
Войти
Сохранение на основе UVC - это стратегия архивирования для обработки сохранения из цифровых объектов. В нем используется универсальный виртуальный компьютер (UVC) - виртуальная машина (VM), специально разработанная для архивных целей, что позволяет как эмулировать, так и миграция в язык -нейтральный формат, например XML.
Сохранение цифровых ресурсов имеет первостепенное значение для депозитарных библиотек, исследовательских библиотек, архивов, государственных учреждений и, фактически, большинства организаций. Преобладающий подход к сохранению цифровых данных - миграция. Миграция влечет за собой периодическое преобразование заархивированной информации в новые логические форматы в качестве их собственных форматов, либо программное или аппаратное обеспечение, от которого они зависят, устаревают. Заметная опасность миграции - это потеря данных и возможная потеря исходной функциональности или «внешнего вида» исходного формата. Кроме того, цифровая миграция требует много времени и затрат, поскольку процесс требует преобразования формата каждого документа в дополнение к копированию преобразованных потоков битов на новые носители, если это необходимо.
Джефф Ротенберг вызвал некоторый переполох в организациях, заинтересованных и ответственных за цифровое хранение, своим докладом в 1999 году: «Избегая технологического зыбучих песков: поиск жизнеспособной технической основы для цифрового хранения». Он заявляет, что не существует жизнеспособных решений, гарантирующих, что цифровая информация будет доступна для чтения в будущем. Предлагаемые решения, основанные на стандартах и миграции, считаются отнимающими много времени и в конечном итоге неспособными сохранить цифровые документы в их первоначальной форме. Он предлагает:
«идеальный подход должен обеспечивать единое, расширяемое, долгосрочное решение, которое можно раз и навсегда разработать и применять единообразно, автоматически и синхронно (например, при каждом следующем цикле обновления) для всех типов документов и всех носителей с минимальным вмешательством человека ».
Он предполагает, что лучший способ удовлетворить вышеуказанным критериям - это эмуляция с помощью; разработка эмулятора, который будет работать на неизвестных компьютерах будущего; разработка методов сбора метаданных, необходимых для поиска, доступа и воссоздания документа; разработка методов инкапсуляции документов, связанных с ними метаданных, программного обеспечения и спецификаций эмулятора.
В 2000 году он предлагает реализовать подход к сохранению на основе эмуляции, при котором спецификации эмулятора выражаются в виде программ и интерпретируются программой интерпретатора спецификации эмулятора, написанной для виртуальной машины эмуляции.
Подход Ротенберга был встречен скептически и сочтен слишком технически сложным, слишком дорогим и слишком трудоемким и, следовательно, экономическим риском (без поддержки эмпирических данных). (См. Раздел для дополнительного чтения)
Рэймонд А. Лори во время его работы в IBM Research Center Almaden, инициировал разработку решения на основе UVC для долгосрочного цифрового хранения. Он описывает этот подход как «универсальный», потому что его определение настолько базовое, что он будет существовать вечно, «виртуальный», потому что его никогда не нужно будет строить физически, и это «компьютер» по своим функциям.
IBM (Нидерланды), владелец активов UVC, продолжает развивать концепцию UVC в рамках проекта PLANETS. Раймонд ван Диссен отвечает за расширение применения концепции UVC для сохранения более сложных объектов.
Национальная библиотека Нидерландов (Koninklijke Bibliotheek, KB) сыграла важную роль в демонстрации этой эмуляции на основе UVC. Concept - это жизнеспособный вариант для долгосрочного цифрового хранения.
В 2000 году защитник эмуляции Джефф Ротенберг участвовал в исследовании с KB, чтобы проверить и оценить возможность использования эмуляции в качестве долгосрочной стратегии сохранения. Его метод заключался в использовании программной эмуляции для воспроизведения поведения устаревших вычислительных платформ на новых платформах, предлагая способ запуска исходного программного обеспечения цифрового документа в далеком будущем, тем самым воссоздавая контент, поведение и «внешний вид» исходного документа.. Ротенберга критиковали за попытку сохранить неправильную вещь, предлагая имитировать поведение старых аппаратных платформ и операционных систем для доступа к исходным данным через исходное программное обеспечение, связанное с ними. Раймонд А. Лори осознал трудности в попытке создать программу, имитирующую «настоящую» машину на будущей платформе, и понял, что такой подход был излишним с точки зрения сохранения цифровых объектов. Вместо этого он представил новый подход к архивированию данных / программ с использованием «универсального виртуального компьютера». Концепция стратегии сохранения на основе UVC была реализована KB и протестирована на файлах PDF в рамках исследования KB / IBM «Долгосрочное сохранение» (LTP). Создать UVC для документов PDF сложнее. Вместо этого KB решило разработать UVC для изображений, потому что этот подход также будет охватывать документы PDF (файл PDF можно легко преобразовать в серию изображений). Подход, основанный на UVC, привел к тому, что UVC стал одним из инструментов постоянного доступа к изображениям JPEG / GIF87 в подсистеме сохранения электронного депо КБ. После успешного внедрения UVC KB продолжило разработку своей стратегии эмуляции для долгосрочного цифрового хранения, сосредоточив внимание на «полной» или аппаратной эмуляции. Этот подход позволил создать надежный компьютерный эмулятор на основе компонентов x86: первый модульный эмулятор для цифрового сохранения.
Универсальный виртуальный компьютер является частью более широкой концепции, называемой Метод сохранения на основе UVC. Этот метод позволяет цифровым объектам (например, текстовым документам, электронным таблицам, изображениям, звуковым волнам и т. Д.) Восстанавливать свой первоначальный вид в любое время в будущем. Методы представляют собой программы, написанные на машинном языке универсального виртуального компьютера (UVC). UVC полностью не зависит от архитектуры компьютера, на котором он работает.
Сам UVC - это программа, которая содержит набор инструкций, а не физический компьютер. Он будет работать как программное приложение на будущей платформе. Поскольку в настоящее время мы не знаем, какое оборудование будет доступно в будущем, UVC необходимо создать в то время, когда мы хотим получить доступ к конкретному документу из репозитория. Затем этот UVC формирует платформу, на которой могут запускаться программы, которые были специально написаны для таких UVC в прошлом. Создать программу эмуляции для UVC в будущем намного проще, чем пытаться имитировать «настоящую» машину.
Метод стратегии сохранения на основе UVC различает архивирование данных, которое не требует полной эмуляции, и программное архивирование, которое требует. Для архивирования данных UVC используется для архивирования методов, которые интерпретируют сохраненный поток данных. Методы представляют собой программы, написанные на машинном языке универсального виртуального компьютера (UVC). Программа UVC полностью независима от архитектуры компьютера, на котором она работает.
Архивирование данных воссоздает "внешний вид" исходного файла, но не функциональность исходного формата. Если электронная форма документа используется только для компактного хранения или если способ, которым документ выглядит для человеческого глаза, - все, что есть, тогда достаточно заархивировать документ как изображение. Если требуются дополнительные функции, например поиск текста, сохранения только изображения недостаточно. В этом случае текст также необходимо заархивировать вместе с изображением документа. Восстановив исходный вид файла в виде изображения, будущий пользователь сможет увидеть, как выглядит исходный файл в макете страницы, стиле, шрифте и т. Д. Сам текст должен быть экспортирован, т.е. в формате ASCII, и может быть сохраненными как последовательность однородных элементов (все атрибуты представления, такие как шрифт, размер и т. д., одинаковы для всех символов), потому что изображение страницы показывает точный вид страницы. В этом случае программа данных UVC состоит из двух частей: одна для декодирования текста, а вторая для декодирования изображения.
Что это влечет за собой
Данные, содержащиеся в потоке битов, хранятся с внутренним представлением, извлеченным из потока данных, логических элементов данных, которые подчиняются определенной схеме в определенной модели данных. Алгоритм (метод) декодирования извлекает различные элементы данных из внутреннего представления и возвращает их, помеченные в соответствии со схемой. Дополнительная схема (схема для чтения схем) с информацией о схеме аналогичным образом сохраняется с данными вместе с методом декодирования схемы для чтения схем.
Логическая модель данных остается простой, чтобы свести к минимуму объем описания, сопровождающего данные, и уменьшить сложность понимания структуры данные. Модель данных, выбранная для метода сохранения на основе UVC, линеаризует элементы данных в иерархию помеченных элементов, организованных с использованием XML-подобного подхода. Тегированные элементы данных извлекаются из потока данных цифрового файла. Тег определяет роль, которую элемент данных играет в структуре данных. Теги элементов содержат конкретную информацию о содержании данных независимо от технологии. Кроме того, элементы данных, помеченные в соответствии со схемой, возвращаются клиенту в представлении логических данных (LDV)
Пример представления логических данных
сахарная голова горы 1916 1500 2100 …
Требуется дополнительная информация о различных элементах данных, чтобы человек мог понять, что означает каждый элемент, такая информация, как место тегов в иерархия, тип данных (числовые, символы) вместе с некоторой информацией о семантике данных. Например, изображение имеет два атрибута, ширину и высоту, что указывает на то, что ширина умножается на высоту в пикселях; но хранятся ли эти пиксели строка за строкой или столбец за столбцом? Или для цветных изображений, как интерпретировать значения RGB, чтобы воссоздать правильный цвет? Эта дополнительная информация также называется метаданными. Схема явно зависит от приложения, поскольку она описывает структуру и значение тегов как частей определенного типа информации.
Если в будущем пользователь получит элементы данных с тегами, он / она, как правило, не поймет значения данных и отношения между ними и будущим пользователем потребуют дополнительной информации о логической структуре. Другими словами, необходима схема для чтения схемы метаданных. Простое решение, принятое для подхода UVC, - это метод для схемы, аналогичный методу для данных: информация схемы хранится во внутреннем представлении и сопровождается методом ее декодирования.
На этом этапе в архив будут включены: сами данные, метаданные, программа UVC для декодирования данных и программа UVC для декодирования метаданных.
Метод UVC для архивирования данных может быть расширен для архивирования программ. Архивирование программы включает архивирование поведения и функциональности программы, а также может включать архивирование операционной системы. Архивирование операционной системы может не понадобиться, если программа представляет собой только серию встроенных инструкций операционной системы. Однако операционная система должна быть заархивирована, если цифровой объект является полноценной системой с взаимодействиями ввода / вывода.
Если взаимодействие ввода / вывода не требуется, достаточно заархивировать программу операционной системы. В этом случае, используя метод, аналогичный описанному выше, во время архивирования необходимо сохранить следующее:
В будущем UVC интерпретирует код UVC, который даст тот же результат, что и исходная программа, работающая в исходной операционной системе.
Когда задействованы взаимодействия ввода / вывода, все усложняется, так как дополнительная программа UVC, имитирующая работу процессора устройства ввода / вывода, должна быть заархивирована. Эта программа UVC создаст структуру данных ввода / вывода.
В будущем - отображение структуры данных необходимо будет записать на фактическое устройство.
Метод UVC заменяет необходимость во множестве стандартов (по одному для каждого формата) одним стандартом для метода UVC. Этот стандарт должен охватывать: функциональные спецификации UVC, интерфейс для вызова методов, модель схемы и схему для чтения схем
Центральная идея сохранения на основе UVC заключается в том, что цифровые объекты, хранящиеся в архиве, могут быть восстановлены в любое время в будущем без потери смысла этого объекта. На архитектуру UVC влияют характеристики реально существующего компьютера. Он содержит память, регистры и набор низкоуровневых инструкций. Архитектура отличается от «настоящего» компьютера тем, что ее не нужно реализовывать физически. Следовательно, нет реальной физической стоимости. Основным элементом UVC является его сегментная память. Он использует сегменты памяти для хранения отдельных частей данных. Этот сегментный дизайн предотвращает случайную перезапись выделенной памяти другими приложениями, поскольку она не разделяет свое пространство памяти.
Вместе с исходными данными можно реконструировать значение каждого конкретного цифрового объекта. UVC можно рассматривать как сердце системы. Подобно виртуальной машине Java и Common Language Runtime, UVC на самом деле является эмулятором, который позволяет программе работать на виртуальных экземплярах необходимых, обычно устаревших, аппаратное обеспечение, и будет продолжать имитировать необходимое оборудование по мере развития технологий. Поскольку в настоящее время мы не знаем, какое оборудование будет доступно в будущем, UVC необходимо создать в то время, когда мы хотим получить доступ к конкретному документу из репозитория. UVC формирует платформу, на которой могут работать программы, специально написанные для UVC.
Необходимо предпринять разные шаги во время архивирования (в настоящее время) и во время извлечения (в будущем).
Шаг 1 - Определите соответствующую логическую схему для данного приложения
Шаг 2 - Выберите внутреннее представление и свяжите программу UVC P с данными. Это часть обычного проектирования приложения
Шаг 3 - Напишите программу UVC для интерпретации данных
Шаг 4 - Заархивируйте информацию схемы, сохранив внутреннее представление информации схемы в битовый поток вместе с UVC-программой Q для его декодирования. Поскольку структура схемы одинакова для всех приложений, схема для чтения схем выбирается раз и навсегда.
Шаг 1. Создайте эмулятор на текущей платформе. Из-за простоты концепции UVC для опытных разработчиков программного обеспечения довольно легко создать эмулятор UVC для конкретной платформы того времени
Шаг 2 - Разработайте средство просмотра логических данных (программу восстановления для восстановления данные). Это прикладная программа, которая считывает объектный код UVC и поток битов и вызывает эмулятор для выполнения программы UVC, т.е. программа управляет UVC и всем взаимодействием ввода / вывода между ним
Шаг 3 - Запишите восстановление программа для восстановления схемы. Поскольку логическое представление информации схемы фиксировано, одна программа восстановления может фактически поддерживать все приложения. Если будущий клиент уже знает логическое представление для восстанавливаемых документов, то схема не обязательно требует извлечения. Кроме того, схему нужно запрашивать только один раз для коллекции документов одного типа
Соглашение UVC включает элементы информации, которые должны быть заархивированы сегодня и сохранены на неопределенный срок. для обеспечения возможности поиска цифровых объектов в будущем. Включены в конвенцию;
условность должна быть «высечена в камне». Его можно сохранить в цифровом виде, на бумаге и / или на носителе.
Сохранение на основе UVC как центральная идея метода сохранения на основе UVC основано на четырех различных компонентах. Это:
Рис. 2 UVC и его компоненты 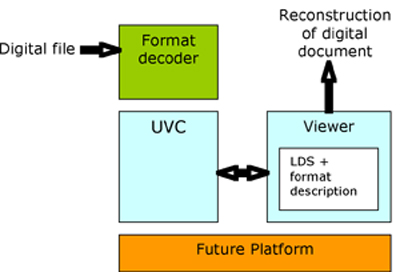
Программа UVC декодирует формат файла цифрового объекта. Эта программа декодирования формата работает на UVC, который является платформо-независимым уровнем, независимым от будущих изменений аппаратного и программного обеспечения. При выполнении декодера формата доставляются теги элементов. Эти элементы создают логическое представление данных (LDV) данных, которое очень похоже на XML. LDV - это реализация LDS, описывающая структуру и значение тегов как частей определенного типа информации.
Все эти компоненты контролируются программой просмотра логических данных, которую просто называют программой просмотра. Для реконструкции средство просмотра запускает UVC и передает его с данными цифрового объекта в декодер формата, работающий поверх UVC. В свою очередь, он извлекает LDV и восстанавливает конкретное представление значения исходного объекта.
В основе архитектуры лежат концепции, существовавшие с начала компьютерной эры: память, регистры и базовые инструкции без дополнительных функций, часто вводимых для повышения производительности выполнения. Производительность имеет второстепенное значение, поскольку программы UVC запускаются в основном для восстановления данных, а не для работы с ними.
