
Войти
Байесовский вывод - это метод статистического вывода, в котором Теорема Байеса используется для обновления вероятности гипотезы по мере появления новых свидетельств или информации. Байесовский вывод - важный метод в статистике, и особенно в математической статистике. Байесовское обновление особенно важно в >Испытательный динамический анализ данных. Байесовский вывод нашел применение в широком спектре деятельности, включая науку, инженерию, философию, медицину, спорт и закон. В философии теории принятия решений байесовский объединить связан с субъективной вероятностью, часто называемой «байесовской вероятностью ».
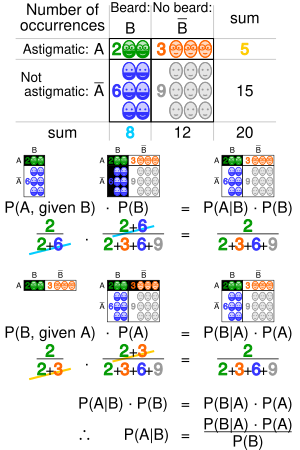 Геометрическая визуализация теоремы Байеса. В таблице значения 2, 3, 6 и 9 дают относительные веса каждого соответствующего условия и случая. Цифры обозначают таблицы, участвующие в каждой метрике, вероятность - это доля каждой затененной цифры. Это показывает, что P (A | B) P (B) = P (B | A) P (A), то есть есть P (A | B) = P (B | A) P (A) / P (B). Аналогичные рассуждения можно использовать, чтобы показать, что P (¬A | B) = P (B | ¬A) P (¬A) / P (B) и т. Д.
Геометрическая визуализация теоремы Байеса. В таблице значения 2, 3, 6 и 9 дают относительные веса каждого соответствующего условия и случая. Цифры обозначают таблицы, участвующие в каждой метрике, вероятность - это доля каждой затененной цифры. Это показывает, что P (A | B) P (B) = P (B | A) P (A), то есть есть P (A | B) = P (B | A) P (A) / P (B). Аналогичные рассуждения можно использовать, чтобы показать, что P (¬A | B) = P (B | ¬A) P (¬A) / P (B) и т. Д. | Гипотеза. Доказательства | Подтвердить гипотезу. H | Нарушить гипотезу. ¬H | Итого | |
|---|---|---|---|---|
| Имеет доказательства. E | P (H | E) · P ( E) . = P (E | H) · P (H) | P (¬H | E) · P (E) . = P (E | ¬H) · P (¬H) | P (E) | |
| Нет Доказательства. ¬E | P(H|¬E)·P(¬E). = P (¬E | H) · P (H) | P (¬H | ¬ E) · P (¬E) . = P (¬E | ¬H) · P (¬H) | P ( ¬E) =. 1 - P (E) | |
| Итого | P(H) | P (¬H) = 1 - P (H) | 1 | |
Байесовский вывод выводит апостериорную вероятность как следствие из двух антецедентов : априорной вероятности и «функции правдоподобия », полученные из статистической модели для наблюдаемых данных. Байесовский вычисляет апостериорную вероятность согласно теореме Байеса :

