
Войти
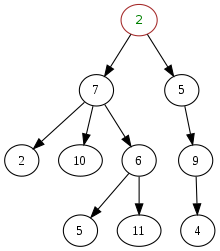 Общий и т. Д. небинарный, несортированный, некоторые метки дублируются, произвольная диаграмма дерева. На этой диаграмме узел с меткой 7 имеет трех дочерних узлов с метками 2, 10 и 6 и одного родителя с меткой 2. Корневой узел наверху не имеет родителя.
Общий и т. Д. небинарный, несортированный, некоторые метки дублируются, произвольная диаграмма дерева. На этой диаграмме узел с меткой 7 имеет трех дочерних узлов с метками 2, 10 и 6 и одного родителя с меткой 2. Корневой узел наверху не имеет родителя. В информатике, дерево - это широко используемый абстрактный тип данных, который имитирует иерархическую древовидную структуру , с корневым значением и поддеревьями дочерних элементов с родительским узлом, представленный как набор связанных узлов.
Древовидная структура данных может быть определена рекурсивно как набор узлов (начиная с корневого узла), где каждый узел является данными структура, состоящая из значения вместе со списком ссылок на узлы («потомки»), с ограничениями, что никакие ссылки не дублируются и ни одна не указывает на корень.
В качестве альтернативы дерево может быть определено абстрактно как целое (глобально) как упорядоченное дерево, со значением, присвоенным каждому узлу. Обе эти точки зрения полезны: в то время как дерево может быть проанализировано математически в целом, когда оно фактически представлено в виде структуры данных, оно обычно представляется и обрабатывается отдельно по узлам (а не как набор узлов и список смежности ребер между узлами, так как можно представить, например, орграф). Например, глядя на дерево в целом, можно говорить о «родительском узле» данного узла, но в целом как структура данных данный узел содержит только список своих дочерних узлов, но не содержит ссылки на его родитель (если есть).
A узел - это структура, которая может содержать значение или условие или представлять отдельную структуру данных (которая может быть собственным деревом). Каждый узел в дереве имеет ноль или более дочерних узлов, которые находятся под ним в дереве (по соглашению деревья рисуются растущими вниз). Узел, у которого есть дочерний узел, называется дочерним родительским узлом (или вышестоящим ). Узел имеет не более одного родителя, но возможно много узлов-предков, таких как родительский родитель. Дочерние узлы с одним и тем же родителем - это дочерние узлы .
Внутренний узел (также известный как внутренний узел, inode для краткости или узел ветви ) - любой узел дерева, имеющий дочерние узлы. Аналогично, внешний узел (также известный как внешний узел, листовой узел или конечный узел ) - это любой узел, который не есть дочерние узлы.
Самый верхний узел в дереве называется корневым узлом . В зависимости от определения может потребоваться, чтобы у дерева был корневой узел (в этом случае все деревья непустые), или может быть разрешено быть пустым, и в этом случае оно не обязательно имеет корневой узел. Будучи самым верхним узлом, корневой узел не будет иметь родителя. Это узел, с которого начинаются алгоритмы в дереве, поскольку в качестве структуры данных можно переходить только от родителей к потомкам. Обратите внимание, что некоторые алгоритмы (например, поиск в глубину после упорядочения) начинаются с корня, но сначала посещают конечные узлы (получают доступ к значению конечных узлов), посещают только корень последним (т. Е. Сначала обращаются к дочерним элементам корня)., но доступ только к значению корня последним). Все остальные узлы могут быть доступны из него, следуя ребрам или ссылкам . (В формальном определении каждый такой путь также уникален.) На диаграммах корневой узел обычно рисуется вверху. В некоторых деревьях, таких как heaps, корневой узел имеет особые свойства. Каждый узел в дереве можно рассматривать как корневой узел поддерева, укорененного в этом узле.
высота узла - это длина самого длинного нисходящего пути к листу от этого узла. Высота корня - это высота дерева. глубина узла - это длина пути к его корню (то есть его корневой путь). Это обычно необходимо при манипулировании различными самобалансирующимися деревьями, в частности деревьями AVL. Корневой узел имеет нулевую глубину, листовые узлы имеют нулевую высоту, а дерево только с одним узлом (следовательно, и корнем, и листом) имеет нулевую глубину и высоту. Обычно пустое дерево (дерево без узлов, если таковые разрешены) имеет высоту -1.
A поддерево дерева T - это дерево, состоящее из узла в T и всех его потомков в T. Таким образом, узлы соответствуют поддеревьям (каждый узел соответствует своему поддереву и всем его потомкам) - поддереву корневому узлу соответствует все дерево, и каждый узел является корневым узлом поддерева, которое он определяет; поддерево, соответствующее любому другому узлу, называется надлежащим поддеревом (по аналогии с надлежащим подмножеством ).
Другие термины, используемые с деревьями:
 Не дерево: две не связанных части, A → B и C → D → E. Существует более одного корня.
Не дерево: две не связанных части, A → B и C → D → E. Существует более одного корня.  Не дерево: цикл A → A. A является корнем, но у него также есть родитель.
Не дерево: цикл A → A. A является корнем, но у него также есть родитель.  Каждый линейный список - это тривиально дерево.
Каждый линейный список - это тривиально дерево. Дерево - это нелинейная структура данных по сравнению с массивами, связанными списками, стеками и очередями, которые являются линейными структурами данных. Дерево может быть пустым без узлов или дерево представляет собой структуру, состоящую из одного узла, называемого корнем, и нуля или одного или нескольких поддеревьев.
Деревья часто рисуются на плоскости. Упорядоченные деревья могут быть представлены по существу однозначно на плоскости и поэтому называются плоскими деревьями следующим образом: если зафиксировать обычный порядок (скажем, против часовой стрелки) и расположить дочерние узлы в этом порядке (сначала входящее родительское ребро, затем первое дочернее ребро и т. д.), это дает вложение дерева в плоскость, уникальное с точностью до внешней изотопии. И наоборот, такое вложение определяет порядок дочерних узлов.
Если поместить корень вверху (родители над детьми, как в генеалогическом дереве ) и разместить все узлы, которые находятся на заданном расстоянии от корня (с точки зрения количества ребер : «уровень» дерева) на заданной горизонтальной линии получается стандартный рисунок дерева. Для двоичного дерева первый дочерний элемент находится слева («левый узел»), а второй дочерний элемент - справа («правый узел»).
Переход по элементам дерева с помощью соединений между родителями и детьми называется хождение по дереву, а действие - хождение по дереву. Часто операция может выполняться, когда указатель достигает определенного узла. Обход, при котором каждый родительский узел проходит до его дочерних узлов, называется переходом предварительного заказа ; прогулка, при которой дети проходят путь до того, как пройдут их соответствующие родители, называется прогулкой после заказа ; обход левого поддерева узла, затем самого узла и, наконец, его правого поддерева, называется обходом по порядку . (Этот последний сценарий, относящийся к ровно двум поддеревьям, левому поддереву и правому поддереву, предполагает, в частности, двоичное дерево .) Обход уровня-порядка эффективно выполняет ширину -первый поиск по всему дереву; узлы проходят уровень за уровнем, где сначала посещается корневой узел, за ним следуют его прямые дочерние узлы и их братья и сестры, за ними следуют его внучатые узлы и их братья и сестры, и т. д., пока не будут пройдены все узлы в дереве.
Есть много разных способов представления деревьев; общие представления представляют узлы как динамически выделяемые записи с указателями на их дочерние элементы, их родителей или и то, и другое, или как элементы в массиве , причем отношения между ними определяются их положением в массив (например, двоичная куча ).
Действительно, двоичное дерево может быть реализовано как список списков (список, значения которого являются списками): заголовок списка (значение первого члена) является левым дочерним элементом (поддеревом), в то время как хвост (список второго и последующих терминов) является правым потомком (поддеревом). Это также можно изменить, чтобы разрешить значения, как в Лиспе S-выражений, где голова (значение первого члена) - это значение узла, голова хвоста (значение второго члена) является левым дочерним элементом, а хвостовая часть (список из третьего и последующих членов) является правым дочерним элементом.
Как правило, узел в дереве не имеет указателей на своих родителей, но эта информация может быть включена (расширена структура данных, чтобы также включить указатель на родительский элемент) или сохранена отдельно. В качестве альтернативы, восходящие ссылки могут быть включены в данные дочернего узла, как в многопоточном двоичном дереве.
Если ребра (к дочерним узлам) рассматриваются как ссылок, тогда дерево является частным случаем орграфа, и древовидная структура данных может быть обобщена для представления ориентированных графов, удалив ограничения, согласно которым узел может иметь не более одного родителя и что циклы отсутствуют. разрешается. Ребра по-прежнему абстрактно рассматриваются как пары узлов, однако термины родительский и дочерний обычно заменяются другой терминологией (например, источник и цель). Существуют разные стратегии реализации : орграф может быть представлен той же локальной структурой данных, что и дерево (узел со значением и список дочерних элементов), при условии, что «список дочерних элементов» является списком ссылок, или глобально такими структурами, как списки смежности.
В теории графов, дерево является связным ациклическим графом ; если не указано иное, в теории графов деревья и графы считаются неориентированными. Между такими деревьями и деревьями, как структура данных, нет однозначного соответствия. Мы можем взять произвольное неориентированное дерево, произвольно выбрать одну из его вершин в качестве корня, сделать все его ребра направленными, заставив их указывать от корневого узла - создавая древообразование - и назначить порядок всем узлам. Результат соответствует древовидной структуре данных. Выбор другого корня или другой порядок приводит к другому.
Для данного узла в дереве его дочерние элементы определяют упорядоченный лес (объединение поддеревьев, заданных всеми дочерними элементами, или, что эквивалентно, взятие поддерева, данное самим узлом, и стирание корня). Так же, как поддеревья естественны для рекурсии (как при поиске в глубину), леса естественны для corecursion (как при поиске в ширину).
С помощью взаимной рекурсии лес можно определить как список деревьев (представленных корневыми узлами), где узел (дерева) состоит из значения и леса (его children):
f: [n [1],..., n [k]] n: vf
Есть различие между деревом как абстрактным типом данных и конкретной структурой данных, аналогично различию между списком и связанным списком.
