
Войти
| Буква | Относительная частота в английском языке | |||
|---|---|---|---|---|
| Тексты | Словари | |||
| a | 8,2% | 8,2 | 7,8% | 7,8 |
| b | 1,5% | 1,5 | 2% | 2 |
| c | 2,8% | 2,8 | 4% | 4 |
| d | 4,3% | 4,3 | 3,8% | 3,8 |
| e | 13% | 13 | 11% | 11 |
| f | 2,2% | 2,2 | 1,4% | 1,4 |
| g | 2% | 2 | 3% | 3 |
| h | 6,1% | 6,1 | 2,3% | 2,3 |
| i | 7% | 7 | 8,6% | 8,6 |
| j | 0,15% | 0,15 | 0,21% | 0,21 |
| k | 0,77% | 0,77 | 0,97% | 0,97 |
| l | 4% | 4 | 5,3% | 5,3 |
| m | 2,4% | 2,4 | 2,7% | 2,7 |
| n | 6,7% | 6,7 | 7,2% | 7,2 |
| o | 7,5% | 7,5 | 6,1% | 6,1 |
| p | 1,9% | 1,9 | 2,8% | 2,8 |
| q | 0,095% | 0,095 | 0,19% | 0,19 |
| r | 6% | 6 | 7,3% | 7,3 |
| s | 6,3% | 6,3 | 8,7% | 8,7 |
| t | 9,1% | 9,1 | 6,7% | 6,7 |
| u | 2,8% | 2,8 | 3,3% | 3,3 |
| v | 0,98% | 0,98 | 1% | 1 |
| w | 2,4% | 2,4 | 0,91% | 0,91 |
| x | 0,15% | 0,15 | 0,27% | 0,27 |
| y | 2% | 2 | 1,6% | 1,6 |
| z | 0,074% | 0,074 | 0,44% | 0,44 |
Частота появления букв - это просто количество раз, когда буквы алфавита появляются в среднем в письменном языке. Анализ частоты букв восходит к арабскому математику Аль-Кинди (около 801–873 гг. Н.э.), который официально разработал метод взлома шифров. Анализ частоты букв приобрел важность в Европе с разработкой подвижного шрифта в 1450 году нашей эры, где необходимо оценить количество шрифтов, необходимых для каждой формы букв. Лингвисты используют частотный анализ букв как элементарный метод для языковой идентификации, где он особенно эффективен для определения того, является ли неизвестная система письма алфавитной, слоговой или идеографической.
Использование частотности букв и частотный анализ играет фундаментальную роль в криптограммах и нескольких играх со словами, включая Палач, Эрудит и телешоу Колесо фортуны. Одно из самых ранних описаний в классической литературе применения знания о частоте букв английского алфавита для решения криптограммы находится в знаменитом рассказе Эдгара Аллана По Золотой жук, где метод успешно применяется для расшифровки сообщения, информирующего о местонахождении сокровища, спрятанного капитаном Киддом.
. Частота букв также сильно влияет на дизайн некоторых раскладок клавиатуры. Самые частые буквы находятся в нижнем ряду пишущей машинки Бликенсдерфер и в исходном ряду раскладки клавиатуры Дворжака.
Частота появления букв в тексте была изучена для использования в криптоанализе и частотном анализе в частности, восходящий к иракскому математику Аль-Кинди (ок. 801–873 гг. н.э.), который формально разработал метод (шифры, которые можно взломать с помощью этой техники, восходят, по крайней мере, к шифру Цезаря изобретен Юлием Цезарем, поэтому этот метод можно было использовать в классические времена). Частотный анализ букв приобрел дополнительное значение в Европе с разработкой подвижного шрифта в 1450 году нашей эры, где необходимо оценить количество шрифтов, необходимых для каждой буквенной формы, о чем свидетельствуют различия в размере буквенного отсека в типографских случаях..
Нет точного частотного распределения букв, лежащего в основе данного языка, поскольку все авторы пишут немного по-разному. Однако большинство языков имеют характерное распределение, которое явно проявляется в более длинных текстах. Даже такие резкие языковые изменения, как переход от старого английского к современному (считающемуся взаимно непонятным), демонстрируют сильные тенденции в частотности соответствующих букв: по небольшой выборке библейских отрывков, от наиболее частых к наименее частым, enaid sorhm tgþlwu æcfy ðbpxz старого английского языка сравнивается с eotha sinrd luymw fgcbp kvjqxz в современном английском, с самыми резкими различиями, касающимися не используемых форм букв.
