
Войти
Kademlia - это распределенная хеш-таблица для децентрализованной одноранговой сети компьютерные сети, разработанные Петаром Маймунковым и Дэвидом Мазьером в 2002 году. Он определяет структуру сети и обмен информацией через узел поиска. Узлы Kademlia обмениваются данными между собой, используя UDP. Виртуальная или оверлейная сеть формируется узлами-участниками. Каждый узел идентифицируется номером или идентификатором узла. Идентификатор узла служит не только для идентификации, но алгоритм Kademlia использует идентификатор узла для поиска значений (обычно хэши файла или ключевые слова). Фактически, идентификатор узла обеспечивает прямое отображение хэшей файлов, и этот узел хранит информацию о том, где получить файл или ресурс.
При поиске некоторого значения алгоритм должен знать связанный ключ и исследует сеть в несколько шагов. На каждом шаге будут найдены узлы, которые находятся ближе к ключу, пока узел, с которым установился контакт, не вернет значение или пока не будут найдены более близкие узлы. Это очень эффективно: как и многие другие DHT, Kademlia связывается только с 

Дополнительные преимущества обнаруживаются, в частности, в децентрализованной структуре, которая повышает устойчивость к атаке отказа в обслуживании. Даже если весь набор узлов будет затоплен, это будет иметь ограниченное влияние на доступность сети, так как сеть будет восстанавливать себя, объединяя сеть вокруг этих «дыр».
I2P реализация Kademlia модифицирована для уменьшения уязвимостей Kademlia, таких как атаки Sybil.
Одноранговые сети обмена файлами первого поколения, такие как как Napster, полагался на центральную базу данных для координации поиска в сети. Одноранговые сети второго поколения, такие как Gnutella, использовали лавинную рассылку для поиска файлов с поиском каждого узла в сети. Одноранговые сети третьего поколения используют распределенные хэш-таблицы для поиска файлов в сети. Распределенные хеш-таблицы хранят ресурсы местоположения по всей сети. Главный критерий для этих протоколов - быстрое обнаружение нужных узлов.
Кадемлия использует вычисление «расстояния» между двумя узлами. Это расстояние вычисляется как исключающее или (XOR) двух идентификаторов узлов, принимая результат как целое число без знака. Ключи и идентификаторы узлов имеют одинаковый формат и длину, поэтому расстояние между ними можно вычислить одинаково. Идентификатор узла обычно представляет собой большое случайное число, которое выбирается с целью быть уникальным для конкретного узла (см. UUID ). Может случиться и так, что географически удаленные узлы - например, из Германии и Австралии - могут быть «соседями», если они выбрали одинаковые случайные идентификаторы узлов.
Исключительный или был выбран, потому что он действует как функция расстояния между всеми идентификаторами узлов. В частности:
Этих трех условий достаточно, чтобы исключить или захватить все существенные, важные особенности «реальной» функции расстояния, при этом они дешевы и просты в вычислении.
Каждая итерация поиска Kademlia приближается на один бит к цели. базовая сеть Kademlia с 2 узлами сделает только n шагов (в худшем случае), чтобы найти этот узел.
Этот раздел упрощен за счет использования одного бита ; см. раздел ускоренный поиск для получения дополнительной информации о реальных таблицах маршрутизации.
Таблицы маршрутизации фиксированного размера были представлены в предварительной версии исходной статьи и используются в более поздней версии только для некоторых математических доказательств. Фактическая реализация Kademlia не имеет таблицы маршрутизации фиксированного размера, а имеет таблицу динамического размера.
Таблицы маршрутизации Kademlia состоят из списка для каждого бита идентификатора узла. (например, если идентификатор узла состоит из 128 бит, узел будет хранить 128 таких списков.) Список имеет много записей. Каждая запись в списке содержит необходимые данные для поиска другого узла. Данные в каждой записи списка обычно представляют собой IP-адрес, порт и идентификатор другого узла. Каждый список соответствует определенному расстоянию от узла. Узлы, которые могут входить в список n, должны иметь бит, отличный от идентификатора узла; первые n-1 бит идентификатора кандидата должны совпадать с битами идентификатора узла. Это означает, что заполнить первый список очень просто, поскольку половина узлов в сети - далекие кандидаты. Следующий список может использовать только 1/4 узлов в сети (на один бит ближе, чем первый) и т. Д.
С идентификатором 128 бит каждый узел в сети будет классифицировать другие узлы в одном 128 различных расстояний, одно конкретное расстояние на бит.
