
Войти
 Сглаживание зашумленного синуса (синяя кривая) скользящей средней (красная кривая).
Сглаживание зашумленного синуса (синяя кривая) скользящей средней (красная кривая). В статистике, скользящее среднее ( скользящее среднее или скользящее среднее) является расчет для анализа точек данных путем создания ряда средних различных подмножеств полного набора данных. Его также называют скользящим средним ( MM) или скользящим средним и представляет собой тип фильтра с конечной импульсной характеристикой. Варианты включают: простые, накопительные или взвешенные формы (описаны ниже).
Учитывая ряд чисел и фиксированный размер подмножества, первый элемент скользящего среднего получается путем взятия среднего значения начального фиксированного подмножества числового ряда. Затем подмножество модифицируется «смещением вперед»; то есть исключение первого числа ряда и включение следующего значения в подмножестве.
Скользящее среднее обычно используется с данными временных рядов для сглаживания краткосрочных колебаний и выделения долгосрочных тенденций или циклов. Порог между краткосрочным и долгосрочным зависит от приложения, и параметры скользящей средней будут установлены соответственно. Например, он часто используется в техническом анализе финансовых данных, таких как цены на акции, доходность или объемы торгов. Он также используется в экономике для изучения валового внутреннего продукта, занятости или других макроэкономических временных рядов. Математически скользящее среднее - это тип свертки, поэтому его можно рассматривать как пример фильтра нижних частот, используемого при обработке сигналов. При использовании с данными, не относящимися к временным рядам, скользящее среднее фильтрует высокочастотные компоненты без какой-либо конкретной привязки ко времени, хотя обычно подразумевается некоторый вид упорядочения. В упрощенном виде это можно рассматривать как сглаживание данных.

В финансовых приложениях простая скользящая средняя ( SMA) - это невзвешенное среднее значение предыдущих точек данных. Однако в науке и технике среднее значение обычно берется из равного количества данных по обе стороны от центрального значения. Это гарантирует, что вариации среднего значения совпадают с вариациями данных, а не смещаются во времени.Примером простого равновзвешенного скользящего среднего является среднее значение по последним записям набора данных, содержащего записи. Пусть будут эти точки данных. Это могут быть цены закрытия акции. Среднее значение по последним точкам данных (дни в этом примере) обозначается и рассчитывается как:
При вычислении следующего среднего с той же шириной выборки учитывается диапазон от до. Новое значение входит в сумму, а самое старое значение выпадает. Это упрощает вычисления за счет повторного использования предыдущего среднего.
Это означает, что фильтр скользящего среднего может быть довольно дешево вычислен для данных в реальном времени с FIFO / кольцевым буфером и всего за 3 арифметических шага.
Во время начального заполнения FIFO / кольцевого буфера окно выборки равно размеру набора данных, поэтому вычисление среднего значения выполняется как кумулятивное скользящее среднее.
Выбранный период () зависит от типа движения интереса, например, краткосрочного, промежуточного или долгосрочного. С финансовой точки зрения уровни скользящей средней можно интерпретировать как поддержку на падающем рынке или сопротивление на растущем рынке.
Если используемые данные не сосредоточены вокруг среднего, простое скользящее среднее отстает от последних данных на половину ширины выборки. На SMA также может непропорционально влиять выпадение старых или поступление новых данных. Одной из характеристик SMA является то, что если данные имеют периодические колебания, то применение SMA этого периода устранит это изменение (среднее всегда содержит один полный цикл). Но совершенно регулярный цикл встречается редко.
Для ряда приложений полезно избегать сдвига, вызванного использованием только «прошлых» данных. Следовательно, можно вычислить центральное скользящее среднее, используя данные, равномерно распределенные по обе стороны от точки в ряду, где рассчитывается среднее значение. Это требует использования нечетного количества точек в окне выборки.
Основным недостатком SMA является то, что он пропускает значительную часть сигнала короче, чем длина окна. Хуже того, он фактически переворачивает его. Это может привести к неожиданным артефактам, таким как пики сглаженного результата, появляющиеся там, где в данных были впадины. Это также приводит к тому, что результат оказывается менее гладким, чем ожидалось, поскольку некоторые из высоких частот не удаляются должным образом.
В кумулятивном скользящем среднем ( CMA) данные поступают в виде упорядоченного потока данных, и пользователь хотел бы получить среднее значение всех данных до текущего момента. Например, инвестору может потребоваться средняя цена всех операций с акциями для конкретной акции до текущего времени. Когда происходит каждая новая транзакция, средняя цена на момент транзакции может быть рассчитана для всех транзакций до этого момента с использованием кумулятивного среднего, обычно равновзвешенного среднего значения последовательности из n значений до текущего времени:
Метод грубой силы для вычисления этого будет заключаться в сохранении всех данных и вычислении суммы и делении на количество точек каждый раз, когда поступают новые данные. Однако можно просто обновить кумулятивное среднее значение по мере того, как новое значение станет доступным, используя формулу
Таким образом, текущее совокупное среднее значение для новых данных равно предыдущему совокупному среднему значению, умноженному на n, плюс последнее значение, разделенное на количество точек, полученных на данный момент, n +1. Когда будут получены все данные ( n = N), совокупное среднее значение будет равно окончательному среднему. Также возможно сохранить промежуточную сумму данных, а также количество точек и разделив полученную сумму на количество точек, чтобы получить CMA каждый раз, когда поступает новая база данных.
Вывести формулу кумулятивного среднего значения несложно. С использованием
и аналогично для n + 1 видно, что
Решение этого уравнения приводит к
Средневзвешенное значение - это среднее значение, которое имеет коэффициенты умножения, позволяющие присвоить разный вес данным в разных положениях в окне выборки. Математически взвешенное скользящее среднее - это свертка данных с фиксированной весовой функцией. Одно приложение устраняет пикселизацию цифрового графического изображения.
В техническом анализе финансовых данных взвешенная скользящая средняя (WMA) имеет особое значение весов, которые уменьшаются в арифметической прогрессии. В n- дневном WMA последний день имеет вес n, второй и т. Д. С точностью до единицы.
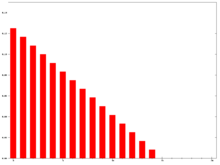 Веса WMA n = 15
Веса WMA n = 15 Знаменатель - это число в треугольнике, равное В более общем случае знаменателем всегда будет сумма отдельных весов.
При вычислении WMA для последовательных значений разница между числителями и составляет. Если обозначить сумму через, то
График справа показывает, как веса уменьшаются от самого высокого веса для самых последних данных до нуля. Его можно сравнить с весами в следующей экспоненциальной скользящей средней.
 Веса EMA N = 15
Веса EMA N = 15 Экспоненциальной скользящей средней (EMA), также известный как экспоненциально взвешенное скользящее среднее (EWMA), является первого порядка с бесконечной импульсной характеристикой фильтра, который применяет весовые коэффициенты, которые уменьшают в геометрической прогрессии. Вес для каждого более старого элемента данных уменьшается экспоненциально, никогда не достигая нуля. На графике справа показан пример снижения веса.
EMA для серии может быть вычислена рекурсивно:
Где:
S 1 может быть инициализирован множеством различных способов, чаще всего путем установки S 1 на Y 1, как показано выше, хотя существуют и другие методы, такие как установка S 1 на среднее значение первых 4 или 5 наблюдений. Важность эффекта инициализации S 1 для результирующей скользящей средней зависит от: меньшие значения делают выбор S 1 относительно более важным, чем большие значения, поскольку более высокие значения приводят к более раннему обесценению более старых наблюдений.
Что бы ни было сделано для S 1, оно предполагает что-то о значениях, предшествующих доступным данным, и обязательно является ошибкой. Ввиду этого первые результаты следует рассматривать как ненадежные до тех пор, пока итерации не сойдутся. Иногда это называют интервалом «раскрутки». Один из способов оценить, когда он может считаться надежным, - это рассмотреть требуемую точность результата. Например, если требуется точность 3%, инициализация с помощью Y 1 и получение данных после пяти постоянных времени (определенных выше) обеспечит сходимость вычислений с точностью до 3% ( в результате останется только lt;3% от Y 1). Иногда с очень маленьким альфа-каналом это может означать, что результат мало что полезен. Это аналогично проблеме использования фильтра свертки (например, средневзвешенного) с очень длинным окном.
Эта формулировка соответствует Хантеру (1986). Путем повторного применения этой формулы в разное время мы можем в конечном итоге записать S t как взвешенную сумму опорных точек, как:
для любого подходящего k ∈ {0, 1, 2,...} Вес общих данных равен.
Эта формула также может быть выражена в терминах технического анализа следующим образом, показывая, как EMA приближается к последним данным, но только пропорционально разнице (каждый раз):
Расширение каждый раз приводит к следующему степенному ряду, показывающему, как весовой коэффициент для каждой точки данных p 1, p 2 и т. Д. Экспоненциально уменьшается:
куда
с тех пор.
Его также можно вычислить рекурсивно без введения ошибки при инициализации первой оценки (n начинается с 1):
Это бесконечная сумма с убывающими членами.
Вопрос о том, как далеко отойти от начального значения, в худшем случае зависит от данных. Большие значения цен в старых данных повлияют на общую сумму, даже если их вес очень мал. Если цены имеют небольшие колебания, можно рассмотреть только их взвешивание. Приведенная выше формула мощности дает начальное значение для конкретного дня, после которого может быть применена формула последовательных дней, показанная первой. Вес, пропущенный при остановке после k членов, равен
который
т.е. дробь
из общего веса.
Например, чтобы получить 99,9% веса, установите указанное выше соотношение равным 0,1% и решите для k:
чтобы определить, сколько терминов следует использовать. Поскольку as, мы знаем, что приближается по мере увеличения N. Это дает:
Когда относится к N как, это упрощается примерно до
для этого примера (99,9% вес.).
Обратите внимание, что не существует «приемлемого» значения, которое следует выбирать, хотя есть некоторые рекомендуемые значения, основанные на приложении. Обычно используемым значением α является. Это потому, что веса SMA и EMA имеют одинаковый «центр масс», когда.
[Доказательство]Веса N- дневной SMA имеют "центр масс" в день, где
(или, если мы используем индексирование с нуля)
В оставшейся части этого доказательства мы будем использовать индексирование с единицей.
Между тем, веса EMA имеют центр масс
То есть,
Мы также знаем серию Маклорена.
Взятие производных от обеих частей по x дает:
или
Подставляя, получаем
или
Таким образом, значение α, которое устанавливает, на самом деле:
или
И то же самое значение α, которое создает EMA, веса которой имеют тот же центр тяжести, что и эквивалентная N-дневная SMA.
Вот почему иногда EMA называют N- дневной EMA. Несмотря на название, предполагающее, что существует N периодов, терминология указывает только фактор α. N не является точкой остановки для вычислений, как в SMA или WMA. Для достаточно большого N первые N опорных точек в EMA составляют около 86% от общего веса в расчетах, когда:
[Доказательство]Сумма весов всех членов (т. Е. Бесконечного числа членов) в экспоненциальной скользящей средней равна 1. Сумма весов N членов равна. Обе эти суммы могут быть получены с помощью формулы суммы геометрического ряда. Вес, пропущенный после N членов, получается путем вычитания его из 1, и вы получаете (по сути, это формула, приведенная ранее для пропущенного веса).
Теперь заменим обычно используемое значение на формулу веса N членов. Если вы сделаете эту замену и воспользуетесь ею, то получите
приближение 0,8647. Наглядно, что это говорит нам о том, что вес после N терминах `` N -период»экспоненциальная скользящая средняя сходится к 0.8647.
Обозначение не является обязательным. (К примеру, аналогичное доказательство можно было бы использовать, чтобы так же легко определить, что ЕМА с периодом полураспада от N -days является или что ЕМА с той же медиане как N -дня SMA является). Фактически, 2 / ( N +1) - это просто общее соглашение для формирования интуитивного понимания взаимосвязи между EMA и SMA для отраслей, где оба обычно используются вместе в одних и тех же наборах данных. На самом деле можно использовать EMA с любым значением α, и ее можно назвать либо указанием значения α, либо более знакомой терминологией N -day EMA.
