
Войти
В глубоком обучении сверточная нейронная сеть (CNN или ConvNet ) - это класс глубоких нейронных сетей, наиболее часто применяемых для анализа визуальных образов. Они также известны как инвариант сдвига или пространственно-инвариантные искусственные нейронные сети (SIANN ), в зависимости от их архитектуры с разделяемыми весами и инвариантности трансляции характеристики. У них есть приложения в распознавании изображений и видео, системы решений, классификации изображений, анализа медицинских изображений, обработка естественного языка и финансовые временные ряды.
CNN являются регуляризованными версиями многослойных перцептронов. Многослойные перцептроны обычно означают полностью связанные сети, то есть каждый нейрон в одном слое связано со всеми нейронами слоя. «Полностью связность» этих сетей делает их склонными к переоснащению данных. Типичные способы регуляризации включают добавление некоторой формы измерения весов функций потерь. CNN использует другой подход к регуляризации: они используют преимущества шаблона шаблона и собирают сложные шаблоны, используя более мелкие и простые шаблоны. Следовательно, по шкале связности и сложности CNN находится на нижнем пределе.
Сверточные сети были вдохновлены биологическими процессами в том смысле, чтотерн связи между нейронами напоминает организацию животного зрительной коры. Отдельные нейроны коры реагируют на стимулы только в ограниченной области поля зрения, известное как рецептивное поле. Рецептивные поля разных нейронов частично перекрываются, так что они покрывают все поле зрения.
CNN используйте относительно небольшую предварительную обработку по сравнению с другими алгоритмами классификации изображений. Это означает, что сеть изучает фильтры, которые связывают в алгоритмах были искусственным вручную. Эта независимость от предшествующих и человеческих усилий при разработке функций является большим преимуществом.
Название «сверточная нейронная сеть» указывает на то, что в сети используется математическая операция, называемая сверткой. Свертка - это особый вид линейных операций. Сверточные сети - это просто нейронные сети, которые используют свертку общего умножения матриц, по крайней мере, на одном из своих умений.
Сверточная нейронная сеть состоит из входного и выходного уровней, а также несколько скрытых слоев. Скрытые слои CNN обычно состоят из серии сверточных слоев, которые сворачиваются с умножением или другими скалярным произведением. Функция активации обычно представляет собой слой RELU, за которыми следуют дополнительные свертки, такие как объединение слоев, полностью связанных слоев и уровней нормализации, называемых скрытыми слоями, поскольку их входы и выходы маскируются функцией активации. и финальная свертка.
Хотя слои в просторечии называются свертками, это делается только по соглашению. Математически это технически скользящее скалярное произведение или взаимная корреляция. Это значение для индексов в матрице, поскольку влияет на то, как вес определен в конкретной индексной точке.
При программировании CNN входом тензор с формой (количество изображений) x (высота изображения) x (ширина изображения) x (глубина изображения ). Затем после прохождения через сверточный слой изображение преобразует карту объектов с формой (количество изображений) x (высота карты объектов) x (ширина карты объектов) x (каналы карты объектов). Сверточный слой в нейронной сети должен получить следующие атрибуты:
Сверточные слои свертывают входные данные и передают его результат следующему слою. Это похоже на реакцию нейрона зрительной коры на определенный стимул. Каждый сверточный нейрон обрабатывает данные только для своего рецептивного поля. Хотя полносвязные нейронные сети с прямой связью можно использовать для изучения функций, а также для классификации данных, использовать эту системууру к изображениям непрактично. Было бы необходимо очень большое количество нейронов даже в мелкой (противоположной глубокой) энергии из-за очень больших входных размеров, связанных с изображениями, где каждый пиксель является релевантной переменной. Например, полностью связанный слой для (маленького) изображения размером 100 x 100 имеет 10 000 весов для каждого нейрона во втором слое. Операция свертки решает эту проблему, как уменьшает количество потерь. Например, независимо от размера изображения, мозаичные размером 5 x 5, требует всех 25 обучаемых параметров. Используя регуляризованные веса по меньшему количеству параметров, можно избежать проблем с уменьшающимся градиентом и увеличивающимся градиентом, наблюдаемым во время обратного распространения в отношении нейронных сетей.
Сверточные сети могут включать локальные или глобальные уровни пула для оптимизации лежащих в основе вычислений. Слои объединения увеличивают размер данных, объединяя выходные данные кластеров нейронов на одном уровне в одном уровне нейрон на следующем уровне. Локальный пул объединяет небольшие кластеры, обычно 2 x 2. Глобальный пул действует на все нейроны сверточного слоя. Кроме того, объединение может вычислять или максимальное среднее значение. Максимальный пул использует максимальное значение от каждого кластера нейронов на предыдущем уровне. Средний пул использует среднее значение от каждого кластера нейронов на предыдущем уровне.
Полностью связанные слои соединяют нейрон в одном слое с каждым нейроном в другом слое. Это в принципе то же самое, что и традиционная нейронная сеть (MLP) многослойного персептрона . Сглаженная матрица проходит через полностью связанный слой для классификации изображений.
