
Войти
| | |
| Международный стандарт | RFC 1945 HTTP / 1.0 (1996) RFC 2068 HTTP / 1.1 (1997) RFC 2616 HTTP / 1.1 (1999) RFC 7230 HTTP / 1.1: синтаксис сообщений и маршрутизация (2014) RFC 7231 HTTP / 1.1: семантика и контент (2014) RFC 7232 HTTP / 1.1: условные запросы ( 2014) RFC 7233 HTTP / 1.1: запросы диапазона (2014) RFC 7234 HTTP / 1.1: кэширование (2014) RFC 7235 HTTP / 1.1: аутентификация (2014) RFC 7540 HTTP / 2 (2015) RFC 7541 HTTP / 2: сжатие заголовков HPACK (2015) RFC 8164 HTTP / 2: Opportunistic Security for HTTP / 2 (2017) RFC 8336 HTTP / 2: The ORIGIN HTTP / 2 Frame (2018) RFC 8441 HTTP / 2: Bootstrapping WebSockets with HTTP / 2 (2018) RFC 8740 HTTP / 2: Использование TLS 1.3 с HTTP / 2 (2020) |
|---|---|
| Разработано | изначально ЦЕРН ; IETF, W3C |
| Введено | 1991 ; 30 лет назад ( 1991) |
| HTTP |
|---|
| Способы запроса |
| Поля заголовка |
| Коды статуса ответа |
| Методы управления безопасным доступом |
| Уязвимости безопасности |
|
| Набор интернет-протоколов |
|---|
| Уровень приложения |
| Транспортный уровень |
|
| Интернет-уровень |
| Связующий слой |
|
|
Протокол передачи гипертекста ( HTTP) является прикладным уровнем протокола в Интернете - протоколе ванной модели для распределенных, совместных, гипермедиа информационных систем. HTTP - это основа передачи данных во всемирной паутине, где гипертекстовые документы включают гиперссылки на другие ресурсы, к которым пользователь может легко получить доступ, например, щелчком мыши или касанием экрана в веб-браузере.
Разработка HTTP была инициирована Тимом Бернерсом-Ли в ЦЕРНе в 1989 году и обобщена в простом документе, описывающем поведение клиента и сервера с использованием первой версии протокола HTTP, получившей название 0.9.
Разработка первых HTTP- запросов на комментарии (RFC) началась несколько лет спустя, и это была скоординированная работа Инженерной группы Интернета (IETF) и Консорциума Всемирной паутины (W3C), позже работа перешла к IETF.
HTTP / 1 был впервые задокументирован (как версия 1.0) в 1996 году. Он развился (как версия 1.1) в 1997 году.
HTTP / 2 является более эффективным выражением семантики HTTP «на проводе», был опубликован в 2015 году и используется 45% веб-сайтов; теперь он поддерживается практически всеми веб-браузерами и основными веб-серверами через Transport Layer Security (TLS) с использованием расширения Application-Layer Protocol Negotiation (ALPN), где требуется TLS 1.2 или новее.
HTTP / 3 является предлагаемым преемником HTTP / 2, и две трети пользователей веб-браузеров (как на настольных компьютерах, так и на мобильных устройствах) уже могут использовать HTTP / 3 на 20% веб-сайтов, которые его уже поддерживают; он использует QUIC вместо TCP для основного транспортного протокола. Как и HTTP / 2, он не отменяет предыдущие основные версии протокола. Поддержка HTTP / 3 была сначала добавлена в Cloudflare и Google Chrome, а также включена в Firefox.
 URL-адрес, начинающийся со схемы HTTP и метки имени домена WWW
URL-адрес, начинающийся со схемы HTTP и метки имени домена WWW HTTP функционирует как протокол запроса-ответа в вычислительной модели клиент-сервер. Веб - браузер, например, может быть клиент и приложение, запущенное на компьютере хостинг на веб - сайт может быть сервер. Клиент отправляет на сервер сообщение HTTP- запроса. Сервер, который предоставляет ресурсы, такие как файлы HTML и другое содержимое, или выполняет другие функции от имени клиента, возвращает клиенту ответное сообщение. Ответ содержит информацию о состоянии завершения запроса, а также может содержать запрошенное содержимое в теле сообщения.