Машины линотипа для английского языка предполагали порядок букв, от от наиболее распространенных до наименее распространенных, быть etaoin shrdlu cmfwyp vbgkjq xz на основе опыта и обычаев ручных наборщиков. Эквивалент для французского языка был elaoin sdrétu cmfhyp vbgwqj xz .
Распределение алфавита по азбуке Морзе на группы букв, требующих равного количества времени для передачи, а затем сортировка этих групп в порядке возрастания дает e это сан хардм wgvlfbk opxcz jyq . Частота букв использовалась другими телеграфными системами, такими как Код Мюррея.
Подобные идеи используются в современных методах сжатия данных, таких как кодирование Хаффмана.
Частоты букв, например Частота слов, как правило, варьируется как в зависимости от автора, так и от темы. Нельзя написать эссе о рентгеновских лучах без частого использования крестиков, и эссе будет иметь своеобразную частоту букв, если эссе посвящено использованию рентгеновских лучей для лечения зебр в Катаре. У разных авторов есть привычки, которые могут быть отражены в использовании букв. Стиль письма Хемингуэя, например, заметно отличается от стиля письма Фолкнера. Буква, биграмма, триграмма, частота слов, длина слова и длина предложения могут быть рассчитаны для конкретных авторов и использованы для доказательства или опровержения авторства текстов даже для авторов, чьи стили не так уж и расходятся.
Точную среднюю частоту букв можно определить только путем анализа большого количества репрезентативного текста. Благодаря наличию современных компьютеров и коллекций больших текстовых корпусов такие вычисления выполняются легко. Примеры могут быть взяты из различных источников (репортажи в прессе, религиозные тексты, научные тексты и художественная литература общего характера), и существуют различия, особенно для художественной литературы общего характера, с положением «h» и «i», причем «h» становится все более распространенным.
Герберт С. Зим в своем классическом вводном тексте по криптографии «Коды и секретное письмо» дает последовательность английских букв как «ETAON RISHD LFCMU GYPWB VKJXZQ», наиболее распространенные пары букв как «TH HE AN RE» ER IN ON AT ND ST ES EN OF TE ED OR TI HI AS TO ", а наиболее распространенные удвоенные буквы как" LL EE SS OO TT FF RR NN PP CC ".
Также следует отметить, что разные диалекты языка также влияют на частоту букв. Например, автор в США создаст текст, в котором буква «z» встречается чаще, чем автор в Соединенном Королевстве, пишущий на ту же тему: такие слова, как «анализировать», «извиняться» и «признавать» содержат буква в американском английском, тогда как те же слова пишутся «анализировать», «извиняться» и «признавать» в британском английском. Это сильно повлияет на частоту буквы «z», так как это редко используемая буква британцами в английском языке.
«Двенадцать верхних букв» составляют около 80% от общего использования. «Восьмерка» букв составляет около 65% от общего использования. Частота букв как функция ранга может хорошо соответствовать нескольким функциям ранга, из которых лучше всего подходит двухпараметрическая функция ранга Кочо / Бета. Другая функция ранжирования без регулируемого свободного параметра также достаточно хорошо соответствует частотному распределению букв (та же функция использовалась для соответствия частотности аминокислот в белковых последовательностях). Шпион, использующий шифр VIC или какой-либо другой шифр на основе шахматной доски обычно использует мнемонику, такую как «грех ошибиться» (отбрасывая второе «r») или «в один прекрасный день, сэр», чтобы запомнить восемь верхних символов.
 California Job Case была разделенной коробкой для печати в 19 веке, размеры соответствовали общности букв
California Job Case была разделенной коробкой для печати в 19 веке, размеры соответствовали общности букв три способа подсчета количества букв, которые приводят к очень разным диаграммам для общих букв. Первый метод, используемый в таблице ниже, - это подсчет частоты букв в корневых словах словаря. Во-вторых, при подсчете учитываются все варианты слов, такие как «рефераты», «абстракции» и «абстрагирование», а не только корневое слово «абстрактного». Эта система приводит к тому, что такие буквы, как 's', появляются гораздо чаще, например, при подсчете букв из списков наиболее часто используемых английских слов в Интернете. Последний вариант - подсчет букв в зависимости от частоты их использования в реальных текстах, в результате чего определенные комбинации букв, такие как 'th', становятся более распространенными из-за частого использования общих слов, таких как «the», «then», «both», и т.д. Такие меры абсолютной частоты использования используются при создании раскладок клавиатуры или частот букв в старых печатных машинах.
Анализ статей в Кратком оксфордском словаре без учета частоты употребления слов дает порядок «EARIOTNSLCUDPMHGBFYWKVXZJQ».
Таблица частотности букв ниже взята с веб-сайта Павла Мички, который цитирует Роберта Леванда «Криптологическая математика».
Согласно Леванду, расположенные от наиболее распространенных к наименее распространенным буквам: etaoinshrdlcumwfgypbvkjxqz . Порядок действий Леванда немного отличается от других, таких как проект Корнельского университета Math Explorer, в котором таблица была создана после измерения 40 000 слов.
В английском языке пробел немного чаще, чем верхняя буква (e) и не- буквенные символы (цифры, знаки препинания и т. д.) вместе занимают четвертую позицию (уже включив пробел) между t и a.
| Буква | Относительная частота как первая буква английского слова | |||
|---|---|---|---|---|
| Тексты | Словари | |||
| a | 1,7% | 1,7 | 5,7% | 5,7 |
| b | 4,4% | 4,4 | 6% | 6 |
| c | 5,2% | 5,2 | 9,4% | 9,4 |
| d | 3,2% | 3,2 | 6,1% | 6,1 |
| e | 2,8% | 2,8 | 3,9% | 3,9 |
| f | 4% | 4 | 4,1% | 4,1 |
| g | 1,6% | 1,6 | 3,3% | 3,3 |
| h | 4,2% | 4,2 | 3,7% | 3,7 |
| i | 7,3% | 7,3 | 3,9% | 3,9 |
| j | 0,51% | 0,51 | 1,1% | 1,1 |
| k | 0,86% | 0,86 | 1% | 1 |
| l | 2,4% | 2,4 | 3,1% | 3,1 |
| m | 3,8% | 3,8 | 5,6% | 5,6 |
| n | 2,3% | 2,3 | 2,2% | 2,2 |
| o | 7,6% | 7,6 | 2,5% | 2,5 |
| p | 4,3% | 4,3 | 7,7% | 7,7 |
| q | 0,22% | 0,22 | 0,49% | 0,49 |
| r | 2,8% | 2,8 | 6% | 6 |
| s | 6,7% | 6,7 | 11% | 11 |
| t | 16% | 16 | 5% | 5 |
| u | 1,2% | 1,2 | 2,9% | 2,9 |
| v | 0,82% | 0,82 | 1,5% | 1,5 |
| w | 5,5% | 5,5 | 2,7% | 2,7 |
| x | 0,045% | 0,045 | 0,05% | 0,05 |
| y | 0,76% | 0,76 | 0,36% | 0,36 |
| z | 0,045% | 0,045 | 0,24% | 0,24 |
Частота появления первых букв слов или имен полезна при предварительном назначении места в физических файлах и индексах. Учитывая 26 ящиков картотеки, а не назначение 1: 1 одного ящика одной букве алфавита, часто бывает полезно использовать код с более равной частотой букв, назначая несколько низкочастотных букв в тот же ящик (часто один ящик обозначается VWXYZ) и для разделения наиболее часто встречающихся начальных букв ('S', 'A' и 'C') на несколько ящиков (часто 6 ящиков Aa-An, Ao- Az, Ca-Cj, Ck-Cz, Sa-Si, Sj-Sz). Та же система используется в некоторых многотомных произведениях, например, в некоторых энциклопедиях. Номера резаков, еще одно сопоставление имен с более равномерно частотным кодом, используются в некоторых библиотеках.
Как общее распределение букв, так и распределение начальных букв слова приблизительно соответствуют распределению Ципфа и даже более точно соответствуют распределению Юла.
Часто частотное распределение первого цифра в каждой системе данных значительно отличается от общей частоты всех цифр в наборе числовых данных, см. закон Бенфорда для получения подробной информации.
