
Войти
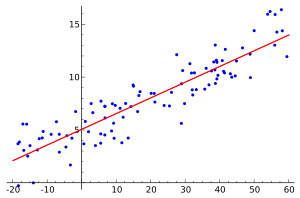 Иллюстрация линейной регрессии на наборе данных. Регрессионный анализ - важная часть математической статистики.
Иллюстрация линейной регрессии на наборе данных. Регрессионный анализ - важная часть математической статистики. Математическая статистика - это применение теории вероятностей, раздела математики, к статистике, в отличие от методов сбора статистических данных. Для этого используются специальные математические методы, включая математический анализ, линейную алгебру, стохастический анализ, дифференциальные уравнения и теорию меры.
Сбор статистических данных связан с планированием исследований, особенно с планом рандомизированных экспериментов и планированием обследований с использованием случайной выборки. Первоначальный анализ данных часто следует протоколу исследования, указанному до его проведения. Данные исследования также можно проанализировать, чтобы рассмотреть вторичные гипотезы, основанные на первоначальных результатах, или предложить новые исследования. Вторичный анализ данных запланированного исследования использует инструменты анализа данных, и процесс его выполнения - математическая статистика.
Анализ данных делится на:
Хотя инструменты анализа данных лучше всего работают с данными рандомизированных исследований, они также применяются к другим типам данных. Например, из естественных экспериментов и наблюдательных исследований, и в этом случае вывод зависит от модели, выбранной статистиком, и поэтому субъективен.
Ниже приведены некоторые из важных тем математической статистики:
Распределение вероятности является функцией, которая присваивает вероятности для каждого измеримого подмножества возможных исходов случайного эксперимента, обследования, или процедур статистического вывода. Примеры можно найти в экспериментах, в которых пространство выборки не является числовым, где распределение было бы категориальным распределением ; эксперименты, пространство выборки которых кодируется дискретными случайными величинами, где распределение может быть задано функцией массы вероятности ; и эксперименты с выборочными пространствами, кодируемыми непрерывными случайными величинами, где распределение может быть задано функцией плотности вероятности. Более сложные эксперименты, например, со случайными процессами, определенными в непрерывном времени, могут потребовать использования более общих вероятностных мер.
Распределение вероятностей может быть одномерным или многомерным. Одномерное распределение дает вероятности того, что одна случайная величина принимает различные альтернативные значения; многомерное распределение ( совместное распределение вероятностей ) дает вероятности случайного вектора - набора из двух или более случайных величин - принимающего различные комбинации значений. Важные и часто встречающиеся одномерные распределения вероятностей включают биномиальное распределение, гипергеометрическое распределение и нормальное распределение. Многомерное нормальное распределение является часто встречающимся многомерным распределением.
Статистический вывод - это процесс вывода на основании данных, которые подвержены случайным изменениям, например ошибкам наблюдений или вариациям выборки. Первоначальные требования к такой системе процедур для вывода и индукции заключаются в том, что система должна давать разумные ответы, когда применяется к четко определенным ситуациям, и что она должна быть достаточно общей для применения в целом ряде ситуаций. Статистические данные используются для проверки гипотез и оценок с использованием выборочных данных. В то время как описательная статистика описывает выборку, выводимая статистика делает выводы о большей совокупности, которую представляет выборка.
Результат статистического вывода может быть ответом на вопрос «что делать дальше?», Где это может быть решение о проведении дальнейших экспериментов или опросов, или о том, как сделать вывод перед реализацией какой-либо организационной или правительственной политики. По большей части, статистический вывод делает предположения о популяциях, используя данные, полученные от интересующей совокупности с помощью некоторой формы случайной выборки. В более общем смысле, данные о случайном процессе получают из его наблюдаемого поведения в течение конечного периода времени. Учитывая параметр или гипотезу, о которой нужно сделать вывод, статистический вывод чаще всего использует:
В статистике, регрессионный анализ представляет собой статистический процесс для оценки взаимосвязи между переменными. Он включает множество способов моделирования и анализа нескольких переменных, когда основное внимание уделяется взаимосвязи между зависимой переменной и одной или несколькими независимыми переменными. В частности, регрессионный анализ помогает понять, как изменяется типичное значение зависимой переменной (или «критериальной переменной»), когда одна из независимых переменных изменяется, в то время как другие независимые переменные остаются неизменными. Чаще всего регрессионный анализ оценивает условное ожидание зависимой переменной с учетом независимых переменных, то есть среднее значение зависимой переменной, когда независимые переменные фиксированы. Реже акцент делается на квантиле или другом параметре местоположения условного распределения зависимой переменной с учетом независимых переменных. Во всех случаях цель оценки является функцией независимых переменных, называемой функцией регрессии. В регрессионном анализе также представляет интерес охарактеризовать изменение зависимой переменной вокруг функции регрессии, которая может быть описана распределением вероятностей.
Разработано много методов проведения регрессионного анализа. Знакомые методы, такие как линейная регрессия, являются параметрическими, поскольку функция регрессии определяется в терминах конечного числа неизвестных параметров, которые оцениваются на основе данных (например, с использованием обычных наименьших квадратов ). Непараметрическая регрессия относится к методам, которые позволяют функции регрессии находиться в заданном наборе функций, который может быть бесконечномерным.
Непараметрическая статистика - это значения, вычисленные на основе данных способом, который не основан на параметризованных семействах распределений вероятностей. Они включают как описательную, так и логическую статистику. Типичными параметрами являются среднее значение, дисперсия и т. Д. В отличие от параметрической статистики, непараметрическая статистика не делает никаких предположений о распределении вероятностей оцениваемых переменных.
Непараметрические методы широко используются для изучения групп населения, которые занимают ранжированный порядок (например, обзоры фильмов, получившие от одной до четырех звезд). Использование непараметрических методов может быть необходимо, когда данные имеют ранжирование, но не имеют четкой числовой интерпретации, например, при оценке предпочтений. Что касается уровней измерения, то непараметрические методы приводят к «порядковым» данным.
Поскольку непараметрические методы делают меньше предположений, их применимость намного шире, чем у соответствующих параметрических методов. В частности, они могут применяться в ситуациях, когда о рассматриваемом приложении известно меньше. Кроме того, из-за использования меньшего количества предположений непараметрические методы более надежны.
Еще одно оправдание использования непараметрических методов - простота. В некоторых случаях, даже когда использование параметрических методов оправдано, непараметрические методы могут быть проще в использовании. Как из-за этой простоты, так и из-за их большей надежности, непараметрические методы рассматриваются некоторыми статистиками как оставляющие меньше места для неправильного использования и недопонимания.
Математическая статистика - это ключевое подразделение статистической дисциплины. Статистические теоретики изучают и улучшают статистические процедуры с помощью математики, а статистические исследования часто поднимают математические вопросы. Статистическая теория опирается на теорию вероятности и принятия решений.
Математики и статистики, такие как Гаусс, Лаплас и К.С. Пирс, использовали теорию принятия решений с распределениями вероятностей и функциями потерь (или функциями полезности ). Теоретико-решающий подход к статистическому выводу был вновь активизирован Абрахамом Вальдом и его преемниками и широко использует научные вычисления, анализ и оптимизацию ; для планирования экспериментов статистики используют алгебру и комбинаторику.
См. Перепечатку Dover, 2004 г.: ISBN 0-486-43912-7