
Войти
A телеграфный код - это одна из кодировок символов, используемых для передачи информации по телеграфии. Азбука Морзе - самый известный такой код. Телеграфом обычно называют электрический телеграф, но телеграфные системы, использующие оптический телеграф, использовались и до этого. Код состоит из ряда кодовых точек, каждая из которых соответствует букве алфавита, цифре или некоторому другому символу. В кодах, предназначенных для машин, а не людей, требуются кодовые точки для управляющих символов, таких как возврат каретки, для управления работой механизма. Каждая кодовая точка состоит из ряда элементов, расположенных уникальным образом для этого символа. Обычно существует два типа элементов (двоичный код), но в некоторых кодах, не предназначенных для машин, использовалось больше типов элементов. Например, Американский код Морзе имел около пяти элементов, а не два (точка и тире) из Международного кода Морзе.
. Коды, предназначенные для интерпретации человеком, были разработаны таким образом, что символы, которые встречаются чаще всего часто имеет наименьшее количество элементов в соответствующей кодовой точке. Например, код Морзе для E, самой распространенной буквы в английском языке, представляет собой одну точку (▄▄▄▄), тогда как Q - это ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄. Эти меры означали, что сообщение может быть отправлено быстрее, и оператору потребуется больше времени, чтобы устать. Телеграфы всегда использовались людьми до конца XIX века. Когда появились автоматизированные телеграфные сообщения, коды с кодовыми точками переменной длины были неудобны для проектирования машин. Вместо этого использовались коды фиксированной длины. Первым из них был код Бодо, пяти- битный код. У Бодо достаточно кодовых точек только для печати в верхнем регистре. В более поздних кодах было больше битов (ASCII их семь), так что можно было печатать как верхний, так и нижний регистр. За пределами эпохи телеграфа современным компьютерам требуется очень большое количество кодовых точек (Unicode имеет 21 бит), чтобы можно было обрабатывать несколько языков и алфавитов (наборы символов ) без необходимости изменения кодировка символов.
 Код Чаппе c. 1794 г.
Код Чаппе c. 1794 г. До появления электрического телеграфа широко используемым методом построения национальных телеграфных сетей был оптический телеграф, состоящий из цепочки башен, с которых сигналы могли передаваться семафором или ставнями от башни к башне. Это было особенно развито во Франции и зародилось во время Французской революции. Код, используемый во Франции, был кодом Chappe, названным в честь изобретателя Клода Шаппа. Британское Адмиралтейство также использовало семафорный телеграф, но со своим собственным кодом. Британский код обязательно отличался от французского, потому что британский оптический телеграф работал иначе. Система Чаппа имела подвижные руки, как если бы она развевала флаги, как в семафор флагов. В британской системе использовался ряд створок, которые можно было открывать или закрывать.
Система Чаппа состояла из большой поворотной балки (регулятора) с рычагами на каждом конце ( индикаторы), которые вращались вокруг регулятора на одном конце. Углы, которые разрешалось принимать этим компонентам, были ограничены кратными 45 ° для облегчения считывания. Это дало пространство для кода 8 × 4 × 8 кодовых точек, но положение индикатора на линии регулятора никогда не использовалось, потому что его было трудно отличить от индикатора, который складывался наверху регулятора, оставляя кодовое пространство 7 × 4 × 7 = 196. Символы всегда формировались с регулятором на левой или правой диагонали (наклонной) и принимались как действительные только тогда, когда регулятор перемещался либо в вертикальное, либо в горизонтальное положение. Левый наклон всегда использовался для сообщений, а правый наклонный - для управления системой. Это дополнительно уменьшило пространство кода до 98, из которых четыре или шесть кодовых точек (в зависимости от версии) были управляющими символами, оставляя пространство кода для текста 94 или 92 соответственно.
