или (0, 1). Можно изменить местоположение и распределение, введя два режима, представляющих минимальное, максимальное значение c (c>a), значения распределения, путем линейного преобразования, заменяющего безразмерную переменную переменную x в терминах новой переменной y (с поддержкой [a, c] или (a, c)) и параметры a и c:

функция плотности вероятности четырех размеров бета-распределения одинаково двухпараметрическому распределению, масштабированному диапазону (ca) (так, чтобы общая площадь под кривой плотности равнялась вероятности, равной единице), и с переменной «y», смещенной и масштабированной следующим образом:

То, что случайная величина Y является бета-распределенной с включением элементов α, β, a и c, будет обозначаться как:

Измерения центрального местоположения масштабируются (на (ca)) и сдвигаются (на a) следующим образом:
![{\displaystyle {\begin{aligned}\mu _{Y}=\mu _{X}(c-a)+a=\left({\frac {\alpha }{\alpha +\beta }}\right)(c-a)+a={\frac {\alpha c+\beta a}{\alpha +\beta }}\\{\text{mode}}(Y)={\text{mode}}(X)(c-a)+a=\left({\frac {\alpha -1}{\alpha +\beta -2}}\right)(c-a)+a={\frac {(\alpha -1)c+(\beta -1)a}{\alpha +\beta -2}}\,\qquad {\text{ if }}\alpha,\beta>1 \\ {\ text {median}} (Y) = {\ text {median}} (X) (ca) + a = \ left (I _ {\ frac {1} {2}} ^ {[- 1]} (\ alpha, \ beta) \ right) (ca) + a \\ {\ text {Неправильно !!:}} G_ {Y } = G_ {X} (ca) + a = \ left (e ^ {\ psi (\ alpha) - \ psi (\ alpha + \ beta)} \ right) (ca) + a \\ {\ text { Неправильно !!:}} H_ {Y} = H_ {X} (ca) + a = \ left ({\ frac {\ alpha -1} {\ alpha + \ beta -1}} \ right) (ca) + a, \, \ qquad {\ text {if}} \ alpha, \ beta>0 \\\ end {align}}}]( ht tps: //wikimedia.org/api/rest_v1/media/math/render/svg/208b62aaf49d6e11cf2c2301d733e7f92a6087d6 )
. (среднее геометрическое и среднее гармоническое не могут быть преобразованы
Параметры формы Y могут быть записаны в его член среднего и дисперсии как

Меры статистической дисперсии масштабируются (их не нужно сдвигать, потому что они уже центрированы по среднему) по диапазону (ca), линейно для среднего о тклонение и нелинейно для дисперсии:



Бук асимметрия и избыточный эксцесс являются безразмерными величинами (поскольку моменты в среднем и нормализованные на стандартное отклонение ), они не зависят от параметров a и c и, следовательно, равны выражениям, приведенным выше в терминах X (с support [0,1] или (0,1)):

![\ text {избыток эксцесса} (Y) = \ text {избыток эксцесса} (X) = \ frac {6 [(\ alpha - \ beta) ^ 2 (\ альфа + \ бета + 1) - \ альфа \ бета (\ альфа + \ бета + 2)]} {\ альфа \ бета (\ альфа + \ бета + 2) (\ альфа + \ бета + 3)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/99ddb3577b02ee0b10163123af23c6d7f728946b)
Свойства
Меры центральной тенденции
Режим
Режим бета-распределенной случайной величины X с α, β>1 - наиболее вероятное значение распределения (соответствующее пику в PDF), и дается следующим выражением:

Когда оба меньше единицы (α, β < 1), this is the anti-mode: the lowest point of the probability density curve.
Если α = β, выражение для режима упрощенной ается до 1/2, форма, что для α = β>1 режим (соотв. анти-режим, когда α, β < 1), is at the center of the distribution: it is symmetric in those cases. See Фигуры раздел в этой статье для полного списка случаев режима, для произвольных значений α и β. Для некоторых из этих самых больших значений плотности находится на одном или обоих концах. В некоторых случаях (максимальное) значение функции плотности, встречающееся в конце, является конечным. Например, в случае α = 2, β = 1 (или α = 1, β = 2) функция плотности становится распределением прямоугольного треугольника, которое является конечным на обоих концах. В некоторых других случаях существует особенность на одном конце, где значение функции плотности приближается к бесконечности. Например, в случае α = β = 1/2, бета-распределение упрощается и становится распределением арксинуса. Среди математиков ведутся споры о некоторых из этих случаев. определить, могут ли концы (x = 0 и x = 1) называться режимами или нет.

Режим для бета-распределения 1 ≤ α ≤ 5 и 1 ≤ β ≤ 5
- Являются ли концы частью области функции плотности
- Может ли особенность когда-либо называться режимом
- Следует ли называть случаи с двумя максимумами бимодальными
Медиана
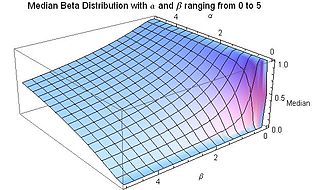
Медиана для бета-распределения для 0 ≤ α ≤ 5 и 0 ≤ β ≤ 5

(Среднее - Медиана) для бета-распределения по сравнению с альфа и бета от 0 до 2
Медиана бета-распределения - это уникальное действительное число ![x = I _ {\ frac {1} {2}} ^ {[- 1]} (\ alpha, \ beta)](https://wikimedia.org/api/rest_v1/media/math/render/svg/2ca6046e74e5db71ed2e8aa0a35783c4fc2db15a) , для регуляризованная неполная бета-функция
, для регуляризованная неполная бета-функция  . Не существует общего выражения в закрытой форме для медианы бета-распределения для произвольных значений α и β. Выражения в закрытой форме для значений параметров α и β следующих:
. Не существует общего выражения в закрытой форме для медианы бета-распределения для произвольных значений α и β. Выражения в закрытой форме для значений параметров α и β следующих:
- Для симметричных случаев α = β, медиана = 1/2.
- Для α = 1 и β>0, медиана
 (в данном зеркальное отображение распределения степенной функции [0,1])
(в данном зеркальное отображение распределения степенной функции [0,1]) - Для α>0 и β = 1 медиана =
 (в данном случае - распределение степенной функции [0,1])
(в данном случае - распределение степенной функции [0,1]) - Для α = 3 и β = 2 медиана = 0,6142724318676105..., реальное решение уравнения четвертой степени 1 - 8x + 6x = 0, которое находится в [0,1].
- Для α = 2 и β = 3 медиана = 0,38572756813238945... = 1-медиана (Beta (3, 2))
Ниже приведены пределы с одним конечным параметром (ненулевым) и другими, приближающимся к этим пределам:

Разумное приближение значений медианы бета-распределения для обоих α и β, больших или равных единице, дается формулой

Когда α, β ≥ 1, относительная погрешность (абсолютная ошибка , деленная на медианное значен ие) в этом приближении составляет менее 4%, а для α ≥ 2 и β ≥ 2 она составляет менее 1%. абсолютная ошибка, деленная на разницу между средним и модой, также мала:
![Abs [(Median-Appr.) / Median] для бета-распределения для 1 ≤ α ≤ 5 и 1 ≤ β ≤ 5](//upload.wikimedia.org/wikipedia/commons/thumb/a/af/Relative_Error_for_Approximation_to_Median_of_Beta_Distribution_for_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg/325px-Relative_Error_for_Approximation_to_Median_of_Beta_Distribution_for_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg)
![Abs [ (Median-Appr.) / (Mean-Mode)] для бета-распределения для 1≤α≤5 и 1≤β≤5](//upload.wikimedia.org/wikipedia/commons/thumb/e/e8/Error_in_Median_Apprx._relative_to_Mean-Mode_distance_for_Beta_Distribution_with_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg/325px-Error_in_Median_Apprx._relative_to_Mean-Mode_distance_for_Beta_Distribution_with_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg)
Среднее

Среднее для бета-распределения для 0 ≤ α ≤ 5 и 0 ≤ β ≤ 5
ожидаемое значение (среднее) (μ) бета-распределение случайная величина X с двумя функциями α и β является функцией только отношений β / α этих параметров:
![\ begin {align} \ mu = \ operatorname {E} [X] = \ int_0 ^ 1 xf (x; \ alpha, \ beta) \, dx \\ = \ int_0 ^ 1 x \, \ frac {x ^ { \ alpha-1} (1-x) ^ {\ beta-1}} {\ Beta (\ alpha, \ beta)} \, dx \\ = \ frac {\ alpha} {\ alpha + \ beta} \ \ = \ frac {1} {1 + \ frac {\ beta} {\ alpha}} \ end {align}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e9137834d9d47360ed6c23550c6236fed5fd35f7)
приведенном выше выражении, получаем μ = 1/2, что для α = β среднее значение находится в центре распределения: оно симметрично. Кроме того, из приведенного выше выражения можно получить следующие пределы:

Следовательно, для β / α → 0 или для α / β → ∞ среднее значение находится на правом правом, x = 1. Для этих предельных значений бета распределение становится одноточечным вырожденным распределением. с дельта-функция Дирака, пик на правом конце, x = 1, с вероятностью 1 и нулевой вероятностью везде. 100% вероятность (абсолютная уверенность) сосредоточена на правом конце, x = 1.
Аналогично, для β / α → ∞ или для α / β → 0 среднее значение находится на левом конце., x = 0. Бета-распределение становится одно-точечным вырожденным распределением с всплеском дельта-функции Дирака на левом конце, x = 0, с вероятностью 1 и нулевой вероятностью везде. еще. 100% вероятность (абсолютная уверенность) сосредоточена на левом конце, x = 0. Ниже приведены пределы с одним конечным параметром (ненулевым), и другой приближается к этому пределу:

В то время как для типичных унимодальных известно, что выборочное среднее (как оценка местоположения) не такой <1275 распределений (с центрально расположенными модами, точками перегиба по обеим сторонам от моды и более длинными хвостами) (с Beta (α, β) таким, что α, β>2)>устойчивый, как медиана выборки, наоборот, для равномерных или «U-образных» бимодальных распределений (с Beta (α, β), таким, что α, β ≤ 1), с модами, расположенными в конце раздачи. Как отмечают Мостеллер и Тьюки (стр. 207), «среднее двух крайних наблюдений использует всю выборочную информацию. Это показывает, как для распределений с коротким хвостом крайние наблюдения должны иметь больший вес ». Напротив, из этого следует, что медиана «U-образных» бимодальных распределений с модами на краю распределения (с Beta (α, β) такими, что α, β ≤ 1) не устойчивой, так как медиана выборки снижает крайние выборочные наблюдения из рассмотрение. Практическое применение этого имеет место, например, для случайных блужданий, поскольку вероятность для времени последнего посещения исходной точки в случайном блуждании распределяется как распределение арксинусов бета (1/2, 1/2): среднее из числа реализаций случайного блуждания является гораздо более надежной оценкой, чем медиана (которая в данном случае является неподходящей оценочной выборочной мерой).
Среднее геометрическое

(Среднее - GeometricMean) для бета-распределения по сравнению с α и β от 0 до 2, форма асимметрии между α и β для среднего геометрического

Средние геометрические для бета-распределения Фиолетовый = G (x), желтый = G (1 - x), меньшие значения α и β спереди

