Базовая модель шума, используемая в теории информации для имитации эффекта многих случайных процессов, происходящих в природе
Аддитивный белый гауссовский noise (AWGN ) - это базовая модель шума, используемая в теории информации для имитации эффекта многих случайных процессов, происходящих в природе. Модификаторы обозначают определенные характеристики:
- Аддитив , потому что он добавляется к любому шуму, который может быть характерен для информационной системы.
- Белый относится к идее, что он имеет равномерную мощность в полосе частот для информационная система. Это аналогия белого цвета, который имеет однородное излучение на всех частотах в видимом спектре.
- по Гауссу , потому что он имеет нормальное распределение во временной области со средней временной областью. нулевое значение.
Широкополосный шум возникает из многих естественных источников шума, таких как тепловые колебания атомов в проводниках (называемые тепловыми шумами или шумом Джонсона – Найквиста ), дробовым шумом, излучение черного тела от Земли и других теплых объектов, а также от небесных источников, таких как Солнце. центральная предельная теорема из теории вероятностей указывает, что суммирование многих случайных процессов будет иметь тенденцию к распределению, называемому гауссовым или нормальным.
AWGN часто используется в качестве модели канала , в которой единственное ухудшение связи - линейное добавление широкополосного или белого шума с постоянная спектральная плотность (выраженная как ватт на герц из ширины полосы ) и гауссово распределение амплитуды. Модель не учитывает замирание, частоту избирательность, помехи, нелинейность или дисперсию. Тем не менее, он создает простые и понятные математические модели, которые полезны для понимания основного поведения системы до рассмотрения этих других явлений.
Канал AWGN является хорошей моделью для многих спутниковых каналов связи в дальнем космосе. Это не лучшая модель для большинства наземных линий связи из-за многолучевого распространения, блокировки местности, помех и т. Д. Однако для моделирования наземного пути AWGN обычно используется для моделирования фонового шума исследуемого канала в дополнение к многолучевости, блокировке местности и т. Д. помехи, помехи от земли и собственные помехи, с которыми современные радиосистемы сталкиваются при наземной эксплуатации.
Содержание
- 1 Пропускная способность канала
- 1.1 Пропускная способность канала и упаковка сфер
- 1.2 Достижимость
- 1.3 Преобразование теоремы кодирования
- 2 Эффекты во временной области
- 3 Эффекты в векторной области
- 4 См. Также
- 5 Ссылки
Емкость канала
Канал AWGN представлен серией выходов  на дискретных индекс временного события
на дискретных индекс временного события  . - это сумма входных
. - это сумма входных  и шум,
и шум,  , где - независимый и одинаково распределенный и полученный из нормального распределения с нулевым средним с дисперсией
, где - независимый и одинаково распределенный и полученный из нормального распределения с нулевым средним с дисперсией  ( шум). также предполагается, что не коррелирует с .
( шум). также предполагается, что не коррелирует с .


Емкость канала бесконечна, если только шум не равно нулю, и достаточно ограничены. Наиболее распространенным ограничением ввода является так называемое ограничение «мощности», которое требует, чтобы для кодового слова  передается по каналу, мы имеем:
передается по каналу, мы имеем:

где  представляет максимальную мощность канала. Следовательно, пропускная способность канала для канала с ограниченной мощностью определяется как:
представляет максимальную мощность канала. Следовательно, пропускная способность канала для канала с ограниченной мощностью определяется как:

где  - это распределение
- это распределение  . Разверните
. Разверните  , записав его в терминах дифференциальной энтропии :
, записав его в терминах дифференциальной энтропии :

Но и  независимы, поэтому:
независимы, поэтому:

Оценка дифференциальной энтропии гауссовского дает:

Поскольку и независимы и их сумма дает  :
:

Из этой оценки мы получаем из собственного ty дифференциальной энтропии, что

Следовательно, пропускная способность канала задается наивысшей достижимой границей взаимной информации :

Где максимизируется, когда:

Таким образом, пропускная способность канала  для канала AWGN определяется как:
для канала AWGN определяется как:

Пропускная способность канала и упаковка сфер
Предположим, что мы отправляем сообщения по каналу с индексом от  до
до  , количество различных возможные сообщения. Если мы кодируем сообщения в
, количество различных возможные сообщения. Если мы кодируем сообщения в  бит, то мы определяем скорость
бит, то мы определяем скорость  как:
как:

Скорость называется достижимо, если существует последовательность кодов, так что максимальная вероятность ошибки стремится к нулю, поскольку приближается к бесконечности. Емкость - это наивысшая достижимая скорость.
Рассмотрим кодовое слово длиной , отправленное через канал AWGN с уровнем шума . При получении отклонение вектора кодового слова теперь составляет , а его средним значением является отправленное кодовое слово. Скорее всего, вектор будет находиться в сфере радиуса  вокруг отправленного кодового слова. Если мы декодируем, отображая каждое полученное сообщение на кодовое слово в центре этой сферы, то ошибка возникает только тогда, когда полученный вектор находится за пределами этой сферы, что очень маловероятно.
вокруг отправленного кодового слова. Если мы декодируем, отображая каждое полученное сообщение на кодовое слово в центре этой сферы, то ошибка возникает только тогда, когда полученный вектор находится за пределами этой сферы, что очень маловероятно.
С каждым вектором кодового слова связана сфера принятых векторов кодового слова, которые декодируются в него, и каждая такая сфера должна однозначно отображаться на кодовое слово. Поскольку эти сферы не должны пересекаться, мы сталкиваемся с проблемой упаковки сфер. Сколько различных кодовых слов мы можем упаковать в наш -битный вектор кодовых слов? Полученные векторы имеют максимальную энергию  и, следовательно, должны занимать сферу радиуса
и, следовательно, должны занимать сферу радиуса  . Каждая сфера кодового слова имеет радиус
. Каждая сфера кодового слова имеет радиус  . Объем n-мерной сферы прямо пропорционален
. Объем n-мерной сферы прямо пропорционален  , поэтому максимальное количество уникально декодируемых сфер, которые могут быть упакованы в нашу сферу с мощностью передачи P равно:
, поэтому максимальное количество уникально декодируемых сфер, которые могут быть упакованы в нашу сферу с мощностью передачи P равно:

Согласно этому аргументу, коэффициент R не может быть больше  .
.
Достижимость
В этом разделе мы показываем достижимость верхней границы ставки из последнего раздела.
Кодовая книга, известная как кодировщику, так и декодеру, создается путем выбора кодовых слов длины n, i.i.d. Гауссовский с дисперсией  и нулевым средним. Для большого n эмпирическая дисперсия кодовой книги будет очень близка к дисперсии ее распределения, тем самым избегая вероятностного нарушения ограничения мощности.
и нулевым средним. Для большого n эмпирическая дисперсия кодовой книги будет очень близка к дисперсии ее распределения, тем самым избегая вероятностного нарушения ограничения мощности.
Принятые сообщения декодируются в сообщение в кодовой книге, которое является уникальным совместно типичным. Если такого сообщения нет или если ограничение мощности нарушено, объявляется ошибка декодирования.
Пусть  обозначает кодовое слово для сообщения , а
обозначает кодовое слово для сообщения , а  , как и перед полученным вектором. Определите следующие три события:
, как и перед полученным вектором. Определите следующие три события:
- Событие
 : мощность полученного сообщения больше, чем .
: мощность полученного сообщения больше, чем . - Event
 : переданные и полученные кодовые слова не являются типичными вместе.
: переданные и полученные кодовые слова не являются типичными вместе. - Событие
 :
:  находится в
находится в  , типичный набор, где
, типичный набор, где  , то есть что неверное кодовое слово является типичным вместе с полученным вектором.
, то есть что неверное кодовое слово является типичным вместе с полученным вектором.
Следовательно, возникает ошибка, если , или любое из  встречаются. По закону больших чисел
встречаются. По закону больших чисел  стремится к нулю, когда n приближается к бесконечности, а по совместному свойству асимптотической равнораспределенности то же самое относится к
стремится к нулю, когда n приближается к бесконечности, а по совместному свойству асимптотической равнораспределенности то же самое относится к  . Следовательно, для достаточно большого оба и меньше, чем
. Следовательно, для достаточно большого оба и меньше, чем  . Поскольку и
. Поскольку и  независимы для , мы имеем, что и также независимы. Следовательно, по совместному AEP
независимы для , мы имеем, что и также независимы. Следовательно, по совместному AEP  . Это позволяет нам вычислить
. Это позволяет нам вычислить  вероятность ошибки следующим образом:
вероятность ошибки следующим образом:

Следовательно, когда n приближается к бесконечности, обнуляется и
Теорема кодирования, обратная
Здесь мы показываем, что ставки выше емкости  недостижимы.
недостижимы.
Предположим, что ограничение мощности удовлетворено для кодовой книги, и дополнительно предположим, что сообщения следуют равномерному распределению. Пусть  будет входными сообщениями, а
будет входными сообщениями, а  выходными сообщениями. Таким образом, информация течет следующим образом:
выходными сообщениями. Таким образом, информация течет следующим образом:

Использование неравенства Фано дает:
 где
где  как
как 
Пусть будет закодированным сообщением с индексом кодового слова i. Тогда:

Пусть  будет средней мощностью кодового слова индекса i:
будет средней мощностью кодового слова индекса i:

Где сумма по всем входным сообщениям  . и независимы, поэтому ожидание мощности является для уровня шума :
. и независимы, поэтому ожидание мощности является для уровня шума :

И, если нормально распределен, мы имеем, что

Следовательно,

Мы можем применить равенство Дженсена к  , вогнутая (нисходящая) функция от x, чтобы получить:
, вогнутая (нисходящая) функция от x, чтобы получить:

Поскольку каждое кодовое слово индивидуально удовлетворяет ограничению мощности, среднее значение также удовлетворяет ограничению мощности. Следовательно,

Что мы можем применить, чтобы упростить неравенство выше, и получить:

Следовательно, должно быть, что  . Следовательно, R должно быть меньше значения, произвольно близкого к мощности, полученной ранее, так как .
. Следовательно, R должно быть меньше значения, произвольно близкого к мощности, полученной ранее, так как .
Эффекты во временной области
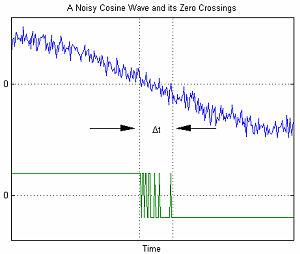
Ноль- Пересечение зашумленного косинуса
При последовательной передаче данных математическая модель AWGN используется для моделирования ошибки синхронизации, вызванной случайным джиттером (RJ).
На графике справа показан пример ошибок синхронизации, связанных с AWGN. Переменная Δt представляет собой неопределенность перехода через нуль. По мере увеличения амплитуды AWGN отношение сигнал / шум уменьшается. Это приводит к увеличению неопределенности Δt.
Под воздействием AWGN среднее количество переходов через нуль в положительную или отрицательную сторону в секунду на выходе узкополосного фильтра, когда на входе является синусоидальная волна:


Где
- f0= центральная частота фильтра
- B = ширина полосы фильтра
- SNR = отношение мощности сигнала к шуму в линейном выражении
Эффекты в векторной области

Вклад AWGN в фазорной области
В современных системах связи, AWGN с ограничением полосы пропускания игнорировать нельзя. При моделировании AWGN с ограниченной полосой пропускания в области вектор статистический анализ показывает, что амплитуды реальных и мнимых вкладов являются независимыми переменными, которые следуют модели гауссова распределения. При объединении величина результирующего фазора представляет собой случайную величину с распределением Рэлея, в то время как фаза равномерно распределена от 0 до 2π.
График справа показывает пример того, как AWGN с ограниченной полосой частот может влиять на сигнал когерентной несущей. Мгновенный отклик вектора шума невозможно точно предсказать, однако его усредненный по времени отклик можно предсказать статистически. Как показано на графике, мы уверенно прогнозируем, что вектор шума будет находиться внутри круга 1σ примерно 38% времени; вектор шума будет находиться внутри круга 2σ примерно 86% времени; а вектор шума будет находиться внутри круга 3σ около 98% времени.
См. также
Ссылки

 Ноль- Пересечение зашумленного косинуса
Ноль- Пересечение зашумленного косинуса  Вклад AWGN в фазорной области
Вклад AWGN в фазорной области