Алгоритм оптимизации для искусственных нейронных сетей
В машинном обучении, обратном распространении (backprop,BP) - широко используемый алгоритм в обучении нейронных сетей прямого распространения для контролируемого обучения. Обобщения обратного распространения существуют для искусственных нейронных сетей (ИНС) и других функций в целом. Все эти классы алгоритмов обычно называются «обратным распространением». В подгонке нейронной сети, обратное распространение вычисляет градиент функции потерь относительно весов сети для одного входа –Пример вывода, и делает это эффективно, в отличие от наивного прямого градиента по отношению к каждому весу индивидуально. Эта эффективность делает возможным использование градиентных методов для обучения многослойных сетей, обновления весов для минимизации потерь; Обычно используются градиентный спуск или варианты, такие как стохастический градиентный спуск. Алгоритм обратного распространения работает путем вычисления градиента функций потерь по отношению к каждому весу по правиламуочки , вычисляя градиент по одному слою за раз, повторяя назад от последнего уровня к повторных вычислений промежуточных членов в цепном правиле; это пример динамического программирования.
Термин обратное распространение строго относится только к алгоритму вычисления градиента, а не к тому, как градиент используется; однако этот термин часто используется в широком смысле слова алгоритма обучения, включая способ использования градиента, например, стохастический градиентный спуск. Обратное распространение вычисление градиента в правиле дельты, которое является однослойной версией обратного распространения, и, в свою очередь, обобщается с помощью автоматического дифференцирования, где обратное распространение является частным случаем обратное накопление (или «обратный режим»). Термин обратное распространение и его общее использование в нейронных сетях было объявлено в Rumelhart, Hinton Williams (1986a), разработано и популяризировано в Rumelhart, Hinton Williams (1986b), но техника была открыта заново много раз и имеет много предшественников, начиная с 1960-х годов; см. § История. Современный обзор дан в учебнике по глубокому обучению от Goodfellow, Bengio Courville (2016).
Содержание
- 1 Обзор
- 2 Умножение матриц
- 3 Присоединенный граф
- 4 Интуиция
- 4.1 Мотивация
- 4.2 Обучение как задача оптимизации
- 5 Выведение
- 5.1 Нахождение производной ошибки
- 6 Функция потерь
- 6.1 Допущения
- 6.2 Пример потери функция
- 7 Ограничения
- 8 История
- 9 См. также
- 10 Примечания
- 11 Ссылки
- 12 Дополнительная литература
- 13 Внешние ссылки
Обзор
Обратное распространение вычисляет градиент в весовом пространстве нейронной сети прямого распространения по отношению к функциям потерь . Обозначьте:
 : вход (векторные характеристики)
: вход (векторные характеристики) : целевой выход
: целевой выход - для классификации, выходными данными будет вектор вероятностей классов (например,
 , а целевым выходом будет конкретный класс, закодированный горячая / фиктивная переменная (например,
, а целевым выходом будет конкретный класс, закодированный горячая / фиктивная переменная (например,  ).
).
 : функция потерь или «функция стоимости»
: функция потерь или «функция стоимости» - Для классификации это обычно перекрестная энтропия (XC, логарифм потерь ), а для регрессии это обычно квадрат ошибки потери (SEL).
 : количество слоев
: количество слоев : между весом слоем
: между весом слоем  и
и  , где
, где  - вес между
- вес между  -й узел в слое и
-й узел в слое и  - й узел в слое
- й узел в слое  : функции активации на уровне
: функции активации на уровне - Для классификации последний обычно является логистическая функция для двоичной классификации и softmax (softargmax) для многоклассовой классификации, в то время как для скрытых слоев это традиционно была сигмоидальная функция (логистическая функция или другие) на каждом узле (координаты), но сегодня более разнообразен, с обычным выпрямителем (пандус, ReLU ).
При выводе обратного распространения, используются другие промежуточные количества; они вводятся по мере необходимости ниже. Члены с помощью функций обратного распространения не обрабатываются специально, поскольку они соответствуют весу с фиксированным входом 1. Для целей обратного распространения функции используются не значения, если они и их производные функции могут быть эффективно оценены.
Вся сеть представляет собой комбинацию композиции функций и умножения матриц :

Для обучающего набора будет набор пар ввода-вывода,  . Для каждой пары ввода-вывода
. Для каждой пары ввода-вывода  в обучающем наборе потеря модели в этой паре является стоимостью разницы между прогнозируемым выводом
в обучающем наборе потеря модели в этой паре является стоимостью разницы между прогнозируемым выводом  и целевым выводом
и целевым выводом  :
:

Обратите внимание на различие: во время оценки модели веса фиксируются, а входные данные меняются (и конечный выход может быть неизвестен), и сеть заканчивается выходным слоем (он не включает функцию потерь). Во время обучения модели пара вход-выход фиксирована, веса меняются, и сеть функций потерь.
Обратное распространение вычисляет градиент для фиксированной пары вход-выход , где вес может изменяться. Каждый отдельный компонент градиента,  , может быть вычислен по цепочному правилу; однако делать это отдельно для каждого веса неэффективно. Обратное распространение вычисляет градиент, обратное сравнение вычислений и вычисляет ненужных промежуточных значений, вычисляя градиент каждого слоя - в частности, градиентного взвешивания каждого слоя, обозначаемый
, может быть вычислен по цепочному правилу; однако делать это отдельно для каждого веса неэффективно. Обратное распространение вычисляет градиент, обратное сравнение вычислений и вычисляет ненужных промежуточных значений, вычисляя градиент каждого слоя - в частности, градиентного взвешивания каждого слоя, обозначаемый  - сзади наперед.
- сзади наперед.
Неформально, ключевой момент заключается в том, что является единственным способом, которым используется вес в  влияет на потерю, - это его влияние на следующие слои, и он делает это линейно, - единственные данные, которые вам нужны для вычислений градиентов весов на слое , а затем вы можете вычислить предыдущий слой
влияет на потерю, - это его влияние на следующие слои, и он делает это линейно, - единственные данные, которые вам нужны для вычислений градиентов весов на слое , а затем вы можете вычислить предыдущий слой  и повторить рекурсивно. Это позволяет избежать неэффективности двумя способами. Во-первых, это позволяет избежать дублирования, потому что при вычислении градиента на слое вам не нужно повторно вычислять все производные на более поздних слоях
и повторить рекурсивно. Это позволяет избежать неэффективности двумя способами. Во-первых, это позволяет избежать дублирования, потому что при вычислении градиента на слое вам не нужно повторно вычислять все производные на более поздних слоях  каждый раз. Во-вторых, он позволяет избежать ненужных промежуточных вычислений, потому что на каждом этапе он вычисляет градиент весов относительно конечного результата (потерь), а не без необходимости вычисляет производные значения скрытых слоев относительно изменений весов
каждый раз. Во-вторых, он позволяет избежать ненужных промежуточных вычислений, потому что на каждом этапе он вычисляет градиент весов относительно конечного результата (потерь), а не без необходимости вычисляет производные значения скрытых слоев относительно изменений весов  .
.
Обратное распространение может быть выражено для простых сетей прямого распространения в терминах матричное умножение, или, в более общем смысле, присоединенный граф.
Матричное умножение
Для базового случая прямой сети, где узлы на каждом уровне подключены только к узлам в ближайшем следующем слое (без пропуска каких-либо слоев), и есть функция потерь, вычисляет скалярные потери для окончательного вывода, обратное распространение можно понять как просто умножение матриц. По сути, обратное распространение оценивает выражение для каждого слоя в обратном направлении - с градиентом весов между слоем, имеющимся простым модификацией частичных произведений («ошибка, распространяющаяся в обратном направлении»). 429>
Для пары вход-выход  , потеря составляет:
, потеря составляет:

Чтобы вычислить это, один начинается с ввода и идет вперед; обозначим взвешенный ввод каждого слоя как  , а вывод слоя как активация
, а вывод слоя как активация  ошибки. Для обратного распространения активация , а также производные
ошибки. Для обратного распространения активация , а также производные  (оценивается как ) должен быть кэширован для использования во время обратного прохода.
(оценивается как ) должен быть кэширован для использования во время обратного прохода.
Производная цепная потеря по входам определяет правилаомочки; обратите внимание, что каждый член - это полная производная, вычисленная по значению сети (в каждом узле) на входе :

Этими членами: производственная функция потерь; производные функции активации; и матрицы весов:

Градиент  - это транспонировать производной вывода в терминах ввода, так что матрицы транспонируются и порядок умножения меняется на противоположный, но элементы остаются теми же:
- это транспонировать производной вывода в терминах ввода, так что матрицы транспонируются и порядок умножения меняется на противоположный, но элементы остаются теми же:

Обратное распространение в этом случае по существу, в оценке выражения этого справа налево (эквивалентно умножении выражения для производной направо слева), вычислении градиента на каждом слое на пути; есть дополнительный шаг, потому что градиент весов - это не просто подвыражение: есть дополнительное умножение.
Представляемую вспомогательную функцию для частичных произведений (умножение справа налево), интерпретируемую как «ошибка на уровне "и определяет как градиент входных значений на уровне :

Обратите внимание, что - это вектор, длина которого равна количеству узлов на уровне ; каждый термин интерпретируется как «стоимость, относящаяся к (значению) этого узла».
Градиент весов в слое тогда равенство:

Фактор  потому, что вес между уровнем и влиять на уровень пропорционально входам (активам): входы фиксированные, вес меняются.
потому, что вес между уровнем и влиять на уровень пропорционально входам (активам): входы фиксированные, вес меняются.
может быть легко вычислено рекурсивно как:

таким образом, градиенты весов могут быть вычислены с использованием нескольких матричных умножений для каждого уровня; это обратное распространение.
По сравнению с наивным расчетом вперед (с <использованием для иллюстрации):

есть два ключевых отличия от обратного распро странения:
- Вычисление через позволяет избежать очевидного дублирования слоев и выше.
- Умножение, начиная с ошибки
 - распространение в обратном направлении - означает, что каждый шаг просто умножает вектор () по матрицам весов
- распространение в обратном направлении - означает, что каждый шаг просто умножает вектор () по матрицам весов  и производные от активаций
и производные от активаций  . Напротив, умножение вперед, начиная с изменений на более раннем уровне, означает, что каждое умножение умножает матрицу на матрицу. Это намного дороже и соответствует отслеживанию всех путей изменений в одном слое вперед до изменений в слое
. Напротив, умножение вперед, начиная с изменений на более раннем уровне, означает, что каждое умножение умножает матрицу на матрицу. Это намного дороже и соответствует отслеживанию всех путей изменений в одном слое вперед до изменений в слое  (для умножения
(для умножения  на
на  , с дополнительными умножениями для производных активаций), который без необходимости вычисляет промежуточные величины того, как изменения веса на значения скрытых узлов.
, с дополнительными умножениями для производных активаций), который без необходимости вычисляет промежуточные величины того, как изменения веса на значения скрытых узлов.
Присоединенный граф
Для более общих графиков и других расширенных вариантов обратное распространение можно понять в терминах автоматического дифференцирования, где обратное распространение - это частный случай обратного накопления ( или «обратного режима»).
Интуиция
Мотивация
Цель любого алгоритма контролируемого обучения - найти функцию, которая наилучшим образом отображает набор входных данных на их правильный выход. Мотивация для обратного распространения - обучение многослойной нейронной сети таким образом, чтобы она могла изучить соответствующие внутренние представления, позволяющие изучить любое произвольное отображение ввода и вывода.
Обучение как задача оптимизации
Чтобы понять математический вывод алгоритма дальнейшего распространения, он сначала помогает развить некоторую интуицию о взаимосвязи между фактическим выходом нейрона и правильным выходом для конкретного обучающего примера. Рассмотрим простую нейронную сеть с двумя входными блоками, одним выходным блоком и без скрытых блоков, и в которой каждый нейрон использует линейный выход (в отличие от различных нейронных сетей, в которых отображаются входов в выходы не -линейный), который является взвешенной суммой его ввода.

Простая нейронная сеть с двумя входными блоками (каждый с одним входом) и одним выходным блоком (с двумя входами)
Первоначально, перед обучением, веса будут установлены случайным образом. Затем нейрон учится на обучающих примерах, в данном случае состоят из набора кортежей  где
где  и
и  - это входы в сеть, а t - правильный выход (выход, который должна выдавать с этими входами, когда она была обучена). Исходная сеть, заданная и , вычислит выход y который, вероятно, отличается от t (с учетом случайных весов). функция потерь
- это входы в сеть, а t - правильный выход (выход, который должна выдавать с этими входами, когда она была обучена). Исходная сеть, заданная и , вычислит выход y который, вероятно, отличается от t (с учетом случайных весов). функция потерь  используется для измерения несоответствия между целевым выходом t и вычисленным выходом y.. Для задач регрессионного рейтинга номер сообщения как функция потерь, для классификации может быть категориальная кроссэнтропия.
используется для измерения несоответствия между целевым выходом t и вычисленным выходом y.. Для задач регрессионного рейтинга номер сообщения как функция потерь, для классификации может быть категориальная кроссэнтропия.
В качестве примера рассмотрим задачу регрессии, используя квадратную ошибку как потерю:

где E - несоответствие или ошибка.
Рассмотрим сеть на одном примере примера:  . Таким образом, входные данные и равны 1 и 1 соответственно, а правильный выход, t равно 0. Теперь, если соотношение между выходом y сети по горизонтальной оси и ошибкой E по вертикальной оси, результатом будет парабола. минимум параболы соответствует выходному значению y, которое минимизирует ошибку E. Для обучающего случая минимум также касается горизонтальной оси, что означает, что ошибка будет равна выходной нулю и сеть может выдавать сигнал y, точно соответствующий целевому выходу t. Следовательно, проблема отображения входов в выходы может быть сведена к задаче оптимизации поиска функции, которая будет выполнять минимальную ошибку.
. Таким образом, входные данные и равны 1 и 1 соответственно, а правильный выход, t равно 0. Теперь, если соотношение между выходом y сети по горизонтальной оси и ошибкой E по вертикальной оси, результатом будет парабола. минимум параболы соответствует выходному значению y, которое минимизирует ошибку E. Для обучающего случая минимум также касается горизонтальной оси, что означает, что ошибка будет равна выходной нулю и сеть может выдавать сигнал y, точно соответствующий целевому выходу t. Следовательно, проблема отображения входов в выходы может быть сведена к задаче оптимизации поиска функции, которая будет выполнять минимальную ошибку.

Поверхность ошибок линейного нейрона для одного обучающего случая
Однако выход нейрона зависит от взвешенной суммы всех его входов:

где  и
и  - весовые коэффициенты на соединении модулей ввода к модулю вывод. Следовательно, ошибка также зависит от входящих в нейрон весов. Если каждый вес нанесен на отдельную горизонтальную ось, а ошибка - на вертикальную, результатом будет параболическая чаша. Для нейрона с k весами тот же график потребует эллиптического параболоида
- весовые коэффициенты на соединении модулей ввода к модулю вывод. Следовательно, ошибка также зависит от входящих в нейрон весов. Если каждый вес нанесен на отдельную горизонтальную ось, а ошибка - на вертикальную, результатом будет параболическая чаша. Для нейрона с k весами тот же график потребует эллиптического параболоида  измерений.
измерений.

Поверхностьлинейного нейрона с двумя входными весами
Одним из часто используемых алгоритмов для поиска набора весов, который минимизирует ошибку, градиентный спуск. Метод для расчета направления наискорейшего спуска используется обратное распространение.
Выведение
Метод градиентного спуска включает в себя вычисление производной функции потерь по весам сети. Обычно это делается с помощью обратного распространения ошибки. Предполагаемая, что один выходной нейрон, функция ошибки в квадрате равна

где
 - потеря для вывода и целевого значения
- потеря для вывода и целевого значения  ,
,- - целевой вывод для обучающей выборки, а
- - фактический вывод выходного нейрона.
Для каждого нейрона , его вывод  определяется как
определяется как

, где функция активации  является нелинейной и дифференцируемой (даже если ReLU не в одной точке). Исторически используемая функция активации является логистическая функция :
является нелинейной и дифференцируемой (даже если ReLU не в одной точке). Исторически используемая функция активации является логистическая функция :

который имеет удобную производную от:

Входные данные  к нейрону - это взвешенная сумма выходных сигналов
к нейрону - это взвешенная сумма выходных сигналов  предыдущих нейронов. Если нейрон находится в первом слое после входного, то входного слоя - это просто входы
предыдущих нейронов. Если нейрон находится в первом слое после входного, то входного слоя - это просто входы  в сети. Количество входных единиц нейрона составляет
в сети. Количество входных единиц нейрона составляет  . Переменная
. Переменная  обозначает вес между нейроном предыдущий слой и нейроном текущий слой.
обозначает вес между нейроном предыдущий слой и нейроном текущий слой.
Нахождение производной ошибки
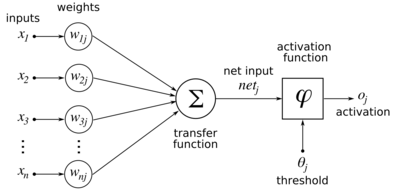
Схема искусственной нейронной сети для используемых здесь обозначений.
Вычисление частной производной ошибки по весу  выполнено с использованием цепного правила дважды:
выполнено с использованием цепного правила дважды:
 | | (Ур. 1) |
В последнем множителе правой части приведенного выше одного члена в сумме зависит от , так что
 | | (уравнение 2) |
Если нейрон находится в первом слое после входного,  просто
просто  .
.
Производная выход нейрона по отношению к его входу - это просто частная производная функция активации:
 | | (уравнение 3) |
что для случая логистической функции активации :