Анализ данных Google Книг, проведенный Питером Норвигом, определил, среди прочего, частоту появления первых букв английских слов.
| Letter | Английский | Французский | Немецкий | Испанский | Португальский | Эсперанто | Итальянский | Турецкий | Шведский | Польский | Голландский | Датский | Исландский | Финский | Чешский |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 8,167% | 7,636% | 6,516% | 11,525% | 14,634% | 12.117% | 11.745% | 11.920% | 9.383% | 8.910% | 7,486% | 6,025% | 10,110% | 12,217% | 8,421% |
| b | 1,492% | 0,901% | 1,886 % | 2,215% | 1,043% | 0,980% | 0,927% | 2,844% | 1,535% | 1,470% | 1,584% | 2,000% | 1,043% | 0,281% | 0,822% |
| c | 2,782% | 3,260% | 2,732% | 4,019% | 3,882% | 0,776% | 4,501% | 0.963% | 1.486% | 3.960% | 1.242% | 0,565% | 0 | 0,281% | 0,740% |
| d | 4.253% | 3.669% | 5.076% | 5.010% | 4.992% | 3.044% | 3,736% | 4,706% | 4,702% | 3,250% | 5,933% | 5,858% | 1.575% | 1.043% | 3,475% |
| e | 12.702% | 14.715% | 16.396% | 12,181% | 12.570% | 8.995% | 11.792% | 8.912% | 10.149% | 7,660% | 18.91% | 15.453% | 6.418% | 7.968% | 7.562% |
| f | 2.228% | 1.066 % | 1,656% | 0,692% | 1,023% | 1,037% | 1,153% | 0,461% | 2,027% | 0,300% | 0,805% | 2,406% | 3,013% | 0,194% | 0,084% |
| g | 2.015% | 0.866% | 3.009% | 1.768% | 1.303% | 1,171% | 1.644% | 1.253% | 2.862% | 1.420% | 3.403% | 4.077% | 4,241% | 0,392% | 0,092% |
| h | 6,094% | 0,737% | 4,577% | 0,703 % | 0,781% | 0,384% | 0,636% | 1,212% | 2,090% | 1,080% | 2,380% | 1.621% | 1.871% | 1.851% | 1,356% |
| i | 6.966% | 7,529% | 6,550% | 6,247% | 6,186% | 10,012% | 10,143% | 8,600% * | 5,817% | 8,210% | 6,499% | 6,000% | 7,578% | 10,817% | 6,073% |
| j | 0.153% | 0.613% | 0.268% | 0.493% | 0.397% | 3,501% | 0,011% | 0,034% | 0,614% | 2,280% | 1,46% | 0,730% | 1,144 % | 2,042% | 1,433% |
| k | 0.772% | 0.074% | 1.417% | 0,011% | 0,015% | 4,163% | 0,009% | 4,683% | 3,140% | 3,510% | 2,248% | 3,395% | 3,314% | 4,973% | 2,894% |
| l | 4,025% | 5,456% | 3.437% | 4.967% | 2.779% | 6.104% | 6.510% | 5.922% | 5,275% | 2,100% | 3,568% | 5,229% | 4,532% | 5,761% | 3,802 % |
| m | 2.406% | 2.968% | 2.534% | 3.157% | 4.738% | 2.994% | 2,512% | 3,752 % | 3,471% | 2,800% | 2,213% | 3,237% | 4,041% | 3,202% | 2,446% |
| n | 6.749% | 7.095% | 9.776% | 6.712% | 4.446% | 7,955% | 6,883% | 7,487% | 8,542% | 5,520% | 10,032% | 7,240% | 7.711% | 8.826% | 6.468% |
| o | 7.507% | 5.796% | 2,594% | 8,683% | 9,735% | 8,779% | 9,832% | 2,476% | 4,482% | 7,750 % | 6,063% | 4,636% | 2,166% | 5,614% | 6,695% |
| p | 1,929% | 2,521% | 0,670% | 2,510% | 2,523% | 2,755% | 3,056% | 0,886% | 1,839% | 3,130% | 1,57% | 1,756% | 0,789% | 1,842% | 1.906% |
| q | 0.095% | 1.362% | 0.018% | 0.877% | 1.204% | 0 | 0.505% | 0 | 0.020% | 0.140% | 0.009% | 0.007% | 0 | 0.013% | 0.001% |
| r | 5.987% | 6.693% | 7.003% | 6.871% | 6.530% | 5.914% | 6.367% | 6,722% | 8. 431% | 4,690% | 6,411% | 8,956% | 8,581% | 2,872% | 4,799% |
| s | 6.327% | 7.948% | 7.270% | 7.977% | 6.805% | 6.092% | 4,981% | 3,014% | 6,590% | 4,320% | 3,73% | 5,805% | 5,630 % | 7,862% | 5,212% |
| t | 9,056% | 7.244% | 6,154% | 4,632% | 4,336% | 5,276% | 5,623% | 3,314% | 7,691% | 3,980% | 6,79% | 6,862% | 4,953% | 8,750% | 5,727% |