В нейронных сетях каждый нейрон получает входные данные из некоторого количества мест на предыдущем уровне. В полностью связанном слое каждый нейрон получает входные данные от каждого предыдущего элемента слоя. В сверточном слое нейроны получают входные данные только из ограниченных подобласти предыдущего слоя. Обычно подобласть имеет квадратную форму (например, размер 5 на 5). Входная область нейрона называется его рецептивным полем. Итак, в полностью связанном слое рецептивное поле - это весь предыдущий слой. В сверточном слое восприятия меньше, чем весь предыдущий слой. Подобласть исходного входного изображения в воспринимаемом поле больше углубления в углублении в сети. Это происходит из-за многократного применения свертки, которая учитывает определенное число пикселей, а также некоторые окружающие пиксели.
Каждый нейрон в нейронной сети вычисляет выходное значение, применяя определенную функцию к входным значениям, поступающим из воспринимающего поля на предыдущем уровне. Функция, которая используется к входным значениям, определяется вектором весов и смещением (обычно действительным числом). Обучение в нейронной сети происходит за счет итеративной корректировки этих смещений и весов.
Вектор весов и с ущерб называется фильтрами и представляет собой характеристики ввода (например, конкретную форму). Отличительной чертой CNN является то, что многие нейроны могут использовать один и тот же фильтр. Это сокращает объем памяти, поскольку единое смещение и единый вектор весов используются для всех принимающих полей, совместно используемых этот фильтр, в отличие от каждого принимающего поля, имеющего собственное смещение и векторное взвешивание.
Дизайн CNN следует за обработкой зрения в живых организмх.
Работа Hubel и Визель в 1950-х и 1960-х годах показали, что зрительные коры головного мозга кошек и обезьян содержат нейроны, которые индивидуально реагируют на небольшие области поля зрения. При условии, что глаза неподвижны, область зрительного пространства, стимулирование возбуждения отдельного нейрона, известна как его рецептивное поле. Соседние клетки имеют похожие и перекрывающиеся рецептивные поля. Размер и расположение рецептивного поля систематически меняются в коре головного мозга, чтобы сформировать полную карту визуального пространства. Кора в каждом полушарии представляет собой контралатеральное поле зрения.
. Их работа 1968 года определила два основных типа зрительных клеток в мозге:
Хьюбел и Визель также предложили каскадную модель эти два типа ячеек для использования в задаче распознавания образов.
«неокогнитрон » был представлен Куних Фукусима в 1980 году. Он был вдохновлен вышеупомянутой работой Хьюбеля и Визеля. Неокогнитрон представил два основных типа слоев в CNN: сверточные слои и слои с понижающей дискретизацией. Сверточный слой содержит блоки, рецептивные поля которых покрывают участок предыдущего слоя. Весовой вектор (набор адаптивных параметров) такого блока часто называют фильтром. Юниты могут использовать общие фильтры. Слои с понижающей дискретизацией содержат блоки, рецептивные поля которых покрывают участки предыдущих сверточных слоев. Такой юнит обычно вычисляет среднее значение активаций юнитов в своем патче. Эта дискретная дискретизация помогает правильно классифицировать объекты в визуальных сценах, даже когда объекты сдвинуты.
В варианте неокогнитрона, называемого крецептроном, вместо использования пространственного усреднения Фукусимы J. Weng et al. представил метод, называемый max-pooling, при котором блок активации дискретизации вычисляет максимум активаций блоков в своем патче. Max-pooling часто используется в современных CNN.
На протяжении десятилетий было предложено несколько алгоритмов обучения с учителем и без учителя для тренировки весов неокогнитрона. Однако сегодня архитектура CNN обычно обучается посредством обратного распространения ошибок.
neocognitron - первая CNN, которая требует, чтобы блоки, расположенные в нескольких сетевых позициях, имели общие веса. Неокогнитроны были адаптированы в 1988 году для анализа сигналов, изменяющихся во времени.
Нейронные сети с временной задержкой (TDNN) были представлены в 1987 году компанией Алекс Вайбел и др. и была первой сверточной сетью, поскольку она достигла инвариантности сдвига. Это было сделано за счет использования распределения веса в сочетании с тренировкой Обратное распространение. Таким образом, используя глобальную структуру, как в неокогнитроне, он выполнил оптимизацию весов вместо локальных.
TDNN - это сверточные сети, разделяющие вес во временном измерении. Они позволяют обрабатывать речевые сигналы независимо от времени. В 1990 году Хэмпшир и Вайбел представили вариант, который представляет собой двумерную свертку. Временные эти TDNN оперировали спектрограммами, полученная система распознавания фонем была инвариантной как к сдвигам во времени, так и по частоте. Это вдохновило на неизменность перевода при обработке изображений с помощью CNN. Разделение выходных сигналов нейронов может охватывать синхронизированные этапы.
TDNN теперь достигают наилучших показателей в распознавании речи на большом расстоянии.
В 1990 году Yamaguchi et al. представила концепцию максимального пула. Они сделали это, объединив TDNN с максимальным пулом, чтобы реализовать независимую от говорящего изолированную систему распознавания слов. В своей системе они использовали несколько TDNN на слово, по одному на каждый слог . Результаты TDNN по входному сигналу были объединены с использованием каждого объединения, а выходные данные уровни были объединены в сети, выполняющие фактическую классификацию слов.
Система распознавания рукописных чисел почтового индекса включала свертки, в которых коэффициенты ядра были разработаны вручную.
Янн ЛеКун и др. (1989) использовали обратное распространение, чтобы узнать коэффициенты ядра свертки из изображений рукописных чисел. Таким образом, обучение было полностью автоматическим, выполнялось лучше, чем ручное вычисление коэффициентов, и подходило для более широкого круга задач распознавания типов изображений.
Этот подход стал источником современного компьютерного зрения.
LeNet-5, новаторской 7-уровневой сверточной сети, созданной LeCun et al. al. В 1998 году эта классификация цифр использовалась банками для распознавания рукописных цифр на чеках (британский английский : чеки), оцифрованных в изображениях 32x32 пикселя. Способность обрабатывать изображения с более высоким разрешением требует все большего и большего числа слоев сверточных нейронных сетей, поэтому этот методен доступностью вычислительных ресурсов.
Точно так же нейронная сеть с инвариантным сдвигом была предложена W. Zhang et al. для распознавания символов изображения в 1988. Архитектура и алгоритм обучения были в 1991 году применены для обработки медицинских изображений и автоматического обнаружения рака груди маммограммах.
. В 1988 году был предложен другой дизайн на основе свертки для применения в разложении одномерной электромиографии свернутых сигналов посредством деконволюции. Этот дизайн был изменен в 1989 году на другие конструкции, основанные на деконволюции.
 Пирамида нейронной абстракции
Пирамида нейронной абстракции Архитектура прямой связи сверточных нейронных сетей была расширена в пирамиде нейронной абстракции боковые и обратные связи. Результирующая рекуррентная сверточная сеть позволяет гибко добавить контекстную переменную для разрешения локальных неоднозначностей. В отличие от предыдущих моделей, выходные данные, подобные изображению, с самым высоким разрешением были сгенерированы, например, для семантической сегментации, реконструкции изображения и задач локализации объектов.
Хотя CNN были изобретены в 1980-х, их прорыв в 2000-х годах потребовал быстрых реализаций на графических процессорах (GPU).
В 2004 году К. С. О и К. Юнг показали, что стандартные нейронные сети могут быть значительно ускорены на графических процессорах. Их реализация была в 20 раз быстрее, чем эквивалентная реализация на CPU. В 2005 году в другой статье также подчеркивалось значение GPGPU для машинного обучения.
. Первая реализация CNN на GPU была описана в 2006 году K. Chellapilla et al. Их реализация была в 4 раза быстрее, чем аналогичная реализация на CPU. В последующих работах также использовались графические процессоры, первоначально для других типов нейронных сетей (отличных от CNN), особенно нейронных сетей без учителя.
В 2010 году Dan Ciresan et al. на IDSIA показала, что даже глубокие стандартные нейронные сети со многими уровнями могут быть быстро обучены на GPU с помощью контролируемого обучения с помощью старого метода, известного как backpropagation. Их сеть превзошла предыдущие методы машинного обучения в тесте MNIST рукописных цифр. В 2011 году они распространили этот подход с использованием графических процессоров на CNN, добившись коэффициента ускорения 60 с впечатляющими результатами. В 2011 году они использовали такие CNN на графическом процессоре, чтобы выиграть конкурс распознавания изображений, в котором они впервые достигли сверхчеловеческой производительности. В период с 15 мая 2011 г. по 30 сентября 2012 г. их CNN выиграли не менее четырех имиджевых конкурсов. В 2012 году они также значительно улучшили лучшую производительность в литературе для нескольких баз данных изображений , включая базу данных MNIST, базу данных NORB, набор данных HWDB1.0 (китайские иероглифы) и набор данных CIFAR10 (набор данных из 60000 32x32 помеченных изображений RGB ).
Впоследствии аналогичный CNN на базе графического процессора Алекса Крижевского и др. выиграл конкурс ImageNet Large Scale Visual Recognition Challenge 2012. Очень глубокая CNN с более чем 100 слоями от Microsoft выиграла конкурс ImageNet 2015.
По сравнению с обучением CNN с использованием GPU, не так много внимания было уделено сопроцессору Intel Xeon Phi . Заметным достижением является метод распараллеливания для обучения сверточных нейронных сетей на Intel Xeon Phi, названный Controlled Hogwild с произвольным порядком синхронизации (CHAOS). CHAOS использует параллелизм на у ровне потоков и SIMD, который доступен на In тел Xeon Phi.
В прошлом для распознавания изображений использовалисьот модели многослойного персептрона (MLP). Однако из-за полной связи между узлами они страдали от проклятия размерности и плохо масштабировались с изображениями с более высоким разрешением. Изображение размером 1000 × 1000 пикселей с сигналов RGB имеет 3 миллиона весов, что слишком велико для эффективной обработки в масштабе с полной связью.
 Слои CNN, организованные в трех измерениях
Слои CNN, организованные в трех измерениях , в CIFAR-10 изображения имеют размер только 32 × 32 × 3 (32 ширины, 32 высоты, 3 цветовых канала), поэтому один полностью связанный нейрон в первом скрытом слое обычной нейронной сети будет иметь 32 * 32 * 3 = 3072 веса. Изображение размером 200 × 200 к появлению нейронов с весами 200 * 200 * 3 = 120 000.
