
Войти
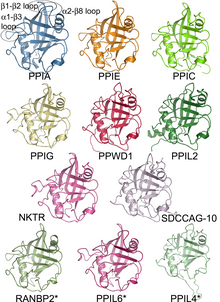 Семейство человеческих циклофилинов, представленное структурами изомеразы домены некоторых из его членов.
Семейство человеческих циклофилинов, представленное структурами изомеразы домены некоторых из его членов. A семейство белков представляет собой группу эволюционно связанных белков. Во многих случаях семейство белков имеет соответствующее семейство генов, в котором каждый ген кодирует соответствующий белок в соотношении 1: 1. Термин "семейство белков" не следует путать с семейством, поскольку он используется в таксономии.
Белки в семействе происходят от общего предка и обычно имеют схожие трехмерные структуры, функции и значительное сходство последовательностей. Самым важным из них является сходство последовательностей (обычно аминокислотная последовательность), поскольку это самый строгий индикатор гомологии и, следовательно, самый четкий индикатор общего происхождения. Существует довольно хорошо разработанная структура для оценки значимости сходства между группой последовательностей с использованием методов выравнивания последовательностей. Очень маловероятно, что белки, не имеющие общего предка, будут иметь статистически значимое сходство последовательностей, что делает выравнивание последовательностей мощным инструментом для идентификации членов семейств белков.
Семейства иногда группируются в более крупные клады, называемые суперсемействами на основании структурного и механистического сходства, даже если нет идентифицируемой гомологии последовательностей.
В настоящее время определено более 60 000 семейств белков, хотя неоднозначность определения семейства белков приводит различных исследователей к сильно различающимся цифрам.
Как и во многих биологических терминах, использование семейства белков в некоторой степени зависит от контекста; он может указывать на большие группы белков с минимально возможным уровнем детектируемого сходства последовательностей, или очень узкие группы белков с почти идентичной последовательностью, функцией и трехмерной структурой, или на любую промежуточную группу. Чтобы различать эти ситуации, термин суперсемейство белков часто используется для обозначения отдаленно связанных белков, родство которых не определяется сходством последовательностей, а определяется только общими структурными особенностями. Другие термины, такие как класс белков, группа, клан и подсемейство, были придуманы годами, но все они имеют одинаковую двусмысленность в использовании. Обычно суперсемейства (структурная гомология ) содержат семейства (гомология последовательностей ), которые содержат подсемейства. Следовательно, суперсемейство, такое как клан PA протеаз, имеет гораздо более низкую консервативность последовательности, чем одно из содержащихся в нем семейств, семейство C04. Маловероятно, что будет согласовано точное определение, и читатель должен понять, как именно эти термины используются в конкретном контексте.
 Выше сохранение последовательности 250 членов клана PA протеаз (надсемейство ). Ниже представлена консервация последовательности 70 членов семейства протеаз C04. Стрелки указывают остатки каталитической триады. Выравнивание на основе структуры с помощью DALI
Выше сохранение последовательности 250 членов клана PA протеаз (надсемейство ). Ниже представлена консервация последовательности 70 членов семейства протеаз C04. Стрелки указывают остатки каталитической триады. Выравнивание на основе структуры с помощью DALI .
Концепция семейства белков возникла в то время, когда было известно очень мало структур или последовательностей белков; в то время были структурно понятны в первую очередь небольшие однодоменные белки, такие как миоглобин, гемоглобин и цитохром с. С того времени было обнаружено, что многие белки содержат множество независимых структурных и функциональных единиц или доменов. Вследствие эволюционного перетасовки разные домены в белке эволюционировали независимо. Это привело в последние годы к сосредоточению внимания на семействах белковых доменов. Определению и каталогизации таких доменов посвящен ряд онлайн-ресурсов (см. Список ссылок в конце этой статьи).