Средние геометрические для бета-распределения. фиолетовый = G (x), желтый = G (1 - x), большие значения α и β впереди
Логарифм среднего геометрического GXраспределения с случайной величиной X - среднее арифметическое ln ( X) или, что эквивалентно, его ожидаемое значение:
![\ ln G_X = \ operatorname {E} [\ ln X]](https://wikimedia.org/api/rest_v1/media/math/render/svg/64b67cb73b90bc0e09ba41003b44f84b6e1d3feb)
Для бета-распределения интеграл ожидаемого значения дает:
![{\ displaystyle {\ begin {align} \ operatorname {E} [\ ln X] = \ int _ {0} ^ {1} \ ln x \, f (x; \ alpha, \ beta) \, dx \\ [4pt] = \ int _ {0} ^ {1} \ ln x \, {\ frac {x ^ {\ alpha -1} (1 -x) ^ {\ beta -1}} {\ mathrm {B} (\ alpha, \ beta)}} \, dx \\ [4pt] = {\ frac {1} {\ mathrm {B} (\ alpha, \ beta)}} \, \ int _ {0} ^ {1} {\ frac {\ partial x ^ {\ alpha -1} (1-x) ^ {\ beta -1}} {\ partial \ alpha}} \, dx \\ [4pt] = {\ frac {1} {\ mathrm {B} (\ alpha, \ beta)}} {\ frac {\ partial} {\ partial \ alpha}} \ int _ {0} ^ {1} x ^ { \ alpha -1} (1-x) ^ {\ beta -1} \, dx \\ [4pt] = {\ frac {1} {\ mathrm {B} (\ alpha, \ beta)}} {\ frac {\ partial \ mathrm {B} (\ alpha, \ beta)} {\ partial \ alpha}} \\ [4pt] = {\ frac {\ partial \ ln \ mathrm {B} (\ alpha, \ beta)} {\ partial \ alpha}} \\ [4pt] = {\ frac {\ partial \ ln \ Gamma (\ alpha)} {\ partial \ alpha}} - {\ frac {\ partial \ ln \ Gamma ( \ alpha + \ beta)} {\ partial \ alpha}} \\ [4pt] = \ psi (\ alpha) - \ psi (\ alpha + \ beta) \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cd9db519e08e3c72cd6f9e2f0c90a7c57bdba035)
где ψ - дигамма-функция.
Следовательно, геометрическая Среднее значение бета-распределения с параметрами формы α и β является экспонентой дигамма-функций α и β следующим образом:
![G_X = e ^ {\ operatorname {E} [\ ln X]} = e ^ {\ psi (\ alpha) - \ psi ( \ альфа + \ бета)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c93ffa7f0155fa3816fcb151c3eb677700aabca2)
Хотя для бета-распределение с одинаковыми параметрами формы α = β, оно Отсюда следует, что асимметрия = 0 и режим = среднее = медиана = 1/2, среднее геометрическое меньше 1/2: 0 < GX< 1/2. The reason for this is that the logarithmic transformation strongly weights the values of X close to zero, as ln(X) strongly tends towards negative infinity as X approaches zero, while ln(X) flattens towards zero as X → 1.
Вдоль линии α = β применяются следующие ограничения:

Ниже приведены ограничения с одним конечным параметром (ненулевым) и другие, приближающиеся к этим пределам:

На прилагаемом графике показана разница между средним и средним геометрическим для параметров формы α и β от нуля до 2. Помимо того, что разница между они стремятся к нулю, когда α и β приближаются к бесконечности, и что разница становится большой при значениях α и β, приближающихся к нулю, на e можно наблюдать очевидную асимметрию среднего геометрического относительно параметров формы α и β. Разница между средним геометрическим и средним значением больше для малых значений α по отношению к β, чем при обмене величинами β и α.
Н. Л. Джонсон и С. Коц предлагает логарифмическое приближение к дигамма-функции ψ (α) ≈ ln (α - 1/2), которое приводит к следующему приближению к среднему геометрическому:

Числовые значения для относительной ошибки в этом приближении следующие: [(α = β = 1): 9,39%]; [(α = β = 2): 1,29%]; [(α = 2, β = 3): 1,51%]; [(α = 3, β = 2): 0,44%]; [(α = β = 3): 0,51%]; [(α = β = 4): 0,26%]; [(α = 3, β = 4): 0,55%]; [(α = 4, β = 3): 0, 24%].
Аналогичным образом можно вычислить параметры формы, необходимые для того, чтобы среднее геометрическое было равно 1/2. Ответ заключается в том, что (при β>1) желаемое значение α стремится к β + 1/2 при β → ∞. Например, все эти пары имеют одно и то же среднее геометрическое 1/2: [ β = 1, α = 1,4427], [β = 2, α = 2,4695 8], [β = 3, α = 3,47943], [β = 4, α = 4,48449], [β = 5, α = 5,48756], [β = 10, α = 10,4938], [β = 100, α = 100,499].
Фундаментальное свойство среднего геометрического, которое может быть доказано как ложное для любого другого среднего, - это
![{\displaystyle \alpha =2:\quad \operatorname {E} \left[-{\frac {1}{N}}{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha,\beta,a,c\mid Y)}{\partial a^{2}}}\right]={\mathcal {I}}_{a,a}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/53538160a2404a5d7b74ae2033fbbb2dbc1045eb)
![{\ displaystyle \ beta = 2: \ quad \ operatorname {E} \ left [ - {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial c ^ {2}}} \ right] = {\ mathcal {I}} _ {c, c}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ee2c6ecfcafe60e54799ab4a16451cf478d65f7d)
![{\ displaystyle \ alpha = 2: \ quad \ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ alpha \ partial a}} \ right] = {\ mathcal {I}} _ {\ alpha, a}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8b8af544d7c5e0cc278aa725daba7f3de2f70d31)
![{\ displaystyle \ beta = 1: \ quad \ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ beta \ partial c}} \ right] = {\ mathcal {I}} _ {\ beta, c}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2f87b32b39997964dcbc95bc64c1364e6832db1d)
(для fu Дальнейшее обсуждение см. в разделе, посвященном информационной матрице Фишера). Таким образом, невозможно строго выполнить оценку максимального правдоподобия для некоторых хорошо известных распределений, принадлежащих к семейству четырехпараметрических бета-распределений, таких как равномерное распределение (Beta (1, 1, a, c)) и распределение арксинусов (Beta (1/2, 1/2, a, c)). Н.Л.Джонсон и С.Коц игнорируют уравнения для гармонических средних и вместо этого предлагают: «Если a и c неизвестны, требуются оценки максимального правдоподобия a, c, α и β., вышеупомянутая процедура (для случая двух неизвестных параметров с преобразованием X как X = (Y - a) / (c - a)) может быть повторена с использованием последовательности пробных значений a и c до тех пор, пока пара (a, c) для которого максимальная вероятность (при заданных a и c) максимально велика »(где для ясности их обозначения для параметров были переведены в настоящие обозначения).
Информационная матрица Фишера
Пусть случайная величина X имеет плотность вероятности f (x; α). Частная производная по параметру (неизвестному и подлежащему оценке) α логарифмической функции правдоподобия называется оценкой. Второй момент оценки называется информацией Фишера :
![{\ displaystyle {\ mathcal {I}} (\ alpha) = \ operatorname {E} \ left [\ left ({\ frac {\ partial} {\ partial \ alpha}} \ ln {\ mathcal {L}} (\ alpha \ mid X) \ right) ^ {2} \ right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/daec13972d17a073bcd447abfde55a6b0e168720)
ожидание для оценки равно нулю, поэтому информация Фишера также является вторым моментом, сосредоточенным на среднем значении оценки: дисперсия оценки.
Если log функция правдоподобия дважды дифференцируема по параметру α и при определенных условиях регулярности, то информация Фишера также может быть записана следующим образом (что часто является более удобным форму для расчетов):
![{\ displaystyle {\ mathcal {I}} (\ alpha) = - \ operatorname {E} \ left [{\ frac {\ partial ^ {2}} { \ partial \ alpha ^ {2}}} \ ln ({\ mathcal {L}} (\ alpha \ mid X)) \ right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/92244569d1fab7e801097aa25a9c883ff75be5aa)
Таким образом, информация Фишера является отрицательным значением математического ожидания второй производной относительно параметра α log функция правдоподобия. Следовательно, информация Фишера является мерой кривизны логарифмической функции правдоподобия α. Низкая кривизна (и, следовательно, высокий радиус кривизны ), более плоская кривая логарифмической функции правдоподобия имеет низкую информацию Фишера; в то время как кривая логарифмической функции правдоподобия с большой кривизной (и, следовательно, с низким радиусом кривизны ) имеет высокую информацию Фишера. Когда информационная матрица Фишера вычисляется на основе оценок параметров («наблюдаемая информационная матрица Фишера»), это эквивалентно замене истинной логарифмической поверхности правдоподобия приближением ряда Тейлора, взятого до квадратичных членов. Слово информация в контексте информации Fisher относится к информации о параметрах. Такая информация, как: оценка, достаточность и свойства дисперсии оценщиков. Граница Крамера – Рао утверждает, что инверсия информации Фишера является нижней границей дисперсии любой оценки параметра α:
![\ operatorname {var} [\ hat \ alpha ] \ geq \ frac {1} {\ mathcal {I} (\ alpha)}.](https://wikimedia.org/api/rest_v1/media/math/render/svg/d93d4983a2717258c52eb47d1562e849a3a66c5c)
Точность, с которой оценка параметра α ограничена информацией Фишера логарифмической функции правдоподобия. Информация Фишера является мерой минимальной ошибки, связанной с оценкой параметра распределения, и ее можно рассматривать как меру разрешающей способности эксперимента, необходимой для различения двух альтернативных гипотез о параметре.
Когда есть N параметров

, тогда информация Фишера принимает форму положительной полуопределенной симметричной матрицы размером N × N , информационной матрицы Фишера, с типичной элемент:
![{(\ mathcal {I} (\ theta))} _ {i, j} = \ operatorname {E} \ left [\ left (\ frac {\ partial} {\ partial \ theta_i} \ ln \ mathcal {L} \ right) \ left (\ frac {\ partial} {\ partial \ theta_j} \ ln \ mathcal {L} \верно) \ справа].](https://wikimedia.org/api/rest_v1/media/math/render/svg/21548fc75268a39c9137d0476132992173ec961d)
При определенных условиях регулярности информационная матрица Фишера также может быть записана в следующей форме, которая часто более удобна для вычислений:
![{(\mathcal{I}(\theta))}_{i, j} = - \operatorname{E} \left [\frac{\partial^2}{\partial\theta_i \, \partial\theta_j} \ln (\mathcal{L}) \right ]\,.](https://wikimedia.org/api/rest_v1/media/math/render/svg/faab65dd329813220161fa8f3772f043a1018d04)
С X 1,..., X Niid случайных величин, может быть построен N-мерный «ящик» со сторонами X 1,..., X N. Коста и Ковер показывают, что дифференциальная энтропия (Шеннона) h (X) связана с объемом типичного набора (имеющего энтропию образца, близкую к истинной энтропии), в то время как информация Фишера связана с поверхностью этого типичного набора.
Два параметра
Для X 1,..., X N независимых случайных величин, каждая из которых имеет бета-структуру, параметризованное значение формы α и β, функция совместной логарифмического правдоподобия для N iid наблюдений составляет:

поэтому Совместная логарифмическая функция правдоподобия на N iid наблюдений:

Для случая с двумя диагональными данными Фишера состоит из 4 компонентов: 2 и 2 внешних. Информационная матрица Фишера симметрична, один из этих недиагональных компонентов. Таким образом, информационная матрица Фишера имеет 3 независимых компонента (2 диагональных и 1 недиагональный).
Арьял и Надараджа рассчитали информационную матрицу Фишера для четырехпараметрического случая, из которого двухпараметрический случай может быть получен следующим образом:
![{\ displaystyle - {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ бета \ середина X)} {N \ partial \ alpha ^ {2}}} = \ oper atorname {var} [\ ln (X)] = \ psi _ {1} (\ alpha) - \ psi _ {1} (\ alpha + \ beta) = {\ mathcal {I}} _ {\ alpha, \ alpha} = \ operatorname {E} \ left [- {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta \ mid X)} {N \ partial \ alpha ^ { 2}}} \ right] = \ ln \ operatorname {var} _ {GX}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c90003d5bd2f6d2bcfe2c788585689726b4b7e36)
![{\displaystyle -{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha,\beta \mid X)}{N\,\partial \beta ^{2}}}=\operatorname {var} [\ln(1-X)]=\psi _{1}(\beta)-\psi _{1}(\alpha +\beta)={\mathcal {I}}_{\beta,\beta }=\operatorname {E} \left[-{\frac {\partial ^{2}\ln {\mathcal {L}}(\alpha,\beta \mid X)}{N\partial \beta ^{2}}}\right]=\ln \operatorname {var} _{G(1-X)}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b59bcc31f14f1f4b3b07bd92a66426bb6ac126b1)
![{\ displaystyle - {\ frac {\ p artial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta \ mid X)} {N \, \ partial \ alpha \, \ partial \ beta}} = \ operatorname {cov} [\ ln X, \ ln (1-X)] = - \ psi _ {1} (\ alpha + \ beta) = {\ mathcal {I}} _ {\ alpha, \ beta} = \ operatorname {E} \ left [ - {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta \ mid X)} {N \, \ partial \ alpha \, \ partial \ beta}} \ right] = \ ln \ operatorname {cov} _ {G {X, (1-X)}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a6c3268da3b23c062ce981ab02d4c454a0267365)
Электронная информационная матрица Фишера симметрична

Информационные компоненты Фишера равны логарифмической геометрической дисперсии и логарифмической геометрической ковариации. Следовательно, они могут быть выражены как тригамма-функции, обозначенные ψ 1 (α), вторая из полигамма-функций, определенные как производная функции дигамма :

Эти производные также выводятся в разделе «Оценка параметров», «Максимальное правдоподобие», «Два неизвестных расписания» и на графиках log функции правдоподобия также показаны в этом разделе. Раздел под названием «Геометрическая дисперсия и ковариация» содержит графики и дальнейшее описание компонентов информационной системы Фишера: логарифмической геометрической формы дисперсии и логарифмической формы ковариации как функции параметров α и β. Раздел «Другие моменты», «Моменты преобразованных случайных величин», «Моменты логарифмически преобразованных случайных величин» содержит формулы для моментов логарифмически преобразованных случайных величин. Изображения для информационных компонентов Фишера  и
и  показаны в разделе «Геометрические дисперсия».
показаны в разделе «Геометрические дисперсия».
Определитель информационной системы Фишера представляет интерес (например, для вычислений априорной вероятности Джеффриса). Из выражений для отдельных компонентов информационной матрицы Фишера следует, что определитель (симметричной) информационной системы Фишера для бета-распределения равен:
![{\ displaystyle {\ begin в {выровненном} \ det ({\ mathcal {I}} (\ alpha, \ beta)) = {\ mathcal {I}} _ {\ alpha, \ alpha} {\ mathcal {I}} _ {\ beta, \ beta} - {\ mathcal {I}} _ {\ alpha, \ beta} {\ mathcal {I}} _ {\ alpha, \ beta} \\ [4pt] = (\ psi _ {1} ( \ alpha) - \ psi _ {1} (\ alpha + \ beta)) (\ psi _ {1} (\ beta) - \ psi _ {1} (\ alpha + \ beta)) - (- \ psi _ {1} (\ alpha + \ beta)) (- \ psi _ {1} (\ alpha + \ beta)) \\ [4pt] = \ psi _ {1} (\ alpha) \ psi _ {1} (\ beta) - (\ psi _ {1} (\ alpha) + \ psi _ {1} (\ beta)) \ psi _ {1} (\ alpha + \ beta) \\ [4pt] \ lim _ { \ alpha \ to 0} \ det ({\ mathcal {I}} (\ alpha, \ beta)) = \ lim _ {\ beta \ to 0} \ det ({\ mathcal {I}} (\ alpha, \ beta)) = \ infty \\ [4pt] \ lim _ {\ alpha \ to \ infty} \ det ({\ mathcal {I}} (\ alpha, \ beta)) = \ lim _ {\ beta \ to \ infty} \ det ({\ mathcal {I}} (\ alpha, \ beta)) = 0 \ end {выравнивается}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b2c5ccf59b05ea730fc108360c07e9ac9634e829)
От критерий Сильвестра (проверка, все ли диагональные элементы положительны), из следует, что информационная матрица Фишера для условия с двумя точками положительно-определенная (при стандартном условии, что параметры формы равны положительные α>0 и β>0).
Четыре параметра

Информация Фишера I (a, a) для α = β по сравнению с диапазоном (c - a) и показателем степени α = β

Информация Фишера I (α, a) для α = β, в зависимости от диапазона (c - a) показателя степени α = β
Если Y 1,..., Y N являются независимыми случайными величинами, каждая из которых имеет бета-распределение с четырьмя параметрами: показатели α и β, а также минимум (диапазон распределения) и c (максимум распределения) (раздел «Альтернативные параметры», «Четыре параметра») с плотностью вероятности функция :
совместная логарифмическая функция правдоподобия для N iid наблюдений:

Для случая с четырьмя включенной информацией Фишера состоит из 4 * 4 = 16 компонентов. Он имеет 12 недиагональных компонентов = (всего 4 × 4 - 4 диагональных). Информационная матрица Фишера симметрична, половина этих компонентов (12/2 = 6) независимы. Следовательно, информационная матрица Фишера имеет 6 независимых недиагональных + 4 диагональных = 10 независимых компонентов. Ариал и Надараджа рассчитали информационную матрицу Фишера для четырехпараметрического случая следующим образом:
![{\ displaystyle - {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ alpha ^ {2}}} = \ operatorname {var} [\ ln (X)] = \ psi _ {1} (\ alpha) - \ psi _ {1} (\ alpha + \ beta) = {\ mathcal {I}} _ {\ alpha, \ alpha} = \ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ alpha ^ {2}}} \ right] = \ ln ( \ operatorname {var_ {GX}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/31be86f2c53663c6d3975bc2676806ba3e538423)
![{\ displaystyle - {\ frac { 1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ beta ^ {2}} } = \ operatorname {var} [\ ln (1-X)] = \ psi _ {1} (\ beta) - \ psi _ {1} (\ alpha + \ beta) = {\ mathcal {I}} _ {\ beta, \ beta} = \ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ beta ^ {2}}} \ right] = \ ln (\ operatorname {var_ {G (1-X)}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/25ab885119f25fae0b9919326db96395d13e3bc3)
![{\ displaystyle - {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ середина Y)} {\ partial \ alpha \, \ partial \ beta}} = \ operatorname {cov} [\ ln X, (1-X)] = - \ psi _ {1} (\ alpha + \ beta) = {\ mathcal {I}} _ {\ alpha, \ beta} = \ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ alpha \, \ partial \ beta}} \ right] = \ ln (\ operatorname {cov} _ {G {X, (1-X)}})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/02a56af746fb9315340cf382951fe0c3f3640678)
В приведенных выше выражениях использование X вместо Y в выражениях var [ln (X)] = ln (var GX) это не ошибка. Выражения в терминах логарифмической геометрической дисперсии и логарифмической геометрической ковариации возникают как функции двухпараметрической параметра параметров X ~ Beta (α, β), поскольку при взятии частных производственных по показателям (α, β) в четырехпараметрическом случае, можно получить те же выражения, что и для случая Эти члены четырехпараметрической информационной матрицы не зависят от минимума и максимума диапазона распределения. Единственный ненулевой член при двойном дифференцировании логарифмической функции правдоподобия относительно показателей α и β - это вторая производная логарифма бета-функции: ln (B (α, β)). Этот член не зависит от минимума и максимума c диапазона распределения. Двойное дифференцирование этого члена приводит к тригамма-функциям. Разделы «Максимальное правдоподобие», «Два неизвестных события» и «Четыре неизвестных события» также показывают этот факт.
Информация Fisher для N i.i.d. Образца в N раз больше индивидуальной информации Fisher (уравнение 11.279, стр. 394 из Cover and Thomas). (Арьял и Надараджа использует одно наблюдение, N = 1, для следующих компонентов информации Фишера, что приводит к результату же, что и рассмотрение производных логарифма правдоподобия на N наблюдений. Кроме того, ниже ошибочное выражение для  в Aryal и Nadarajah было исправлено.)
в Aryal и Nadarajah было исправлено.)
![{\displaystyle {\begin{aligned}\alpha>2: \ quad \ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial a ^ {2}}} \ right] = {\ mathcal {I}} _ {a, a} = {\ fra c {\ beta (\ alpha + \ beta -1)} {(\ alpha -2) (ca) ^ {2}}} \\\ beta>2: \ quad \ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial c ^ {2}}} \ right] = {\ mathcal {I}} _ {c, c} = {\ frac {\ alpha (\ alpha + \ beta -1)} {(\ beta -2) (ca) ^ {2}}} \\\ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial a \, \ partial c}} \ right] = {\ mathcal {I}} _ {a, c} = {\ frac {(\ alpha + \ beta -1)} {(ca) ^ {2}}} \\\ alpha>1: \ quad \ operatorname {E} \ left [- {\ frac {1 } {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ alpha \, \ partial a} } \ right] = {\ mathcal {I}} _ {\ alpha, a} = {\ frac {\ beta} {(\ alpha -1) (ca)}} \\\ OperatorName {E} \ left [ - {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ alpha \, \ partia l c}} \ right] = {\ mathcal {I}} _ {\ alpha, c} = {\ frac {1} {(ca)}} \\\ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y)} {\ partial \ beta \, \ partial a}} \ right] = {\ mathcal {I}} _ {\ beta, a} = - {\ frac {1} {(ca)}} \\\ beta>1: \ quad \ operatorname {E} \ left [- {\ frac {1} {N}} {\ frac {\ partial ^ {2} \ ln {\ mathcal {L}} (\ alpha, \ beta, a, c \ mid Y) } {\ partial \ beta \, \ partial c}} \ right] = {\ mathc al {I}} _ {\ beta, c} = - {\ frac {\ alpha} {(\ beta -1) (ca)}} \ end {align}}}]( https://wikimedia.org/api/rest_v1/media/math/render/svg/636646f51bdb1a3193b1721483878e98f4f19c3e )
Два нижних диагональных элемента информационной матрицы Фишера относительно параметра "a" (минимум диапазона распределения): , и в отношении параметра " c "(максимум диапазона распределения):  определены только для показателей степени α>2 и β>2 соответственно. Компонент информационной матрицы Фишера для минимального "a" приближается к бесконечности для степени α, приближающейся к 2 сверху, а компонент информационной матрицы Фишера для максимального значения «c» приближается к бесконечности для показателя β, приближающегося к 2 сверху.
определены только для показателей степени α>2 и β>2 соответственно. Компонент информационной матрицы Фишера для минимального "a" приближается к бесконечности для степени α, приближающейся к 2 сверху, а компонент информационной матрицы Фишера для максимального значения «c» приближается к бесконечности для показателя β, приближающегося к 2 сверху.
Информационная матрица Фишера для случая с четырьмя параметрами не зависит от отдельных значений минимального «а» и максимального «с», а только от общего диапазона (с-а). Более того, компоненты информационной матрицы Фишера, которые зависят от дальности (c-a), зависят только через ее обратную величину (или квадрат обратной), так что информация Фишера уменьшается с увеличением дальности (c-a).
На прилагаемых изображениях показаны информационные компоненты Фишера и  . Изображения для информационных компонентов Фишера
. Изображения для информационных компонентов Фишера  и
и  показаны в разделе «Геометрическая дисперсия». Все эти информационные компоненты Фишера выглядят как бассейн, «стенки» которого расположены при низких значениях параметров.
показаны в разделе «Геометрическая дисперсия». Все эти информационные компоненты Фишера выглядят как бассейн, «стенки» которого расположены при низких значениях параметров.
Следующие компоненты информации Фишера бета-распределения с четырьмя параметрами могут быть выражены в терминах двухпараметров: X ~ бета (α, β) ожидания преобразованного отношения ((1-X) / X) и его зеркального изображения (X / (1-X)), масштабированного по диапазону (c − a), что может быть полезно для интерпретации:
![\mathcal{I}_{\alpha, a} =\frac{\operatorname{E} \left[\frac{1-X}{X} \right ]}{c-a}= \frac{\beta}{(\alpha-1)(c-a)} \text{ if }\alpha>1]( https://wikimedia.org/api/rest_v1/media/math/render/svg/e670565bb8d06bace69cf892864520f5c83b5449 )
![\mathcal{I}_{\beta, c} = -\frac{\operatorname{E} \left [\frac{X}{1-X} \right ]}{c-a}=- \frac{\alpha}{(\beta-1)(c-a)}\text{ if }\beta>1]( https: // wikime dia.org/api/rest_v1/media/math/render/svg/94f9b7788a4f19e1cbc765ab8fc85a7ad55dec4f)
Это также ожидаемые значения «инвертированного бета-распределения» или основного бета-распределения (также известного как бета-распределение второго типа или Тип VI Пирсона ) и его зеркальное отображение, масштабированное по диапазону (c - a).
Кроме того, следующие компоненты информации Фишера могут быть выражены в терминах гармонической (1 / X) дисперсии или дисперсии на основе преобразованных в отношение переменных ((1-X) / X) следующим образом:
![{\displaystyle {\begin{aligned}\alpha>2: \ quad {\ mathcal {I} } _ {a, a} = \ operatorname {var} \ left [{\ frac {1} {X}} \ right] \ left ({\ frac {\ alpha -1} {ca}} \ right) ^ {2} = \ operatorname {var} \ left [{\ frac {1-X} {X}} \ right] \ left ({\ frac {\ alpha -1} {ca}} \ right) ^ {2} = {\ frac {\ beta (\ alpha + \ beta -1)} {(\ alpha -2) (ca) ^ {2}}} \\\ beta>2: \ quad {\ mathcal {I}} _ {c, c} = \ operatorname {var} \ left [{\ frac {1} {1-X}} \ right] \ left ({\ frac {\ beta -1} {ca}} \ right) ^ {2} = \ operatorname {var} \ left [{\ frac {X} {1-X}} \ right] \ left ({\ frac {\ beta -1} {ca}} \ right) ^ {2} = {\ frac {\ alp ha (\ alpha + \ beta -1)} {(\ beta -2) (ca) ^ {2}}} \\ {\ mathcal {I}} _ {a, c} = \ operatorname {cov} \ left [{\ frac {1} {X}}, {\ frac {1} {1-X}} \ right] {\ frac {(\ alpha -1) (\ beta -1)} {(ca) ^ {2}}} = \ operatorname {cov} \ left [{\ frac {1-X} {X}}, {\ frac {X} {1-X}} \ right] {\ frac {(\ alpha - 1) (\ beta -1)} {(ca) ^ {2}}} = {\ frac {(\ alpha + \ beta -1)} {(ca) ^ {2}}} \ end {выровнено}} }]( https://wikimedia.org/api/rest_v1/media/math/render/svg/f1f89730020364bb58791ca0eb47d0de25c896c2 )
См. раздел« Моменты линейно преобразованные, произведенные и инвертированные случайные величины »для этих ожиданий.
Определитель информационной матрицы Фишера представляет интерес (например, для вычисления априорной вероятности Джеффриса). Из выражений для отдельных компонентов следует, что определитель (симметричной) информационной матрицы Фишера для бета-распределения с четырьмя параметрами равен:

Используя критерий Сильвестра (проверка, все ли диагональные элементы положительны), и поскольку диагональные компоненты и имеют особенности при α = 2 и β = 2, из этого следует, что информационная матрица Фишера для случая с четырьмя положительно особенными для α>2 и β>2. Формула-распределений (симметричная или несимметричная) формула колокола, отсюда следует, что информационная матрица. Таким образом, важные распределения, принадлежащие семейству четырехпараметрического бета-распределения, такие какболическое распределение (Beta (2,2, a, c)) и равномерное распределение (Beta (1,1, a, c))) имеют информационные компоненты Фишера ( ), которые в случае четырех параметров (хотя их информационные компоненты Фишера все параметры для случая двух параметров). Четырехпараметрическое полуокружное распределение Вигнера (бета (3 / 2,3 / 2, a, c)) и арксинусное распределение (бета (1 / 2,1 / 2, a, c)) имеют отрицательные детерминанты информации Фишера для четырехпараметрического случая.
), которые в случае четырех параметров (хотя их информационные компоненты Фишера все параметры для случая двух параметров). Четырехпараметрическое полуокружное распределение Вигнера (бета (3 / 2,3 / 2, a, c)) и арксинусное распределение (бета (1 / 2,1 / 2, a, c)) имеют отрицательные детерминанты информации Фишера для четырехпараметрического случая.
Байесовский вывод


:
равномерное распределение плотности вероятности было предложено
Томас Байес, чтобы предотвратить игнорирование априорных вероятностей в
байесовском выводе. Он не показывает состояние полного незнания, а состояние знания, в котором мы наблюдали по крайней мере один успех и одну неудачу, и поэтому у нас есть предварительное знание, что оба состояния являются физически возможно.
Использование бета-распределений в байесовском выводе связано с тем, что они обеспечивают семейство сопряженных априорных распределений вероятностей для биномиального (включая Бернулли ) и геометрические распределения. Область бета-распределения можно рассматривать как вероятность, и на самом деле распределение используется для описания значений вероятности p:

Примерами бета-распределений, используемых в априорных вероятностях представления игнорирования значений предшествующих параметров в байесовском выводе, являются бета (1,1), бета (0,0) и бета (1/2, 1/2).
.
Правило преемственности
Классическим применением бета-распределения правило преемственности, введенное в 18 веке Пьером-Симоном Лапласом в курсе лечения проблемы восхода солнца. В нем указано, что, учитывая его успех в n условно независимых испытаниях Бернулли с вероятностью p, оценка значения в следующем испытании составляет  . Эта оценка представляет собой ожидаемое значение апостериорного распределения по p, а именно Beta (s + 1, n - s + 1), которое задается правилами Байеса, если решена однородная априорная вероятность по p (т. Е. Beta (1, 1)), а затем принесло успехи в испытаниях. Правило преемственности Лапласа подверглось критике со стороны выдающих ученых. Р. Т. Кокс описал применение Лапласом правил преемственности к проблеме восход солнца (стр. 89) как «пародию на правильное использование этого принципа». Кейнс замечает (Ch.XXX, p. 382), «действительно, это настолько глупая теорема, что принимать ее во внимание дискредитировано». Карл Пирсон показал, что вероятность того, что следующие (n + 1) испытания будут успешными после успехов в испытаниях, составляет всего 50%, что было сочтено такими учеными, как Джеффрис, слишком низким и неприемлемым представлением научного процесса. экспериментов для проверки предложенного научного закона. Как Джеффрис (стр. 128) (с указанием CD Broad ) - преемственность Лапласа - высокая вероятность успеха (n + 1) / (n + 2)) в следующем испытании, но только умеренная вероятность (50 %) того, что следующая выборка (n + 1) сопоставимого размера будет столь же успешной. Как указывает Перкс, «правило преемственности трудно принять. Оно присваивает вероятность следующего испытания, что подразумевает предположение, что фактический пробег является средним пробегом, и что мы всегда находимся в конце среднего пробега. Казалось бы, более разумным было предположить, что мы находимся в середине среднего прогона. Ясно, что имеет высокое значение высокого уровня вероятностей, если они должны соответствовать разумному мнению ». Эти проблемы с правилами преемственности Лапласа побудили Холдейна, Перкса, Джеффриса и других искать другие формы априорной вероятности (см. Следующий раздел , озаглавленный «Байесовский вывод» ). По словам Джейнса, основная проблема с правилами преемственности состоит в том, что оно недействительно, когда s = 0 или s = n (см. правило преемственности для анализа его действительности).
. Эта оценка представляет собой ожидаемое значение апостериорного распределения по p, а именно Beta (s + 1, n - s + 1), которое задается правилами Байеса, если решена однородная априорная вероятность по p (т. Е. Beta (1, 1)), а затем принесло успехи в испытаниях. Правило преемственности Лапласа подверглось критике со стороны выдающих ученых. Р. Т. Кокс описал применение Лапласом правил преемственности к проблеме восход солнца (стр. 89) как «пародию на правильное использование этого принципа». Кейнс замечает (Ch.XXX, p. 382), «действительно, это настолько глупая теорема, что принимать ее во внимание дискредитировано». Карл Пирсон показал, что вероятность того, что следующие (n + 1) испытания будут успешными после успехов в испытаниях, составляет всего 50%, что было сочтено такими учеными, как Джеффрис, слишком низким и неприемлемым представлением научного процесса. экспериментов для проверки предложенного научного закона. Как Джеффрис (стр. 128) (с указанием CD Broad ) - преемственность Лапласа - высокая вероятность успеха (n + 1) / (n + 2)) в следующем испытании, но только умеренная вероятность (50 %) того, что следующая выборка (n + 1) сопоставимого размера будет столь же успешной. Как указывает Перкс, «правило преемственности трудно принять. Оно присваивает вероятность следующего испытания, что подразумевает предположение, что фактический пробег является средним пробегом, и что мы всегда находимся в конце среднего пробега. Казалось бы, более разумным было предположить, что мы находимся в середине среднего прогона. Ясно, что имеет высокое значение высокого уровня вероятностей, если они должны соответствовать разумному мнению ». Эти проблемы с правилами преемственности Лапласа побудили Холдейна, Перкса, Джеффриса и других искать другие формы априорной вероятности (см. Следующий раздел , озаглавленный «Байесовский вывод» ). По словам Джейнса, основная проблема с правилами преемственности состоит в том, что оно недействительно, когда s = 0 или s = n (см. правило преемственности для анализа его действительности).
Байесовская априорная вероятность (бета (1,1))
Бета-распределение достигает максимальной дифференциальной энтропии для бета (1,1): равномерная плотность вероятности для все значения в области распределения имеют одинаковую плотность. Это равномерное распределение Бета (1,1) было предложено («с большим сомнением») Томасом Байесом в качестве априорного распределения вероятностей, чтобы выразить незнание правильного априорного распределения. Это предварительное распределение было принято (по-видимому, из его работ, без каких-либо сомнений) Пьером-Симоном Лапласом, и поэтому оно было также известно как «правило Байеса-Лапласа» или «правило Лапласа». «обратной вероятности » в публикациях первой половины 20 века. В конце 19-го и начале 20-го века ученые осознали, что предположение о равномерной «равной» плотности вероятности зависит от фактических функций (например, от того, какая шкала наиболее подходит - линейной или логарифмической) и используемых параметризаций.. В частности, особого внимания требует поведение вблизи концов распределений с конечной опорой (например, вблизи x = 0 для распределения с начальной опорой при x = 0). Кейнс (Ch.XXX, p. 381) подверг критике использование равномерной априорной вероятности Байеса (Beta (1,1)), согласно которой все значения между нулем и единицей равновероятны, следующим образом: «Таким образом, опыт, если он что-то показывает, показывает, что наблюдается очень заметная группировка статистических отношений в окрестностях нуля и единицы, отношений для положительных теорий и корреляций между положительными качествами в окрестности нуля, а также для отрицательных теорий и корреляций между отрицательными качествами в окрестности единство. "
априорная вероятность Холдейна (бета (0,0))