Помимо среднего, нас также могут интересовать дисперсия и стандартное отклонение для оценки статистической значимости отклонения от среднего.
EWMVar можно легко вычислить вместе со скользящей средней. Начальные значения - и, а затем мы вычисляем последующие значения, используя:
Исходя из этого, экспоненциально взвешенное скользящее стандартное отклонение может быть вычислено как. Затем мы можем использовать стандартную оценку для нормализации данных относительно скользящего среднего и дисперсии. Этот алгоритм основан на алгоритме Велфорда для вычисления дисперсии.
Модифицированного скользящего среднего (ММА), работает скользящей средней (RMA), или сглаженное скользящее среднее (SMMA) определяется как:
Короче говоря, это экспоненциальная скользящая средняя с. Единственная разница между EMA и SMMA / RMA / MMA - это способ вычисления. Для EMA обычно выбирают
Некоторые показатели производительности компьютера, например средняя длина очереди процесса или средняя загрузка ЦП, используют форму экспоненциального скользящего среднего.
Здесь α определяется как функция времени между двумя измерениями. Примером коэффициента, придающего больший вес текущим показаниям и меньший вес старым показаниям, является
где exp () - экспоненциальная функция, время считывания t n выражается в секундах, а W - период времени в минутах, в течение которого показание считается усредненным (среднее время жизни каждого показания в среднем). Учитывая приведенное выше определение α, скользящую среднюю можно выразить как
Например, среднее значение L длины очереди обработки Q за 15 минут, измеряемое каждые 5 секунд (разница во времени составляет 5 секунд), вычисляется как
Иногда используются другие системы взвешивания - например, при торговле акциями объемный вес будет взвешивать каждый период времени пропорционально его торговому объему.
Еще одно взвешивание, используемое актуариями, - это 15-точечная скользящая средняя Спенсера (центральная скользящая средняя). Его симметричные весовые коэффициенты равны [−3, −6, −5, 3, 21, 46, 67, 74, 67, 46, 21, 3, −5, −6, −3], которые разлагаются как[1, 1, 1, 1] × [1, 1, 1, 1] × [1, 1, 1, 1, 1] × [−3, 3, 4, 3, −3]/320 и оставляет образцы любого кубического многочлена без изменений.
За пределами мира финансов средства взвешенного управления имеют множество форм и применений. Каждая весовая функция или «ядро» имеет свои особенности. В технике и науке частота и фазовая характеристика фильтра часто имеют первостепенное значение для понимания желаемых и нежелательных искажений, которые конкретный фильтр будет применять к данным.
Средство не просто «сглаживает» данные. Среднее - это разновидность фильтра нижних частот. Следует понимать влияние конкретного используемого фильтра, чтобы сделать соответствующий выбор. По этому поводу во французской версии этой статьи обсуждаются спектральные эффекты трех видов средних (кумулятивных, экспоненциальных, гауссовских).
Со статистической точки зрения скользящее среднее, когда оно используется для оценки основного тренда во временном ряду, подвержено редким событиям, таким как быстрые потрясения или другие аномалии. Более надежная оценка тенденции - это простая скользящая медиана по n временным точкам:
где медиана находится, например, путем сортировки значений в скобках и нахождения значения посередине. Для больших значений n медиана может быть эффективно вычислена путем обновления индексируемого списка пропусков.
Статистически скользящая средняя оптимальна для восстановления основного тренда временного ряда, когда колебания тренда распределены нормально. Однако нормальное распределение не дает высокой вероятности очень большим отклонениям от тренда, что объясняет, почему такие отклонения будут иметь непропорционально большое влияние на оценку тренда. Можно показать, что если вместо этого предполагается, что флуктуации распределены по Лапласу, то скользящая медиана является статистически оптимальной. Для данной дисперсии распределение Лапласа дает более высокую вероятность редких событий, чем нормальное, что объясняет, почему скользящая медиана лучше переносит удары, чем скользящая средняя.
Когда простая скользящая медиана, приведенная выше, является центральной, сглаживание идентично среднему фильтру, который применяется, например, в обработке сигналов изображения.
В модели регрессии скользящего среднего предполагается, что интересующая переменная представляет собой взвешенное скользящее среднее ненаблюдаемых независимых членов ошибки; веса в скользящей средней являются параметрами, которые необходимо оценить.
Эти два понятия часто путают из-за их названия, но, хотя у них много общего, они представляют разные методы и используются в очень разных контекстах.
 Примером простого равновзвешенного скользящего среднего является среднее значение по последним записям набора данных, содержащего записи. Пусть будут эти точки данных. Это могут быть цены закрытия акции. Среднее значение по последним точкам данных (дни в этом примере) обозначается и рассчитывается как:
Примером простого равновзвешенного скользящего среднего является среднее значение по последним записям набора данных, содержащего записи. Пусть будут эти точки данных. Это могут быть цены закрытия акции. Среднее значение по последним точкам данных (дни в этом примере) обозначается и рассчитывается как: 
















![{\ displaystyle {\ begin {align} x_ {n + 1} amp; = (x_ {1} + \ cdots + x_ {n + 1}) - (x_ {1} + \ cdots + x_ {n}) \\ [6 пт] \ end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4198137da4158776d97b63e5924acff1fa5460da)

![{\ displaystyle {\ begin {align} {\ textit {CMA}} _ {n + 1} amp; = {x_ {n + 1} + n \ cdot {\ textit {CMA}} _ {n} \ over {n +1}} \\ [6pt] amp; = {x_ {n + 1} + (n + 1-1) \ cdot {\ textit {CMA}} _ {n} \ over {n + 1}} \\ [ 6pt] amp; = {(n + 1) \ cdot {\ textit {CMA}} _ {n} + x_ {n + 1} - {\ textit {CMA}} _ {n} \ over {n + 1}} \\ [6pt] amp; = {{\ textit {CMA}} _ {n}} + {{x_ {n + 1} - {\ textit {CMA}} _ {n}} \ over {n + 1}} \ конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ac31c1a45a506a2f7e97c0887afc19b83da137cd)








![{\ displaystyle {\ begin {align} {\ text {Total}} _ {M + 1} amp; = {\ text {Total}} _ {M} + p_ {M + 1} -p_ {M-n + 1 } \\ [3pt] {\ text {Numerator}} _ {M + 1} amp; = {\ text {Numerator}} _ {M} + np_ {M + 1} - {\ text {Total}} _ {M } \\ [3pt] {\ text {WMA}} _ {M + 1} amp; = {{\ text {Numerator}} _ {M + 1} \ over n + (n-1) + \ cdots + 2 + 1 } \ конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8ff41461f4d60351300c4ef7cee5f75821fed5ab)



 - значение за период времени.
- значение за период времени.
 - значение EMA в любой период времени.
- значение EMA в любой период времени.![{\ displaystyle {\ begin {align} S_ {t} = \ alpha amp; \ left [Y_ {t} + (1- \ alpha) Y_ {t-1} + (1- \ alpha) ^ {2} Y_ { t-2} + \ cdots \ right. \\ [6pt] amp; \ left. \ cdots + (1- \ alpha) ^ {k} Y_ {tk} \ right] + (1- \ alpha) ^ {k + 1} S_ {t- (k + 1)} \ конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a2010e0f9130c03db3bccc10401d09ad14d490e5)


![{\ displaystyle {\ text {EMA}} _ {\ text {сегодня}} = {\ text {EMA}} _ {\ text {вчера}} + \ alpha \ left [{\ text {price}} _ {\ текст {сегодня}} - {\ text {EMA}} _ {\ text {вчера}} \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f5618cac038375bf2832f8ce6a42917e5a7464e9)

![{\ displaystyle {\ text {EMA}} _ {\ text {сегодня}} = {\ alpha \ left [p_ {1} + (1- \ alpha) p_ {2} + (1- \ alpha) ^ {2 } p_ {3} + (1- \ alpha) ^ {3} p_ {4} + \ cdots \ right]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/92eb7704cddb522915f9e484af573a66e11d2400)
 является
является 
 является
является 