где
 обозначает любую гипотезу, вероятность которой могут повлиять данные (называемые доказательства). Часто существуют конкурирующие гипотезы, и задача состоит в том, чтобы определить, какая из них наиболее вероятна.
обозначает любую гипотезу, вероятность которой могут повлиять данные (называемые доказательства). Часто существуют конкурирующие гипотезы, и задача состоит в том, чтобы определить, какая из них наиболее вероятна. , априорная вероятность - это оценка вероятности гипотезы до данных
, априорная вероятность - это оценка вероятности гипотезы до данных  , текущее свидетельство соблюдается., свидетельство, соответствует новым данным, которые не использовались при вычислении априорной вероятности.
, текущее свидетельство соблюдается., свидетельство, соответствует новым данным, которые не использовались при вычислении априорной вероятности. , апостериорная вероятность, это вероятность задано , то есть после . Это то, что мы хотим знать: вероятность гипотезы с учетом наблюдаемых свидетельств.
, апостериорная вероятность, это вероятность задано , то есть после . Это то, что мы хотим знать: вероятность гипотезы с учетом наблюдаемых свидетельств. - вероятность того, что соблюдение при заданном и называется правдоподобием. Как функция от с фиксированным , это указывает на совместимость доказательства с гипотеза. Функция правдоподобия является функцией свидетельства, , тогда как апостериорная вероятность является функцией гипотезы, .
- вероятность того, что соблюдение при заданном и называется правдоподобием. Как функция от с фиксированным , это указывает на совместимость доказательства с гипотеза. Функция правдоподобия является функцией свидетельства, , тогда как апостериорная вероятность является функцией гипотезы, . иногда называют предельным правдоподобием или «модельным свидетельством». Этот фактор одинаков для всех рассматриваемых гипотез (что очевидно из того факта, что гипотеза нигде в символе не появляется, в отличие от всех других факторов), поэтому этот фактор не учитывается при определении относительной вероятности различных гипотез.
иногда называют предельным правдоподобием или «модельным свидетельством». Этот фактор одинаков для всех рассматриваемых гипотез (что очевидно из того факта, что гипотеза нигде в символе не появляется, в отличие от всех других факторов), поэтому этот фактор не учитывается при определении относительной вероятности различных гипотез.Для разных значений
правило Байеса также можно записать следующим образом:

потому что

и

где 
Один быстрый и простой способ запомнить уравнение: для ис правила использования умножения:
Байесовское обновление широко используется и удобно с вычислительной точки зрения. Однако это не единственное правило обновления, которое можно считать рациональным.
Ян Хакинг отмечает, что стандартные аргументы «голландской книги » не определяют байесовское обновление: они оставляют возможность открытой того, что небайесовские правила обновления могут избежать голландской книги. Хакерский писал: «И ни аргумент в голландской книге, ни какой-либо другой аргумент в персоналистском арсенале доказательств аксиом вероятности не влечет за собой динамическое допущение. Ни одно из них не влечет за собой байесианство. Таким образом, персоналист требует, чтобы динамическое допущение было байесовским. верно, что в случае персоналист может отказаться от байесовской модели обучения на собственном опыте. Соль может потерять свой вкус ».
Действительно, существуют небайесовские правила обновления, которые также избегают голландских книг (как обсуждается в литературе по «вероятностной кинематике ») после публикации Ричарда К. Джеффри, которое применяет правило Байеса к случаю, когда самому свидетельству приписывается вероятность. Дополнительные гипотезы, необходимые для однозначного требования байесовского обновления, были сочтены существенными, сложными и неудовлетворительными.
 , точка данных в целом. Фактически это может быть вектор значений.
, точка данных в целом. Фактически это может быть вектор значений. , параметр распределения точки данных, т. Е.
, параметр распределения точки данных, т. Е.  . Фактически это может быть вектор параметров.
. Фактически это может быть вектор параметров. , гиперпараметр распределения параметров, т. Е.
, гиперпараметр распределения параметров, т. Е.  . Фактически это может быть вектор гиперпараметров.
. Фактически это может быть вектор гиперпараметров. - образец, набор
- образец, набор  наблюдаемые точки данных, т. Е.
наблюдаемые точки данных, т. Е.  .
. , новая точка данных, где необходимо спрогнозировать.
, новая точка данных, где необходимо спрогнозировать. . Предыдущее распределение может быть нелегко определить; в такой одной из возможностей может быть использование предшествующего Джеффри предварительного распределения перед обновлением его новыми данными.
. Предыдущее распределение может быть нелегко определить; в такой одной из возможностей может быть использование предшествующего Джеффри предварительного распределения перед обновлением его новыми данными. . Это называется правдобием, особенно если рассматривать его также как функцию программы (ов), иногда записывается как
. Это называется правдобием, особенно если рассматривать его также как функцию программы (ов), иногда записывается как  .
. .
.
Это выражается словами как «апостериорная пропорциональна времени вероятности до», или иногда как «апостериорная = вероятность предшествующего времени, превышающая доказательство ».


Байесовская теория требует использования апостериорного прогнозирующего распределения для выполнения прогнозного вывода, т. е. для прогнозирования распределения новой, ненаблюдаемой точки данных. То есть вместо фиксированной точки в качестве прогноза возвращается по возможным точкам. Только так можно использовать все апостериорное распределение задач (ов). Для сравнения прогноз в частотной статистике часто включает поиск оптимальной точечной оценки (ов), например, с помощью максимального правдоподобия или максимальной апостери оценочной (MAP) - а затем подставить эту оценку в формулу распределения точки данных. Это имеет недостаток, заключающийся в том, что он не учитывает какую-либо неопределенность в значении и, следовательно, недооценивает дисперсию прогнозного распределения.
(В некоторых случаях частотная статистика может обойти проблему., доверительные интервалы и Например интервалы прогноза в частотной статистике при построении из нормального распределения с неизвестным средним и дисперсией строятся с использованием t-распределения Стьюдента. Это правильно оценивает дисперсию тому благодаря, что (1) среднее значение нормально распределенных случайных величин также нормально (2) прогнозирование распределения нормально распределенной точки данных с неизвестным средним средним размером и дисперсией, с использованием сопряженных или неинформативных априорных значений, имеет t-распределение Сть байюдента в статистике апостериорное прогнозное распределение всегда можно определить - или по крайней мере, с произвольным уровнем производительности при использовании численных методов.)
Оба прогнозных распределений формула сложного типа распределения вероятно стей (как и маргинальное правдоподобие капюшон ). Фактически, если априорное распределение является сопряженным априорным, и, следовательно, априорное и апостериорное распределение происходит из одного семейства, легко из заметить, что как априорные, так и апостериорные предсказательные предсказательные распределения также соответствуют одному и тому же составному составному распределению. Единственное отличие состоит в том, что апостериорное прогнозное распределение использует обновленные значения гиперпараметров (применяя правила байесовского обновления, приведенные в сопряженной предыдущей статье ), в то время как предыдущее прогнозное распределение использует значения гиперпараметров, которые появляются в предварительном распределении.
Если свидетельство одновременных используемых обновлений по набору исключительных и исчерпывающих утверждений, можно рассматривать как действующее на это исследование в целом.
 Схема, иллюстрирующая пространство событий
Схема, иллюстрирующая пространство событий  в общей формулировке байесовского вывода. Хотя эта диаграмма показывает дискретные модели и события, непрерывный случай может быть визуализирован аналогичным образом с использованием плотностей вероятностей.
в общей формулировке байесовского вывода. Хотя эта диаграмма показывает дискретные модели и события, непрерывный случай может быть визуализирован аналогичным образом с использованием плотностей вероятностей. Предположим, что процесс генерирует независимые и одинаково распределенные события 




Предположим, что в процессе наблюдается генерация 




После наблюдения дополнительных доказательств эта процедура может быть повторена.
Для наблюдения независимых и одинаково распределенных наблюдений 

Где

.
путем параметрической формулы пространства моделей, вера во все модели может быть обновлена за один шаг. Распределение по пространству модели рассматривать как распределение по пространству параметрам. Распределения в этом разделе выражены как непрерывные, представленные плотностью вероятностей, поскольку это обычная ситуация. Однако этот метод в равной применимости к дискретным распределениям.
Пусть вектор 





где



Если 



Первое следует непосредственно из теоремы Байеса. Последнее можно получить, применив первое правило к событию «не 


Рассмотрим распределение поведения обвинений, поскольку оно обновляется большое количество раз с помощью независимых и одинаково распределенных испытаний. 465>независимо от исходной априорной вероятности при некоторых условиях, описанных впервые. И строго доказано Джозефом Л. Дубом в 1948 году, а именно, если рассматриваемая случайная величина имеет конечное вероятностное пространство. Более общие результаты были получены позже статистиком Дэвидом А. Фридманом, который опубликовал две основополагающие исследоват ельские работы в 1963 и 1965 годах, когда и при обстоятельствах гарантируется асимптотическое поведение апостериорного распределения. Его статья 1963 года, как и Дуб (1949), рассматривает конечный случай и приходит к удовлетельному заключению. Однако, если случайная величина имеет бесконечное, но счетное вероятностное пространство (т. Е. Соответствующее кубику с бесконечным множеством граней), статья 1965 года демонстрирует, что для плотного подмножества априорных значений Бернштейна-фон Мизеса Теорема неприменима. В этом случае почти наверняка нет асимптотической сходимости. Позже, в 1980-х и 1990-х годах Фридман и Перси Диаконис продолжили работу над случаем бесконечных счетных вероятностных пространств. Подводя итог, может быть недостаточно испытаний, чтобы подавить эффекты собственного выбора, и особенно для больших (но конечных) систем сходимость может быть очень медленной.
В параметризованной форме часто возникают проблемы с распределением, называемых конъюгированных приоров. Полезность сопряженного априорного распределения заключается в том, что соответствующее апостериорное распределение будет в том же семействе, и расчет может быть выражен в закрытой форме.
Часто желательно использовать апостериорное распределение для оценки параметров или вариант. Несколько методов байесовской оценки выбирают измерения центральной тенденции из апостериорного распределения.
Для одномерных задач существует уникальная медиана для практических непрерывных задач. Апостериорная медиана привлекательна как робастная оценка.
Если существует конечное среднее для апостериорного распределения, то апостериорное среднее методом оценки.
![{\ displaystyle {\ tilde {\ theta}} = \ operatorname {E} [\ theta] = \ int \ theta \, p (\ theta \ mid \ mathbf {X}, \ alpha) \, d \ theta}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fe77d50024b7504dd853e6cee501d293653c546b)
Выбор значения с наибольшей вероятностью определяет максимальные апостериорные (MAP) оценки:

Есть примеры, когда максимум не достигается, в этом случае набор оценок MAP пуст.
Существуют и другие методы оценки, которые минимизируют апостериорный риск (ожидаемые-апостериорные потери) по отношению к функция потерь, и они представляют интерес для теории статистических решений с использованием выборочного распределения («частотная статистика»).
апостериорное прогнозирующее распределение нового наблюдения

| Чаша. Печенье | #1 | #2 | . Итого | ||
|---|---|---|---|---|---|
| H1 | H2 | ||||
| Простая | E | 30 | 20 | 50 | |
| Шоколад | ¬E | 10 | 20 | 30 | |
| Итого | 40 | 40 | 80 | ||
| P (H 1 | E) = 30/50 = 0,6 | |||||
Предположим, есть две полные тарелки печенья. В чаше № 1 есть 10 шоколадных крошек и 30 простых печений, а в чаше № 2 - по 20 штук каждого вида. Наш друг Фред выбирает наугад миску, а затем наугад выбирает печенье. Мы предполагаем, что нет никаких оснований полагать, что Фред относится к одной миске иначе, чем к другому, как и к печеньям. Печенье оказывается обычным. Насколько вероятно, что Фред взял его из чаши №1?
Интуитивно кажется очевидным, что ответ должен быть больше половины, так как в чаше №1 простого печенья больше. Точный ответ дает теорема Байеса. Пусть 






До того, как мы наблюдали за файлом cookie, вероятность, которую мы присвоили Фреду, выбравшему чашу № 1, была априорной вероятностью, 

 Пример результатов для примеров археологии. Это моделирование было создано с использованием c = 15.2.
Пример результатов для примеров археологии. Это моделирование было создано с использованием c = 15.2. Археолог работает на месте, которое, как считается, относится к средневековому периоду, между 11-м и 16-м веками. Однако точно неизвестно, когда именно в этот период это место было заселено. Найдены фрагменты глиняной посуды, некоторые из них глазированные, а некоторые украшенные. Если бы этот участок был заселен в период раннего средневековья, то 1% керамики был бы покрыт глазурью и 50% его площади украшали бы, тогда как если бы он был заселен в период позднего средневековья, то 81% был бы застеклен и 5 % его площади оформлено. Насколько точно археолог может быть уверен в дате заселения при обнаружении фрагментов?
Степень уверенности в непрерывной переменной 