: априорная вероятность Холдейна Вероятность, выражающая полное игнорирование предшествующей информации, когда мы даже не уверены, физически ли возможно, чтобы эксперимент закончился успехом или неудачей. При α, β → 0 бета-распределение приближается к двухточечному
распределению Бернулли со всей плотностью вероятности, сосредоточенной на каждом конце, в точках 0 и 1, и ничего между ними. Подбрасывание монеты: одна грань монеты имеет значение 0, а другая сторона - 1.
Бета (0,0) распределение было предложено J.B.S. Холдейн, который предположил, что априорная вероятность,представляющая полную неопределенность, должна быть пропорциональна p (1 − p). Функцию p (1 − p) можно рассматривать как предел числителя бета-распределения, поскольку оба параметра формы стремятся к нулю: α, β → 0. Бета-функция (в знаменателе бета-распределения) стремится к бесконечности для оба параметра стремятся к нулю, α, β → 0. Следовательно, p (1 − p), деленное на бета-функцию, приближается к 2-точечному распределению Бернулли с равной вероятностью 1/2 на каждом конце, при 0 и 1, и ничего между ними, поскольку α, β → 0. Подбрасывание монеты: одна грань монеты находится в положении 0, а другая сторона - в 1. Априорное распределение вероятностей Холдейна Beta (0,0) - это "неправильный предыдущий ", потому что его интегрирование (от 0 до 1) не может строго сходиться к 1 из-за особенностей на каждом конце. Однако это не проблема для вычисления апостериорных вероятностей, если размер выборки не очень мал. Кроме того, Зеллнер указывает, что по шкале логарифм шансов (преобразование логит ln (p / 1-p)) априор Холдейна является равномерно плоским априорном. Тот факт, что равномерная априорная вероятность на logit преобразованной переменной ln (p / 1 − p) (с областью (-∞, ∞)) эквивалентна априорной вероятности Холдейна в области [0, 1] на это указывал Гарольд Джеффрис в первом издании (1939 г.) его книги «Теория вероятностей» (стр. 123). Джеффрис пишет: «Конечно, если мы доведем правило Байеса-Лапласа до крайностей, мы придем к результатам, которые не соответствуют чьему-либо образу мышления. Правило (Холдейна) dx / (x (1 − x)) заходит слишком далеко наоборот. Это привело бы к выводу, что если выборка относится к одному типу в отношении некоторого свойства, существует вероятность 1, что все население принадлежит к этому типу ". Тот факт, что «единообразие» зависит от параметризации, побудил Джеффриса искать форму априорной модели, которая была бы инвариантной при различных параметризациях.
априорная вероятность Джеффриса (бета (1 / 2,1 / 2) для распределения Бернулли или для биномиального распределения)
 априорная вероятность Джеффри
априорная вероятность Джеффри для бета-распределения: квадратный корень из определителя матрицы
информации Фишера :

является функцией
тригамма-функции ψ1параметров формы α, β

плотности апостериорного бета с образцами, имеющими успех = "s", отказ = "f" из s / (s + f) = 1/2 и s + f = {3,10,50} на основе 3 различных априорных функций вероятности: Холдейна (бета (0,0), Джеффриса (бета (1 / 2,1 / 2)) и Байеса (Бета (1,1)). Изображение показывает, что существует небольшая разница между апостериорными значениями для апостериорных при размере выборки 50 (с более выраженным пиком около p = 1/2). Значительные различия проявляются для очень малых размеров выборки 3

Плотность апостериорного бета с успешными образцами = "s", неудача = "f" из s / (s + f) = 1/4, и s + f ∈ {3,10,50}, на основе трех различных априорных функций вероятности: Холдейна (бета (0,0), Джеффриса (бета (1 / 2,1 / 2)) и Байеса (бета (1, 1)). Изображение показывает, что существует небольшая разница между апостерическими значениями для апостериорной выборки с размером выборки 50 (с более выраженным пиком p = 1/4). = 3, в этом вырожденном и маловероятном случае априор Холдейна дает обратную J-образную форму с модой при p = 0 вместо p = 1/4. Если имеется достаточно данных выборки , три априорных значения Байеса (бета (1, 1)), Джеффриса (бета (1 / 2,1 / 2)) и Холдейна (бета (0,0)) должны дать аналогичную
апостериорную вероятность плотности.

Апостериорные плотности бета с образцами имея успех = s, неудача = f из s / (s + f) = 1/4 и s + f ∈ {4,12,40}, на основе трех различных априорных функций вероятности: Холдейна (бета (0,0), Джеффри (бета (1/2, 1/2)) и Байеса (бета (1,1)). Изображение показывает, что существует небольшая разница между апостериорными значениями для апостериорной выборки при размере выборки 40 ( Значительные различия проявляются для очень малых размеров выборки
Гарольд Джеффрис использовать использовать неинформативную априорную вероятностную меру, которая должна быть инвариантной при повторной параметры : пропорциональной квадратному корню из определитель матрицы информации Фишера. Для распределения Бернулли это можно показать следующим образом: для монеты, которая является «орлом» с вероятностью p ∈ [0, 1] и является «решкой» с вероятностью 1 - p, для данного (H, T) ∈ {(0,1), (1,0)} вероятнос ть равна p (1 - p). Времена T = 1 - H, распределение Бернулли равно p (1 - p). Рассматривая p как единственный параметр, следует, что вероятность распределения Бернулли равна

Информационная матрица Фишера имеет только один компонент (это скаляр, потому что есть только один параметр: p), поэтому:
![{\ displaystyle {\ begin {align} {\ sqrt {{\ mathcal {I}} (p)} } = {\ sqrt {\ operatorname {E} \! \ left [\ left ({\ frac {d} {dp}} \ ln ({\ mathcal {L}} (p \ mid H)) \ right) ^ {2} \ right]}} \\ [6pt] = {\ sqrt {\ operatorname {E} \! \ Left [\ left ({\ frac {H} {p}} - {\ frac {1- H} {1-p}} \ right) ^ {2} \ right]}} \\ [6pt] = {\ sqrt {p ^ {1} (1-p) ^ {0} \ left ({\ frac {1} {p}} - {\ frac {0} {1-p}} \ right) ^ {2} + p ^ {0} (1-p) ^ {1} \ left ({\ frac { 0} {p}} - {\ frac {1} {1-p}} \ right) ^ {2}}} \\ = {\ frac {1} {\ sqrt {p (1-p)}} }. \ конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/324e2e5a963eed1652cf2d3a9ba95e5491b5df95)
Аналогично, для биномиального распределения с n Бернулли испытывает, можно показать, что

Таким образом, для Бернулли и биномиальных распределений, до Джеффри пропорционально  , что оказывается пропорциональным бета-распределению с переменными областями x = p и возможной формой α = β = 1/2, распределение арксинуса :
, что оказывается пропорциональным бета-распределению с переменными областями x = p и возможной формой α = β = 1/2, распределение арксинуса :

Следующая часть будет показана, что нормализируется константа для априорной Джеффри несущественна для окончательного результата, потому что нормализируется константа сокращается в теореме Байеса для апостериорной вероятности. Следовательно, бета (1 / 2,1 / 2) используется как априор Джеффри для Бернулли, так и для биномиального распределения. Как показано в следующем разделе, при использовании этого выражения как априорной вероятности, умноженной на правдоподобие в теореме Байеса, апостериорная вероятность оказывается бета-распределением. Однако важно понимать, что априор Джеффриса пропорционален для распределения Бернулли и биномиального распределения, но не для бета-распределения. Априор Джеффри для бета-распределения определяет определителем информации Фишера для бета-распределения, которое, как показано в разделе под названием «Информационная матрица Фишера», является функцией тригамма-функции ψ1параметров формы α и β следующим образом:

Как обсуждалось ранее, априор Джеффри для распределения Бернулли и биномиального распределения пропорционален арксинусному распределению Бета (1 / 2,1 / 2), одномерной кривой, которая выглядит как бассейн в виде функции распределения Бернулли и биномиального распределения. Стенки бассейна образованы приближением p к сингулярности на концах p → 0 и p → 1, где Beta (1 / 2,1 / 2) стремится к бесконечности. Джеффрис априор для бета-распределения представляет собой двумерную поверхность (встроенную в трехмерное пространство), которая выглядит как бассейн, только две из его стенок встречаются в части α = β = 0 (и отсутствуют две стенки), как функция параметров формы α и β бета-распределения. Две смежные стенки этой двумерной поверхности образованы формируются формы α и β, приближающиеся к сингулярным функциям (тригамма-функции) при α, β → 0. У нее нет стенок для α, β → ∞, потому что в этом случае Определитель информационной матрицы Фишера для бета -распределения стремится к нулю.
В следующем разделе будет показана априорная вероятность априорной вероятности (при умножении на биномиальную функцию правдоподобия), которые являются промежуточными между результатами апостериорной вероятности априорных вероятностей Холдейна и Байеса.
Априор Джеффри может быть трудно получить аналитически, а в некоторых случаях его просто не существует (даже для простых функций распределения такого как асимметричное треугольное распределение ). Бергер, Бернардо и Сан в статье 2009 года определили эталонное априорное распределение вероятностей (в отличие от априорного Джеффри) существует для асимметричного треугольного распределения. Они не могут получить выражение в своей замкнутой форме для априорной ссылки, что она идеально соответствует (собственному) априорному

где θ - переменная вершины для асимметричного треугольного распределения с опорой [0, 1] (соответствующие следующие значения параметров в статье Википедии о треугольном распределении : вершина c = θ, левый конец a = 0 и правый конец b = 1). Бергер и др. также приводят эвристический аргумент, что Бета (1 / 2,1 / 2) действительно может быть точной априорной Бергера - Бернардо - Сан для асимметричного треугольного распределения. Следовательно, бета (1 / 2,1 / 2) не только априор Джеффриса для распределений Бернулли и биномиальных распределений, но также, по-видимому, является эталоном Бергера – Бернардо – Сан для асимметричного треугольного распределения (для которого априор Джеффриса не Существуют), распределение, используемое в управлении проектами, и PERT анализ для описания стоимости и продолжительности задач проекта.
Кларк и Бэррон доказывают, что среди непрерывных положительных априоров Джеффрис априор (если он существует) асимптотически максимизирует взаимную информацию Шеннона между выборкой размера n и параметром, и поэтому Джеффрис априор является самый неинформативный априор (измерение информации как информации Шеннона). Доказательство основывается на исследовании расхождения Кульбака – Лейблера между функциями плотности вероятности для случайных величин iid.
Влияние различных вариантов априорной вероятности на апостериорное бета-распределение
Если выборки взяты из совокупности случайной величины X, что приводит к s успехам и f неудачам в "n" Бернулли испытывает n = s + f, затем функцию правдоподобия для параметров s и f при x = p (обозначение x = p в приведенных ниже выражениях подчеркнет, что область x обозначает значение параметра p в биномиальном распределении) является следующим биномиальным распределением :

Если представления о априорной вероятности информации достаточно хорошо аппроксимируются бета-распределением с параметрами α Prior и β Prior, то:

Согласно теореме Байеса для непрерывного пространства событий, апостериорная вероятность дается как произведение априорной вероятности и функции правдоподобия (с учетом свидетельства s и f = n - s), нормализованных так, чтобы площадь под кривой равнялась один след ующим образом:
![{\ displaystyle {\ begin {выровнено } \ operatorname {posteriorprobability} (x = p \ mid s, ns) \\ [6pt] = {} {\ frac {\ operatorname {PriorProbability} (x = p; \ alpha \ operatorname {Prior}, \ beta \ operatorname {PriorProbability}) {\ mathcal {L}} (s, f \ mid x = p)} {\ int _ {0} ^ {1} \ operatorname {PriorProbability} (x = p; \ alpha \ operatorname { Prior}, \ beta \ operatorname {Prior}) {\ mathcal {L}} (s, f \ mid x = p) dx}} \\ [6pt] = {} {\ frac {{n \ choose s} x ^ {s + \ alpha \ operatorname {Prior} -1} (1-x) ^ {n-s + \ beta \ operatorname {Prior} -1} / \ mathrm {B} (\ alpha \ operatorname {Prior}, \ beta \ operatorname {Prior})} {\ int _ {0} ^ {1} \ left ({n \ choose s} x ^ {s + \ alpha \ operatorname {Pri или} -1} (1-x) ^ {n-s + \ beta \ operatorname {Prior} -1} / \ mathrm {B} (\ alpha \ operatorname {Prior}, \ beta \ operatorname {Prior}) \ right) dx}} \\ [6pt] = {} {\ frac {x ^ {s + \ alpha \ operatorname {Prior} -1} (1-x) ^ {n-s + \ beta \ operatorname {Prior} -1 }} {\ int _ {0} ^ {1} \ left (x ^ {s + \ alpha \ operatorname {Prior} -1} (1-x) ^ {n-s + \ beta \ operatorname {Prior} -1} \ right) dx}} \\ [6pt] = {} {\ frac {x ^ {s + \ alpha \ operatorname {Prior} -1} (1-x) ^ {n-s + \ beta \ operatorname {Prior} -1}} {\ mathrm {B} (s + \ alpha \ operatorname {Prior}, n-s + \ beta \ operatorname {Prior})}}. \ End {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3604b1c47e226d5ce09894b1a3b372fba8c9f8a3)
Биномиальный коэффициент

появляется как в числителе, так и в знаменателе апостериорной вероятности, и он не зависит от переменной интегрирования x, следовательно, он сокращается и не имеет отношения к окончательному результату. Точно так же нормализующий коэффициент для априорной вероятности, бета-функция B (αPrior, βPrior) отменяется, и это не имеет значения для окончательного результата. Такой же результат апостериорной вероятности может быть получен, если использовать ненормированный априор

, потому что все нормализующие множители сокращаются. Некоторые авторы (включая самого Джеффриса), таким образом, используют ненормализованную априорную формулу, поскольку константа нормализации сокращается. Числитель апостериорной вероятности оказывается просто (ненормированным) произведением априорной вероятности и функции правдоподобия, а знаменатель - ее интегралом от нуля до единицы. Бета-функция в знаменателе B (s + α Prior, n - s + β Prior) появляется как нормировочная константа, чтобы гарантировать, что полная апостериорная вероятность равна единице.
Отношение s / n количества успешных испытаний к общему количеству испытаний является достаточной статистикой в биномиальном случае, что актуально для следующих результатов.
Для априорной вероятности Байеса (Beta (1,1)) апостериорная вероятность равна:
Для Jeffreys 'ранее вероятность (бета (1 / 2,1 / 2)), апостериорная вероятность равна:
и для Haldane априорная вероятность (Бета (0,0)), апостериорная вероятность равна:
Из приведенных выше выражений следует, что для s / n = 1/2) все три вышеупомянутые априорные вероятности приводят к идентичное расположение для апостериорной вероятности, среднее значение = режим = 1/2. Для s / n < 1/2, the mean of the posterior probabilities, using the following priors, are such that: mean for Bayes prior>среднее значение для априорного Джеффри>среднее для априорного значения Холдейна. Для s / n>1/2 порядок этих неравенств меняется на противоположный, так что априорная вероятность Холдейна дает наибольшее апостериорное среднее. Априорная вероятность Холдейна Beta (0,0) приводит к апостериорной плотности вероятности со средним значением (ожидаемым значением для вероятности успеха в «следующем» испытании), идентичным отношению s / n количества успехов к общему количеству. испытаний. Таким образом, априор Холдейна дает апостериорную вероятность с ожидаемым значением в следующем испытании, равным максимальной вероятности. Априорная вероятность Байеса Beta (1,1) приводит к апостериорной плотности вероятности с модой, идентичной отношению s / n (максимальное правдоподобие).
В случае, если 100% испытаний были успешными s = n, априорная вероятность Байеса Beta (1,1) приводит к апостериорному ожидаемому значению, равному правилу последовательности (n + 1) / (n + 2), в то время как предыдущая бета-версия Холдейна (0,0) дает апостериорное ожидаемое значение 1 (абсолютная уверенность в успехе в следующем испытании). Априорная вероятность Джеффри дает апостериорное ожидаемое значение, равное (n + 1/2) / (n + 1). Перкс (стр. 303) указывает: «Это обеспечивает новое правило преемственности и выражает« разумную »позицию, которую следует занять, а именно: после непрерывной серии n успехов мы предполагаем вероятность следующего испытания, эквивалентную предположению что мы примерно на полпути к средней пробежке, т. е. что мы ожидаем неудачи один раз за (2n + 2) испытаний. Правило Байеса – Лапласа подразумевает, что мы приближаемся к концу средней пробежки или что мы ожидаем неудачи один раз в (n + 2) испытаниях. Сравнение явно свидетельствует в пользу нового результата (то, что теперь называется приором Джеффри) с точки зрения «разумности» ».
И наоборот, в случае, если 100% испытаний закончились неудачей ( s = 0), априорная вероятность Байеса Beta (1,1) приводит к апостериорному ожидаемому значению успеха в следующем испытании, равному до 1 / (n + 2), в то время как предшествующая бета-версия Холдейна (0,0) дает апостериорное ожидаемое значение успеха в следующем испытании, равное 0 (абсолютная уверенность в неудаче в следующем испытании). Априорная вероятность Джеффри приводит к апостериорному ожидаемому значению успеха в следующем испытании, равному (1/2) / (n + 1), на что Перкс (стр. 303) указывает: «это гораздо более отдаленный результат, чем результат Байеса. -Результат Лапласа 1 / (n + 2) ".
Джейнс ставит под сомнение (для унифицированного априорного бета (1,1)) использование этих формул для случаев s = 0 или s = n, поскольку интегралы не сходятся (бета (1,1) неправильный априор для s = 0 или s = n). На практике условия 0
Как отмечалось в разделе о правиле последовательности, К. Пирсон показал, что после n успехов в n попытках апостериорная вероятность (на основе распределения Байеса-Бета (1,1) как априорная вероятность) того, что следующие (n + 1) испытания будут успешными, равна 1/2 независимо от значения n. Основываясь на бета-распределении Холдейна (0,0) как априорной вероятности, эта апостериорная вероятность равна 1 (абсолютная уверенность в том, что после n успехов в n испытаниях все следующие (n + 1) испытания будут успешными). Перкс (стр. 303) показывает, что для так называемых апоров Джеффри эта вероятность равна ((n + 1/2) / (n + 1)) ((n + 3/2) / (n + 2))... (2n + 1/2) / (2n + 1), что для n = 1, 2, 3 дает 15/24, 315/480, 9009/13440; быстро приближается к предельному значению  , когда n стремится к бесконечности. Перкс отмечает, что то, что сейчас известно как априор Джеффри: «явно более« разумно », чем либо результат Байеса-Лапласа, либо результат альтернативного правила (Холдейна), отвергнутого Джеффрисом, который дает определенность как вероятность. Он явно обеспечивает намного лучшее соответствие с процессом индукции. Является ли он «абсолютно» разумным для этой цели, то есть достаточно ли он велик, без абсурдности достижения единства, - это вопрос, который должны решать другие. Но необходимо понимать, что результат зависит от предположения о полном безразличии и отсутствии знаний до проведения эксперимента по отбору проб ».
, когда n стремится к бесконечности. Перкс отмечает, что то, что сейчас известно как априор Джеффри: «явно более« разумно », чем либо результат Байеса-Лапласа, либо результат альтернативного правила (Холдейна), отвергнутого Джеффрисом, который дает определенность как вероятность. Он явно обеспечивает намного лучшее соответствие с процессом индукции. Является ли он «абсолютно» разумным для этой цели, то есть достаточно ли он велик, без абсурдности достижения единства, - это вопрос, который должны решать другие. Но необходимо понимать, что результат зависит от предположения о полном безразличии и отсутствии знаний до проведения эксперимента по отбору проб ».
Ниже приведены дисперсии апостериорного распределения, полученные с помощью этих трех априорных распределений вероятностей:
для априорной вероятности Байеса (Beta (1,1)), апостериорная дисперсия:

для Джеффриса априорная вероятность (бета (1 / 2,1 / 2)), апостериорная дисперсия составляет:

и для априорной вероятности Холдейна (бета (0,0)) апостериорная дисперсия составляет:

Итак, как заметил Силви, для больших n дисперсия мала и, следовательно, апостериорное распределение сильно концентрировано, тогда как предполагаемое априорное распределение было очень размытым. Это согласуется с тем, на что можно было бы надеяться, поскольку смутные априорные знания преобразуются (посредством теоремы Байеса) в более точные апостериорные знания посредством информативного эксперимента. Для малых n априорные результаты Haldane Beta (0,0) дают наибольшую апостериорную дисперсию, тогда как априорные результаты Bayes Beta (1,1) дают более концентрированные апостериорные отклонения. Предварительная бета-версия Джеффри (1 / 2,1 / 2) дает апостериорную дисперсию между двумя другими. По мере увеличения n дисперсия быстро уменьшается, так что апостериорная дисперсия для всех трех априорных значений сходится примерно к одному и тому же значению (приближаясь к нулевой дисперсии при n → ∞). Вспоминая предыдущий результат о том, что априорная вероятность Бета (0,0) Холдейна приводит к апостериорной плотности вероятности со средним значением (ожидаемым значением для вероятности успеха в следующем «испытании»), идентичным отношением s / n количества успехов к общему количеству испытаний, из приведенного выше выражения следует, что также предварительная бета Холдейна (0,0) приводит к апостериорной дисперсии, идентичной дисперсии, выраженной в терминах макс. оценка правдоподобия s / n и размер выборки (в разделе «Дисперсия»):

