Открытый стандарт для распараллеливания
Интерфейс прикладного программирования (API) OpenMP (Open Multi-Processing ) поддерживает многоплатформенное shared-memory многопроцессорное программирование на C, C ++ и Fortran на многие платформы, архитектуры с набором команд и операционные системы, включая Solaris, AIX, HP-UX, Linux, macOS и Windows. Он состоит из набора директив компилятора, библиотечных подпрограмм и переменных среды, которые влияют на поведение во время выполнения.
OpenMP управляется некоммерческий технологический консорциум Совет по обзору архитектуры OpenMP (или OpenMP ARB), совместно созданный широким кругом ведущих поставщиков компьютерного оборудования и программного обеспечения, включая Arm, AMD, IBM, Intel, Cray, HP, Fujitsu, Nvidia, NEC, Red Hat, Texas Instruments и Oracle Corporation.
OpenMP использует портативную масштабируемую модель, которая дает программистам простой и гибкий интерфейс для разработки параллельных приложений для платформ, от стандартного настольного компьютера до суперкомпьютера.
. Приложение, созданное с использованием гибридной модели параллельного программирования, может работать на компьютерном кластере с использованием как OpenMP, так и интерфейса передачи сообщений (MPI), su ch, что OpenMP используется для параллелизма внутри (многоядерного) узла, в то время как MPI используется для параллелизма между узлами. Также были предприняты попытки запустить OpenMP в системах с программной распределенной общей памятью, преобразовать OpenMP в MPI и расширить OpenMP для систем с неразделенной памятью.
Содержание
- 1 Дизайн
- 2 История
- 3 основных элемента
- 3.1 Создание потока
- 3.2 Конструкции распределения работы
- 3.3 Вариантные директивы
- 3.4 Пункты
- 3.5 Подпрограммы времени выполнения на уровне пользователя
- 3.6 Переменные среды
- 4 Реализации
- 5 Плюсы и минусы
- 6 Ожидаемая производительность
- 7 Соответствие потоков
- 8 Тесты
- 9 См. Также
- 10 Ссылки
- 11 Дополнительная литература
- 12 Внешние ссылки
Дизайн
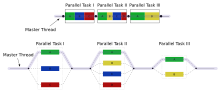
Иллюстрация
многопоточности, где первичный поток разделяет несколько потоков, которые выполняют блоки кода параллельно.
OpenMP - это реализация многопоточности, метод распараллеливания, при котором основной поток (последовательность инструкций, выполняемых последовательно) разветвляет заданное количество подпотоков, и система разделяет задачу между ними. Затем потоки выполняются одновременно, а среда выполнения распределяет потоки между разными процессорами.
Раздел кода, предназначенный для параллельного выполнения, помечен соответствующим образом директивой компилятора, которая заставит потоки формироваться до того, как этот раздел будет выполнен. К каждому потоку прикреплен идентификатор, который можно получить с помощью функции (называемой omp_get_thread_num ()). Идентификатор потока является целым числом, а идентификатор основного потока равен 0. После выполнения распараллеленного кода потоки снова присоединяются к основному потоку, который продолжается до конца программы.
По умолчанию каждый поток выполняет параллельную часть кода независимо. Конструкции разделения работы могут использоваться для разделения задачи между потоками, чтобы каждый поток выполнял выделенную ему часть кода. Таким образом, с помощью OpenMP можно достичь как параллелизма задач, так и параллелизма данных.
Среда выполнения распределяет потоки между процессорами в зависимости от использования, загрузки компьютера и других факторов. Среда выполнения может назначать количество потоков на основе переменных среды, или код может делать это с помощью функций. Функции OpenMP включены в заголовочный файл с пометкой omp.hв C /C ++.
History
Комиссия по обзору архитектуры OpenMP (ARB) опубликовала свой Первые спецификации API, OpenMP для Fortran 1.0, в октябре 1997 года. В октябре следующего года они выпустили стандарт C / C ++. В 2000 году была выпущена версия 2.0 спецификаций Fortran, а в 2002 была выпущена версия 2.0 спецификаций C / C ++. Версия 2.5 - это комбинированная спецификация C / C ++ / Fortran, выпущенная в 2005 году.
До версии 2.0, OpenMP в первую очередь определил способы распараллеливания очень регулярных циклов, как это происходит в матрично-ориентированном численном программировании, где количество итераций цикла известно во время входа. Это было признано ограничением, и к реализациям были добавлены различные расширения параллельных задач. В 2005 году была сформирована попытка стандартизировать параллелизм задач, которая в 2007 году опубликовала предложение, вдохновленное функциями параллелизма задач в Cilk, X10 и Chapel.
Version Версия 3.0 была выпущена в мае 2008 года. В новые функции версии 3.0 включены концепция задач и конструкция задачи, значительно расширяющая сферу применения OpenMP за пределы конструкций параллельного цикла, составляющих большую часть OpenMP 2.0.
Версия 4.0 спецификации была выпущена в июле 2013 года. Она добавляет или улучшает следующие функции: поддержка ускорителей ; атомикс ; обработка ошибок; сходство потока ; расширения задач; определяемое пользователем сокращение ; поддержка SIMD ; Поддержка Fortran 2003.
Текущая версия - 5.0, выпущенная в ноябре 2018 года.
Обратите внимание, что не все компиляторы (и ОС) поддерживают полный набор функций для последняя версия / ы.
Основные элементы

Схема конструкций OpenMP
Основные элементы OpenMP - это конструкции для создания потоков, распределения рабочей нагрузки (распределения работы), управления средой данных, синхронизации потоков, подпрограмм времени выполнения на уровне пользователя и переменные среды.
В C / C ++ OpenMP использует #pragmas. Специфические прагмы OpenMP перечислены ниже.
Создание потока
Прагма omp parallel используется для разветвления дополнительных потоков для параллельного выполнения работы, заключенной в конструкции. Исходный поток будет обозначен как главный поток с идентификатором 0.
Пример (программа C): Отображение «Hello, world». с использованием нескольких потоков.
#include #include int main (void) {#pragma omp parallel printf ("Привет, мир. \ N"); возврат 0; }
Используйте флаг -fopenmp для компиляции с использованием GCC:
$ gcc -fopenmp hello.c -o hello
Вывод на компьютер с двумя ядрами и, следовательно, двумя потоками:
Привет, мир. Привет мир.
Однако вывод также может быть искажен из-за состояния состязания, вызванного двумя потоками, совместно использующими стандартный вывод .
Привет, привет, мир. rld.
(Является ли printfпотокобезопасным, зависит от реализации. C ++ std :: cout, с другой стороны, всегда потокобезопасен.)
Конструкции распределения работы
Используются, чтобы указать, как назначить независимую работу одному или всем потокам.
- omp for или omp do: используется для разделения итераций цикла между потоками, также называемых конструкциями цикла.
- разделы: назначение последовательных, но независимых блоков кода разным потокам
- single: при указании блока кода, который выполняется только одним потоком, в конце подразумевается барьер
- master: аналогично single, но блок кода будет выполняться только главным потоком, а не барьер подразумевается в конце.
Пример: инициализировать значение большого массива параллельно, используя каждый поток для выполнения части работы
int main (int argc, char ** argv) {int a [100000] ; #pragma omp parallel for for (int i = 0; i < 100000; i++) { a[i] = 2 * i; } return 0; }Этот пример является досадно параллельным и зависит только от значения i. Флаг OpenMP parallel for сообщает системе OpenMP разделите эту задачу между своими рабочими потоками. Каждый поток получит уникальную и частную версию переменной. Например, с двумя рабочими потоками одному потоку может быть передана версия i, которая работает от 0 до 49999, а второй получает версию от 50000 до 99999.
Директивы Variant
Директивы Variant - одна из основных функций, представленных в спецификации OpenMP 5.0 для облегчения программистам повышения производительности и переносимости. Они позволяют адаптировать OpenMP прагмы и пользовательский код во время компиляции. Спецификация определяет черты для описания активных конструкций OpenMP, исполнительные устройства и функциональные возможности, предоставляемые реализацией, контекстные селекторы, основанные на чертах и определяемых пользователем условиях, а также метадирективу и директиву объявления. s для пользователей, чтобы запрограммировать одну и ту же область кода с помощью вариантных директив.
- Метадиректива - это исполняемая директива, которая условно преобразуется в другую директиву во время компиляции путем выбора из нескольких вариантов директив на основе признаков, которые определяют условие или контекст OpenMP.
- Директива объявления варианта имеет те же функции, что и метадиректива но выбирает вариант функции на сайте вызова на основе контекста или определенных пользователем условий.
Механизм, предоставляемый двумя вариантами директив для выбора вариантов, более удобен в использовании, чем предварительная обработка C / C ++, поскольку он напрямую поддерживает выбор варианта в OpenMP и позволяет компилятору OpenMP анализировать и определять окончательную директиву из вариантов и контекста.
// адаптация кода с помощью директив предварительной обработки int v1 [N], v2 [N], v3 [N]; #if defined (nvptx) #pragma omp целевые группы распространяют карту параллельного цикла (to: v1, v2) map (from: v3) for (int i = 0; i < N; i++) v3[i] = v1[i] * v2[i]; #else #pragma omp target parallel loop map(to:v1,v2) map(from:v3) for (int i= 0; i< N; i++) v3[i] = v1[i] * v2[i]; #endif // code adaptation using metadirective in OpenMP 5.0 int v1[N], v2[N], v3[N]; #pragma omp target map(to:v1,v2) map(from:v3) #pragma omp metadirective \ when(device={arch(nvptx)}: target teams distribute parallel loop)\ default(target parallel loop) for (int i= 0; i< N; i++) v3[i] = v1[i] * v2[i];Пункты
Поскольку OpenMP - это модель программирования с общей памятью, большинство переменных в коде OpenMP по умолчанию видимы для всех потоков. Но иногда частные переменные необходимы, чтобы избежать состояния гонки, и возникает необходимость передавать значения между последовательной частью и параллельной областью (блок кода выполняется параллельно), поэтому управление средой данных вводится в виде предложений атрибутов совместного использования данных путем добавления их к директиве OpenMP. Различные типы предложений:
- предложения атрибутов совместного использования данных
- общие: данные, объявленные за пределами параллельной области является общим, что означает видимый и доступный для всех потоков одновременно. По умолчанию все переменные в рабочей области являются общими, кроме счетчика итераций цикла.
- закрытые: данные, объявленные в параллельной области является частным для каждого потока, что означает, что каждый поток будет У меня есть локальная копия, и я использую ее как временную переменную. Частная переменная не инициализируется, и значение не поддерживается для использования за пределами параллельной области. По умолчанию счетчики итераций цикла в конструкциях цикла OpenMP являются частными.
- default: позволяет программисту указать, что область видимости данных по умолчанию в параллельной области будет либо общей, либо отсутствовать для C / C ++, либо shared, firstprivate, private или none для Fortran. Параметр none заставляет программиста объявлять каждую переменную в параллельной области, используя предложения атрибутов совместного использования данных.
- firstprivate: как private, но не инициализировано исходным значением.
- lastprivate: как private, за исключением исходного значения обновляется после построения.
- сокращение: безопасный способ объединения работы всех потоков после построения.
- предложения синхронизации
- критично: вложенный блок кода будет выполняться только одним потоком за раз, и не выполняется одновременно несколькими потоками. Он часто используется для защиты общих данных от состояния гонки.
- атомарно: обновление памяти (запись или чтение-изменение-запись) в следующей инструкции будет выполняться атомарно. Это не делает атомарным весь оператор; только обновление памяти атомарно. Компилятор может использовать специальные аппаратные инструкции для лучшей производительности, чем при использовании критического.
- упорядоченный: структурированный блок выполняется в том порядке, в котором итерации будут выполняться в последовательном цикле
- барьер: каждый поток ждет, пока все другие потоки команды не достигнут этой точки. Конструкция разделения работы имеет в конце неявную барьерную синхронизацию.
- nowait: указывает, что потоки, завершающие назначенную работу, могут продолжаться, не дожидаясь завершения всех потоков в группе. В отсутствие этого предложения потоки сталкиваются с барьерной синхронизацией в конце конструкции разделения работы.
- Пункты планирования
- расписание (тип, фрагмент): это полезно, если конструкция разделения работы представляет собой цикл выполнения или для цикла. Итерация (и) в конструкции распределения работы назначается потокам в соответствии с методом планирования, определенным в этом пункте. Существуют три типа планирования:
- статический: здесь всем потокам выделяются итерации, прежде чем они выполнят итерации цикла. По умолчанию итерации делятся между потоками поровну. Однако указание целого числа для блока параметров будет выделять количество последовательных итераций в блоке для конкретного потока.
- динамический: здесь некоторые итерации выделяются меньшему количеству потоков. Как только конкретный поток завершает выделенную ему итерацию, он возвращается, чтобы получить еще один из оставшихся итераций. Блок параметров определяет количество непрерывных итераций, которые выделяются потоку за раз.
- guided: большой кусок непрерывных итераций выделяется каждому потоку динамически (как указано выше). Размер блока экспоненциально уменьшается с каждым последующим выделением до минимального размера, указанного в параметре chunk
- IF control
- , если: Это заставит потоки распараллеливать задачу только при выполнении условия. В противном случае блок кода выполняется последовательно.
- Инициализация
- firstprivate: данные являются частными для каждого потока, но инициализируются с использованием значения переменной с тем же именем из главного потока.
- lastprivate: данные являются личными для каждого потока. Значение этих частных данных будет скопировано в глобальную переменную с тем же именем за пределами параллельной области, если текущая итерация является последней итерацией в параллельном цикле. Переменная может быть как firstprivate, так и lastprivate.
- threadprivate: данные являются глобальными, но во время выполнения они являются частными в каждой параллельной области. Разница между threadprivate и private заключается в глобальной области видимости, связанной с threadprivate и сохраняемым значением в параллельных регионах.
- Копирование данных
- copyin: аналогично firstprivate для частных переменных, переменные threadprivate не инициализируются, если только не используется copyin для передачи значение из соответствующих глобальных переменных. Копирование не требуется, поскольку значение переменной threadprivate сохраняется на протяжении всего выполнения программы.
- copyprivate: используется с single для поддержки копирования значений данных из частных объектов в одном потоке (один поток) к соответствующим объектам в других потоках в команде.
- Сокращение
- сокращение (operator | intrinsic: list): переменная имеет локальную копию в каждом потоке, но значения локальных копий будут суммированы (уменьшены) в глобальную общую переменную. Это очень полезно, если конкретная операция (указанная в операторе для этого конкретного предложения) с переменной выполняется итеративно, так что ее значение на определенной итерации зависит от ее значения на предыдущей итерации. Шаги, ведущие к операционному приращению, распараллеливаются, но потоки обновляют глобальную переменную потокобезопасным способом. Это может потребоваться при распараллеливании численного интегрирования функций и дифференциальных уравнений в качестве распространенного примера.
- Прочие
- flush: значение этой переменной восстанавливается из регистра в память для использования этого значения вне параллельной части
- master: выполняется только главным потоком (потоком, который разветвлял все остальные во время выполнения директивы OpenMP). Нет неявного барьера; другие члены группы (потоки) не требуются для доступа.
Подпрограммы времени выполнения на уровне пользователя
Используются для изменения / проверки количества потоков, определения того, находится ли контекст выполнения в параллельной области, сколько процессоров в текущая система, установка / снятие блокировок, временные функции и т. д.
Переменные среды
Метод для изменения функций выполнения приложений OpenMP. Используется для управления планированием итераций цикла, количеством потоков по умолчанию и т. Д. Например, OMP_NUM_THREADS используется для указания количества потоков для приложения.
Реализации
OpenMP реализован во многих коммерческих компиляторах. Например, Visual C ++ 2005, 2008, 2010, 2012 и 2013 поддерживают его (OpenMP 2.0, в редакциях Professional, Team System, Premium и Ultimate), а также Intel Parallel Studio для различных процессоров. Компиляторы и инструменты Oracle Solaris Studio поддерживают последние спецификации OpenMP с повышением производительности для ОС Solaris (UltraSPARC и x86 / x64) и платформ Linux. Компиляторы Fortran, C и C ++ из The Portland Group также поддерживают OpenMP 2.5. GCC также поддерживает OpenMP, начиная с версии 4.2.
Компиляторы с реализацией OpenMP 3.0:
- GCC 4.3.1
- Компилятор Mercurium
- Intel Fortran и компиляторы C / C ++ версий 11.0 и 11.1, Intel C / C ++ и Fortran Composer XE 2011 и Intel Parallel Studio.
- Компилятор IBM XL
- Sun Studio 12 update 1 содержит полную реализацию OpenMP 3.0
Некоторые компиляторы поддерживают OpenMP 3.1:
- GCC 4.7
- Компиляторы Intel Fortran и C / C ++ 12.1
- Компиляторы IBM XL C / C ++ для AIX и Linux, V13.1 и компиляторы IBM XL Fortran для AIX и Linux, V14.1
- LLVM / Clang 3.7
- Компиляторы Absoft Fortran v. 19 для Windows, Mac OS X и Linux
Компиляторы, поддерживающие OpenMP 4.0:
- GCC 4.9.0 для C / C ++, GCC 4.9.1 для Fortran
- компиляторы Intel Fortran и C / C ++ 15.0
- IBM XL C / C ++ для Linux, V13.1 (частично) и XL Fortran для Linux, V15.1 (частично)
- LLVM / Clang 3.7 (частично)
Поддержка нескольких компиляторов OpenMP 4.5:
- GCC 6 для C / C ++
- компиляторов Intel Fortran и C / C ++ 17.0, 18.0, 19.0
- LLVM / Clang 12
Частичная поддержка OpenMP 5.0:
- GCC 9 для компиляторов C / C ++
- Intel Fortran и C / C ++ 19.1
- LLVM / Clang 12
Компиляторы с автоматическим распараллеливанием, которые генерируют исходный код, аннотированный директивами OpenMP :
- iPat / OMP
- PLUTO
- ROSE (структура компилятора)
- S2P от KPIT Cummins Infosystems Ltd.
Некоторые профилировщики и отладчики явно поддерживают OpenMP:
- Инструмент распределенной отладки Allinea (DDT) - отладчик для кодов OpenMP и MPI
- Allinea MAP - профилировщик для кодов OpenMP и MPI
- TotalView - отладчик от Программное обеспечение Rogue Wave для OpenMP, MPI и последовательных кодов
- ompP - профилировщик для OpenMP
- VAMPIR - профилировщик для OpenMP и кода MPI
Плюсы и минусы
Плюсы:
- Переносимый многопоточный код (в C / C ++ и других языках обычно приходится вызывать специфичные для платформы примитивы, чтобы получить многопоточность).
- Просто: нет необходимости обрабатывать передачу сообщений как MPI поддерживает.
- Компоновка и декомпозиция данных обрабатываются автоматически с помощью директив.
- Масштабируемость сравнима с MPI в системах с общей памятью.
- Инкрементальный параллелизм: может работать над одной частью программы за один раз, никаких существенных изменений кода не требуется.
- Унифицированный код как для последовательных, так и для параллельных приложений: конструкции OpenMP обрабатываются как комментарии, когда выполняются последовательные компиляторы.
- Операторы исходного (последовательного) кода, как правило, не нужно изменять при распараллеливании с OpenMP. Это снижает вероятность непреднамеренного появления ошибок.
- Возможны как крупнозернистый, так и мелкозернистый параллелизм.
- В нерегулярной мультифизике приложения, которые не придерживаются только режима вычислений SPMD, что встречается в сильно связанных системах жидкость-частицы, гибкость OpenMP может иметь большое преимущество в производительности по сравнению с MPI.
- Может использоваться на различных ускорителях, таких как GPGPU и FPGA.
Минусы:
- Риск появления трудных для отладки ошибок синхронизации и состояния гонки.
- По состоянию на 2017 год эффективно работает только в многопроцессорные платформы с памятью (см., однако, Intel Cluster OpenMP и другие платформы с распределенной разделяемой памятью ).
- Требуется компилятор, поддерживающий OpenMP.
- Масштабируемость ограничено архитектурой памяти.
- Нет поддержки для сравнения и замены.
- Отсутствует надежная обработка ошибок.
- Недостаток детализированных механизмов для управления потоками Отображение d-процессора.
- Высокая вероятность случайной записи ложного кода совместного использования.
Ожидаемая производительность
Можно было бы ожидать увеличения скорости в N раз при запуске программы, распараллеленной с использованием OpenMP на платформе N процессора. Однако это редко происходит по следующим причинам:
- Когда существует зависимость, процесс должен ждать, пока не будут вычислены данные, от которых он зависит.
- Когда несколько процессов совместно используют непараллельный ресурс проверки (например, файл для записи), их запросы выполняются последовательно. Следовательно, каждый поток должен ждать, пока другой поток не освободит ресурс.
- Большая часть программы не может быть распараллелена с помощью OpenMP, что означает, что теоретический верхний предел ускорения ограничен в соответствии с утверждением Амдала. law.
- N процессоров в симметричной многопроцессорной обработке (SMP) могут иметь вычислительную мощность в N раз больше, но пропускная способность памяти обычно не увеличивается в N раз. Довольно часто исходный путь к памяти используется совместно несколькими процессорами, и может наблюдаться снижение производительности, когда они конкурируют за пропускную способность совместно используемой памяти.
- Многие другие распространенные проблемы, влияющие на окончательное ускорение параллельных вычислений, также относятся к OpenMP, например балансировка нагрузки и накладные расходы на синхронизацию.
- Оптимизация компилятора может быть не столь эффективной при вызове OpenMP. Обычно это может привести к тому, что однопоточная программа OpenMP будет работать медленнее, чем тот же код, скомпилированный без флага OpenMP (который будет полностью последовательным).
Соответствие потоков
Некоторые поставщики рекомендуют устанавливать процессор affinity в потоках OpenMP, чтобы связать их с определенными ядрами процессора. Это минимизирует затраты на миграцию потоков и переключение контекста между ядрами. Это также улучшает локальность данных и снижает трафик согласованности кэша между ядрами (или процессорами).
Тесты
Было разработано множество тестов для демонстрации использования OpenMP, тестирования его производительности и оценки правильности.
Простые примеры
Тесты производительности включают:
Тесты на корректность включают:
- OpenMP Validation Suite
- OpenMP Validation и Verification Testsuite
- DataRaceBench - это набор тестов, предназначенный для систематической и количественной оценки эффективности инструментов обнаружения гонки данных OpenMP.
- AutoParBench - тестовый набор для оценки компиляторов и инструментов, которые могут автоматически вставлять OpenMP директивы.
См. также
Ссылки
Дополнительная литература
Внешние ссылки
- Официальный сайт, включает последние спецификации OpenMP, ссылки на ресурсы, оживленный набор форумов, где можно задать вопросы и получить ответы от экспертов и разработчиков OpenMP
- OpenMPCon, веб-сайт конференции разработчиков OpenMP
- IWOMP, веб-сайт для ежегодного Международного семинара по OpenMP
- Пользователи OpenMP в Великобритании, веб-сайт группы пользователей OpenMP в Великобритании и конференции
- IBM Octopiler с поддержкой OpenMP
- Блай se Барни, сайт Ливерморской национальной лаборатории Лоуренса, посвященный OpenMP
- Объединение OpenMP и MPI (PDF)
- Смешивание MPI и OpenMP
- Измерение и визуализация параллелизма OpenMP с помощью C ++ планировщик маршрутизации, вычисляющий Speedup фактор

 Иллюстрация многопоточности, где первичный поток разделяет несколько потоков, которые выполняют блоки кода параллельно.
Иллюстрация многопоточности, где первичный поток разделяет несколько потоков, которые выполняют блоки кода параллельно.  Схема конструкций OpenMP
Схема конструкций OpenMP