Предположим, предварительная единообразие 


На графике показано компьютерное моделирование изменяющейся веры при обнаружении 50 фрагментов. В моделировании сайт был заселен примерно в 1420 году, или 
A теории принятия решений обоснование использования байесовского вывода было дано Абрахамом Вальдом, который доказал, что каждая уникальная байесовская процедура допустимый. И наоборот, каждая допустимая статистическая процедура является либо байесовской процедурой, либо пределом байесовских процедур.
Вальд охарактеризовал допустимые процедуры как байесовские процедуры (и пределы байесовских процедур), делая байесовский формализм центральный метод в таких областях частотного вывода, как оценка параметров, проверка гипотез и вычисление доверительных интервалов. Например:
Байесовская методология также играет роль в выборе модели, где цель состоит в том, чтобы выбрать одну модель из набора конкурирующих моделей, которая наиболее точно представляет основной процесс, который генерировал наблюдаемые данные. При сравнении байесовских моделей выбирается модель с наивысшей апостериорной вероятностью для данных. Апостериорная вероятность модели зависит от свидетельства или предельного правдоподобия, которое отражает вероятность того, что данные генерируются моделью и на основе априорного убеждения модели. Когда две конкурирующие модели априори считаются равновероятными, отношение их апостериорных вероятностей соответствует байесовскому фактору. Сравнение сравнения байесовских моделей направлено на выбор модели с наивысшей апостериорной вероятностью, эта методология также упоминается как правило максимального апостериорного выбора (MAP) или правило вероятности MAP.
Хотя байесовские методы концептуально просты, они могут быть сложными математически и численно. Вероятностные языки программирования (PPL) реализуют функции простого построения байесовских моделей вместе с эффективными методами автоматического вывода. Это помогает создать модели от логических выводов, позволяя практикам сосредоточиться на своих конкретных проблемах и оставляя PPL для обработки вычислительных деталей за них.
Байесовский вывод находит применение в искусственном интеллекте и экспертных систем. Байесовские методы вывода были фундаментальной частью компьютеризированных методов распознавания образов с конца 1950-х годов. Существует также постоянно растущая связь между байесовскими методами и методами моделирования Монте-Карло, поскольку сложные модели не могут быть обработаны в закрытой форме с помощью байесовского анализа, в то время как структура графической модели может позволяют использовать эффективные алгоритмы моделирования, такие как выборка Гиббса и другие схемы алгоритма Метрополиса - Гастингса. Недавно байесовский вывод приобрел популярность в сообществе филогенетиков для этих причин; ряд приложений позволяет одновременно оценивать многие демографические и эволюционные параметры.
Применительно к статистической классификации, байесовский вывод использовался для разработки алгоритмов идентификации спама в электронной почте. Приложения, которые используют байесовский вывод для фильтрации спама, включают CRM114, DSPAM, Bogofilter, SpamAssassin, SpamBayes, Mozilla, XEAMS и другие. Классификация спама более подробно рассматривается в статье о наивном байесовском классификаторе.
Индуктивный вывод Соломонова - это теория предсказания, основанная на наблюдениях; например, предсказание следующего символа на основе заданной серии символов. Единственное предположение состоит в том, что окружающая среда следует некоторому неизвестному, но вычислимому распределению вероятностей. Это формальная индуктивная структура, сочетающаяся два хорошо изученных индуктивного вывода: байесовскую статистику и бритву Оккама. Универсальная априорная вероятность Соломонова любого префикса p вычислимой последовательности x - это сумма вероятностей всех программ (для универсального компьютера), которые вычисляют что-то, начинающееся с p. Из которого можно использовать универсальные априорную теорему и теорему, прогнозируемые предсказания еще невидимых частей x.
Байесовский вывод применен в различных приложениях биоинформатики, включая анализ дифференциальной экспрессии генов. Байесовский вывод также используется в общей модели риска рака, называемой CIRI (непрерывный индивидуальный индекс риска), где серийные измерения включены для обновления байесовской модели, которая в основном построена на основе предшествующих знаний.
байесовский вывод может использовать присяжными для последовательного накопления доказательств и против обвиняемого, а также для проверки соответствует ли он в целом их личному порогу для вне разумных сомнений. '. Теорема Байеса последовательно выполняющие следующие действия. Преимущество байесовского подхода в том, что он дает присяжным беспристрастный и рациональный механизм для объединения доказательств. Возможно, будет уместно объяснить присяжным теорему Байеса в форме шансы, поскольку ставки понимаются более широко, чем вероятности. В качестве альтернативы для жюри может быть проще использовать логарифмический подход , заменяющий умножение сложением.

Если существование преступления не вызывает сомнений, только личность виновника, было предложено предварительное мнение было одинаковым для квалифицированного населения. Например, если бы преступление могло совершить 1000 человек, априорная вероятность вины была бы 1/1000.
Использование теоремы Байеса присяжными является спорным. В Соединенном Королевстве защитник эксперт-свидетель объяснил присяжным теорему Байеса по делу Р против Адамса. Присяжные признали виновным, но дело было обжаловано на основании, что присяжным, не желавшим использовать теорему Байеса, не было предоставлено никаких средств для сбора доказательств. Апелляционный суд оставил приговор в силе, но также высказал мнение, что «введение методов лечения» или любого подобного метода в уголовный процесс погружает присяжных в неуместные и ненужные области теории и сложности, отвлекая их от их надлежащей задачи.. "
Гарднер-Медвин утверждает, что критерием, на котором должен быть приговор по уголовному делу, является не вероятность виновности, а скорее вероятность доказательства, учитывая, что обвиняемый невиновен (сродни частотник p-значение ). Он утверждает, что если апостериорная вероятность должна быть вычислена по теореме Байеса, это будет зависеть от частоты совершения преступления, что является необычным доказательством для рассмотрения в уголовном процессе. Рассмотрим следующие три утверждения:
Гарднер. -Медвин утверждает, что присяжные A и не-B подразумевают истинность C, но обратное неверно, что B и C правы, но в этом слу чае он утверждает, что присяжные должны оправдать, даже если они знают, что они отпустят некоторых людей. См. Также парадокс Линдли.
Байесовская эпистемология - это движение, которое защитесовский вывод как средство обоснования правил индуктивной логики.
Карл Поппер и Дэвид Миллер отвергли идею байесовского рационализма, т.е. Использование правил использования эпистемологических выводов: он подвержен тому же порочному кругу, что и другой другой юстифонистская эпистемология, потому что она предполагает то, что пытается оправдать. Согласно этой точке зрения, рациональная интерпретация вывода будет рассматривать его просто как вероятностную версию фальсификации, отвергая широко распространенное среди байесовцев мнение о том, что высокая вероятность, достигаемая с помощью ряда байесовских обновлений, что гипотеза вне разумных сомнений или даже с вероятностью больше 0.
Проблема, рассмотренная Байесом в предложении 9 его эссе, «Эссе для решения проблемы в Доктрине Шансов », апостериорным распределением для степени a (степень успеха) биномиального распределения.
Термин байесовский относится к Томасу Байесу (1702–1761), который доказал, что вероятностные пределы могут быть наложены на неизвестное событие. Пьер-Симон Лаплас (1749–1827) представил (как Принцип VI) то, что сейчас называется теоремой Байеса, и использовал ее для решения проблем в астрономии. Механика, медицинская статистика, надежность и юриспруденция. байесовский вывод, в котором использовались единые априорные значения в соответствии с принципом недостаточной причины Лапласа, был назван «обратной вероятностью » (поскольку он выводит в обратном направлении от наблюдений к параметрам или от следствий к причинам). После 1920-х годов «обратная вероятность» была в степени вытеснена набором методов, которые стали называть частотной статистикой.
. В 20-м веке идеи Лапласа получили дальнейшее развитие в двух разных направлениях, что привело к объективной и субъективные течения в байесовской практике. В объективном или «неинформативном» потоке статистический анализ зависит только от предполагаемой модели, проанализированные данные и метод, присваивающее априорное значение, которое отличается от одного объективного практикующего байесовского метода к другому. В субъективном или «информативном» потоке спецификации априорного мнения зависит от убеждения (т. Е. Предположений, на основании готового действовать анализ), которое может обобщать информацию от экспертов, предыдущих исследований и т. Д.
В 1980-х годах наблюдался резкий рост исследований и приложений байесовских методов, в основном связанный с открытием методов Монте-Карло с цепью Маркова, которые устранили многие вычислительные проблемы и растущий интерес к нестандартным, сложные приложения. Несмотря на рост байесовских исследований, большая часть обучения в бакалавриате по-прежнему на основе частотной статистике. Тем не менее, байесовские методы широко приняты и используются, например, в области машинного обучения.
Следующие книги через в порядке возрастания вероятностной сложности:

