
Войти
В теории информации, турбо - кода (первоначально на французском Turbocodes) представляют собой класс высокопроизводительного исправления ошибок (FEC) коды разработаны около 1990-91, но впервые опубликованного в 1993 году они были первыми практические коды вплотную подойти максимально канал пропускная способность или предел Шеннона, теоретический максимум для кодовой скорости, при котором надежная связь все еще возможна при определенном уровне шума. Турбокоды используются в мобильной связи 3G / 4G (например, в UMTS и LTE ) и в спутниковой связи ( дальний космос ), а также в других приложениях, где разработчики стремятся обеспечить надежную передачу информации по каналам связи с ограниченной полосой пропускания или задержкой в наличие искажающего данные шума. Турбокоды конкурируют с кодами проверки на четность с низкой плотностью (LDPC), которые обеспечивают аналогичную производительность.
Название «турбо-код» возникло из-за контура обратной связи, используемого во время обычного декодирования турбокода, который был аналогичен обратной связи по выхлопу, используемой для турбонаддува двигателя. Хагенауэр утверждал, что термин «турбо-код» является неправильным, поскольку в процессе кодирования отсутствует обратная связь.
Основная заявка на патент для турбокодов была подана 23 апреля 1991 года. В патентной заявке Клод Берроу указан как единственный изобретатель турбокодов. Подача патента привела к получению нескольких патентов, в том числе патента США 5,446,747, срок действия которого истек 29 августа 2013 г.
Первой публичной статьей по турбо-кодам была « Кодирование и декодирование с исправлением ошибок, близкое к пределу Шеннона: турбо-коды ». Этот документ был опубликован в 1993 г. в Трудах Международной конференции по коммуникациям IEEE. Документ 1993 года был сформирован из трех отдельных документов, которые были объединены из-за нехватки места. В результате слияния газета перечислила трех авторов: Берру, Главье и Титимайшима (из Télécom Bretagne, бывший ENST Bretagne, Франция). Однако из исходной заявки на патент ясно, что Берроу является единственным изобретателем турбо-кодов и что другие авторы статьи предоставили материал, отличный от основных концепций.
Турбокоды были настолько революционными на момент своего появления, что многие эксперты в области кодирования не поверили полученным результатам. Когда производительность была подтверждена, произошла небольшая революция в мире кодирования, которая привела к исследованию многих других типов итеративной обработки сигналов.
Первым классом турбокода был параллельный каскадный сверточный код (PCCC). С момента появления оригинальных параллельных турбокодов в 1993 году было обнаружено множество других классов турбокодов, включая последовательные версии последовательные конкатенированные сверточные коды и коды с повторным накоплением. Методы итеративного турбодекодирования также применялись к более традиционным системам FEC, включая сверточные коды с коррекцией Рида – Соломона, хотя эти системы слишком сложны для практической реализации итерационных декодеров. Турбо-эквализация также вытекала из концепции турбо-кодирования.
В дополнение к турбокодам Берроу также изобрел рекурсивные систематические сверточные коды (RSC), которые используются в примерной реализации турбокодов, описанных в патенте. Турбокоды, которые используют коды RSC, кажутся более эффективными, чем турбокоды, которые не используют коды RSC.
До турбокодов лучшими конструкциями были последовательные конкатенированные коды, основанные на внешнем коде исправления ошибок Рида – Соломона в сочетании с внутренним сверточным кодом короткой длины с ограничениями, декодированным по Витерби, также известным как коды RSV.
В более поздней статье Берроу отнесся к интуиции «Дж. Баттейла, Дж. Хагенауэра и П. Хохера, которые в конце 80-х годов подчеркнули интерес к вероятностной обработке». Он добавляет, что « Р. Галлагер и М. Таннер уже представили методы кодирования и декодирования, общие принципы которых тесно связаны», хотя необходимые вычисления в то время были непрактичными.
Существует множество различных примеров турбокодов, использующих различные кодирующие устройства компонентов, соотношения ввода / вывода, перемежители и шаблоны прокалывания. Этот пример реализации кодера описывает классический турбокодер и демонстрирует общую конструкцию параллельных турбокодов.
Эта реализация кодировщика отправляет три подблока битов. Первый субблок - это m- битовый блок данных полезной нагрузки. Второй подблок - это n / 2 битов четности для данных полезной нагрузки, вычисленных с использованием рекурсивного систематического сверточного кода (кода RSC). Третий подблок - это n / 2 битов четности для известной перестановки данных полезной нагрузки, снова вычисленной с использованием кода RSC. Таким образом, с полезной нагрузкой отправляются два избыточных, но разных подблока битов четности. Полный блок имеет m + n битов данных с кодовой скоростью m / ( m + n). Перестановка данных полезной нагрузки осуществляется с помощью устройства, называемого перемежитель.
Аппаратно этот кодер турбокода состоит из двух идентичных кодеров RSC, C 1 и C 2, как показано на рисунке, которые подключены друг к другу с использованием схемы конкатенации, называемой параллельной конкатенацией:

На рисунке M - регистр памяти. Линия задержки и перемежитель вынуждают входные биты d k появляться в разных последовательностях. На первой итерации входная последовательность d k появляется на обоих выходах кодировщика, x k и y 1k или y 2k из-за систематичности кодировщика. Если кодеры C 1 и C 2 используются в n 1 и n 2 итерациях, их скорости соответственно равны
Декодер построен аналогично вышеуказанному кодировщику. Два элементарных декодера соединены между собой, но последовательно, а не параллельно. Декодер работает на более низкой скорости (т.е.), таким образом, оно предназначено для кодера, и для соответственно. дает мягкое решение, которое вызывает задержку. Такая же задержка вызвана линией задержки в кодировщике. В операции «S вызывает задержку.
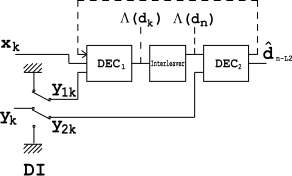
Перемежитель, установленный между двумя декодерами, используется здесь для рассеивания пакетов ошибок, поступающих на выходе. Блок DI - это модуль демультиплексирования и вставки. Он работает как переключатель, перенаправляя входные биты в один момент и в другой. В выключенном состоянии, он питается как и входы с битами (нулями).
Рассмотрим канал AWGN без памяти и предположим, что на k -й итерации декодер получает пару случайных величин:
где и - независимые составляющие шума, имеющие одинаковую дисперсию. является к -й бит с выхода кодера.
Избыточная информация демультиплексируется и отправляется через DI в (когда) и (когда).
дает мягкое решение; то есть:
и доставляет его. называется логарифмом отношения правдоподобия (LLR). - апостериорная вероятность (APP) бита данных, которая показывает вероятность интерпретации принятого бита как. Принятие во внимание LLR приводит к трудному решению; т.е. декодированный бит.
Известно, что алгоритм Витерби не может рассчитать APP, поэтому его нельзя использовать в. Вместо этого используется модифицированный алгоритм BCJR. Для этого подходит алгоритм Витерби.
Однако изображенная структура не является оптимальной, поскольку использует только надлежащую часть доступной избыточной информации. Для улучшения конструкции используется петля обратной связи (см. Пунктирную линию на рисунке).
Интерфейс декодера выдает целое число для каждого бита в потоке данных. Это целое число является мерой того, насколько вероятно, что бит равен 0 или 1, и также называется мягким битом. Целое число может быть взято из диапазона [-127, 127], где:
Это вводит вероятностный аспект в поток данных от внешнего интерфейса, но он передает больше информации о каждом бите, чем просто 0 или 1.
Например, для каждого бита внешний интерфейс традиционного беспроводного приемника должен решить, находится ли внутреннее аналоговое напряжение выше или ниже заданного порогового уровня напряжения. Для декодера турбокода внешний интерфейс будет обеспечивать целочисленную меру того, насколько далеко внутреннее напряжение от заданного порога.
Чтобы декодировать m + n -битовый блок данных, интерфейс декодера создает блок мер правдоподобия с одной мерой правдоподобия для каждого бита в потоке данных. Имеется два параллельных декодера, по одному для каждого из n / 2- битных субблоков четности. Оба декодера используют подблок вероятностей m для данных полезной нагрузки. Декодер, работающий над вторым субблоком четности, знает перестановку, которую кодер использовал для этого субблока.
Ключевым нововведением турбокодов является то, как они используют данные вероятности для согласования различий между двумя декодерами. Каждый из двух сверточных декодеров генерирует гипотезу (с полученными вероятностями) для шаблона из m битов в подблоке полезной нагрузки. Битовые комбинации гипотез сравниваются, и, если они различаются, декодеры обмениваются полученными вероятностями, которые они имеют для каждого бита в гипотезах. Каждый декодер включает полученные оценки правдоподобия из другого декодера для генерации новой гипотезы для битов в полезной нагрузке. Затем они сравнивают эти новые гипотезы. Этот итеративный процесс продолжается до тех пор, пока два декодера не выдвинут одну и ту же гипотезу для m- битного шаблона полезной нагрузки, обычно за 15–18 циклов.
Можно провести аналогию между этим процессом и решением кроссвордов, таких как кроссворд или судоку. Рассмотрим частично завершенный, возможно, искаженный кроссворд. Два решателя головоломки (декодера) пытаются решить эту задачу: у одного есть только «нисходящие» подсказки (биты четности), а у другого - только «поперечные» подсказки. Для начала оба решателя угадывают ответы (гипотезы) на свои собственные подсказки, отмечая, насколько они уверены в каждой букве (бит полезной нагрузки). Затем они сравнивают записи, обмениваясь ответами и рейтингами доверия друг с другом, замечая, где и чем они отличаются. Основываясь на этих новых знаниях, они оба придумывают обновленные ответы и рейтинги уверенности, повторяя весь процесс до тех пор, пока не придут к одному и тому же решению.
Турбокоды работают хорошо благодаря привлекательной комбинации случайного появления кода в канале с физически реализуемой структурой декодирования. На турбокоды влияет пол ошибок.
Телекоммуникации:
С точки зрения искусственного интеллекта, турбо-коды можно рассматривать как пример зацикленного распространения убеждений в байесовских сетях.






