Области каждого белка имеют разные функциональные ограничения (особенности, критические для структуры и функции белка). Например, активный сайт фермента требует, чтобы определенные аминокислотные остатки были точно ориентированы в трех измерениях. С другой стороны, интерфейс связывания белок-белок может состоять из большой поверхности с ограничениями на гидрофобность или полярность аминокислотных остатков. Функционально ограниченные области белков развиваются медленнее, чем неограниченные области, такие как поверхностные петли, что приводит к появлению заметных блоков консервативной последовательности при сравнении последовательностей семейства белков (см. множественное выравнивание последовательностей ). Эти блоки чаще всего называют мотивами, хотя используется много других терминов (блоки, подписи, отпечатки пальцев и т. Д.). Опять же, многие онлайн-ресурсы посвящены идентификации и каталогизации белковых мотивов (см. Список в конце статьи).
Согласно нынешнему консенсусу, семейства протеинов возникают двумя путями. Во-первых, разделение родительского вида на два генетически изолированных потомка позволяет гену / белку независимо накапливать вариации (мутации ) в этих двух линиях. В результате получается семейство ортологичных белков, обычно с консервативными мотивами последовательностей. Во-вторых, дупликация гена может создать вторую копию гена (называемую паралогом ). Поскольку исходный ген все еще может выполнять свою функцию, дублированный ген может свободно расходиться и приобретать новые функции (путем случайной мутации). Определенные семейства генов / белков, особенно у эукариот, в ходе эволюции претерпевают экстремальные расширения и сокращения, иногда одновременно с дупликациями всего генома. Это расширение и сокращение семейств белков является одной из характерных черт эволюции генома, но его важность и разветвления в настоящее время неясны.
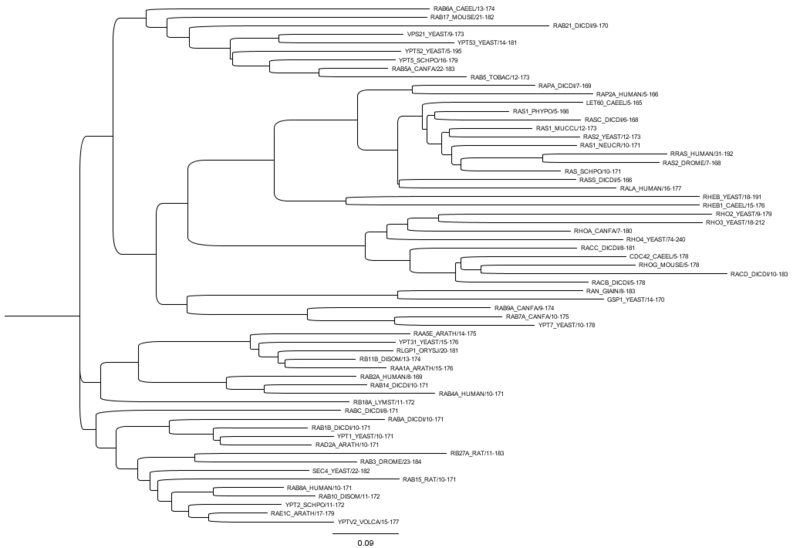 Филогенетическое древо надсемейства РАН. Дерево было создано с использованием FigTree (бесплатное онлайн-программное обеспечение).
Филогенетическое древо надсемейства РАН. Дерево было создано с использованием FigTree (бесплатное онлайн-программное обеспечение). По мере увеличения общего количества секвенированных белков и увеличения интереса к анализу протеом возникает постоянные усилия по организации белков в семейства и описанию составляющих их доменов и мотивов. Надежная идентификация семейств белков имеет решающее значение для филогенетического анализа, функциональной аннотации и исследования разнообразия функций белков в данной филогенетической ветви. Enzyme Function Initiative (EFI) использует семейства белков и суперсемейства в качестве основы для разработки стратегии на основе последовательности / структуры для крупномасштабного функционального назначения ферментов с неизвестной функцией.
Алгоритмические средства для установления семейств белков в большом масштабе основаны на понятии сходства. В большинстве случаев единственное сходство, к которому мы имеем доступ, - это сходство последовательностей.
Существует множество биологических баз данных, в которых записываются примеры семейств белков и которые позволяют пользователям определять, принадлежат ли недавно идентифицированные белки к известному семейству. Вот несколько примеров:
Аналогичным образом существует множество алгоритмов поиска в базе данных, например:
.