
Войти
Иерархическая временная память (HTM ) является биологически ограниченной теория (или модель) интеллекта, первоначально описанная в книге Об интеллекте 2004 года Джеффом Хокинсом с Сандрой Блейксли. HTM основывается на неврологии и физиологии и взаимодействии пирамидных нейронов в неокортексе млекопитающих ( в частности, человеческий ) мозг.
В основе HTM лежат обучающиеся алгоритмы, которые могут сохранять, изучать, выводить и вызывать последовательности высокого порядка. В отличие от большинства других методов машинного обучения, HTM непрерывно изучает (в процессе неконтролируемого ) основанные на времени шаблоны в немаркированных данных. HTM устойчив к шуму и обладает высокой производительностью (он может изучать несколько шаблонов одновременно). Применительно к компьютерам HTM хорошо подходит для прогнозирования, обнаружения аномалий, классификации и, в конечном итоге, сенсомоторных приложений.
Теория была проверена и реализована в программном обеспечении с помощью примеров приложений из Numenta и несколько коммерческих приложений от партнеров Numenta.
Типичный HTM сеть представляет собой иерархию уровней дерева, (не путать со «слоями» неокортекса, как описано ниже). Эти уровни состоят из более мелких элементов, называемых регионами (или узлами). Один уровень иерархии может содержать несколько регионов. На более высоких уровнях иерархии часто меньше регионов. Более высокие уровни иерархии могут повторно использовать шаблоны, изученные на более низких уровнях, комбинируя их для запоминания более сложных шаблонов.
Каждый регион HTM выполняет одну и ту же базовую функцию. В режимах обучения и вывода сенсорные данные (например, данные глаз) поступают в области нижнего уровня. В режиме генерации области нижнего уровня выводят сгенерированный шаблон данной категории. Верхний уровень обычно имеет одну область, в которой хранятся самые общие и наиболее постоянные категории (концепции); они определяют или определяются меньшими концепциями на более низких уровнях - концепциями, более ограниченными во времени и пространстве. В режиме вывода область (на каждом уровне) интерпретирует информацию, поступающую из ее «дочерних» областей, как вероятности категорий, которые она хранит в памяти.
Каждая область HTM обучается путем идентификации и запоминания пространственных паттернов - комбинаций входных битов, которые часто возникают одновременно. Затем он определяет временные последовательности пространственных паттернов, которые могут возникать один за другим.
HTM - это развивающаяся теория (или модель): это еще не законченная теория, поскольку наши знания о неокортексе являются неполными. Таким образом, новые данные о неокортексе постепенно включаются в модель HTM, которая со временем меняется в ответ. Новые результаты не обязательно аннулируют предыдущие части модели, поэтому идеи одного поколения не обязательно исключаются из следующего. Из-за развивающейся природы теории было несколько поколений алгоритмов HTM, которые кратко описаны ниже.
Первое поколение алгоритмов HTM (или первая версия теории HTM) иногда называют дзета 1.
Во время обучения узел (или область) получает временную последовательность пространственных паттернов в качестве входных данных. Процесс обучения состоит из двух этапов:
Концепции пространственного и временного пула по-прежнему очень важны в современной теории HTM. Временное объединение еще недостаточно изучено, и его значение со временем изменилось (по мере развития теории HTM).
Во время вывода узел вычисляет набор вероятностей того, что шаблон принадлежит каждому известному совпадению. Затем он вычисляет вероятности того, что входные данные представляют каждую временную группу. Набор вероятностей, назначенных группам, называется "убеждением" узла о входном шаблоне. (В упрощенной реализации убеждение узла состоит только из одной победившей группы). Это убеждение является результатом вывода, который передается одному или нескольким «родительским» узлам на следующем более высоком уровне иерархии.
«Неожиданные» шаблоны для узла не имеют доминирующей вероятности принадлежности к какой-либо временной группе, но имеют почти равные вероятности принадлежности к нескольким из групп. Если последовательности шаблонов аналогичны обучающим последовательностям, то присвоенные группам вероятности не будут меняться так часто, как шаблоны принимаются. Выход узла не изменится так сильно, и разрешение во времени будет потеряно.
В более общей схеме убеждение узла может быть отправлено на вход любого узла (ов) на любом уровне (ах), но связи между узлами по-прежнему фиксированы. Узел более высокого уровня объединяет этот вывод с выводом других дочерних узлов, таким образом формируя свой собственный шаблон ввода.
Поскольку разрешение в пространстве и времени теряется в каждом узле, как описано выше, убеждения, сформированные узлами более высокого уровня, представляют еще больший диапазон пространства и времени. Это должно отражать организацию физического мира, как она воспринимается человеческим мозгом. Считается, что более крупные концепции (например, причины, действия и объекты) изменяются медленнее и состоят из более мелких понятий, которые изменяются быстрее. Джефф Хокинс постулирует, что мозг развил иерархию этого типа, чтобы соответствовать, предсказывать и влиять на организацию внешнего мира.
Более подробную информацию о функционировании HTM Zeta 1 можно найти в старой документации Numenta.
Второе поколение алгоритмов обучения HTM, часто называемые алгоритмами коркового обучения (CLA), кардинально отличался от дзета 1. Он основан на структуре данных, называемой разреженными распределенными представлениями (то есть структура данных, элементы которой являются двоичными, 1 или 0, и количество 1 битов мало по сравнению с количеством 0 битов) для представления активности мозга и более биологически реалистичной модели нейрона (часто также называемой ячейкой в контексте теории HTM). В этой теории HTM есть два основных компонента: алгоритм пространственного пула, который выводит разреженные распределенные представления (SDR), и алгоритм памяти последовательностей, который обучается для представления и прогнозирования сложных последовательностей.
В этом новом поколении слои и миниколонки коры головного мозга являются адресовано и частично смоделировано. Каждый уровень HTM (не путать с уровнем HTM иерархии HTM, как описано выше) состоит из ряда тесно связанных мини-столбцов. Уровень HTM создает разреженное распределенное представление из своих входных данных, так что фиксированный процент мини-столбцов активен в любой момент. Под министолбцом понимается группа ячеек, имеющих одинаковое принимающее поле . В каждом мини-столбце есть несколько ячеек, которые могут запоминать несколько предыдущих состояний. Ячейка может находиться в одном из трех состояний: активное, неактивное и прогнозируемое.
Воспринимающее поле каждого мини-столбца - это фиксированное количество входов, которые случайным образом выбираются из гораздо большего количества входных данных узла. В зависимости от (конкретного) шаблона ввода некоторые мини-столбцы будут более или менее связаны с активными входными значениями. Пространственное объединение выбирает относительно постоянное количество наиболее активных мини-столбцов и инактивирует (подавляет) другие мини-столбцы в непосредственной близости от активных. Подобные шаблоны ввода, как правило, активируют стабильный набор мини-столбцов. Объем памяти, используемый каждым слоем, можно увеличить, чтобы изучить более сложные пространственные шаблоны, или уменьшить, чтобы изучить более простые шаблоны.
Как упоминалось выше, клетка (или нейрон) мини-столбца в любой момент времени может находиться в активном, неактивном или прогнозирующем состоянии. Изначально клетки неактивны.
Если одна или несколько ячеек в активном мини-столбце находятся в состоянии прогнозирования (см. Ниже), они будут единственными ячейками, которые станут активными на текущем временном шаге. Если ни одна из ячеек в активном мини-столбце не находится в состоянии прогнозирования (что происходит во время начального временного шага или когда активация этого мини-столбца не ожидалась), все ячейки становятся активными.
Когда ячейка становится активной, она постепенно образует связи с соседними ячейками, которые, как правило, активны в течение нескольких предыдущих временных шагов. Таким образом, ячейка учится распознавать известную последовательность, проверяя, активны ли подключенные ячейки. Если активно большое количество подключенных ячеек, эта ячейка переключается в прогнозирующее состояние в ожидании одного из нескольких следующих входов последовательности.
Выходные данные слоя включают мини-столбцы как в активном, так и в прогнозирующем состоянии. Таким образом, мини-столбцы активны в течение длительного времени, что приводит к большей временной стабильности, которую видит родительский слой.
Алгоритмы коркового обучения могут непрерывно обучаться на основе каждого нового шаблона ввода, поэтому отдельный режим вывода не требуется. Во время логического вывода HTM пытается сопоставить поток входных данных с фрагментами ранее изученных последовательностей. Это позволяет каждому уровню HTM постоянно прогнозировать вероятное продолжение распознанных последовательностей. Индекс предсказанной последовательности - это результат слоя. Поскольку прогнозы имеют тенденцию меняться реже, чем входные шаблоны, это приводит к увеличению временной стабильности выходных данных на более высоких уровнях иерархии. Прогнозирование также помогает заполнить недостающие шаблоны в последовательности и интерпретировать неоднозначные данные, заставляя систему делать выводы о том, что она предсказывала.
алгоритмы коркового обучения в настоящее время предлагаются как коммерческие SaaS компанией Numenta (например, Grok).