Веб-браузер - это пример пользовательского агента (UA). Другие типы пользовательских агентов включают программное обеспечение для индексирования, используемое поставщиками поиска ( веб-сканеры ), голосовыми браузерами, мобильными приложениями и другим программным обеспечением, которое получает доступ, потребляет или отображает веб-контент.
HTTP разработан, чтобы позволить промежуточным сетевым элементам улучшать или обеспечивать связь между клиентами и серверами. Веб -сайты с высокой посещаемостью часто выигрывают от серверов веб-кеша, которые доставляют контент от имени вышестоящих серверов, чтобы сократить время отклика. Веб-браузеры кэшируют ранее использованные веб-ресурсы и повторно используют их, когда это возможно, для уменьшения сетевого трафика. Прокси-серверы HTTP на границах частной сети могут облегчить связь для клиентов, не имеющих адреса с глобальной маршрутизацией, путем ретрансляции сообщений с внешними серверами.
Чтобы промежуточные HTTP-узлы (прокси-серверы, веб-кеши и т. Д.) Могли выполнять свои функции, некоторые из HTTP-заголовков (найденных в HTTP-запросах / ответах) управляются поэтапно, тогда как другие HTTP-заголовки управляются сквозным образом. конец (управляется только исходным клиентом и целевым веб-сервером).
HTTP - это протокол прикладного уровня, разработанный в рамках набора Интернет-протоколов. Его определение предполагает лежащий в основе и надежный протокол транспортного уровня, поэтому обычно используется протокол управления передачей (TCP). Однако HTTP может быть адаптирован для использования ненадежных протоколов, таких как протокол дейтаграмм пользователя (UDP), например, в HTTPU и протоколе обнаружения простых служб (SSDP).
Ресурсы HTTP идентифицируются и размещаются в сети с помощью универсальных указателей ресурсов (URL) с использованием схем универсальных идентификаторов ресурсов (URI) http и https. Как определено в RFC 3986, URI кодируются как гиперссылки в HTML- документах, чтобы формировать взаимосвязанные гипертекстовые документы.
HTTP / 1.1 - это версия исходного HTTP (HTTP / 1.0). В HTTP / 1.0 для каждого запроса ресурса выполняется отдельное соединение с одним и тем же сервером. HTTP / 1.1 вместо этого может повторно использовать соединение для выполнения нескольких запросов ресурсов (например, HTML-страниц, фреймов, изображений, скриптов, таблиц стилей и т. Д.).
Таким образом, связь HTTP / 1.1 имеет меньшую задержку, поскольку установление TCP-соединений сопряжено со значительными накладными расходами, особенно в условиях высокого трафика.
HTTP / 2 - это версия предыдущего HTTP / 1.1, чтобы поддерживать ту же модель клиент-сервер и те же методы протокола, но с этими различиями в порядке:
Таким образом, связь HTTP / 2 имеет гораздо меньшую задержку и, в большинстве случаев, даже большую скорость, чем связь HTTP / 1.1.
HTTP / 3 - это ревизия предыдущего HTTP / 2 для использования транспортных протоколов UDP + QUIC вместо TCP / IP-соединений и, таким образом, для преодоления проблемы перегрузки TCP / IP-соединения, которая может блокировать или замедлять поток данных всех его потоки.
 Тим Бернерс-Ли
Тим Бернерс-Ли Термин гипертекст был введен Тедом Нельсоном в 1965 году в проекте Xanadu Project, который, в свою очередь, был вдохновлен видением Ванневаром Бушем 1930-х годов системы поиска и управления информацией на основе микрофильмов « memex », описанной в его эссе 1945 года « Как мы можем думать». ". Тиму Бернерсу-Ли и его команде в ЦЕРН приписывают изобретение оригинального протокола HTTP, а также HTML и связанной с ним технологии для веб- сервера и текстового веб-браузера. Бернерс-Ли впервые предложил проект «WorldWideWeb» в 1989 году, ныне известный как World Wide Web. Первый веб-сервер был запущен в 1990 году. Используемый протокол имел только один метод, а именно GET, который запрашивал страницу с сервера. Ответ сервера всегда представлял собой HTML-страницу.