со средним значением μ = s / n и выборки ν = n.
В байесовском выводе использование предшествующего распределения Бета (αPrior, βPrior) перед биномиальным распределением эквивалентным добавлением (αPrior - 1) псевдонаблюдений за «успехом» и (βPrior - 1) псевдонаблюдения «неудач» относительно фактического количества ожидаемых успехов и неудач, оценка результатов биномиального распределения по доле успехов как для реального, так и для псевдонаблюдений. Единообразный априорный бета (1,1) не пере (или вычитает) какие-либо псевдо-наблюдения, поскольку для бета (1,1) следует, что (αPrior - 1) = 0 и (βPrior - 1) = 0. Априор Холдейна Бета (0,0) вычитает по одному псевдонаблюдению из каждого, а предыдущая бета Джеффри (1 / 2,1 / 2) вычитает 1/2 псевдонаблюдения успеха и равное количество неудач. Это вычитание имеет эффект сглаживания апостерического распределения. Если доля успехов не составляет 50% (s / n 1/2), значения αPrior и βPrior меньше 1 (и, следовательно, отрицательные (αPrior - 1) и (βPrior - 1)) благоприятствуют разреженности, т. Е. Распределения, в которых параметр p ближе к 0 или 1. Фактически, αPrior и βPrior между 0 и 1 при совместной работе функционируют как параметр концентрации.
На прилагаемых графиках показаны апостериорные функции плотности вероятности для размеров выборки n. ∈ {3,10,50}, успехи s ∈ {n / 2, n / 4} и бета (αPrior, βPrior) ∈ {Beta (0,0), Beta (1 / 2,1 / 2), Beta ( 1,1)}. Также имели место случаи для n = {4,12,40}, успеха s = {n / 4} и Beta (αPrior, βPrior) ∈ {Beta (0,0), Beta (1 / 2,1 / 2)., Бета (1,1)}. Первый график показывает симметричные случаи для успехов s ∈ {n / 2} со средним значением = mode = 1/2, а второй график показывает искаженные случаи s ∈ {n / 4}. Изображения показывают, что существует небольшая разница между апостериорными значениями для апостериорного исследования с размером выборки 50 (представляет собой более выраженным пиком около p = 1/2). Значительные различия для очень малых размеров выборки (в частности, для более плоского распределения для вырожденного случая размера выборки = 3). Таким образом, искаженные случаи с успехом = {n / 4} демонстрируют больший эффект от выбора априорного критерия при небольшом размере выборки, чем симметричные случаи. Для симметричного распределения априорное бета-распределение Байеса (1,1) дает наиболее "пиковые" и самые высокие апостериорные распределения, а априорное бета-распределение Холдейна (0,0) дает наиболее плоское и наименьшее пиковое распределение. Между ними находится предыдущая бета-версия Jeffreys (1/2, 1/2). Для почти симметричных, но не слишком перекошенных распределений эффект априорных значений аналогичен. Для очень небольшого размера выборки (в данном случае для размера выборки 3) и асимметричного распределения (в этом примере для s ∈ {n / 4}) априор Холдейна может привести к обратному J-образному распределению с сингулярностью на левый конец. Однако это происходит только в вырожденных случаях (в этом примере n = 3 и, следовательно, s = 3/4 < 1, a degenerate value because s should be greater than unity in order for the posterior of the Haldane prior to have a mode located between the ends, and because s = 3/4 is not an integer number, hence it violates the initial assumption of a binomial distribution for the likelihood) and it is not an issue in generic cases of reasonable sample size (such that the condition 1 < s < n − 1, necessary for a mode to exist between both ends, is fulfilled).
В главе 12 (стр. 385) своей книги Джейнс утверждает, что Холдейн предшествовал бета-версии (0, 0) предварительное состояние знания о полном незнании, когда мы даже не уверены, физически возможно, чтобы эксперимент привел к успеху или неудаче, в то время как байесовский (унифицированный) априорный бета (1,1), если каждый знает, что возможны оба бинарных исхода. Джейнс заявляет: «интерпретирующий предшествующий алгоритм Байеса-Лапласа (бета (1,1)) как описывающий не состояние полного невежества, а состояние знания, в котором мы наблюдали один успех и один неудача... Хотя бы один успех и одну неудачу, тогда мы узнаем, что эксперимент является истинным бинарным экспериментом в смысле физических возможностей ». Джейнс специально не обсуждает предыдущую бета-версию Джеффриса (1 / 2,1 / 2) (Обсуждение Джейнсом« Приора Джеффриса »на стр. 181, 423 иорный в главе 12 книги Джейнса вместо этого упомянутый неподходящий, не-ни преобразованный, предшествующий "1 / p dp", введенный Джеффрисом в издании его книги 1939 года, как он представил то, что теперь известно как апри инвариант Джеффриса: квадратный корень из определителя информационной матрицы Фишера. «1 / p» является априорным инвариантом Джеффриса (1946) для экспоненциального распределения, а не для распределений Бернулли или биномиальных распределений). Однако из вышеприведенного обсуждения следует, что бета Джеффриса (1 / 2,1 / 2) предшествует состоянию знаний, промежуточному между бета-версией Холдейна (0,0) и бета-версией Байеса (1,1).
Аналогичным образом Карл Пирсон в своей книге 1892 года Грамматика науки (стр. 144 издания 1900 г.) утверждал, что байесовская (бета (1,1) форма Пирсон писал: «Это не меньшее, единственное предположение, которое мы, кажется, сделали, - это то, что мы ничего». природа, рутина и аномия (от греческого ανομία, а именно: a- «без» и nomos «закон») должны рассматриваться как соответствующие вероятности возникновения. оно включает в себя знание о природе, которое мы не обладаем. Мы используем наш опыт построения и действия монет в целом, чтобы утверждать, что орел и решка равноверны, но мы не имеем права утверждать перед опытом, что, поскольку мы ничего не знаем о природа, распорядок и нарушение равновероятны. ашем невежестве мы должны рассмотреть, прежде чем испытать, что natu Он может состоять из всех процедур, всех аномалий (безнормальности) или их смеси в любых пропорциях, и все они равновероятны. Какая из этих конституций после опыта наиболее вероятной, должна явноеть от того, каким был этот опыт ».
Если имеется достаточно данных выборки, а апостериорная вероятностная мода не находится одной из крайностей области (x = 0 или x = 1), три априора Байеса (бета (1,1)), Джеффриса (бета (1 / 2,1 / 2)) и Холдейна (бета (0, 0)) должны давать аналогичные плотности апостериорной вероятности. В противном случае, как указывает Гельман и др. (Стр. 65), «если доступно так мало данных, что выбор неинформативного априорного распределения имеет значение, необходимо указать соответствующую информацию в предварительном распределении», или, как указывает Бергер (стр. 125), «когда разные разумные априорные значения имеют разные разные» ответы, можно ли утверждать, что существует один ответ? Не лучше ли признать, что существует научная неопределенность, а вывод зависит от предшествующих убеждений? »
.
Возникновение и применение
Статистика заказов
Бета-распределение имеет важное применение в теории порядка . Основной результат состоит в том, что распределение k-го наименьшего из выборки размера n из непрерывного равномерного распределения имеет бета-распределение. Этот результат суммируется как:

Из этого и применения теории, относящейся к интегральному преобразованию вероятностей, можно получить распределение любой статистики отдельного порядка из непрерывного распределения.
Субъективная логика
В стандартной логике признания либо истинными, либо ложными. В отличие от этого, субъективная логика предполагает, что люди не могут определять с абсолютной точностью. Уверенность в том, является ли утверждением о реальном мире абсолютно верным или ложным. В субъективной логике апостериорные оценки вероятности двоичных событий могут быть представлены бета-распределениями.
Вейвлет-анализ
A вейвлет является волнообразным колебание с амплитудой , которое начинается с нуля, увеличивается, а снова уменьшается до нуля. Обычно это можно представить как «кратковременное колебание», которое быстро затухает. Вейвлеты Программу извлечения информации из различных типов данных, включая, но не ограничиваясь, аудиосигналы и изображения. Таким образом, вейв использует специально созданные для того, чтобы получить свойства, которые делают их полезными для обработки сигналов. Вейвлеты локализованы как по времени, так и по частоте, тогда как стандартное преобразование Фурье локализовано только по частотам. Таким образом, стандартные преобразования Фурье применимы только к стационарным процессам, а вейвлеты применимы к не- стационарным процессам. Непрерывные вейвлеты могут быть построены на основе бета-распределения. Бета-вейвлеты можно рассматривать как мягкую разновидность которые вейвлетов Хаара, форма точно настраивает установленные формы α и β.
Управление проектом: моделирование стоимости и расписания
Бета-рейтинг может быть для моделирования событий, которые имеют место в пределах интервала, определяемого минимальным и максимальным числом. По этой причине бета-распределение - вместе с треугольным распределением - широко используется в PERT, метод критического пути (CPM), Совместное моделирование графика затрат (JCSM) и системы управления проектами / контроля для описания времени до завершения и стоимости задачи. В управлении проектами широко используются стенографические вычисления для оценки среднего и стандартного отклонения бета-распределения:

где a - минимум, c - максимум, а b - наиболее вероятное значение (режим для α>1 и β>1).
Приведенная выше оценка для mean  известен как PERT трехточечная оценка и является точным для любого из следующих значений β (для произвольного α в пределах этих диапазонов):
известен как PERT трехточечная оценка и является точным для любого из следующих значений β (для произвольного α в пределах этих диапазонов):
- β = α>1 (симметричный случай) с стандартным отклонением
 , асимметрия = 0, и избыточный эксцесс =
, асимметрия = 0, и избыточный эксцесс = 
или
- β = 6 - α для 5>α>1 (наклонный случай) со стандартным отклонением

асимметрия =  и избыточный эксцесс =
и избыточный эксцесс = 
Приведенная выше оценка для стандартного отклонения σ (X) = (c - a) / 6 точна для любого из следующих значения α и β:
- α = β = 4 (симметричный) с асимметрией, = 0 и избыточным эксцессом = −6/11.
- β = 6 - α и
 (правосторонний, положительный перекос) с перекосом
(правосторонний, положительный перекос) с перекосом  и избыточный эксцесс = 0
и избыточный эксцесс = 0 - β = 6 - α и
 (левосторонний, отрицательный перекос) с перекосом
(левосторонний, отрицательный перекос) с перекосом  и избыточный эксцесс = 0
и избыточный эксцесс = 0

В противном случае они могут быть плохой аппроксимацией для бета-распределений с другими значениями α и β, демонстрируя средние ошибки 40% в среднем и 549% в дисперсии.
Вычислительные методы
Создание бета -распределенные случайные величины
Если X и Y независимы, с  и
и  , затем
, затем

