
Войти
В математике последовательность с низким расхождением - это последовательность, обладающая тем свойством, что для всех значений N ее подпоследовательность x 1,..., x N имеет низкое расхождение.
Грубо говоря, несоответствие последовательности является низким, если доля точек в последовательности, попадающей в произвольное множестве B близка к пропорциональна степени из B, так как будет происходить в среднем (но не для конкретных образцов) в случае равнораспределен последовательность. Конкретные определения несоответствия различаются в зависимости от выбора B ( гиперсферы, гиперкубы и т. Д.) И того, как вычисляется (обычно нормализуется) и комбинируется несоответствие для каждого B (обычно с использованием наихудшего значения).
Последовательности с низким расхождением также называются квазислучайными последовательностями из-за их общего использования в качестве замены равномерно распределенных случайных чисел. Модификатор «квази» используется для более четкого обозначения того, что значения последовательности с низким расхождением не являются ни случайными, ни псевдослучайными, но такие последовательности обладают некоторыми свойствами случайных величин, а в некоторых приложениях, таких как метод квази-Монте-Карло, их меньшее расхождение. это важное преимущество.
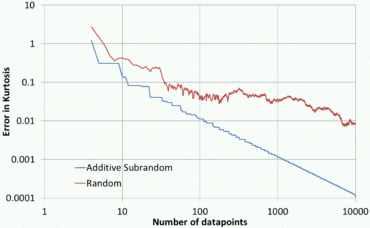 Ошибка в оценке эксцесса как функции количества точек данных. «Аддитивная квазислучайность» дает максимальную ошибку, когда c = ( √ 5 - 1) / 2. «Случайный» дает среднюю ошибку по шести сериям случайных чисел, где среднее значение берется для уменьшения величины диких колебаний.
Ошибка в оценке эксцесса как функции количества точек данных. «Аддитивная квазислучайность» дает максимальную ошибку, когда c = ( √ 5 - 1) / 2. «Случайный» дает среднюю ошибку по шести сериям случайных чисел, где среднее значение берется для уменьшения величины диких колебаний. Квазислучайные числа имеют преимущество перед чистыми случайными числами в том, что они быстро и равномерно покрывают интересующую область. У них есть преимущество перед чисто детерминированными методами в том, что детерминированные методы дают высокую точность только тогда, когда количество точек данных предварительно установлено, тогда как при использовании квазислучайных последовательностей точность обычно постоянно повышается по мере добавления дополнительных точек с полным повторным использованием существующих точек. С другой стороны, квазислучайные наборы точек могут иметь значительно меньшее расхождение для заданного числа точек, чем чисто случайные последовательности.
Два полезных приложений находятся в поиске характеристической функции в виде функции плотности вероятности, и при нахождении производной функции детерминированной функции с небольшим количеством шума. Квазислучайные числа позволяют очень быстро вычислять моменты более высокого порядка с высокой точностью.
Приложения, которые не включают сортировку, заключаются в нахождении среднего, стандартного отклонения, асимметрии и эксцесса статистического распределения, а также в нахождении интегральных и глобальных максимумов и минимумов сложных детерминированных функций. Квазислучайные числа также могут использоваться для обеспечения отправных точек для детерминированных алгоритмов, которые работают только локально, например, итерация Ньютона – Рафсона.
Квазислучайные числа также можно комбинировать с алгоритмами поиска. Алгоритм в стиле быстрой сортировки двоичного дерева должен работать исключительно хорошо, потому что квазислучайные числа сглаживают дерево намного лучше, чем случайные числа, и чем более плоское дерево, тем быстрее выполняется сортировка. С помощью алгоритма поиска можно использовать квазислучайные числа для нахождения режима, медианы, доверительных интервалов и совокупного распределения статистического распределения, а также всех локальных минимумов и всех решений детерминированных функций.
По крайней мере, три метода численного интегрирования можно сформулировать следующим образом. Учитывая набор { x 1,..., x N } в интервале [0,1], аппроксимируйте интеграл функции f как среднее значение функции, вычисленной в этих точках:
Если точки выбраны как x i = i / N, это правило прямоугольника. Если точки выбраны для случайного (или псевдослучайного ) распределения, это метод Монте-Карло. Если точки выбраны как элементы последовательности с низким расхождением, это квази-Монте-Карло метод. Замечательный результат, неравенство Коксмы – Главки (изложенное ниже), показывает, что погрешность такого метода может быть ограничена произведением двух членов, одно из которых зависит только от f, а другое - невязка множества { x 1,..., x N }.
Множество { x 1,..., x N } удобно построить таким образом, чтобы при построении набора из N +1 элементов не нужно было пересчитывать предыдущие N элементов. Правило прямоугольника использует набор точек с низким расхождением, но в целом элементы должны быть пересчитаны, если N увеличивается. Элементы не нужно пересчитывать в случайном методе Монте-Карло, если N увеличивается, но наборы точек не имеют минимального расхождения. Используя последовательности с низким несоответствием, мы стремимся к низкому несоответствию и отсутствию необходимости в повторных вычислениях, но на самом деле последовательности с низким несоответствием могут быть постепенно улучшены при несоответствии, если мы не допускаем повторного вычисления.
Несоответствие из множества Р = { х 1,..., х N } определяется, используя Нидеррейтер в обозначение, как и
где λ s - s -мерная мера Лебега, A ( B ; P) - количество точек в P, попадающих в B, а J - множество s -мерных интервалов или ящиков вида
где.
Звезда несоответствие Д *Н ( Р) определяется аналогично, за исключением того, что верхняя грань берется по множеству J * прямоугольных коробок вида
где u i находится в полуоткрытом интервале [0, 1).
Эти двое связаны между собой
Примечание: с этими определениями несоответствие представляет собой наихудшее или максимальное отклонение плотности точек однородного набора. Однако значимы и другие меры погрешности, ведущие к другим определениям и мерам вариации. Например, L2-несоответствие или модифицированное центрированное L2-несоответствие также интенсивно используются для сравнения качества однородных наборов точек. И то, и другое намного проще вычислить для больших N и s.
Пусть Ī s - s -мерный единичный куб, Ī s = [0, 1] ×... × [0, 1]. Пусть f имеет ограниченную вариацию V ( f) на s в смысле Харди и Краузе. Тогда для любых x 1,..., x N в I s = [0, 1) ×... × [0, 1),
Коксма - Hlawka неравенство является точным в следующем смысле: для любой точки множества { х 1,..., х N } в Я ей и любой, существует функция F с ограниченной вариации и V ( ф) = 1 такой, что
Следовательно, качество правила численного интегрирования зависит только от расхождения D *N ( x 1,..., x N).
Пусть. Для нас пишут
и обозначим точкой, полученной из x заменой координат, не входящих в u, на. потом
где - функция невязки.
Применяя неравенство Коши – Шварца для интегралов и сумм к тождеству Главки – Зарембы, получаем версию неравенства Коксмы – Главки:
где
а также
Расхождение L2 имеет большое практическое значение, поскольку для данного набора точек возможны быстрые явные вычисления. Таким образом, легко создавать оптимизаторы набора точек, используя в качестве критериев несоответствие L2.
Вычислительно сложно найти точное значение невязки больших наборов точек. Erdős - Туран - Коксм неравенство дает верхнюю границу.
Пусть x 1,..., x N - точки в I s, а H - произвольное положительное целое число. потом
где
Гипотеза 1. Существует постоянная c s, зависящая только от размерности s, такая, что
для любого конечного точечного множества { x 1,..., x N }.
Гипотеза 2. Существует константа с 'S, зависящим только от х, такой, что
для бесконечного числа N для любой бесконечной последовательности x 1, x 2, x 3,....
Эти предположения эквивалентны. Они были доказаны для s ≤ 2 В. М. Шмидтом. В более высоких измерениях соответствующая проблема все еще остается открытой. Наиболее известные нижние оценки получены Майклом Лейси и соавторами.
Пусть s = 1. Тогда
для любого конечного точечного множества { x 1,..., x N }.
Пусть s = 2. В. М. Шмидт доказал, что для любого конечного точечного множества { x 1,..., x N },
где
К.Ф. Рот для произвольных размерностей s gt; 1 доказал, что
для любого конечного точечного множества { x 1,..., x N }. Йозеф Бек добился двукратного улучшения этого результата в трех измерениях. Это было улучшено Д. Билыком и М. Т. Лейси до степени единственного логарифма. Наиболее известная оценка для s gt; 2 принадлежит Д. Билыку, М. Т. Лейси и А. Вагаршакяну. Для s gt; 2 существует t gt; 0, так что
для любого конечного точечного множества { x 1,..., x N }.
Поскольку любое распределение случайных чисел может быть отображено в однородное распределение, а квазислучайные числа отображаются таким же образом, эта статья касается только генерации квазислучайных чисел в многомерном равномерном распределении.
Известны конструкции последовательностей такие, что
где C - некоторая постоянная, зависящая от последовательности. После гипотезы 2 считается, что эти последовательности имеют наилучший порядок сходимости. Примеры ниже являются ван - дер - последовательности Корпута, в последовательности Halton, и последовательностей Соболь. Одним из общих ограничений является то, что методы построения обычно могут гарантировать только порядок сходимости. На практике низкое расхождение может быть достигнуто только в том случае, если N достаточно велико, а при большом заданном s этот минимум N может быть очень большим. Это означает, что выполнение анализа Монте-Карло, например, с s = 20 переменными и N = 1000 точками из генератора последовательности с низким расхождением, может дать лишь очень незначительное улучшение точности.
Последовательности квазислучайных чисел могут быть сгенерированы из случайных чисел путем наложения отрицательной корреляции на эти случайные числа. Один из способов сделать это, чтобы начать с набором случайных чисел на и числах конструкта квазислучайных, равномерные на использовании:
для нечетных и для четных.
Второй способ сделать это с начальными случайными числами - построить случайное блуждание со смещением 0,5, как в:
То есть возьмите предыдущее квазислучайное число, сложите 0,5 и случайное число и возьмите результат по модулю 1.
Для более чем одного измерения можно использовать латинские квадраты соответствующего измерения для обеспечения смещения, чтобы гарантировать равномерное покрытие всей области.
 Покрытие единицы кв. Слева для аддитивных квазислучайных чисел с c = 0,5545497..., 0,308517... Справа для случайных чисел. Сверху донизу. 10, 100, 1000, 10000 очков.
Покрытие единицы кв. Слева для аддитивных квазислучайных чисел с c = 0,5545497..., 0,308517... Справа для случайных чисел. Сверху донизу. 10, 100, 1000, 10000 очков. Для любого иррационального последовательность
имеет тенденцию к несоответствию. Обратите внимание, что последовательность может быть определена рекурсивно с помощью
Хорошее значение дает меньшее расхождение, чем последовательность независимых однородных случайных чисел.
Несоответствие может быть ограничена аппроксимации экспоненты в. Если показатель аппроксимации равен, то для любого имеет место следующая оценка:
По теореме Туэ – Зигеля – Рота показатель приближения любого иррационального алгебраического числа равен 2, что дает оценку выше.
Приведенное выше рекуррентное отношение аналогично рекуррентному отношению, используемому линейным конгруэнтным генератором, генератором псевдослучайных чисел низкого качества:
Для описанной выше аддитивной повторяемости с низким расхождением a и m выбраны равными 1. Обратите внимание, однако, что это не будет генерировать независимых случайных чисел, поэтому не должно использоваться для целей, требующих независимости.
Значение с наименьшим расхождением равно
Еще одно значение, которое почти так же хорошо, это:
В более чем одном измерении для каждого измерения необходимы отдельные квазислучайные числа. Удобный набор используемых значений - это квадратные корни из простых чисел от двух вверх, взятые по модулю 1:
Однако было показано, что набор значений, основанный на обобщенном золотом сечении, дает более равномерно распределенные точки.
В списке генераторов псевдослучайных чисел перечислены методы генерации независимых псевдослучайных чисел. Примечание. В некоторых измерениях рекурсивное повторение приводит к однородным наборам хорошего качества, но для больших s (например, sgt; 8) другие генераторы наборов точек могут предложить гораздо меньшие расхождения.
Позволять
- b -арное представление натурального числа n ≥ 1, т. е. 0 ≤ d k ( n) lt; b. Набор
Тогда существует постоянная C, зависящая только от b такая, что ( g b ( n)) n ≥ 1 удовлетворяет
где D *N - звездная невязка.
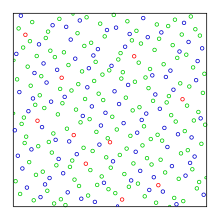 Первые 256 точек (2,3) последовательности Халтона Основная статья: последовательность Холтона
Первые 256 точек (2,3) последовательности Халтона Основная статья: последовательность Холтона Последовательность Халтона является естественным обобщением последовательности Ван дер Корпута на более высокие измерения. Пусть s - произвольная размерность, а b 1,..., b s - произвольные взаимно простые целые числа больше 1. Определим
Тогда существует константа C, зависящая только от b 1,..., b s, такая, что последовательность { x ( n)} n ≥1 является s -мерной последовательностью с
 2D набор Хаммерсли размера 256
2D набор Хаммерсли размера 256 Пусть Ь 1,..., б ы -1 быть взаимно простым целыми положительными числами больше 1. При заданной ей и N, то ев - мерном Хаммерл набор размера N определяется путем
для п = 1,..., N. потом
где C - постоянная, зависящая только от b 1,..., b s −1. Примечание: формулы показывают, что множество Хаммерсли на самом деле является последовательностью Халтона, но мы бесплатно получаем еще одно измерение, добавляя линейную развертку. Это возможно только в том случае, если заранее известно N. Линейное множество - это также множество с минимально возможным одномерным несоответствием в целом. К сожалению, для более высоких измерений такие «наборы записей несоответствия» не известны. Для s = 2 большинство генераторов наборов точек с малым расхождением выдают расхождения, по крайней мере, почти оптимальные.
Вариант Антонова – Салеева последовательности Соболя генерирует числа от нуля до единицы непосредственно как двоичные дроби длины из набора специальных двоичных дробей, называемых числами направления. Биты кода Грея из,, используются для выбора номера направления. Чтобы получить значение последовательности Соболя, возьмите исключающее ИЛИ двоичного значения кода Грея с соответствующим номером направления. Количество требуемых размеров влияет на выбор.
Выборка диска Пуассона популярна в видеоиграх для быстрого размещения объектов так, чтобы они выглядели случайными, но гарантируют, что каждые две точки разделены по крайней мере на указанное минимальное расстояние. Это не гарантирует низкого расхождения (как, например, Соболь), но по крайней мере значительно меньшее расхождение, чем чистая случайная выборка. Цель этих шаблонов выборки основана на частотном анализе, а не на несоответствии, типе так называемых шаблонов «синего шума».
Точки, нанесенные ниже, - это первые 100, 1000 и 10000 элементов последовательности типа Соболь. Для сравнения также показаны 10000 элементов последовательности псевдослучайных точек. Последовательность с низким расхождением была сгенерирована алгоритмом 659 TOMS. Реализация алгоритма на Фортране доступна в Netlib.
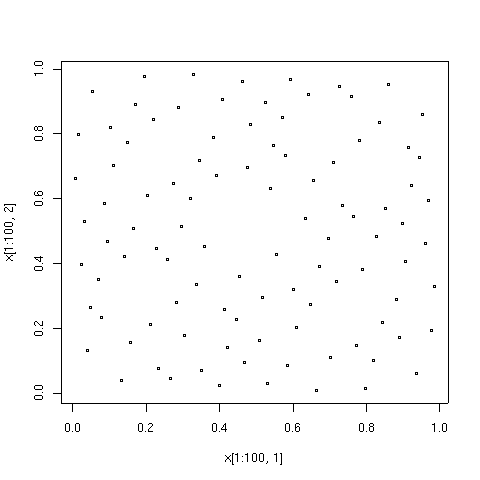 Первые 100 точек в последовательности с малым расхождением типа Соболя.
Первые 100 точек в последовательности с малым расхождением типа Соболя. 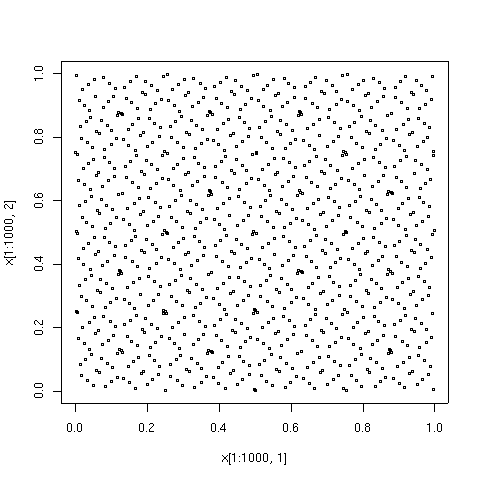 Первые 1000 точек в той же последовательности. Эти 1000 составляют первые 100 с еще 900 очками.
Первые 1000 точек в той же последовательности. Эти 1000 составляют первые 100 с еще 900 очками. 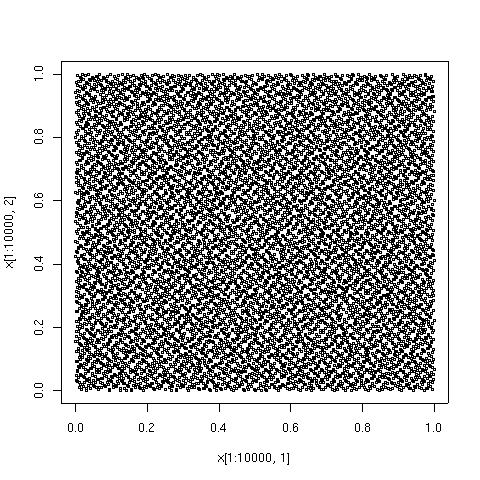 Первые 10000 точек в той же последовательности. Эти 10000 составляют первую 1000 с еще 9000 очками.
Первые 10000 точек в той же последовательности. Эти 10000 составляют первую 1000 с еще 9000 очками. 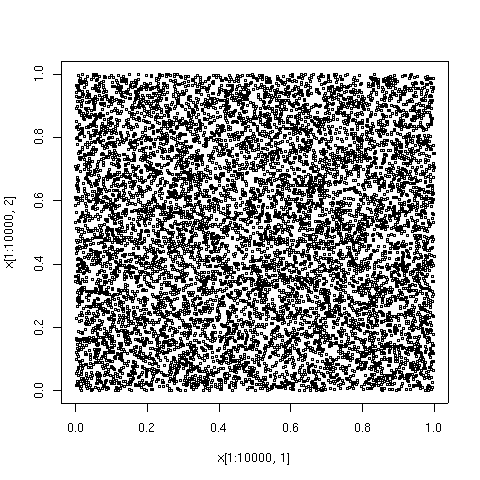 Для сравнения - первые 10000 точек в последовательности равномерно распределенных псевдослучайных чисел. Очевидны области большей и меньшей плотности.
Для сравнения - первые 10000 точек в последовательности равномерно распределенных псевдослучайных чисел. Очевидны области большей и меньшей плотности. 














![{\ displaystyle {\ frac {1} {N}} \ sum _ {i = 1} ^ {N} f (x_ {i}) - \ int _ {{\ bar {I}} ^ {s}} f (u) \, du = \ sum _ {\ emptyset \ neq u \ substeq D} (- 1) ^ {| u |} \ int _ {[0,1] ^ {| u |}} \ operatorname {disk } (x_ {u}, 1) {\ frac {\ partial ^ {| u |}} {\ partial x_ {u}}} f (x_ {u}, 1) \, dx_ {u},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/646d05c4c12cae58e128651816856d90c9a25e51)


![{\ displaystyle \ operatorname {disc} _ {d} (\ {t_ {i} \}) = \ left (\ sum _ {\ emptyset \ neq u \ substeq D} \ int _ {[0,1] ^ { | u |}} \ operatorname {disc} (x_ {u}, 1) ^ {2} \, dx_ {u} \ right) ^ {1/2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/609a886b91fa44773d2ddd89c752bc1a037309a6)
![{\ Displaystyle \ | е \ | _ {d} = \ left (\ sum _ {u \ substeq D} \ int _ {[0,1] ^ {| u |}} \ left | {\ frac {\ partial ^ {| u |}} {\ partial x_ {u}}} f (x_ {u}, 1) \ right | ^ {2} dx_ {u} \ right) ^ {1/2}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/dee8232a0985af6392e00e77e9bdfa8c4f98fe77)














 для нечетных и для четных.
для нечетных и для четных. 
