Первая документированная версия HTTP была написана в 1991 году. Дэйв Рэггетт возглавил рабочую группу HTTP (HTTP WG) в 1995 году и хотел расширить протокол за счет расширенных операций, расширенного согласования, более богатой метаинформации, связанной с протоколом безопасности, который стал более широким. эффективен за счет добавления дополнительных методов и полей заголовка. RFC 1945 официально представил и признал HTTP версию 1.0 в 1996 году.
Рабочая группа HTTP планировала опубликовать новые стандарты в декабре 1995 года, и поддержка предварительного стандарта HTTP / 1.1 на основе разрабатываемого тогда RFC 2068 (называемого HTTP-NG) была быстро принята основными разработчиками браузеров в начале 1996 года. новых браузеров был быстрым. В марте 1996 года одна веб-хостинговая компания сообщила, что более 40% браузеров, используемых в Интернете, были совместимы с HTTP 1.1. Та же самая веб-хостинговая компания сообщила, что к июню 1996 года 65% всех браузеров, обращающихся к их серверам, были совместимы с HTTP / 1.1. Стандарт HTTP / 1.1, как определено в RFC 2068, был официально выпущен в январе 1997 года. Усовершенствования и обновления стандарта HTTP / 1.1 были выпущены в соответствии с RFC 2616 в июне 1999 года.
В 2007 году была сформирована рабочая группа HTTP, чтобы частично пересмотреть и прояснить спецификацию HTTP / 1.1.
В июне 2014 года WG выпустила обновленную спецификацию из шести частей, отменяющую RFC 2616 :
В мае 2015 года HTTP / 2 был опубликован как RFC 7540.
С 2016 года многие менеджеры по продуктам и разработчики пользовательских агентов (браузеров и т. Д.) И веб-серверов начали планировать постепенный отказ от поддержки протокола HTTP / 0.9 и прекращение ее поддержки, главным образом по следующим причинам:
В 2021 году поддержка HTTP / 0.9 по-прежнему будет присутствовать во многих веб-серверах и браузерах (только для ответов сервера), поэтому неясно, сколько времени займет это удаление, возможно, оно будет сначала выполнено в пользовательских агентах (браузерах и т. Д.), А затем в веб-серверы.
| Год | Версия |
|---|---|
| 1991 г. | HTTP / 0.9 |
| 1996 г. | HTTP / 1.0 |
| 1997 г. | HTTP / 1.1 |
| 2015 г. | HTTP / 2 |
| 2020 (проект) | HTTP / 3 |
Сеанс HTTP - это последовательность сетевых транзакций запрос – ответ. Клиент HTTP инициирует запрос, устанавливая соединение по протоколу управления передачей (TCP) с определенным портом на сервере (обычно порт 80, иногда порт 8080; см. Список номеров портов TCP и UDP ). HTTP-сервер, прослушивающий этот порт, ожидает сообщения запроса от клиента. После получения запроса сервер отправляет обратно строку состояния, например « HTTP / 1.1 200 OK », и собственное сообщение. Тело этого сообщения обычно является запрошенным ресурсом, хотя также может быть возвращено сообщение об ошибке или другая информация.
В HTTP / 0.9 TCP / IP соединение всегда закрыта после того, как ответ сервера был отправлен.
В HTTP / 1.0, как указано в RFC 1945, то TCP / IP соединение должно всегда быть закрыто сервером после того, как ответ был послан. ПРИМЕЧАНИЕ: с конца 1996 года некоторые разработчики популярных браузеров и серверов HTTP / 1.0 (особенно те, которые планировали также поддержку HTTP / 1.1) начали развертывать (как неофициальное расширение) своего рода механизм поддержания активности (с использованием новые заголовки HTTP), чтобы соединение TCP / IP оставалось открытым для более чем пары запрос / ответ и, таким образом, для ускорения обмена несколькими запросами / ответами.
В HTTP / 1.1 был официально представлен механизм keep-alive, так что соединение можно было повторно использовать для более чем одного запроса / ответа. Такие постоянные соединения заметно сокращают задержку запроса, поскольку клиенту не нужно повторно согласовывать соединение TCP 3-Way-Handshake после отправки первого запроса. Еще один положительный побочный эффект заключается в том, что в целом со временем соединение становится быстрее из-за механизма медленного старта TCP.
HTTP / 1.1 добавил также конвейерную обработку HTTP, чтобы еще больше сократить время задержки при использовании постоянных соединений, позволяя клиентам отправлять несколько запросов перед ожиданием каждого ответа. Эта оптимизация никогда не считалась действительно безопасной, потому что несколько веб-серверов и многие прокси-серверы, особенно прозрачные прокси-серверы, размещенные в Интернете / интрасети между клиентами и серверами, не обрабатывали конвейерные запросы должным образом (они обслуживали только первый запрос, отбрасывая другие, или они закрывались. соединение, потому что они увидели больше данных после первого запроса и т. д.). Помимо этого, в безопасном и идемпотентном режиме можно конвейеризовать только запросы GET и HEAD. После многих лет борьбы с проблемами, вызванными включением конвейерной обработки, эта функция была сначала отключена, а затем удалена из большинства браузеров также из-за объявленного принятия HTTP / 2.
HTTP / 2 расширил использование постоянных соединений за счет мультиплексирования множества одновременных запросов / ответов через одно соединение TCP / IP.
HTTP / 3 не использует TCP / IP-соединения, но UDP + QUIC, чтобы избежать проблемы перегрузки TCP / IP соединения.
В HTTP / 0.9 запрошенный ресурс всегда отправлялся целиком.
HTTP / 1.0 добавил заголовки для управления ресурсами, кэшируемыми клиентом, чтобы разрешить условные запросы GET ; на практике сервер должен возвращать все содержимое запрошенного ресурса только в том случае, если время его последнего изменения неизвестно клиенту или если оно изменилось с момента последнего полного ответа на запрос GET.
HTTP / 1.0 добавил заголовок «Content-Encoding», чтобы указать, было ли возвращенное содержимое ресурса сжатым или нет.
В HTTP / 1.0, если общая длина содержимого ресурса не была известна заранее (то есть потому, что он был динамически сгенерирован и т. Д.), Тогда заголовок "Content-Length: number"не присутствовал в заголовках HTTP, и клиент предполагал, что когда сервер закрывает соединение, содержание было отправлено полностью. Этот механизм не мог отличить успешно завершенную передачу ресурса от прерванной (из-за ошибки сервера / сети или чего-то еще).
HTTP / 1.1 добавил новые заголовки, чтобы лучше управлять условным извлечением кэшированных ресурсов.
HTTP / 1.1 представил кодирование передачи по частям, чтобы разрешить потоковую передачу контента по частям, чтобы надежно отправлять его, даже когда сервер не знает заранее его длину (т. Е. Потому, что он генерируется динамически и т. Д.).
HTTP / 1.1 добавил также обслуживание диапазона байтов, когда клиент может запросить только одну или несколько частей (диапазонов байтов) ресурса (то есть первую часть, часть в середине или в конце всего содержимого и т. Д.) и сервер обычно отправляет только запрошенные части. Это полезно для возобновления прерванной загрузки (когда файл действительно большой), когда только часть контента должна быть показана или динамически добавлена к уже видимой части браузером (т.е. только первый или следующие n комментариев из веб-страницу), чтобы сэкономить время, пропускную способность, системные ресурсы и т. д.
HTTP / 2 и HTTP / 3 сохранили вышеупомянутые функции HTTP / 1.1.
HTTP - это протокол без сохранения состояния. Протокол без сохранения состояния не требует, чтобы HTTP-сервер сохранял информацию или статус каждого пользователя в течение нескольких запросов. Однако некоторые веб-приложения реализуют состояния или сеансы на стороне сервера, используя, например, файлы cookie HTTP или скрытые переменные в веб-формах.
HTTP предоставляет несколько схем аутентификации, таких как базовая аутентификация доступа и дайджест-аутентификация доступа, которые работают через механизм запрос-ответ, посредством которого сервер идентифицирует и выдает запрос перед обслуживанием запрошенного контента.
HTTP обеспечивает общую структуру для управления доступом и аутентификации через расширяемый набор схем аутентификации запрос – ответ, которые могут использоваться сервером для оспаривания запроса клиента и клиентом для предоставления информации аутентификации.