![{\ Displaystyle \ альфа \ влево [(1- \ альфа) ^ {k} + (1- \ альфа) ^ {k + 1} + (1- \ альфа) ^ {k + 2} + \ cdots \ right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bf74123f6ed7d1ba9a526b0fe36838ba9c850417)
![{\ Displaystyle \ альфа (1- \ альфа) ^ {к} \ влево [1+ (1- \ альфа) + (1- \ альфа) ^ {2} + \ cdots \ right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1dbfe024eb53506e6e9a9a4d834af5f0edfcafd3)
![{\ displaystyle {\ begin {align} amp; {\ frac {{\ text {вес пропущен при остановке после}} k {\ text {terms}}} {\ text {total weight}}} \\ [6pt] = { } amp; {\ frac {\ alpha \ left [(1- \ alpha) ^ {k} + (1- \ alpha) ^ {k + 1} + (1- \ alpha) ^ {k + 2} + \ cdots \ right]} {\ alpha \ left [1+ (1- \ alpha) + (1- \ alpha) ^ {2} + \ cdots \ right]}} \\ [6pt] = {} amp; {\ frac { \ alpha (1- \ alpha) ^ {k} {\ frac {1} {1- (1- \ alpha)}}} {\ frac {\ alpha} {1- (1- \ alpha)}}} \ \ [6pt] = {} amp; (1- \ alpha) ^ {k} \ end {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7460819a37ee41817b79d3078939358ade59f9bd)













![{\ Displaystyle R _ {\ mathrm {EMA}} = \ альфа \ влево [1 + 2 (1- \ альфа) +3 (1- \ альфа) ^ {2} +... + к (1- \ альфа) ^ {k-1} \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1fff0d58c6b00ffbbc98e20d2405b149d1a8ece9)












![{\ Displaystyle 1- \ влево [1- (1- \ альфа) ^ {N + 1} \ вправо] = (1- \ альфа) ^ {N + 1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/93f4dcf492e2e4e37dedfa96f490c388e4368546)

![{\ Displaystyle {\ гидроразрыва {\ альфа \ влево [1+ (1- \ альфа) + (1- \ альфа) ^ {2} + \ cdots + (1- \ альфа) ^ {N} \ right]} { \ alpha \ left [1+ (1- \ alpha) + (1- \ alpha) ^ {2} + \ cdots \ right])}} = 1 - {\ left (1- {2 \ over N + 1}) \ right)} ^ {N}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/81ff4efdf926fa13bac71f29bb665b8c2c99a56f)
![{\ displaystyle \ lim _ {N \ to \ infty} \ left [1 - {\ left (1- {2 \ over N + 1} \ right)} ^ {N + 1} \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/530a883020214767d5958af035e1c0c54308f07f)












![{\ Displaystyle S_ {n} = \ альфа (t_ {n} -t_ {n-1}) Y_ {n} + \ left [1- \ alpha (t_ {n} -t_ {n-1}) \ right ] S_ {n-1}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5f02fa54d8899c48a023c97613336e3b202092b8)

![{\ displaystyle S_ {n} = \ left [1- \ exp \ left (- {{t_ {n} -t_ {n-1}} \ over {W \ cdot 60}} \ right) \ right] Y_ { n} + \ exp \ left (- {{t_ {n} -t_ {n-1}} \ over {W \ cdot 60}} \ right) S_ {n-1}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/489654cce07841be14e0b10ed8e3146dc6b6da6e)
![{\ displaystyle {\ begin {align} L_ {n} amp; = \ left [1- \ exp \ left ({- {\ frac {5} {15 \ cdot 60}}} \ right) \ right] Q_ {n } + e ^ {- {\ frac {5} {15 \ cdot 60}}} L_ {n-1} \\ [6pt] amp; = \ left [1- \ exp \ left ({- {\ frac {1 } {180}}} \ right) \ right] Q_ {n} + e ^ {- {\ frac {1} {180}}} L_ {n-1} \\ [6pt] amp; = Q_ {n} + e ^ {- {\ frac {1} {180}}} \ left (L_ {n-1} -Q_ {n} \ right) \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9da1772372b3d06e6a7141d79c687c8ae078fc37)