В качестве типа данных дерево имеет значение и дочерние элементы, и дети сами деревья; значение и дочерние элементы дерева интерпретируются как значение корневого узла и поддеревьев дочерних элементов корневого узла. Чтобы разрешить конечные деревья, нужно либо разрешить список дочерних элементов быть пустым (в этом случае деревья могут быть непустыми, а «пустое дерево» вместо этого будет представлено лесом из нулевых деревьев), либо разрешить деревьям быть пустым, и в этом случае список дочерних элементов может иметь фиксированный размер (коэффициент ветвления, особенно 2 или «двоичный»), если желательно.
В качестве структуры данных связанное дерево представляет собой группу из узлов, где каждый узел имеет значение и список из ссылок на другие узлы (его дочерние элементы). Также существует требование, чтобы никакие две «нисходящие» ссылки не указывали на один и тот же узел. На практике узлы в дереве обычно включают в себя и другие данные, такие как следующие / предыдущие ссылки, ссылки на их родительские узлы или почти что угодно.
Из-за использования ссылок на деревья в структуре данных связанного дерева деревья часто обсуждаются неявно, предполагая, что они представлены ссылками на корневой узел, поскольку часто именно так они реализуются. Например, вместо пустого дерева может быть пустая ссылка: дерево всегда непусто, но ссылка на дерево может быть пустой.
Рекурсивно, как тип данных, дерево определяется как значение (некоторого типа данных, возможно, пустое) вместе со списком деревьев (возможно, пустой список), поддеревья его потомков; символически:
(Дерево t состоит из значения v и списка других деревьев.)
Подробнее элегантно, с помощью взаимной рекурсии, одним из основных примеров которой является дерево, дерево может быть определено в терминах леса (списка деревьев), где дерево состоит из значения и леса (поддеревья его потомков):
Обратите внимание, что это определение дано в терминах значений, и подходит для функциональных языков (предполагает ссылочную прозрачность ); разные деревья не имеют связей, поскольку представляют собой просто списки значений.
В качестве структуры данных дерево определяется как узел (корень), который сам состоит из значения (некоторого типа данных, возможно, пустого) вместе со списком ссылок на другие узлы (список возможно пусто, возможно ссылки пустые); символически:
(Узел n состоит из значения v и списка ссылок на другие узлы.)
Эта структура данных определяет ориентированный граф, и чтобы он был деревом, необходимо добавить условие к его глобальной структуре (его топологии), а именно, что не более одной ссылки может указывать на любой заданный узел (узел имеет не более одного parent), и ни один узел в дереве не указывает на корень. Фактически, каждый узел (кроме корневого) должен иметь ровно одного родителя, а у корня не должно быть родителей.
Действительно, учитывая список узлов и для каждого узла список ссылок на его дочерние элементы, нельзя сказать, является ли эта структура деревом или нет, не проанализировав ее глобальную структуру и что она на самом деле топологически является дерево, как определено ниже.
В качестве абстрактного типа данных определяется тип абстрактного дерева T со значениями некоторого типа E с использованием типа абстрактного леса F (список деревьев), функциями:
с аксиомами:
С точки зрения теории типов, дерево - это индуктивный тип, определяемый конструкторами nil (пустой лес) и node (дерево с корневым узлом с заданным значением и дочерними элементами).
В целом древовидная структура данных представляет собой упорядоченное дерево, обычно со значениями, прикрепленными к каждому узлу. В частности, это (если требуется, чтобы оно было непустым):
вместе с:
Часто деревья имеют фиксированный (точнее, ограниченный) коэффициент ветвления (outdegree ), особенно всегда с двумя дочерними узлами (возможно, пустыми, следовательно, не более двух непустых дочерних узлов), следовательно, «двоичное дерево».
Разрешение пустых деревьев делает некоторые определения более простыми, некоторые - более сложными: корневое дерево должно быть непустым, поэтому, если пустые деревья разрешены, приведенное выше определение вместо этого становится «пустым деревом или корневым деревом, такое что... ". С другой стороны, пустые деревья упрощают определение фиксированного коэффициента ветвления: с разрешенными пустыми деревьями двоичное дерево - это дерево, в котором каждый узел имеет ровно два дочерних элемента, каждый из которых является деревом (возможно, пустым). Полный набор операций с деревом должен включать операцию разветвления.
Математически неупорядоченное дерево (или "алгебраическое дерево") может быть определено как алгебраическая структура (X, parent), где X - непустой несущий набор узлов, а parent - функция на X, которая назначает каждому узлу x его «родительский» узел, parent (x). Структура подчиняется условию, что каждая непустая подалгебра должна иметь одинаковую фиксированную точку. То есть должен быть уникальный «корневой» узел r, такой, что parent (r) = r, и для каждого узла x некоторый родительский элемент итеративного приложения (parent (⋯ parent (x) ⋯)) равен r.
Есть несколько эквивалентных определений.
