
Войти
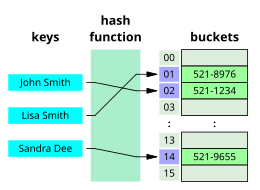 Визуальное представление хеш-таблицы , структура данных, позволяющая быстро извлекать информацию.
Визуальное представление хеш-таблицы , структура данных, позволяющая быстро извлекать информацию. В информатике алгоритм поиска - это любой алгоритм, который решает задача поиска, а именно, получить информацию, хранящуюся в некоторой структуре данных или вычисленную в пространстве поиска предметной области, либо с дискретными, либо с непрерывными значениями. К конкретным применениям алгоритмов поиска относятся:
Классические проблемы поиска, описанные выше, и веб-поиск - обе проблемы в поиске информации, но обычно изучаются как отдельные подполя и решаются и оцениваются по-разному. Задачи веб-поиска обычно сосредоточены на фильтрации и поиске документов, наиболее релевантных человеческим запросам. Классические алгоритмы поиска обычно оцениваются по тому, насколько быстро они могут найти решение и гарантированно ли это решение будет оптимальным. Хотя алгоритмы поиска информации должны быть быстрыми, качество ранжирования более важно, равно как и то, были ли пропущены хорошие результаты и включены ли плохие результаты.
Подходящий алгоритм поиска часто зависит от структуры данных, в которой выполняется поиск, и может также включать предварительные знания о данных. Некоторые структуры базы данных специально созданы для ускорения или повышения эффективности алгоритмов поиска, например, дерево поиска, хэш-карта или индекс базы данных.
. Алгоритмы поиска могут быть классифицированы на основе их механизма поиска. Линейный поиск. Алгоритмы линейно проверяют каждую запись на наличие записи, связанной с целевым ключом. Двоичный поиск или поиск с половинным интервалом, многократно нацеливается на центр структуры поиска и разделяет поиск пространство пополам. Алгоритмы сравнительного поиска улучшают линейный поиск, последовательно удаляя записи на основе сравнений ключей, пока не будет найдена целевая запись, и могут применяться к структурам данных в определенном порядке. Алгоритмы цифрового поиска работают на основе свойств цифр в структурах данных, использующих цифровые ключи. Наконец, хеширование напрямую сопоставляет ключи с записями на основе хэш-функции . Поиск вне линейного поиска требует, чтобы данные были каким-то образом отсортированы.
Алгоритмы часто оцениваются по их вычислительной сложности или максимальному теоретическому времени выполнения. Например, функции двоичного поиска имеют максимальную сложность O (log n) или логарифмическое время. Это означает, что максимальное количество операций, необходимых для поиска цели поиска, является логарифмической функцией размера области поиска.
Алгоритмы поиска виртуальных пространств используются в задаче удовлетворения ограничений, где цель состоит в том, чтобы найти набор присвоений значений определенным переменным, которые будут удовлетворять конкретным математическим уравнениям и неравенства / равенства. Они также используются, когда цель состоит в том, чтобы найти присвоение переменной, которое максимизирует или минимизирует определенную функцию этих переменных. Алгоритмы решения этих проблем включают в себя базовый поиск грубой силой (также называемый «наивным» или «неинформированным» поиском) и различные эвристики, которые пытаются использовать частичное знание структуры. этого пространства, такие как линейная релаксация, создание ограничений и распространение ограничений.
Важным подклассом являются методы локального поиска, которые рассматривают элементы пространства поиска как вершины графа с ребрами, определенными набором эвристик, применимых к случаю; и сканировать пространство, перемещаясь от элемента к элементу по краям, например, в соответствии с критерием наискорейшего спуска или наилучшим первым, или в стохастическом поиске. В эту категорию входит большое количество общих метаэвристических методов, таких как моделирование отжига, запретный поиск, команды A и генетическое программирование, которые особым образом сочетают произвольные эвристики.
Этот класс также включает в себя различные алгоритмы поиска по дереву, которые рассматривают элементы как вершины дерева и обходят это дерево в некотором особом порядке. Примеры последнего включают исчерпывающие методы, такие как поиск в глубину и поиск в ширину, а также различные эвристические методы сокращения дерева поиска, такие как как возврат с возвратом и ветвление и граница. В отличие от общей метаэвристики, которая в лучшем случае работает только в вероятностном смысле, многие из этих методов поиска по дереву гарантированно находят точное или оптимальное решение, если дать им достаточно времени. Это называется «полнота ».
Другой важный подкласс состоит из алгоритмов для исследования дерева игр многопользовательских игр, таких как шахматы или нарды, чьи узлы состоят из всех возможных игровых ситуаций, которые могут возникнуть в результате текущей ситуации. Цель этих задач - найти ход, обеспечивающий наилучшие шансы на победу, с учетом всех возможных ходов соперника (ов). Подобные проблемы возникают, когда людям или машинам приходится принимать последовательные решения, результаты которых не полностью находятся под их контролем, например, в робот руководстве или в маркетинге, финансах, или военное стратегическое планирование. Задачи такого типа - комбинаторный поиск - широко изучались в контексте искусственного интеллекта. Примерами алгоритмов для этого класса являются минимаксный алгоритм, альфа-бета-отсечение и алгоритм A * и его варианты.
Название «комбинаторный поиск» обычно используется для алгоритмов, которые ищут конкретную подструктуру данной дискретной структуры, например граф, строка , конечная группа и т. д. Термин комбинаторная оптимизация обычно используется, когда цель - найти подструктуру с максимальным (или минимальным) значением некоторого параметра. (Поскольку подструктура обычно представлена в компьютере набором целочисленных переменных с ограничениями, эти проблемы можно рассматривать как частные случаи удовлетворения ограничений или дискретной оптимизации; но они обычно формулируются и решаются в более абстрактных условиях, когда внутреннее представление явно не упоминается.)
Важным и широко изученным подклассом являются алгоритмы графа, в частности, алгоритмы обхода графа, для поиска конкретных подструктур в заданный граф - например, подграфы, пути, схемы и т. д. Примеры включают алгоритм Дейкстры, алгоритм Крускала, алгоритм ближайшего соседа и алгоритм Прима.
Другой важный подкласс этой категории - алгоритмы поиска строк, которые ищут шаблоны в строках. Двумя известными примерами являются алгоритмы Бойера – Мура и Кнута – Морриса – Пратта, а также несколько алгоритмов, основанных на структуре данных суффиксное дерево.
В 1953 году американский статистик Джек Кифер разработал поиск Фибоначчи, который может быть используется для нахождения максимума унимодальной функции и имеет множество других приложений в информатике.
Существуют также методы поиска, разработанные для квантовых компьютеров, такие как алгоритм Гровера, которые теоретически быстрее, чем линейные или грубые. принудительный поиск даже без помощи структур данных или эвристики.
Категории: