
Войти
Семантическая сеть является расширением World Wide Web через стандарты, установленные World Wide Web Consortium (W3C). Цель семантической паутины - сделать данные Интернета машиночитаемыми. Чтобы включить кодирование семантики с данными, используются такие технологии, как Resource Description Framework (RDF) и Web Ontology Language (OWL). Эти технологии используются для формального представления метаданных. Например, онтология может описывать концепции, отношения между сущностями и категории вещей. Эта встроенная семантика предлагает значительные преимущества, такие как рассуждение над данными и работа с разнородными источниками данных.
Эти стандарты продвигают общие форматы данных и протоколы обмена в Интернете, в основном RDF. Согласно W3C, «Семантическая сеть Web обеспечивает общую структуру, которая позволяет совместно использовать и повторно использовать данные в рамках приложений, предприятий и сообществ». Таким образом, семантическая сеть Web рассматривается как интегратор для различных приложений и систем контента и информации.
Термин был введен Тимом Бернерсом-Ли для обозначения сети данных (или сети данных ), которые могут обрабатываться машинами, то есть сети, в которой значительная часть , означающая, машиночитаема. В то время как критики ставят под сомнение ее осуществимость, сторонники утверждают, что приложения в библиотеке и информатике, промышленности, биологии и исследованиях гуманитарных наук уже доказали обоснованность первоначальной концепции.
Бернерс-Ли первоначально выразил свое видение концепции Семантическая сеть в 1999 году выглядела следующим образом:
У меня есть мечта о сети [в которой компьютеры] станут способны анализировать все данные в сети - контент, ссылки и транзакции между людьми и компьютерами. «Семантическая сеть», которая делает это возможным, еще не появилась, но когда она появится, повседневные механизмы торговли, бюрократии и нашей повседневной жизни будут управляться машинами, разговаривающими с машинами. "интеллектуальные агенты ", которых люди рекламировали веками, наконец материализуется.
Статья Бернерс-Ли, Хендлер и <31, статья 2001 Scientific American 2001 г.>Лассила описал ожидаемую эволюцию существующей сети в семантическую сеть. В 2006 году Бернерс-Ли и его коллеги заявили, что: «Эта простая идея… остается в значительной степени нереализованной». В 2013 году более четырех миллионов веб-доменов содержали разметку семантической сети.
В следующем примере текст «Пауль Шустер родился в Дрездене» на веб-сайте будет снабжен аннотацией, связывающей человека с местом его рождения. Следующий фрагмент HTML показывает, как небольшой граф описывается в синтаксисе RDFa с использованием словаря schema.org и Викиданных ID:
Пол Шустер родился в Дрездене.
 График, полученный из примера RDFa
График, полученный из примера RDFa В примере определены следующие пять троек (показаны в Синтаксис Turtle ). Каждая тройка представляет одно ребро в результирующем графе: первый элемент тройки (субъект) - это имя узла, с которого начинается ребро, второй элемент (предикат) - тип ребра, а последний и третий элемент (объект) либо имя узла, на котором заканчивается край, либо буквальное значение (например, текст, число и т. д.).
_: a <http://www.w3.org/1999/02/22-rdf-syntax-ns#type ><http://schema.org/Person >. _: a <http://schema.org/name >"Пол Шустер". _: a <http://schema.org/birthPlace ><http://www.wikidata.org/entity/Q1731 >. <http://www.wikidata.org/entity/Q1731 ><http://schema.org/itemtype ><http://schema.org/Place >. <http://www.wikidata.org/entity/Q1731 ><http://schema.org/name >«Дрезден».
Результатом троек является график, показанный в на данном рисунке.
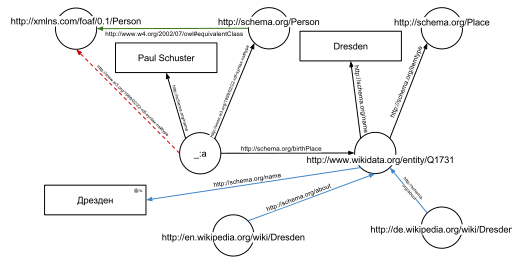 График, полученный из примера RDFa, обогащенный дополнительными данными из Интернета
График, полученный из примера RDFa, обогащенный дополнительными данными из Интернета Одно из преимуществ использования унифицированных идентификаторов ресурсов ( URI) заключается в том, что их можно разыменовать с помощью протокола HTTP. Согласно так называемым принципам связанных открытых данных, такой разыменованный URI должен привести к документу, который предлагает дополнительные данные о данном URI. В этом примере все URI как для ребер, так и для узлов (например, http://schema.org/Person, http://schema.org/birthPlace, http : //www.wikidata.org/entity/Q1731) может быть разыменован и приведет к появлению дополнительных RDF-графиков, описывающих URI, например что Дрезден - это город в Германии, или что человек в смысле этого URI может быть вымышленным.
На втором графике показан предыдущий пример, но теперь он дополнен несколькими тройками из документов, которые являются результатом разыменования http://schema.org/Person(зеленый край) и http://www.wikidata.org/entity/Q1731(синие края).
В дополнение к краям, явно указанным в задействованных документах, края могут быть автоматически выведены: тройка
_: a <http://www.w3.org/1999/02/22- rdf-syntax-ns # type ><http://schema.org/Person >.
из исходного фрагмента RDFa и тройного
<http://schema.org/Person ><http://www.w3.org/2002/07/owl#equivalentClass ><http://xmlns.com/foaf/0.1/Person >.
из документа по адресу http://schema.org/Person(зеленый край на рисунке) позволяют вывести следующую тройку, учитывая семантику OWL (красная пунктирная линия на второй рисунок):
_: a <http://www.w3.org/1999/02/22-rdf-syntax-ns#type ><http: // xmlns. com / foaf / 0.1 / Person >.
Концепция модели семантической сети была сформирована в начале 1960-х такими исследователями, как когнитивист Аллан М. Коллинз, лингвист М. Росс Куиллиан и психолог Элизабет Ф. Лофтус как форма представления семантически структурированного знания. При применении в контексте современного Интернета он расширяет сеть гиперссылок удобочитаемых веб-страниц, вставляя машиночитаемые метаданные о страницах и о том, как они связаны друг с другом. Это позволяет автоматическим агентам получать более интеллектуальный доступ к Интернету и выполнять больше задач от имени пользователей. Термин «семантическая паутина» был введен Тимом Бернерсом-Ли, изобретателем Всемирной паутины и директором Консорциума Всемирной паутины («W3C "), который наблюдает за разработкой предлагаемых стандартов семантической сети. Он определяет семантическую сеть как «сеть данных, которые могут прямо или косвенно обрабатываться машинами».
Многие технологии, предложенные W3C, уже существовали до того, как они были размещены под зонтиком W3C. Они используются в различных контекстах, особенно в тех, которые имеют дело с информацией, которая охватывает ограниченную и определенную область, и где совместное использование данных является общей необходимостью, например, в научных исследованиях или обмене данными между предприятиями. Кроме того, появились другие технологии с аналогичными целями, такие как микроформаты.
Многие файлы на обычном компьютере также могут быть условно разделены на удобочитаемые документы и машиночитаемые данные. Такие документы, как почтовые сообщения, отчеты и брошюры, читают люди. Данные, такие как календари, адресные книги, списки воспроизведения и электронные таблицы, представлены с помощью прикладной программы, которая позволяет их просматривать, искать и комбинировать.
В настоящее время Всемирная паутина в основном основана на документах, написанных на языке гипертекстовой разметки (HTML ), соглашении о разметке, которое используется для кодирования основного текста. перемежается с мультимедийными объектами, такими как изображения и интерактивные формы. Теги метаданных предоставляют метод, с помощью которого компьютеры могут классифицировать содержимое веб-страниц. В приведенных ниже примерах названиям полей «ключевые слова», «описание» и «автор» присвоены такие значения, как «вычисления», «дешевые виджеты для продажи» и «Джон Доу».
Благодаря этой маркировке метаданных и категоризации другие компьютерные системы, которые хотят получить доступ к этим данным и поделиться ими, могут легко идентифицировать соответствующие значения.
С помощью HTML и инструмента для его визуализации (возможно, программное обеспечение веб-браузера, возможно, другой пользовательский агент ), можно создать и представить страницу со списком товаров для продажи. HTML-код этой страницы каталога может делать простые утверждения на уровне документа, такие как «заголовок этого документа - 'Widget Superstore'», но в самом HTML нет возможности однозначно утверждать, что, например, номер позиции X586172 является Acme Гизмо с розничной ценой 199 евро или потребительский товар. Скорее, HTML может только сказать, что диапазон текста «X586172» - это то, что следует расположить рядом с «Acme Gizmo», «199 евро» и т. Д. Нет способа сказать «это каталог» или даже установить, что «Acme Gizmo» - это что-то вроде названия или 199 евро - это цена. Также невозможно выразить, что эти фрагменты информации связаны вместе при описании отдельного элемента, отличного от других элементов, которые, возможно, перечислены на странице.
Семантический HTML относится к традиционной практике HTML разметки в соответствии с намерением, а не непосредственного указания деталей макета. Например, использование , обозначающего «акцент», а не , которое указывает курсивом. Детали макета оставлены на усмотрение браузера в сочетании с каскадными таблицами стилей. Но эта практика не позволяет определить семантику таких объектов, как товары для продажи или цены.
Микроформаты расширяют синтаксис HTML для создания машиночитаемой семантической разметки об объектах, включая людей, организации, события и продукты. Подобные инициативы включают RDFa, Microdata и Schema.org.
Семантическая паутина продвигает решение дальше. Он включает публикацию на языках, специально разработанных для данных: Resource Description Framework (RDF), Web Ontology Language (OWL) и Extensible Markup Language (XML ). HTML описывает документы и связи между ними. RDF, OWL и XML, напротив, могут описывать произвольные вещи, такие как люди, собрания или детали самолетов.
Эти технологии объединены для предоставления описаний, дополняющих или заменяющих содержание веб-документов. Таким образом, контент может проявляться как описательные данные, хранящиеся в доступных через Интернет базах данных, или как разметка в документах (в частности, в Extensible HTML (XHTML ) с вкраплениями XML, или, что чаще,, чисто в XML, с хранением сигналов макета или рендеринга отдельно). Машиночитаемые описания позволяют менеджерам контента добавлять смысл в контент, то есть описывать структуру наших знаний об этом контенте. Таким образом, машина может обрабатывать знания сама, а не текст, используя процессы, подобные человеческим дедуктивным рассуждениям и логическим выводам, тем самым получая более значимые результаты и помогая компьютерам выполнять автоматический сбор информации. и исследования.
Пример тега, который будет использоваться на несемантической веб-странице:
- blog
Кодирование аналогичной информации на семантической веб-странице может выглядеть следующим образом:
- Семантическая сеть
Тим Бернерс-Ли называет результирующую сеть связанных данных Giant Global Graph, в отличие от основанной на HTML World Wide Web. Бернерс-Ли утверждает, что если в прошлом было совместное использование документов, то будущее - это совместное использование данных. Его ответ на вопрос «как» дает три указания. Во-первых, URL-адрес должен указывать на данные. Во-вторых, любой, кто обращается к URL-адресу, должен вернуть данные. В-третьих, отношения в данных должны указывать на дополнительные URL-адреса с данными.
Тим Бернерс-Ли описал семантическую сеть как компонент Web 3.0 .
Люди продолжают спрашивать, что такое Web 3.0. Я думаю, может быть, когда у вас есть наложение масштабируемой векторной графики - все рябит, складывается и выглядит туманным - на Web 2.0 и доступ к семантической сети, интегрированной на огромном пространстве данных, у вас будет доступ к невероятному ресурсу данных…
— Тим Бернерс-Ли, 2006«Семантическая паутина» иногда используется как синоним «Веб 3.0», хотя определение каждого термина варьируется. Web 3.0 начал возникать как движение от централизации таких сервисов, как поиск, социальные сети и чат-приложения, функционирование которых зависит от одной организации.
Guardian журналист Джон Харрис положительно оценил концепцию Web 3.0 в начале 2019 года и, в частности, работу Бернерс-Ли над проектом Solid, основанным на хранилищах личных данных или «модулях», над которыми работают отдельные лица. сохранить контроль. Бернерс-Ли создал стартап Inrupt, чтобы продвигать идею и привлекать разработчиков-добровольцев.
Некоторые из проблем Семантической паутины включают обширность, неопределенность, неопределенность, непоследовательность и обман. Автоматизированные системы рассуждений должны будут иметь дело со всеми этими проблемами, чтобы выполнить обещание Семантической паутины.
Этот список проблем является скорее иллюстративным, чем исчерпывающим, и он фокусируется на вызовах «объединяющей логике» и «доказательству» уровней Семантической паутины. Итоговый отчет Группы инкубаторов Консорциума World Wide Web (W3C) по обоснованию неопределенности для World Wide Web (URW3-XG) объединяет эти проблемы под одним заголовком «неопределенность». Многие из упомянутых здесь методов потребуют расширений для языка веб-онтологий (OWL), например, для аннотирования условных вероятностей. Это область активных исследований.
Стандартизация семантической сети в контексте Web 3.0 находится под контролем W3C.
Термин «семантическая сеть Интернет» часто используется более конкретно для обозначения форматов и технологий, которые его обеспечивают. Сбор, структурирование и восстановление связанных данных обеспечивается технологиями, которые обеспечивают формальное описание концепций, терминов и отношений в пределах заданной области знаний. Эти технологии определены как стандарты W3C и включают:
 Стек семантической паутины
Стек семантической паутины Стек семантической паутины иллюстрирует архитектуру семантической паутины. Функции и отношения компонентов можно резюмировать следующим образом:
Установленные стандарты:
Еще не полностью реализован:
Цель состоит в том, чтобы повысить удобство использования и полезность Интернета и его взаимосвязанных ресурсы путем создания семантических веб-сервисов, таких как:
. Такие службы могут быть полезны для общедоступных поисковых систем или могут использоваться для управления знаниями в рамках организация. Бизнес-приложения включают:
В корпорации существует замкнутая группа пользователей и руководство может обеспечить соблюдение руководящих принципов компании, таких как принятие конкретных онтологий и использование семантической аннотации. По сравнению с общедоступной семантической сетью требования к масштабируемости меньше, и в целом можно больше доверять информации, циркулирующей внутри компании; конфиденциальность не является проблемой вне обработки данных клиентов.
Критики ставят под сомнение базовую осуществимость полного или даже частичного выполнения Семантической паутины, указывая как на трудности ее создания, так и на отсутствие универсальной полезности, не позволяющей вложить необходимые усилия. В статье 2003 года Маршалл и Шипман указывают на когнитивные накладные расходы, связанные с формализацией знаний, по сравнению с созданием традиционного веб-гипертекста :
Хотя изучение основ HTML относительно несложно, для изучения языка представления знаний или инструмента требуется автору, чтобы узнать о методах абстракции представления и их влиянии на рассуждения. Например, понимание отношения класс-экземпляр или отношения суперкласс-подкласс - это больше, чем понимание того, что одно понятие является «типом» другого понятия. […] Этим абстракциям преподают компьютерных ученых в целом и инженеров по знаниям в частности, но они не соответствуют аналогичному естественному языковому значению «типа» чего-либо. Эффективное использование такого формального представления требует, чтобы автор стал квалифицированным инженером по знаниям в дополнение к любым другим навыкам, необходимым в предметной области. […] После того, как кто-то изучает формальный язык представления, часто бывает гораздо больше усилий для выражения идей в этом представлении, чем в менее формальном представлении […]. Действительно, это форма программирования, основанная на объявлении семантических данных и требующая понимания того, как алгоритмы рассуждений будут интерпретировать созданные структуры.
Согласно Маршаллу и Шипману, неявный и изменяющийся характер многие знания добавляют к проблеме инженерии знаний и ограничивают применимость семантической паутины к определенным доменам. Еще одна проблема, на которую они указывают, - это специфические для домена или организации способы выражения знаний, которые должны быть решены посредством согласия сообщества, а не только техническими средствами. Как оказалось, специализированные сообщества и организации для внутрикорпоративных проектов имели тенденцию принимать технологии семантической паутины в большей степени, чем периферийные и менее специализированные сообщества. Практические ограничения для принятия оказались менее сложными там, где область и сфера применения более ограничены, чем у широкой публики и всемирной паутины.
Наконец, Маршалл и Шипман видят прагматические проблемы в идее («Навигатор знаний» в стиле ) интеллектуальные агенты, работающие в семантической сети, в значительной степени управляемой вручную:
В ситуациях, когда потребности пользователей известны, а распределенные информационные ресурсы хорошо описаны, этот подход может быть очень эффективным; в непредвиденных ситуациях, которые объединяют непредвиденный массив информационных ресурсов, подход Google более надежен. Более того, семантическая сеть Web полагается на более хрупкие цепочки вывода; недостающий элемент цепочки приводит к неспособности выполнить желаемое действие, в то время как человек может предоставить недостающие части, используя подход, более похожий на Google. […] Компромисс между затратами и выгодой может работать в пользу специально созданных метаданных Семантической паутины, направленных на объединение воедино разумных, хорошо структурированных информационных ресурсов, специфичных для предметной области; пристальное внимание к потребностям пользователей / клиентов будет способствовать успеху этих федераций.
Критика Кори Доктороу («метакрап ») основана на человеческом поведении и личных предпочтениях. Например, люди могут включать в веб-страницы ложные метаданные, пытаясь ввести в заблуждение механизмы семантической паутины, которые наивно предполагают достоверность метаданных. Этот феномен был хорошо известен благодаря метатегам, обманывающим алгоритм ранжирования Altavista для повышения рейтинга определенных веб-страниц: механизм индексации Google специально ищет такие попытки манипуляции. Питер Гарденфорс и Тимо Хонкела указывают, что семантические веб-технологии, основанные на логике, охватывают лишь часть соответствующих явлений, связанных с семантикой.
Энтузиазм по поводу семантической сети может быть смягчен опасениями по поводу цензуры и конфиденциальности. Например, методы анализа текста теперь можно легко обойти, используя другие слова, например, метафоры, или используя изображения вместо слов. Усовершенствованная реализация семантической сети упростит для правительств контроль над просмотром и созданием онлайн-информации, поскольку эту информацию будет намного легче понять автоматизированной машине блокировки контента. Кроме того, поднимался вопрос о том, что при использовании файлов FOAF и геолокации метаданных анонимность, связанная с авторством статей на такие темы, как как личный блог. Некоторые из этих проблем были рассмотрены в проекте «Policy Aware Web», который является активной темой исследований и разработок.
Еще одна критика семантической паутины заключается в том, что создание и публикация контента потребует гораздо больше времени, поскольку для одного фрагмента данных потребуется два формата: один для просмотра людьми и один для машин. Однако многие разрабатываемые веб-приложения решают эту проблему, создавая машиночитаемый формат после публикации данных или запроса машины на получение таких данных. Разработка микроформатов была одной из реакций на такого рода критику. Еще один аргумент в защиту возможности семантической паутины - это вероятное падение стоимости задач человеческого интеллекта на цифровых рынках труда, таких как Amazon Mechanical Turk.
, такие как eRDF. и RDFa позволяют встраивать произвольные данные RDF в HTML-страницы. Механизм GRDDL (Сбор описаний ресурсов из диалектов языка) позволяет автоматически интерпретировать существующий материал (включая микроформаты) как RDF, поэтому издателям нужно использовать только один формат, например HTML.
Первой исследовательской группой, явно фокусирующейся на корпоративной семантической сети, была группа ACACIA в INRIA-Sophia-Antipolis, основанная в 2002 году. Результаты их работы включают поисковую систему Corese на основе RDF (S) и применение семантических веб-технологий в сфере электронного обучения.
. Исследовательская группа корпоративной семантической сети, расположенная в Свободном университете Берлина, специализируется на строительных блоках: корпоративном семантическом поиске, корпоративном семантическом сотрудничестве и разработке корпоративных онтологий.
Инженерные исследования онтологий включают этот вопрос о том, как привлекать неопытных пользователей к созданию онтологий и семантически аннотированного контента, а также для извлечения явных знаний из взаимодействия пользователей внутри предприятий.
Тим О'Рейли, придумавший термин Web 2.0, предложил долгосрочное видение Семантической паутины как сети данных, в которой сложные приложения манипулируют сетью данных. Сеть данных преобразует World Wide Web из распределенной файловой системы в распределенную систему баз данных.