
Войти
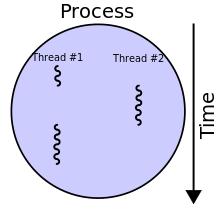 Процесс с двумя потоками выполнения, работающий на одном процессоре
Процесс с двумя потоками выполнения, работающий на одном процессоре В информатике, поток выполнения - это наименьшая последовательность запрограммированных инструкций, которой может независимо управлять планировщик, который обычно является частью операционной системы. Реализация потоков и процессов различается в разных операционных системах, но в большинстве случаев поток является компонентом процесса. Несколько потоков могут существовать в одном процессе, выполняя одновременно и разделяя ресурсы, такие как память, в то время как разные процессы не разделяют эти ресурсы. В частности, потоки процесса совместно используют его исполняемый код и значения его динамически выделяемых переменных и не локальных для потока глобальных переменных в любой момент времени..
Обычно системы с одним процессором реализовать многопоточность посредством квантования времени : центральный процессор (CPU) переключается между различными программными потоками. Это переключение контекста обычно происходит очень часто и достаточно быстро, чтобы пользователи воспринимали потоки или задачи как выполняющиеся параллельно. В многопроцессорной или многоядерной системе, несколько потоков могут выполняться в параллельном, при этом каждый процессор или ядро выполняет отдельный поток одновременно; на процессоре или ядре с аппаратными потоками отдельные программные потоки также могут выполняться одновременно отдельными аппаратными потоками.
Потоки впервые появились под названием «задачи» в Мультипрограммирование OS / 360 с переменным числом задач (MVT) в 1967 году. Saltzer ( 1966) зачисляет Виктора Александровича Высоцкого с термином «нить». планировщики процессов многих современных операционных систем напрямую поддерживают как временные, так и многопроцессорные потоки, а ядро операционной системы позволяет программистам управлять потоками, предоставляя необходимые функции через систему -call интерфейс. Некоторые реализации потоковой передачи называются потоками ядра, тогда как легковесные процессы (LWP) представляют собой определенный тип потока ядра, который разделяет одно и то же состояние и информацию. Более того, программы могут иметь потоки пользовательского пространства при работе с таймерами, сигналами или другими методами для прерывания их собственного выполнения, выполняя своего рода ad hoc квантование времени.
Потоки отличаются от традиционных многозадачных процессов операционной системы процессов несколькими способами:
Такие системы, как Windows NT и OS / 2, как говорят, имеют дешевые потоки и дорогие процессы; в других операционных системах разница не так велика, за исключением стоимости переключателя адресного пространства, который на некоторых архитектурах (в частности, x86 ) приводит к обратному преобразованию буфер (TLB) очищается.
В компьютерном программировании однопоточность - это обработка одной команды за раз. Противоположностью однопоточности является многопоточность.
При формальном анализе семантики переменных и состояния процесса термин однопоточность может использоваться по-разному для обозначения «обратного отслеживания в пределах одного потока». ", который широко распространен в сообществе функционального программирования.
Многопоточность в основном встречается в многозадачных операционных системах. Многопоточность - это широко распространенная модель программирования и выполнения, которая позволяет нескольким потокам существовать в контексте одного процесса. Эти потоки совместно используют ресурсы процесса, но могут выполняться независимо. Модель многопоточного программирования предоставляет разработчикам полезную абстракцию параллельного выполнения. Многопоточность также может применяться к одному процессу, чтобы обеспечить параллельное выполнение в многопроцессорной системе.
Многопоточные приложения обладают следующими преимуществами:
Многопоточность имеет следующие недостатки:
Операционные системы планируют потоки либо с приоритетом, либо совместно. В многопользовательских операционных системах, вытесняющая многопоточность является более широко используемым подходом для более тонкого управления временем выполнения посредством переключения контекста. Однако упреждающее планирование может переключать потоки контекста в моменты, непредвиденные программистами, вызывая конвой блокировок, инверсию приоритета или другие побочные эффекты. Напротив, кооперативная многопоточность полагается на потоки, чтобы отказаться от контроля над выполнением, таким образом гарантируя, что потоки выполняются до завершения. Это может создать проблемы, если совместный многозадачный поток блокирует, ожидая ресурс , или если он истощает другие потоки, не передавая контроль над выполнением во время интенсивных вычислений.
