При изучении графиков и сетей, степень узла в сети - это количество подключений, которые он имеет к другим узлам, а распределение степеней - это распределение вероятностей этих степеней по всей сети.
Содержание
- 1 Определение
- 2 Наблюдаемые распределения степеней
- 3 Распределение избыточных степеней
- 4 Метод генерирующих функций
- 5 Распределение степеней для направленных сетей
- 6 См. Также
- 7 Ссылки
Определение
степень узла в сети (иногда неправильно называемая связностью ) - это количество соединений или ребер узел относится к другим узлам. Если сеть направлена , что означает, что ребра указывают в одном направлении от одного узла к другому, тогда узлы имеют две разные степени: входящую, которая представляет собой количество входящих ребер, и исходящую. степень, которая является количеством исходящих ребер.
Затем определяется степень распределения P (k) сети как доля узлов в сети со степенью k. Таким образом, если в сети всего n узлов и n k из них имеют степень k, мы имеем P (k) = n k / n.
Та же самая информация также иногда представлена в форме распределения кумулятивных степеней, доли узлов со степенью меньше k или даже дополнительного распределения кумулятивной степени, доли узлов со степенью больше или равной до k (1 - C), если рассматривать C как совокупное распределение степеней; то есть дополнение C.
Наблюдаемое распределение степеней
Распределение степеней очень важно при изучении как реальных сетей, таких как Интернет и социальные сети и теоретические сети. Простейшая сетевая модель, например (модель Эрдеша – Реньи) случайный граф, в котором каждый из n узлов независимо связан (или нет) с вероятностью p (или 1 - p), имеет биномиальное распределение степеней k:

(или Пуассон в пределе большого n, если средняя степень  фиксируется). Однако в большинстве сетей в реальном мире распределение степеней сильно отличается от этого. Большинство из них сильно наклонено вправо, что означает, что подавляющее большинство узлов имеют низкую степень, но небольшое количество, известное как «концентраторы», имеет высокую степень. Утверждалось, что некоторые сети, в частности Интернет, всемирная паутина и некоторые социальные сети, имеют распределение степеней, которое приблизительно соответствует степенному закону :
фиксируется). Однако в большинстве сетей в реальном мире распределение степеней сильно отличается от этого. Большинство из них сильно наклонено вправо, что означает, что подавляющее большинство узлов имеют низкую степень, но небольшое количество, известное как «концентраторы», имеет высокую степень. Утверждалось, что некоторые сети, в частности Интернет, всемирная паутина и некоторые социальные сети, имеют распределение степеней, которое приблизительно соответствует степенному закону :  , где γ - постоянная. Такие сети называются безмасштабными сетями и привлекают особое внимание своими структурными и динамическими свойствами. Однако в последнее время были проведены некоторые исследования, основанные на реальных наборах данных, в которых утверждается, что, несмотря на то, что большинство наблюдаемых сетей имеют распределение степеней с толстыми хвостами, они отклоняются от безмасштабных.
, где γ - постоянная. Такие сети называются безмасштабными сетями и привлекают особое внимание своими структурными и динамическими свойствами. Однако в последнее время были проведены некоторые исследования, основанные на реальных наборах данных, в которых утверждается, что, несмотря на то, что большинство наблюдаемых сетей имеют распределение степеней с толстыми хвостами, они отклоняются от безмасштабных.
Распределение избыточных степеней
Распределение избыточных степеней - это распределение вероятности для узла, достигнутого при следовании за ребром, количества других ребер, прикрепленных к этому узлу. Другими словами, это распределение исходящих ссылок от узла, достигнутого при переходе по ссылке.
Предположим, что сеть имеет распределение степеней  , выбирая один узел (случайно или нет) и переходя к одному из его соседей (предполагается, что у этого узла есть хотя бы один сосед), тогда вероятность того, что этот узел будет иметь
, выбирая один узел (случайно или нет) и переходя к одному из его соседей (предполагается, что у этого узла есть хотя бы один сосед), тогда вероятность того, что этот узел будет иметь  соседей, не определяется как . Причина в том, что всякий раз, когда какой-либо узел выбирается в неоднородной сети, более вероятно достичь хобов, следуя за одним из существующих соседей этого узла. Истинная вероятность таких узлов иметь степень равна
соседей, не определяется как . Причина в том, что всякий раз, когда какой-либо узел выбирается в неоднородной сети, более вероятно достичь хобов, следуя за одним из существующих соседей этого узла. Истинная вероятность таких узлов иметь степень равна  , что называется избыточная степень этого узла. В модели конфигурации , в которой корреляции между узлами были проигнорированы, и предполагается, что каждый узел связан с любыми другими узлами в сети с той же вероятностью, распределение избыточных степеней может быть найдено как:
, что называется избыточная степень этого узла. В модели конфигурации , в которой корреляции между узлами были проигнорированы, и предполагается, что каждый узел связан с любыми другими узлами в сети с той же вероятностью, распределение избыточных степеней может быть найдено как:

где  - средний градус (средний градус) модели. Отсюда следует тот факт, что средняя степень соседа любого узла больше, чем средняя степень этого узла. В социальных сетях это означает, что у ваших друзей в среднем больше друзей, чем у вас. Это известно как парадокс дружбы. Можно показать, что сеть может иметь гигантский компонент, если его средняя степень превышения больше единицы:
- средний градус (средний градус) модели. Отсюда следует тот факт, что средняя степень соседа любого узла больше, чем средняя степень этого узла. В социальных сетях это означает, что у ваших друзей в среднем больше друзей, чем у вас. Это известно как парадокс дружбы. Можно показать, что сеть может иметь гигантский компонент, если его средняя степень превышения больше единицы:

Имейте в виду, что последние два уравнения предназначены только для модели конфигурации и позволяют получить распределение избыточных степеней реального -слова сети, мы также должны добавить корреляции степеней.
Метод генерирующих функций
Генерирующие функции можно использовать для вычисления различных свойств случайных сетей. Учитывая распределение степеней и избыточную степень распределение некоторой сети, и res соответственно, можно записать два степенных ряда в следующих формах:
 и
и 
 можно также получить из производных от
можно также получить из производных от  :
:

Если мы знаем производящую функцию для распределения вероятностей , тогда мы можем восстановить значения путем дифференцирования:

Некоторые свойства, например моменты, могут быть легко вычислены из и его производных:


И вообще:
![{\ displaystyle {\ langle k ^ {m} \ rangle} = {\ Biggl [} {{\ bigg (} \ operatorname {x} {\ operatorname {d} \! \ over \ operatorname {dx} \!} {\ biggl)} ^ {m}} G_ {0} (x) {\ Biggl]} _ {x = 1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9906ae36afd8a3c61e56fec3a175c839b8206439)
Для с распределением по Пуассону случайные сети, такие как график ER,  , поэтому теория случайных сетей этого типа особенно проста. Распределения вероятностей для 1-го и 2-го ближайших соседей генерируются функциями и
, поэтому теория случайных сетей этого типа особенно проста. Распределения вероятностей для 1-го и 2-го ближайших соседей генерируются функциями и  . В более широком смысле, распределение
. В более широком смысле, распределение  -го соседа генерируется следующим образом:
-го соседа генерируется следующим образом:
 , с
, с  итераций функции
итераций функции  , действующей на себя.
, действующей на себя.
Среднее число первых соседей,  , равно
, равно  , а среднее количество вторых соседей:
, а среднее количество вторых соседей: ![{\displaystyle c_{2}={\biggl [}{d \over dx}G_{0}{\big (}G_{1}(x){\big)}{\biggl ]}_{x=1}=G_{1}'(1)G'_{0}{\big (}G_{1}(1){\big)}=G_{1}'(1)G'_{0}(1)=G''_{0}(1)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5a226661873e033c63285c727c723aa8422452ce)
Распределение степени для направленных сетей
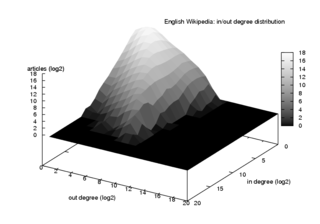
Распределение степени входа / выхода для графа гиперссылок Википедии (логарифмические шкалы)
В направленном сети, каждый узел имеет некоторую внутреннюю степень  и некоторую внешнюю степень
и некоторую внешнюю степень  которые представляют собой количество ссылок, которые должным образом входили и выходили из этого узла. Если
которые представляют собой количество ссылок, которые должным образом входили и выходили из этого узла. Если  - это вероятность того, что случайно выбранный узел имеет внутреннюю степень и out-degree , затем производящая функция, назначенная этому совместному распределению вероятностей можно записать с двумя значениями
- это вероятность того, что случайно выбранный узел имеет внутреннюю степень и out-degree , затем производящая функция, назначенная этому совместному распределению вероятностей можно записать с двумя значениями  и
и  как:
как:

Поскольку каждая ссылка в направленной сети должна выходить из одного узла и входить в другой, чистое среднее количество ссылок, входящих в
узел, равно нулю. Следовательно,
 ,
,
что означает, что поколение функция должна удовлетворять:

где  - средняя степень (как внутри, так и снаружи) узлов. в сети;
- средняя степень (как внутри, так и снаружи) узлов. в сети; 
Использование функции  , мы снова можем найти функцию генерации для распределения внутренних / исходящих степеней и распределения входных / выходных степеней, как и раньше.
, мы снова можем найти функцию генерации для распределения внутренних / исходящих степеней и распределения входных / выходных степеней, как и раньше.  можно определить как производящие функции для количества поступающих ссылок на случайно выбранный узел, а
можно определить как производящие функции для количества поступающих ссылок на случайно выбранный узел, а  можно определить как количество входящих ссылок на узел, достигнутый при переходе по случайно выбранной ссылке. Мы также можем определить производящие функции
можно определить как количество входящих ссылок на узел, достигнутый при переходе по случайно выбранной ссылке. Мы также можем определить производящие функции  и
и  для числа, выходящего из такого узла:
для числа, выходящего из такого узла:




Здесь среднее количество первых соседей, , или, как ранее было указано, , равно  , а среднее количество 2-х соседей, достижимых из случайно выбранного узла, равно:
, а среднее количество 2-х соседей, достижимых из случайно выбранного узла, равно:  . Это также номера 1-го и 2-го соседей, из которых может быть достигнут случайный узел, поскольку эти уравнения явно симметричны в и .
. Это также номера 1-го и 2-го соседей, из которых может быть достигнут случайный узел, поскольку эти уравнения явно симметричны в и .
См. Также
Ссылки
- Albert, R.; Барабаши, А.-Л. (2002). «Статистическая механика сложных сетей». Обзоры современной физики. 74 (1): 47–97. arXiv : cond-mat / 0106096. Bibcode : 2002RvMP... 74... 47A. doi : 10.1103 / RevModPhys.74.47.
- Дороговцев, С.; Мендес, Дж. Ф. Ф. (2002). «Эволюция сетей». Успехи физики. 51 (4): 1079–1187. arXiv : cond-mat / 0106144. Bibcode : 2002AdPhy..51.1079D. doi : 10.1080 / 00018730110112519.
- Ньюман, М. Э. Дж. (2003). «Структура и функции сложных сетей». SIAM Обзор. 45 (2): 167–256. arXiv : cond-mat / 0303516. Bibcode : 2003SIAMR..45..167N. doi : 10.1137 / S003614450342480.
- Шломо Хэвлин и Реувен Коэн (2010). Сложные сети: структура, надежность и функции. Cambridge University Press.

 Распределение степени входа / выхода для графа гиперссылок Википедии (логарифмические шкалы)
Распределение степени входа / выхода для графа гиперссылок Википедии (логарифмические шкалы)