
Войти
Функция плотности вероятности 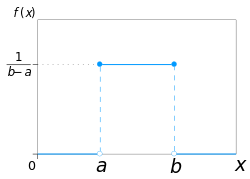 . Использование соглашения о максимуме . Использование соглашения о максимуме | |||
Кумулятивная функция распределения  | |||
| Обозначение |  или или  | ||
|---|---|---|---|
| Параметры | |||
| Поддержка | ![x \ in [a, b]](https://wikimedia.org/api/rest_v1/media/math/render/svg/026357b404ee584c475579fb2302a4e9881b8cce) | ||
![{\ begin {cases} {\ frac {1} {ba}} {\ text {for}} x \ in [a, b] \\ 0 {\ text {else}} \ end {cases}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/648692e002b720347c6c981aeec2a8cca7f4182f) | |||
| CDF | ![{\displaystyle {\begin{cases}0{\text{for }}x<a\\{\frac {x-a}{b-a}}{\text{for }}x\in [a,b]\\1{\text{for }}x>b \ end {cases}}}]( https://wikimedia.org/api/rest_v1/media/ math / render / svg / 2948c023c98e2478806980eb7f5a03810347a568 ) | ||
| Среднее |  | ||
| Медиана | | ||
| Mode | любое значение в  | ||
| Дисперсия |  | ||
| Асимметрия | 0 | ||
| Пример. эксцесс |  | ||
| Энтропия |  | ||
| MGF |  | ||
| CF |  | ||
В теории вероятностей и статистика, непрерывное равномерное распределение или прямоугольное распределение - это семейство симметричных распределений вероятностей. Распределение описывает эксперимент, в котором есть произвольный результат, находящийся в определенных пределах. Границы определяются параметрами a и b, которые являются минимальным и максимальным значениями. Интервал может быть либо закрытым (например, [a, b]), либо открытым (например, (a, b)). Поэтому распределение часто обозначается сокращением U (a, b), где U означает равномерное распределение. Разница между границами определяет длину интервала; все интервалы одинаковой длины на опоре распределения равновероятны. Это максимальное распределение вероятностей энтропии для случайной величины X без каких-либо ограничений, кроме тех, которые содержатся в опоре распределения.
Функция плотности вероятности непрерывного равномерного распределения:
Значения f (x) на двух границах a и b обычно не важны, потому что они не все тер значения интегралов от f (x) dx на любом интервале, от x f (x) dx или от любого более высокого момента. Иногда они выбираются равными нулю, а иногда - 1 / b - a. Последнее уместно в контексте оценки методом максимального правдоподобия. В контексте анализа Фурье можно принять значение f (a) или f (b) равным 1/2 (b - a), поскольку тогда обратное преобразование многих интегралов transforms этой унифицированной функции вернет саму функцию, а не функцию, которая равна «почти везде », то есть за исключением набора точек с нулевой мерой. Кроме того, это согласуется со знаковой функцией , которая не имеет такой двусмысленности.
Графически функция плотности вероятности изображается в виде прямоугольника, где 

В терминах среднего μ и дисперсии σ плотность вероятности может быть записана как:

Для случайной величины X

Найдите
) В графическом представлении функции равномерного распределения [f (x) vs x] площадь под кривая в указанных границах отображает вероятность (заштрихованная область изображена в виде прямоугольника). Для этого конкретного примера, приведенного выше, базой будет 

для случайной величины X
Найти 
 .
.Пример выше предназначен для случая условной вероятности для равномерного распределения: задано 



кумулятивная функция распределения :
Обратное значение:
В обозначении среднего и дисперсии, кумулятивная функция распределения:

, а обратная функция:


из которого мы можем вычислить исходные моменты m k



Для особого случая a = –b, то есть для
![{\ displaystyle f (x) = {\ begin {cases} {\ frac {1} {2b}} {\ text {for}} \ -b \ leq x \ leq b, \\ [8pt] 0 {\ text {else}}, \ end {cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/344403932243231c3df979bec46a73a852a453e7)
функции, создающие момент, сводятся к простой форме

Для случайной величины, следующей за этим распределением, ожидаемое значение тогда m 1 = (a + b) / 2 и дисперсия равна m 2 - m 1 = (b - a) / 12.
Для n ≥ 2 n-й кумулянт равномерного распределения на интервале [-1/2, 1/2] равен B n / n, где B n - n-е число Бернулли.
Ограничение 

One Интересным свойством стандартного равномерного распределения является то, что если u 1 имеет стандартное равномерное распределение, то также и 1-u 1. Это свойство можно использовать, помимо прочего, для создания противоположных переменных. Другими словами, это свойство известно как метод инверсии, где непрерывное стандартное равномерное распределение может использоваться для генерации случайных чисел для любого другого непрерывного распределения. Если u - равномерное случайное число со стандартным равномерным распределением (0,1), то 
Пока те же соглашения соблюдаются в точках перехода, функция плотности вероятности также может выражаться через ступенчатую функцию Хевисайда :

или в терминах функции прямоугольника

В точке перехода знаковой функции нет двусмысленности. Используя соглашение о половине максимума в точках перехода, равномерное распределение может быть выражено в терминах функции знака как:

Среднее значение (первый момент ) распределения:

Второй момент распределения:

Как правило, n-й момент равномерной распределение:

Дисперсия (второй центральный момент ):

Пусть X 1,..., X n будет выборкой iid из U (0,1). Пусть X (k) будет статистикой k-го порядка из этого образца. Тогда распределение вероятностей X (k) является бета-распределением с параметрами k и n - k + 1. Ожидаемое значение равно

Этот факт полезен при построении графиков Q – Q.
Дисперсия

См. также : Статистика по порядку § Распределения вероятностей по статистике по порядку
Вероятность того, что равномерно распределенная случайная величина попадает в любой интервал фиксированной длины, не зависит от местоположения самого интервала (но зависит от размера интервала), пока интервал содержится в опоре распределения.
Чтобы убедиться в этом, если X ~ U (a, b) и [x, x + d] является подинтервалом [a, b] с фиксированным d>0, то
![P \ left (X \ in \ left [x, x + d \ right] \ right) = \ int _ {x} ^ {x + d} {\ frac {\ mathrm {d} y} {ba}} \, = {\ frac {d} {ba}} \, \!](https://wikimedia.org/api/rest_v1/media/math/render/svg/340d0dbad9f439585a005637a3ac06a4d6214f1f) который не зависит от x. Этот факт мотивирует название распределения.
который не зависит от x. Этот факт мотивирует название распределения.Это распределение можно обобщить на более сложные наборы, чем интервалы. Если S является борелевским множеством положительной конечной меры, равномерное распределение вероятностей на S может быть определено путем определения pdf равным нулю вне S и постоянно равным 1 / K на S, где K - это мера Лебега из S.
Учитывая равномерное распределение на [0, b] с неизвестным b, несмещенная оценка минимальной дисперсии (UMVUE) для максимум определяется как

, где m - максимум выборки, а k - размер выборки, выборка без замены t (хотя это различие почти наверняка не имеет значения для непрерывного распределения). Это следует по тем же причинам, что и оценка для дискретного распределения, и может рассматриваться как очень простой случай оценки максимального разнесения. Эта проблема широко известна как проблема немецких танков из-за применения максимальной оценки к оценкам производства немецких танков во время Второй мировой войны.
оценка максимального правдоподобия определяется по формуле:

где m - максимум выборки, также обозначается как 
Метод оценки моментов задается следующим образом:

где 
Средняя точка распределения (a + b) / 2 является как средним, так и медианным значением равномерного распределения. Хотя и выборочное среднее, и выборочная медиана являются несмещенными оценками средней точки, ни одна из них не является столь же эффективной, как выборка среднего диапазона, т. Е. Среднее арифметическое максимум выборки и минимум выборки, которые являются оценкой UMVU средней точки (а также оценкой максимального правдоподобия ).
Пусть X 1, X 2, X 3,..., X n - выборка из U (0, L), где L - максимум совокупности. Тогда X (n) = max (X 1, X 2, X 3,..., X n) имеет плотность
Доверительный интервал тогда для предполагаемого максимума совокупности будет (X (n), X (n) / α), где 100 (1 - α)% - это искомый уровень достоверности. В символах