До начала 2000-х годов большинство настольных компьютеров имели только один одноядерный процессор без поддержки аппаратных потоков, хотя потоки все еще использовались на таких компьютерах, поскольку переключение между потоками, как правило, все еще быстрее, чем полный процесс переключает контекст. В 2002 году Intel добавила поддержку одновременной многопоточности в процессор Pentium 4 под названием hyper-threading ; в 2005 году они представили двухъядерный процессор Pentium D, а AMD представили двухъядерный процессор Athlon 64 X2.
Процессоры во встроенных системах, которые предъявляют более высокие требования к режимам реального времени, могут поддерживать многопоточность за счет уменьшения времени переключения потоков, возможно, путем выделения выделенного регистровый файл для каждого потока вместо сохранения / восстановления общего регистрового файла.
Планирование может выполняться на уровне ядра или на уровне пользователя, а многозадачность может выполняться вытесняюще или совместно. Это дает множество связанных понятий.
На уровне ядра процесс содержит один или несколько потоков ядра, которые совместно используют ресурсы процесса, такие как память и дескрипторы файлов: процесс - это единица ресурсов, а поток - это единица планирования и исполнение. Планирование ядра обычно выполняется в упреждающем или, что реже, совместно. На уровне пользователя процесс, такой как система времени выполнения, может сам планировать несколько потоков выполнения. Если они не разделяют данные, как в Erlang, они обычно аналогичным образом называются процессами, а если они совместно используют данные, они обычно называются (пользовательскими) потоками, особенно если они запланированы с упреждением. Совместно запланированные пользовательские потоки известны как волокна; разные процессы могут по-разному планировать пользовательские потоки. Пользовательские потоки могут выполняться потоками ядра различными способами (один-к-одному, многие-к-одному, многие-ко-многим). Термин «облегченный процесс » по-разному относится к пользовательским потокам или механизмам ядра для планирования пользовательских потоков в потоках ядра.
Процесс - это «тяжеловесная» единица планирования ядра, поскольку создание, уничтожение и переключение процессов относительно дороги. Процессы владеют ресурсами, выделенными операционной системой. Ресурсы включают память (как для кода, так и для данных), дескрипторы файлов, сокеты, дескрипторы устройств, окна и блок управления процессом. Процессы изолированы с помощью изоляции процессов и не используют совместно адресные пространства или файловые ресурсы, кроме как с помощью явных методов, таких как наследование дескрипторов файлов или сегментов разделяемой памяти или отображение одного и того же файла совместно - см. межпроцессное взаимодействие. Создание или уничтожение процесса относительно дорого, так как ресурсы необходимо приобретать или высвобождать. Процессы обычно являются многозадачными с вытеснением, а переключение процессов является относительно дорогостоящим, помимо базовой стоимости переключения контекста, из-за таких проблем, как очистка кеша.
Поток ядра - это «облегченная» единица планирование ядра. В каждом процессе существует как минимум один поток ядра. Если в процессе существует несколько потоков ядра, они используют одну и ту же память и файловые ресурсы. Потоки ядра являются многозадачными с вытеснением, если процесс планировщика операционной системы является вытесняющим. Потоки ядра не владеют ресурсами, за исключением стека , копии регистров, включая счетчик программ и локальное хранилище потока (если есть), поэтому их создание и уничтожение относительно дешевы. Переключение потоков также относительно дешево: оно требует переключения контекста (сохранение и восстановление регистров и указателя стека), но не изменяет виртуальную память и, таким образом, поддерживает кеширование (оставляя TLB действительным). Ядро может назначить по одному потоку каждому логическому ядру в системе (потому что каждый процессор разбивается на несколько логических ядер, если он поддерживает многопоточность, или поддерживает только одно логическое ядро на физическое ядро, если это не так), и может менять потоки, которые заблокироваться. Однако для обмена потоками ядра требуется гораздо больше времени, чем для пользовательских потоков.
Потоки иногда реализуются в библиотеках пользовательского пространства, поэтому они называются пользовательскими потоками. Ядро не знает о них, поэтому они управляются и планируются в пользовательском пространстве. Некоторые реализации основывают свои пользовательские потоки на нескольких потоках ядра, чтобы извлечь выгоду из многопроцессорных машин (M: N модель ). В этой статье термин «поток» (без квалификатора ядра или пользователя) по умолчанию относится к потокам ядра. Пользовательские потоки, реализуемые виртуальными машинами, также называются зелеными потоками. Пользовательские потоки, как правило, быстро создаются и управляются, но не могут использовать преимущества многопоточности или многопроцессорности и будут заблокированы, если все связанные с ними потоки ядра будут заблокированы, даже если есть некоторые пользовательские потоки, готовые к запуску.
Волокна - это еще более легкая единица планирования, которая совместно запланирована : работающее волокно должно явно "yield ", чтобы позволить другому волокну работать, что делает их реализацию намного проще ядра или. Волокно можно запланировать для запуска в любом потоке одного и того же процесса. Это позволяет приложениям повышать производительность, управляя расписанием самостоятельно, вместо того, чтобы полагаться на планировщик ядра (который может не быть настроен для приложения). Среды параллельного программирования, такие как OpenMP, обычно реализуют свои задачи через волокна. С волокнами тесно связаны сопрограммы, с той разницей, что сопрограммы являются конструкцией уровня языка, а волокна - конструкцией системного уровня.
Потоки в одном процессе используют одно и то же адресное пространство. Это позволяет одновременно выполняющемуся коду связать плотно и удобно для обмена данными без накладных расходов или сложности IPC. Однако при совместном использовании между потоками даже простые структуры данных становятся склонными к условиям гонки, если им требуется более одной инструкции ЦП для обновления: два потока могут в конечном итоге попытаться обновить структуру данных одновременно и найти он неожиданно меняется под ногами. Ошибки, вызванные гоночными условиями, очень сложно воспроизвести и изолировать.
Чтобы предотвратить это, потоки интерфейсов прикладного программирования (API) предлагают примитивы синхронизации, такие как мьютексы для блокировки данных структуры против одновременного доступа. В однопроцессорных системах поток, работающий в заблокированном мьютексе, должен находиться в спящем режиме и, следовательно, запускать переключение контекста. В многопроцессорных системах поток может вместо этого опросить мьютекс в спин-блокировке. Оба эти фактора могут снизить производительность и вынудить процессоры в системах с симметричной многопроцессорной обработкой (SMP) бороться за шину памяти, особенно если степень детализации блокировки в порядке.
Хотя потоки кажутся маленьким шагом от последовательных вычислений, на самом деле они представляют собой огромный шаг. Они отбрасывают самые важные и привлекательные свойства последовательных вычислений: понятность, предсказуемость и детерминизм. Потоки как модель вычислений крайне недетерминированы, и работа программиста сводится к устранению этого недетерминизма.
— Проблема с потоками, Эдвард А. Ли, Калифорнийский университет в Беркли, 2006Реализации пользовательских потоков или волокон обычно полностью находятся в пользовательском пространстве. В результате переключение контекста между пользовательскими потоками или волокнами внутри одного процесса чрезвычайно эффективно, поскольку оно вообще не требует какого-либо взаимодействия с ядром: переключение контекста может быть выполнено путем локального сохранения регистров ЦП, используемых текущим выполняющимся пользовательским потоком. или волокно, а затем загружает регистры, необходимые для выполнения пользовательским потоком или волокном. Поскольку планирование осуществляется в пользовательском пространстве, политику планирования можно легче адаптировать к требованиям рабочей нагрузки программы.
Однако использование блокирующих системных вызовов в пользовательских потоках (в отличие от потоков ядра) или волокнах может быть проблематичным. Если пользовательский поток или волокно выполняет системный вызов, который блокируется, другие пользовательские потоки и волокна в процессе не могут работать, пока системный вызов не вернется. Типичным примером этой проблемы является выполнение ввода-вывода: большинство программ написано для синхронного выполнения ввода-вывода. Когда инициируется операция ввода-вывода, выполняется системный вызов и не возвращается, пока операция ввода-вывода не будет завершена. В промежуточный период весь процесс «блокируется» ядром и не может работать, что лишает возможности выполнения другие пользовательские потоки и волокна в том же процессе.
Распространенным решением этой проблемы является предоставление API ввода-вывода, который реализует синхронный интерфейс с помощью внутреннего неблокирующего ввода-вывода и планирования другого пользовательского потока или волокна во время выполнения операции ввода-вывода.. Аналогичные решения могут быть предусмотрены для других системных вызовов блокировки. В качестве альтернативы, программа может быть написана так, чтобы избежать использования синхронного ввода-вывода или других системных вызовов блокировки.
SunOS 4.x реализовала облегченные процессы или LWP. NetBSD 2.x + и DragonFly BSD реализуют LWP как потоки ядра (модель 1: 1). От SunOS 5.2 до SunOS 5.8, а также от NetBSD 2 до NetBSD 4 реализована двухуровневая модель, мультиплексирующая один или несколько потоков пользовательского уровня в каждом потоке ядра (модель M: N). SunOS 5.9 и новее, а также NetBSD 5 устранили поддержку пользовательских потоков, вернувшись к модели 1: 1. FreeBSD 5 реализовала модель M: N. FreeBSD 6 поддерживает как 1: 1, так и M: N, пользователи могут выбирать, какую из них следует использовать с данной программой, используя /etc/libmap.conf. Начиная с FreeBSD 7, по умолчанию стало 1: 1. FreeBSD 8 больше не поддерживает модель M: N.
Использование потоков ядра упрощает пользовательский код, перемещая некоторые из наиболее сложных аспектов многопоточности в ядро. Программе не нужно планировать потоки или явно передавать процессор. Пользовательский код может быть написан в знакомом процедурном стиле, включая вызовы API-интерфейсов блокировки, без потери других потоков. Однако многопоточность ядра может вызвать переключение контекста между потоками в любое время и, таким образом, обнажить опасность гонки и параллелизма ошибки, которые в противном случае были бы скрытыми. В системах SMP это еще больше усугубляется тем, что потоки ядра могут буквально выполняться на отдельных процессорах параллельно.
Потоки, созданные пользователем в соответствии 1: 1 с планируемыми объектами в ядре, являются простейшими возможными потоками реализация. OS / 2 и Win32 использовали этот подход с самого начала, в то время как в Linux обычная библиотека C реализует этот подход (через NPTL или более ранняя LinuxThreads ). Этот подход также используется в Solaris, NetBSD, FreeBSD, macOS и iOS.
Модель N: 1 подразумевает, что все потоки уровня приложения отображаются на один запланированный объект уровня ядра; ядру ничего не известно о потоках приложения. При таком подходе переключение контекста может быть выполнено очень быстро, и, кроме того, оно может быть реализовано даже на простых ядрах, которые не поддерживают многопоточность. Однако одним из основных недостатков является то, что он не может получить преимущества от аппаратного ускорения на многопоточных процессорах или многопроцессорных компьютерах: никогда не может быть запланировано более одного потока одновременно. время. Например: если одному из потоков необходимо выполнить запрос ввода-вывода, весь процесс блокируется и преимущество потоковой передачи не может быть использовано. GNU Portable Threads использует потоки на уровне пользователя, как и State Threads.
M: N отображает некоторые Mколичество потоков приложения на некоторое Nколичество сущностей ядра или «виртуальных процессоров». Это компромисс между потоками на уровне ядра («1: 1») и на уровне пользователя («N: 1»). В общем, системы потоков "M: N" сложнее реализовать, чем потоки ядра или пользователя, потому что требуются изменения как в ядре, так и в коде пользовательского пространства. В реализации M: N библиотека потоков отвечает за планирование пользовательских потоков на доступных планируемых объектах; это делает переключение контекста потоков очень быстрым, так как позволяет избежать системных вызовов. Однако это увеличивает сложность и вероятность инверсии приоритета, а также субоптимального планирования без обширной (и дорогостоящей) координации между планировщиком пользовательского пространства и планировщиком ядра.
Волокна могут быть реализованы без поддержки операционной системы, хотя некоторые операционные системы или библиотеки предоставляют явную поддержку для них.
IBM PL / I (F) включала поддержку многопоточности (называемой многозадачностью) в конце 1960-х годов, и это было продолжено в оптимизирующем компиляторе и более поздних версиях. Компилятор IBM Enterprise PL / I представил новую модель «потокового» API. Ни одна из версий не входила в стандарт PL / I.
Многие языки программирования в той или иной степени поддерживают многопоточность. Многие реализации C и C ++ поддерживают многопоточность и предоставляют доступ к встроенным API потоковой обработки операционной системы. Некоторые языки программирования более высокого уровня (и обычно кроссплатформенные ), такие как Java, Python и .NET Framework языков, предоставляют разработчикам доступ к многопоточности, абстрагируя специфичные для платформы различия в реализациях потоковой передачи во время выполнения. Несколько других языков программирования и языковых расширений также пытаются полностью абстрагироваться от концепции параллелизма и потоковой передачи от разработчика (Cilk, OpenMP, Message Passing Interface (MPI)). Некоторые языки вместо этого предназначены для последовательного параллелизма (особенно с использованием графических процессоров), не требуя параллелизма или потоков (Ateji PX, CUDA ).
Некоторые интерпретируемые языки программирования имеют реализации (например, Ruby MRI для Ruby, CPython для Python), которые поддерживают многопоточность и параллелизм, но не параллельное выполнение потоков из-за на глобальную блокировку интерпретатора (GIL). GIL - это блокировка взаимного исключения, удерживаемая интерпретатором, которая может помешать интерпретатору одновременно интерпретировать код приложения в двух или более потоках одновременно, что эффективно ограничивает параллелизм в многоядерных системах. Это ограничивает производительность в основном для потоков с привязкой к процессору, которые требуют процессора, и не сильно для потоков с привязкой к вводу-выводу или сетью.
Другие реализации интерпретируемых языков программирования, такие как Tcl с использованием расширения Thread, избегают ограничения GIL за счет использования модели Apartment, в которой данные и код должны явно «совместно использоваться» между потоками. В Tcl у каждого потока есть один или несколько интерпретаторов.
Управляемое событиями программирование Языки описания оборудования, такие как Verilog, имеют другую модель потоков, которая поддерживает чрезвычайно большое количество потоков (для моделирования оборудования).
Стандартизованный интерфейс для реализации потоков - это POSIX Threads (Pthreads), который представляет собой набор вызовов библиотеки C-функций. Поставщики ОС могут свободно реализовать интерфейс по своему желанию, но разработчик приложения должен иметь возможность использовать один и тот же интерфейс на нескольких платформах. Большинство платформ Unix, включая Linux, поддерживают потоки Pthreads. Microsoft Windows имеет собственный набор потоковых функций в интерфейсе process.h для многопоточности, например beginthread. Java предоставляет еще один стандартизированный интерфейс для операционной системы хоста с использованием библиотеки Java concurrency java.util.concurrent.
Многопоточные библиотеки предоставляют вызов функции для создания нового потока, который принимает функцию в качестве параметра. Затем создается параллельный поток, который начинает выполнение переданной функции и заканчивается, когда функция возвращается. Библиотеки потоков также предлагают функции синхронизации, которые позволяют реализовать состояние гонки - многопоточные функции без ошибок, используя мьютексы, условные переменные, критические секции, семафоры, контролируют и другие примитивы синхронизации.
Еще одна парадигма использования потоков - это пулы потоков, где при запуске создается заданное количество потоков, которые затем ждут назначения задачи. Когда приходит новая задача, она просыпается, завершает задачу и возвращается в режим ожидания. Это позволяет избежать относительно дорогостоящих функций создания и уничтожения потоков для каждой выполняемой задачи, а также избавляет разработчика приложений от управления потоками и оставляет его библиотеке или операционной системе, которая лучше подходит для оптимизации управления потоками. Например, такие фреймворки, как Grand Central Dispatch и Threading Building Blocks.
В моделях программирования, таких как CUDA, предназначенных для параллельных вычислений данных, массив потоков выполняет один и тот же код параллельно, используя только его ID для поиска данных в памяти. По сути, приложение должно быть спроектировано так, чтобы каждый поток выполнял одну и ту же операцию с разными сегментами памяти, чтобы они могли работать параллельно и использовать архитектуру GPU.
| Викиверситет содержит обучающие ресурсы о Процессах и потоках в Операционные системы / Процессы и потоки |