
Войти
Подбор распределения вероятностей или просто подгонка распределения - это подгонка распределения вероятностей к серии данных, касающихся повторного измерения переменного явления.
Цель аппроксимации распределения - прогнозировать вероятность или прогнозировать частоту появления величины явления в определенном интервале.
Существует множество распределений вероятностей (см. список распределений вероятностей ), некоторые из которых могут быть более точно подогнаны под наблюдаемую частоту данных, чем другие, в зависимости от характеристик явления и распределения. Предполагается, что близкое распределение дает хорошие прогнозы.
Следовательно, при подгонке распределения необходимо выбрать распределение, которое хорошо подходит для данных.
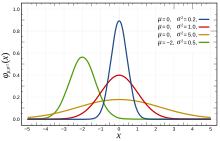 Различные формы симметричного нормального распределения в зависимости от среднего μ и дисперсии σ
Различные формы симметричного нормального распределения в зависимости от среднего μ и дисперсии σ Выбор подходящего распределения зависит от наличия или отсутствия симметрии набора данных относительно среднего значения.
Симметричные распределения
Когда данные симметрично распределены вокруг среднее, в то время как частота появления данных дальше от среднего уменьшается, можно, например, выбрать нормальное распределение, логистическое распределение или t-распределение Стьюдента. Первые два очень похожи, в то время как последний с одной степенью свободы имеет «более тяжелые хвосты», что означает, что значения, более удаленные от среднего, встречаются относительно чаще (т.е. эксцесс выше). Распределение Коши также является симметричным.
Смещение распределений вправо
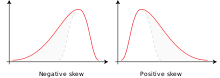 Смещение влево и вправо
Смещение влево и вправо Когда большие значения имеют тенденцию быть дальше от среднего, чем меньшие значения, одно имеет неравномерное распределение вправо (т.е. положительна асимметрия ), можно, например, выбрать логнормальное распределение (т. е. логарифмические значения данных нормально распределены ), логарифмическое распределение (т. е. логарифмические значения данных соответствуют логистическому распределению ), распределение Гамбеля, экспоненциальное распределение, Распределение Парето, распределение Вейбулла, распределение Берра или распределение Фреше. Последние четыре распределения ограничены слева.
Распределение смещения влево
Когда меньшие значения имеют тенденцию быть дальше от среднего, чем большие значения, одно имеет неравномерное распределение влево (т.е. имеется отрицательная асимметрия), можно, например, выбрать квадратно-нормальное распределение (то есть нормальное распределение, примененное к квадрату значений данных), инвертированное (зеркальное) распределение Гамбеля, распределение Дагума (зеркальное распределение Берра) или Распределение Гомперца, ограниченное слева.
Существуют следующие методы аппроксимации распределения:
Например, параметр  (ожидание ) можно оценить с помощью среднего данных и параметра (ожидание ) можно оценить с помощью среднего данных и параметра  (дисперсия ) может быть оценена из стандартного отклонения данных. Среднее значение находится как (дисперсия ) может быть оценена из стандартного отклонения данных. Среднее значение находится как  , где , где  - значение данных, а - значение данных, а  - количество данных, а стандартное отклонение рассчитывается как - количество данных, а стандартное отклонение рассчитывается как  . С этими параметрами многие распределения, например нормальное распределение, полностью определены. . С этими параметрами многие распределения, например нормальное распределение, полностью определены. |
 Кумулятивное распределение Гамбеля, подогнанное к максимальным однодневным осадкам в октябре в Суринаме методом регрессии с добавлением доверительной полосы с использованием cumfreq
Кумулятивное распределение Гамбеля, подогнанное к максимальным однодневным осадкам в октябре в Суринаме методом регрессии с добавлением доверительной полосы с использованием cumfreq . Например, кумулятивное распределение Гамбеля может быть линеаризовано до  , где - переменная данных, а , где - переменная данных, а  , где , где  - кумулятивная вероятность, т. Е. Вероятность того, что значение данных меньше . Таким образом, используя позицию построения графика для , можно найти параметры - кумулятивная вероятность, т. Е. Вероятность того, что значение данных меньше . Таким образом, используя позицию построения графика для , можно найти параметры  и и  из линейной регрессии из линейной регрессии  на , и распределение Гамбеля полностью определено. на , и распределение Гамбеля полностью определено. |
Обычно данные преобразуются логарифмически, чтобы соответствовать симметричным распределениям (например, нормальному и логистическому ) к данным, подчиняющимся положительному распределению. перекос (т.е. наклон вправо, с mean >в режиме и с правым хвостом, который длиннее левого), см. логнормальное распределение и логистическое распределение. Подобного эффекта можно добиться, извлекая квадратный корень из данных.
Для соответствия симметричному распределению данных, подчиняющихся отрицательно искаженному распределению (т.е. смещенному влево, с средним < режимом, а с правым хвостом это короче чем левый хвост) можно использовать квадраты значений данных для выполнения подгонки.
В более общем смысле можно возвести данные в степень p, чтобы согласовать симметричные распределения с данными, подчиняющимися распределению любой асимметрии, при этом p < 1 when the skewness is positive and p>1, когда асимметрия отрицательная. Оптимальное значение p должно быть найдено численным методом. Численный метод может состоять из предположения диапазона значений p, затем многократного применения процедуры аппроксимации распределения для всех предполагаемых значений p и, наконец, выбора значения p, для которого сумма квадратов отклонений вычисленных вероятностей от измеренных частот (хи в квадрате ) является минимальным, как это сделано в CumFreq.
. Обобщение увеличивает гибкость распределений вероятностей и увеличивает их применимость при подборе распределения.
 (A) Смещение распределения вероятностей Гамбеля вправо и (B) Смещение распределения вероятностей Гамбеля влево
(A) Смещение распределения вероятностей Гамбеля вправо и (B) Смещение распределения вероятностей Гамбеля влево Скошенные распределения можно инвертировать (или отразить), заменив в математическом выражении кумулятивная функция распределения (F) с ее дополнением: F '= 1-F, получение дополнительной функции распределения (также называемой функцией выживания ), которая дает зеркало образ. Таким образом, распределение, которое смещено вправо, преобразуется в распределение, которое смещено влево, и наоборот.
| Пример. F-выражение положительно искаженного распределения Гамбеля : F = exp [-exp {- (Xu) /0.78s}], где u - режим (т. Е. Значение встречается наиболее часто), а s - стандартное отклонение. Распределение Гамбеля можно преобразовать с помощью F '= 1-exp [-exp {- (x-u) /0.78s}]. Это преобразование дает обратное, зеркальное или дополнительное распределение Гамбеля, которое может соответствовать ряду данных, подчиняющемуся отрицательно искаженному распределению. |
Техника инверсии асимметрии увеличивает количество распределений вероятностей, доступных для аппроксимации распределения, и расширяет возможности аппроксимации распределения.
Некоторые распределения вероятностей, такие как экспоненциальное, не поддерживают значения данных (X), равные или меньшие нуля. Тем не менее, когда присутствуют отрицательные данные, такие распределения все еще можно использовать, заменяя X на Y = X-Xm, где Xm - минимальное значение X. Эта замена представляет собой сдвиг распределения вероятностей в положительном направлении, то есть вправо, потому что Xm отрицательно. После завершения аппроксимации распределения Y соответствующие значения X находятся из X = Y + Xm, что представляет собой обратный сдвиг распределения в отрицательном направлении, то есть влево.. Техника сдвига распределения увеличивает шанс найти правильно подходящее распределение вероятностей.
 Составное (прерывистое) распределение с доверительным поясом
Составное (прерывистое) распределение с доверительным поясом Существует возможность использовать два разных распределения вероятностей, одно для нижнего диапазона данных, а другое для более высокого, например, Распределение Лапласа. Диапазоны разделены точкой останова. Использование таких составных (прерывистых) распределений вероятностей может быть целесообразным, если данные изучаемого явления были получены при двух наборах различных условий.
 Анализ неопределенности с поясами уверенности с использованием биномиального распределения
Анализ неопределенности с поясами уверенности с использованием биномиального распределения Прогнозы возникновения событий, основанные на подобранных распределениях вероятностей, подвержены неопределенности, которая возникает из следующих условий:
 Вариации девяти периода повторяемости кривые 50-летних выборок из теоретической 1000-летней записи (базовая линия), данные от Benson
Вариации девяти периода повторяемости кривые 50-летних выборок из теоретической 1000-летней записи (базовая линия), данные от Benson Оценка неопределенности в первом и втором случае может быть получена с помощью биномиального распределения вероятностей с использованием например вероятность превышения Pe (т. е. вероятность того, что событие X больше эталонного значения Xr для X) и вероятность непревышения Pn (т. е. вероятность того, что событие X меньше или равно эталонному значению Xr, это также называется кумулятивная вероятность ). В этом случае есть только две возможности: либо превышение, либо непревышение. Эта двойственность является причиной применимости биномиального распределения.
С помощью биномиального распределения можно получить интервал прогнозирования. Такой интервал также оценивает риск отказа, то есть вероятность того, что прогнозируемое событие все еще останется за пределами доверительного интервала. Анализ достоверности или риска может включать период повторяемости T = 1 / Pe, как это сделано в гидрологии.
 Список распределений вероятностей, ранжированных по степени соответствия.
Список распределений вероятностей, ранжированных по степени соответствия.  Гистограмма и плотность вероятности набор данных, соответствующий распределению GEV
Гистограмма и плотность вероятности набор данных, соответствующий распределению GEV Путем ранжирования степени соответствия различных распределений можно получить представление о том, какое распределение является приемлемым, а какое - не.
Из кумулятивной функции распределения (CDF) можно получить гистограмму и функцию плотности вероятности (PDF).