В статистике, когда p-значение используется в качестве тестовой статистики для простой нулевой гипотезы, и распределение тестовой статистики является непрерывным, тогда значение p равномерно распределено между 0 и 1, если нулевая гипотеза верна.
Вероятности для функции равномерного распределения легко вычислить благодаря простоте формы функции. Следовательно, существуют различные приложения, для которых это распределение может использоваться, как показано ниже: ситуации проверки гипотез, случаи случайной выборки, финансы и т. Д. Более того, в целом эксперименты физического происхождения следуют равномерному распределению (например, выброс радиоактивных веществ частицы ). Однако важно отметить, что в любом приложении есть неизменное предположение, что вероятность попадания в интервал фиксированной длины постоянна.
В области экономики, обычно спрос и пополнение могут не соответствовать ожидаемому нормальному распределению. В результате для лучшего прогнозирования вероятностей и тенденций используются другие модели распределения, такие как процесс Бернулли. Но, согласно Ванке (2008), в конкретном случае исследования времени выполнения для управления запасами в начале жизненного цикла, когда анализируется совершенно новый продукт, униформа распространение оказывается более полезным. В этой ситуации другое распределение может оказаться нежизнеспособным, поскольку нет существующих данных о новом продукте или что история спроса недоступна, поэтому на самом деле нет подходящего или известного распределения. Равномерное распределение было бы идеальным в этой ситуации, поскольку случайная переменная времени выполнения заказа (связанная со спросом) для нового продукта неизвестна, но результаты, вероятно, будут находиться в диапазоне между правдоподобными двумя значениями. Таким образом, время выполнения представляет собой случайную величину. Из модели равномерного распределения можно было рассчитать другие факторы, связанные с временем выполнения заказа, такие как и. Также было отмечено, что равномерное распределение также использовалось из-за простоты вычислений.
Равномерное распределение полезно для выборки из произвольных распределений. Общий метод - это метод выборки с обратным преобразованием, который использует кумулятивную функцию распределения (CDF) целевой случайной величины. Этот метод очень полезен в теоретической работе. Поскольку моделирование с использованием этого метода требует инвертирования CDF целевой переменной, были разработаны альтернативные методы для случаев, когда cdf не известен в закрытой форме. Одним из таких методов является выборка отклонения.
. Нормальное распределение является важным примером, когда метод обратного преобразования неэффективен. Однако существует точный метод, преобразование Бокса – Мюллера, которое использует обратное преобразование для преобразования двух независимых однородных случайных величин в две независимые нормально распределенные случайные переменные.
При аналого-цифровом преобразовании возникает ошибка квантования. Эта ошибка вызвана округлением или усечением. Когда исходный сигнал намного больше, чем один младший значащий бит (LSB), ошибка квантования существенно не коррелирует с сигналом и имеет приблизительно равномерное распределение. RMS-ошибка, следовательно, следует из дисперсии этого распределения.
Есть много приложений, в которых полезно проводить эксперименты по моделированию. Многие языки программирования поставляются с реализациями для генерации псевдослучайных чисел, которые эффективно распределяются в соответствии со стандартным равномерным распределением.
Если u является значением, выбранным из стандартного равномерного распределения, тогда значение a + (b - a) u следует за равномерным распределением, параметризованным a и b, как описано выше.
Хотя исторические истоки концепции равномерного распределения неубедительны, предполагается, что термин «равномерный» возник из концепции равновероятности в играх в кости. (обратите внимание, что игра в кости будет иметь дискретное, а не непрерывное однородное пространство отсчетов). Равновероятность упоминается в Джероламо Кардано Liber de Ludo Aleae, руководстве, написанном в 16 веке и подробно описывающем расширенное вероятностное исчисление применительно к игре в кости.