Когда узлы встречаются в сети, они добавляются в списки. Это включает в себя операции сохранения и извлечения и даже помощь другим узлам в поиске ключа. Каждый обнаруженный узел будет рассматриваться для включения в списки. Следовательно, информация о сети, которую имеет узел, очень динамична. Это обеспечивает постоянное обновление сети и повышает устойчивость к сбоям или атакам.
В литературе Кадемлиа списки называются k-ведрами. k является общесистемным числом, например 20. Каждое k-ведро - это список, содержащий до k записей; т.е. для сети с k = 20 каждый узел будет иметь списки, содержащие до 20 узлов для определенного бита (на определенном расстоянии от себя).
Поскольку количество возможных узлов для каждого k-ведра быстро уменьшается (потому что будет очень мало узлов, которые находятся так близко), младшие битовые k-сегменты будут полностью отображать все узлы в этом разделе сети. Поскольку количество возможных идентификаторов намного больше, чем может быть любая популяция узлов, некоторые из k-блоков, соответствующих очень коротким расстояниям, останутся пустыми.
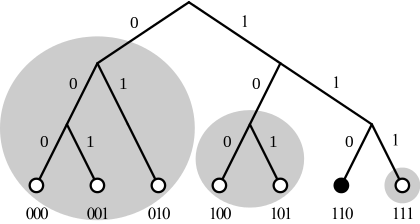 Сетевой раздел для узла 110
Сетевой раздел для узла 110 Рассмотрим простую сеть справа. Размер сети составляет 2 ^ 3 или восемь максимальных ключей и узлов. Участвуют семь узлов; маленькие кружки внизу. Рассматриваемый узел - это шестой узел (двоичный 110) черного цвета. Для каждого узла в этой сети есть три k-ведра. Узлы ноль, один и два (двоичные 000, 001 и 010) являются кандидатами на самый дальний k-сегмент. Узел три (двоичный 011, не показан) не участвует в сети. В средней k-корзине размещаются четвертый и пятый узлы (двоичные 100 и 101). Наконец, третье k-ведро может содержать только седьмой узел (двоичный 111). Каждая из трех k-корзин обведена серым кружком. Если размер k-сегмента был равен двум, то самый дальний 2-сегментный сегмент может содержать только два из трех узлов. Например, если у шестого узла есть узел один и два в самом дальнем 2-сегменте, он должен будет запросить поиск идентификатора узла для этих узлов, чтобы найти местоположение (IP-адрес) нулевого узла. Каждый узел хорошо знает свое окружение и контактирует с несколькими удаленными узлами, что может помочь определить местонахождение других удаленных узлов.
Известно, что узлы, которые были подключены в течение длительного времени в сети, вероятно, будут оставаться подключенными в течение длительного времени в будущем. Из-за этого статистического распределения Kademlia выбирает длинные подключенные узлы, чтобы они оставались хранящимися в k-бакетах. Это увеличивает количество известных действительных узлов в какой-то момент в будущем и обеспечивает более стабильную сеть.
Когда k-ведро заполнено и для этого k-ведра обнаружен новый узел, отправляется запрос PING для наименее недавно обнаруженного узла в k-ведре. Если обнаруживается, что узел все еще жив, новый узел помещается во вторичный список, замещающий кеш. Кэш замены используется только в том случае, если узел в k-ведре перестает отвечать. Другими словами: новые узлы используются только тогда, когда старые узлы исчезают.
В Kademlia четыре сообщения.
Каждое сообщение RPC включает случайное значение от инициатора. Это гарантирует, что полученный ответ соответствует ранее отправленному запросу. (см. Magic cookie )
Поиск узлов может выполняться асинхронно. Количество одновременных поисков обозначается α и обычно равно трем. Узел инициирует запрос FIND_NODE, запрашивая узлы α в своих собственных k-сегментах, которые являются ближайшими к желаемому ключу. Когда эти узлы-получатели получают запрос, они просматривают свои k-сегменты и возвращают k ближайших узлов к желаемому ключу, который им известен. Запрашивающая сторона обновит список результатов с результатами (идентификаторами узлов), которые он получает, сохраняя k лучших (k узлов, которые ближе к искомому ключу), которые отвечают на запросы. Затем инициатор запроса выберет эти k лучших результатов и отправит им запрос, и повторяйте этот процесс снова и снова. Поскольку каждый узел лучше знает свое окружение, чем любой другой узел, полученные результаты будут другими узлами, которые каждый раз все ближе и ближе к искомому ключу. Итерации продолжаются до тех пор, пока узлы возвращаются th at ближе, чем лучшие предыдущие результаты. Когда итерации останавливаются, k лучших узлов в списке результатов - это те узлы во всей сети, которые наиболее близки к желаемому ключу.
Информация об узле может быть дополнена временем приема-передачи или RTT. Эта информация будет использоваться для выбора тайм-аута, определенного для каждого запрашиваемого узла. Когда время ожидания запроса истекает, может быть инициирован другой запрос, никогда одновременно не превосходящий запросы α.
Информация находится путем сопоставления ее с ключом. Для карты обычно используется хэш . Узлы хранилища будут иметь информацию из-за предыдущего сообщения STORE. Поиск значения следует той же процедуре, что и поиск ближайших узлов к ключу, за исключением того, что поиск завершается, когда узел имеет запрошенное значение в своем хранилище и возвращает это значение.
Значения хранятся в нескольких узлах (k из них), чтобы позволить узлам приходить и уходить, и при этом иметь значение, доступное в каком-то узле. Периодически узел, хранящий значение, будет исследовать сеть, чтобы найти k узлов, которые близки к значению ключа, и реплицировать на них значение. Это компенсирует исчезнувшие узлы.
Кроме того, для популярных значений, которые могут иметь много запросов, нагрузка на узлы хранилища уменьшается, если извлекающий элемент сохраняет это значение в каком-то узле рядом, но за пределами k ближайших. Это новое хранилище называется кешем. Таким образом, значение сохраняется все дальше и дальше от ключа, в зависимости от количества запросов. Это позволяет по популярным поисковым запросам быстрее находить продавца. Поскольку значение возвращается из узлов, находящихся дальше от ключа, это устраняет возможные «горячие точки». Узлы кэширования сбросят значение через определенное время в зависимости от их расстояния от ключа.
Некоторые реализации (например, Kad ) не имеют ни репликации, ни кеширования. Целью этого является быстрое удаление старой информации из системы. Узел, предоставляющий файл, будет периодически обновлять информацию в сети (выполнять сообщения FIND_NODE и STORE). Когда все узлы, содержащие файл, отключатся, никто не будет обновлять его значения (источники и ключевые слова), и информация в конечном итоге исчезнет из сети.
Узел, который хочет присоединиться к сети, должен сначала пройти процесс начальной загрузки. На этом этапе присоединяющийся узел должен знать IP-адрес и порт другого узла - узла начальной загрузки (полученного от пользователя или из сохраненного списка) - который уже участвует в сети Kademlia. Если присоединяющийся узел еще не участвовал в сети, он вычисляет случайный идентификационный номер, который, как предполагается, еще не назначен никакому другому узлу. Он использует этот идентификатор до выхода из сети.
Присоединяющийся узел вставляет узел начальной загрузки в одну из своих k-корзин. Присоединяющийся узел затем выполняет поиск узла своего собственного идентификатора по узлу начальной загрузки (единственный другой узел, который он знает). «Самостоятельный поиск» заполнит k-сегменты других узлов новым идентификатором узла и заполнит k-сегменты присоединяемого узла узлами на пути между ним и узлом начальной загрузки. После этого присоединяющийся узел обновляет все k-сегменты, расположенные дальше, чем k-сегмент, в который попадает узел начальной загрузки. Это обновление представляет собой просто поиск случайного ключа, который находится в этом диапазоне k-сегментов.
Изначально узлы имеют одно k-ведро. Когда k-ведро заполнится, его можно разделить. Разделение происходит, если диапазон узлов в k-ведре охватывает собственный идентификатор узла (значения слева и справа в двоичном дереве). Kademlia ослабляет даже это правило для одного k-ведра "ближайших узлов", потому что обычно одно отдельное ведро будет соответствовать расстоянию, на котором находятся все узлы, которые являются ближайшими к этому узлу, они могут быть больше k, и мы хотим этого знать их всех. Может оказаться, что рядом с узлом существует сильно несбалансированное двоичное поддерево. Если k равно 20, и имеется 21+ узлов с префиксом «xxx0011.....», а новый узел - «xxx000011001», новый узел может содержать несколько k-сегментов для других 21+ узлов. Это гарантирует, что сеть знает обо всех узлах в ближайшем регионе.
Kademlia использует метрику XOR для определения расстояния. Два идентификатора узла или идентификатор узла и ключ подвергаются операции XOR, и в результате получается расстояние между ними. Для каждого бита функция XOR возвращает ноль, если два бита равны, и один, если два бита различны. Метрические расстояния XOR соответствуют неравенству треугольника : если A, B и C являются вершинами (точек) треугольника, то расстояние от A до B меньше (или равно) сумма расстояний от A до C и B.
Метрика XOR позволяет Kademlia расширять таблицы маршрутизации за пределы отдельных битов. Группы битов могут быть помещены в k-сегменты. Группа битов называется префиксом. Для m-битового префикса будет 2–1 k-сегментов. Отсутствующий k-сегмент является дальнейшим расширением дерева маршрутизации, содержащего идентификатор узла. M-битный префикс уменьшает максимальное количество поисков с журнала 2 n до журнала 2 n. Это максимальные значения, а среднее значение будет намного меньше, что увеличивает шанс найти узел в k-ведре, у которого больше битов, чем просто префикс с целевым ключом.
Узлы могут использовать смеси префиксов в своей таблице маршрутизации, например, Kad Network, используемую eMule. Сеть Kademlia может быть даже неоднородной в реализации таблиц маршрутизации за счет усложнения анализа поиска.
Хотя метрика XOR не нужна для понимания Kademlia, она имеет решающее значение для анализа протокола. Арифметика XOR формирует абелеву группу, позволяющую проводить закрытый анализ. Другие протоколы и алгоритмы DHT требуют моделирования или сложного формального анализа для прогнозирования поведения и правильности сети. Использование групп битов в качестве маршрутной информации также упрощает алгоритмы.
Для анализа алгоритма рассмотрим сеть Kademlia из 







Пусть 


![\ sup_ {x_1, \ ldots, x_n} \, \ sup_ {x \ in \ {x_1, \ ldots, x_n \}} \, \ sup_ {y \ in \ {0,1 \} ^ d} \ mathbb E [T_ {xy}] \ le (1 + o (1)) \ frac {\ log n} {H_k},](https://wikimedia.org/api/rest_v1/media/math/render/svg/45c858fed0fa63cee23b58ab815118ac52bac762)
где 





Чтобы сделать модель ближе к реальным сетям Kademlia, 
![\ begin {align} T_ {xy} \ xrightarrow {p} \ frac {\ log n} {c_k}, \ \ \ mathbb E [T_ {xy}] \ to \ frac {\ log n} {c_k}, \ end {align}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8969828abb25d0d320d069d57b607e60dbaec030)
где 




Kademlia используется в сетях обмена файлами. Выполняя поиск по ключевым словам Kademlia, можно найти информацию в сети обмена файлами и загрузить ее. Поскольку нет центрального экземпляра для хранения индекса существующих файлов, эта задача делится поровну между всеми клиентами: если узел хочет поделиться файлом, он обрабатывает содержимое файла, вычисляя на его основе число (hash ), который будет идентифицировать этот файл в сети обмена файлами. Хэши и идентификаторы узлов должны быть одинаковой длины. Затем он ищет несколько узлов, чей ID близок к хешу, и имеет собственный IP-адрес, хранящийся на этих узлах. то есть он публикует себя как источник для этого файла. Поисковый клиент будет использовать Kademlia для поиска в сети узла, идентификатор которого имеет наименьшее расстояние до хэша файла, а затем получит список источников, который хранится в этом узле.
Поскольку ключ может соответствовать множеству значений, например много источников одного и того же файла, каждый узел хранения может иметь разную информацию. Затем источники запрашиваются со всех k узлов, близких к ключу.
Хеш файла обычно получается из специально сформированной Интернет-ссылки магнитной ссылки, найденной где-то в другом месте или включенной в файл индексации, полученный из других источников.
Поиск по имени файла осуществляется с использованием ключевых слов. Имя файла делится на составляющие его слова. Каждое из этих ключевых слов хешируется и сохраняется в сети вместе с соответствующим именем файла и хешем файла. Поиск включает в себя выбор одного из ключевых слов, обращение к узлу с идентификатором, ближайшим к этому хешу ключевого слова, и получение списка имен файлов, содержащих это ключевое слово. Поскольку к каждому имени файла в списке прикреплен свой хэш, выбранный файл можно получить обычным способом.
Общедоступные сети с использованием алгоритма Kademlia (эти сети несовместимы друг с другом):