Спецификация HTTP-аутентификации также предоставляет произвольную, зависящую от реализации конструкцию для дальнейшего разделения ресурсов, общих для данного корневого URI. Строка значения области, если она присутствует, комбинируется с каноническим корневым URI, чтобы сформировать компонент пространства защиты запроса. Фактически это позволяет серверу определять отдельные области аутентификации под одним корневым URI.
Клиент отправляет на сервер сообщения запроса, которые состоят из:
GET /images/logo.png HTTP/1.1Host: www.example.comAccept-Language: en
В протоколе HTTP / 1.1 все поля заголовка, за исключением, Host: hostnameявляются необязательными.
Строка запроса, содержащая только имя пути, принимается серверами для обеспечения совместимости с HTTP-клиентами до спецификации HTTP / 1.0 в RFC 1945.
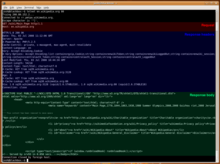 Запрос HTTP / 1.1, сделанный с помощью telnet. Запрос сообщение, ответ раздел заголовка и тело ответа выдвинуты на первый план.
Запрос HTTP / 1.1, сделанный с помощью telnet. Запрос сообщение, ответ раздел заголовка и тело ответа выдвинуты на первый план. HTTP определяет методы (иногда называемые глаголами, но нигде в спецификации не упоминается глагол, а OPTIONS или HEAD не является глаголом), чтобы указать желаемое действие, которое должно быть выполнено над идентифицированным ресурсом. Что представляет этот ресурс, будь то уже существующие данные или данные, которые генерируются динамически, зависит от реализации сервера. Часто ресурс соответствует файлу или выходным данным исполняемого файла, находящегося на сервере. Спецификация HTTP / 1.0 определила методы GET, HEAD и POST, а спецификация HTTP / 1.1 добавила пять новых методов: PUT, DELETE, CONNECT, OPTIONS и TRACE. Поскольку они указаны в этих документах, их семантика хорошо известна, и на нее можно положиться. Любой клиент может использовать любой метод, а сервер можно настроить для поддержки любой комбинации методов. Если метод неизвестен промежуточному звену, он будет рассматриваться как небезопасный и неидемпотентный метод. Нет ограничений на количество методов, которые могут быть определены, и это позволяет определять будущие методы без нарушения существующей инфраструктуры. Например, WebDAV определил семь новых методов, а RFC 5789 определил метод PATCH.
Имена методов чувствительны к регистру. Это контрастирует с именами полей заголовка HTTP, которые нечувствительны к регистру.
Все HTTP-серверы общего назначения должны реализовывать как минимум методы GET и HEAD, а все другие методы считаются необязательными в спецификации.
| Метод запроса | RFC | Запрос имеет тело полезной нагрузки | Ответ имеет тело полезной нагрузки | Безопасно | Идемпотент | Кэшируемый |
|---|---|---|---|---|---|---|
| ПОЛУЧАТЬ | RFC 7231 | По желанию | да | да | да | да |
| ГОЛОВА | RFC 7231 | По желанию | Нет | да | да | да |
| ПОЧТА | RFC 7231 | да | да | Нет | Нет | да |
| ПОЛОЖИЛ | RFC 7231 | да | да | Нет | да | Нет |
| УДАЛЯТЬ | RFC 7231 | По желанию | да | Нет | да | Нет |
| СОЕДИНЯТЬ | RFC 7231 | По желанию | да | Нет | Нет | Нет |
| ПАРАМЕТРЫ | RFC 7231 | По желанию | да | да | да | Нет |
| СЛЕД | RFC 7231 | Нет | да | да | да | Нет |
| ПЛАСТЫРЬ | RFC 5789 | да | да | Нет | Нет | Нет |
Метод запроса безопасен, если запрос с этим методом не оказывает ожидаемого воздействия на сервер. Методы GET, HEAD, OPTIONS и TRACE определены как безопасные. Другими словами, безопасные методы предназначены только для чтения. Однако они не исключают побочных эффектов, таких как добавление информации о запросе в файл журнала или начисление платы за рекламную учетную запись, поскольку они по определению не запрашиваются клиентом.
Напротив, методы POST, PUT, DELETE, CONNECT и PATCH небезопасны. Они могут изменять состояние сервера или иметь другие эффекты, такие как отправка электронного письма. Поэтому такие методы обычно не используются соответствующими веб-роботами или поисковыми роботами ; некоторые из них, как правило, обращаются с просьбами без учета контекста или последствий.
Несмотря на предписанную безопасность GET- запросов, на практике их обработка сервером никак не ограничивается технически. Следовательно, неосторожное или преднамеренное программирование может вызвать нетривиальные изменения на сервере. Это не рекомендуется, поскольку это может вызвать проблемы для веб-кеширования, поисковых систем и других автоматизированных агентов, которые могут вносить непреднамеренные изменения на сервере. Например, веб-сайт может разрешить удаление ресурса через URL-адрес, такой как https://example.com/article/1234/delete, который при произвольной выборке, даже с использованием GET, просто удалит статью.
Одним из примеров того, как это происходило на практике, была недолгая бета-версия Google Web Accelerator, которая предварительно выбирала произвольные URL-адреса на странице, которую просматривал пользователь, что приводило к автоматическому изменению или удалению записей в массовом порядке. Бета-версия была приостановлена всего через несколько недель после ее первого выпуска из-за широкой критики.
Метод запроса является идемпотентным, если несколько идентичных запросов с этим методом имеют тот же предполагаемый эффект, что и один такой запрос. Методы PUT и DELETE, а также безопасные методы определены как идемпотентные.
Напротив, методы POST, CONNECT и PATCH не обязательно являются идемпотентными, и поэтому отправка идентичного запроса POST несколько раз может дополнительно изменить состояние сервера или иметь дополнительные эффекты, такие как отправка электронной почты. В некоторых случаях это может быть желательно, но в других случаях это может быть связано с несчастным случаем, например, когда пользователь не осознает, что его действие приведет к отправке другого запроса, или он не получил адекватной обратной связи о том, что их первый запрос был успешный. Хотя веб-браузеры могут отображать диалоговые окна с предупреждениями, чтобы предупреждать пользователей в некоторых случаях, когда перезагрузка страницы может повторно отправить запрос POST, обычно веб-приложение должно обрабатывать случаи, когда запрос POST не должен отправляться более одного раза.
Обратите внимание, что то, является ли метод идемпотентным, не определяется протоколом или веб-сервером. Вполне возможно написать веб-приложение, в котором (например) вставка в базу данных или другое неидемпотентное действие запускается GET или другим запросом. Однако игнорирование этой рекомендации может привести к нежелательным последствиям, если пользовательский агент предполагает, что повторение одного и того же запроса безопасно, когда это не так.
Метод запроса кэшируется, если ответы на запросы с этим методом могут быть сохранены для повторного использования в будущем. Методы GET, HEAD и POST определены как кэшируемые.
Напротив, методы PUT, DELETE, CONNECT, OPTIONS, TRACE и PATCH не кэшируются.
Поля заголовка запроса позволяют клиенту передавать дополнительную информацию за пределы строки запроса, действуя как модификаторы запроса (аналогично параметрам процедуры). Они предоставляют информацию о клиенте, о целевом ресурсе или об ожидаемой обработке запроса.
Сервер отправляет клиенту ответные сообщения, которые состоят из:
HTTP/1.1 200 OKContent-Type: text/htmlВ HTTP / 1.0 и с тех пор первая строка ответа HTTP называется строкой состояния и включает числовой код состояния (например, « 404 ») и текстовую фразу причины (например, «Не найдено»). Код состояния ответа - это трехзначный целочисленный код, представляющий результат попытки сервера понять и удовлетворить соответствующий запрос клиента. То, как клиент обрабатывает ответ, зависит в первую очередь от кода состояния и, во вторую очередь, от других полей заголовка ответа. Клиенты могут не понимать все зарегистрированные коды состояния, но они должны понимать свой класс (заданный первой цифрой кода состояния) и рассматривать нераспознанный код состояния как эквивалентный коду состояния x00 этого класса.
Стандартные фразы причины являются только рекомендациями и могут быть заменены «местными эквивалентами» по усмотрению веб-разработчика. Если код состояния указывает на проблему, пользовательский агент может отобразить фразу причины для пользователя, чтобы предоставить дополнительную информацию о характере проблемы. Стандарт также позволяет пользовательскому агенту пытаться интерпретировать фразу причины, хотя это может быть неразумно, поскольку в стандарте явно указано, что коды состояния машиночитаемы, а фразы причины читаемы человеком.
Первая цифра кода состояния определяет его класс:
1XX (информационный)2XX (успешный)3XX (перенаправление)4XX (ошибка клиента)5XX (Ошибка сервера)Поля заголовка ответа позволяют серверу передавать дополнительную информацию за пределы строки состояния, действуя как модификаторы ответа. Они предоставляют информацию о сервере или о дальнейшем доступе к целевому ресурсу или связанным ресурсам.
Каждое поле заголовка ответа имеет определенное значение, которое может быть дополнительно уточнено семантикой метода запроса или кодом состояния ответа.
Самый популярный способ установления зашифрованного HTTP-соединения - HTTPS. Также существуют два других метода для установления зашифрованного HTTP-соединения: защищенный протокол передачи гипертекста и использование заголовка HTTP / 1.1 Upgrade для указания обновления до TLS. Однако поддержка этих двух браузеров практически отсутствует.
Ниже приведен пример диалога между HTTP-клиентом и HTTP-сервером, работающим на www.example.com, порт 80.
GET / HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8 Accept-Language: en-GB,en;q=0.5 Accept-Encoding: gzip, deflate, br Connection: keep-alive
За клиентским запросом (состоящим в данном случае из строки запроса и нескольких заголовков, которые могут быть сокращены до только "Host: hostname"заголовка) следует пустая строка, так что запрос заканчивается двойным концом строки, каждый в форме возврат каретки с последующим переводом строки. Значение "Host: hostname"заголовка различает различные имена DNS, совместно использующие один IP-адрес, что позволяет использовать виртуальный хостинг на основе имени. Хотя в HTTP / 1.0 это необязательно, в HTTP / 1.1 это обязательно. ("/" ( Косая черта) обычно приводит к извлечению файла /index.html, если он есть.)
HTTP/1.1 200 OK Date: Mon, 23 May 2005 22:38:34 GMT Content-Type: text/html; charset=UTF-8 Content-Length: 155 Last-Modified: Wed, 08 Jan 2003 23:11:55 GMT Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux) ETag: "3f80f-1b6-3e1cb03b" Accept-Ranges: bytes Connection: close lt;htmlgt; lt;headgt; lt;titlegt;An Example Pagelt;/titlegt; lt;/headgt; lt;bodygt; lt;pgt;Hello World, this is a very simple HTML document.lt;/pgt; lt;/bodygt; lt;/htmlgt;
Поле заголовка ETag (тег объекта) используется для определения того, идентична ли кэшированная версия запрошенного ресурса текущей версии ресурса на сервере. "Content-Type"указывает тип Интернет-носителя данных, передаваемых сообщением HTTP, а "Content-Length"указывает его длину в байтах. Веб- сервер HTTP / 1.1 публикует свою способность отвечать на запросы для определенных диапазонов байтов документа, устанавливая поле "Accept-Ranges: bytes". Это полезно, если клиенту нужно иметь только определенные части ресурса, отправленные сервером, что называется обслуживанием байтов. Когда "Connection: close"отправлено, это означает, что веб-сервер закроет TCP- соединение сразу после окончания передачи этого ответа.
Большинство строк заголовка являются необязательными, но некоторые являются обязательными. Если заголовок "Content-Length: number"отсутствует в ответе с телом объекта, это следует рассматривать как ошибку в HTTP / 1.0, но это может не быть ошибкой в HTTP / 1.1, если заголовок "Transfer-Encoding: chunked"присутствует. При кодировании с фрагментированной передачей размер фрагмента равен 0, чтобы пометить конец содержимого. Некоторые старые реализации HTTP / 1.0 опускали заголовок, "Content-Length"когда длина объекта тела не была известна в начале ответа, и поэтому передача данных клиенту продолжалась до тех пор, пока сервер не закроет сокет.
A может использоваться для информирования клиента о том, что часть тела передаваемых данных сжимается с помощью алгоритма gzip. "Content-Encoding: gzip "
| HTTP |
|---|
| Способы запроса |
| Поля заголовка |
| Коды статуса ответа |
| Методы управления безопасным доступом |
| Уязвимости безопасности |
|