
Войти
 Иллюстрация разложения по сингулярным числам UΣV вещественной матрицы 2 × 2 M.
Иллюстрация разложения по сингулярным числам UΣV вещественной матрицы 2 × 2 M.В линейная алгебра, разложение по сингулярным числам (SVD ) - это факторизация вещественного или комплексная матрица, которая обобщает собственное разложение квадратной нормальной матрицы на любую 
В частности, сингулярная val ue разложение 







диагональные элементы 
SVD не уникален. Всегда можно выбрать разложение так, чтобы сингулярные значения 
Термин иногда относится к компактному SVD, аналогичному разложению 





Математические приложения SVD включают вычисление псевдообратной матрицы, аппроксимацию матрицы и определение ранга, диапазона и нулевого пространства матрицы. SVD также чрезвычайно полезен во всех областях науки, инженерии и статистики, таких как обработка сигналов, аппроксимация методом наименьших квадратов данные и управление процессом.
 Анимированная иллюстрация SVD реальной двумерной матрицы сдвига M. Сначала мы видим единичный диск синим цветом вместе с двумя каноническими единичными векторами. Затем мы видим действия M, который искажает диск в виде эллипса. SVD раскладывает M на три простых преобразования: начальное вращение V, масштабирование по осям координат и окончательный поворот U . Длины σ 1 и σ 2 полуосей эллипса являются сингулярными значениями для M, а именно Σ1,1 и Σ2,2.
Анимированная иллюстрация SVD реальной двумерной матрицы сдвига M. Сначала мы видим единичный диск синим цветом вместе с двумя каноническими единичными векторами. Затем мы видим действия M, который искажает диск в виде эллипса. SVD раскладывает M на три простых преобразования: начальное вращение V, масштабирование по осям координат и окончательный поворот U . Длины σ 1 и σ 2 полуосей эллипса являются сингулярными значениями для M, а именно Σ1,1 и Σ2,2.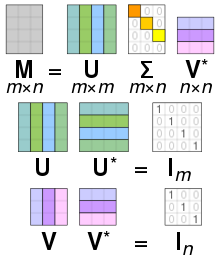 Визуализация матричных умножений при разложении по сингулярным числам
Визуализация матричных умножений при разложении по сингулярным числам В специальном случай, когда M является вещественной квадратной матрицей размером m × m, матрицы U и V могут быть выбраны как действительные m × m матрицы тоже. В этом случае «унитарный» означает то же самое, что и «ортонормированный ». Затем, интерпретируя обе унитарные матрицы, а также диагональную матрицу, резюмированную здесь как A, как линейное преобразование x→Axпространства R, матрицы U и V представляют вращения или отражение пространства, а
В частности, если M имеет положительный определитель, тогда U и V могут быть выбраны как отражения или оба поворота. Если определитель отрицательный, ровно один из них должен быть отражением. Если определитель равен нулю, каждый может быть независимо выбран как принадлежащий к любому типу.
Если матрица M является действительной, но не квадратной, а именно m × n с m ≠ n, ее можно интерпретировать как линейное преобразование из R в Р . Тогда U и V могут быть выбраны для поворота на R и R соответственно; и 
Как показано на рисунке сингулярные значения можно интерпретировать как величину полуосей эллипса в 2D. Эту концепцию можно обобщить на n-мерное евклидово пространство, где сингулярные значения любой квадратной матрицы n × n рассматриваются как величина полуоси n-мерного эллипсоид. Точно так же сингулярные значения любой матрицы m × n можно рассматривать как величину полуоси n-мерного эллипсоида в m-мерном пространстве, например, как эллипс в (наклонной) 2D плоскости. в трехмерном пространстве. Особые значения кодируют величину полуоси, а сингулярные векторы кодируют направление. Подробнее см. ниже.
Поскольку U и V унитарны, столбцы каждого из них образуют набор ортонормированные векторы, которые можно рассматривать как базисные векторы. Матрица M отображает базисный вектор Viна растянутый единичный вектор σ iUi. По определению унитарной матрицы то же самое верно для их сопряженных транспозиций U и V, за исключением того, что геометрическая интерпретация сингулярных значений как отрезков теряется. Короче говоря, столбцы U, U, Vи V являются ортонормированными основаниями. Когда
Поскольку U и V являются унитарными, мы знаем, что столбцы U1,..., UmU дает ортонормированный базис K, а столбцы V1,..., VnV дают ортонормированный базис K (с учетом к стандартным скалярным произведениям на этих пространствах).

имеет особенно простое описание этих ортонормированных базисов:

где σ i - i-я диагональная запись в
Таким образом, геометрическое содержание теоремы SVD можно резюмировать следующим образом: для любого линейного отображения T: K → K можно найти ортонормированные базисы K и K такие, что T отображает i-й базисный вектор K на неотрицательное кратное i-го базисного вектора K, и отправляет оставшиеся базисные векторы в ноль. По отношению к этим базам отображение T поэтому представляется диагональной матрицей с неотрицательными действительными диагональными элементами.
Чтобы получить более наглядный вид сингулярных значений и факторизации SVD - по крайней мере, при работе с реальными векторными пространствами - рассмотрите сферу S радиуса один в R . Линейное отображение T отображает эту сферу на эллипсоид в R . Ненулевые особые значения - это просто длины полуосей этого эллипсоида. Особенно, когда n = m, и все сингулярные значения различны и отличны от нуля, SVD линейного отображения T может быть легко проанализировано как последовательность трех последовательных ходов: рассмотрим эллипсоид T (S) и, в частности, его оси; затем рассмотрите направления в R, отправленные T на эти оси. Эти направления оказываются взаимно ортогональными. Сначала примените изометрию V, посылая эти направления на оси координат R . На втором ходу примените эндоморфизм D, диагонализованный вдоль осей координат и растягивающий или сжимающий в каждом направлении, используя длины полуосей T (S) в качестве коэффициентов растяжения. Затем композиция D∘ Vотправляет единичную сферу на эллипсоид, изометричный T (S). Чтобы определить третий и последний ход U, примените изометрию к этому эллипсоиду, чтобы перенести его на T (S). Как легко проверить, композиция U∘ D∘ Vсовпадает с T.
Рассмотрим матрицу 4 × 5

Разложение по единственному числу этой матрицы задается формулой U
![{\ displaystyle {\ begin {align} \ mathbf {U} = {\ begin {bmatrix} \ color {Green} 0 \ color {Blue} - 1 \ color {Cyan} 0 \ color {Emerald} 0 \\\ color {Green} -1 \ color {Blue} 0 \ color {Cyan} 0 \ color {Emerald} 0 \\\ color {Green} 0 \ color {Blue} 0 \ color {Cyan} 0 \ color {Emerald} -1 \ \\ color {Green} 0 \ color {Blue} 0 \ color {Cyan} -1 \ color {Emerald} 0 \ end {bmatrix}} \\ [6pt] {\ boldsymbol {\ Sigma}} = {\ begin {bmatrix} 3 0 0 0 \ color {Серый} {\ mathit {0}} \\ 0 {\ sqrt {5}} 0 0 \ color {Gray} {\ mathit {0}} \\ 0 0 2 0 \ color {Grey} {\ mathit {0}} \\ 0 0 0 \ color {Red} \ mathbf {0} \ color {Gray} {\ mathit {0}} \ end {bmatrix}} \\ [6pt] \ mathbf {V} ^ {*} = {\ begin {bmatrix} \ color {Violet} 0 \ color {Violet} 0 \ color {Violet} -1 \ color {Violet} 0 \ color {Violet} 0 \\\ color {Plum} - {\ sqrt {0.2}} \ color {Plum} 0 \ color {Plum} 0 \ color {Plum} 0 \ color {Plum} - {\ sqrt {0.8}} \\\ color {Magenta} 0 \ color {Magenta} -1 \ color {Magenta} 0 \ color {Magenta} 0 \ co lor {Magenta} 0 \\\ color {Orchid} 0 \ color {Orchid} 0 \ color {Orchid} 0 \ color {Orchid} 1 \ color {Orchid} 0 \\\ color {Purple} - {\ sqrt {0.8).. }} \ color {Purple} 0 \ color {Purple} 0 \ color {Purple} 0 \ color {Purple} {\ sqrt {0.2}} \ end {bmatrix}} \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/452662baa2e3386f81d938a5c93828dbcbd095df)
Матрица масштабирования
![{\ displaystyle {\ begin {align} \ mathbf {U} \ mathbf {U} ^ {*} = {\ begin {bmatrix} 1 0 0 0 \\ 0 1 0 0 \\ 0 0 1 0 \\ 0 0 0 1 \ end {bmatrix}} = \ mathbf {I} _ {4} \\ [6pt] \ mathbf {V} \ mathbf {V} ^ {*} = {\ begin {bmatrix} 1 0 0 0 0 \\ 0 1 0 0 0 \\ 0 0 1 0 0 \\ 0 0 0 1 0 \ \ 0 0 0 0 1 \ end {bmatrix}} = \ mathbf {I} _ {5} \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/47909bf34c8f6bf555462da282152e537800e0b2)
Это конкретное разложение по сингулярным числам не является уникальным. Выбор 

также является допустимым единственным числом ценностная декомпозиция.
Неотрицательное действительное число σ является сингулярным значение для M тогда и только тогда, когда существуют векторы единичной длины 


Векторы
В любом разложении по сингулярным числам

диагональные элементы
Особое значение, для которого мы можем найти два левых (или правых) сингулярных вектора, которые являются линейно независимыми, называется вырожденным. Если 

В качестве исключения левый и правый сингулярные векторы сингулярного значения 0 включают все единичные векторы в ядре и коядре, соответственно, в M, которое по теореме ранг – недействительность не может быть той же размерности, если m ≠ n. Даже если все сингулярные значения отличны от нуля, если m>n, то коядро нетривиально, и в этом случае U дополняется m - n ортогональными векторами из коядра. Наоборот, если m < n, then V дополняется n - m ортогональными векторами из ядра. Однако, если сингулярное значение 0 существует, дополнительные столбцы U или V уже появляются как левый или правый сингулярные векторы.
Невырожденные сингулярные значения всегда имеют уникальные лево- и правые сингулярные векторы с точностью до умножения на единичный фазовый множитель e (для реального случая с точностью до знака). Следовательно, если все сингулярные значения квадратной матрицы M невырождены и не равны нулю, то ее разложение по сингулярным значениям будет уникальным с точностью до умножения столбца U на коэффициент единичной фазы и одновременное умножение соответствующего столбца V на тот же коэффициент единичной фазы. В общем, SVD уникален до произвольных унитарных преобразований, применяемых единообразно к векторам-столбцам обоих U и V, охватывающих подпространства каждого сингулярного значения, и вплоть до произвольных унитарных преобразований на векторы U и V, охватывающие ядро и коядро, соответственно, M.
Разложение по сингулярным значениям является очень общим в том смысле, что его можно применить к любой матрице размера m × n, тогда как разложение по собственным значениям можно применить только к диагонализуемым матрицам. Тем не менее, эти два разложения связаны.
Для SVD M, как описано выше, выполняются следующие два соотношения:

Правые части этих соотношений описывают разложения левых частей на собственные значения. Следовательно:
(ненулевые особые значения) являются квадратными корнями ненулевого собственные значения из MMили MM.В частном случае, когда M является нормальной матрицей, которая поопределению должна быть квадратная, спектральная теорема говорит, что он может быть единственно диагонализован с использованием базиса собственных векторов, так что его можно записать M= УДУ для унитарной матрицы U и диагональная матрица D . Когда M также является положительно полуопределенным, разложение M= UDU является также разложением по сингулярным числам. В противном случае его можно преобразовать в SVD, переместив фазу каждого σ в либо на соответствующее ему Vi, либо Ui. Естественная связь SVD с ненормальными матрицами осуществляется теоремы о полярном разложении : M= SR, где S= U
Таким образом, за исключением положительных полуопределенных нормальных матриц, разложение по собственным значениям и SVD для M, хотя и связаны, различаются: различаются: разложение по собственным значениям M= UDU, где U не обязательно унитарен и D не обязательно положительно полуопределен, тогда как SVD - это M= U
Разложение по сингулярным числам может быть приложение для вычисления псевдообратной матрицы. (Различные варианты используют разные обозначения для псевдообратной матрицы; здесь мы используем.) Действительно, псевдообратная матрица M с разложением по сингулярным значениям M= UΣVравно
, где Σ - этодообратное Значение Σ, которое формируется заменой каждого ненулевого диагонального элемента его обратным и транспонированием полученной матрицы. Псевдообратная функция - это один из способов линейных наименьших квадратов.
Набор однородных линейных уравнений может быть записан как Ax= 0для матриц A и вектор х . Типичная ситуация состоит в том, что A известно и необходимо определить ненулевое значение x, которое удовлетворяет уравнению. Такой x принадлежит нулевому пространству A и иногда называется (правым) нулевым вектором A . Вектор x можно охарактеризовать как правый сингулярный вектор, соответствующему сингулярному значению A, равному нулю. Это наблюдение означает, что если A представляет собой квадратную матрицу и не имеет исчезающего сингулярного значения, уравнение не имеет ненулевого x в качестве решения. Это также означает, что при наличии нескольких вариантов любая линейная комбинация соответствующих правых сингулярных векторов является допустимым решением. Аналогично определению (правого) нулевого вектора ненулевой x, удовлетворяющий xA= 0, с x, обозначающим сопряженное обозначение x, является левым нулевым вектором A.
A Всего наименьших квадратов Задача относится к определению вектора x, который минимизирует 2-норму дату Ax при ограничении || x || = 1. Решением оказывается правый сингулярный вектор A, соответствующему наименьшему сингулярному значению.
Другое применение SVD состоит в том, что обеспечивает явное представление диапазона диапазона и пустого пространства в матрица М . Право-сингулярные стандарты, соответствующие исчезающим сингулярным значениям M, охватывают нулевое пространство M и лево-сингулярные стандарты, соответствующие ненулевым сингулярным значениям M охватывают диапазон M . Например, в приведенном выше примере пустое пространство занято двумя последними строками V, а диапазон - первыми тремя столбцами U.
. Как следствие, ранг из M равенство количеству ненулевых сингулярных значений, которое совпадает с ненулевых диагональных элементов в
В некоторых практических приложениях необходимо решить аппроксимации матрицы M другой матрицей 