В качестве ближайшей альтернативы можно определить неупорядоченные деревья как частичные алгебры (X, родительские), которые получаются из полных алгебр, описанных выше, если родительский элемент (r) не определен. То есть корень r является единственным узлом, на котором родительская функция не определена, и для каждого узла x корень достижим из x в ориентированном графе (X, parent). Это определение фактически совпадает с определением антидревесценции. В книге TAoCP используется термин ориентированное дерево.
| Неупорядоченное дерево - это структура (X, ≺), где X - это набор узлов, а ≺ - отношение между дочерними и родительскими узлами, такое что : | |
| (1) | X не пусто. |
|---|---|
| (2) | X слабо связан в ≺. |
| (3) | ≺ является функциональным. |
| (4) | ≺ удовлетворяет ACC : нет бесконечной последовательности x 1 ≺ x 2 ≺ x 3 ≺ ⋯. |
Поле справа описывает частичную алгебру (X, родительскую) как реляционную структуру (X, ≺). Если (1) заменяется на
тогда условие (2) становится избыточным.
Используя это определение, можно предоставить специальную терминологию для обобщений неупорядоченных деревьев, которые соответствуют выделенным подмножествам перечисленных условий:
Другое эквивалентное определение неупорядоченного дерева - это определение теоретико-множественное дерево, которое является однокорневым и имеет высоту не более ω ("конечное" дерево). То есть алгебраические структуры (X, родительский) эквивалентны частичным порядкам (X, ≤), которые имеют верхний элемент r и каждый главный нарушает (также известный как главный фильтр ) - это конечная цепочка . Чтобы быть точным, мы должны говорить об обратном теоретико-множественном дереве, поскольку теоретико-множественное определение обычно использует противоположный порядок.
Соответствие между (X, parent) и (X, ≤) устанавливается через рефлексивное транзитивное замыкание / сокращение, при этом сокращение приводит к "частичному" версия без корневого цикла.
Определение деревьев в теории дескриптивных множеств (DST) использует представление частичных порядков (X, ≥) в виде префиксов порядков между конечными последовательностями. Оказывается, что до изоморфизма существует взаимно однозначное соответствие между (обратным) деревьями DST и древовидными структурами, определенными до сих пор.
Мы можем обратиться к четырем эквивалентным характеристикам дерева как алгебры, дерева как частичной алгебры, дерева как частичного порядка и дерева как префиксного порядка. Существует также пятое эквивалентное определение - корневое дерево с теоретико-графами, которое является просто связным ациклическим корневым графом.
Выражение деревьев как (частичных) алгебр (также называемых функциональные графы ) (X, родительский) непосредственно следует за реализацией древовидных структур с использованием родительских указателей. Обычно используется частичная версия, в которой корневой узел не имеет определенного родителя. Однако в некоторых реализациях или моделях устанавливается даже родительская (r) = r цикличность. Примечательные примеры:
из объекта -ориентированное программирование. В этом случае корневой узел - это верхний метакласс - единственный класс, который является прямым экземпляром самого себя.
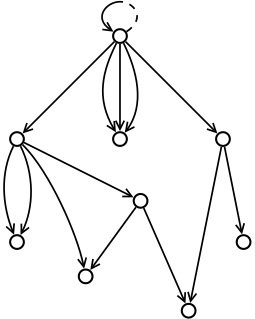
Обратите внимание, что приведенное выше определение допускает бесконечные деревья. Это позволяет описывать бесконечные структуры, поддерживаемые некоторыми реализациями, с помощью ленивого вычисления. Ярким примером является бесконечная регрессия собственных классов из объектной модели Ruby. В этой модели дерево, установленное с помощью связей суперклассамежду нетерминальными объектами, является бесконечным и имеет бесконечную ветвь (единственная бесконечная ветвь «спиральных» объектов - см. Диаграмму ).
В каждом неупорядоченном дереве (X, родительский) есть выделенное разделение множества X узлов на одноуровневые наборы. Два некорневых узла x, y принадлежат одному набору братьев и сестер, если parent (x) = parent (y). Корневой узел r формирует одноэлементный одноуровневый набор {r}. Дерево называется локально конечным или конечно ветвящимся, если каждое из его родственных множеств конечно.
Каждая пара отдельных братьев и сестер несравнима в ≤. Вот почему в определении используется слово «неупорядоченный». Такая терминология может ввести в заблуждение, когда все одноуровневые множества являются одиночными, т.е. когда множество X всех узлов полностью упорядочено (и, следовательно, хорошо упорядочено ) на ≤ В таком случае мы мог бы вместо этого говорить об одинарном ветвящемся дереве.
Как и любой частично упорядоченный набор, древовидные структуры (X, ≤) могут быть представлены порядком включения - системами множеств, в котором ≤ совпадает с ⊆, индуцированный порядок включения. Рассмотрим структуру (U, ℱ), такую, что U - непустое множество, а ℱ - набор подмножеств U, такой, что выполняются следующие условия (согласно определению Nested Set Collection ):
Тогда структура (ℱ, ⊆) является неупорядоченным деревом корень которого равен U. Наоборот, если (U, ≤) - неупорядоченное дерево, а ℱ - множество {↓ x | x ∈ U} всех главных идеалов дерева (U, ≤), то множество system (U, ℱ) удовлетворяет указанным выше свойствам.
 Дерево как ламинарная система множеств (скопировано из Модель вложенных множеств )
Дерево как ламинарная система множеств (скопировано из Модель вложенных множеств )Представление древовидной структуры системы множеств обеспечивает семантическую модель по умолчанию - в большинстве случаев В большинстве случаев древовидные структуры данных представляют собой иерархию включения. Это также предлагает обоснование для направления порядка с корнем наверху: корневой узел является большим контейнером, чем любой другой узел. Известные примеры:
неупорядоченное дерево (X, ≤) является обоснованным, если строгое частичное упорядочение < is a является обоснованным отношением. В частности, каждое конечное дерево хорошо обосновано. Принимая аксиому зависимого выбора, дерево является хорошо обоснованным тогда и только тогда, когда у него нет бесконечной ветви.
Хорошо обоснованные деревья могут быть определены рекурсивно - путем формирования деревьев из несвязного объединения меньших деревьев. Для точного определения предположим, что X - это набор узлов. Используя рефлексивность частичных порядков, мы можем идентифицировать любое дерево (Y, ≤) на подмножестве X с его частичным порядком (≤) - подмножеством X × X. Множество ℛ всех отношений R которые образуют хорошо обоснованное дерево (Y, R) на подмножестве Y в X, определяется на этапах ℛ i, так что ℛ = ⋃ {ℛ i | i - порядковый номер}. Для каждого порядкового номера i пусть R принадлежит i-й ступени ℛ i тогда и только тогда, когда R равно
где ℱ - подмножество ⋃ {ℛ k | k < i} such that elements of ℱ are pairwise disjoint, and x is a node that does not belong to dom(⋃ℱ). (We use dom(S) to denote the домен отношения S.) Обратите внимание, что нижний этап ℛ 0 состоит из одноузловых деревьев {(x, x)}, поскольку возможен только пустой. На каждом этапе (возможно) новые деревья R строятся путем взятия леса ⋃ℱ с компонентами ℱ из нижних этапов и присоединения нового корня x к вершине ⋃ℱ.
В отличие от высоты дерева, которая не превышает ω, ранг хорошо обоснованных деревьев неограничен, см. Свойства «разворачивания ».
В вычислениях общий способ определения хорошо обоснованных деревьев - через рекурсивные упорядоченные пары (F, x): дерево - это лес F вместе с «свежим» узел x. Лес F, в свою очередь, представляет собой возможно пустое множество деревьев с попарно непересекающимися множествами узлов. Чтобы получить точное определение, действуйте так же, как при построении имен, используемых в теоретико-множественной технике принуждения. Пусть X - набор узлов. В надстройке над X определите наборы T, ℱ деревьев и лесов, соответственно, и узлы карты: T → ℘ (X), назначив каждому дереву t его базовый набор узлов так, чтобы:
| (деревья над X) | t ∈ T | ↔ | t - пара (F, x) из ℱ × X такая, что для всех s ∈ F,. x ∉ узлов (s), | |
| (леса над X) | F ∈ ℱ | ↔ | F - подмножество T такое, что для любых s, t ∈ F, s ≠ t,. node (s) ∩ nodes (t) = ∅}}, | |
| (узлы деревьев) | y ∈ node (t) | ↔ | t = (F, x) ∈ T и. либо y = x, либо y ∈ node (s) для некоторого s ∈ F}}. |
Окружности в приведенных выше условиях могут быть устранены путем разделения каждого из T, ℱ и узлов на этапы, как в предыдущем подразделе. Затем определим отношение «поддерево» ≤ на T как рефлексивное транзитивное замыкание отношения «непосредственное поддерево» ≺, определенного между деревьями как
| s ≺ t | ↔ | s ∈ π 1 (t) |
, где π 1 (t) - проекция t на первую координату; т.е. это лес F такой, что t = (F, x) для некоторого x ∈ X. Можно заметить, что (T, ≤) является многодеревом : для любого t ∈ T главное идеал ↓ t, упорядоченный по ≤, является хорошо обоснованным деревом как частичный порядок. Более того, для каждого дерева t ∈ T его структура порядка «узлов» (nodes (t), ≤ t) задается как x ≤ t y тогда и только тогда, когда есть леса F, G ∈ ℱ такие, что и (F, x), и (G, y) являются поддеревьями t и (F, x) ≤ (G, y).
Другая формализация, а также обобщение неупорядоченных деревьев может быть получена путем повторения пар узлов «родитель-потомок». Каждую такую упорядоченную пару можно рассматривать как абстрактную сущность - «стрелку». Это приводит к созданию мультидиграфа (X, A, s, t), где X - набор узлов, A - набор стрелок, а s и t - функции от A до X, назначающие каждой стрелке ее источник. и цель соответственно. Структура подчиняется следующим условиям:
В (1) символ композиции ○ должен интерпретироваться слева направо. Условие говорит, что обратная последовательность стрелок - это полная карта от дочернего к родительскому. Обозначим эту родительскую карту между стрелками p, т.е. p = s ○ t. Тогда у нас также есть s = p ○ t, поэтому мультииграф, удовлетворяющий (1,2), также может быть аксиоматизирован как (X, A, p, t) с родительским отображением p вместо s в качестве определяющей составляющей. Обратите внимание, что корневая стрелка обязательно представляет собой петлю, т.е. ее источник и цель совпадают.
