В теории кодирования блочные коды представляют собой большое и важное семейство коды исправления ошибок, которые кодируют данные в блоках. Существует огромное количество примеров блочных кодов, многие из которых имеют широкий спектр практических применений. Абстрактное определение блочных кодов концептуально полезно, потому что оно позволяет теоретикам кодирования, математикам и компьютерным специалистам изучать ограничения всех блочных кодов унифицированным способом. Такие ограничения часто принимают форму границ, которые связывают различные параметры блочного кода друг с другом, такие как его скорость и его способность обнаруживать и исправлять ошибки.
Примеры блочных кодов: коды Рида – Соломона, коды Хэмминга, коды Адамара, коды расширителей, коды Голея и коды Рида – Маллера. Эти примеры также принадлежат к классу линейных кодов, и поэтому они называются линейными блочными кодами . В частности, эти коды известны как алгебраические блочные коды или циклические блочные коды, потому что они могут быть сгенерированы с использованием логических полиномов.
Алгебраические блочные коды обычно жестко декодируются с использованием алгебраических декодеров.
Термин блочный код может также относиться к любому коду с исправлением ошибок, который действует на блок  битов входных данных для создания
битов входных данных для создания  битов выходных данных
битов выходных данных  . Следовательно, блочный кодер - это устройство без памяти. В соответствии с этим определением коды, такие как турбокоды, сверточные коды с завершением и другие итеративно декодируемые коды (турбоподобные коды), также будут считаться блочными кодами. Сверточный кодер без завершения может быть примером неблочного (без кадра) кода, который имеет память и вместо этого классифицируется как древовидный код.
. Следовательно, блочный кодер - это устройство без памяти. В соответствии с этим определением коды, такие как турбокоды, сверточные коды с завершением и другие итеративно декодируемые коды (турбоподобные коды), также будут считаться блочными кодами. Сверточный кодер без завершения может быть примером неблочного (без кадра) кода, который имеет память и вместо этого классифицируется как древовидный код.
В этой статье рассматриваются «алгебраические блочные коды».
Содержание
- 1 Код блока и его параметры
- 1.1 Алфавит Σ
- 1.2 Длина сообщения k
- 1.3 Длина блока n
- 1.4 Скорость R
- 1.5 Расстояние d
- 1.6 Популярные обозначения
- 2 Примеры
- 3 Свойства обнаружения и исправления ошибок
- 4 Нижняя и верхняя границы блочных кодов
- 4.1 Семейство кодов
- 4.2 Граница Хэмминга
- 4.3 Синглтон граница
- 4.4 Граница Плоткина
- 4.5 Граница Гилберта – Варшамова
- 4.6 Граница Джонсона
- 4.7 Граница Элиаса – Бассалиго
- 5 Сферические упаковки и решетки
- 6 См. также
- 7 Ссылки
- 8 Внешние ссылки
Код блока и его параметры
Коды с исправлением ошибок используются для надежной передачи цифровых данных по ненадежным каналам связи с учетом шума канала. Когда отправитель хочет передать, возможно, очень длинный поток данных с использованием блочного кода, отправитель разбивает поток на части некоторого фиксированного размера. Каждая такая часть называется сообщением, и процедура, заданная блочным кодом, кодирует каждое сообщение индивидуально в кодовое слово, также называемое блоком в контексте блочных кодов. Затем отправитель передает все блоки получателю, который, в свою очередь, может использовать некоторый механизм декодирования для (надеюсь) восстановления исходных сообщений из возможно поврежденных полученных блоков. Производительность и успех всей передачи зависит от параметров канала и блочного кода.
Формально, блочный код - это инъективное отображение
 .
.
Здесь  - конечное и непустое множество и и - целые числа. Значение и значение этих трех параметров и других параметров, связанных с кодом, описаны ниже.
- конечное и непустое множество и и - целые числа. Значение и значение этих трех параметров и других параметров, связанных с кодом, описаны ниже.
Алфавит Σ
Кодируемый поток данных моделируется как строка над некоторым алфавитом. Размер  алфавита часто записывается как
алфавита часто записывается как  . Если
. Если  , то блочный код называется двоичным блочным кодом. Во многих приложениях полезно рассматривать как простую степень и определять с конечным полем
, то блочный код называется двоичным блочным кодом. Во многих приложениях полезно рассматривать как простую степень и определять с конечным полем  .
.
Длина сообщения k
Сообщения являются элементами  из
из  , то есть строки длиной . Следовательно, число называется длиной сообщения или размером блочного кода.
, то есть строки длиной . Следовательно, число называется длиной сообщения или размером блочного кода.
Длина блока n
Длина блока блочного кода - это количество символов в Блок. Следовательно, элементы  из
из  представляют собой строки длины и соответствуют блокам, которые могут быть получены получателем. Поэтому их еще называют принятыми словами. Если
представляют собой строки длины и соответствуют блокам, которые могут быть получены получателем. Поэтому их еще называют принятыми словами. Если  для некоторого сообщения , то называется кодовым словом .
для некоторого сообщения , то называется кодовым словом .
Скорость R
rate блочного кода определяется как отношение длины сообщения к длине блока:
 .
.
Большая скорость означает, что количество фактического сообщения на переданный блок велико. В этом смысле скорость измеряет скорость передачи, а величина  измеряет накладные расходы, возникающие из-за кодирования с помощью блочного кода. Это простой теоретический факт, что скорость не может превышать
измеряет накладные расходы, возникающие из-за кодирования с помощью блочного кода. Это простой теоретический факт, что скорость не может превышать  , поскольку данные, как правило, не могут быть сжаты без потерь. Формально это следует из того факта, что код
, поскольку данные, как правило, не могут быть сжаты без потерь. Формально это следует из того факта, что код  является инъективным отображением.
является инъективным отображением.
Расстояние d
расстояние или минимальное расстояние d блочного кода - это минимальное количество позиций, в которых любые два отдельных кодовых слова отличаются, а относительное расстояние  - это дробь
- это дробь  . Формально для полученных слов
. Формально для полученных слов  , пусть
, пусть  обозначают расстояние Хэмминга между
обозначают расстояние Хэмминга между  и
и  , то есть количество позиций, в которых и различаются. Тогда минимальное расстояние
, то есть количество позиций, в которых и различаются. Тогда минимальное расстояние  кода определяется как
кода определяется как
![{\ displaystyle d: = \ min _ {m_ {1}, m_ {2} \ in \ Sigma ^ {k} \ на вершине m_ {1} \ neq m_ {2}} \ Delta [C (m_ {1}), C (m_ {2})]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e18b5dbaf37ec5d007e818f498c3da826bf19767) .
.
Поскольку любой код должен быть инъективным, любые два кодовых слова не совпадают по крайней мере в одной позиции, поэтому расстояние любого кода составляет не менее . Кроме того, расстояние равно минимальному весу для линейных блочных кодов, потому что:
![{\ displaystyle \ min _ {m_ {1}, m_ {2} \ in \ Sigma ^ {k} \ на вершине m_ {1} \ neq m_ {2 }} \ Delta [C (m_ {1}), C (m_ {2})] = \ min _ {m_ {1}, m_ {2} \ in \ Sigma ^ {k} \ atop m_ {1} \ п eq m_ {2}} \ Delta [\ mathbf {0}, C (m_ {1}) + C (m_ {2})] = \ min _ {m \ in \ Sigma ^ {k} \ atop m \ neq \ mathbf {0}} w [C (m)] = w _ {\ min}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ee8487d3a455a6636af4093144e8d23d60f40a81) .
.
Чем больше расстояние, тем больше ошибок исправляется и обнаруживается. Например, если мы рассматриваем только ошибки, которые могут изменить символы отправленного кодового слова, но никогда не стираем и не добавляем их, то количество ошибок - это количество позиций, в которых отправленное кодовое слово и полученное слово отличаются. Код с расстоянием d позволяет приемнику обнаруживать до  ошибок передачи после изменения позиции кодового слова никогда не могут случайно дать другое кодовое слово. Кроме того, если возникает не более
ошибок передачи после изменения позиции кодового слова никогда не могут случайно дать другое кодовое слово. Кроме того, если возникает не более  ошибок передачи, приемник может однозначно декодировать полученное слово в кодовое слово. Это связано с тем, что каждое полученное слово имеет не более одного кодового слова на расстоянии . Если возникает больше чем ошибок передачи, приемник не может однозначно декодировать полученное слово в целом, так как может быть несколько возможных кодовые слова. Один из способов для приемника справиться с этой ситуацией состоит в использовании декодирования списка, при котором декодер выводит список всех кодовых слов в определенном радиусе.
ошибок передачи, приемник может однозначно декодировать полученное слово в кодовое слово. Это связано с тем, что каждое полученное слово имеет не более одного кодового слова на расстоянии . Если возникает больше чем ошибок передачи, приемник не может однозначно декодировать полученное слово в целом, так как может быть несколько возможных кодовые слова. Один из способов для приемника справиться с этой ситуацией состоит в использовании декодирования списка, при котором декодер выводит список всех кодовых слов в определенном радиусе.
Популярное обозначение
Обозначение  описывает блочный код над алфавитом размером с длиной блока , длина сообщения и расстояние . Если блочный код является линейным блочным кодом, тогда квадратные скобки в обозначении
описывает блочный код над алфавитом размером с длиной блока , длина сообщения и расстояние . Если блочный код является линейным блочным кодом, тогда квадратные скобки в обозначении ![[n, k, d] _ {q}](https://wikimedia.org/api/rest_v1/media/math/render/svg/5eef76e1d6b74cc535236a6249e75afeea540ee3) являются используется для представления этого факта. Для двоичных кодов с индекс иногда опускается. Для разделяемых кодов максимального расстояния расстояние всегда равно
являются используется для представления этого факта. Для двоичных кодов с индекс иногда опускается. Для разделяемых кодов максимального расстояния расстояние всегда равно  , но иногда точное расстояние равно не известно, нетривиально доказать или заявить, или не нужно. В таких случаях компонент может отсутствовать.
, но иногда точное расстояние равно не известно, нетривиально доказать или заявить, или не нужно. В таких случаях компонент может отсутствовать.
Иногда, особенно для неблочных кодов, используется запись  используется для кодов, содержащих
используется для кодов, содержащих  кодовые слова длины . Для блочных кодов с сообщениями длины по алфавиту размера это число будет
кодовые слова длины . Для блочных кодов с сообщениями длины по алфавиту размера это число будет  .
.
Примеры
Как упоминалось выше, существует огромное количество кодов с исправлением ошибок, которые на самом деле являются блочными кодами. Первым исправляющим ошибки кодом был код Хэмминга (7,4), разработанный Ричардом У. Хэммингом в 1950 году. Этот код преобразует сообщение, состоящее из 4 бит, в кодовое слово 7 бит, добавив 3 бита четности. Следовательно, этот код является блочным кодом. Оказывается, это также линейный код и расстояние 3. В сокращенной записи выше это означает, что код Хэмминга (7,4) - это ![[7,4,3] _ {2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/499457f6464e18a49d7e72d66681299c4862829a) код.
код.
Коды Рида – Соломона представляют собой семейство кодов с и является степенью простого числа. Коды ранга - это семейство кодов с  . коды Адамара представляют собой семейство
. коды Адамара представляют собой семейство ![[ n, k, d] _ {2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6392bca52bc90f88c7d4362f078cf66ff24fb557) коды с
коды с  и
и  .
.
Свойства обнаружения и исправления ошибок
Кодовое слово  можно рассматривать как точку в -размерном пространстве , а код
можно рассматривать как точку в -размерном пространстве , а код  является подмножеством . Код имеет расстояние означает, что
является подмножеством . Код имеет расстояние означает, что  , в шаре Хэмминга нет другого кодового слова с центром в с радиусом , который определяется как набор слов размерности , которых расстояние от до не превышает . Точно так же с (минимальным) расстоянием имеет следующие свойства:
, в шаре Хэмминга нет другого кодового слова с центром в с радиусом , который определяется как набор слов размерности , которых расстояние от до не превышает . Точно так же с (минимальным) расстоянием имеет следующие свойства:
- может обнаруживать ошибки: потому что кодовое слово - единственное кодовое слово в шаре Хэмминга с центром в самом себе с радиусом , шаблон ошибок или меньше ошибок могут изменить одно кодовое слово на другое. Когда получатель обнаруживает, что полученный вектор не является кодовым словом , ошибки обнаруживаются (но нет гарантии исправления).
- может исправить
 ошибки. Поскольку кодовое слово является единственным кодовым словом в шаре Хэмминга с центром в самом себе с радиусом , два шара Хэмминга с центрами в двух разных кодовых словах соответственно с радиусом не пересекаются друг с другом. Следовательно, если мы рассматриваем исправление ошибок как поиск кодового слова, ближайшего к принятому слову
ошибки. Поскольку кодовое слово является единственным кодовым словом в шаре Хэмминга с центром в самом себе с радиусом , два шара Хэмминга с центрами в двух разных кодовых словах соответственно с радиусом не пересекаются друг с другом. Следовательно, если мы рассматриваем исправление ошибок как поиск кодового слова, ближайшего к принятому слову  , пока количество ошибок не превышает , в шаре Хэмминга есть только одно кодовое слово с центром в с радиусом , поэтому все ошибки можно исправить.
, пока количество ошибок не превышает , в шаре Хэмминга есть только одно кодовое слово с центром в с радиусом , поэтому все ошибки можно исправить. - Для декодирования при наличии более ошибок, декодирование списка или декодирование максимального правдоподобия можно использовать.
- может исправить стирает. Под стиранием это означает, что положение стертого символа известно. Исправление может быть выполнено с помощью -проходного декодирования: в
 при передаче стертой позиции заполняется с символом и выполняется исправление ошибок. Должна быть одна передача, что количество ошибок не превышает и, следовательно, стирания могут быть исправлены.
при передаче стертой позиции заполняется с символом и выполняется исправление ошибок. Должна быть одна передача, что количество ошибок не превышает и, следовательно, стирания могут быть исправлены.
Нижняя и верхняя границы блочных кодов
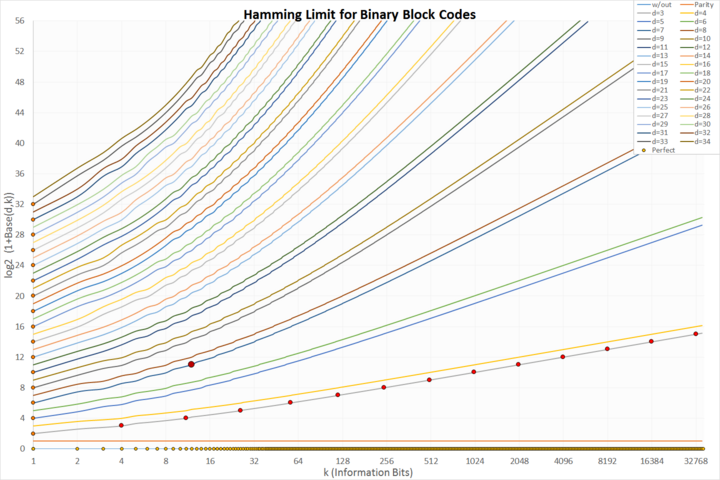
Предел Хэмминга

Существуют теоретические пределы (например, предел Хэмминга), но другой вопрос заключается в том, какие коды могут фактически быть построены. Это похоже на
упаковку сфер в коробку во многих измерениях. Эта диаграмма показывает конструктивные коды, которые являются линейными и двоичными. Ось x показывает количество защищенных символов k, ось y - количество необходимых контрольных символов n – k. На графике показаны пределы для различных расстояний Хэмминга от 1 (незащищенный) до 34. Точками отмечены точные коды:
- светло-оранжевый по оси x: тривиальные незащищенные коды
- оранжевый по оси y: тривиальные повторяющиеся коды
- темно-оранжевый на наборе данных d = 3: классические совершенные коды Хэмминга
- темно-красный и больше: единственный идеальный двоичный код Голея
Семейство кодов
 называется семейством кодов, где
называется семейством кодов, где  - это код
- это код  с монотонным увеличением
с монотонным увеличением  .
.
Скорость семейства кодов C определяется как 
Относительное расстояние семейства кодов C определяется как 
Чтобы изучить отношенияh ip между  и
и  , набор известны нижняя и верхняя границы блочных кодов.
, набор известны нижняя и верхняя границы блочных кодов.
Граница Хэмминга
![{\ displaystyle R \ leq 1- {1 \ over n} \ cdot \ log _ {q} \ cdot \ left [\ sum _ {i = 0} ^ {\ left \ lfloor {{\ delta \ cdot n-1} \ over 2} \ right \ rfloor} {\ binom {n } {i}} (q-1) ^ {i} \ right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7fcd5bd29f60ab24152148b90b87025547204969)
Граница синглтона
Граница синглтона - это сумма скорости и относительное расстояние блочного кода не может быть намного больше 1:
 .
.
В другом слов, каждый блочный код удовлетворяет неравенству  . коды Рида – Соломона являются нетривиальными примерами кодов, которые удовлетворяют singleton, связанный с равенством.
. коды Рида – Соломона являются нетривиальными примерами кодов, которые удовлетворяют singleton, связанный с равенством.
Граница Плоткина
Для ,  . Другими словами,
. Другими словами,  .
.
Для общего случая следующие границы Плоткина верны для любого  с расстоянием d:
с расстоянием d:
- Если

- Если

Для любого q- код с расстоянием , 
Граница Гилберта – Варшамова
 , где
, где  ,
,  - q-ичная функция энтропии.
- q-ичная функция энтропии.
Граница Джонсона
Определить  .. Пусть
.. Пусть  - максимальное количество кодовых слов в шаре Хэмминга радиуса e для любого кода. расстояния d.
- максимальное количество кодовых слов в шаре Хэмминга радиуса e для любого кода. расстояния d.
Тогда у нас есть граница Джонсона:  , если
, если 
Граница Элиаса – Бассалыго

Упаковка сфер и решетки
Блочные коды привязаны к задаче упаковки сфер , которому на протяжении многих лет уделялось некоторое внимание. В двух измерениях это легко визуализировать. Возьмите связку монет на столе и сдвиньте их вместе. В результате получился шестиугольник, похожий на пчелиное гнездо. Но блочные коды полагаются на большее количество измерений, которые трудно визуализировать. Мощный код Голея, используемый для связи в дальнем космосе, использует 24 измерения. При использовании в качестве двоичного кода (что обычно бывает) размеры относятся к длине кодового слова, как определено выше.
Теория кодирования использует модель N-мерной сферы. Например, сколько пенни можно упаковать в круг на столе или в трех измерениях, сколько шариков можно упаковать в глобус. Другие соображения относятся к выбору кода. Например, упаковка шестиугольника в прямоугольную коробку оставляет пустые места по углам. По мере увеличения размеров процент пустого пространства становится меньше. Но при определенных размерах упаковка использует все пространство, и эти коды являются так называемыми совершенными кодами. Таких кодов очень мало.
Другое свойство - это количество соседей, которое может иметь одно кодовое слово. Опять же, рассмотрим в качестве примера гроши. Сначала мы упаковываем пенни в прямоугольную сетку. У каждого пенни будет 4 ближайших соседа (и 4 на дальних углах). В шестиугольнике у каждого пенни будет 6 ближайших соседей. Соответственно, в трех и четырех измерениях максимальную упаковку дают 12-гранный и 24-элементный с 12 и 24 соседями соответственно. Когда мы увеличиваем размеры, количество ближайших соседей увеличивается очень быстро. В общем, значение задается числами поцелуев.
. В результате увеличивается количество способов, которыми шум заставляет приемник выбирать соседа (следовательно, ошибка). Это фундаментальное ограничение блочных кодов, да и вообще всех кодов. Может быть труднее вызвать ошибку для одного соседа, но количество соседей может быть достаточно большим, поэтому общая вероятность ошибки действительно снижается.
См. Также
Ссылки
- JH ван Линт (1992). Введение в теорию кодирования. GTM. 86(2-е изд.). Springer-Verlag. п. 31. ISBN 3-540-54894-7.
- F.J. МакУильямс ; Нью-Джерси Слоан (1977). Теория кодов, исправляющих ошибки. Северная Голландия. п. 35. ISBN 0-444-85193-3.
- W. Хаффман; В.Плесс (2003). Основы кодов исправления ошибок. Издательство Кембриджского университета. ISBN 978-0-521-78280-7.
- С. Линь; Д. Дж. Младший Костелло (1983). Кодирование с контролем ошибок: основы и приложения. Прентис-Холл. ISBN 0-13-283796-X.
Внешние ссылки

 Предел Хэмминга
Предел Хэмминга  Существуют теоретические пределы (например, предел Хэмминга), но другой вопрос заключается в том, какие коды могут фактически быть построены. Это похоже на упаковку сфер в коробку во многих измерениях. Эта диаграмма показывает конструктивные коды, которые являются линейными и двоичными. Ось x показывает количество защищенных символов k, ось y - количество необходимых контрольных символов n – k. На графике показаны пределы для различных расстояний Хэмминга от 1 (незащищенный) до 34. Точками отмечены точные коды:
Существуют теоретические пределы (например, предел Хэмминга), но другой вопрос заключается в том, какие коды могут фактически быть построены. Это похоже на упаковку сфер в коробку во многих измерениях. Эта диаграмма показывает конструктивные коды, которые являются линейными и двоичными. Ось x показывает количество защищенных символов k, ось y - количество необходимых контрольных символов n – k. На графике показаны пределы для различных расстояний Хэмминга от 1 (незащищенный) до 34. Точками отмечены точные коды: