Статистический метод
В статистике и машинном обучении, lasso (оператор наименьшего сжатия и выбора ; также Lasso или LASSO ) - метод регрессионного анализа который выполняет как выбор модели, так и регуляризацию, чтобы повысить точность прогнозирования и интерпретируемость статистической модели, которую он производит. Первоначально он введен в геофизическую литературу в 1986 году, а позже независимо был открыт и популяризирован в 1996 году Робертом Тибширани, который ввел термин и предоставил дальнейшее наблюдаемых описанных.
Лассо изначально было сформулировано для моделей линейной регрессии, и этот простой случай раскрывает значительную информацию о поведении оценщика, включая его связь с регрессией гребня и выбор наилучшего подмножества и связи между оценками коэффициентов лассо и так называемым мягким пороговым значением. Он также показывает, что (как и стандартная линейная регрессия) коэффициентов не обязательно должны быть уникальными, если ковариаты являются коллинеарными.
Хотя изначально он был определен для линейной регрессии, регуляризация лассо легко расширяется до широкого множества статистических моделей, включая обобщенные линейные модели, уравнения обобщенной оценки, модели пропорциональных опасностей и M-оценки, простыми методами. Способность Лассо выполнять выбор подмножества зависит от формы статистики и имеет множество интерпретаций, в том числе с точки зрения , байесовской и выпуклого анализа.
. LASSO связан с шумоподавлением основного преследования.
Содержание
- 1 Мотивация
- 2 Основная форма
- 2.1 Ортонормированные ковариаты
- 2.2 Коррелированные ковариаты
- 3 Общая форма
- 4 Интерпретации
- 4.1 Геометрическая интерпретация
- 4.2 Упрощение интерпретации λ с компромиссом между точностью и простотой
- 4.3 Байесовская интерпретация
- 4.4 Интерпретация выпуклой релаксации
- 5 Обобщения
- 5.1 Эластичная сетка
- 5.2 Групповое лассо
- 5.3 Объединенное лассо
- 5.4 Квазинормы и мостовая регрессия
- 5.5 Адаптивное лассо
- 5.6 Предыдущее лассо
- 6 Вычисление решений лассо
- 7 Выбор решения регуляризации
- 8 См. Также
- 9 Источники
Мотивация
Лассо было введено для повышения точности прогнозов и интерпретируемости методов путем изменения подбора моделей, чтобы выбрать только подмножество предоставленных ковариат для использования в окончательной модели, а не использовать их все. Он разработан независимо в геофизике на основе предыдущих работ, в которой использовались штрафы  как для подбора, так и для штрафов за коэффициенты, а также статистик, Роберт Тибширани на основе неотрицательной гарроты Бреймана.
как для подбора, так и для штрафов за коэффициенты, а также статистик, Роберт Тибширани на основе неотрицательной гарроты Бреймана.
Для лассо наиболее широко используемым методом выбора, какие ковариаты задают, был пошаговый выбор, что улучшает точность прогнозов в определенных случаях, например, когда только несколько ковариат имеют сильную связь с результатом. Однако в других случаях это может усугубить ошибку прогноза. Кроме того, в то время гребенчатая регрессия была самым популярным методом повышения точности прогнозов. Риджевая регрессия улучшает ошибку прогнозирования за счет сжатия коэффициентов регрессии для уменьшения переобучения, но не выполняет ковариативный выбор и, следовательно, не выполняет функции не помогает сделать модель более интерпретируемой.
Лассо может достигать этих целей, заставляя абсолютные коэффициенты регрессии быть меньше фиксирующего значения, что заставляет усиливать коэффициенты обнуляться, эффективно выбирая более простую модель, это не включает эти коэффициенты. Эта идея похожа на гребневую регрессию, в которой содержится сумма квадратов коэффициентов, должна быть меньше фиксированного значения, хотя в случае гребневой регрессии это только уменьшает размер коэффициентов, но не устанавливает никаких из них к нулю.
Базовая форма
Лассо введено в наименьших квадратов, и может быть поучительно сначала рассмотреть этот случай, поскольку он показывает многие свойства лассо в простой обстановке.
Рассмотрим выборку, состоящую из N наблюдений, каждый из которых состоит из p ковариат и одного результата. Пусть  будет результатом, а
будет результатом, а  - вектор ковариации для случая i. Тогда цель лассо - решить
- вектор ковариации для случая i. Тогда цель лассо - решить

