
Войти
В информатике префиксная сумма, кумулятивная сумма, включительно сканирование или просто сканирование последовательности чисел x 0, x 1, x 2,... - вторая последовательность чисел y 0, y 1, y 2,..., суммы префиксов (промежуточные суммы ) входной последовательности:
Например, префиксные суммы натуральных чисел являются треугольными числами :
| входные числа | 1 | 2 | 3 | 4 | 5 | 6 | ... |
|---|---|---|---|---|---|---|---|
| префиксные суммы | 1 | 3 | 6 | 10 | 15 | 21 | ... |
Префиксные суммы тривиально вычислить в последовательных моделях вычислений, используя формулу y i = y i - 1 + x i для вычисления каждого выходного значения в порядке последовательности. Однако, несмотря на простоту вычисления, префиксные суммы являются полезным примитивом в некоторых алгоритмах, таких как сортировка подсчета, и они формируют основу функции высшего порядка scan в функциональное программирование языков. Суммы префиксов также широко изучались в параллельных алгоритмах, как в качестве тестовой задачи, которая должна быть решена, так и в качестве полезного примитива для использования в качестве подпрограммы в других параллельных алгоритмах.
В абстрактном смысле, a Для суммирования префикса требуется только бинарный ассоциативный оператор ⊕, что делает его полезным для многих приложений, от вычисления разложений пар точек до обработки строк.
Математически операцию взятия префиксных сумм можно обобщить от конечных до бесконечных последовательностей; в этом контексте префиксная сумма известна как частичная сумма ряда серии. Префиксное суммирование или частичное суммирование формируют линейные операторы в векторных пространствах конечных или бесконечных последовательностей; их обратные - операторы конечных разностей.
В термины функционального программирования, сумма префикса может быть обобщена для любой двоичной операции (не только для операции сложения ); функция высшего порядка, полученная в результате этого обобщения, называется сканированием, и она тесно связана с операцией свернуть. И сканирование, и операции сворачивания применяют данную бинарную операцию к одной и той же последовательности значений, но отличаются тем, что сканирование возвращает всю последовательность результатов бинарной операции, тогда как свертка возвращает только окончательный результат. Например, последовательность чисел факториала может быть сгенерирована путем сканирования натуральных чисел с использованием умножения вместо сложения:
| входные числа | 1 | 2 | 3 | 4 | 5 | 6 | ... |
|---|---|---|---|---|---|---|---|
| префикс продуктов | 1 | 2 | 6 | 24 | 120 | 720 | ... |
Реализация сканирования на языке программирования и библиотеках может быть включающим или исключающим. Инклюзивное сканирование включает ввод x i при вычислении вывода y i (т.е. 

В следующей таблице перечислены примеры включающих и эксклюзивных функций сканирования, предоставляемых несколькими языками программирования и библиотеками:
| Язык / библиотека | Инклюзивное сканирование | Исключительное сканирование |
|---|---|---|
| Haskell | scanl1 | scanl |
| MPI | MPI_Scan | MPI_Exscan |
| C ++ | std: : inclusive_scan | std :: exclusive_scan |
| Scala | scan | |
| Rust | scan |
Есть два ключевых алгоритма для параллельного вычисления суммы префиксов. Первый предлагает более короткий промежуток и больший параллелизм, но неэффективен для работы. Второй вариант эффективен в работе, но требует удвоения диапазона и меньшего параллелизма. Они по очереди представлены ниже.
 Представление схемы высокопараллельной суммы параллельных префиксов с 16 входами
Представление схемы высокопараллельной суммы параллельных префиксов с 16 входами Hillis и Steele представляют следующую сумму параллельных префиксов алгоритм:
 to
to do
do to
to do in parallel
do in parallel  затем
затем 

В приведенном выше обозначении 
Учитывая n процессоров, выполняющих каждую итерацию внутреннего цикла за постоянное время, алгоритм в целом выполняется за время O (log n), то есть количество итераций внешнего цикла.
 Схематическое представление эффективной суммы параллельных префиксов с 16 входами
Схематическое представление эффективной суммы параллельных префиксов с 16 входами Эффективную сумму параллельных префиксов можно вычислить с помощью следующих шагов.
Если входная последовательность имеет n шагов, то рекурсия продолжается до глубины O (log n), что также является ограничением времени параллельной работы этого алгоритма. Количество шагов алгоритма составляет O (n), и он может быть реализован на параллельной машине произвольного доступа с O (n / log n) процессорами без какого-либо асимптотического замедления путем присвоения нескольких индексов каждому процессору. в циклах алгоритма, в котором элементов больше, чем процессоров.
Каждый из предыдущих алгоритмов выполняется за время O (log n). Однако в первом случае требуется ровно log 2 n шагов, а во втором - 2 log 2 n - 2 шагов. Для проиллюстрированных примеров с 16 входами алгоритм 1 является 12-сторонним параллельным (49 единиц работы, разделенных на интервал 4), в то время как алгоритм 2 является только 4-сторонним параллельным (26 единиц работы, разделенных на интервал, равный 6). Однако алгоритм 2 эффективен с точки зрения работы - он выполняет только постоянный коэффициент (2) объема работы, требуемой последовательным алгоритмом - в то время как алгоритм 1 работает неэффективно - он выполняет асимптотически больше работы (логарифмический коэффициент), чем требуется. последовательно. Следовательно, алгоритм 1, вероятно, будет работать лучше, когда доступен обширный параллелизм, но алгоритм 2, вероятно, будет работать лучше, когда параллелизм более ограничен.
Параллельные алгоритмы для суммирования префиксов часто можно обобщить для других операций сканирования на ассоциативных двоичных операциях, а также они могут быть эффективно вычислены на современном параллельном оборудовании, таком как GPU. Идея создания аппаратного функционального блока, предназначенного для вычисления многопараметрической префиксной суммы, была запатентована Узи Вишкин.
Многие параллельные реализации следуют двухпроходной процедуре, при которой частичные префиксные суммы вычисляются на первом проходе при каждой обработке Ед. изм; затем вычисляется префиксная сумма этих частичных сумм и передается обратно в блоки обработки для второго прохода с использованием теперь известного префикса в качестве начального значения. Асимптотически этот метод требует примерно двух операций чтения и одной операции записи для каждого элемента.
Реализация параллельного алгоритма суммы префиксов, как и другие параллельные алгоритмы, должна учитывать архитектуру распараллеливания платформы. В частности, существует несколько алгоритмов, адаптированных для платформ, работающих с общей памятью, а также алгоритмов, которые хорошо подходят для платформ, использующих распределенную память, полагаясь на передачу сообщений как единственная форма межпроцессного взаимодействия.
Следующий алгоритм предполагает модель машины с общей памятью ; все элементы обработки (PE) имеют доступ к одной и той же памяти. Версия этого алгоритма реализована в многоядерной стандартной библиотеке шаблонов (MCSTL), параллельной реализации стандартной библиотеки шаблонов C ++, которая предоставляет адаптированные версии для параллельных вычислений различных алгоритмов.
Для одновременного вычисления суммы префиксов по 



В первом цикле каждый PE вычисляет локальную сумму префиксов для своего блока. Последний блок вычислять не нужно, поскольку эти суммы префиксов рассчитываются только как смещения к суммам префиксов последующих блоков, а последний блок по определению не выполняется.
Смещения
Выполняется вторая развертка. На этот раз первый блок не нужно обрабатывать, так как не нужно учитывать смещение предыдущего блока. Однако в этот цикл вместо него включается последний блок, и суммы префиксов для каждого блока вычисляются с учетом смещений блоков суммы префиксов, вычисленных в предыдущем цикле.
function prefix_sum (elements) {n: = size (elements) p: = number of processing elements prefix_sum: = [0... 0] of size n do parallel i = 0 to p-1 {// i: = индекс текущего PE от j = i * n / (p + 1) до (i + 1) * n / (p + 1) - 1 do {// Сохраняет только префиксную сумму локальных блоков store_prefix_sum_with_offset_in (elements, 0, prefix_sum)}} x = 0 для i = 1 to p {x + = prefix_sum [i * n / (p + 1) - 1] // Построение суммы префикса по первым p блокам prefix_sum [i * n / (p + 1)] = x // Сохраняем результаты для использования в качестве смещений во второй развертке} do parallel i = 1 to p {// i: = index of current PE from j = i * n / (p + 1) to (i + 1) * n / (p + 1) - 1 do {offset: = prefix_sum [i * n / (p + 1)] // Вычислить сумму префикса, взяв сумму предыдущих блоков как смещение store_prefix_sum_with_offset_in (elements, offset, prefix_sum)}} return prefix_sum}Алгоритм суммы префиксов гиперкуба хорошо адаптирован для платформ с распределенной памятью и других платформ. ks с обменом сообщениями между элементами обработки. Предполагается, что 

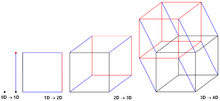 Различные гиперкубы для разного количества узлов
Различные гиперкубы для разного количества узлов На протяжении всего алгоритма каждый PE рассматривается как угол в гипотетическом гиперкубе, при этом известно общее сумма префикса 

и равны локальной сумме префиксов своих собственных элементов.обменивается и агрегируется между двумя гиперкубами, что сохраняет неизменным тот факт, что все PE в углах этого нового гиперкуба хранят общую сумму префиксов этого новый унифицированный гиперкуб в их переменной . Однако только гиперкуб, содержащий PE с более высоким индексом, также добавляет этот к их локальной переменной с сохранением инварианта, что хранит только значение суммы префиксов всех элементов в PE с индексами, меньшими или равными их собственному индексу.В 

i: = Индекс собственного процессорного элемента (PE) m: = префиксная сумма локальных элементов этого PE d: = количество измерений гиперкуба x = m; // Инвариант: Сумма префикса для этого PE в текущем субкубе σ = m; // Инвариант: префиксная сумма всех элементов в текущем субкубе для (k = 0; k <= d-1; k++) { y = σ @ PE(i xor 2^k) // Get the total prefix sum of the opposing sub cube along dimension k σ = σ + y // Aggregate the prefix sum of both sub cubes if (i 2^k) { x = x + y // Only aggregate the prefix sum from the other sub cube, if this PE is the higher index one. } }Конвейерный алгоритм двоичного дерева - еще один алгоритм для платформ с распределенной памятью который особенно хорошо подходит для сообщений большого размера.
Как и алгоритм гиперкуба, он предполагает особую структуру связи. Элементы обработки (PE) гипотетически расположены в виде двоичного дерева (например, Дерево Фибоначчи) с инфиксной нумерацией в соответствии с их индексом в PE. Связь в таком дереве всегда происходит между родительскими и дочерними узлами.
инфиксная нумерация гарантирует, что для любого заданного PE j, индексы всех узлов, достижимых его левым поддеревом ![{\ displaystyle \ mathbb {[l... j-1]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e42e648cab095972c89f5c3cdfd706a6d6542ab)

![{\ displaystyle \ mathbb {[j + 1...r]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9bb02bd7fbd1f725326c3fcdeba81a5b64ea2192)
 Обмен информацией между обрабатывающими элементами во время восходящей (синий) и нисходящей (красный) фаз в алгоритме конвейерной суммы префиксов двоичного дерева.
Обмен информацией между обрабатывающими элементами во время восходящей (синий) и нисходящей (красный) фаз в алгоритме конвейерной суммы префиксов двоичного дерева. ![{\ displaystyle \ mathbb {\ oplus [л..j-1]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/111c0326733e32d7fff1d2436c8f91bd93c2f911) левого поддерева необходимо агрегировать для вычисления локального префикса PE j сумма
левого поддерева необходимо агрегировать для вычисления локального префикса PE j сумма ![{\ displaystyle \ mathbb {\ oplus [l..j]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c8540c987feea78fa6b8c24881a0743b47567bf3) .
.![{\ displaystyle \ mathbb {\ oplus [j + 1..r]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aaf861ae0ef24c4ce8902502b30eb173ccee27f9) правого поддерева необходимо агрегировать для вычисления локальной суммы префиксов PE более высокого уровня h, которые достигаются на пути, содержащем левое дочернее соединение (что означает
правого поддерева необходимо агрегировать для вычисления локальной суммы префиксов PE более высокого уровня h, которые достигаются на пути, содержащем левое дочернее соединение (что означает ![{\ displaystyle \ mathbb {\ oplus [ 0..j]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ce3a3c99c6216685a2b3ecebd478ab7cddd1a185) из PE j необходимо для вычисления общих сумм префиксов в правом поддереве (например,
из PE j необходимо для вычисления общих сумм префиксов в правом поддереве (например, ![{\ displaystyle \ mathbb {\ oplus [0..j..r]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b4a67fa871d710d36cb7e7db6f6202d1938211f8) для узла с наивысшим индексом в поддереве).
для узла с наивысшим индексом в поддереве).![{\ displaystyle \ mathbb {\ oplus [0..l-1]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/29c0eb618b27e5892fb370b0eb4fdf14a18ed333) первого узла более высокого порядка, который достигается через восходящий путь, включающий правильное дочернее соединение для вычисления его общей суммы префиксов.
первого узла более высокого порядка, который достигается через восходящий путь, включающий правильное дочернее соединение для вычисления его общей суммы префиксов.Обратите внимание на различие между суммой локального поддерева и общей суммой префиксов. Точки два, три и четыре могут наводить на мысль, что они образуют круговую зависимость, но это не так. PE более низкого уровня могут потребовать общую сумму префиксов PE более высокого уровня для вычисления их общей суммы префиксов, но PE более высокого уровня требуют только суммы локальных префиксов поддерева для вычисления их общей суммы префиксов. Корневому узлу как узлу самого высокого уровня требуется только локальная сумма префиксов его левого поддерева для вычисления своей собственной суммы префиксов. Каждому PE на пути от PE 0 к корневому PE требуется только локальная сумма префиксов его левого поддерева для вычисления своей собственной суммы префиксов, тогда как каждый узел на пути от PE p-1 (последний PE) к PE корень требует, чтобы общая сумма префиксов его родительского элемента вычислялась его собственной общей суммой префиксов.
Это приводит к двухфазному алгоритму:
восходящая фаза . Распространение локальной префиксной суммы поддерева ![{ \ displaystyle \ mathbb {\ oplus [l..j..r]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/77936279f8ecfbcde9d649eff659d5fc0acec03c)
Нисходящая фаза . Распространение эксклюзивного (эксклюзивного PE j, а также PE в его левом поддереве) общая сумма префиксов
Обратите внимание, что Алгоритм выполняется параллельно на каждом PE, и PE будут блокироваться при получении, пока их дети / родители не предоставят им пакеты.
k: = количество пакетов в сообщении m PE m @ {left, right, parent, this}: = // Сообщения в разных PE x = m @ this // Фаза вверх - вычисление локального префикса поддерева суммы от j = 0 до k-1: // Конвейерная обработка: для каждого пакета сообщения, если hasLeftChild: блокирование приема m [j] @ left // Это заменяет локальный m [j] полученным m [j] // Агрегировать включающую локальную сумму префиксов из PE с нижним индексом x [j] = m [j] ⨁ x [j] if hasRightChild: блокирующий прием m [j] @ right // Мы не агрегируем m [j] в локальную сумму префиксов, поскольку правые дочерние элементы имеют более высокий индекс PE, отправьте x [j] ⨁ m [j] родительскому элементу else: отправьте x [j] родительскому элементу // Нисходящая фаза для j = 0 до k-1: m [j] @ this = 0 if hasParent: blocking receive m [j] @ parent // Для левого потомка m [j] - это исключающая сумма префикса родителей, для правого потомка - включающая префиксная сумма x [j] = m [j] ⨁ x [j] send m [j] to left // Общая сумма префиксов всех PE, меньших этого или любого PE в левом поддереве send x [j] вправо // Общая сумма префиксов всех PE меньше или равен этому PEЕсли сообщение 

Если алгоритм используется без конвейерной обработки, всегда работают только два уровня (отправляющие PE и принимающие PE) двоичного дерева, в то время как все остальные PE ожидают. Если есть элементы обработки 






После разделения на k пакетов, каждый размером 




Алгоритм можно дополнительно оптимизировать, используя полнодуплексную связь или связь по модели телефона и перекрывая восходящую и нисходящую фазы.
Когда набор данных может обновляться динамически, он может храниться в структуре данных дерево Фенвика. Эта структура позволяет как искать любое индивидуальное значение суммы префикса, так и изменять любое значение массива за логарифмическое время за операцию. Однако в более ранней статье 1982 г. представлена структура данных, называемая деревом частичных сумм (см. Раздел 5.1), которая, по-видимому, перекрывает деревья Фенвика; в 1982 году термин «префикс-сумма» еще не был так распространен, как сегодня.
Для многомерных массивов таблица суммированных областей обеспечивает структуру данных на основе сумм префиксов для вычисления сумм произвольных прямоугольных подмассивов. Это может быть полезным примитивом в операциях свертки изображений.
Counting sort - это алгоритм целочисленной сортировки, который использует сумму префиксов гистограмма частот клавиш для вычисления позиции каждого ключа в отсортированном выходном массиве. Он работает за линейное время для целочисленных ключей, размер которых меньше количества элементов, и часто используется как часть radix sort, быстрого алгоритма сортировки целых чисел, размер которых менее ограничен.
Список ранжирование, проблема преобразования связанного списка в массив, представляющий ту же последовательность элементов, может рассматриваться как вычисление суммы префикса для последовательности 1, 1, 1,... и затем сопоставление каждого элемента с позицией массива, заданной его значением суммы префикса; за счет объединения ранжирования списков, сумм префиксов и обходов Эйлера многие важные проблемы на деревьях могут быть решены с помощью эффективных параллельных алгоритмов.
Раннее применение параллельной суммы префиксов Алгоритмы были разработаны в виде двоичных сумматоров, логических схем, которые могут складывать два n-битных двоичных числа. В этом приложении последовательность битов переноса сложения может быть представлена как операция сканирования последовательности пар входных битов с использованием функции большинства для объединения предыдущего переноса с этими двумя битами. Каждый бит выходного номера затем может быть найден как исключающий или из двух входных битов с соответствующим битом переноса. Используя схему, которая выполняет операции параллельного алгоритма суммирования префиксов, можно разработать сумматор, который использует O (n) логических вентилей и O (log n) временных шагов.
В Параллельная машина с произвольным доступом модель вычислений, префиксные суммы могут использоваться для моделирования параллельных алгоритмов, которые предполагают возможность одновременного доступа нескольких процессоров к одной и той же ячейке памяти на параллельных машинах, которые запрещают одновременный доступ. Посредством сети сортировки набор параллельных запросов доступа к памяти может быть упорядочен в последовательность, так что доступы к одной и той же ячейке будут непрерывными в пределах последовательности; Затем операции сканирования могут использоваться для определения того, какой из обращений успешно записывает в запрошенные ячейки, и для распределения результатов операций чтения из памяти на несколько процессоров, которые запрашивают один и тот же результат.
В Guy Blelloch доктор философии. Согласно утверждению, параллельные операции с префиксом являются частью формализации модели параллелизма данных, предоставляемой такими машинами, как Connection Machine. Машина соединений CM-1 и CM-2 обеспечивала гиперкубическую сеть, в которой мог быть реализован описанный выше алгоритм 1, тогда как CM-5 предоставлял выделенную сеть для реализации алгоритма 2.
При построении кодов Грея последовательностей двоичных значений со свойством, что значения последовательных последовательностей отличаются друг от друга в одной битовой позиции, число n может быть преобразовано в значение кода Грея в позиции n последовательность, просто взяв исключающее или из n и n / 2 (число, образованное сдвигом n вправо на одну битовую позицию). Обратная операция - декодирование значения x, закодированного по Грею, в двоичное число - более сложна, но может быть выражена как сумма префиксов битов x, где каждая операция суммирования в пределах суммы префикса выполняется по модулю два. Сумма префиксов этого типа может быть эффективно выполнена с использованием побитовых логических операций, доступных на современных компьютерах, путем вычисления исключающего или числа x с каждым из чисел, образованных сдвигом x влево на некоторое количество битов. это степень двойки.
Параллельный префикс (с использованием умножения в качестве базовой ассоциативной операции) также может использоваться для построения быстрых алгоритмов параллельной полиномиальной интерполяции. В частности, его можно использовать для вычисления коэффициентов разделенной разности формы Ньютона полинома интерполяции. Этот подход на основе префиксов также можно использовать для получения обобщенных разделенных разностей для (конфлюэнтной) интерполяции Эрмита, а также для параллельных алгоритмов для систем Вандермонда.