Распределение вероятностей
КошиФункция плотности вероятности  . Фиолетовая кривая - стандартное распределение Коши . Фиолетовая кривая - стандартное распределение Коши |
Накопительная функция распределения  |
| Параметры |  местоположение (действительное ). местоположение (действительное ).  масштаб (реальный) масштаб (реальный) |
|---|
| Поддержка |  |
|---|
| PDF | ![\ frac {1} {\ pi \ gamma \, \ left [1 + \ влево (\ гидроразрыва {x- x_0} {\ gamma} \ right) ^ 2 \ right]} \!](https://wikimedia.org/api/rest_v1/media/math/render/svg/2fa7448ba911130c1e33621f1859393d3f00af5c) |
|---|
| CDF |  |
|---|
| Квантиль | ![x_0 + \ gamma \, \ tan [\ pi (F- \ tfrac {1} {2})]](https://wikimedia.org/api/rest_v1/media/math/render/svg/64de18db70e8ca851bdd237472076e12f7d99857) |
|---|
| Среднее | неопределенное |
|---|
| Медианное | |
|---|
| Режим | |
|---|
| Дисперсия | undefined |
|---|
| Асимметрия | undefined |
|---|
| Пример. эксцесс | undefined |
|---|
| Энтропия |  |
|---|
| MGF | не существует |
|---|
| CF |  |
|---|
| информация Фишера |  |
|---|
Распределение Коши, названное в честь Огюстена Коши, является непрерывным распределением вероятностей. Это также известно, особенно физиков, как распределение Лоренца (после Хендрика Лоренца ), распределение Коши - Лоренца, Функция Лоренца (ian), или распределение Брейта - Вигнера . Распределение Коши  - это распределение x-точки пересечения луча, выходящего из
- это распределение x-точки пересечения луча, выходящего из  с равномерно распределенным углом. Это также распределение отношений двух независимых нормально распределенных случайных величин с нулевым средним.
с равномерно распределенным углом. Это также распределение отношений двух независимых нормально распределенных случайных величин с нулевым средним.
Распределение Коши часто используется в качестве канонического примера «патологического » распределения, поскольку его ожидаемое значение и его дисперсия не является (но см. § Объяснение неопределенных моментов ниже). Распределение Коши не имеет конечных моментов порядка больше или равного единице; существуют только дробные абсолютные моменты. Распределение Коши не имеет функции , производящей момент.
В математике оно используется вместе с ядром Пуассона, которое является фундаментальным решением для уравнение Лапласа в верхней полуплоскости .
Это одно из немногих распределений, которое стабильно имеет функцию плотности вероятности, которая может быть выражена аналитически, другими являются нормальное распределение и распределение Леви.
Содержание
- 1
- 2 Характеристика
- 2.1 Функция плотности вероятности
- 2.2 Кумулятивная функция История распределения
- 2.3 Энтропия
- 3 Дивергенция Кульбака-Лейблера
- 4 Свойства
- 4.1 Характеристическая функция
- 5 Объяснение неопределенных моментов
- 5.1 Среднее
- 5.2 Меньшие моменты
- 5.3 Высшие моменты
- 5.4 Моменты усеченных распределений
- 6 Оценка параметров
- 7 Общее распределение Коши
- 8 Свойства преобразования
- 9 Мера Леви
- 10 Связанные распределения
- 11 R элятивистское распределение Брейта - Вигнера
- 12 Возникновение и применение
- 13 См. также
- 14 Ссылки
- 15 Внешние ссылки
История

Оценка среднего и стандартного отклонения по выборкам из распределения Коши (внизу) не сходится с большим количеством выборок, как в
нормальном распределении ( вверху). Скачки могут быть сколь угодно большими, как видно на графиках внизу. (Щелкните, чтобы развернуть)
Функции сучались функции распределения Коши из математики в 17 веке, но в контексте и под названием ведьмы Агнеси. Несмотря на название, первый явный анализ свойств распределения Коши был опубликован французским математиком Пуассоном в 1824 году, и Коши стал ассоциироваться с ним только во время академических споров в 1853 году. Таким образом, название распределения является случаем закона эпонимии Стиглера. Пуассон заметил, что если брать среднее значение наблюдений, следующая за таким распределением, то средняя ошибка сходится к какому-либо конечному наблюдению. Таким образом, использование Лапласом центральной предельной теоремы с таким распределением было неуместным, поскольку предполагало конечное среднее значение и дисперсию. Несмотря на это, Пуассон не должен считать этот вопрос важным, в отличие от Бьенайме, который был вовлечь Коши в долгий спор по этому поводу.
Характеристика
Функция плотности вероятности
Распределение Коши имеет плотность плотности вероятности (PDF)
![f (x; x_ {0}, \ gamma) = {\ frac {1} {\ pi \ gamma \ left [1+ \ left ({\ frac {x-x_ {0}} {\ gamma}) } \ right) ^ {2} \ right]}} = {1 \ over \ pi \ gamma} \ left [{\ gamma ^ {2} \ over (x-x_ {0}) ^ {2} + \ gamma ^ {2}} \ right],](https://wikimedia.org/api/rest_v1/media/math/render/svg/cebade496753f1664a6afd9c260c993023c03b3b)
где  - параметр местоположения, определяющий местоположение пика распределения, а
- параметр местоположения, определяющий местоположение пика распределения, а  - это параметр масштаба , определяет полуширину на полувысоте (HWHM), альтернативно
- это параметр масштаба , определяет полуширину на полувысоте (HWHM), альтернативно  составляет полную ширину на половине значений (FWHM). также равен половине межквартирного размаха и иногда называется вероятной ошибкой. Огюстен-Луи Коши использовал такую функцию плотности в 1827 году с бесконечно малым параметр масштаба, определяя то, что теперь будет называться дельта-функции Дирака.
составляет полную ширину на половине значений (FWHM). также равен половине межквартирного размаха и иногда называется вероятной ошибкой. Огюстен-Луи Коши использовал такую функцию плотности в 1827 году с бесконечно малым параметр масштаба, определяя то, что теперь будет называться дельта-функции Дирака.
Максимальное значение или амплитуда PDF-файла Коши:  , расположенный в
, расположенный в  .
.
Иногда бывает удобно выразить PDF через комплексный параметр 

Особый случай, когда  и
и  называется стандартным распределением Коши с функцией плотности вероятности
называется стандартным распределением Коши с функцией плотности вероятности

В физике трехпараметрическая функция Лоренца часто используется:
![f (x; x_0, \ gamma, I) = \ frac {I} {\ left [1 + \ влево (\ f rac {x-x_0} {\ gamma} \ right) ^ 2 \ right]} = I \ left [{\ gamma ^ 2 \ над (x - x_0) ^ 2 + \ gamma ^ 2} \ right],](https://wikimedia.org/api/rest_v1/media/math/render/svg/ef75c5f31667a907f64963eb478d03f33f8374d2)
где  - высота пика. Указанная трехпараметрическая функция не является функцией плотности вероятности, поскольку она не интегрируется до 1, за исключением особого случая, когда
- высота пика. Указанная трехпараметрическая функция не является функцией плотности вероятности, поскольку она не интегрируется до 1, за исключением особого случая, когда 
Кумулятивная функция распределения
кумулятивная функция распределения распределения Коши:

и функция квантиля (обратный cdf ) распределения Коши равен
![Q (p; x_0, \ gamma) = x_0 + \ gamma \, \ tan \ left [\ pi \ left (p- \ tfrac {1} {2} \ right) \ right].](https://wikimedia.org/api/rest_v1/media/math/render/svg/42c17241be79f1edbb111b82fc9a86ad55c9fd37)
Отсюда следует, что первый и третий квартили равны  , и, следовательно, межквартильный размах равенство .
, и, следовательно, межквартильный размах равенство .
Для стандартного распределения кумулятивная функция распределения упрощается до функция арктангенса  :
:

Энтропия
Энтропия распределения Коши определяется выражением:
![{\ displaystyle {\ begin {align} H (\ gamma) = - \ int _ {- \ infty} ^ {\ infty} f (x; x_ {0}, \ gamma) \ log (f (x; x_ {0}, \ gamma)) \, dx \\ [6pt] = \ журнал (4 \ пи \ гамма) \ конец {выровнено}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d648f0a9098d95824886093f233fb0681578a4eb)
Производственная квантильная функция , квантильная функция плотности для распределения Коши:
![{\displaystyle Q'(p;\gamma)=\gamma \,\pi \,{\sec }^{2}\left[\pi \left(p-{\tfrac {1}{2}}\right)\right].\!}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c98f59acfc3b417126a88a731035e87a4deaa16b)
дифференциальная энтропия распределение может быть определено в терминах его квантильной плотности, а именно:

Распределение Коши - это максимальная вероятности энтропии для случайной переменной  для которого
для которого
![{\ displaystyle \ operatorname {E} [\ log (1+ (X- x_ {0}) ^ {2} / \ gamma ^ {2})] = \ log 4}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a7f6982d1d9f8690a4cd034887fe55c659e005b0)
или альтернативный вариант для случайной переменной для что
![{\ displaystyle \ operatorname {E} [\ log (1+ (X-x_ {0}) ^ {2})] = 2 \ log (1+ \ gamma).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1202d0f364823a72e303a5b48e2d6fdab06f361e)
В стандартной форме это Максимальная вероятность энтропии для случайной переменной , для которой
![{\ displaystyle \ operatorname {E} \! \ Left [\ ln (1 + X ^ {2}) \ right] = \ ln 4.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d21003746c5e5935ead79eea3221bade73eac657)
.
расхождение Кульбака-Лейблера
Дивергенция Кульбака-Лейблера между двумя распределениями Коши имеет следующую симметричную формулу замкнутой формы:

Свойства
Распределение Коши представляет собой распределение, для которого среднее, дисперсия или более высокие моменты. Его режим и медиана хорошо и оба Равны .
Когда  и
и  - две независимые нормально распределенные случайные величины с ожидаемого числа 0 и дисперсия 1, то отношение
- две независимые нормально распределенные случайные величины с ожидаемого числа 0 и дисперсия 1, то отношение  имеет стандартное распределение Коши.
имеет стандартное распределение Коши.
Если  является
является  положительно-полуопределенная матрица ковариаций со строго положительными диагональными элементами, то для независимо и одинаково распределенных
положительно-полуопределенная матрица ковариаций со строго положительными диагональными элементами, то для независимо и одинаково распределенных  и любой случайный
и любой случайный  -вектор
-вектор  независимо от и
независимо от и  такие, что
такие, что  и
и  (определяя категориальное распределение ), выполняется
(определяя категориальное распределение ), выполняется

Если  являются независимыми и одинаково распределенными случайными величинами, каждой со стандартным распределением Коши, то выборочное среднее
являются независимыми и одинаково распределенными случайными величинами, каждой со стандартным распределением Коши, то выборочное среднее  имеет такое же стандартное распределение Коши. Чтобы убедиться, что это так, вычислите качественную функцию выборочного среднего:
имеет такое же стандартное распределение Коши. Чтобы убедиться, что это так, вычислите качественную функцию выборочного среднего:
![{\ displaystyle \ varphi _ {\ overline {X}} (t) = \ mathrm {E } \ left [e ^ {i {\ overline {X}} t} \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cbd1345191c42b12d19411b3f0f96f19cab8cf4e)
где  - выборочное среднее. Этот пример показывает, что гипотеза конечной дисперсии в центральной предельной теореме не может быть отброшена. Это также пример обобщенной версии центральной предельной теоремы, которая характерна для всех стабильных распределений, частным случаем которых является распределение Коши.
- выборочное среднее. Этот пример показывает, что гипотеза конечной дисперсии в центральной предельной теореме не может быть отброшена. Это также пример обобщенной версии центральной предельной теоремы, которая характерна для всех стабильных распределений, частным случаем которых является распределение Коши.
Распределение Коши - это бесконечно делимое распределение вероятностей. Это также строго стабильное распределение.
Стандартное распределение Коши совпадает с t-распределением Стьюдента с одной степенью свободы.
Как и все стабильные распределения, семейство масштаба местоположения, к которому принадлежат Коши, замкнуто при линейных преобразованиях с действительными коэффициентами. Кроме того, распределение Коши закрывается при дробно-линейных преобразованиях с действующими коэффициентами. В этой связи см. параметры распределений Коши Маккаллахом.
Характеристическая функция
Пусть обозначает распределенную случайную категорию Коши. характерная функция распределение Коши определяется как
![{\ displaystyle \ varphi _ {X} (t; x_ {0}, \ gamma) = \ operatorname {E} \ left [e ^ {iXt} \ right] = \ int _ {- \ infty} ^ {\ infty} f (x; x_ {0}, \ gamma) e ^ {ixt} \, dx = e ^ {ix_ {0} t- \ gamma | т | }.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c3d9f15cc821e9dc77f9975bbef43ea61c23baee)
что является просто Фурье преобразовать плотность вероятности. Первоначальная плотность вероятности может быть выражена через характеристическую функцию, по существу, с помощью обратного преобразования Фурье:

n-й момент распределения - это n-я производная характеристическая функция, вычисленная при  . Обратите внимание, что характерная функция не дифференцируема в начале координат: это соответствует тому факту, что распределение Коши не имеет четко определенных моментов выше, чем нулевой момент.
. Обратите внимание, что характерная функция не дифференцируема в начале координат: это соответствует тому факту, что распределение Коши не имеет четко определенных моментов выше, чем нулевой момент.
Объяснение неопределенных моментов
Среднее
Если распределение вероятностей имеет функция плотности  , тогда среднее значение, если оно существует, дается как
, тогда среднее значение, если оно существует, дается как

Мы можем оценить этот двусторонний несобственный интеграл путем вычисления суммы двух односторонних несобственных интегралов. То есть

для произвольного действительного числа  .
.
Для существования интеграла (даже в виде бесконечного значения), хотя бы один из членов этой суммы должен быть конечным, или оба должны быть бесконечными и иметь один и тот же знак. В случае распределения Коши оба члена в этой сумме (2) бесконечны и имеют противоположный знак. Следовательно, (1) не определено, как и среднее значение.
Обратите внимание, что главное значение Коши среднего значения распределения Коши равно

который равен нулю. С другой стороны, соответствующий интеграл

не равно нулю, что легко увидеть, вычислив интеграл. Это снова показывает, что среднее (1) не может существовать.
Различные результаты теории вероятностей относительно ожидаемых значений, такие как строгий закон больших чисел, не выполняются для распределения Коши.
Меньшие моменты
Определены абсолютные моменты для  . Для
. Для  мы имеем
мы имеем
![{\ displaystyle \ operatorname {E} [| X | ^ {p}] = \ gamma ^ {p} \ mathrm {sec} (\ pi p / 2).}](https://wikimedia.org/api/rest_v1/media/math/render/svg/34e2a867bc2b1f3c8c5fe805aa71577f466e948c)
Высшие моменты
Распределение Коши не имеет конечных моментов любого порядка. Некоторые из более высоких исходных моментов действительно существуют и имеют значение бесконечности, например, необработанный второй момент:
![{ \ displaystyle {\ begin {align} \ operatorname {E} [X ^ {2}] \ propto \ int _ {- \ infty} ^ {\ infty} {\ frac {x ^ {2}} {1 + x ^ {2}}} \, dx = \ int _ {- \ infty} ^ {\ infty} 1 - {\ frac {1} {1 + x ^ {2}}} \, dx \\ [8pt] = \ int _ {- \ infty} ^ {\ infty} dx- \ int _ {- \ infty} ^ {\ infty} {\ frac {1} {1 + x ^ {2}}} \, dx = \ int _ {- \ infty} ^ {\ infty} dx- \ pi = \ infty. \ End {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b821427592463519bb2fe3f38a52f61183af76cd)
Изменив формулу, можно увидеть, что второй момент по сути является бесконечным интегралом константы (здесь 1). Более высокие даже мощные необработанные моменты также будут оцениваться до бесконечности. Однако сырые моменты с нечетной нечеткой нечеткой нечеткой, что отличается от хорошей со скоростью бесконечности. Необработанные моменты с нечетной степенью не достижимой оценки, поскольку их значения по существу эквивалентны  , поскольку две половины интеграла расходятся и имеют противоположные знаки. Первый необработанный момент - это среднее значение, которого, как ни странно, не существует. (См. Также обсуждение выше по этому поводу.) Это, в свою очередь, означает, что все центральные моменты и стандартизованные моменты не используются, поскольку все они основаны на среднем значении. Дисперсия - которая является вторым центральным моментом - также не (несмотря на то, что необработанный второй момент имеет размерность).
, поскольку две половины интеграла расходятся и имеют противоположные знаки. Первый необработанный момент - это среднее значение, которого, как ни странно, не существует. (См. Также обсуждение выше по этому поводу.) Это, в свою очередь, означает, что все центральные моменты и стандартизованные моменты не используются, поскольку все они основаны на среднем значении. Дисперсия - которая является вторым центральным моментом - также не (несмотря на то, что необработанный второй момент имеет размерность).
Результаты для высших моментов следуют из неравенства Гёльдера, которое подразумевает, что более высокие моменты (или половины моментов) расходятся, если более низкие.
Моменты усеченных распределений
Рассмотрим усеченное распределение, определенное ограничение стандартного распределения Коши интервалом [-10, 10]. Такое усеченное распределение имеет все моменты (и центральная предельная теорема применима к i.i.d. наблюдения из него); тем не менее, почти для всех практических целей оно ведет себя как распределение Коши.
Оценка параметров
Параметры распределения Коши не соответствуют среднему значению и дисперсии, попытка оценить параметры Коши с использованием выбора среднего и выборочной дисперсии не увенчается успехом. Например, если i.i.d. выборка размера n берется из распределения Коши, можно вычислить выборочное среднее как:

Хотя примерные значения  будут сосредоточены вокруг центральное значение , среднее значение выборки будет становиться все более изменчивым по мере увеличения числа наблюдений из-за увеличения вероятности обнаружения точек выборки с большим абсолютным значением. Фактически, распределение выборочного среднего будет равно распределению самих наблюдений; то есть выборочное среднее большой выборки не лучше (или хуже) для оценки , чем любое отдельное наблюдение из выборки. Точно так же расчет дисперсии выборки приведет к тому, что значения будут расти по мере увеличения количества наблюдений.
будут сосредоточены вокруг центральное значение , среднее значение выборки будет становиться все более изменчивым по мере увеличения числа наблюдений из-за увеличения вероятности обнаружения точек выборки с большим абсолютным значением. Фактически, распределение выборочного среднего будет равно распределению самих наблюдений; то есть выборочное среднее большой выборки не лучше (или хуже) для оценки , чем любое отдельное наблюдение из выборки. Точно так же расчет дисперсии выборки приведет к тому, что значения будут расти по мере увеличения количества наблюдений.
Таким образом, более надежные средства оценки центрального значения и параметра масштабирования необходимы. Один из простых методов - взять среднее значение выборки в качестве оценки и половину выборки межквартильного размаха в качестве оценки. из . Были разработаны другие, более точные и надежные методы. Например, усеченное среднее средних 24% выборки статистика заказов дает оценку для , что более эффективно, чем использование медианы выборки или полного среднего значения выборки. Однако из-за толстых хвостов распределения Коши эффективность средства оценки снижается, если используется более 24% выборки.
Максимальное правдоподобие также можно использовать для оценки параметры и . Однако это имеет тенденцию усложняться тем фактом, что для этого требуется найти корни многочлена высокой степени, и может быть несколько корней, которые представляют локальные максимумы. Кроме того, хотя оценка максимального правдоподобия является асимптотически эффективной, она относительно неэффективна для небольших выборок. Функция логарифма правдоподобия для распределения Коши для размера выборки  :
:

Максимизация функции правдоподобия журнала относительно и дает следующую систему уравнений:


Обратите внимание, что

является монотонной функцией в и что решение должен удовлетворять

Решение только для требует решения многочлена степени  и решения только для
и решения только для  требует решения полинома степени
требует решения полинома степени  . Следовательно, независимо от того, выполняется ли решение для одного параметра или для обоих параметров одновременно, обычно требуется численное решение на компьютере. Преимущество оценки максимального правдоподобия - асимптотическая эффективность; оценка с использованием выборочной медианы лишь примерно на 81% асимптотически эффективна, чем оценка по максимальной вероятности. Среднее значение усеченной выборки с использованием статистики среднего порядка 24% составляет около 88% как асимптотически эффективный показатель как оценка максимального правдоподобия. Когда метод Ньютона используется для поиска решения для оценки максимального правдоподобия, статистика среднего порядка 24% может использоваться в качестве начального решения для .
. Следовательно, независимо от того, выполняется ли решение для одного параметра или для обоих параметров одновременно, обычно требуется численное решение на компьютере. Преимущество оценки максимального правдоподобия - асимптотическая эффективность; оценка с использованием выборочной медианы лишь примерно на 81% асимптотически эффективна, чем оценка по максимальной вероятности. Среднее значение усеченной выборки с использованием статистики среднего порядка 24% составляет около 88% как асимптотически эффективный показатель как оценка максимального правдоподобия. Когда метод Ньютона используется для поиска решения для оценки максимального правдоподобия, статистика среднего порядка 24% может использоваться в качестве начального решения для .
Форму можно оценить с помощью медианы абсолютных значений, поскольку для местоположения 0 переменные Коши ,  параметр формы.
параметр формы.
Многомерное распределение Коши
A случайный вектор  называется многомерным распределением Коши, если каждая линейная комбинация его компонентов
называется многомерным распределением Коши, если каждая линейная комбинация его компонентов  имеет распределение Коши. То есть для любого постоянного вектора
имеет распределение Коши. То есть для любого постоянного вектора  случайная величина
случайная величина  должно иметь одномерное распределение Коши. Характеристическая функция многомерного распределения Коши определяется выражением:
должно иметь одномерное распределение Коши. Характеристическая функция многомерного распределения Коши определяется выражением:

где  и
и  - вещественные функции с a однородной функцией от первая степень и положительная однородная функция первой степени. Более формально:
- вещественные функции с a однородной функцией от первая степень и положительная однородная функция первой степени. Более формально:


для всех  .
.
Примером двумерного распределения Коши может быть задается по формуле:
![{\ displaystyle f (x, y; x_ {0}, y_ {0}), \ gamma) = {1 \ over 2 \ pi} \ left [{\ gamma \ over ((x-x_ {0}) ^ {2} + (y-y_ {0}) ^ {2} + \ gamma)) ^ {2}) ^ {3/2}} \ right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6d8819f3c50d69b56d61fe3055c18b1b53d37e50)
Обратите внимание, что в этом примере, хотя и нет аналога в ковариационную матрицу  и
и  не статистически независимы.
не статистически независимы.
Мы также можем написать эта формула для комплексной переменной. Тогда функция плотности вероятности комплексного Коши равна:
![{\ displaystyle f (z; z_ {0 }, \ gamma) = {1 \ over 2 \ pi} \ left [{\ gamma \ over (| z-z_ {0} | ^ {2} + \ gamma ^ {2}) ^ {3/2}} \ right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/de0257adbd6a9a7b9216baf7a6837e0da6255390)
Аналогично одномерной плотности, многомерная плотность Коши также связана с многомерным распределением Стьюдента. Они эквивалентны, когда параметр степеней свободы равен единице. Плотность распределения Стьюдента измерения  с одной степенью свободы принимает следующий вид:
с одной степенью свободы принимает следующий вид:
![f ({\ mathbf x}; {\ mathbf \ mu}, {\ mathbf \ Sigma}, k) = \ frac {\ Gamma \ left (\ frac {1 + k} {2} \ right)} {\ Gamma (\ frac {1} {2}) \ pi ^ {\ frac {k} {2}} \ left | {\ mathbf \ Sigma} \ right | ^ {\ frac {1} {2}} \ left [1+ ({\ mathbf x} - {\ mathbf \ mu}) ^ T {\ mathbf \ Sigma} ^ {- 1} ({\ mathbf x} - {\ mathbf \ mu}) \ right] ^ {\ frac {1+ k} {2}}}.](https://wikimedia.org/api/rest_v1/media/math/render/svg/d9e1b5b8a0ffbbba9a4478b2acb4da449c1006d5)
Свойства и детали для этой плотности могут можно получить, рассматривая его как частный случай многомерной плотности Стьюдента.
Свойства преобразования
- Если
 затем
затем 
- Если
 и
и  независимы, тогда
независимы, тогда  и
и 
- Если
 , затем
, затем 
- Параметризация МакКуллахом распределений Коши : выражение распределения Коши через один комплексный параметр , определить
 для обозначения
для обозначения  . Если , то:
. Если , то:

где ,  ,
,  и
и  - действительные числа.
- действительные числа.
- Используя то же соглашение, что и выше, если , то:

- где
 - круговое распределение Коши.
- круговое распределение Коши.
мера Леви
Распределение Коши - это стабильное распределение индекса 1. Представление Леви – Хинчина такого устойчивого распределения параметра задается для  по :
по :

where

and  can be expressed explicitly. In the case of the Cauchy distribution, one has
can be expressed explicitly. In the case of the Cauchy distribution, one has  .
.
This last representation is a consequence of the formula

Related distributions
 Student's t distribution
Student's t distribution  non-standardized Student's t distribution
non-standardized Student's t distribution - If
 independent, then
independent, then 
- If
 then
then 
- If
 then
then 
- If
 then
then 
- The Cauchy distribution is a limiting case of a Pearson distribution of type 4
- The Cauchy distribution is a special case of a Pearson distribution of type 7.
- The Cauchy distribution is a stable distribution : if
 , then
, then  .
. - The Cauchy distribution is a singular limit of a hyperbolic distribution
- The wrapped Cauchy distribution, taking values on a circle, is derived from the Cauchy distribution by wrapping it around the circle.
- If
 ,
,  , затем
, затем  . Для половинных распределений Коши это соотношение выполняется, если положить
. Для половинных распределений Коши это соотношение выполняется, если положить  .
.
Релятивистское распределение Брейта – Вигнера
В ядерной и физике частиц, энергетический профиль резонанс описывается релятивистским распределением Брейта – Вигнера, а распределение Коши - (нерелятивистским) распределением Брейта – Вигнера.
Возникновение и применения
- В спектроскопия, распределение Коши описывает форму спектральных линий, которые подвержены однородному уширению, в котором все атомы взаимодействуют одинаково с диапазоном частот, содержащимся в Форма линии. Многие механизмы вызывают однородное уширение, в первую очередь столкновительное уширение. Lifeti me или естественное уширение также приводит к форме линии, описываемой распределением Коши.
- Применения распределения Коши или его преобразования можно найти в полях, работающих с экспоненциальным ростом. В статье Уайта 1958 года была получена тестовая статистика для оценок
 для уравнения
для уравнения  и где оценка за правдоподобеньших квадратов найдена с использованием обычных
и где оценка за правдоподобеньших квадратов найдена с использованием обычных
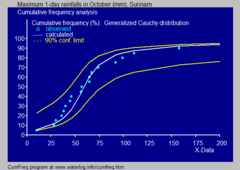
Дневные осадки с использованием
CumFreq, см. также
аппроксимация распределения - Распределение Коши часто представляет собой распределение Распределение. Классическая ссылка на это называется проблемой маяка Чайки и как в приведенном выше разделе как распределение Брейта - Вигнера в физике элемента. ентарных частиц.
- В гидрологии распределены Коши применяемые к экстремальным явлениям, как годовые максимальные однодневные осадки и сток реки. Синий рисунок иллюстрирует пример подгонки распределения Коши к ранжированным месячным максимальным однодневным осадкам, также 90% доверительный пояс, основанный на биноми распределении. Данные о дождевых осадках представлены с помощью , где представлены позиции как часть кумулятивного частотного анализа.
- Выражение для мнимой части комплексной электрической диэлектрической проницаемости согласно модели Лоренца распределением Коши..
- В дополнительном распределении к модели толстых хвостов в вычислительных финансах, Коши распределения можно использовать для моделирования VAR (значение с риском ), производя много большая вероятность экстремального риска, чем распределение Гаусса.
См. также
Ссылки
Внешние ссылки

 . Фиолетовая кривая - стандартное распределение Коши
. Фиолетовая кривая - стандартное распределение Коши
 Оценка среднего и стандартного отклонения по выборкам из распределения Коши (внизу) не сходится с большим количеством выборок, как в нормальном распределении ( вверху). Скачки могут быть сколь угодно большими, как видно на графиках внизу. (Щелкните, чтобы развернуть)
Оценка среднего и стандартного отклонения по выборкам из распределения Коши (внизу) не сходится с большим количеством выборок, как в нормальном распределении ( вверху). Скачки могут быть сколь угодно большими, как видно на графиках внизу. (Щелкните, чтобы развернуть)  Дневные осадки с использованием CumFreq, см. также аппроксимация распределения
Дневные осадки с использованием CumFreq, см. также аппроксимация распределения