Скорость также не вызывает особого беспокойства, поскольку будущие машины будут намного быстрее, а эмуляция UVC на будущей машине, следовательно, будет работать намного быстрее. Кроме того, гибкость UVC важнее скорости выполнения. Даже в этом случае производительность всегда можно улучшить.
UVC для архивирования данных, т. Е. Архивирования статических файлов, доказал свою работоспособность в операционной среде цифрового архивирования. UVC - один из инструментов постоянного доступа к изображениям в базе знаний.
Доказано, что UVC успешно восстанавливает цифровые объекты в их первоначальном виде. Приложение простое, потому что для изображений не требуется никаких функций. Подход к разработке UVC для изображений JPEG оправдан, так как большинство форматов можно преобразовать в этот формат. Например, документ PDF можно отобразить как серию изображений JPEG, тем самым сохраняя «внешний вид» исходного цифрового объекта, но жертвуя функциональностью. Более того, приложение для изображений JPEG можно легко адаптировать для имитации изображений TIFF, внеся небольшую корректировку в схему логических данных.
Подход также может применяться ко всем другим объектам, не содержащим поведенческих аспектов. Например, интерпретаторы написаны (частично) для Excel, Lotus 1-2-3 и PDF. Однако эти приложения обрабатывают только статические функции форматов.
Эмуляция на основе UVC использует UVC как универсальную платформу, на которой может быть построен независимый от платформы эмулятор. UVC (программа) воссоздает простой универсальный компьютер и может быть легко реализована на любой компьютерной платформе сейчас и в будущем. С помощью этой стратегии будущие пользователи всегда должны иметь доступ к исходному объекту и просматривать его. Официальная спецификация UVC должна быть сохранена во время хранения. Кроме того, декодеры должны быть разработаны для каждого конкретного формата файла, и LSD требуется для каждого типа цифрового объекта, определяя типы объектов по изображению, звуку, электронной таблице, тексту и т. Д. И, конечно же, исходные объекты также должны быть сохранены.
Как упоминалось ранее, подход на основе UVC был эффективно реализован только для статических файлов. Технология продолжает разрабатываться Раймондом ван Диссеном (IBM) для включения динамических объектов путем использования средств связи между программой UVC и будущим приложением.
Другие подходы к эмуляции: многослойная эмуляция, перенесенная эмуляция и эмуляция виртуальной машины (ВМ).
Многослойная эмуляция
Многослойная эмуляция - это эмуляция, зависящая от платформы, которая со временем требует, чтобы несколько эмуляторов работали друг над другом для восстановления исторической платформы. Это обеспечивает лучшую производительность и функциональность, но не обеспечивает совместимости между платформами. Этот подход в основном можно найти в игровой индустрии.
Перенесенная эмуляция
Перенесенная эмуляция включает создание зависимого от платформы эмулятора, который необходимо перенести (адаптировать) на последующие более новые хосты. Когда конкретная операционная система, в которой создается эмулятор, устаревает, эмулятор переводится для работы на новой текущей платформе. Этот подход представляет собой стратегию с высокими рисками
Виртуальная машина эмуляции (EVM)
EVM была представлена Джеффом Ротенбергом в 1999 году и включает введение дополнительного уровня между платформой хоста и эмулятором и, как утверждается, быть независимыми от платформы и времени. Этот подход использует виртуальную машину и интерпретатор спецификации эмулятора. Считается, что он не зависит от платформы и времени. Это довольно сложно, так как спецификация эмуляции должна быть написана для компьютерной платформы, на которой работает исходное программное обеспечение. Затем спецификация интерпретируется интерпретатором спецификации эмуляции, который создает эмулятор для старой платформы. И интерпретатор, и созданный эмулятор работают в EVM.
Ожидается, что вопросы авторского права для этого подхода не будут отличаться от проблем любого другого подхода.
Если для формата существуют права интеллектуальной собственности, этот вопрос следует обсудить с владельцами формата. Точно так же для приложений с поддержкой UVC требуется исходный код от разработчика и, следовательно, разрешение от владельца. Наконец, для эмуляции оборудования требуются все соответствующие лицензии на программное обеспечение, работающее в системе.
.