| u | 2,758% | 6,311% | 4.166% | 2.927% | 3.639% | 3.183% | 3.011% | 3,235% | 1,919% | 2,500% | 1,99% | 1,979% | 4,562% | 5,008% | 2,160 % |
| v | 0.978% | 1.838% | 0.846% | 1.138% | 1.575% | 1.904% | 2,097% | 0,959% | 2,415% | 0,040% | 2,85% | 2,332% | 2,437% | 2,250% | 5,344% |
| w | 2,360% | 0,049% | 1,921% | 0,017% | 0,037% | 0 | 0,033% | 0 | 0,142% | 4,650% | 1,52% | 0,069% | 0 | 0,094% | 0,016% |
| x | 0,150% | 0,427% | 0,034% | 0,215% | 0,253% | 0 | 0,003% | 0 | 0,159% | 0,020% | 0,036% | 0,028% | 0,046% | 0,031% | 0,027% |
| y | 1,974% | 0,128% | 0.039% | 1.008% | 0.006% | 0 | 0.020% | 3.336% | 0.708% | 3.760% | 0.035% | 0.698% | 0.900% | 1.745% | 1.043% |
| z | 0,074% | 0,326% | 1,134% | 0,467% | 0,470% | 0,494% | 1,181% | 1,500 % | 0,070% | 5,640% | 1,39% | 0,034% | 0 | 0,051% | 1,599% |
| à | 0 | 0,486 % | 0 | 0 | 0,072% | 0 | 0,635% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| â | 0 | 0,051% | 0 | 0 | 0,562% | 0 | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| á | 0 | 0 | 0 | 0,502% | 0,118% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,799% | 0 | 0,867% |
| å | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,338% | 0 | 0 | 1,190% | 0 | 0,003% | 0 |
| ä | 0 | 0 | 0,578% | 0 | 0 | 0 | 0 | 0 | 1,797% | 0 | 0 | 0 | 0 | 3,577% | 0 |
| ã | 0 | 0 | 0 | 0 | 0,733% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ą | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,990% | 0 | 0 | 0 | 0 | 0 |
| æ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,872% | 0,867% | 0 | 0 |
| œ | 0 | 0,018% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ç | 0 | 0,085% | 0 | 0 | 0,530% | 0 | 0 | 1,156% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĉ | 0 | 0 | 0 | 0 | 0 | 0,657% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ć | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,400% | 0 | 0 | 0 | 0 | 0 |
| č | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,462% |
| ď | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,015% |
| ð | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4,393% | 0 | 0 |
| è | 0 | 0,271% | 0 | 0 | 0 | 0 | 0,263% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| é | 0 | 1,504% | 0 | 0,433% | 0,337% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,647% | 0 | 0,633% |
| ê | 0 | 0,218% | 0 | 0 | 0,450% | 0 | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ë | 0 | 0,008% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ę | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,110% | 0 | 0 | 0 | 0 | 0 |
| ě | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,222% |
| ĝ | 0 | 0 | 0 | 0 | 0 | 0,691% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ğ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,125% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĥ | 0 | 0 | 0 | 0 | 0 | 0,022% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| î | 0 | 0,045% | 0 | 0 | 0 | 0 | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ì | 0 | 0 | 0 | 0 | 0 | 0 | (0,030%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| í | 0 | 0 | 0 | 0,725% | 0,132% | 0 | 0,030% | 0 | 0 | 0 | 0 | 0 | 1,570% | 0 | 1,643% |