Кроме того, такая сетевая архитектура не принимает во внимание пространственную структуру данных, обрабатывая входные пиксели, которые находятся далеко друг от друга. друга, так же, как пиксели, которые расположены близко друг к другу. Это игнорирует местонахождение ссылок в данных изображения, как в вычислительном, так и в семантическом отношении. Таким образом, полное соединение нейронов расточительно для таких целей, как распознавание изображений, которые преобладают пространственно локальные входные шаблоны.
Сверточные нейронные сети - это биологически вдохновленные варианты многослойных перцептронов, которые предназначены для имитации поведения зрительной коры. Эти модели смягчают проблемы, связанные с архитектурой MLP, за счет использования сильной пространственно-локальной корреляции, присутствующей в естественных изображениях. В отличие от MLP, CNN имеют следующие отличительные особенности:
Вместе они свойства позволяют CNN достичь лучшего общего результата по проблемам зрения. Распределение значительно сокращает количество изученных свободных параметров, тем самым снижая требования к памяти для работы сети и позволяя обучать более крупные и мощные сети.
Архитектура CNN сформирована стеком отдельных слоев, которые преобразуют входной объем в выходной объем (например, удерживая оценку класса) посредством дифференцируемой функции. Обычно используются несколько различных типов слоев. Это обсуждается ниже.
 Нейроны сверточного слоя (синий), подключенные к их сверточному полю (красный)
Нейроны сверточного слоя (синий), подключенные к их сверточному полю (красный) Сверточный слой является основным строительным блоком CNN. Параметры слоя состоят из обучаемых фильтров (или ядер ), которые имеют небольшое воспринимающее поле, но простираются на всю глубину входного объема. Во время прямого прохода каждый фильтр сворачивается по ширине и высоте входного объема, вычисляя скалярное произведение между элементами фильтра и входом и создавая двумерный карта активации этого фильтра. В результате сеть изучает фильтры, которые активируются, когда она определяет тип объекта в некоторой пространственной позиции во входных данных.
Сложение карт активации для всех фильтров по формам глубины полный выходной объем сверточного слоя. Таким образом каждую запись в выходном объеме можно также интерпретировать как выход нейрона, который смотрит на небольшую область на входе и разделяет параметры с нейронами на той же карте активации.
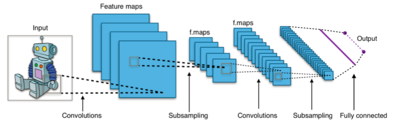 Типичная архитектура CNN
Типичная архитектура CNN При работе с многомерными входами, такими как изображения, непрактично подключать нейроны ко всем нейронам в предыдущем томе, потому что такая сетевая архитектура не принимает пространственную преобразованные данные. Сверточные сети используют пространственно локальную корреляцию, применяя шаблон разреженной локальной связи между нейронами соседних слоев: каждый нейрон связан только с небольшим областью входного объема.
Степень этой связи - это гиперпараметр, называемый рецептивным полем нейрона. Соединения локально в пространстве (по ширине и высоте), но всегда проходят по всей глубине входного пространства. Такая архитектура гарантирует, что изученные фильтры дают самый сильный отклик для помещения локальный входной шаблон.
Три гиперпараметра управляют размером выходного размера сверточного слоя: глубина, шаг и заполнение нулями.
 шаг S приводит к тому, что фильтр переводит на S комплекты для каждого варианта. \ textstyle S \ geq 3}
шаг S приводит к тому, что фильтр переводит на S комплекты для каждого варианта. \ textstyle S \ geq 3} встречаются редко. Восприимчивые поля меньше перекрываются, и результирующий выходной объем имеет меньшие пространственные размеры при увеличении длины шага.
встречаются редко. Восприимчивые поля меньше перекрываются, и результирующий выходной объем имеет меньшие пространственные размеры при увеличении длины шага.Пространственный размер выходного тома может быть вычислен как функция размера входного тома 




Если это число не является целым числом, то шаги неверны, и нейроны не могут быть выложены плиткой, чтобы соответствовать входному объему симметричным способом. Как правило, установка нулевого отступа на 

Схема совместного использования используется в сверточных слоях для управления различными параметрами. Он основан на предположении, что если функция патча полезна для вычисления в некоторой пространственной позиции, она также должна быть полезна для вычислений в других позициях. Обозначая один двумерный срез глубины как срез глубин, нейроны в каждом срезе глубины вынуждены использовать одни и те же веса и смещения.
все нейроны в одном глубинном срезе имеют одинаковые параметры, проход в каждом глубинном срезе сверточного слоя может быть вычислен как свертка весов нейрона с входным объемом. Поэтому обычно наборы весов называются фильтром (или ядром ), который свертывается с вводом. Результатом этой свертки является карта активации, и набор карт активации для каждого отдельного фильтра складывается вместе по измерению обработки для получения выходного объема. Совместное использование возможностей инвариантности трансляции архитектуры CNN.
Иногда предположение о совместном использовании параметров может не иметь смысла. Это особенно актуально, когда входные изображения в CNN имеют некоторую конкретную центрированную структуру; для которого мы ожидаем, что совершенно разные функции будут изучены в разных пространственных точках. Мы можем ожидать, что специфические для глаз или волос особенности будут изучены в разных частях изображения. В этом случае обычно ослабляют использование системы, используемой вместо этого просто называют уровень «локально подключенным уровнем».
