
Войти
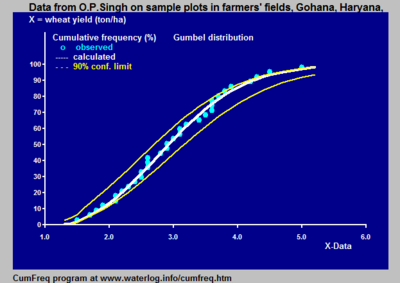 Кумулятивное частотное распределение, адаптированное кумулятивное распределение вероятностей и доверительные интервалы
Кумулятивное частотное распределение, адаптированное кумулятивное распределение вероятностей и доверительные интервалы Кумулятивный частотный анализ - это анализ частота появления значений явления меньше эталонного значения. Явление может зависеть от времени или пространства. Накопленная частота также называется частотой непревышения.
Кумулятивный частотный анализ выполняется, чтобы получить представление о том, как часто определенное явление (характеристика) оказывается ниже определенного значения. Это может помочь в описании или объяснении ситуации, в которой задействовано данное явление, или в планировании мероприятий, например, в защите от наводнений..
Этот статистический метод можно использовать для определения вероятности повторения такого события, как наводнение. в будущем в зависимости от того, как часто это происходило в прошлом. Его можно адаптировать к таким вещам, как изменение климата, вызывающее более влажную зиму и более сухое лето.
Частотный анализ - это анализ того, как часто или как часто наблюдаемое явление происходит в определенном диапазоне.
Частотный анализ применяется к записи длины N наблюдаемых данных X 1, X 2, X 3... X N о переменном явлении X. Запись может быть зависящей от времени (например, количество осадков, измеренных в одном месте) или от места (например, урожайность в области) или иным образом.
Элемент накопленная частота MXrопорного значения Xr является частота, с которой наблюдаемые значения Х меньше или равна Xr.
Относительная накопленная частота Fc может быть рассчитана по формуле:
, где N - количество данных
Вкратце это выражение можно записать как:
Когда Xr = Xmin, где Xmin - уникальное минимальное наблюдаемое значение, оказывается, что Fc = 1 / N, потому что M = 1 С другой стороны, когда Xr = Xmax, где Xmax - уникальное максимальное наблюдаемое значение, обнаруживается, что Fc = 1, потому что M = N. Следовательно, когда Fc = 1, это означает, что Xr является значением, при котором все данные меньше или равно Xr.
В процентах уравнение гласит:
совокупная вероятность Pc X, меньшее или равное Xr, может быть оценено несколькими способами на основе совокупной частоты M.
Один из способов - использовать относительную накопленную частоту Fc в качестве оценки.
Другой способ - учесть возможность того, что в редких случаях X может принимать значения, превышающие наблюдаемый максимум Xmax. Это можно сделать, разделив совокупную частоту M на N + 1 вместо N. Оценка будет иметь следующий вид:
Существуют также другие предложения для знаменателя (см. нанесение позиций ).
 Ранжированные кумулятивные вероятности
Ранжированные кумулятивные вероятности Оценка вероятности упрощается за счет ранжирования данных.
Когда наблюдаемые данные X расположены в порядке возрастания (X 1 ≤ X 2 ≤ X 3 ≤.. ≤ X N, минимальное первое и максимальное последнее), а Ri - номер ранга наблюдения Xi, где адфикс i указывает порядковый номер в диапазоне возрастающих данных, тогда может быть оценена совокупная вероятность по:
Когда, с другой стороны, наблюдаемые данные из X расположены в порядке убывания, максимальное первое и минимальное последнее, а Rj - порядковый номер наблюдения Xj, кумулятивная вероятность может быть оценена следующим образом:
 Различные кумулятивные нормальные распределения вероятностей с их параметры
Различные кумулятивные нормальные распределения вероятностей с их параметры Чтобы представить совокупное частотное распределение в виде непрерывного математического уравнения вместо дискретного набора данных, можно попытаться подогнать совокупное частотное распределение к известной совокупной вероятности di stribution,.. В случае успеха известного уравнения будет достаточно для определения частотного распределения, и таблица данных не потребуется. Кроме того, уравнение помогает интерполяции и экстраполяции. Однако следует проявлять осторожность при экстраполяции совокупного частотного распределения, поскольку это может быть источником ошибок. Одна из возможных ошибок состоит в том, что распределение частот больше не следует выбранному распределению вероятностей за пределами диапазона наблюдаемых данных.
Любое уравнение, которое дает значение 1 при интегрировании от нижнего предела до верхнего предела, хорошо согласующегося с диапазоном данных, может использоваться как распределение вероятностей для подгонки. Образец распределений вероятностей, которые можно использовать, можно найти в распределениях вероятностей.
Распределения вероятностей можно подогнать несколькими методами, например:
Применение обоих типов методов с использованием, например,
часто показывают, что ряд распределений хорошо соответствует данным и не дает существенно разных результатов, тогда как различия между ними могут быть небольшими по сравнению с шириной доверительного интервала. Это показывает, что бывает сложно определить, какое распределение дает лучшие результаты.
 Кумулятивное частотное распределение с разрывом
Кумулятивное частотное распределение с разрывом Иногда можно подогнать один тип распределения вероятностей к нижней части диапазона данных, а другой тип - к верхней части, разделив их точка останова, благодаря которой улучшается общая подгонка.
На рисунке показан пример полезного введения такого прерывистого распределения для данных об осадках на севере Перу, где климат зависит от поведения Тихоокеанского течения Эль-Ниньо. Когда Ниньо простирается на юг Эквадора и впадает в океан вдоль побережья Перу, климат в северном Перу становится тропическим и влажным. Когда Ниньо не достигает Перу, климат здесь полузасушливый. По этой причине более высокие осадки имеют другое частотное распределение, чем более низкие осадки.
Когда кумулятивное частотное распределение выводится из записи данных, можно спросить, можно ли его использовать для предсказаний. Например, учитывая распределение речного стока за 1950–2000 годы, можно ли это распределение использовать для прогнозирования того, как часто будет превышаться определенный речной сток в 2000–50 годах? Ответ - да, при условии, что условия окружающей среды не изменятся. Если условия окружающей среды действительно изменяются, например, изменения инфраструктуры водосбора реки или режима выпадения дождя из-за климатических изменений, прогноз на основе исторических данных может быть систематически ошибочным. Даже при отсутствии систематической ошибки может быть случайная ошибка, потому что случайно наблюдаемые разряды в течение 1950-2000 гг. Могли быть выше или ниже нормальных, в то время как, с другой стороны, разряды с 2000 по 2000 гг. 2050 год может случайно оказаться ниже или выше нормы. Проблемы, связанные с этим, были исследованы в книге Черный лебедь.
 Биномиальные распределения для Pc = 0,1 (синий), 0,5 (зеленый) и 0,8 (красный) в выборке размером N = 20. Распределение является симметричным только тогда, когда Pc = 0,5
Биномиальные распределения для Pc = 0,1 (синий), 0,5 (зеленый) и 0,8 (красный) в выборке размером N = 20. Распределение является симметричным только тогда, когда Pc = 0,5  90% биномиальных доверительных поясов по логарифмической шкале.
90% биномиальных доверительных поясов по логарифмической шкале. Теория вероятностей может помочь оценить диапазон, в котором может находиться случайная ошибка. В случае кумулятивной частоты есть только два возможность: определенное эталонное значение X превышается или не превышается. Сумма частоты превышения и совокупной частоты составляет 1 или 100%. Следовательно, биномиальное распределение можно использовать для оценки диапазона случайной ошибки.
Согласно нормальной теории, биномиальное распределение может быть аппроксимировано, и для больших N стандартное отклонение Sd можно рассчитать следующим образом:
где Pc - кумулятивная вероятность, а N - количество данных. Видно, что стандартное отклонение Sd уменьшается при увеличении числа наблюдений N.
При определении доверительного интервала Pc используется t-критерий Стьюдента (т). Значение t зависит от количества данных и уровня достоверности оценки доверительного интервала. Затем нижний (L) и верхний (U) пределы достоверности Pc в симметричном распределении находятся из:
Это известно как интервал Вальда. Однако биномиальное распределение симметрично относительно среднего только при Pc = 0,5, но становится асимметричным и становится все более и более асимметричным, когда Pc приближается к 0 или 1. Следовательно, с помощью аппроксимации Pc и 1-Pc могут быть используется в качестве весовых коэффициентов при присвоении t.Sd L и U:
, где видно, что эти выражения для Pc = 0,5 совпадают с предыдущими.
| N = 25, Pc = 0,8, Sd = 0,08, уровень достоверности 90%, t = 1,71, L = 0,58, U = 0,85. Таким образом, с достоверностью 90% найдено, что 0,58 < Pc < 0.85. Тем не менее существует 10% -ная вероятность того, что Pc < 0.58, or Pc>0,85 |
Примечания
 Периоды возврата и пояс доверия. Кривая периодов повторяемости увеличивается экспоненциально.
Периоды возврата и пояс доверия. Кривая периодов повторяемости увеличивается экспоненциально. Кумулятивная вероятность Pc также может быть названа вероятностью непревышения. вероятность превышения Pe (также называемая функцией выживаемости ) находится из:
период повторяемости T, определенный как :
и указывает ожидаемое количество наблюдений, которые необходимо выполнить снова, чтобы найти значение переменной в исследовании, большее, чем значение, используемое для T.. Верхнее (T U) и более низкие (T L) доверительные интервалы периодов повторяемости могут быть найдены соответственно как:
Для экстремальных значений исследуемой переменной U близко к 1, а небольшие изменения U вызывают большие изменения T U. Следовательно, предполагаемый период повторяемости экстремальных значений подвержен большой случайной ошибке. Более того, найденные доверительные интервалы сохраняются для долгосрочного прогноза. Для прогнозов на более коротком этапе доверительные интервалы U-L и T U−TLмогут быть шире. Вместе с ограниченной достоверностью (менее 100%), использованной в t-тесте, это объясняет, почему, например, 100-летние осадки могут выпадать дважды за 10 лет.
 Девять период повторяемости кривых 50-летних выборок из теоретической 1000-летней записи (базовая линия)
Девять период повторяемости кривых 50-летних выборок из теоретической 1000-летней записи (базовая линия) Строгое понятие периода повторяемости фактически имеет значение только тогда, когда оно касается времени- зависимое явление, такое как точечные осадки. Период возврата тогда соответствует ожидаемому времени ожидания, пока превышение не произойдет снова. Период повторяемости имеет то же измерение, что и время, для которого репрезентативно каждое наблюдение. Например, когда наблюдения касаются ежедневных осадков, период повторяемости выражается в днях, а для годовых осадков - в годах.
На рисунке показаны вариации, которые могут возникнуть при получении выборок переменной, которая следует определенному распределению вероятностей. Данные были предоставлены Бенсоном.
Полоса уверенности вокруг экспериментальной кривой накопленной частоты или периода повторяемости дает представление о регионе, в котором может быть найдено истинное распределение.
Также поясняется, что экспериментально найденное наиболее подходящее распределение вероятностей может отклоняться от истинного распределения.
 Гистограмма, полученная из адаптированного кумулятивного распределения вероятностей
Гистограмма, полученная из адаптированного кумулятивного распределения вероятностей 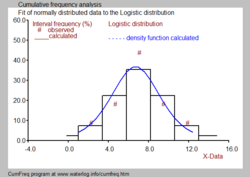 Гистограмма и функция плотности вероятности, полученные из кумулятивного распределения вероятностей, для логистического распределения.
Гистограмма и функция плотности вероятности, полученные из кумулятивного распределения вероятностей, для логистического распределения.Наблюдаемые данные могут быть упорядочены в классах или группах с порядковым номером k. Каждая группа имеет нижний предел (L k) и верхний предел (U k). Когда класс (k) содержит данные m k и общее количество данных равно N, тогда относительная частота класса или группы находится из:
или кратко:
или в процентах:
Представление частот всех классов дает распределение частот или гистограмма. Гистограммы, даже если они сделаны из одной и той же записи, различаются для разных классов.
Гистограмма также может быть получена из подобранного кумулятивного распределения вероятностей:
Может быть разница между Fg k и Pg k из-за отклонений наблюдаемых данных от подобранного распределения (см. синий рисунок).
Часто требуется объединить гистограмму с функция плотности вероятности, как показано на черно-белом изображении.