Это причина, по которой обратное распространение требует, чтобы функция активации была дифференцируемой. (Тем не менее, функция активации ReLU, которая недифференцируема в 0, стала довольно популярной, например, в AlexNet )
. Первый фактор легко оценить, находится ли нейрон в выходном слое, потому что тогда что тогда  и
и
 | | (уравнение 4) |
Если половина квадратной клетки используется как функция потерь, мы можем переписать это как

Однако, если находится на произвольном внутреннем уровне сети, нахождение производной с учетом менее очевидно.
Рассмотрение как функции с входными данными являются все нейроны  получение входных данных от нейрона ,
получение входных данных от нейрона ,

и взяв полную производную по , рекурсивный образуется выражение для производной:
 | | (Ур. 5) |
Следовательно, производная по может быть вычислена, если все производные по выходам  следующего слоя - те, что ближе к выходному нейрону - известны. [Обратите внимание: если какой-либо из нейронов в наборе не был подключен к нейрону , они были бы независимыми из и соответствующая частная производная при суммировании обращается в нуль до 0.]
следующего слоя - те, что ближе к выходному нейрону - известны. [Обратите внимание: если какой-либо из нейронов в наборе не был подключен к нейрону , они были бы независимыми из и соответствующая частная производная при суммировании обращается в нуль до 0.]
Подстановка Ур. 2, Ур. 3 уравнение 4 и уравнение. 5 в Ур. 1 получаем:


с

если - это логистическая функция, а ошибка - это квадратная ошибка:

Чтобы обновить вес с помощью градиентного спуска, один необходимо выбрать скорость обучения,  . Изменение веса отражать влияние на увеличение или уменьшение в . Если
. Изменение веса отражать влияние на увеличение или уменьшение в . Если  , увеличение увеличивает ; и наоборот, если
, увеличение увеличивает ; и наоборот, если  , увеличение уменьшает . Новый
, увеличение уменьшает . Новый  добавляется к старому весу и произведению скорости обучения и градиента, умноженному на
добавляется к старому весу и произведению скорости обучения и градиента, умноженному на  гарантирует, что изменяется так, что всегда уменьшается . Другими словами, в уравнении непосредственно ниже
гарантирует, что изменяется так, что всегда уменьшается . Другими словами, в уравнении непосредственно ниже  всегда изменяет таким образом, что уменьшается:
всегда изменяет таким образом, что уменьшается:

Функция потерь
Функция потерь - это функция, которая отображает значения одной или нескольких переменных на действительное число, интуитивно представляя некоторую «стоимость», связанную с этими значениями. Для обратного распространения функция потерь вычисляет разницу между выходными данными сети и ожидаемыми выходными данными после того, как обучающий пример распространился по сети.
Допущения
Математическое выражение функции потерь должно удовлетворять двум условиям, чтобы его можно было использовать при обратном распространении. Во-первых, его можно записать как среднее  над функциями ошибок
над функциями ошибок  , для
, для  отдельных примеров обучения,
отдельных примеров обучения,  . Причина этого предположения заключается в том, что алгоритм обратного распространения ошибки вычисляет градиент функции ошибок для одного обучающего примера, который необходимо обобщить на общую функцию ошибок. Второе предположение состоит в том, что его можно записать как функцию выходных данных нейронной сети.
. Причина этого предположения заключается в том, что алгоритм обратного распространения ошибки вычисляет градиент функции ошибок для одного обучающего примера, который необходимо обобщить на общую функцию ошибок. Второе предположение состоит в том, что его можно записать как функцию выходных данных нейронной сети.
Пример функции потерь
Пусть  будут векторами в
будут векторами в  .
.
Выберите функцию ошибки  , измеряющую разницу между двумя выходными данными. Стандартный выбор - квадрат евклидова расстояния между векторами и
, измеряющую разницу между двумя выходными данными. Стандартный выбор - квадрат евклидова расстояния между векторами и  :
:

Функция ошибок для
обучающих примеров может быть записана как среднее значение потерь для отдельных примеров:

Ограничения

Градиентный спуск может найти локальный минимум вместо глобального минимума.
- Градиентный спуск с обратным распространением не гарантирует нахождение глобального минимума функции ошибок, но только местный минимум; Кроме того, у него есть проблемы с переходом плато в ландшафте функции ошибок. Эта проблема, вызванная невыпуклостью функций ошибок в нейронных сетях, долгое время считалась серьезным недостатком, но Янн ЛеКун и др. утверждают, что во многих практических задачах это не так.
- Обучение с обратным распространением не требует нормализации входных векторов; однако нормализация может улучшить производительность.
- Обратное распространение требует, чтобы производные функции активации были известны во время проектирования сети.
История
Был объявлен термин обратное распространение и его общее использование в нейронных сетях в Rumelhart, Hinton Williams (1986a), затем развита и популяризирована в Rumelhart, Hinton Williams (1986b), но метод был повторно открыт независимо много раз, и многие предшественники датировали его к 1960-м годам.
Основы непрерывного обратного распространения ошибки были получены в контексте теории управления Генри Дж. Келли в 1960 году и Артуром Э. Брайсона в 1961 г. Они использовали принципы динамического программирования. В 1962 году Стюарт Дрейфус опубликовал более простой вывод, основанный только на правиле цепочки. Брайсон и Хо описали его как многоступенчатый метод оптимизации динамической системы в 1969 году. Обратное распространение ошибок было получено исследователями в начале 60-х годов и реализовано для работы на компьютере еще в 1970 году Сеппо Линнаинмаа. Пол Вербос был первым в США. предположить, что его можно использовать для нейронных сетей, после его глубокого анализа в своей диссертации 1974 года. Хотя это и не применяется к нейронным сетям, в 1970 году Линнаинмаа опубликовал общий метод автоматического дифференцирования (AD). Хотя это вызывает споры, некоторые ученые, что на самом деле это первый шаг к разработке алгоритма обратного распространения. В 1973 году Дрейфус адаптирует параметры контроллеров пропорционально градиентам ошибок. В 1974 году Вербос показал возможность применения этого принципа к искусственным нейронным сетям, а в 1982 году он применил AD-метод Линнаинмаа к нелинейным функциям.
Позже метод Вербоса был переоткрыт и описан в 1985 году Паркером, в 1986 году - Рамельхарт, Хинтон и Уильямс. Ром Элхарт, Хинтон и Уильямс экспериментально показали, что метод может генерировать полезные внутренние представления данных в скрытых слоях нейронных сетей. Янн ЛеКун, изобретатель сверточной нейронной сети, современную форму обратной связи. алгоритм обученияронных сетей в своей докторской диссертации в 1987 году. В 1993 году Эрик Ван выиграл международный по распознаванию образов с помощью обратного распространения. дешевые, мощные вычислительные системы на базе GPU. Это особенно заметно в исследованиях распознавания речи, машинного зрения, обработки естественного языка и изучение языковых структур, которые они использовались для объяснения множества явлений, связанных с изучением первого и второго языков.).
Обратное распространение ошибок было предложено для объяснения компонентов человеческого мозга ERP, таких как N400 и P600.
См. Также
Примечания
Ссылки
Дополнительная литература
Внешние ссылки

 Простая нейронная сеть с двумя входными блоками (каждый с одним входом) и одним выходным блоком (с двумя входами)
Простая нейронная сеть с двумя входными блоками (каждый с одним входом) и одним выходным блоком (с двумя входами)  Поверхность ошибок линейного нейрона для одного обучающего случая
Поверхность ошибок линейного нейрона для одного обучающего случая  Поверхностьлинейного нейрона с двумя входными весами
Поверхностьлинейного нейрона с двумя входными весами  Схема искусственной нейронной сети для используемых здесь обозначений.
Схема искусственной нейронной сети для используемых здесь обозначений.  Градиентный спуск может найти локальный минимум вместо глобального минимума.
Градиентный спуск может найти локальный минимум вместо глобального минимума.