 Максимальное объединение с фильтром 2x2 и шагом = 2
Максимальное объединение с фильтром 2x2 и шагом = 2 Другой концепцией CNN является объединение, которое является нелинейной понижающей выборки. Существует несколько нелинейных функций для реализации пула, среди которых наиболее распространен максимальный максимальный пул. Он разделяет входное изображение на набор неперекрывающихся прямоугольников и для каждой такой подобласти выводит максимум.
Интуитивно понятно, что точное расположение объекта менее важно, чем его приблизительное расположение относительно других объектов. Это идея использования пула в сверточных нейронных сетях. Уровень улучшения используемого размера памяти размера представления, уменьшения количества параметров, занимаемой и объема вычислений в сети, и, следовательно, для управления переобучением. Обычно уровень объединения между последовательными сверточными уровнями (за каждым из них обычно следует уровень ReLU) периодически вставляют в архитектуру CNN. Операция объединения может использоваться как другая форма инвариантности трансляции.
Уровень объединения работает независимо на каждом срезе глубины ввода и изменяет его размер в пространстве. Наиболее распространенная форма - это объединяющий слой с фильтрами размера 2 × 2, применяемыми с шагом 2 субдискретизации на каждом срезе глубины во входных данных на 2 по ширине и высоте, отбрасывая 75% активаций:
 В этом случае каждые максимальная операция превышает 4 числа. Размер глубины остается неизменным.
В этом случае каждые максимальная операция превышает 4 числа. Размер глубины остается неизменным. В дополнение к максимальному объединению, блоки объединения могут использовать другие функции, такие как среднее объединение или ℓ2-нормальное объединение. Исторически сложилось так, что средний пул часто использовался, но в последнее время он потерял популярность по сравнению с максимальным пулом, который на практике работает лучше.
Из-за агрессивного уменьшения размера представления в последнее время наблюдается тенденция к использованию меньшего фильтрует или полностью отбрасывает уровни пула.
 Пул рентабельности инвестиций до размера 2x2. В этом примере предложение области (входной параметр) имеет размер 7x5.
Пул рентабельности инвестиций до размера 2x2. В этом примере предложение области (входной параметр) имеет размер 7x5. "Область интересов "объединение (также известное как объединение RoI) является вариантом максимального объединения, в котором размер выходных данных фиксирован, а входной прямоугольник является параметр.
Пул - важный компонент сверточных нейронных сетей для обнаружения объектов на основе архитектуры Fast R-CNN.
ReLU - это сокращение от выпрямленного линейного блока, которое применяет ненасыщающую функцию активации 
Для увеличения нелинейности также используются другие функции, например насыщающий гиперболический тангенс 


Наконец, после нескольких уровней сверточного и максимального пула, высокоуровневые рассуждения в нейронной сети выполняются через полностью подключенные слои. Нейроны в полностью связующих нейронных сетях искусственных нейронных сетей. Таким образом, их активации могут быть вычислены как аффинное преобразование с матричным умножением с последующим смещением с ущербом (сложение вектор изученного или фиксированного члена с ущерба). [Требуется ссылка?]
«Уровень потерь» определяет, как обучение штрафует за отклонение между прогнозируемым (выходным) и истинным меткой и обычно является последним слоем нейронной сети. Могут Награды функции потерь, подходящие для разных задач.
Softmax потеря используется для прогнозирования одного класса из K взаимоисключающих классов. сигмоид перекрестная энтропия потеря используется для прогнозирования K других значений вероятности в ![[0,1]](https://wikimedia.org/api/rest_v1/media/math/render/svg/738f7d23bb2d9642bab520020873cccbef49768d)

CNN используют больше гиперпараметров, чем стандартный многослойный персептрон (MLP). Хотя обычные правила для констант скорости обучения и регуляризации все еще применяются, при оптимизации следует учитывать.
Так как размер карты будут уменьшаться с глубиной, слои с входным слоем меньше фильтров, в то время как более высокие слои могут иметь больше. Для выравнивания вычислений на каждом слое изображение характеристик v a на положение пикселя сохраняется примерно постоянным по слоям. Для сохранения большего количества информации о вводе потребуется общее количество активаций (карт функций, умноженное на количество позиций пикселей) не уменьшилось от одного слоя к другому.
Количество карт функций влияет на емкость и зависит от количества примеров и сложности задачи.
Общие формы фильтра, встречающиеся в литературе, сильно различаются и обычно выбираются на основе набора данных.
Таким образом, задача состоит в том, чтобы найти правильный уровень детализации, чтобы создать абстракции в надлежащем масштабе, конкретный данные, и без переобучения.
Типичные значения - 2 × 2. Очень большие входные объемы могут потребовать объединение 4 × 4 в нижних слоях. Однако выбор более резко формально увеличит размер сигнала и может привести к избыточной потере информации. Часто лучше всего работают неперекрывающиеся окна объединения.
Регуляризация - это процесс введения дополнительной информации для решения некорректно поставленной проблемы или предотвращения переоснащение. CNN использует различные системы регуляризации.
Стол полностью связанный с большинством параметров, он подвержен переобучению. Один из методов уменьшения переобучения - выпадение. На каждом этапе обучения узлы либо «выпадают» из сети с вероятностью 

На этапах обучения вероятность того, что скрытый узел будет удален, обычно составляет 0,5; для входных узлов, однако эта вероятность обычно значительно ниже, поскольку информация напрямую теряется, когда входные узлы игнорируются или отбрасываются.
Во время тестирования после завершения обучения мы в идеале хотели найти выборочное среднее всех преступников 

Избегая обучения всех узлов по всем обучающим данным, выпадение уменьшает переобучение. Также метод увеличения скорости обучения. Это делает комбинацию моделей практичной даже для глубоких нейронных сетей. Кажется, что этот метод уменьшает взаимодействие узлов, создавая их, изучать более надежные функции, которые лучше обобщаются для новых данных.
DropConnect - это обобщение прерывания, при котором каждое соединение, а не каждый блок вывода, может быть прервано с вероятностью
DropConnect похож на отсев, поскольку он привносит динамическую разреженность в модели, но отличается тем, что разреженность зависит от веса, а не выходного слоя слоя. Другими словами, в котором полностью формируется уровень с DropConnect, становится редко выбирается случайный этап обучения.
Главный недостаток исключения заключается в том, что он не имеет тех же преимуществ для сверточных слоев, где нейроны не полностью связаны.
В стохастическом объединении на основе детерминированные операции объединения заменяются стохастической процедурой, в которой активация в каждой области выбирается случайным образом в соответствии с полиномиальным распределением, данные мероприятиями в региональном объединении. Этот подход свободен от гиперпараметров и может быть объединен с другими подходами к регуляризации, такими как выпадение и увеличение данных.
Альтернативный взгляд на стохастический пул в, что он эквивалентен стандартному максимальному объединению, но с большим копием входного изображения, каждая из которых имеет небольшие локальные деформации. Это похоже на явные упругие деформации входных изображений, обеспечивающих отличную производительность для набора данных MNIST. Использование стохастического объединения в многослойной модели дает экспоненциальное деформаций, поскольку выборки в более высоких слоях зависят от тех, что ниже.
Грань переобучения модели определяет как ее мощность, так и объем обучения, которое она получает, обеспечение сверточной сети с большими обучающими примерами может уменьшить переобучение. Эти сети обычно обучаются со всеми доступными данными, один из подходов в том, чтобы либо генерировать новые данные с нуля (если возможно), либо использовать данные для создания новых. Измерительные схемы асимметричного изображения на несколько процентов для создания новых примеров с той же меткой.
Один из самых простых Методы предотвращения переобучения сети - просто остановить обучение до того, как произойдет переобучение. Его недостатком является то, что процесс обучения останавливается.
Еще один простой способ предотвращения переобучение - это ограничение количества скрытых блоков на каждом уровне или ограничения глубины сети. Для сверточных сетей размер фильтра также влияет на количество параметров. Ограничение количества параметров напрямую ограничивает предсказательную силу сети, увеличивающую сложность функций, которую она может выполнять с данными, и, таким образом, ограничивает количество переобучения. Это эквивалентно «нулевая норма ».
Простая форма добавленного регуляризатора - это уменьшение веса, которое просто дополнительной ошибки, пропорциональную весов (L1 norm ) или квадрату величины (L2 norm ) весового вектора к ошибке в каждом узле. Уровень приемлемой сложности модели можно снизить, увеличив константу пропорциональности, тем самым увеличив размер за большие весовые стандарты.
Регуляризация L2 - наиболее распространенная форма регуляризации. Это может быть реализовано путем штрафования квадрата величины всех параметров непосредственно в объективе. Регуляризация L2 имеет интуитивно понятную интерпретацию сильного наказания векторов пиковых весов и предпочтение векторов диффузных весов. Из-за мультипликативного взаимодействия между весами и входами это полезное свойство, побуждающая сеть использовать все свои входы немного, а не некоторые из них много.
Регуляризация L1 - еще одна распространенная форма. Можно комбинировать L1 с регуляризацией L2 (это называется эластичной сетевой регуляризацией ). Регуляризация L1 приводит к тому, что весовые становятся разреженными во время оптимизации. Другими словами, нейроны с регуляризацией L1 в конечном итоге используют только разреженное подмножество своих наиболее важных входных данных и становятся почти инвариантными к шумным входам.
Другой способ регулирования обеспечивает соблюдение максимальной границы веса для каждого использования прогнозируемого градиентного спуска для обеспечения соблюдения ограничения. На практике это соответствует выполнению обновления как обычно, а затем наложению ограничения ограничения вектора весов 
Объединение теряет точные пространственные отношения между частями высокого уровня (такими как нос и рот на изображении лица). Эти отношения необходимы для распознавания личности. Перекрытие пулов, чтобы каждая функция находилась в нескольких пулах, помогает сохранить информацию. Сам по себе перевод не может экстраполировать понимание геометрических отношений на радикально новую точку зрения. С другой стороны, люди очень хорошо умеют экстраполировать; увидев новую форму, как только она распознать ее с другой точки зрения.
Настоящее время распространенным способом решения этой проблемы является обучение сети преобразованных данных в разных ориентациях, масштабах, освещении и т. д. что сеть может справиться с этими вариациями. Это требует больших вычислений для больших наборов данных. Альтернативой является использование иерархии координатных кадров и использования группы нейронов для представления сочетания формы признака и его положения относительно сетчатки. Поза относительно сетчатки - это отношение между системой координат сетчатки и системой внутренних функций.
Таким образом, один из способов представления чего-либо - это встроить в нее систему координат. Как только это будет сделано, крупные черты лица можно будет распознать, используя согласованность поз их частей (например, позы носа и рта делают последовательное предсказание позы всего лица). Использование этого подхода гарантирует, что сущность более высокого уровня (например, лицо) присутствует, когда более низкий уровень (например, нос и рот) определяет свой прогноз позы. Элементы визуальных объектов, представляющие собой визуальные объекты, позволяют моделировать пространственные преобразования как линейные операции, которые упрощают для просмотра иерархии визуальных объектов и обобщение по точкам зрения. Это похоже на то, как человеческая зрительная система накладывает рамки для представления форм.
Часто используются CNN. в системы распознавания изображений. В 2012 году в базе данных MNIST сообщалось о част ошибок 0,23 процента. В другой статье об использовании CNN для использования в сообщениях, что процесс обучения был «на удивление быстрым»; в той же статье лучшие опубликованные результаты по состоянию на 2011 год получены в базе данных MNIST и базе данных NORB. Впечатление аналогичный CNN под названием AlexNet выиграл ImageNet Large Scale Visual Recognition Challenge 2012.
В применении к распознаванию лиц CNN значительно снизили количество ошибок. В другой статье сообщается, что уровень распознавания 97,6 процента «5600 изображений более 10 предметов». CNN использовались для объективной оценки качества видео после ручного обучения; получившаяся система очень низкую среднеквадратичную ошибку.
. ImageNet Large Scale Visual Recognition Challenge - эталон классификации и обнаружения объектов с миллионами изображений и сотнями классов объектов. В ILSVRC 2014, крупномасштабная модель визуального распознавания, почти каждая высокопоставленная команда использовала CNN в качестве своей конкретной структуры. Победитель (основа DeepDream ) увеличил среднее значение точности обнаружения объектов до 0,439329 и уменьшил ошибку классификации до 0,06656, лучшего результата на сегодняшний день. В его сети применено более 30 слоев. Производительность сверточных нейронных сетей в тестах ImageNet была близка к показателям людей. Лучшие алгоритмы все еще борются с маленькими или тонкими объектами, такими как маленький муравей на стебле цветка или человек, размерий перо в руке. У них также есть проблемы с изображениями, искаженными фильтрами, что становится все распространенным явлением в современных цифровых камерах. Напротив, такие изображения редко беспокоят людей. Однако у людей обычно возникают проблемы с проблемами. Например, они не умеют классать объекты по мелкозернистым категориям, таким как конкретная порода собак или вид птиц, в то время как сверточные нейронные сети справляются с этим.
В 2015 году многослойная CNN возможность обнаружения лиц под разными углами, в том числе перевернутыми, даже если они частично закрыты, с конкурентоспособной производительностью. Сеть обучена на базе данных из 200 000 изображений, которые включают лица под разными углами и ориентациями, и еще 20 миллионов изображений без лиц. Они использовали пакеты из 128 изображений с более чем 50 000 повторений.
Сверточные нейронные сети использовались для определения намерения человека управлять вспомогательными устройствами. Есть два способа использовать CNN, принимают сигналы EMG в качестве входных. Один из способов - применить спектограмму и сопоставить ее с 2D-объектом. Затем ее можно использовать аналогично распознаванию изображений. Другой способ - использовать сопроводительные CNN, которые напрямую сопоставляют необработанные сигналы ЭМГ с классами (классификация) или положением руки / сустава (регрессия).
По сравнению с данными изображения В области применения CNN для классификации видео ведется сравнительно мало работы. Видео сложнее, поскольку имеет другое (временное) измерение. Однако были исследованы некоторые расширения CNN в видеодомене. Один из подходов - рассматривать пространство и время как эквивалентные измерения входных данных и выполнять свертки как во времени, так и в пространстве. Другой способ - объединить функции двух сверточных нейронных сетей, одну для пространственного и одну для временного потока. Долговременная кратковременная память (LSTM) повторяющиеся блоки обычно включаются после CNN для учета межкадровых или межклиповых зависимостей. введены схемы неконтролируемого обучения для обучения пространственно-временным функциям, основанные на сверточных ограниченных машинах Больцмана и независимом подпространственном анализе.
CNN также были исследованы для обработки естественного языка. Модели CNN эффективны для различных задач НЛП и достигают отличных результатов в семантическом синтаксическом анализе, поиск запросов, моделировании предложений, классификации, прогнозировании и других задачах НЛП.
CNN с одномерными свертками использовалась на временном ряде в частотной области (спектральный остаток) неконтролируемой моделью для обнаружения аномалий во временной области.
CNNs имеют был использован в обнаружении наркотиков. Прогнозирование взаимодействия между молекулами и биологическими белками может определить потенциальные способы лечения. В 2015 году Atomwise представила AtomNet, первую нейронную сеть с глубоким обучением для структурного рационального дизайна лекарств. Система непосредственно на трехмерных представлениях химических взаимодействий. Подобно тому, как сети распознавания изображений учатся составлять более мелкие пространственно близкие элементы в более крупные сложные структуры, AtomNet обнаруживает химические свойства, такие как ароматичность, sp-углерод и водородная связь. Впоследствии AtomNet использовалась для прогнозирования новых кандидатов биомолекул для множественных заболеваний, в первую очередь для лечения вируса Эбола и рассеянного склероза.
CNN могут быть естественным образом адаптированы для анализа достаточно большой коллекции временных рядов данных, представляющих однонедельные потоки физической активности человека, дополненные обширными клиническими данными (включая регистр смертей, как предусмотрено, например, исследованием NHANES ). Простая CNN была объединена с моделью пропорциональных рисков Кокса-Гомпертца и использовалась для создания контрольного примера цифровых биомаркеров старения в форме предиктора смертности от всех причин..
CNN использовались в игре шашки. С 1999 по 2001 год Фогель и Челлапилла опубликовали статьи, показывающие, как сверточная нейронная сеть может научиться играть в шашку, используя коэволюцию. В процессе обучения не использовались предыдущие профессиональные игры человека, а скорее был сосредоточен на минимальном наборе информации, содержащейся в шахматной доске: расположение и тип фигур, а также разница в количестве фигур между двумя сторонами. В конечном итоге программа (Blondie24 ) была протестирована в 165 играх с игроками и заняла наивысшее значение в 0,4%. Он также выиграл у программы Chinook на ее "экспертном" уровне игры.
CNN использовались в компьютерном Go. В декабре 2014 года Кларк и Сторки опубликовали статью, показывающую, что CNN, обученная путем обучения с учителем из базы данных профессиональных игр людей, может превзойти GNU Go и выиграть несколько игр у поиска по дереву Монте-Карло Fuego 1.1 в разы быстрее, чем Fuego играл. Позже было объявлено, что большая 12-слойная сверточная нейронная сеть правильно предсказала профессиональный ход в 55% позиций, что сравнимо с точностью игрока-человека 6 дан. Когда обученная сверточная сеть использовалась непосредственно для игры в игры Go без какого-либо поиска, она превосходила традиционную поисковую программу GNU Go в 97% игр и соответствовала производительности дерева Монте-Карло. search программа Fuego, моделирующая десять тысяч разыгрываний (около миллиона позиций) за ход.
Пара CNN для выбора ходов, которые нужно попробовать («политическая сеть») и оценки позиций («сеть ценностей»), управляющих MCTS использовались AlphaGo, первой, кто победил лучшего игрока того времени.
Рекуррентные нейронные сети обычно считаются лучшими архитектурами нейронных сетей для прогнозирования временных рядов (и моделирования последовательности в целом), но недавние исследования показывают, что сверточные сети могут работать сопоставимо или даже лучше. Расширенные свертки могут позволить одномерным сверточным нейронным сетям эффективно изучать зависимости временных рядов. Свертки могут быть реализованы более эффективно, чем решения на основе RNN, и они не страдают от исчезающих (или взрывных) градиентов. Сверточные сети могут обеспечить улучшенную производительность прогнозирования, когда есть несколько похожих временных рядов, на которых можно учиться. CNN также могут применяться для решения других задач анализа временных рядов (например, классификации временных рядов или квантильного прогнозирования).
Поскольку археологические находки, такие как глиняные таблички с клинописью, все чаще приобретаются с помощью 3D-сканеров Становятся доступны первые эталонные наборы данных, такие как HeiCuBeDa, обеспечивающие почти 2.000 нормализованных 2D- и 3D-наборов данных, подготовленных с помощью GigaMesh Software Framework. Таким образом, измерения на основе кривизны используются в сочетании с геометрическими нейронными сетями (GNN), например. для классификации периода, когда эти глиняные таблички являются одними из самых старых документов в истории человечества.
Для многих приложений данные обучения менее доступны. Сверточным нейронным сетям обычно требуется большой объем обучающих данных, чтобы избежать переобучения . Распространенным методом является обучение сети на большом наборе данных из связанного домена. После того, как параметры сети сойдутся, выполняется дополнительный этап обучения с использованием данных в домене для точной настройки весов сети. Это позволяет успешно применять сверточные сети для решения задач с небольшими обучающими наборами.
Сквозное обучение и прогнозирование - обычная практика в компьютерном зрении. Однако для критических систем, таких как беспилотные автомобили, требуются интерпретируемые человеком объяснения. Благодаря недавним достижениям в области визуальной заметности, пространственного и временного внимания, наиболее критические пространственные области / временные моменты могут быть визуализированы для подтверждения прогнозов CNN.
Глубокие Q-сети (DQN) - это тип модели глубокого обучения, сочетающий глубокую нейронную сеть с Q-обучением, форма обучения с подкреплением. В отличие от более ранних агентов обучения с подкреплением, DQN, использующие CNN, могут обучаться непосредственно из многомерных сенсорных входов.
Предварительные результаты были представлены в 2014 году, а в феврале 2015 года - в сопроводительном документе. В исследовании описывается применение к Atari 2600 игры. Этому предшествовали другие модели глубокого обучения с подкреплением.
Сверточные сети глубоких убеждений (CDBN) имеют структуру, очень похожую на сверточные нейронные сети, и обучаются аналогично сетям глубоких убеждений. Поэтому они используют двухмерную структуру изображений, как это делают CNN, и используют предварительное обучение, такое как сети глубоких убеждений. Они обеспечивают общую структуру, которую можно использовать во многих задачах обработки изображений и сигналов. Результаты тестов для стандартных наборов данных изображений, таких как CIFAR, были получены с использованием CDBN.