| ï | 0 | 0,005% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ı | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5,114% * | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĵ | 0 | 0 | 0 | 0 | 0 | 0,055% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ł | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,820% | 0 | 0 | 0 | 0 | 0 |
| ñ | 0 | 0 | 0 | 0,311% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ń | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,200% | 0 | 0 | 0 | 0 | 0 |
| ň | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,007% |
| ò | 0 | 0 | 0 | 0 | 0 | 0 | 0,002% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ö | 0 | 0 | 0,443% | 0 | 0 | 0 | 0 | 0,777% | 1,305% | 0 | 0 | 0 | 0,777% | 0,444% | 0 |
| ô | 0 | 0,023% | 0 | 0 | 0,635% | 0 | ~ 0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ó | 0 | 0 | 0 | 0,827 % | 0,296% | 0 | ~ 0% | 0 | 0 | 0,850% | 0 | 0 | 0,994% | 0 | 0,024% |
| õ | 0 | 0 | 0 | 0 | 0,040% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ø | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,939% | 0 | 0 | 0 |
| ř | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,380% |
| ŝ | 0 | 0 | 0 | 0 | 0 | 0,385% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ş | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,780% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ś | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,660% | 0 | 0 | 0 | 0 | 0 |
| š | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,688% |
| ß | 0 | 0 | 0,307% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ť | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,006% |
| þ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1,455% | 0 | 0 |
| ù | 0 | 0,058% | 0 | 0 | 0 | 0 | (0,166%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ú | 0 | 0 | 0 | 0,168% | 0,207% | 0 | 0,166% | 0 | 0 | 0 | 0 | 0 | 0,613% | 0 | 0,045% |
| û | 0 | 0.060% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ŭ | 0 | 0 | 0 | 0 | 0 | 0.520% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ü | 0 | 0 | 0.995% | 0,012% | 0,026% | 0 | 0 | 1,854% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ů | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,204% |
| ý | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,228% | 0 | 0,995% |
| ź | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,060% | 0 | 0 | 0 | 0 | 0 |
| ż | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,830% | 0 | 0 | 0 | 0 | 0 |
| ž | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0,721% |
* См. Пунктирная и без точечная I.
На приведенном ниже рисунке показано частотное распределение 26 наиболее распространенных латинских букв в некоторых языках. Все эти языки используют одинаковый алфавит из 25+ символов.
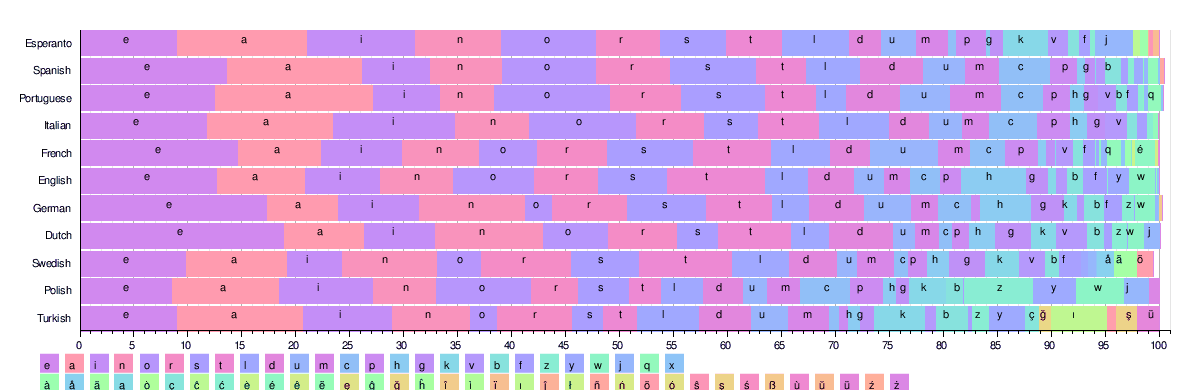
Основываясь на этих таблицах, эквивалентные результаты 'etaoin shrdlu ' для каждого языка выглядят следующим образом:
Некоторые полезные таблицы для частот одной буквы, биграммы, триграммы, тетраграммы и пентаграммы на основе 20 000 слов, которые учитывают комбинации длины слова и положения букв для слов длиной от 3 до 7 букв. Ссылки следующие: