
Войти
| R-tree | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Тип | tree | ||||||||
| Изобретено | 1984 | ||||||||
| Изобретено на | |||||||||
| Сложность времени в нотации большого O | |||||||||
| |||||||||
 Простой пример R-дерева для 2D-прямоугольники
Простой пример R-дерева для 2D-прямоугольники  Визуализация R * -дерева для 3D-точек с использованием ELKI (кубы являются страницами каталогов)
Визуализация R * -дерева для 3D-точек с использованием ELKI (кубы являются страницами каталогов) R-деревья используются древовидные структуры данных для методов пространственного доступа, т. е. для индексации многомерной информации, такой как географические координаты, прямоугольники или многоугольники. R-дерево был предложен Антонином Гуттманом в 1984 году и нашел существенное применение как в теоретическом, так и в прикладном контексте. В реальной жизни R-дерево может использоваться для хранения пространственных объектов, таких как местоположения ресторанов или многоугольников, из которых составлены типовые карты: улиц, зданий, очертаний озер, береговых линий и т. д., а затем быстро находите ответы на такие запросы, как "Найти все музеи в пределах 2 км от моего текущего местоположения "," найти все участки дороги в пределах 2 км от моего местоположения "(чтобы отобразить их в навигационной системе ) или" найти ближайшую заправочную станцию "(хотя и не брать дороги во внимание). R-дерево также может ускорить поиск ближайшего соседа для различных показателей расстояния, включая расстояние по дуге.
Ключевая идея структуры данных состоит в том, чтобы сгруппировать близлежащие объекты и представить их с их минимумом ограничивающий прямоугольник на следующем более высоком уровне дерева; «R» в R-дереве означает прямоугольник. Поскольку все объекты лежат внутри этого ограничивающего прямоугольника, запрос, который не пересекает ограничивающий прямоугольник, также не может пересекать ни один из содержащихся в нем объектов. На уровне листа каждый прямоугольник описывает отдельный объект; на более высоких уровнях агрегация увеличивающегося числа объектов. Это также можно рассматривать как более грубое приближение набора данных.
Подобно B-дереву, R-дерево также является сбалансированным деревом поиска (так что все конечные узлы находятся на одной глубине), организует данные на страницах и спроектировано для хранения на диске (как используется в базах данных ). Каждая страница может содержать максимальное количество записей, часто обозначаемое как 
Как и в случае с большинством деревьев, алгоритмы поиска (например, пересечение, сдерживание, поиск ближайшего соседа ) довольно просты. Ключевой идеей является использование ограничивающих рамок, чтобы решить, искать ли внутри поддерева. Таким образом, большинство узлов в дереве никогда не читаются во время поиска. Подобно B-деревьям, R-деревья подходят для больших наборов данных и баз данных, где узлы могут быть выгружены в память при необходимости, а все дерево не может храниться в основной памяти. Даже если данные можно уместить в памяти (или кэшировать), R-деревья в большинстве практических приложений обычно обеспечивают преимущества в производительности по сравнению с простой проверкой всех объектов, когда количество объектов превышает несколько сотен или около того. Однако для приложений в памяти существуют аналогичные альтернативы, которые могут обеспечить немного лучшую производительность или их проще реализовать на практике.
Ключевая сложность R-дерева состоит в том, чтобы построить эффективное дерево, которое, с одной стороны, сбалансировано (так что листовые узлы находятся на одной высоте), с другой стороны, прямоугольники не покрывают слишком много пустого пространства и не перекрываются слишком сильно (чтобы во время поиска нужно было обрабатывать меньшее количество поддеревьев). Например, первоначальная идея вставки элементов для получения эффективного дерева состоит в том, чтобы всегда вставлять в поддерево, которое требует наименьшего увеличения его ограничивающего прямоугольника. После заполнения страницы данные разделяются на два набора, каждый из которых должен занимать минимальную площадь. Большая часть исследований и улучшений для R-деревьев направлена на улучшение способа построения дерева и может быть сгруппирована по двум целям: построение эффективного дерева с нуля (известная как массовая загрузка) и выполнение изменений в существующем дереве (вставка и удаление).
R-деревья не гарантируют хорошей производительности в худшем случае, но обычно хорошо работают с реальными данными. Хотя представляет больший теоретический интерес, вариант Priority R-tree R-tree (с массовой загрузкой) является оптимальным для наихудшего случая, но из-за повышенной сложности не получил большого внимания в практических приложениях, поэтому далеко.
Когда данные организованы в R-дереве, соседи на заданном расстоянии r и k ближайшие соседи (для любого L-Norm ) всех точек можно эффективно вычислить с помощью пространственного соединения. Это полезно для многих алгоритмов, основанных на таких запросах, например, Локальный фактор выброса. DeLi-Clu, Density-Link-Clustering - это алгоритм кластерного анализа, который использует структуру R-tree для подобного типа пространственного соединения для эффективного вычисления кластеризации OPTICS.
Данные в R-деревьях организованы в страницы, которые могут иметь переменное количество записей (до некоторого заранее определенного максимума и обычно выше минимального заполнения). Каждая запись в не- листовом узле хранит две части данных: способ идентификации дочернего узла и ограничивающий прямоугольник всех записей в этом дочернем узле. узел. Конечные узлы хранят данные, необходимые для каждого дочернего элемента, часто точку или ограничивающую рамку, представляющую дочерний элемент, и внешний идентификатор для дочернего элемента. Для точечных данных конечными записями могут быть только сами точки. Для данных многоугольника (которые часто требуют хранения больших многоугольников) обычная настройка - хранить только MBR (минимальный ограничивающий прямоугольник) многоугольника вместе с уникальным идентификатором в дереве.
В поиск по диапазону входом является прямоугольник поиска (окно запроса). Поиск очень похож на поиск в B + дереве. Поиск начинается с корневого узла дерева. Каждый внутренний узел содержит набор прямоугольников и указателей на соответствующий дочерний узел, а каждый листовой узел содержит прямоугольники пространственных объектов (указатель на некоторый пространственный объект может находиться там). Для каждого прямоугольника в узле необходимо решить, перекрывает он прямоугольник поиска или нет. Если да, необходимо также найти соответствующий дочерний узел. Поиск выполняется таким образом рекурсивно до тех пор, пока не будут пройдены все перекрывающиеся узлы. Когда достигается листовой узел, содержащиеся в нем ограничивающие рамки (прямоугольники) проверяются относительно прямоугольника поиска, и их объекты (если они есть) помещаются в набор результатов, если они лежат в пределах прямоугольника поиска.
Для приоритетного поиска, такого как поиск ближайшего соседа, запрос состоит из точки или прямоугольника. Корневой узел вставляется в приоритетную очередь. Пока очередь не станет пустой или пока не будет возвращено желаемое количество результатов, поиск продолжается, обрабатывая ближайшую запись в очереди. Узлы дерева раскрываются, и их дочерние элементы повторно вставляются. Конечные записи возвращаются при обнаружении в очереди. Этот подход можно использовать с различными показателями расстояния, включая расстояние по дуге для географических данных.
Чтобы вставить объект, дерево рекурсивно просматривается из корневой узел. На каждом шаге проверяются все прямоугольники в текущем узле каталога, и кандидат выбирается с помощью эвристики, такой как выбор прямоугольника, который требует наименьшего увеличения. Затем поиск спускается на эту страницу, пока не достигнет листового узла. Если листовой узел заполнен, он должен быть разделен перед выполнением вставки. Опять же, поскольку исчерпывающий поиск слишком затратен, используется эвристика для разделения узла на два. При добавлении вновь созданного узла к предыдущему уровню этот уровень снова может переполняться, и эти переполнения могут распространяться до корневого узла; когда этот узел также переполняется, создается новый корневой узел, и дерево увеличивается в высоту.
На каждом уровне алгоритм должен решить, в какое поддерево вставить новый объект данных. Когда объект данных полностью содержится в одном прямоугольнике, выбор очевиден. Когда есть несколько вариантов или прямоугольников, которые необходимо увеличить, выбор может существенно повлиять на производительность дерева.
В классическом R-дереве объекты вставляются в поддерево, которое требует наименьшего увеличения. В более продвинутом R * -дереве используется смешанная эвристика. На уровне листа он пытается минимизировать перекрытие (в случае завязок предпочтительнее минимальное увеличение, а затем минимальная площадь); на более высоких уровнях оно ведет себя аналогично R-дереву, но на связях снова предпочитает поддерево с меньшей площадью. Уменьшение перекрытия прямоугольников в R * -дереве является одним из ключевых преимуществ перед традиционным R-деревом (это также является следствием других используемых эвристик, а не только выбора поддерева).
Поскольку перераспределение всех объектов узла на два узла имеет экспоненциальное количество вариантов, необходимо использовать эвристику, чтобы найти лучшее разделение. В классическом R-дереве Гутман предложил две такие эвристики, названные QuadraticSplit и LinearSplit. При квадратичном разбиении алгоритм ищет пару прямоугольников, которая является наихудшей комбинацией в одном узле, и помещает их в качестве исходных объектов в две новые группы. Затем он ищет запись, которая имеет наибольшее предпочтение для одной из групп (с точки зрения увеличения площади), и назначает объект этой группе до тех пор, пока не будут назначены все объекты (удовлетворяющие минимальному заполнению).
Существуют и другие стратегии разделения, такие как разделение Грина, эвристика разделения R * -дерева (которая снова пытается минимизировать перекрытие, но также предпочитает квадратичные страницы) или алгоритм линейного разделения, предложенный Ang и Tan (которые, однако, могут создавать очень неправильные прямоугольники, которые менее эффективны для многих реальных запросов диапазона и окна). В дополнение к более продвинутой эвристике разделения, R * -дерево также пытается избежать разделения узла, повторно вставляя некоторые из элементов узла, что аналогично способу B-дерева уравновешивает переполненные узлы. Было показано, что это также уменьшает перекрытие и, следовательно, увеличивает производительность дерева.
Наконец, X-tree можно рассматривать как вариант R * -дерева, которое также может решить не разбивать узел, а построить так называемый суперузел, содержащий все лишние записи, когда не удается найти хорошее разделение (особенно для данных большой размерности).

Квадратичное разбиение Гуттмана.. Страницы в этом дереве часто перекрываются.

Линейное расщепление Гуттмана.. Еще хуже структура, но строить быстрее.

Раскол Грина. Страницы пересекаются гораздо меньше, чем в стратегии Гуттмана.

Линейное разбиение по Анг-Тану.. Эта стратегия создает нарезанные страницы, что часто приводит к снижению производительности запросов.
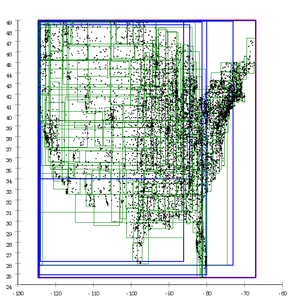
R * tree топологическое разбиение.. Страницы перекрываются гораздо меньше, поскольку R * -дерево пытается минимизировать перекрытие страниц, а повторные вставки дополнительно оптимизировали дерево. Стратегия разделения предпочитает квадратные страницы, что обеспечивает лучшую производительность для общих картографических приложений.

Массовая загрузка R * tree с использованием Sort-Tile-Recursive (STR).. Листовые страницы вообще не перекрываются, а страницы каталога частично перекрываются. Это очень эффективное дерево, но оно требует, чтобы данные были полностью известны заранее.

M-деревья похожи на R-дерево, но используют вложенные сферические страницы.. Однако разделение этих страниц намного сложнее, и страницы обычно намного больше перекрываются.
Удаление записи со страницы может потребовать обновления ограничивающих прямоугольников родительских страниц. Однако, когда страница не заполнена, она не будет сбалансирована со своими соседями. Вместо этого страница будет растворена, и все ее дочерние элементы (которые могут быть поддеревьями, а не только конечными объектами) будут повторно вставлены. Если во время этого процесса корневой узел будет иметь единственный элемент, высота дерева может уменьшиться.
 , требуемый коэффициент разделения в каждом измерении для достижения этого как
, требуемый коэффициент разделения в каждом измерении для достижения этого как  , затем последовательно разбивает каждое измерение на
, затем последовательно разбивает каждое измерение на  разделы одинакового размера с использованием одномерной сортировки. Полученные страницы, если они занимают более одной страницы, снова загружаются массово с использованием того же алгоритма. Для точечных данных конечные узлы не будут перекрываться, а «мозаика» пространства данных на страницы примерно одинакового размера.
разделы одинакового размера с использованием одномерной сортировки. Полученные страницы, если они занимают более одной страницы, снова загружаются массово с использованием того же алгоритма. Для точечных данных конечные узлы не будут перекрываться, а «мозаика» пространства данных на страницы примерно одинакового размера.| journal =()| journal =()