Здесь  - заранее заданный свободный параметр, определяющий степень регуляризации. Пусть
- заранее заданный свободный параметр, определяющий степень регуляризации. Пусть  будет ковариантной матрицей, так что
будет ковариантной матрицей, так что  и
и  - это строка i в , выражение может быть записано более компактно как
- это строка i в , выражение может быть записано более компактно как

где  стандартная
стандартная  norm и
norm и  является вектором агрегата
является вектором агрегата  .
.
Обозначение скалярного среднего значений точек данных  как
как  и среднее значение числа ответа на
и среднее значение числа ответа на  , итоговая оценка для
, итоговая оценка для  в конечном итоге
в конечном итоге  , так что
, так что

и поэтому стандартно работать с переменными, которые были центрированы (с нулевым средним). Кроме того, ковариаты обычно стандартизированы  , чтобы решение не зависело от шкалы измерений.
, чтобы решение не зависело от шкалы измерений.
Может оказаться полезным переписать

в так называемой лагранжевой форме

, где точное соотношение между и  зависит от данных.
зависит от данных.
Ортонормированные ковариаты
Теперь можно рассмотреть некоторые основные свойства оценщика лассо.
Предположим сначала, что ковариаты ортонормированы, так что  , где
, где  - это внутренний продукт и
- это внутренний продукт и  - это дельта Кронекера, или, эквивалентно,
- это дельта Кронекера, или, эквивалентно,  , используя методы субградиента, можно показать, что
, используя методы субградиента, можно показать, что

 называется оператором мягкого определения порога, поскольку он трансформируется приближает значения к нулю (делает их точно равными нулю, если они достаточно малы) вместо того, чтобы устанавливать меньшие значения на ноль и оставлять более крупные нетронутыми в качестве жесткого порога, часто обозначаемого
называется оператором мягкого определения порога, поскольку он трансформируется приближает значения к нулю (делает их точно равными нулю, если они достаточно малы) вместо того, чтобы устанавливать меньшие значения на ноль и оставлять более крупные нетронутыми в качестве жесткого порога, часто обозначаемого  , будет.
, будет.
Это можно сравнить с регрессией гребня, где цель - минимизировать

, что дает

Таким образом, гребенчатая регрессия сжимает все коэффициенты на единый коэффициент  и не установить любые коэффициенты на ноль.
и не установить любые коэффициенты на ноль.
Его также можно сравнить с регрессией с выбором лучшего подмножества, в котором цель в том, чтобы минимизировать

где  - это «
- это « norm», который определяется как
norm», который определяется как  , если ровно m компонентов z отличны от нуля. В этом случае можно показать, что
, если ровно m компонентов z отличны от нуля. В этом случае можно показать, что

где - это так называемая функция жесткого порога, а  - индикаторная функция (1, если ее аргумент истинен, и 0 в случае потери).
- индикаторная функция (1, если ее аргумент истинен, и 0 в случае потери).
Следовательно, оценки лассо имеют общие черты оценок как из регрессии по гребню, так и из регрессии выбора наилучшего подмножества, поскольку они оба уменьшают все коэффициенты, как регрессия гребня, но также устанавливают некоторые из них равными нулю, в лучший вариант выбора подмножества. Кроме того, как регрессия гребня масштабирует все коэффициенты с помощью постоянного коэффициента, лассо вместо этого переводит коэффициенты в сторону нуля на постоянное значение и устанавливает их в ноль, если они достигают его.
Коррелированные ковариаты
Возвращаясь к общему случаю, в котором разные ковариаты могут быть независимыми, можно рассмотреть особый случай, в котором две ковариаты, скажем, j и k идентичны для каждого случая, так что  , где
, где  . Затем значения
. Затем значения  и
и  , которые минимизируют Целевая функция лассо не определено однозначно. На самом деле, если есть какое-то решение
, которые минимизируют Целевая функция лассо не определено однозначно. На самом деле, если есть какое-то решение  , в котором
, в котором  , тогда, если
, тогда, если ![{\ displaystyle s \ in [0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aff1a54fbbee4a2677039524a5139e952fa86eb9) замена
замена  на
на  и
и  по
по  , оставив все остальные
, оставив все остальные  исправлено, дает новое решение, поэтому целевая функция лассо тогда имеет континуум допустимых минимизаторов. Были разработаны несколько вариантов лассо, включая Elastic Net, для устранения этого недостатка, который обсуждается ниже.
исправлено, дает новое решение, поэтому целевая функция лассо тогда имеет континуум допустимых минимизаторов. Были разработаны несколько вариантов лассо, включая Elastic Net, для устранения этого недостатка, который обсуждается ниже.
Общая форма
Регуляризация лассо может быть расширена в широком спектре целевых функций, например, для общих линейных моделей, обобщенных оценок оценки, модели пропорциональных рисков и M-оценки в целом очевидным образом. Учитывая целевую функцию

регуляризованная версия оценки лассо будет решением

где только  наказывается, в то время как
наказывается, в то время как  может принимать любое допустимое значение, так же как не был наказан в основном случае.
может принимать любое допустимое значение, так же как не был наказан в основном случае.
Интерпретации
Геометрическая интерпретация

Формы области ограничений для регрессии лассо и гребня.
Как обсуждалось выше, лассо может устанавливать коэффициенты равными нулю, а регрессия гребня, которая выглядит внешне похоже, не может. Это происходит из-за разницы в форме ограничений в двух случаях. И лассо, и регрессию гребня можно интерпретировать как минимизацию одной и той же целевой функции

, но с учетом других ограничений:  для лассо и
для лассо и  для гребня. Из рисунка видно, что область ограничения, определяемая нормой , представляет собой квадрат, повернутый так, что его углы лежат на осях (в обычно кросс-многогранник ), в то время как область, определяемая нормой
для гребня. Из рисунка видно, что область ограничения, определяемая нормой , представляет собой квадрат, повернутый так, что его углы лежат на осях (в обычно кросс-многогранник ), в то время как область, определяемая нормой  , является кругом (обычно n-сфера ), которая вращательно инвариантна и, следовательно, не имеет углов. Как видно на рисунке, выпуклый объект, касающийся границы, такой как показанная линия, вероятно, встретит угол (или его многомерный эквивалент) гиперкуба, для которого некоторые компоненты тождественно равны нулю, а в случае n-сферы - точки на границе, для которых некоторые из компонентов равны нулю, не отличаются от других, и вероятность контакта выпуклого объекта с точкой, в некоторых компонентах равны нулю, не выше, чем для единицы, для которой ни один из них.
, является кругом (обычно n-сфера ), которая вращательно инвариантна и, следовательно, не имеет углов. Как видно на рисунке, выпуклый объект, касающийся границы, такой как показанная линия, вероятно, встретит угол (или его многомерный эквивалент) гиперкуба, для которого некоторые компоненты тождественно равны нулю, а в случае n-сферы - точки на границе, для которых некоторые из компонентов равны нулю, не отличаются от других, и вероятность контакта выпуклого объекта с точкой, в некоторых компонентах равны нулю, не выше, чем для единицы, для которой ни один из них.
Упрощение интерпретации λ за счет компромисса между точностью и простотой
Лассо можно масштабировать, чтобы было легче предвидеть и влиять на то, какая степень усадки связана с заданным значением . Предполагается, что стандартизирован с помощью значений z-значений и что  центрирован так, что имеет среднее значение нуля. Пусть представляет предполагаемые коэффициенты регрессии, а
центрирован так, что имеет среднее значение нуля. Пусть представляет предполагаемые коэффициенты регрессии, а  относится к оптимизированные для данных методом решения наименьших квадратов. Затем мы можем определить лагранжиан как компромисс между оптимизированными решениями в выборке и простоте показателей. Это приводит к
относится к оптимизированные для данных методом решения наименьших квадратов. Затем мы можем определить лагранжиан как компромисс между оптимизированными решениями в выборке и простоте показателей. Это приводит к

где  указано ниже. Первая дробь представляет относительную точность, вторая дробь - относительную простоту, а балансирует между ними..
указано ниже. Первая дробь представляет относительную точность, вторая дробь - относительную простоту, а балансирует между ними..

Стилизованные пути решения для

norm и

норма, когда

и

Если существует единственный регрессор, то относительную простоту можно определить, указав как  , что является максимальной величиной отклонения от когда
, что является максимальной величиной отклонения от когда  . Предполагаемая, что , путь решения может быть определен в терминах известной меры точности, называемой
. Предполагаемая, что , путь решения может быть определен в терминах известной меры точности, называемой  :
:

Если , используется решение OLS. Предполагаемое значение равно выбирается, если больше, чем ., если  , тогда представляет пропорциональное влияние . Другими словами,
, тогда представляет пропорциональное влияние . Другими словами,  определяет в процентах какова минимальная степень гипотетического значения параметра data-opt имитированное решение OLS.
определяет в процентах какова минимальная степень гипотетического значения параметра data-opt имитированное решение OLS.
Если -norm for наказания откло нений от нуля при наличии одного регрессора задается путь решения по  . Подобно
. Подобно  ,
,  перемещается в направлении точка
перемещается в направлении точка  , когда близко к нулю; но в отличие от , влияние уменьшается в , если увеличивается ( см. рисунок)..
, когда близко к нулю; но в отличие от , влияние уменьшается в , если увеличивается ( см. рисунок)..
При наличии нескольких регрессоров момент активации управления (т. Е. Допускается отклонение от ) также определяется регрессором вклад в точность . Сначала мы определяем

Значение , равное 75%, означает, что точность внутри выборки улучшается на 75%, если используются неограниченные решения OLS вместо предполагаемых значения. Индивидуальный вклад отклонения от каждой гипотезы можно вычислить с помощью  умножения на матрицы
умножения на матрицы

где  . Если
. Если  , когда вычисляется , тогда диагональные элементы
, когда вычисляется , тогда диагональные элементы  суммируются до . Значения диагонали могут быть меньше 0 и, в более исключительных случаях, больше 1. Если регрессоры не коррелированы, то
суммируются до . Значения диагонали могут быть меньше 0 и, в более исключительных случаях, больше 1. Если регрессоры не коррелированы, то  диагональный элемент просто соответствует
диагональный элемент просто соответствует  значение между и ..
значение между и ..
Теперь мы можем получить измененную версию адаптивного лассо Zou ( 2006), установив  . Если регрессоры не коррелированы, момент активации программы задается параметром
. Если регрессоры не коррелированы, момент активации программы задается параметром

То есть, если регрессоры не коррелированы, снова указывает, какое минимальное влияние есть. Даже когда регрессоры коррелированы, более того, первый раз, когда активируется параметр регрессии, происходит, когда равно наивысшей диагонали элемент ..
Эти результаты можно сравнить с масштабированной версией лассо, если мы определим  , которое представляет собой среднее абсолютное отклонение от . Если предположить, что регрессоры не коррелированы, то момент активации регрессора определен выражением
, которое представляет собой среднее абсолютное отклонение от . Если предположить, что регрессоры не коррелированы, то момент активации регрессора определен выражением

Для  , момент активации снова задается
, момент активации снова задается  . Более того, если вектор нулей и существует подмножество
. Более того, если вектор нулей и существует подмножество  соответствующие параметры, которые в равной степени соответствуют идеальному соответствию , это подмножество будет активировано при значение
соответствующие параметры, которые в равной степени соответствуют идеальному соответствию , это подмножество будет активировано при значение  . В конце концов, момент активации соответствующего регрессора тогда равенство
. В конце концов, момент активации соответствующего регрессора тогда равенство  . Другими словами, включение нерелевантных регрессоров задерживает момент активации соответствующих регрессоров измененным лассо. Адаптивное лассо и лассо являются частными случаями оценщика 1ASTc. Последний группирует параметры вместе только в том случае, если абсолютная корреляция между регрессорами больше заданного значения. Для получения дополнительной информации см. Хорнвег (2018).
. Другими словами, включение нерелевантных регрессоров задерживает момент активации соответствующих регрессоров измененным лассо. Адаптивное лассо и лассо являются частными случаями оценщика 1ASTc. Последний группирует параметры вместе только в том случае, если абсолютная корреляция между регрессорами больше заданного значения. Для получения дополнительной информации см. Хорнвег (2018).
Байесовская интерпретация

Распределения Лапласа резкий пик на их среднем значении с большей плотностью вероятности, сконцентрированной там по сравнению с нормальным распределением.
Так же, как может быть регрессия гребня интерпретируется как линейная регрессия, для коэффициентов которой были назначены нормальные априорные распределения, лассо можно интерпретировать как линейную регрессию, для которой коэффициенты имеют априорные распределения Лапласа. Распределение Лапласа имеет резкий в нуле (его первая производная прерывистая), и оно концентрирует пик вероятной массы ближе к нулю, чем нормальное распределение. Это дает альтернативное объяснение того, почему лассо стремится установить некоторые коэффициенты равными нулю, в то время как регрессия гребня - нет.
Интерпретация выпуклой релаксации
Лассо также можно рассматривать как выпуклую релаксацию наилучшего подмножества задача регрессии выбора, которая заключается в нахождении подмножества ковариат  , которое приводит к наименьшему значению функции для некоторого фиксированного
, которое приводит к наименьшему значению функции для некоторого фиксированного  , где n - общее количество ковариат. «norm», , дает количество ненулевых элементов который является предельным случаем «norm» в форме
, где n - общее количество ковариат. «norm», , дает количество ненулевых элементов который является предельным случаем «norm» в форме  (где кавычки означают, что это не совсем норма для
(где кавычки означают, что это не совсем норма для  , поскольку
, поскольку  не является выпуклым для , поэтому неравенство треугольника не выполняется). Следовательно, поскольку p = 1 - наименьшее значение, для которого «norm» является выпуклым (и, следовательно, фактически нормой), лассо равно в некотором смысле наилучшее выпуклое приближение к задаче выбора наилучшего подмножества, поскольку область, определенная
не является выпуклым для , поэтому неравенство треугольника не выполняется). Следовательно, поскольку p = 1 - наименьшее значение, для которого «norm» является выпуклым (и, следовательно, фактически нормой), лассо равно в некотором смысле наилучшее выпуклое приближение к задаче выбора наилучшего подмножества, поскольку область, определенная  - это выпуклая оболочка области, определенной как
- это выпуклая оболочка области, определенной как  для .
для .
Обобщения
Было создано несколько вариантов лассо, чтобы исправить ограничения оригинальной техники и сделать метод более полезным для конкретных задач. Почти все они сосредоточены на уважении или использовании различных типов зависимостей между ковариатами. Упругая сетевая регуляризация Дополнительная точность, подобный гребенчатой регрессии, которая повышает производительность, когда количество предикторов увеличивает размер выборки, позволяет выбирать сильно коррелированные переменные вместе и повышает общую точность прогнозирования. Групповое лассо позволяет выбирать группы связанных ковариат как единое целое, что может быть полезно в тех случаях, когда нет смысла выбирать одни ковариаты без других. Также были разработаны дополнительные расширения группового лассо для выполнения выбора отдельных групп (разреженное групповое лассо) и перекрытие между группами (перекрывающееся групповое лассо). Слитные лассо могут быть оценены изучаемой системой. Регуляризованные модели лассо могут быть подобраны с использованием различных методов, включая методы субградиента, регрессию наименьшего угла (LARS) и методы проксимального градиента. Определение оптимального значения регуляризации - важная часть обеспечения хорошей работы модели; обычно он выбирается с помощью перекрестной проверки.
эластичной сети
В 2005 году Зоу и Хасти представили эластичную сеть для устранения некоторых недостатков лассо. Когда p>n (количество ковариат больше, чем размер выбора), лассо может выбрать только одну ковариату (даже если результатом является больше), и он имеет тенденцию выбирать только одну ковариату из любого набора сильно коррелированных ковариат. Кроме того, даже когда n>p, если ковариаты сильно коррелированы, регрессия гребня имеет тенденцию работать лучше.
Эластичная сетка расширяет лассо, добавляя дополнительный штрафной срок, дающий

что эквивалентно решение

Как ни странно, задача может быть записана в простой форме лассо

позволяя
 ,
,  ,
, 
Тогда  , который, когда ковариаты ортогональны друг другу, дает
, который, когда ковариаты ортогональны друг другу, дает

Итак, результат эластичного чистого штрафа представляет собой комбинацию эффектов штрафов лассо и хребта.
Возвращаясь к общему случаю, тот факт, что функция штрафа теперь строго выпуклая, означает, что если ,  , который отличается от лассо. Как правило, если
, который отличается от лассо. Как правило, если 

- это примерная корреляционная матрица, потому что  нормализованы.
нормализованы.
Следовательно, ковариаты с высокой степенью корреляции будут иметь сходные коэффициенты регрессии, причем степень сходства будет зависеть от обоих:  и
и  , что сильно отличается от лассо. Это явление, при котором сильно коррелированные ковариаты имеют одинаковые коэффициенты регрессии, называется как группирующий эффект и обычно считается желательным, поскольку во многих приложениях, таких как идентификация генов, связанных с заболеванием, хотелось бы найти все связанные ковариаты, а не выбирать только одну из каждого набора st коррелированные ковариаты, как это часто бывает с лассо. Кроме того, выбор только одной ковариаты из каждой группы обычно приводит к увеличению ошибок прогнозирования, поскольку модель менее надежна (вот почему регрессия гребня часто превосходит лассо).
, что сильно отличается от лассо. Это явление, при котором сильно коррелированные ковариаты имеют одинаковые коэффициенты регрессии, называется как группирующий эффект и обычно считается желательным, поскольку во многих приложениях, таких как идентификация генов, связанных с заболеванием, хотелось бы найти все связанные ковариаты, а не выбирать только одну из каждого набора st коррелированные ковариаты, как это часто бывает с лассо. Кроме того, выбор только одной ковариаты из каждой группы обычно приводит к увеличению ошибок прогнозирования, поскольку модель менее надежна (вот почему регрессия гребня часто превосходит лассо).
Групповое лассо
В 2006 году Юань и Линь представили групповое лассо, чтобы заранее заданным группам ковариат быть выбранными в моделях или из нее вместе, где все члены группы либо включены, либо не включены. Показывает, что используется набор ненадлежащих данных. В этом случае часто не имеет смысла только несколько уровней ковариаты; групповое лассо может быть, что все переменные, кодирующие категориальную ковариату, либо включены, либо исключены из моделей вместе. Еще одна среда, в которой группирование является естественным, - это биологические исследования. Некоторые пути связаны с исходом, чем связаны гены. Целевая функция для группы лассо является естественным обобщением стандартной цели лассо

где матрица плана и вектор ковариации были заменены набором матриц дизайна  и ковариантных векторов , по одному для каждой из J-групп. Кроме того, срок штрафа теперь представляет собой сумму более норм, определенно определенными матрицами
и ковариантных векторов , по одному для каждой из J-групп. Кроме того, срок штрафа теперь представляет собой сумму более норм, определенно определенными матрицами  . Если каждая ковариата находится в своей собственной группе и
. Если каждая ковариата находится в своей собственной группе и  , то это сводится к стандартному лассо, а если существует только одна группа и
, то это сводится к стандартному лассо, а если существует только одна группа и  , это сводится к регрессии гребня. Временной сокращается до нормы для подпространств, определенных каждой группой, он не может выбрать только некоторые ковариаты из группы, просто как не может регресс гребня. Ограничения имеют некоторые недифференциальные точки, соответствующие тождественным нулю некоторым подпространств. Следовательно, он может установить коэффициентов, соответствующих подпространствам, равным нулю, другим только сжимать. Однако которое можно расширить групповое лассо до так называемого разреженного группового лассо, можно выбрать отдельные ковариаты в группе, добавив дополнительный штраф к каждому подпространству. Другое расширение, групповое лассо с перекрытием, позволяет разделять ковариаты между разными группами, например, если должен возникать двумя путями.
, это сводится к регрессии гребня. Временной сокращается до нормы для подпространств, определенных каждой группой, он не может выбрать только некоторые ковариаты из группы, просто как не может регресс гребня. Ограничения имеют некоторые недифференциальные точки, соответствующие тождественным нулю некоторым подпространств. Следовательно, он может установить коэффициентов, соответствующих подпространствам, равным нулю, другим только сжимать. Однако которое можно расширить групповое лассо до так называемого разреженного группового лассо, можно выбрать отдельные ковариаты в группе, добавив дополнительный штраф к каждому подпространству. Другое расширение, групповое лассо с перекрытием, позволяет разделять ковариаты между разными группами, например, если должен возникать двумя путями.
Плавленый лассо
В некоторых случаях изучаемый объект может иметь пространственную или временную нагрузку, которую необходимо во время анализа, например, данные на основе серий или изображений. В 2005 году Тибширани и его коллеги представили слитное лассо, чтобы расширить использование лассо именно для этого типа данных. Целевая функция объединенного лассо равна
![{\ displaystyle {\ begin {align} \ min _ {\ beta} \ left \ {{\ гидроразрыва {1} {N}} \ sum _ {i = 1} ^ {N} \ left (y_ {i} -x_ {i} ^ {t} \ beta \ right) ^ {2} \ right \} \ \ [4pt] {\ text {subject to}} \ sum _ {j = 1} ^ {p} | \ beta _ {j} | \ leq t_ {1} {\ text {and}} \ sum _ {j = 2} ^ {p} | \ beta _ {j} - \ beta _ {j-1} | \ leq t_ {2}. \ конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a75f99fe3b19232504b470197d1158638ad10255)
Первое ограничение - это просто стандартное ограничение лассо, но второе ограничение большие изменения относительно временной или пространственной структуры, которая отражает основную логику изучаемой системы. Кластерное лассо - это обобщенное объединенное лассо, которое идентифицирует и соответствующие ковариаты на основе их эффектов (коэффициентов). Основная идея состоит в том, чтобы наказывать между коэффициентами, чтобы ненулевые коэффициенты образовывали кластеры вместе. Это можно смоделировать с помощью следующей регуляризации:
Напротив, можно сначала сгруппировать переменные в сильно коррелированные группы, а затем извлечь одну репрезентативную ковариату из каждого кластера.
Существует несколько алгоритмов, которые решают задачу слитого лассо и некоторые обобщения в прямой форме, т. е. есть алгоритм, который решает ее точно за конечное число операций.
Квазинормы и мостовая регрессия
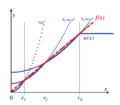
Пример потенциальной функции PQSQ (кусочно-квадратичной функции субквадратичного роста)

; здесь мажорантная функция

; потенциал с обрезкой после

.

Пример того, как эффективная регуляризованная регрессия PQSQ работает так же, как
-нормальное лассо.
Лассо, эластичная сетка, группировка и объединенное лассо показывает штрафные функции из и нормы (с весом, если необходимо). В мостовой регрессии используются общие нормы ( ) и квазинормы (
) и квазинормы (

где

Утверждается, что Дробные квазинормы (

где  - произвольная вогнутая монотонно возрастающая функция (например,
- произвольная вогнутая монотонно возрастающая функция (например,  дает штраф лассо и
дает штраф лассо и  дает штраф
дает штраф  ).
).
Эффективный алгоритм минимизации основан на кусочно-квадратичной аппроксимации субквадратичного роста (PQSQ).
Адаптивное лассо
Адаптивное лассо было введено Zou (2006, JASA) для линейной регрессии и Zhang and Lu (2007, Биометрика) для регрессии пропорциональных рисков.
Предыдущее лассо
Предыдущее лассо было введено Jiang et al. (2016) для обобщенных линейных моделей, включить априорную информацию. В предшествующем лассо информация суммируется в псевдоответы (называемые предыдущими ответами)  , а к обычной практике функции обобщенных линейных моделей добавленная целевая функция со штрафом лассо. Не умаляя общности, мы используем линейную регрессию для иллюстрации априорного лассо. В линейной регрессии новую целевую функцию можно записать как
, а к обычной практике функции обобщенных линейных моделей добавленная целевая функция со штрафом лассо. Не умаляя общности, мы используем линейную регрессию для иллюстрации априорного лассо. В линейной регрессии новую целевую функцию можно записать как

что эквивалентно

обычная целевая функция лассо с ответами , замененными средневзвешенным сроком представленных ответов и предыдущих ответов  (называются скорректированными значениями ответа по априорной информации).
(называются скорректированными значениями ответа по априорной информации).
В предыдущем лассо параметр  назывался параметрромировки, который уравновешивает относительную важность данных и предшествующей информации. В крайнем случае
назывался параметрромировки, который уравновешивает относительную важность данных и предшествующей информации. В крайнем случае  предыдущее лассо сокращается до лассо. Если
предыдущее лассо сокращается до лассо. Если  предварительное лассо будет эксклюзивно на предварительную информацию для соответствия модели. Кроме того, параметр балансировки имеет другую привлекательную интерпретацию: он управляет дисперсией в распределении с байесовской точки зрения.
предварительное лассо будет эксклюзивно на предварительную информацию для соответствия модели. Кроме того, параметр балансировки имеет другую привлекательную интерпретацию: он управляет дисперсией в распределении с байесовской точки зрения.
Априорное лассо более эффективно при оценке и прогнозировании параметров (с меньшей ошибкой оценки и ошибкой прогнозирования), когда априорная информация имеет высокое качество и устойчива к априорной информации низкого качества с хорошим выбором параметра балансировки .
Вычисление решений лассо
Функции потерь лассо не дифференцируема, но были разработаны разные методы, от выпуклого анализа и теории оптимизации до вычислить путь решения лассо. К ним координатный спуск, методы субградиента, регрессия по наименьшему углу (LARS) и методы проксимального градиента. Субградиентные методы являются естественным обобщением методов, таких как градиентный спуск и стохастический градиентный спуск, для случая, когда целевая функция не дифференцируема во всех точках. LARS - это метод, который позволяет работать с моделями лассо, и во многих случаях позволяет им очень эффективно подбирать их, хотя он может работать не во всех обстоятельствах. LARS генерирует полные пути решения. Проксимальные методы стали благодаря своей гибкости и популярности активных исследований. Выбор метода зависеть от конкретной используемой версии лассо, данных и доступных ресурсов. Однако проксимальные методы обычно работают хорошо в большинстве случаев.
Выбор параметров регуляризации
Выбор регуляризации () также является основой использования лассо. Его правильный выбор важен для производительности лассо, поскольку он контролирует силу сжатия и выбор числа, что в умеренных количествах может улучшить точность прогнозов, так и интерпретируемость. Если регуляризация станет слишком сильной, важные переменные могут быть исключены из моделей, а коэффициенты могут быть чрезмерно сжаты, что может нанести ущерб как прогнозной способности, так и сделанным выводам. Перекрестная проверка часто используется для выбора параметра регуляризации.
Информационные критерии, такие как <4>байесовский информационный критерий (BIC) и информационный критерий Акаике (AIC), могут быть предпочтительнее перекрестной проверки, они быстрее вычислить, в то время время как их производительность менее изменчива в небольших выборках. Информационный критерий выбирает параметр регуляризации оценщика, максимизируя точность модели в выборке и снижая ее эффективное количество / степеней свободы. Zou et al. (2007) проверяется эффективные степени свободы путем подсчета количества параметров, отклоняющихся от нуля. Подход с использованием степеней свободы был сочтен ошибочным Кауфман и Россет (2014) и Янсон и др. (2015), потому что степень свободы модели увеличивается, даже если на нее сильнее накладывается параметр регуляризации. В качестве альтернативы можно использовать определенную выше относительную простоту для подсчета эффективных параметров (Hoornweg, 2018). Для лассо эта мера определяется как
 ,
,
который монотонно увеличивается от нуля до при уменьшении настройки регуляризации с  до нуля.
до нуля.
См. Также
Ссылки

 Формы области ограничений для регрессии лассо и гребня.
Формы области ограничений для регрессии лассо и гребня.  Стилизованные пути решения для
Стилизованные пути решения для  Распределения Лапласа резкий пик на их среднем значении с большей плотностью вероятности, сконцентрированной там по сравнению с нормальным распределением.
Распределения Лапласа резкий пик на их среднем значении с большей плотностью вероятности, сконцентрированной там по сравнению с нормальным распределением.  Пример потенциальной функции PQSQ (кусочно-квадратичной функции субквадратичного роста)
Пример потенциальной функции PQSQ (кусочно-квадратичной функции субквадратичного роста)  Пример того, как эффективная регуляризованная регрессия PQSQ работает так же, как
Пример того, как эффективная регуляризованная регрессия PQSQ работает так же, как