В сентябре 2011 года Джеффу Хокинсу был задан следующий вопрос относительно алгоритмов коркового обучения: «Как узнать, являются ли изменения, которые вы вносите в модель, хороший или нет?" На что Джефф ответил: «Есть две категории ответа: одна - это нейробиология, а другая - методы машинного интеллекта. В сфере нейробиологии мы можем сделать много прогнозов, и их можно проверить. Если наши теории объясняют широкий спектр наблюдений в области нейробиологии, то это говорит нам, что мы на правильном пути. В мире машинного обучения их не волнует только то, насколько хорошо оно работает с практическими проблемами. В нашем случае это еще предстоит выяснить. В той мере, в какой вы можете решить проблему, которую никто не мог решить раньше, люди обратят на это внимание ».
Третье поколение основано на второе поколение и добавляет теорию сенсомоторного вывода в неокортексе. Эта теория предполагает, что кортикальные столбцы на каждом уровне иерархии могут изучать полные модели объектов с течением времени и что особенности изучаются в определенных местах на объектах. Теория была расширена в 2018 году и получила название Теория тысячи мозгов.
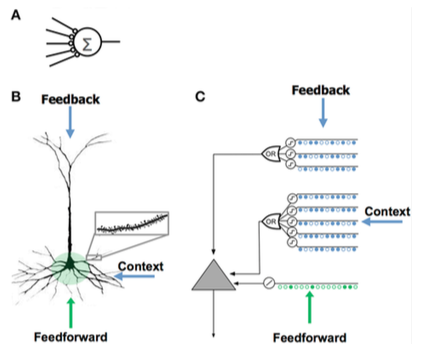 Сравнение искусственной нейронной сети (A), биологического нейрона (B) и нейрона HTM (C
Сравнение искусственной нейронной сети (A), биологического нейрона (B) и нейрона HTM (C | Искусственная нейронная сеть (ИНС) | Неокортикальный пирамидный нейрон (биологический нейрон ) | Нейрон-модель HTM |
|---|---|---|
|
|
|
HTM пытается реализовать функциональность, которая характерна для иерархически связанной группы корковых областей в неокортексе. Область неокортекса соответствует одному или нескольким уровням в иерархии HTM, в то время как гиппокамп отдаленно похож на самый высокий уровень HTM. Один узел HTM может представлять группу кортикальных столбцов в определенной области.
Хотя это в первую очередь функциональная модель, было сделано несколько попыток связать алгоритмы HTM со структурой нейронных связей в слоях неокортекса. Неокортекс организован в виде вертикальных столбцов из 6 горизонтальных слоев. Шесть слоев клеток в неокортексе не следует путать с уровнями иерархии HTM.
HTM-узлы пытаются смоделировать часть кортикальных столбцов (от 80 до 100 нейронов) примерно с 20 HTM «клетками» на столбец. HTM моделируют только слои 2 и 3 для обнаружения пространственных и временных характеристик входных данных с 1 ячейкой на столбец в слое 2 для пространственного «объединения» и от 1 до 2 дюжин на столбец в слое 3 для временного объединения. Ключом к HTM и кортексам является их способность справляться с шумом и вариациями входных данных, что является результатом использования «разреженного дистрибутивного представления», при котором только около 2% столбцов активны в любой момент времени.
HTM пытается смоделировать часть обучения и пластичности коры, как описано выше. Различия между HTM и нейронами включают:
Интеграция компонента памяти с нейронными сетями имеет долгую историю, восходящую к ранним исследованиям распределенных представлений и самоорганизующихся карт. Например, в разреженной распределенной памяти (SDM) шаблоны, закодированные нейронными сетями, используются в качестве адресов памяти для памяти с адресацией по содержимому, причем «нейроны» по существу служат в качестве кодировщиков адресов и декодеры.