Система Chappe в основном передавала сообщения с использованием кодовой книги с большим количеством заданных слов и фраз. Впервые он был использован на экспериментальной цепочке башен в 1793 году и введен в эксплуатацию от Парижа до Лилля в 1794 году. Кодовая книга, использованная в этой ранней стадии, доподлинно неизвестна, но неопознанная кодовая книга в Парижский почтовый музей, возможно, принадлежал системе Чаппе. Расположение этого кода в столбцах по 88 записей привело Holzmann Pehrson к предположению, что могло быть использовано 88 кодовых точек. Однако предложение 1793 г. касалось десяти кодовых точек, представляющих цифры 0–9, и Буше говорит, что эта система все еще использовалась до 1800 г. (Хольцманн и Пирсон поместили изменение в 1795 г.). Кодовая книга была пересмотрена и упрощена в 1795 году для ускорения передачи. Код состоял из двух частей, первая часть состояла из 94 буквенных и цифровых символов, а также некоторых часто используемых комбинаций букв. Второй раздел представлял собой кодовую книгу из 94 страниц с 94 записями на каждой странице. Кодовая точка была назначена для каждого числа до 94. Таким образом, для передачи всего предложения нужно было отправить только два символа - номера страницы и строки кодовой книги, по сравнению с четырьмя символами при использовании десятисимвольного кода.
В 1799 году были добавлены три дополнительных подразделения. В них были дополнительные слова и фразы, географические места и имена людей. Эти три раздела требовали добавления дополнительных символов перед символом кода, чтобы идентифицировать правильную книгу. Код был снова пересмотрен в 1809 году и после этого оставался стабильным. В 1837 году Габриэль Флокон ввел горизонтальную систему кодирования, которая не требовала перемещения тяжелого регулятора. Вместо этого в центре регулятора был предусмотрен дополнительный индикатор для передачи этого элемента кода.
 Код главы c. 1809
Код главы c. 1809  код Эделькранца 636, который декодируется под девиз Телеграфного корпуса; Passa väl upp («Будь на страже»)
код Эделькранца 636, который декодируется под девиз Телеграфного корпуса; Passa väl upp («Будь на страже») Система Edelcrantz использовалась в Швеции и была второй по величине сетью, построенной после Франции. Телеграф состоял из десяти ставен. Девять из них были расположены в матрице 3 × 3. Каждый столбец заслонок представлял собой восьмеричную цифру с двоичным кодом с закрытой заслонкой, представляющей «1» и наиболее значительную цифру внизу. Таким образом, каждый символ телеграфной передачи представлял собой трехзначное восьмеричное число. Десятый ставень был очень большим наверху. Это означало, что перед кодовой точкой должна стоять буква «A».
Одно из применений шторки «А» заключалось в том, что числовой код, которому предшествовала «А», означал прибавление нуля (умножение на десять) к цифре. Большие числа могут быть обозначены следующим за цифрой кодом для сотен (236), тысяч (631) или их комбинации. Это потребовало передачи меньшего количества символов, чем отправка всех нулевых цифр по отдельности. Однако основная цель кодовых точек «A» заключалась в создании кодовой книги заранее определенных сообщений, очень похожей на кодовую книгу Чаппа.
Символы без «А» представляли собой большой набор цифр, букв, общих слогов и слов для облегчения уплотнения кода. Примерно в 1809 году Эделькранц представил новую кодовую книгу с 5120 кодовыми точками, каждая из которых требует передачи двух символов для идентификации.
| A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P | Q | R | S | T |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 003 | 026 | ✗ | 055 | 112 | 125 | 162 | 210 | 254 | ✗ | 274 | 325 | 362 | 422 | 450 | 462 | ✗ | 500 | 530 | 610 |
| U | V | W | X | Y | Z | Å | Ä | Ö | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 00 | 000 |
| 640 | 650 | ✗ | 710 | 711 | 712 | 713 | 723 | 737 | 001 | 002 | 004 | 010 | 020 | 040 | 100 | 200 | 400 | 236 | 631 |
Было много кодовых точек для исправления ошибок (272, ошибка), управления потоком и контрольных сообщений. Обычно предполагалось, что сообщения будут передаваться по всей линии, но были обстоятельства, когда отдельным станциям требовалось связываться напрямую, обычно для управленческих целей. Наиболее распространенной и простой ситуацией была связь между соседними станциями. Кодовые точки 722 и 227 использовались для этой цели, чтобы привлечь внимание следующей станции к солнцу или от него соответственно. Для более удаленных станций использовались кодовые точки 557 и 755 соответственно, после чего следовала идентификация запрашивающей и целевой станций.
Флаговая сигнализация широко использовалась для передачи сигналов точка-точка. до оптического телеграфа, но было трудно построить общенациональную сеть с переносными флажками. Требовалось гораздо более крупное механическое устройство семафорных телеграфных башен, чтобы можно было добиться большего расстояния между линиями связи. Однако во время Гражданской войны в США была создана обширная сеть с переносными флагами. Это была система wig-wag, в которой использовался код, изобретенный Альбертом Дж. Майером. Некоторые из использованных башен были огромными, до 130 футов, для хорошей дальности. Код Майера требовал только одного флага с использованием троичного кода . То есть каждый элемент кода состоял из одной из трех различных позиций флага. Однако для алфавитных кодовых точек требуется только две позиции, третья позиция используется только в управляющих символах. Использование троичного кода в алфавите привело бы к более коротким сообщениям, поскольку в каждой кодовой точке требуется меньшее количество элементов, но двоичную систему легче читать на большом расстоянии, поскольку необходимо различать меньшее количество позиций флагов. В руководстве Майера также описан троичный алфавит с фиксированной длиной из трех элементов для каждой кодовой точки.
 Кук и Уитстон 1- Код иглы (C W1)
Кук и Уитстон 1- Код иглы (C W1) Во время раннего развития электрического телеграфа было изобретено множество различных кодов. Практически каждый изобретатель создавал свой код для своего конкретного устройства. Самым ранним кодом, коммерчески использовавшимся на электрическом телеграфе, был пятистрочный код телеграфа Кука и Уитстона (C W5). Впервые он был использован на Great Western Railway в 1838 году. C W5 имел главное преимущество, заключающееся в том, что оператору не нужно было изучать код; буквы можно было прочитать прямо с дисплея. Однако у него был недостаток: требовалось слишком много проводов. Был разработан код с одной иглой C W1, для которого требовался только один провод. C W1 широко использовался в Великобритании и Британской империи.
 Американский код Морзе
Американский код Морзе Некоторые другие страны использовали C W1, но он так и не стал международным стандартом, и, как правило, каждая страна разработала свой собственный код. В США использовался американский код Морзе, элементы которого состояли из точек и тире, отличающихся друг от друга длиной импульса тока на телеграфной линии. Этот код использовался на телеграфе, изобретенном Сэмюэлем Морсом и Альфредом Вейлом, и впервые был использован в коммерческих целях в 1844 году. Первоначально у Морзе были кодовые точки только для цифр. Он планировал, что числа, отправленные по телеграфу, будут использоваться в качестве индекса к словарю с ограниченным набором слов. Вейл изобрел расширенный код, который включал кодовые точки для всех букв, чтобы можно было отправить любое желаемое слово. Код Вейла превратился в американский код Морзе. Во Франции телеграф использовал телеграф Фуа-Бреге, телеграф с двумя иглами, который отображал иглы в коде Чаппе, тот же код, что и французский оптический телеграф, который все еще использовался более широко, чем электрический телеграф. во Франции. Для французов это было большим преимуществом, поскольку им не нужно было переучивать своих операторов новому коду.
 Международная азбука Морзе
Международная азбука Морзе В Германии в 1848 г. Фридрих Клеменс Герке разработал сильно модифицированную версию американского Морзе для использования на немецких железных дорогах. У American Morse было три разных длины тире и две разные длины промежутка между точками и тире в кодовой точке. В коде Герке было только одно тире, и все межэлементные промежутки в кодовой точке были равны. Герке также создал кодовые точки для немецких букв умляут, которых нет в английском языке. Многие страны Центральной Европы входили в Немецко-австрийский телеграфный союз. В 1851 году Союз решил принять общий код для всех своих стран, чтобы сообщения могли пересылаться между ними без необходимости для операторов перекодировать их на границах. Для этого был принят кодекс Герке.
В 1865 году конференция в Париже приняла код Герке в качестве международного стандарта, назвав его Международным кодом Морзе. С некоторыми очень незначительными изменениями это код Морзе, используемый сегодня. Стрелочные телеграфные приборы Кука и Уитстона были способны использовать азбуку Морзе, поскольку точки и тире можно было посылать при перемещении стрелки влево и вправо. К этому времени игольчатые инструменты изготавливались с концевыми упорами, которые при ударе иглы делали две совершенно разные ноты. Это позволило оператору написать сообщение, не глядя на иглу, что было намного эффективнее. Это было аналогичное преимущество телеграфа Морзе, в котором операторы могли слышать сообщение от щелчка якоря реле. Тем не менее, после национализации британских телеграфных компаний в 1870 году Главное почтовое управление решило стандартизировать телеграф Морзе и избавиться от множества различных систем, унаследованных от частных компаний.
В США телеграфные компании отказались от использования International Morse из-за затрат на переподготовку операторов. Они выступили против попыток правительства сделать это законом. В большинстве других стран телеграф находился под контролем государства, поэтому изменение можно было просто санкционировать. В США телеграфом управляла не одна организация. Скорее всего, это было множество частных компаний. В результате международные операторы должны были свободно владеть обеими версиями Морзе и перекодировать как входящие, так и исходящие сообщения. США продолжали использовать американскую Морзе на стационарные телефоны (радиотелеграфия обычно используется Международная Морзе), и это оставалось дело до появления телепринтеров которые требовали совершенно различные коды и визуализации эмиссии спорным.
 Одна страница из китайской кодовой книги телеграфа
Одна страница из китайской кодовой книги телеграфа Скорость отправки в ручном телеграфе ограничена скоростью, которую оператор может отправить каждый элемент кода. Скорость обычно указывается в словах в минуту. У всех слов разная длина, поэтому буквальный подсчет слов даст разный результат в зависимости от содержания сообщения. Вместо этого слово определяется как пять символов с целью измерения скорости, независимо от того, сколько слов фактически содержится в сообщении. Код Морзе и многие другие коды также не имеют одинаковой длины кода для каждого символа слова, что снова вводит переменную, связанную с содержанием. Чтобы преодолеть это, используется скорость, с которой оператор многократно передает стандартное слово. PARIS обычно выбирается в качестве этого стандарта, потому что это длина среднего слова в азбуке Морзе.
В американском азбуке Морзе символы обычно короче, чем в международном азбуке Морзе. Отчасти это связано с тем, что в American Morse используется больше точечных элементов, а отчасти потому, что наиболее распространенное тире, короткое тире, короче, чем международное тире Морзе - два точечных элемента против трех точечных элементов в длину. В принципе, американская азбука Морзе будет передаваться быстрее, чем международная азбука Морзе, если все другие переменные равны. На практике есть два момента, которые отвлекают от этого. Во-первых, американскому Морзе с примерно пятью элементами кодирования было труднее определить время при быстрой отправке. Неопытные операторы были склонны отправлять искаженные сообщения - эффект, известный как hog Morse. Вторая причина заключается в том, что американец Морзе более склонен к межсимвольной интерференции (ISI) из-за большей плотности близко расположенных точек. Эта проблема была особенно серьезной с подводными телеграфными кабелями, что делало American Morse менее подходящим для международной связи. Единственное решение, которое оператор должен был немедленно решить с ISI, - это снизить скорость передачи.
Код Морзе для нелатинских алфавитов, таких как кириллица или арабский шрифт, достигается путем построения кодировки символов для рассматриваемого алфавита с использованием тех же или почти тех же кодовых точек, что и в латинском алфавите.. Слоговые словари, такие как японская катакана, также обрабатываются таким же образом (код вабуна ). Альтернатива добавления дополнительных кодовых точек к коду Морзе для каждого нового символа приведет к тому, что передача кода будет очень длинной на некоторых языках.
Языки, использующие логограммы, труднее обрабатывать из-за требуется гораздо большее количество символов. Китайский телеграфный код использует кодовую книгу примерно из 9800 знаков (7000 при запуске в 1871 году), каждому из которых присвоен четырехзначный номер. Именно эти числа передаются, поэтому китайский код Морзе целиком состоит из цифр. Номера нужно искать на принимающей стороне, что делает этот процесс медленным, но в эпоху, когда широко использовался телеграф, опытные китайские телеграфисты могли вспоминать по памяти многие тысячи общих кодов. Китайский телеграфный код до сих пор используется правоохранительными органами, поскольку это однозначный метод записи китайских имен в некитайских шрифтах.
 Исходный код Бодо
Исходный код Бодо Ранние печатные телеграфы продолжали использовать азбуку Морзе, но оператор больше не отправлял точки и тире напрямую с помощью одной клавиши. Вместо этого они использовали клавиатуру пианино, на каждой клавише которой были помечены символы. Машина сгенерировала соответствующую точку кода Морзе нажатием клавиши. Совершенно новый тип кода был разработан Эмилем Бодо, запатентован в 1874 году. Код Бодо был 5-битным двоичным кодом, с битами, отправляемыми последовательно. Наличие кода фиксированной длины значительно упростило конструкцию машины. Оператор вводил код с маленькой 5-клавишной фортепианной клавиатуры, каждая клавиша соответствовала одному биту кода. Как и код Морзе, код Бодо был организован так, чтобы минимизировать утомляемость оператора с помощью кодовых точек, требующих наименьшего количества нажатий клавиш, назначенных для наиболее распространенных букв.
Ранние печатные телеграфы требовали механической синхронизации между отправляющим и принимающим аппаратом. Печатный телеграф Хьюза 1855 года достиг этого, посылая рывок Морзе при каждом обороте машины. Другое решение было принято в сочетании с кодом Бодо. При передаче к каждому символу добавлялись стартовые и стоповые биты, что позволяло асинхронную последовательную связь. Эта схема стартовых и стоповых битов использовалась во всех более поздних основных телеграфных кодах.
На загруженных телеграфных линиях вариант кода Бодо использовался с перфорированной бумагой. лента. Это был код Мюррея, изобретенный Дональдом Мюрреем в 1901 году. Вместо прямой передачи на линию, нажатия клавиш оператора пробивали дыры в ленте. Каждый ряд отверстий на ленте имел пять возможных позиций для пробивки, соответствующих пяти битам кода Мюррея. Затем лента пропускалась через считыватель ленты, который генерировал код и отправлял его по телеграфной линии. Преимущество этой системы состояло в том, что несколько сообщений можно было очень быстро послать в линию с одной ленты, что позволяло использовать линию лучше, чем прямое ручное управление.
Мюррей полностью изменил кодировку символов, чтобы минимизировать износ машины, поскольку усталость оператора больше не была проблемой. Таким образом, наборы символов исходных кодов Бодо и Мюррея несовместимы. Пяти битов кода Бодо недостаточно для представления всех букв, цифр и знаков препинания, необходимых в текстовом сообщении. Кроме того, печатные телеграфы требуют дополнительных символов для лучшего управления машиной. Примеры этих управляющих символов : перевод строки и возврат каретки. Мюррей решил эту проблему, введя коды сдвига. Эти коды инструктируют принимающую машину изменить кодировку символов на другой набор символов. В коде Мюррея использовались два кода сдвига; сдвиг фигуры и сдвиг букв. Другим управляющим символом, введенным Мюрреем, был символ удаления (DEL, код 11111), который пробивал все пять отверстий на ленте. Его предполагаемая цель состояла в том, чтобы удалить с ленты ошибочные символы, но Мюррей также использовал несколько DEL, чтобы отметить границу между сообщениями. После того, как все отверстия были пробиты, образовалась перфорация, которую можно было легко разорвать на отдельные сообщения на принимающей стороне. Вариант кода Бодо-Мюррея стал международным стандартом под названием International Telegraph Alphabet No. 2 (ITA 2) в 1924 году. «2» в ITA 2 объясняется тем, что исходный код Бодо стал основой для ITA 1. ITA 2 оставался стандартным телеграфным кодом, который использовался до 1960-х годов, и все еще использовался в местах, значительно превышающих те..
 Код ITA 2 в виде перфоленты
Код ITA 2 в виде перфоленты телетайп был изобретен в 1915 году. Это печатный телеграф с клавиатурой, похожей на пишущую машинку. оператор набирает сообщение. Тем не менее, телеграммы продолжали отправляться в верхнем регистре только потому, что не было места для строчного набора символов в кодах Бодо-Мюррея или ITA 2. Это изменилось с появлением компьютеров и желанием связать с телеграфной системой сообщения, созданные компьютером, или документы, составленные текстовым редактором. Непосредственной проблемой было использование кодов смены, которое вызывало трудности с компьютерным хранением текста. Если была получена часть сообщения или только один символ, было невозможно определить, какой сдвиг кодировки следует применить, без поиска последнего элемента управления сдвигом в остальной части сообщения. Это привело к введению 6-битного кода TeleTypeSetter (TTS). В TTS дополнительный бит использовался для хранения состояния сдвига, тем самым устраняя необходимость в символах сдвига. TTS также принесла некоторую пользу телетайпам, а также компьютерам. Повреждение переданного буквенного кода TTS привело к печати одной неправильной буквы, которую, вероятно, мог бы исправить принимающий пользователь. С другой стороны, повреждение символа смены ITA 2 привело к тому, что все сообщение с этого момента и далее искажалось до тех пор, пока не был отправлен следующий символ смены.
К 1960-м годам телетайп улучшился. Технология означала, что более длинные коды были далеко не таким значительным фактором в стоимости телетайпов, как раньше. Пользователи компьютеров хотели строчных букв и дополнительных знаков препинания, а производители телетайпов и компьютеров хотели избавиться от ITA 2 и ее кодов сдвига. Это побудило Американскую ассоциацию стандартов разработать 7-битный код, Американский стандартный код для обмена информацией (ASCII ). Окончательная форма ASCII была опубликована в 1964 году и быстро стала стандартным кодом телетайпа. ASCII был последним крупным кодом, разработанным специально для телеграфного оборудования. После этого телеграфия быстро пришла в упадок и была в значительной степени заменена компьютерными сетями, особенно Интернетом в 1990-х годах.
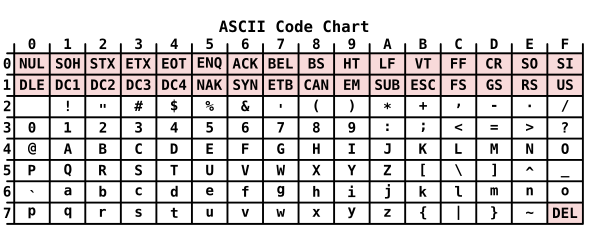
ASCII имел несколько функций, предназначенных для помощи в компьютерном программировании. Буквенные символы располагались в числовом порядке кодовых точек, поэтому сортировка по алфавиту могла быть достигнута просто путем числовой сортировки данных. Кодовая точка для соответствующих букв верхнего и нижнего регистра отличалась только значением бита 6, что позволяло сортировать сочетание регистров по алфавиту, если этот бит игнорировался. Были представлены и другие коды, в частности, IBM EBCDIC, полученный на основе метода ввода перфокарт, но именно ASCII и его производные стали популярными как язык. franca компьютерного обмена информацией.
Появление микропроцессора в 1970-х и персонального компьютера в 1980-х с их 8-битная архитектура привела к тому, что 8-битный байт стал стандартной единицей компьютерной памяти. Упаковка 7-битных данных в 8-битное хранилище неудобно для извлечения данных. Вместо этого большинство компьютеров хранит один символ ASCII на байт. Остался один кусок, который не делал ничего полезного. Производители компьютеров использовали этот бит в расширенном ASCII, чтобы преодолеть некоторые ограничения стандартного ASCII. Основная проблема заключалась в том, что ASCII был ориентирован на английский язык, особенно американский английский, и не имел акцентированных гласных, используемых в других европейских языках, таких как французский. В набор символов также были добавлены символы валют других стран. К сожалению, разные производители реализовали разные расширенные ASCII, что делало их несовместимыми на платформах. В 1987 году Международная организация по стандартизации выпустила стандарт ISO 8859-1 для 8-битной кодировки символов на основе 7-битного ASCII, который получил широкое распространение.
Кодировки символов ISO 8859 были разработаны для не латинских шрифтов, таких как кириллица, иврит, арабский и Греческий. Это все еще было проблематично, если в документе или данных использовалось более одного скрипта. Требовалось несколько переключений между кодировками символов. Это было решено публикацией в 1991 году стандарта для 16-битного Unicode, разрабатываемого с 1987 года. Unicode поддерживает символы ASCII в тех же кодовых точках для совместимости. Помимо поддержки нелатинских шрифтов, Unicode предоставил кодовые точки для логограмм, таких как китайские иероглифы, и многих специальных символов, таких как астрологические и математические символы. В 1996 году Unicode 2.0 допускал кодовые точки более 16 бит; до 20 бит и 21 бит с дополнительной областью частного использования. 20-битный Unicode обеспечил поддержку исчезнувших языков, таких как старый курсив и многих редко используемых китайских символов.
В 1931 году Международный код сигналов, изначально созданный для судовой связи посредством сигнализации с использованием флагов, был расширен за счет добавления набора пятибуквенных кодов для использования операторами радиотелеграфа.
| Код | A. N | B. O | C. P | D. Q | E. R | F. S | G. T | H. U | I. V | J. W | K. X | L. Y | M. Z | Тип данных | Примечания | Ссылка |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Двухэлементный парик Майера | 11. 22 | 1221. 12 | 212. 2121 | 111. 2122 | 21. 122 | 1112. 121 | 1122. 1 | 211. 221 | 2. 2111 | 2211. 2212 | 1212. 1211 | 112. 222 | 2112. 1111 | Последовательный, переменная длина | 1 = флаг слева, 2 = флаг справа. | |
| Международный код Морзе в обозначении флага | 12. 21 | 2111. 222 | 2121. 1221 | 211. 2212 | 1. 121 | 1121. 111 | 221. 2 | 1111. 112 | 11. 1112 | 1222. 122 | 212. 2112 | 1211. 2122 | 22. 2211 | Последовательный, переменная длина | 1 = флаг слева, 2 = флаг справа | |
| Американский Морзе в обозначении флага | 12. 21 | 2111. 131 | 1131. 11111 | 211. 1121 | 1. 1311 | 121. 111 | 221. 2 | 1111. 112 | 11. 1112 | 2121. 122 | 212. 1211 | 2+. 11311 | 22. 11131 | Последовательный, varia длина пятна | 1 = флаг слева, 2 = флаг справа, 3 = флаг опущен | |
| трехэлементный парик Майера | 112. 322 | 121. 223 | 211. 313 | 212. 131 | 221. 331 | 122. 332 | 123. 133 | 312. 233 | 213. 222 | 232. 322 | 323. 321 | 231. 111 | 132. 113 | Последовательный, 3-элементный | 1 = флаг слева, 2 = флаг справа, 3 = флаг опущен |
| Код | A. N | B. O | C. P | D. Q | E. R | F. S | G. T | H. U | I. V | J. W | K. X | L. Y | M. Z | Тип данных | Примечания | Ref |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 игла Шиллинга (1820) |  | Последовательный, переменная длина | Это первый код, использующий одиночный контур.. | |||||||||||||
| 1 игла Гаусса и Вебера (1833) |  | Последовательный, переменная длина | . | |||||||||||||
| 5 игл Кука и Уитстона (1838) |  | Параллельно, 5 элементов | ||||||||||||||
| 2 иглы Кука и Уитстона | 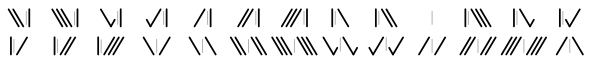 | Последовательно-параллельные, переменная длина | ||||||||||||||
| 1 игла Кука и Уитстона (1846) |  | Серийный номер переменной длины | . | |||||||||||||
| 1 игла Highton |  | Серийный номер переменной длины | . | |||||||||||||
| Морзе в виде кода иглы |  | Последовательный, переменной длины | Игла слева = точка. Игла справа = тире. | |||||||||||||
| Код Фоя-Бреге. (2-игла) |  | Параллельно, 2- element | ||||||||||||||
Альтернативным представлением кодов игл является использование цифры «1» для левой иглы и «3» для правой иглы. Цифра «2», которая не встречается в большинстве кодов, представляет иглу в нейтральном вертикальном положении. Кодовые точки, использующие эту схему, отмечены на лицевой стороне некоторых игольчатых инструментов, особенно используемых для обучения.
| Код | A. N | B. O | C. P | D. Q | E. R | F. S | G. T | H. U | I. V | J. W | K. X | L. Y | M. Z | Тип данных | Примечания | Ссылка |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Steinheil (1837) | ▄▄▄▄▄▄. ▄▄▄▄ | ▄▄▄▄ ▄▄▄▄. ▄▄▄▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄. ✗ | ▄▄. ▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄ | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄ | ▄▄. ▄▄▄▄▄▄ | ▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄. ✗ | ▄▄▄▄▄▄. ✗ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | Серийный номер переменной длины | ||
| Steinheil (1849) | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄▄▄. ▄ ▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ ▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄ ▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄ ▄▄▄▄▄▄▄. ✗ | ▄▄▄▄▄▄▄▄▄▄▄▄. ✗ | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | S erial, variable length | ||
| Bain (1843) | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | Serial, variable length | ||
| Morse (c. 1838) | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄. ▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | Serial, variable length | ||
| Morse (c. 1840). (American Morse) | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄. ▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄ | Serial, variable leng th | ||
| Gerke (1848). (continental morse) | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | Serial, variable length | ||
| International Morse. (1851) | ▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | ▄▄▄▄▄▄▄▄▄▄. ▄▄▄▄▄▄▄▄▄▄▄▄▄▄ | Serial, variable length |
When used with a printing telegraph or siphon recorder, the "dashes" of dot-dash codes are often made the same length as the "dot". Typically, the mark on the tape for a dot is made above the mark for a dash. An example of this can be seen in the 1837 Steinheil code, which is nearly identical to the 1849 Steinheil code, except that they are represented differently in the table. International Morse code was commonly used in this form on submarine telegraph cables.
| Code | A. N | B. O | C. P | D. Q | E. R | F. S | G. T | H. U | I. V | J. W | K. X | L. Y | M. Z | Data type | Notes | Ref |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baudot and ITA 1 | 01. 1E | 0C. 07 | 0D. 1F | 0F. 1D | 02. 1C | 0E. 14 | 0A. 15 | 0B. 05 | 06. 17 | 09. 16 | 19. 12 | 1B. 04 | 1A. 13 | Serial, 5-bit | ||
| Baudot–Murray and ITA 2 | 03. 0C | 19. 18 | 0E. 16 | 09. 17 | 01. 0A | 0D. 05 | 1A. 10 | 14. 07 | 06. 1E | 0B. 13 | 0F. 1D | 12. 15 | 1C. 11 | Serial, 5-bit | ||
| ASCII | 41/61. 4E/6E | 42/62. 4F/6F | 43/63. 50/70 | 44/64. 51/71 | 45/65. 52/72 | 46/66. 53/73 | 47/67. 54/74 | 48/78. 55/75 | 49/69. 56/76 | 4A/6A. 57/77 | 4B/6B. 58/78 | 4C/6C. 59/79 | 4D/6D. 5A/7A | Serial, 7-bit |