Итак, один из алгоритмов генерации бета-вариаций - это генерировать  , где X - гамма-вариация с параметрами (α, 1), а Y - независимая гамма-вариация с параметры (β, 1). Фактически, здесь и
, где X - гамма-вариация с параметрами (α, 1), а Y - независимая гамма-вариация с параметры (β, 1). Фактически, здесь и  независимы, и
независимы, и  . Если
. Если  и
и  не зависит от
не зависит от  и
и  , тогда
, тогда  и
и  не зависит от . Это показывает, что произведение независимых
не зависит от . Это показывает, что произведение независимых  и
и  случайные величины - это a
случайные величины - это a  случайная величина.
случайная величина.
Кроме того, статистика k-го порядка из n равномерно распределенных переменных равна  , поэтому альтернативой, если α и β являются малыми целыми числами, является генерация α + β - 1 однородной переменной и выбор α-го наименьшего значения.
, поэтому альтернативой, если α и β являются малыми целыми числами, является генерация α + β - 1 однородной переменной и выбор α-го наименьшего значения.
Другой способ создания бета-распределения - это модель урны Pólya. Согласно этому методу, один запуск с «урной» с использованием α «bl Отметьте« шары и β »белые шары и проведите равномерную розыгрыш с заменой. При каждой попытке добавлен дополнительный шар в соответствии с цветом последнего выпавшего шара.
Также можно использовать выбор с обратным преобразованием.
История
 Карл Пирсон проанализировал бета- распределение как решение Тип I распределений Пирсона
Карл Пирсон проанализировал бета- распределение как решение Тип I распределений Пирсона Первое систематическое современное обсуждение бета-распределения, вероятно, связано с Карлом Пирсоном FRS (27 марта 1857 г. - 27 апреля 1936 г.), влиятельный англичанин математик, которому приписывают создание дисциплин математической. В статьях Пирсона бета-формула сформулировано как решениедифференциального уравнения: Распределение Пирсона типа I, обычное Полностью идентичен, за исключением произвольного сдвига и масштабирования (бета-распределения и распределения Пирсона типа I всегда можно выровнять путем правильного выбора параметров). Фактически, в нескольких английских книгах и журналах статьях за несколько десятилетий до Второй мировой войны было принято называть бета-распределением типа I Пирсона. Уильям П. Элдертон (1877–1962) в своей монографии 1906 года «Частотные кривые и корреляция» далее анализирует бета-распределение как распределение типа I Пирсона, включая полное обсуждение метода моментов для случая четырех параметров., и диаграммы (что Элдертон называет) U-образной, J-образной, скрученной J-образной формы, формы «треуголка», горизонтальных и наклонных прямых ящиков. Элдертон написал: «Я в основном в долгу перед профессором Пирсоном, но это такая задолженность, за которую невозможно выразить официальную благодарность». Элдертон в своей монографии 1906 года предоставляет впечатляющий объем информации о бета-распределении, включая уравнения для происхождения, распределения в качестве режима, а также для других распределений Пирсона: типов с I по VII. Элдертон также включил ряд приложений, включая одно («II») по бета- и гамма-функциям. В более поздних изданиях Элдертон добавил уравнения происхождения, определенных в качестве среднего, и анализ распределений Пирсона с VIII по XII.
Как отмечают Боуман и Шентон, «Фишер и Пирсон разошлись во мнениях относительно подхода к оценке (фактора), в частности, в отношении (метода Пирсона) моментов и (метода Фишера) максимальной вероятности в случае бета-распределения»., Согласно Боуману и Шентону, «случай, когда модель типа I (бета-распределение) оказалась в центре споров, было чистой случайностью». Рональд Фишер ( 17 февраля 1890 г. - 29 июля 1962 г.) был одним из гигантов статистики в первой половине 20-го века, и его давний публичный конфликт с Карлом Пирсоном можно проследить в некоторых статьях. Бета-распределения и критики Фишером метода моментов Пирсона как произвольного см. Статью Пирсона «Метод моментов и метод максимального правдоподобия» (опубликованная через три года после его выхода на пенсию из Университетского колледжа). разделена между Фишером и сыном Пирсона Эгоном), в котором Пирсон пишет: «Я читал (статья Кошая в Журнале Королевского статистического общества, 1933 г.), которая, насколько мне известно, является единственным случаем в настоящее время опубликовано о методе профессора Фишера. К моему удивлению, этот метод зависит от сначала расчета констант частоты кривой с помощью метода моментов, а затем наложения на них, что Фишер называет "методом правдоподобия" дальнейшее приближение для получения того, что он использует, он, таким образом, получит «более эффективные значения» констант кривой ».
Трактат Дэвида и Эдвардса по истории статистики цитирует первое современное рассмотрение бета-распределения в 1911 году с использованием обозначения бета, которое стало стандартным благодаря Коррадо Джини, итальянцу статистик, демограф и социолог, разработавшие коэффициент Джини. Н.Л.Джонсон и С.Коц в своей всеобъемлющей и очень информативной монографии о ведущих исторических личностях в статистических науках называют Коррадо Джини «ранним байесовским... который занимался проблемой выявления параметров начального бета-распределения, выделяя методы, которые предвосхитили появление так называемого эмпирического байесовского подхода ». Байес в посмертной статье, опубликованной в 1763 году Ричардом Прайсом, получил бета-распределение как плотность вероятности успеха в испытаниях Бернулли (см. Раздел «Приложения, байесовский вывод» "в этой статье), но в статье не анализируются какие-либо моменты бета-распределения и не обсуждаются какие-либо его свойства.
Ссылки
Внешние ссылки
 | Викискладе есть носители, связанные с Бета-распределением. |
- «Бета-распределением» Фионой Маклахлан, Wolfram Demonstrations Project, 2007.
- Бета-распространение - Обзор и пример, xycoon.com
- Бета-распространение, brighton-webs.co.uk
- Видео о бета-распространении, exstrom.com
- , Энциклопедия математики, EMS Press, 2001 [1994]
- Вайсштейн, Эрик У. «Бета-распределение». MathWorld.
- Статистика Гарвардского университета 110 Лекция 23 «Бета-распространение», профессор Джо Блитцштейн



 Анимация бета-распределения для различных значений его параметров.
Анимация бета-распределения для различных значений его параметров.  CDF для симметричного бета-распределения в зависимости от x и α = β
CDF для симметричного бета-распределения в зависимости от x и α = β  CDF для искаженного бета-распределения в зависимости от x и β = 5α
CDF для искаженного бета-распределения в зависимости от x и β = 5α 







 Режим для бета-распределения 1 ≤ α ≤ 5 и 1 ≤ β ≤ 5
Режим для бета-распределения 1 ≤ α ≤ 5 и 1 ≤ β ≤ 5  Медиана для бета-распределения для 0 ≤ α ≤ 5 и 0 ≤ β ≤ 5
Медиана для бета-распределения для 0 ≤ α ≤ 5 и 0 ≤ β ≤ 5  (Среднее - Медиана) для бета-распределения по сравнению с альфа и бета от 0 до 2
(Среднее - Медиана) для бета-распределения по сравнению с альфа и бета от 0 до 2 ![Abs [(Median-Appr.) / Median] для бета-распределения для 1 ≤ α ≤ 5 и 1 ≤ β ≤ 5](http://upload.wikimedia.org/wikipedia/commons/thumb/a/af/Relative_Error_for_Approximation_to_Median_of_Beta_Distribution_for_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg/325px-Relative_Error_for_Approximation_to_Median_of_Beta_Distribution_for_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg)
![Abs [ (Median-Appr.) / (Mean-Mode)] для бета-распределения для 1≤α≤5 и 1≤β≤5](http://upload.wikimedia.org/wikipedia/commons/thumb/e/e8/Error_in_Median_Apprx._relative_to_Mean-Mode_distance_for_Beta_Distribution_with_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg/325px-Error_in_Median_Apprx._relative_to_Mean-Mode_distance_for_Beta_Distribution_with_alpha_and_beta_from_1_to_5_-_J._Rodal.jpg)
 Среднее для бета-распределения для 0 ≤ α ≤ 5 и 0 ≤ β ≤ 5
Среднее для бета-распределения для 0 ≤ α ≤ 5 и 0 ≤ β ≤ 5  (Среднее - GeometricMean) для бета-распределения по сравнению с α и β от 0 до 2, форма асимметрии между α и β для среднего геометрического
(Среднее - GeometricMean) для бета-распределения по сравнению с α и β от 0 до 2, форма асимметрии между α и β для среднего геометрического  Средние геометрические для бета-распределения Фиолетовый = G (x), желтый = G (1 - x), меньшие значения α и β спереди
Средние геометрические для бета-распределения Фиолетовый = G (x), желтый = G (1 - x), меньшие значения α и β спереди  Средние геометрические для бета-распределения. фиолетовый = G (x), желтый = G (1 - x), большие значения α и β впереди
Средние геометрические для бета-распределения. фиолетовый = G (x), желтый = G (1 - x), большие значения α и β впереди  Информация Фишера I (a, a) для α = β по сравнению с диапазоном (c - a) и показателем степени α = β
Информация Фишера I (a, a) для α = β по сравнению с диапазоном (c - a) и показателем степени α = β  Информация Фишера I (α, a) для α = β, в зависимости от диапазона (c - a) показателя степени α = β
Информация Фишера I (α, a) для α = β, в зависимости от диапазона (c - a) показателя степени α = β 

 априорная вероятность Джеффри для бета-распределения: квадратный корень из определителя матрицы информации Фишера :
априорная вероятность Джеффри для бета-распределения: квадратный корень из определителя матрицы информации Фишера :  плотности апостериорного бета с образцами, имеющими успех = "s", отказ = "f" из s / (s + f) = 1/2 и s + f = {3,10,50} на основе 3 различных априорных функций вероятности: Холдейна (бета (0,0), Джеффриса (бета (1 / 2,1 / 2)) и Байеса (Бета (1,1)). Изображение показывает, что существует небольшая разница между апостериорными значениями для апостериорных при размере выборки 50 (с более выраженным пиком около p = 1/2). Значительные различия проявляются для очень малых размеров выборки 3
плотности апостериорного бета с образцами, имеющими успех = "s", отказ = "f" из s / (s + f) = 1/2 и s + f = {3,10,50} на основе 3 различных априорных функций вероятности: Холдейна (бета (0,0), Джеффриса (бета (1 / 2,1 / 2)) и Байеса (Бета (1,1)). Изображение показывает, что существует небольшая разница между апостериорными значениями для апостериорных при размере выборки 50 (с более выраженным пиком около p = 1/2). Значительные различия проявляются для очень малых размеров выборки 3  Плотность апостериорного бета с успешными образцами = "s", неудача = "f" из s / (s + f) = 1/4, и s + f ∈ {3,10,50}, на основе трех различных априорных функций вероятности: Холдейна (бета (0,0), Джеффриса (бета (1 / 2,1 / 2)) и Байеса (бета (1, 1)). Изображение показывает, что существует небольшая разница между апостерическими значениями для апостериорной выборки с размером выборки 50 (с более выраженным пиком p = 1/4). = 3, в этом вырожденном и маловероятном случае априор Холдейна дает обратную J-образную форму с модой при p = 0 вместо p = 1/4. Если имеется достаточно данных выборки , три априорных значения Байеса (бета (1, 1)), Джеффриса (бета (1 / 2,1 / 2)) и Холдейна (бета (0,0)) должны дать аналогичную апостериорную вероятность плотности.
Плотность апостериорного бета с успешными образцами = "s", неудача = "f" из s / (s + f) = 1/4, и s + f ∈ {3,10,50}, на основе трех различных априорных функций вероятности: Холдейна (бета (0,0), Джеффриса (бета (1 / 2,1 / 2)) и Байеса (бета (1, 1)). Изображение показывает, что существует небольшая разница между апостерическими значениями для апостериорной выборки с размером выборки 50 (с более выраженным пиком p = 1/4). = 3, в этом вырожденном и маловероятном случае априор Холдейна дает обратную J-образную форму с модой при p = 0 вместо p = 1/4. Если имеется достаточно данных выборки , три априорных значения Байеса (бета (1, 1)), Джеффриса (бета (1 / 2,1 / 2)) и Холдейна (бета (0,0)) должны дать аналогичную апостериорную вероятность плотности.  Апостериорные плотности бета с образцами имея успех = s, неудача = f из s / (s + f) = 1/4 и s + f ∈ {4,12,40}, на основе трех различных априорных функций вероятности: Холдейна (бета (0,0), Джеффри (бета (1/2, 1/2)) и Байеса (бета (1,1)). Изображение показывает, что существует небольшая разница между апостериорными значениями для апостериорной выборки при размере выборки 40 ( Значительные различия проявляются для очень малых размеров выборки
Апостериорные плотности бета с образцами имея успех = s, неудача = f из s / (s + f) = 1/4 и s + f ∈ {4,12,40}, на основе трех различных априорных функций вероятности: Холдейна (бета (0,0), Джеффри (бета (1/2, 1/2)) и Байеса (бета (1,1)). Изображение показывает, что существует небольшая разница между апостериорными значениями для апостериорной выборки при размере выборки 40 ( Значительные различия проявляются для очень малых размеров выборки 


 Карл Пирсон проанализировал бета- распределение как решение Тип I распределений Пирсона
Карл Пирсон проанализировал бета- распределение как решение Тип I распределений Пирсона