
Войти
 Одна инструкция, несколько данных
Одна инструкция, несколько данных Одна инструкция, несколько данных (SIMD ) - это класс из параллельных компьютеров в таксономии Флинна. Он описывает компьютеры с несколькими элементами обработки, которые одновременно выполняют одну и ту же операцию с несколькими точками данных. Такие машины используют параллелизм уровня данных, но не параллелизм : есть одновременные (параллельные) вычисления, но только один процесс (инструкция) в данный момент. SIMD особенно подходит для обычных задач, таких как регулировка контрастности цифрового изображения или регулировка громкости цифрового звука. Большинство современных конструкций ЦП включают инструкции SIMD для повышения производительности использования мультимедиа. SIMD не следует путать с SIMT, который использует потоков.
Первое использование инструкций SIMD было в ILLIAC IV, которое было завершено в 1966 году.
SIMD послужило основой для векторных суперкомпьютеров начала 1970-х, такие как CDC Star-100 и Texas Instruments ASC, которые могли оперировать «вектором» данных с помощью одной инструкции. Векторная обработка была особенно популяризирована компанией Cray в 1970-х и 1980-х годах. Архитектуры векторной обработки теперь считаются отдельными от компьютеров SIMD, исходя из того факта, что векторные компьютеры обрабатывали векторы по одному слову за раз через конвейерные процессоры (хотя все еще основаны на одной инструкции), тогда как современные компьютеры SIMD обрабатывают все элементы вектора. одновременно.
Первая эра современных компьютеров SIMD характеризовалась массово-параллельной обработкой -стилем суперкомпьютерами, такими как Thinking Machines СМ-1 и СМ-2. На этих компьютерах было много процессоров с ограниченной функциональностью, которые могли работать параллельно. Например, каждый из 65 536 однобитовых процессоров в Thinking Machines CM-2 будет выполнять одну и ту же инструкцию в одно и то же время, что позволяет, например, логически объединить 65 536 пар бит за раз, используя сеть, соединенную с гиперкубом или ОЗУ, выделенное процессору, для поиска его операндов. Супервычисления отошли от подхода SIMD, когда недорогие скалярные MIMD подходы, основанные на обычных процессорах, таких как Intel i860 XP, стали более мощными, а интерес к SIMD ослаб.
Текущая эра процессоров SIMD выросла из рынка настольных компьютеров, а не из рынка суперкомпьютеров. Поскольку настольные процессоры стали достаточно мощными, чтобы поддерживать игры в реальном времени и обработку аудио / видео в течение 1990-х годов, спрос на этот конкретный тип вычислительной мощности вырос, и производители микропроцессоров обратились к SIMD, чтобы удовлетворить спрос. Hewlett-Packard представила инструкции MAX в настольных компьютерах PA-RISC 1.1 в 1994 году для ускорения декодирования MPEG. Sun Microsystems представила целочисленные инструкции SIMD в своих расширениях набора команд "VIS " в 1995 году в своем микропроцессоре UltraSPARC I. Компания MIPS последовала их примеру, выпустив аналогичную систему MDMX.
Первый широко распространенный SIMD для настольных ПК был с расширениями Intel MMX для архитектуры x86 в 1996 году. Это вызвало появление гораздо более мощного AltiVec в системах Motorola PowerPC и IBM POWER. В ответ Intel в 1999 году представила совершенно новую систему SSE. С тех пор было несколько расширений наборов инструкций SIMD для обеих архитектур.
Все эти разработки были ориентированы на поддержку графики в реальном времени и, следовательно, ориентированы на обработку в двух, трех или четыре измерения, обычно с длиной вектора от двух до шестнадцати слов, в зависимости от типа данных и архитектуры. Когда необходимо отличать новые архитектуры SIMD от старых, более новые архитектуры считаются архитектурами с «короткими векторами», поскольку более ранние суперкомпьютеры SIMD и векторные имели длину вектора от 64 до 64000. Современный суперкомпьютер почти всегда представляет собой кластер компьютеров MIMD, каждый из которых реализует инструкции SIMD (короткие векторные). Современный настольный компьютер часто представляет собой многопроцессорный компьютер MIMD, где каждый процессор может выполнять инструкции SIMD с коротким вектором.
Приложение, которое может использовать преимущества SIMD, - это приложение, в котором одно и то же значение добавляется (или вычитается из) большого количества точек данных, что является обычной операцией во многих мультимедийные приложения. Одним из примеров может быть изменение яркости изображения. Каждый пиксель изображения состоит из трех значений яркости красной (R), зеленой (G) и синей (B) частей цвета. Для изменения яркости значения R, G и B считываются из памяти, к ним добавляется (или вычитается) значение, а полученные значения записываются обратно в память.
В процессоре SIMD есть два улучшения этого процесса. С одной стороны, данные понимаются как блоки, и сразу несколько значений могут быть загружены. Вместо серии инструкций, говорящих «получить этот пиксель, теперь получить следующий пиксель», процессор SIMD будет иметь единственную инструкцию, которая фактически говорит «получить n пикселей» (где n - число, которое варьируется от проекта к проекту). По ряду причин это может занять гораздо меньше времени, чем получение каждого пикселя по отдельности, как при традиционной архитектуре ЦП.
Другое преимущество заключается в том, что инструкция обрабатывает все загруженные данные за одну операцию. Другими словами, если система SIMD работает, загружая восемь точек данных одновременно, операция add, применяемая к данным, будет выполняться для всех восьми значений одновременно. Этот параллелизм отличается от параллелизма, обеспечиваемого суперскалярным процессором ; восемь значений обрабатываются параллельно даже на не суперскалярном процессоре, и суперскалярный процессор может иметь возможность выполнять несколько операций SIMD параллельно.
Для устранения проблем 1 и 5 в векторном расширении RISC-V и в ARM Scalable Vector Extension используется альтернативный подход. : вместо того, чтобы раскрывать детали уровня подрегистра программисту, набор команд абстрагирует их как несколько «векторных регистров», которые используют одни и те же интерфейсы для всех процессоров с этим набором команд. Аппаратное обеспечение решает все проблемы с выравниванием и «извлечением» петель. Машины с разными размерами векторов могут запускать один и тот же код. LLVM называет этот векторный тип vscale.
Примеры суперкомпьютеров SIMD (не включая векторные процессоры ):
Мелкомасштабные (64 или 128 бит) SIMD стали популярны в процессорах общего назначения в начале 1990-х годов и продолжались до 1997 года и позже с помощью видеоинструкций движения (MVI) для Альфа. Инструкции SIMD можно найти, в той или иной степени, на большинстве процессоров, включая IBM AltiVec и PowerPC, HP PA-RISC Multimedia Acceleration eXtensions (MAX), Intel, MMX и iwMMXt, SSE, SSE2, SSE3 SSSE3 и SSE4.x, AMD 3DNow!, ARC подсистема ARC Video, SPARC VIS и VIS2, Sun MAJC, ARM Технология Neon, MIPS 'MDMX (MaDMaX) и MIPS-3D. IBM, Sony и Toshiba совместно разработали SPU в процессоре Cell Processor. Набор инструкций в значительной степени основан на SIMD. Philips, теперь NXP, разработал несколько процессоров SIMD под названием Xetal. Xetal имеет 320 16-битных процессорных элементов, специально разработанных для задач зрения.
Современные графические процессоры (графические процессоры) часто представляют собой широкие реализации SIMD, способные выполнять переходы, загрузку и хранение по 128 или 256 бит за раз.
Последние инструкции Intel AVX-512 SIMD теперь обрабатывают 512 бит данных одновременно.
 Обычное утроение четырех 8-битных чисел. ЦП загружает одно 8-битное число в R1, умножает его на R2, а затем сохраняет ответ из R3 обратно в ОЗУ. Этот процесс повторяется для каждого числа.
Обычное утроение четырех 8-битных чисел. ЦП загружает одно 8-битное число в R1, умножает его на R2, а затем сохраняет ответ из R3 обратно в ОЗУ. Этот процесс повторяется для каждого числа. 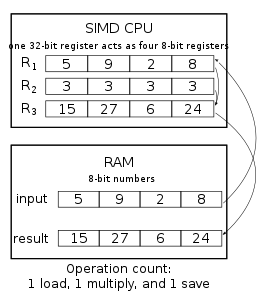 Утроение SIMD четырех 8-битных чисел. ЦП загружает сразу 4 числа, умножает их все за одно SIMD-умножение и сохраняет все сразу обратно в ОЗУ. Теоретически скорость можно умножить на 4.
Утроение SIMD четырех 8-битных чисел. ЦП загружает сразу 4 числа, умножает их все за одно SIMD-умножение и сохраняет все сразу обратно в ОЗУ. Теоретически скорость можно умножить на 4. инструкции SIMD широко используются для обработки трехмерной графики, хотя современные графические карты со встроенным SIMD в значительной степени переняли эту задачу от ЦП. Некоторые системы также включают функции перестановки, которые повторно упаковывают элементы внутри векторов, что делает их особенно полезными для обработки и сжатия данных. Они также используются в криптографии. Тенденция универсальных вычислений на графических процессорах (GPGPU ) может привести к более широкому использованию SIMD в будущем.
Внедрение систем SIMD в программном обеспечении персональных компьютеров поначалу шло медленно из-за ряда проблем. Во-первых, многие из ранних наборов инструкций SIMD имели тенденцию снижать общую производительность системы из-за повторного использования существующих регистров с плавающей запятой. Другие системы, такие как MMX и 3DNow!, предлагали поддержку типов данных, которые не были интересны широкой аудитории, и имели дорогостоящие инструкции переключения контекста для переключения между использованием FPU и регистры MMX . Компиляторам также часто не хватало поддержки, что заставляло программистов прибегать к кодированию на языке ассемблера.
SIMD на x86 запускался медленно. Появление 3DNow! от AMD и SSE от Intel несколько запутало ситуацию, но сегодня система, похоже, успокоилась (после AMD приняла SSE), а новые компиляторы должны привести к большему количеству программного обеспечения с поддержкой SIMD. Intel и AMD теперь предоставляют оптимизированные математические библиотеки, в которых используются инструкции SIMD, и альтернативы с открытым исходным кодом, такие как, и начали появляться (см. Также libm ).
Apple Computer, добился большего успеха, хотя и вошел в Рынок SIMD позже остальных. AltiVec предлагал богатую систему, и ее можно было программировать с использованием все более сложных компиляторов от Motorola, IBM и GNU, поэтому программирование на ассемблере требуется редко. Кроме того, многие системы, которые выиграли бы от SIMD, были поставлены самой Apple, например iTunes и QuickTime. Однако в 2006 году Apple компьютеры перешли на процессоры Intel x86. Apple API и инструменты разработки (XCode ) были модифицированы для поддержки SSE2 и SSE3, а также AltiVec. Apple была основным покупателем чипов PowerPC у IBM и Freescale Semiconductor, и, хотя они отказались от платформы, дальнейшее развитие f AltiVec продолжается в нескольких проектах PowerPC и Power ISA от Freescale и IBM.
SIMD в регистре, или SWAR, представляет собой набор методов и приемов, используемых для выполнения SIMD в регистрах общего назначения на оборудовании, которое не обеспечивает прямой поддержки инструкций SIMD. Это можно использовать для использования параллелизма в определенных алгоритмах даже на оборудовании, которое не поддерживает SIMD напрямую.
Издатели наборов инструкций SIMD обычно создают свои собственные расширения языка C / C ++ с встроенными функциями или специальными типами данных, гарантирующими генерацию вектора код. Intel, AltiVec и ARM NEON предоставляют расширения, широко используемые компиляторами для их процессоров. (Более сложные операции - задача векторных математических библиотек.)
Компилятор GNU C продвигает расширения на шаг вперед, превращая их в универсальный интерфейс, который можно использовать на любой платформе. предоставление способа определения типов данных SIMD. Компилятор LLVM Clang также реализует эту функцию с аналогичным интерфейсом, определенным в IR. Крейт Pack_simd в Rust использует этот интерфейс, также как и Swift 2.0+.
В C ++ есть экспериментальный интерфейс std :: experimental :: simd, который работает аналогично расширению GCC. Кажется, это реализована в libcxx LLVM. Для GCC и libstdc ++ доступна библиотека-оболочка, которая строится на основе расширения GCC.
Microsoft добавила SIMD в .NET в RyuJIT. Пакет System.Numerics.Vector, доступный в NuGet, реализует типы данных SIMD.
Вместо того, чтобы предоставлять тип данных SIMD, компиляторам также можно намекнуть на автоматическую векторизацию некоторых циклов, потенциально требуя некоторых утверждения об отсутствии зависимости данных. Это не так гибко, как прямое управление переменными SIMD, но проще в использовании. OpenMP 4.0+ имеет подсказку #pragma omp simd. Cilk имеет аналогичную функцию #pragma simd. GCC и Clang также имеют свои собственные прагмы для векторизации циклов.
Обычно ожидается, что потребительское программное обеспечение будет работать на ряде процессоров, охватывающих несколько поколений, что может ограничить возможность программиста использовать новые инструкции SIMD для повышения вычислительной производительности программа. Решение состоит в том, чтобы включить несколько версий одного и того же кода, использующего либо старые, либо новые технологии SIMD, и выбрать ту, которая лучше всего подходит для ЦП пользователя во время выполнения (динамическая отправка ). Существует два основных лагеря решений:
Первое решение поддерживается компилятором Intel C ++ и коллекцией компиляторов GNU начиная с GCC 6. Однако, поскольку GCC требует явных меток для «клонирования» функций, более простой способ сделать таким образом, скомпилировать несколько версий библиотеки и позволить системе glibc выбрать одну, подход, принятый поддерживаемым Intel проектом Clear Linux.
В 2013 году Джон Маккатчан объявил, что он создал высокопроизводительный интерфейс для наборов инструкций SIMD для языка программирования Dart, в результате чего Впервые преимущества SIMD для веб-программ. Интерфейс состоит из двух типов:
Экземпляры этих типов неизменяемы и в оптимизированном коде отображаются напрямую в регистры SIMD. Операции, выраженные в Dart, обычно компилируются в одну инструкцию без каких-либо накладных расходов. Это похоже на встроенные функции C и C ++. Тесты для 4 × 4 матричного умножения, трехмерного преобразования вершин и визуализации набора Мандельброта показывают почти 400% ускорение по сравнению с написанным скалярным кодом в Дарт.
Работа МакКатчана над Dart, которая теперь называется SIMD.js, была принята ECMAScript, и Intel объявила на IDF 2013, что они внедряют спецификацию МакКатчана как для V8, так и для SpiderMonkey. Однако к 2017 году SIMD.js был исключен из стандартной очереди ECMAScript в пользу использования аналогичного интерфейса в WebAssembly. По состоянию на август 2020 года интерфейс WebAssembly остается незавершенным, но его портативная 128-битная функция SIMD уже нашла применение во многих движках.
Emscripten, компилятор Mozilla C / C ++ - to-JavaScript, с расширениями, может включать компиляцию программ C ++, которые используют встроенные функции SIMD или векторный код в стиле GCC, в SIMD API JavaScript, что приводит к эквивалентному ускорению по сравнению с в скалярный код. Он также поддерживает предложение 128-битной SIMD WebAssembly.
Хотя в целом оказалось трудным найти устойчивые коммерческие приложения для процессоров, поддерживающих только SIMD, хотя это и имело определенный успех. - это GAPP, который был разработан Lockheed Martin и внедрен в коммерческий сектор путем их выделения. Последние воплощения GAPP стали мощным инструментом в приложениях обработки видео в реальном времени, таких как преобразование между различными стандартами видео и частотой кадров (NTSC в / из PAL, NTSC в / из форматов HDTV и т. Д.), деинтерлейсинг, уменьшение шума изображения, адаптивное сжатие видео и улучшение изображения.
Более распространенное приложение для SIMD можно найти в видеоиграх : почти каждая современная игровая консоль с 1998 где-то включала процессор SIMD в своей архитектуре. PlayStation 2 была необычна тем, что один из ее векторных блоков с плавающей запятой мог функционировать как автономный DSP, выполняющий собственный поток команд, или как сопроцессор, управляемый обычными командами ЦП. Приложения 3D-графики, как правило, хорошо поддаются обработке SIMD, поскольку они в значительной степени полагаются на операции с 4-мерными векторами. Microsoft Direct3D 9.0 теперь выбирает во время выполнения специфичные для процессора реализации своих собственных математических операций, включая использование инструкций с поддержкой SIMD.
Одним из последних процессоров, использующих векторную обработку, является Cell Processor, разработанный IBM в сотрудничестве с Toshiba и Sony. Он использует несколько процессоров SIMD (архитектура NUMA, каждый с независимым локальным хранилищем и управляется центральным процессором общего назначения) и ориентирован на огромные наборы данных, необходимые для обработки 3D и видео. Приложения. Он отличается от традиционных ISA тем, что изначально является SIMD без отдельных скалярных регистров.
Ziilabs произвела процессор типа SIMD для использования на мобильных устройствах, таких как медиаплееры и мобильные телефоны.
Коммерческие процессоры SIMD большего размера доступны от ClearSpeed Technology, Ltd. и Stream Processors, Inc.. ClearSpeed CSX600 (2004) имеет 96 ядер, каждое с двумя модулями с плавающей запятой двойной точности, в то время как CSX700 (2008) имеет 192. Потоковые процессоры возглавляет компьютерный архитектор Билл Далли. Их процессор Storm-1 (2007) содержит 80 ядер SIMD, управляемых процессором MIPS.