
Войти
A сеть без масштабирования является сетью, распределение степеней которого следует степенному закону, по крайней мере, асимптотически. То есть доля P (k) узлов в сети, имеющая k подключений к другим узлам, идет для больших значений k как

где 

Сообщается, что многие сети не имеют масштабов, хотя статистический анализ опроверг многие из этих утверждений и серьезно поставил под сомнение другие. Предпочтительное присоединение и фитнес-модель были предложены в качестве механизмов для объяснения предполагаемого степенного распределения степеней в реальных сетях.
В исследованиях сетей ссылок между научными статьями Дерек де Солла Прайс в 1965 г. показал, что количество ссылок на pap Число цитирований, которые они получают, имеет распределение с тяжелым хвостом, следующее распределение Парето или степенной закон, и, таким образом, сеть цитирования без масштабирования. Однако он не использовал термин «безмасштабная сеть», который появился несколько десятилетий спустя. В более поздней статье в 1976 году Прайс также предложил механизм для объяснения появления степенных законов в сетях цитирования, который он назвал «кумулятивным преимуществом», но который сегодня более известен под названием предпочтительное присоединение.
Недавний интерес в безмасштабных сетях началась в 1999 году с работы Альберта-Ласло Барабаси и его коллег из Университета Нотр-Дам, которые составили карту топологии части Всемирной паутины, обнаружив, что некоторые узлы, которые они назвали «концентраторами», имели гораздо больше соединений, чем другие, и что сеть в целом имела степенное распределение числа каналов, соединяющихся с узлом. Обнаружив, что несколько других сетей, включая некоторые социальные и биологические сети, также имеют распределение степеней с тяжелым хвостом, Барабаши и его сотрудники придумали термин «безмасштабная сеть» для описания класса сетей, которые демонстрируют степенное распределение степеней. Однако, изучая семь примеров сетей в социальных, экономических, технологических, биологических и физических системах, Amaral et al. среди этих семи примеров не удалось найти немасштабируемую сеть. Только один из этих примеров, сеть киноактеров, имеет распределение степеней P (k), соответствующее степенному режиму для умеренного k, хотя в конечном итоге за этим степенным режимом последовало резкое ограничение, показывающее экспоненциальное затухание для больших k.
Барабаши и Река Альберт предложили порождающий механизм для объяснения появления степенных распределений, который они назвали «предпочтительной привязкой » и который, по сути, совпадает с предложенным Цена. Аналитические решения для этого механизма (также похожие на решение Прайса) были представлены в 2000 г. Дороговцевым, Мендесом и Самухиным и независимо Крапивским, Реднером и Лейвразом, а затем были строго доказаны. математик Бела Боллобас. Примечательно, однако, что этот механизм создает только определенное подмножество сетей в безмасштабном классе, и с тех пор было обнаружено множество альтернативных механизмов.
История безмасштабных сетей также включает некоторые разногласия. На эмпирическом уровне безмасштабный характер некоторых сетей был поставлен под сомнение. Например, три брата Фалаутсос полагали, что Интернет имеет степенное распределение на основе данных traceroute ; однако было высказано предположение, что это иллюзия уровня 3, созданная маршрутизаторами, которые выглядят как узлы высокого уровня, при этом скрывая внутреннюю структуру уровня 2 AS они взаимосвязаны.
На теоретическом уровне были предложены уточнения абстрактного определения «безмасштабный». Например, Ли и др. (2005) недавно предложили потенциально более точную «безмасштабную метрику». Вкратце, пусть G - граф с множеством ребер E, и обозначим степень вершины 


Максимальное значение, когда узлы высокой степени связаны с другими узлы высокой степени. Теперь определите

где s max - максимальное значение s (H) для H в наборе всех графов с распределением степеней, идентичным таковому для G. Это дает метрику от 0 до 1, где граф G с малым S (G) является «богатым масштабом», а граф G с S (G), близким к 1, «безмасштабный». Это определение отражает понятие самоподобия, подразумеваемое в названии «безмасштабный».
Есть два основных компонента, которые объясняют появление свойства отсутствия масштабирования в сложных сетях: рост и предпочтительное присоединение. Под «ростом» понимается процесс роста, при котором в течение длительного периода времени новые узлы присоединяются к уже существующей системе, сети (например, всемирной паутине, которая за 10 лет выросла на миллиарды веб-страниц). Наконец, «предпочтительным присоединением» называется новый приходящий узел, который предпочитает подключаться к другому узлу, который уже имеет определенное количество связей с другими. Таким образом, существует более высокая вероятность того, что все больше и больше узлов будут связываться с тем узлом, который уже имеет много ссылок, что приведет к окончанию этого узла к концентратору. В зависимости от сети концентраторы могут быть либо ассортативными, либо дезассортативными. Ассортативность можно найти в социальных сетях, в которых известные / известные люди будут лучше узнавать друг друга. Дизассортативность может быть обнаружена в технологических (Интернет, World Wide Web) и биологических (взаимодействие белков, метаболизм) сетях.
 Случайная сеть (a) и безмасштабная сеть (b). В безмасштабной сети выделены более крупные концентраторы.
Случайная сеть (a) и безмасштабная сеть (b). В безмасштабной сети выделены более крупные концентраторы. 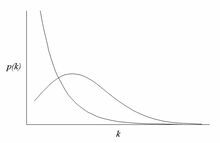 Сложное распределение степени сети случайных и безмасштабных
Сложное распределение степени сети случайных и безмасштабных Наиболее заметной характеристикой безмасштабной сети является относительная общность вершин со степенью превышает средний. Узлы наивысшего уровня часто называют «концентраторами», и считается, что они служат определенным целям в своих сетях, хотя это во многом зависит от домена.
Свойство отсутствия масштабирования сильно коррелирует с устойчивостью сети к сбоям. Оказывается, за крупными узлами следуют более мелкие. За этими меньшими узлами, в свою очередь, следуют другие узлы с еще меньшей степенью и так далее. Эта иерархия допускает отказоустойчивое поведение. Если отказы происходят случайно и подавляющее большинство узлов имеют небольшую степень, вероятность того, что это повлияет на концентратор, почти ничтожна. Даже если произойдет отказ концентратора, сеть, как правило, не потеряет свою связность из-за оставшихся концентраторов. С другой стороны, если мы выберем несколько крупных хабов и вытащим их из сети, сеть превратится в набор довольно изолированных графов. Таким образом, концентраторы являются одновременно сильной стороной и слабостью безмасштабных сетей. Эти свойства были изучены аналитически с использованием теории перколяции Cohen et al и Callaway et al. Коэн и др. Доказали, что для широкого диапазона сетей без масштабирования для 




Другой важной характеристикой безмасштабных сетей является распределение коэффициента кластеризации, которое уменьшается по мере увеличения степени узла. Это распределение также следует степенному закону. Это означает, что узлы с низкой степенью принадлежат очень плотным подграфам, и эти подграфы связаны друг с другом через концентраторы. Рассмотрим социальную сеть, узлами которой являются люди, а ссылками - отношения знакомства между людьми. Легко видеть, что люди склонны объединяться в сообщества, то есть небольшие группы, в которых все знают всех (такое сообщество можно представить как полный граф ). Кроме того, у членов сообщества также есть несколько знакомых отношений с людьми за пределами этого сообщества. Однако некоторые люди связаны с большим количеством сообществ (например, знаменитости, политики). Этих людей можно считать центрами, ответственными за феномен маленького мира.
В настоящее время более специфические характеристики безмасштабных сетей меняются в зависимости от генеративного механизма, используемого для их создания. Например, сети, созданные с помощью предпочтительного присоединения, обычно размещают вершины с высокой степенью в середине сети, соединяя их вместе, чтобы сформировать ядро, а узлы с прогрессивной более низкой степенью составляют области между ядром и периферией. Случайное удаление даже большой части вершин очень мало влияет на общую связность сети, предполагая, что такие топологии могут быть полезны для безопасности, в то время как целевые атаки разрушают связность очень быстро. Другие безмасштабные сети, в которых вершины высокой степени размещаются на периферии, не проявляют этих свойств. Точно так же коэффициент кластеризации безмасштабных сетей может значительно варьироваться в зависимости от других топологических деталей.
Еще одна характеристика касается среднего расстояния между двумя вершинами в сети. Как и в большинстве неупорядоченных сетей, таких как модель сети малого мира, это расстояние очень мало по сравнению с высокоупорядоченной сетью, такой как решетчатый граф. Примечательно, что некоррелированный степенной граф, имеющий 2 < γ < 3 will have ultrasmall diameter d ~ ln ln N where N is the number of nodes in the network, as proved by Cohen and Havlin. Thus, the diameter of a growing scale-free network might be considered almost constant in practice.
Розенфельд и др. Предложили метод создания детерминированных сетей без фрактального масштаба
Вопрос о том, как иммунизировать эффективно масштабируемые свободные сети, которые представляют собой реалистичные сети, такие как Интернет и социальные сети, был тщательно изучен. Одна из таких стратегий состоит в иммунизации узлов с наибольшей степенью, то есть целенаправленных (преднамеренных) атак, поскольку для этого случая p 
Свойства случайного графа могут изменяться или оставаться неизменными при преобразованиях графа. Машаги А. и др., Например, продемонстрировали, что преобразование, которое преобразует случайные графы в их дуальные по ребрам графы (или линейные графы), дает ансамбль графов с почти одинаковым распределением степеней, но со степенью корреляции и значительно более высокий коэффициент кластеризации. Графы без масштабирования, как таковые, остаются без масштабирования при таких преобразованиях.
Хотя многие реальные сети считаются немасштабируемыми, доказательства часто остаются неубедительными, в первую очередь из-за растущее понимание более строгих методов анализа данных. Таким образом, безмасштабный характер многих сетей все еще обсуждается в научном сообществе. Вот несколько примеров сетей, заявленных как немасштабируемые:
 Снимок взвешенной планарной стохастической решетки (WPSL).
Снимок взвешенной планарной стохастической решетки (WPSL). Безмасштабная топология имеет были также обнаружены в высокотемпературных сверхпроводниках. Свойства высокотемпературного сверхпроводника - соединения, в котором электроны подчиняются законам квантовой физики и движутся в идеальной синхронности без трения - по-видимому, связаны с фрактальным расположением кажущихся случайными атомами кислорода и искажением решетки.
Ячеистая структура, заполняющая пространство, взвешенная плоская стохастическая решетка (WPSL) недавно была предложена, распределение координационных чисел которой подчиняется степенному закону. Это означает, что в решетке есть несколько блоков, у которых есть удивительно большое количество соседей, с которыми они имеют общие границы. Его построение начинается с инициатора, скажем, квадрата единичной площади, и генератора, который случайным образом делит его на четыре блока. После этого генератор последовательно применяется снова и снова только к одному из доступных блоков, выбранных предпочтительно по отношению к их площадям. Это приводит к разделению квадрата на все более мелкие взаимоисключающие прямоугольные блоки. Двойник WPSL (DWPSL) получается путем замены каждого блока узлом в его центре, а общая граница между блоками с ребром, соединяющим две соответствующие вершины, получается как сеть, распределение степеней которой следует степенному закону. Причина этого в том, что он развивается в соответствии с правилом модели привязки, управляемой посредничеством, которое также воплощает правило предпочтительного подключения, но замаскировано.
Безмасштабные сети возникают не случайно. Эрдеш и Реньи (1960) изучали модель роста графов, в которой на каждом шаге два узла выбираются равномерно случайным образом и между ними вставляется связь. Свойства этих случайных графов отличаются от свойств, обнаруженных в безмасштабных сетях, и поэтому необходима модель для этого процесса роста.
Наиболее широко известная генеративная модель для подмножества безмасштабных сетей - это генеративная модель Барабаши и Альберта (1999) богатый, обогащайся, в которой каждая новая веб-страница создает ссылки на существующие веб-страницы. с распределением вероятностей, которое не является равномерным, но пропорциональным текущей степени загрузки веб-страниц. Эта модель была первоначально изобретена Дереком Дж. Де Солла Прайсом в 1965 году под термином совокупное преимущество, но не стала популярной до тех пор, пока Барабаши заново не открыл результаты под своим нынешним названием (БА Модель ). В соответствии с этим процессом страница с большим количеством внутренних ссылок будет привлекать больше внутренних ссылок, чем обычная страница. Это генерирует степенной закон, но результирующий граф отличается от реального веб-графа другими свойствами, такими как наличие небольших тесно связанных сообществ. Были предложены и изучены более общие модели и характеристики сети. Например, Pachon et al. (2018) предложили вариант генеративной модели богатые становятся богатыми, которая учитывает два разных правила присоединения: предпочтительный механизм присоединения и единый выбор только для самых последних узлов. Обзор см. В книге Дороговцева и Мендеса.
. Несколько иную модель генерации веб-ссылок предложили Пеннок и др. (2002). Они исследовали сообщества, интересующиеся определенной темой, например домашние страницы университетов, публичных компаний, газет или ученых, и отказались от основных узлов сети. В этом случае распределение ссылок больше не было степенным, а напоминало нормальное распределение. Основываясь на этих наблюдениях, авторы предложили генеративную модель, которая сочетает предпочтительную привязанность с базовой вероятностью получения ссылки.
Другой генеративной моделью является модель копия, изученная Kumar et al. (2000), в котором новые узлы выбирают существующий узел случайным образом и копируют часть связей существующего узла. Это также порождает степенной закон.
Рост сетей (добавление новых узлов) не является необходимым условием для создания немасштабируемой сети. Дангалчев (2004) приводит примеры создания статических безмасштабных сетей. Другая возможность (Caldarelli et al. 2002) - рассматривать структуру как статическую и рисовать связь между вершинами в соответствии с определенным свойством двух задействованных вершин. После определения статистического распределения для этих свойств вершин (пригодности) оказывается, что в некоторых случаях статические сети также развивают безмасштабные свойства.
Произошел всплеск активности в области моделирования безмасштабных сложных сетей. Рецепту Барабаши и Альберта последовали несколько вариаций и обобщений, а также переработка предыдущих математических работ. Пока в модели существует степенное распределение , это безмасштабная сеть, а модель этой сети - безмасштабная модель.
Многие реальные сети (приблизительно) безмасштабные и, следовательно, требуют немасштабных моделей для их описания. В схеме Прайса для построения безмасштабной модели необходимы два компонента:
1. Добавление или удаление узлов. Обычно мы концентрируемся на росте сети, то есть на добавлении узлов.
2. Предпочтительное присоединение : 
Обратите внимание, что фитнес-модели (см. Ниже) могут работать также статически, без изменения количества узлов. Следует также иметь в виду, что тот факт, что модели «предпочтительного присоединения» приводят к появлению безмасштабных сетей, не доказывает, что это механизм, лежащий в основе эволюции реальных безмасштабных сетей, поскольку могут существовать различные механизмы в работают в реальных системах, которые, тем не менее, требуют масштабирования.
Было предпринято несколько попыток создать безмасштабные свойства сети. Вот несколько примеров:
Например, первая безмасштабная модель, модель Барабаши – Альберта, имеет предпочтительную линейную привязку 
(Обратите внимание, что еще одна общая особенность 



Дангалчев строит двухуровневую модель, добавляя а второстепенное вложение. Привлекательность узла в модели 2-L зависит не только от количества узлов, связанных с ним, но также от количества связей в каждом из этих узлов.

где C - коэффициент от 0 до 1.
В модели подключения, управляемого посредником (MDA), новый узел, идущий с 



Фактор 

среднее значение IHM в большом


Однако для 


Модель Барабаши – Альберта предполагает, что вероятность 

Крапивский, Реднер и Лейвраз демонстрируют, что безмасштабный характер сети разрушается из-за нелинейного предпочтительного присоединения. Единственный случай, когда топология сети не масштабируется, - это тот случай, когда предпочтительное присоединение асимптотически линейно, то есть 


Таким образом показатель степени распределения может быть настроен на любое значение от 2 до 
Существует еще один вид безмасштабной модели, которая растет согласно к некоторым шаблонам, таким как иерархическая сетевая модель.
итеративная конструкция, ведущая к иерархической сети. Начиная с полностью подключенного кластера из пяти узлов, мы создаем четыре идентичные реплики, соединяющие периферийные узлы каждого кластера с центральным узлом исходного кластера. Из этого мы получаем сеть из 25 узлов (N = 25). Повторяя тот же процесс, мы можем создать еще четыре реплики исходного кластера - четыре периферийных узла каждого из них подключаются к центральному узлу узлов, созданных на первом этапе. Это дает N = 125, и процесс может продолжаться бесконечно.
Идея заключается в том, что связь между двумя вершинами назначается не случайным образом с вероятностью p, равной для всех пар вершин. Скорее для каждой вершины j существует внутренняя пригодность x j, и связь между вершиной i и j создается с вероятностью 

Предполагая, что в основе сети лежит гиперболическая геометрия, можно использовать структуру пространственных сетей для создания безмасштабных распределений степеней. Это неоднородное распределение степеней затем просто отражает отрицательную кривизну и метрические свойства лежащей в основе гиперболической геометрии.
Начиная с безмасштабных графов с низкой степенью коэффициент корреляции и кластеризации, можно генерировать новые графики с гораздо более высокой степенью корреляции и коэффициентами кластеризации, применяя двойное граничное преобразование.
UPA model вариант модели предпочтительной привязанности (предложенный Пачоном и др.), которая учитывает два разных правила привязанности: механизм предпочтительной привязанности (с вероятностью 1-p), который подчеркивает, что система богатых становится богаче, и равномерный выбор (с вероятностью p) для самых последних узлов. Эта модификация интересна для изучения устойчивости безмасштабного поведения распределения степеней. Аналитически доказано, что асимптотически степенное распределение степеней сохраняется.
В контексте теории сетей a масштаб- свободная идеальная сеть - это случайная сеть с распределением степеней, следующим безмасштабным идеальным газом распределением плотности. Эти сети способны воспроизводить распределение по размерам городов и результаты выборов, раскрывая распределение социальных групп по размеру с помощью теории информации в сложных сетях, когда к сети применяется процесс роста конкурентного кластера. В моделях безмасштабных идеальных сетей можно продемонстрировать, что число Данбара является причиной явления, известного как «шесть степеней разделения ».
Для немасштабируемой сети с 