Компьютеры хранят информацию в плотных представлениях, таких как 32-битное слово, где возможны все комбинации единиц и нулей. Напротив, мозг использует разреженные распределенные представления (SDR). В неокортексе человека примерно 16 миллиардов нейронов, но в любой момент времени активен лишь небольшой процент. Активность нейронов подобна битам в компьютере, поэтому их представление является разреженным. Подобно SDM, разработанному НАСА в 80-х годах и моделям векторного пространства, используемым в скрытом семантическом анализе, HTM использует разреженные распределенные представления. 132>
SDR, используемые в HTM, являются двоичными представлениями данных, состоящими из многих битов с небольшим процентом активных битов (единицы); типичная реализация может иметь 2048 столбцов и 64 КБ искусственных нейронов, из которых всего 40 могут быть активными одновременно. Хотя может показаться менее эффективным, чтобы большая часть битов оставалась «неиспользованной» в любом данном представлении, SDR имеют два основных преимущества перед традиционными плотными представлениями. Во-первых, SDR терпимы к искажению и двусмысленности из-за того, что значение представления разделяется (распределяется) по небольшому проценту (разреженному) активных битов. В плотном представлении переворот одного бита полностью меняет значение, в то время как в SDR один бит может не сильно повлиять на общий смысл. Это приводит ко второму преимуществу SDR: поскольку значение представления распределяется по всем активным битам, сходство между двумя представлениями может использоваться как мера семантического сходства в объектах, которые они представляют. То есть, если два вектора в SDR имеют единицы в одной позиции, то они семантически похожи в этом атрибуте. Биты в SDR имеют семантическое значение, и это значение распределяется по битам.
Теория семантического сворачивания основывается на этих свойствах SDR, чтобы предложить новую модель языковой семантики, в которой слова закодированы в слова-SDR, и сходство между терминами, предложениями и текстами может быть вычислено с помощью простых мер расстояния.
Подобно байесовской сети, HTM содержит набор узлов, которые расположены в виде дерева: сформированная иерархия. Каждый узел в иерархии обнаруживает массив причин во входных шаблонах и временных последовательностях, которые он получает. Байесовский алгоритм пересмотра убеждений используется для распространения убеждений с прямой связью и обратной связи от дочерних узлов к родительским и наоборот. Однако аналогия с байесовскими сетями ограничена, поскольку HTM можно обучать самостоятельно (так что каждый узел имеет однозначные семейные отношения), справляться с чувствительными ко времени данными и предоставлять механизмы для скрытого внимания.
Теория иерархических корковых вычислений, основанных на байесовском распространении убеждений, было предложено ранее Тай Синг Ли и Дэвидом Мамфордом. Хотя HTM в основном согласуется с этими идеями, он добавляет подробности об обработке инвариантных представлений в зрительной коре.
Как и любую систему, моделирующую детали неокортекса, HTM можно рассматривать как искусственная нейронная сеть. Древовидная иерархия, обычно используемая в HTM, напоминает обычную топологию традиционных нейронных сетей. HTM пытается моделировать корковые столбики (от 80 до 100 нейронов) и их взаимодействие с меньшим количеством HTM. «нейроны». Целью современных HTM является захват как можно большего количества функций нейронов и сети (как они понимаются в настоящее время) в пределах возможностей обычных компьютеров и в областях, которые могут быть легко использованы, например, обработка изображений. Например, обратная связь от более высоких уровней и моторный контроль не предпринимаются, потому что еще не понятно, как их включить, и используются двоичные вместо переменных синапсов, потому что они были определены как достаточные для текущих возможностей HTM.
LAMINART и аналогичные нейронные сети, исследованные Стивеном Гроссбергом, пытаются смоделировать как инфраструктуру коры, так и поведение нейронов во временных рамках, чтобы объяснить нейрофизиологические и психофизические данные. Однако эти сети в настоящее время слишком сложны для реального применения.
HTM также связана с работой Томазо Поджио, включая подход к моделированию вентрального потока зрительной коры, известной как HMAX. Сходства HTM с различными идеями искусственного интеллекта описаны в выпуске журнала Artificial Intelligence за декабрь 2005 г.
Neocognitron, иерархическая многослойная нейронная сеть, предложенная профессором Кунихико Фукусима в 1987 году является одной из первых моделей Deep Learning нейронных сетей.
Платформа Numenta для интеллектуальных вычислений (NuPIC) - одна из нескольких доступных реализаций HTM. Некоторые из них предоставляются Numenta, а некоторые разрабатываются и поддерживаются сообществом HTM с открытым исходным кодом..
NuPIC включает реализации пространственного пула и временной памяти как на C ++, так и на Python. Он также включает 3 API. Пользователи могут создавать системы HTM, используя прямые реализации алгоритмов , или создавать сеть, используя Network API, который представляет собой гибкую структуру для построения сложных ассоциаций между различными уровнями коры головного мозга.
NuPIC 1.0 был выпущен в июле 2017 года, после чего кодовая база была переведена в режим обслуживания. Текущие исследования продолжаются в Numenta кодовые базы исследований.
Следующие коммерческие приложения доступны с использованием NuPIC:
На NuPIC доступны следующие инструменты:
На NuPIC доступны следующие примеры приложений. см. numenta.com/applications/ :