где 
SVD можно рассматривать как разложение матрицы на взвешенную упорядоченную сумму разделимых матриц. Под разделимой мы подразумеваем, что матрица A может быть записана как внешнее произведение векторов A= u⊗ v, или, в координатах, 

Здесь Uiи Vi- это i-й столбец соответствующий матриц SVD, σ i - упорядоченные сингулярные значения, и каждый Aiотделимо. SVD можно использовать для нахождения разделения фильтра изображения обработки на отдельные горизонтальные и вертикальные фильтры. Обратите внимание, что количество ненулевых σ i - это внимание в точности ранг матрицы.
Разделимые модели часто возникают в биологических системах, и SVD-факторизация полезна для анализа таких систем. Например, некоторые восприимчивые поля простых клеток визуальной области V1 могут хорошо использовать с помощью фильтра Габора в пространственной области, умноженного на функцию модуляции во временной области. Таким образом, данный линейный фильтр, оцениваемый, например, посредством обратной корреляции, можно переставить два пространственных измерения в одно измерение, таким образом, получая двумерный фильтр (пространство, время), который может быть разложен с помощью SVD. Тогда первый столбец U в SVD-факторизации представляет собой Габор, а первый столбец V представляет модуль времени (или наоборот). Затем можно определить индекс отделимости

, которая представляет собой долю степени в матрице M, которая учитывается первой разделяемой матрицей в разложении.
Можно использовать SVD квадратной матрицы A для определения ортогональной матрицы O, ближайшей к A . Точность подгонки измеряется нормой Фробениуса из O− A. Решением является продукт UV . Это интуитивно понятно, потому что ортогональная матрица будет иметь разложение UIV, где I - единичная матрица, так что если A= U
Похожая проблема с интересными приложениями формы - это ортогональная проблема Прокруста, которая в нахождении ортогональной матрицы O, которая наиболее точно отображает А в В . В частности,

где 
Эта проблема эквивалентна поиску ближайшей ортогональной матрицы к заданной матрице M= AB.
Алгоритм Кабша (называемый проблемой Вахбы в других областях) использует SVD для вычисления оптимального поворота (относительно минимизации наименьших квадратов), который выровняет набор точек с соответствующим набором точек. Среди прочего, он используется для сравнения структур молекул.
SVD и псевдоинверсия были успешно применены к обработке сигналов, обработке изображений и больших данных ( например, при обработке геномных сигналов).
SVD также широко применяется для изучения линейных обратных задач и полезен при анализе методов регуляризации например, Тихонова. Он широко используется в статистике, где он связан с анализом главных компонентов и с анализом соответствия, а также в обработке сигналов и распознавании образов <562.>. Он также используется в модальном анализе только для вывода, где немасштабированные формы колебаний могут быть определены из сингулярных векторов. Еще одно использование - скрытое семантическое индексирование при обработке текста на естественном языке.
В обычных численных вычислениях с участием линейных или линеаризованных систем существует универсальная константа, которая характеризует регулярность или особенность проблемы, которая является «числом обусловленности» системы 
SVD также играет решающую роль в области квантовой информации в форме, которую часто называют как разложение Шмидта. С его помощью состояния двух квантовых систем естественным образом разлагаются, обеспечивая необходимое и достаточное условие для их запутанности : если ранг
Одно из применений SVD к довольно большим матрицам - это численный прогноз погоды, где методы Ланцоша используются для оценки наиболее линейно быстро растущих нескольких возмущений центрального численного прогноз погоды на заданный начальный период времени; то есть сингулярные векторы, соответствующие наибольшим сингулярным значениям линеаризованного пропагатора для глобальной погоды за этот интервал времени. Выходными сингулярными векторами в этом случае являются целые погодные системы. Затем эти возмущения пропускаются через полную нелинейную модель для генерации ансамблевого прогноза , позволяющего справиться с некоторой неопределенностью, которая должна допускаться в отношении текущего центрального прогноза.
SVD также применялся для моделирования сокращенного порядка. Целью моделирования пониженного порядка является уменьшение количества степеней свободы в сложной системе, которую необходимо моделировать. SVD был объединен с радиальными базисными функциями для интерполяции решений трехмерных задач нестационарного потока.
Интересно, что SVD использовался для улучшения моделирования формы гравитационных волн с помощью наземного гравитационно-волнового интерферометра. АЛИГО. SVD может помочь повысить точность и скорость генерации сигналов для поддержки поиска гравитационных волн и обновления двух различных моделей сигналов.
Декомпозиция по сингулярным значениям используется в рекомендательных системах для прогнозирования оценок пользователей. Распределенные алгоритмы были разработаны с целью вычисления SVD на кластерах обычных машин.
Другая реализация кода алгоритма рекомендации Netflix SVD (третий оптимальный алгоритм в конкурсе, проводимом Netflix, чтобы найти лучшую совместную фильтрацию методы прогнозирования пользовательских оценок фильмов на основе предыдущих обзоров) на платформе Apache Spark доступны в следующем репозитории GitHub, реализованном Александросом Иоаннидисом. Оригинальный алгоритм SVD, который в этом случае выполняется параллельно, поощряет пользователей веб-сайта GroupLens, консультируясь с предложениями по мониторингу новых фильмов, адаптированными к потребностям каждого пользователя.
СВД низкого ранга применялась для обнаружения горячих точек на основе пространственно-временных данных с применением для обнаружения болезни вспышки. Комбинация SVD и SVD более высокого порядка также применялась для обнаружения событий в реальном времени из сложных потоков данных (многомерные данные с пространственными и временными измерениями) в Наблюдение за заболеваниями.
Собственное значение λ матрицы M характеризуется алгебраическим использованием M u = λu. Когда M равно эрмитовскому, также доступна вариационная характеристика. Пусть M будет действительной симметричной матрицей размера n × n . Определите

Согласно теореме об экстремальных значениях, эта непрерывная функция использует максимума при некотором u, когда ограничен единичной сферой {|| х || = 1}. По теореме о множителях Лагранжа u обязательно удовлетворяет

для некоторого действительного числа λ. Символ набла, ∇, является оператором del (дифференцирование по x). Используя симметрию M, получаем

Следовательно, M u = λu, поэтому u является собственным вектором единичной длины M . Для каждого собственного вектора v единичной длины элемента M его собственное значение равно f (v), поэтому λ является наибольшим значением длины M . То же вычисление, выполненное с ортогональным дополнением к u, дает следующее по величине собственное значение и так далее. Сложный эрмитов случай аналогичен; там f (x) = x * M x - вещественная функция от 2n вещественного числа.
Особые значения похожи в том, что они могут быть алгебраически или на основе вариационных принципов. Хотя, в отличие от случая собственных значений, эрмитичность или симметрия M больше не требуется.
В этом разделе приводятся эти два аргумента в использовании функций разложения по сингулярным числам.
Пусть 

где 












Отсюда следует, что

Кроме того, второе уравнение подразумевает 

где нижние индексы в матрицах идентичности используются для обозначения того, что они имеют разные размеры.
Давайте теперь определим

Тогда

, поскольку 





Мы видим, что это почти желаемый результат, за исключением того, что 


столбцы в 

Для V1у нас уже есть V2, чтобы сделать его унитарным. Теперь определите

где дополнительные нулевые строки добавляются или удаляются для создания количество нулевых строк равно количеству столбцов U2, и, следовательно, общие размеры 

который является желаемый результат:

Обратите внимание, что аргумент может начинаться с диагонализации MM а не MM(это прямо показывает, что MM и MMимеют одинаковые ненулевые собственные значения).
Особые значения также могут быть охарактеризованы как максимумы uMv, рассматриваемые как функция u и v, над определенными подпространствами. Сингулярные векторы - это значения u и v, где достигаются эти максимумы.
Пусть M обозначает матрицу m × n с действительными элементами. Пусть S будет единицей 

Рассмотрим функцию σ, ограниченную на S × S. Поскольку и S, и S компактны, их изделие также компактно. Кроме того, поскольку σ непрерывно, оно достигает наибольшего значения по крайней мере для одной пары векторов u ∈ S и v ∈ S. Это наибольшее значение обозначается σ 1, а соответствующие векторы обозначены u1и v1. Поскольку σ 1 является наибольшим значением σ (u, v), оно должно быть неотрицательным. Если бы он был отрицательным, изменение знака u1или v1сделало бы его положительным и, следовательно, больше.
Утверждение. u1, v1- левый и правый сингулярные векторы M с соответствующим сингулярным значением σ 1.
Доказательство. Подобно случаю собственных значений, по предположению, два вектора удовлетворяют критерию Лагранжа уравнение множителя:

После некоторой алгебры это становится

Умножив первое уравнение слева на 


Подставляя это в пару уравнений выше, мы получаем

Это доказывает утверждение.
Больше сингулярных векторов и сингулярных значений можно найти, максимизируя σ (u, v) по сравнению с нормализованным u, v, которые ортогональны u1и v1соответственно.
Переход от действительного числа к комплексному аналогичен случаю собственных значений.
Разложение по сингулярным значениям может быть вычислено с использованием следующих наблюдений:
) - квадратные корни неотрицательных собственных значений обоих MMи MM.SVD матрицы M обычно вычисляется с помощью двухэтапной процедуры. На первом этапе матрица сокращается до двунаправленной матрицы. Это требует O (mn) операций с плавающей запятой (flop), предполагая, что m ≥ n. Второй шаг - вычислить SVD двухдиагональной матрицы. Этот шаг может быть выполнен только с помощью итеративного метода (как и в случае с алгоритмами собственных значений ). Однако на практике достаточно вычислить SVD с определенной точностью, как машина эпсилон. Если эта точность считается постоянной, то второй шаг занимает O (n) итераций, каждая из которых стоит O (n) провалов. Таким образом, первый этап более дорогой, а общая стоимость составляет O (млн) операций (Trefethen Bau III 1997, Lecture 31).
Первый шаг может быть выполнен с использованием отражений Хаусхолдера за 4 млн - 4n / 3 флопов, предполагая, что нужны только сингулярные значения, а не сингулярные векторы. Если m намного больше, чем n, то предпочтительно сначала уменьшить матрицу M до треугольной матрицы с помощью QR-разложения , а затем использовать отражения Хаусхолдера для дальнейшего уменьшения матрицы до двухдиагональной формы. ; общая стоимость составляет 2 млн + 2 тыс. операций (Trefethen Bau III 1997, Лекция 31).
Второй шаг может быть выполнен с помощью варианта QR-алгоритма для вычисления собственных значений, который впервые был описан Golub Kahan (1965) harvtxt error : несколько целей (2 ×): CITEREFGolubKahan1965 (справка ). Подпрограмма DBDSQR LAPACK реализует этот итерационный метод с некоторыми изменениями, чтобы охватить случай, когда особые значения очень малы (Demmel Kahan 1990). Вместе с первым шагом с использованием отражений Хаусхолдера и, при необходимости, QR-разложения, это формирует процедуру DGESVD для вычисления разложения по сингулярным значениям.
Тот же алгоритм реализован в Научной библиотеке GNU (GSL). GSL также предлагает альтернативный метод, использующий односторонний на шаге 2 (GSL Team 2007). Этот метод вычисляет SVD двухдиагональной матрицы путем решения последовательности задач SVD 2 × 2, аналогично тому, как алгоритм собственных значений Якоби решает последовательность методов собственных значений 2 × 2 (Golub Van Loan 1996, §8.6.3). Еще один метод для шага 2 использует идею алгоритмов собственных значений «разделяй и властвуй» (Trefethen Bau III 1997, Lecture 31).
Существует альтернативный способ, в котором явно не используется разложение по собственным значениям. Обычно проблема сингулярных чисел матрицы M преобразуется в эквивалентную симметричную задачу на собственные значения, такую как M M, MMили

Подходы которые используют разложение по собственным значениям, основаны на алгоритме QR, который хорошо разработан, чтобы быть стабильным и быстрым. Обратите внимание, что сингулярные значения являются действительными, а правые и левые сингулярные векторы не требуются для формирования преобразований подобия. Можно итеративно переключаться между QR-разложением и LQ-разложением, чтобы найти действительные диагональные эрмитовы матрицы. Разложение QR дает M⇒ QR, а разложение LQ для R дает R⇒ LP. Таким образом, на каждой итерации у нас есть M⇒ QLP, обновляем M⇐ Lи повторяем ортогонализации. В конце концов, эта итерация между QR-разложением и LQ-разложением дает левую и правую унитарные сингулярные матрицы. Этот подход нельзя легко ускорить, поскольку алгоритм QR может иметь спектральные сдвиги или дефляцию. Это связано с тем, что метод сдвига нелегко определить без использования преобразований подобия. Однако этот итеративный подход очень просто реализовать, поэтому он является хорошим выбором, когда скорость не имеет значения. Этот метод также дает представление о том, как чисто ортогональные / унитарные преобразования могут получить SVD.
Сингулярные значения матрицы 2 × 2 могут быть найдены аналитически. Пусть матрица имеет вид
где 


В приложениях довольно необычно, чтобы полное SVD, включая полное унитарное разложение нулевого пространства матрицы, требовалось. Вместо этого часто бывает достаточно (а также быстрее и экономичнее для хранения) вычислить сокращенную версию SVD. Для матрицы M размера m × n ранга r можно выделить следующее:

Вычисляются только n векторов-столбцов U, соответствующих векторам-строкам V *. Остальные векторы-столбцы U не вычисляются. Это значительно быстрее и экономичнее, чем полный SVD, если n m. Матрица U 'n, таким образом, имеет размер m × n, Σ n имеет диагональ n × n, а V имеет размер n × n.
Первым этапом вычисления тонкого SVD обычно будет QR-разложение M, которое может значительно ускорить вычисление, если n m.

Вычисляются только r векторов-столбцов U и r векторов-строк V *, соответствующих ненулевым сингулярным значениям Σ r. Остальные векторы U и V * не вычисляются. Это быстрее и экономичнее, чем тонкий СВД, если r ≪ n. Матрица U r, таким образом, имеет размер m × r, Σ r - диагональ r × r, а V r * - это r × n.

Только t векторов-столбцов U и t векторов-строк V *, соответствующие t наибольшим сингулярным значениям Σ t рассчитаны. Остальная часть матрицы отбрасывается. Это может быть намного быстрее и экономичнее, чем компактный SVD, если t≪r. Матрица U t, таким образом, имеет вид m × t, Σ t - диагональ t × t, а V t * - это t × n.
Конечно, усеченный SVD больше не является точным разложением исходной матрицы M, но, как обсуждалось выше, приблизительной матрицей
Сумма k наибольших сингулярных значений M представляет собой матричную норму, Ky Fan k-норма M.
Первая из норм Ky Fan, 1-норма Ky Fan, совпадает с оператором norm M как линейным оператором относительно к евклидовой норме K и K. Другими словами, 1-норма Ки Фана - это операторная норма, индуцированная стандартным ℓ евклидовым скалярным произведением. По этой причине его еще называют операторной 2-нормой. Нетрудно проверить связь между 1-нормой Ky Fan и сингулярными значениями. В общем случае это верно для ограниченного оператора M в (возможно, бесконечномерном) гильбертовом пространстве

Но в матричном случае (M * M) является нормальной матрицей, поэтому || M * M || - наибольшее собственное значение (M * M), то есть наибольшее сингулярное значение M.
Последняя из норм Ки Фана, сумма всех сингулярных значений, является нормой следа (также известная как «ядерная норма»), определяемая как || M || = Tr [(M * M)] (собственные значения M * M - это квадраты сингулярных значений).
Сингулярные значения связаны с другой нормой в пространстве операторов. Рассмотрим скалярное произведение Гильберта – Шмидта на матрицах n × n, определенное как

Итак индуцированная норма равна

Поскольку след инвариантен относительно унитарной эквивалентности, это показывает

где σ i - сингулярные значения М . Это называется нормой Фробениуса, 2-нормой Шаттена или нормой Гильберта – Шмидта из M . Прямой расчет показывает, что норма Фробениуса M = (m ij) совпадает с:

Кроме того, норма Фробениуса и норма следа (ядерная норма) являются частными случаями Норма Шаттена.





Два типа тензора существуют декомпозиции, которые обобщают SVD на многоходовые массивы. Один из них разбивает тензор на сумму тензоров ранга 1, что называется разложением тензорного ранга . Второй тип разложения вычисляет ортонормированные подпространства, связанные с различными факторами, появляющимися в тензорном произведении векторных пространств, в которых живет тензор. Это разложение упоминается в литературе как SVD высшего порядка (HOSVD) или Tucker3 / TuckerM. Кроме того, полилинейный анализ главных компонентов в обучении полилинейных подпространств включает в себя те же математические операции, что и разложение Таккера, и используется в другом контексте уменьшения размерности.
Сингулярные значения матрицы A однозначно определены и инвариантны относительно левых и / или правых унитарных преобразований A. Другими словами, сингулярные значения UAV для унитарных U и V равны равны сингулярным значениям A. Это важное свойство для приложений, в которых необходимо сохранять евклидовы расстояния и инвариантность относительно вращений.
Масштабно-инвариантный SVD, или SI-SVD, аналогичен обычному SVD, за исключением того, что его однозначно определенные сингулярные значения инвариантны относительно диагональных преобразований A. Другими словами, сингулярные значения DAE для невырожденных диагональных матриц D и E равны сингулярным значениям A. Это важное свойство для приложений, для которых требуется инвариантность к выбору единиц измерения переменных (например, метрических единиц по сравнению с имперскими).
преобразование модели TP численно восстанавливает HOSVD функций. Для получения дополнительной информации посетите:
Факторизация M= U

где 
Это можно показать, имитируя линейный алгебраический аргумент для матричного случая выше. VT f V * - это уникальный положительный квадратный корень из M * M, как указано в функциональном исчислении Бореля для самосопряженных операторов. Причина, по которой U не обязательно должен быть унитарным, заключается в том, что, в отличие от конечномерного случая, при заданной изометрии U 1 с нетривиальным ядром подходящее U 2 может не быть найдено так, что

- унитарный оператор.
Что касается матриц, факторизация по сингулярным числам эквивалентна полярному разложению для операторов: мы можем просто написать

и обратите внимание, что UV * по-прежнему частичная изометрия при положительном значении VT f V *.
Понятие сингулярных значений и левых / правых сингулярных векторов может быть расширено до компактного оператора в гильбертовом пространстве, поскольку они имеют дискретный спектр. Если T компактно, каждое ненулевое λ в его спектре является собственным значением. Более того, компактный самосопряженный оператор может быть диагонализован по его собственным векторам. Если M компактно, то MMтоже. Применяя результат диагонализации, унитарный образ его положительного квадратного корня T f имеет набор ортонормированных собственных векторов {e i }, соответствующих строго положительным собственным значениям {σ i }. Для любого ψ ∈ H

где ряд сходится в топологии нормы на H. Обратите внимание, как это похоже на выражение из специального кейс. σ i называются сингулярными значениями M . {Uei} (соответственно {Vei}) можно рассматривать как лево-сингулярные (соответственно право-сингулярные) топ-строение для M.
Компактные операторы в гильбертовом пространстве являются контактированием операторами конечного ранга в единой операторнойологии. Вышеупомянутое выражение ряда дает явное представление. Непосредственным следствием этого является:
Разложение по сингулярным числам было разработано различными геометрами, который хотел определить, может ли реальная билинейная форма быть сделана равной другой посредством других ортогональных преобразователей двух пространств, в которых она действует. Эухенио Бельтрами и Камилла Джордан независимо от друга в 1873 и 1874 годах разработаны, что сингулярные значения билинейных форм, представленные в виде матрицы, образуют полный набор инвариантов для билинейных форм при ортогональных подстановках. Джеймс Джозеф Сильвестр также пришел к разложению по сингулярным числам для вещественных квадратных матриц в 1889 году, по-внешнему, независимо от Бельтрами и Джордана. Сильвестр назвал сингулярные значения каноническими множителями матрицы A. Четвертым математиком, открывшим независимое разложение по сингулярным числам, является Autonne в 1915 году, который пришел к нему с помощью полярного разложения. Первое доказательство разложения по сингулярным числам для прямоугольных и комплексных матриц, по-видимому, было сделано Карлом Эккартом и Гейлом Дж. Янгом в 1936 году; они рассматривали это как обобщение преобразования главной оси для эрмитовых матриц.
В 1907 г. Эрхард Шмидт определил аналог сингулярных значений для интегральных операторов (компактные при некоторых слабых технических предположениях); похоже, он не знал о параллельной работе над сингулярными значениями конечных матриц. Эта теория была развита Эмилем Пикаром в 1910 году, который первым назвал числа 
Практические методы вычисления SVD восходят к Когбетлянцу в 1954, 1955 году и Хестенсу в 1958 году. Они очень похожи на алгоритм собственных значений Якоби, который использует вращения плоскости или вращения Гивенса. Однако они были заменены методом Джина Голуба и Уильяма Кахана, опубликованным в 1965 году, который использует преобразования Хаусхолдера или отражения. В 1970 году Голуб и Кристиан Райнш опубликовали вариант алгоритма Голуба / Кахана, который до сих пор остается наиболее часто используемым.