Важное обобщение вышеупомянутой структуры достигается путем разрешения целевой карте t быть «многие к одному». Это означает, что (2) ослабляется до
Обратите внимание, что условие (1) утверждает, что только лист стрелы могут иметь одну и ту же цель. То есть, ограничение t на диапазон p по-прежнему инъективное.
Мультидиграфы, удовлетворяющие (1,2 '), можно назвать "деревьями стрелок" - их характеристики дерева накладываются на стрелки, а не на узлы. Эти структуры можно рассматривать как наиболее существенную абстракцию Linux VFS, поскольку они отражают жесткую структуру файловых систем. Узлы называются inodes, стрелки - dentries (или жесткими ссылками ). Родительская и целевая карты p и t соответственно представлены полями d_parentи d_inodeв структуре данных dentry. Каждому inode назначается фиксированный тип файла, из которых тип directory играет особую роль «спроектированных родителей»:
Использование пунктирного стиля для первой половины корневого цикла указывает на то, что, как и в родительской карте, существует частичная версия для исходной карты в источник корневой стрелки не определен. Этот вариант используется для дальнейшего обобщения, см. # Использование путей в мультидиграфе.
Неупорядоченные деревья естественным образом возникают при «разворачивании» доступных точечных графов.
Пусть ℛ = (X, R, r) - указанная реляционная структура, то есть такая, что X - это набор узлов, R - отношение между узлами (подмножество X × X), а r - выделенный «корневой» узел.. Предположим далее, что ℛ доступно, что означает, что X равно прообразу {r} при рефлексивном транзитивном замыкании R, и назовем такую структуру доступным точечным графом или apg для краткости. () Тогда можно вывести другой apg ℛ '= (X', R ', r') - развертывание ℛ - следующим образом:
Очевидно, структура (X', R ') представляет собой неупорядоченное дерево в" частичном -алгебра »версия: R 'является частичным отображением, которое связывает каждый некорневой элемент X' с его родителем путем выталкивания пути. Корневой элемент, очевидно, r '. Более того, выполняются следующие свойства:
Примечания:
Как показано на экзамене Из-за жестко связанной структуры файловых систем многие структуры данных в вычислениях допускают множественные связи между узлами. Следовательно, чтобы правильно отобразить появление неупорядоченных деревьев среди структур данных, необходимо обобщить доступные точечные графы для настройки нескольких графов. Чтобы упростить терминологию, мы используем термин колчан, который является установленным синонимом слова «мультидиграф».

Пусть доступный остроконечный колчан или для краткости apq определяется как структура
, где
Таким образом, ℳ - это «частичный мультиграф».
Структура подчиняется следующим условиям:
ℳ называется деревом, если целевая карта t является взаимно однозначной связью между стрелками и узлами. Разворачивание формируется последовательностями, упомянутыми в (2), которые являются путями доступности (см. Алгебра путей ). В качестве apq развертывание можно записать как
, где
Как и в случае с apgs, разворачивание идемпотентно и всегда приводит в дереве.
Базовый apg получается как структура
, где
На диаграмме выше показан пример apq со стрелками 1 + 14. В JavaScript, Python или Ruby, структура может быть создана с помощью следующего (точно такого же) кода:
r = {}; r [1] = {}; r [2] = r [1]; r [3] = {}; r [4] = {}; r [1] [5] = {}; r [1] [14] = r [1] [5]; r [3] [7] " = {}; r [3] [8] = r [3] [7]; r [3] [13] = {}; r [4] [9] = r [4]; r [4] [10 ] = r [4]; r [4] [11] = {}; r [3] [7] [6] = r [3]; r [3] [7] [12] = r [1] [ 5];Неупорядоченные деревья и их обобщения составляют суть систем именования. Есть два ярких примера систем именования: файловые системы и (вложенные) ассоциативные массивы. Структуры на основе нескольких графов из предыдущих подразделов обеспечивали анонимные абстракции для обоих случаев. Чтобы получить возможность именования, стрелки должны быть снабжены именами как идентификаторы. Имя должно быть локально уникален - внутри каждого родственного набора стрелок может быть не более одной стрелки с указанным именем.
источник | имя | цель |
|---|---|---|
| s (a) | σ (a) | t (a) |
Это можно формализовать как структуру
где
Для стрелки a составляющими тройки (s (a), σ (a), t (a)) являются соответственно источник, имя и цель a. Структура подчиняется следующим условиям:
Эту структуру можно назвать вложенным словарем или apq. В вычислительной технике такие структуры встречаются повсеместно. Приведенная выше таблица показывает, что стрелки можно рассматривать как «невещественные» как множество A '= {(s (a), σ (a), t (a)) | a ∈ A \ {a r }} троек источник-имя-цель. Это приводит к реляционной структуре (X, Σ, A '), которую можно рассматривать как таблицу реляционной базы данных. Подчеркивание в источникеи имениуказывает первичный ключ.
. Структуру можно перефразировать как детерминированную помеченную систему перехода : X - это набор " состояния », Σ - это набор« меток », A '- набор« помеченных переходов ». (Более того, корневой узел r = t (a r) является «начальным состоянием», а условие доступности означает, что каждое состояние достижимо из начального состояния.)

На диаграмме справа показан вложенный словарь ℰ, который имеет тот же базовый мультидиграф, что и в примере в предыдущем подразделе. Структура может быть создана с помощью кода ниже. Как и раньше, точно такой же код применяется для JavaScript, Python и Ruby.
Во-первых, субструктура, ℰ 0, создается путем однократного присвоения литерала {...}до r. Эта структура, изображенная сплошными линиями, представляет собой «дерево стрелок » (следовательно, это остовное дерево ). Литерал, в свою очередь, представляет собой сериализацию JSON для ℰ 0.
. Затем оставшиеся стрелки создаются путем присвоения уже существующих узлов. Стрелки, вызывающие циклы, отображаются синим цветом.
r = {"a": {"a": 5, "b": 5}, "c": {"a": {"w": 5}, "c": {}}, " d ": {" w ": 1.3}} r [" b "] = r [" a "]; r ["c"] ["b"] = r ["c"] ["a"] r ["c"] ["a"] ["p"] = r ["c"]; r ["d"] ["e"] = r ["d"] ["self"] = r ["d"]В Linux VFS функция имени σ представлена d_name Полев структуре данных dentry. Приведенная выше структура ℰ 0 демонстрирует соответствие между JSON-представляемыми структурами и жестко связанными структурами файловых систем. В обоих случаях существует фиксированный набор встроенных типов «узлов», один из которых является типом контейнера, за исключением того, что в JSON фактически существует два таких типа - объект и массив. Если последний игнорируется (а также различие между отдельными примитивными типами данных), то предоставленные абстракции файловых систем и данных JSON одинаковы - оба являются деревьями стрелок, снабженными наименованием σ и различием узлов-контейнеров.
Функция именования σ вложенного словаря ℰ естественным образом распространяется от стрелок до путей стрелок. Каждой последовательности p = [a 1,..., a n ] последовательных стрелок неявно назначается путь (см. Pathname ) - последовательность σ (p) = [σ (a 1),..., σ (a n)] названий стрелок. Локальная уникальность переносится на пути стрелок: разные одноуровневые пути имеют разные имена. В частности, пути стрелок, ведущих к корню, находятся во взаимно однозначном соответствии со своими именами путей. Это соответствие обеспечивает «символическое» представление развертывания ℰ через имена путей - узлы в ℰ глобально идентифицируются через дерево имен путей.
Структуры, представленные в предыдущем подразделе, образуют только базовую «иерархическую» часть древовидных структур данных, которые появляются в вычислениях. В большинстве случаев существует также дополнительное «горизонтальное» упорядочение между братьями и сестрами. В деревьях поиска порядок обычно устанавливается «ключом» или значением, связанным с каждым из братьев и сестер, но во многих деревьях это не так. Например, документы XML, списки в файлах JSON и многие другие структуры имеют порядок, который не зависит от значений в узлах, но сам является данными - сортировка абзацев романа по алфавиту приведет к потере информации.
Соответствующее расширение ранее описанных древовидных структур (X, ≤) может быть определено путем наделения каждого одноуровневого набора следующим линейным порядком.
Альтернативное определение согласно Кубояме представлено в следующий подраздел.
Упорядоченное дерево - это структура (X, ≤ V, ≤ S), где X - непустой набор узлов и ≤ V и ≤ S - это отношения в X, называемые v этериальным (или также иерархическим) порядком и s порядком объединения, соответственно. Структура подчиняется следующим условиям:
Условия (2) и (3) говорят, что (X, ≤ S) является покомпонентным линейным порядком, причем каждый компонент является набор братьев и сестер. Условие (4) утверждает, что если одноуровневое множество S бесконечно, то (S, ≤ S) изоморфно (ℕ, ≤), обычному порядку натуральных чисел.
Учитывая это, есть три (других) выделенных частичных заказа, которые однозначно задаются следующими предписаниями:
(| = | (≤V) ○ ( | (h по горизонтали), | |
(| = | (>V) ∪ ( | («несогласованный» l в порядке следования), | |
(| = | ( | («согласованный» l inear order). | |
Это составляет систему «VSHL» из пяти частичных порядков ≤ V, ≤ S, ≤ H, ≤ L⁺, ≤ L⁻ на том же множестве X узлов, в котором, кроме пары {≤ S, ≤ H }, любые два отношения однозначно определяют остальные три, см. Таблицу детерминированности.
Примечания относительно условных обозначений:
 ).
).Это дает шесть версий ≺, <, ≤, ≻,>, ≥ для одного отношения частичного порядка. За исключением ≺ и ≻, каждая версия однозначно определяет другие. Переход от ≺ к Частичные порядки ≤ V и ≤ H являются дополнительными: Как следствие, «согласованный» линейный порядок Покрывающие отношения ≺ L⁻ и ≺ L⁺ соответствуют обходу предварительного заказа. и обход постзаказа соответственно. Если x ≺ L⁻ y, тогда, в зависимости от того, есть ли у y предыдущий родственник или нет, узел x является либо «самым правым» нестрогим потомком предыдущего брата y, либо, в последнем случае, x - первый дочерний элемент y. Пары Определение Кубоямы «упорядоченных деревьев с корнями» использует горизонтальный порядок ≤ H в качестве определяющего отношения. (См. Также Приложения.) Используя введенные обозначения и терминологию, определение можно выразить следующим образом. Упорядоченное дерево - это структура (X, ≤ V, ≤ H) такая, что выполняются условия (1–5): Порядок братьев и сестер (≤ S) получается как ( В следующей таблице показана определяемость системы «V-S-H-L». Выражения отношения в теле таблицы равны одному из В последних двух строках inf L⁻ (Y) обозначает инфимум Y в (X, ≤ L⁻), а sup L⁺ (Y) обозначает супремум Y в (X, ≤ L ⁺). В обеих строках (≤ S) соответственно (≥ S) могут быть эквивалентно заменены на родственную эквивалентность (≤S) ○ (≥ S). В частности, разбиение на одноуровневые множества вместе с ≤ L⁻ или ≤ L⁺ также достаточно для определения упорядоченного дерева. первый presc Преобразование для ≺ V может быть прочитано как: родительский элемент некорневого узла x равен точной нижней грани набора всех непосредственных предшественников братьев и сестер x, где слова «infimum» и «предшественники» являются означает в отношении ≤ L⁻. Аналогично второму рецепту, просто используйте «супремум», «преемники» и ≤ L⁺. . Отношения ≤ S и ≤ H, очевидно, не могут образовывать определяющую пару. В качестве простейшего примера рассмотрим упорядоченное дерево ровно с двумя узлами - тогда нельзя сказать, какой из них является корнем. В таблице справа показано соответствие введенных отношений осям XPath, которые используются в системах структурированного документа для доступа к узлам, которые имеют особые отношения упорядочения к начальному «контекстному» узлу. Для контекстного узла x его ось, названная спецификатором в левом столбце, представляет собой набор узлов, который равен изображению {x} в соответствующем отношении. Начиная с XPath 2.0, узлы «возвращаются» в порядке документа, который является «несогласованным» линейным порядком ≤ L⁻. «Согласованность» была бы достигнута, если бы вертикальный порядок ≤ V был задан противоположным образом, с направлением снизу вверх наружу от корня, как в теории множеств, в соответствии с естественными деревьями. Ниже приведен список частичных отображений, которые обычно используются для упорядоченного обхода дерева. Каждая карта представляет собой выделенную функциональную подотношение ≤ L⁻ или ее противоположность. Карты обхода составляют частичную (X, parent, previousSibling,..., nextNode), которая формирует основу для представления деревья как связанные структуры данных. По крайней мере, концептуально существуют родительские ссылки, родственные связи смежности и первые / последние дочерние ссылки. Это также относится к неупорядоченным деревьям в целом, что можно увидеть в структуре данных dentry в Linux VFS. Подобно системе частичного порядка VSHL, есть пары карты обхода, которые однозначно определяют всю упорядоченную древовидную структуру. Естественно, одна из таких генерирующих структур - это (X, V, S), которую можно транскрибировать как (X, parent, nextSibling) - структура родительских и соседних ссылок. Другой важной генерирующей структурой является (X, firstChild, nextSibling), известная как бинарное дерево левого потомка и правого брата. Эта частичная алгебра устанавливает взаимно однозначное соответствие между двоичными деревьями и упорядоченными деревьями. Соответствие двоичным деревьям дает краткое определение упорядоченных деревьев как частичных алгебр. Упорядоченное дерево - это структура Структура частичного порядка (X, ≤ V, ≤ S) получается следующим образом : Упорядоченные деревья могут быть естественно закодированы конечными последовательностями натуральных чисел. Обозначим ω множество всех конечных последовательностей натуральных чисел. Тогда любое непустое подмножество W в ω, замкнутое при вводе префиксов , порождает упорядоченное дерево: возьмите порядок префиксов для ≥ V и лексикографический порядок для ≤ L⁻. И наоборот, для упорядоченного дерева T = (X, V, ≤ L⁻) назначьте каждому узлу x последовательность Можно заметить, что 
Определение с использованием горизонтального порядка
Таблица достоверности
V, S (≤V) ○ ( V, H ( (>V) ∪ ( ( V, L⁻ ( ( V, L⁺ ( ( H, L⁻ (>L⁻) ∖ ( H, L⁺ ( L⁻, L⁺ (>L⁻) ∩ ( ( S, L⁻ x ≺ V y ↔ y = inf L⁻ (Y), где Y - изображение {x} под (≥ S) ○ (≻ L⁻) S, L⁺ x ≺ V y ↔ y = sup L⁺ (Y), где Y - изображение {x} под (≤ S) ○ (≺ L⁺) оси XPath
ось XPath Отношение предокпредок или я≤V потомок≻V потомок>V потомок или я≥V следующийследующий-братродительский≺V предшествующий>H предыдущий-брат>S самidX Карты обхода
Генерирующая структура
Определение с использованием двоичных деревьев

(≺S) = (rs), (≻V) = (lc) ○ (≤ S). Кодирование последовательностями

Поуровневое упорядочение
 Пунктирная линия указывает на
Пунктирная линия указывает на См. Также
Другие деревья
Примечания
Ссылки
Дополнительная литература
Внешние ссылки
![]()
На Викискладе есть материалы, связанные с древовидными структурами.
