
Войти
Алгоритм Краскала находит минимальный остовный лес неориентированного взвешенного по ребрам графа. Если граф связан, он находит минимальное остовное дерево. (Минимальное остовное дерево связного графа - это подмножество ребер, которое формирует дерево, включающее каждую вершину, где сумма весов всех ребер в дереве минимизирована. Для несвязного графа минимальный остовной лес равен состоит из минимального остовного дерева для каждого связного компонента. ) Это жадный алгоритм в теории графов, так как на каждом шаге он добавляет следующее ребро с наименьшим весом, которое не будет формировать цикл, к минимальному остовному лесу.
Этот алгоритм впервые появился в Proceedings of the American Mathematical Society, pp. 48–50 в 1956 году и был написан Джозефом Крускалом.
Другие алгоритмы для этой задачи включают в себя алгоритм Примы, на обратном удаление алгоритма и алгоритм борувки.
По завершении алгоритма лес образует минимальный остовный лес графа. Если граф связан, лес состоит из одного компонента и образует минимальное остовное дерево.
 Демонстрация алгоритма Крускала на полном графе с весами, основанными на евклидовом расстоянии.
Демонстрация алгоритма Крускала на полном графе с весами, основанными на евклидовом расстоянии. Следующий код реализован с несвязной структурой данных. Здесь мы представляем наш лес F как набор ребер и используем структуру данных с непересекающимся набором, чтобы эффективно определять, являются ли две вершины частью одного и того же дерева.
algorithm Kruskal(G) is F:= ∅ for each v ∈ G.V do MAKE-SET(v) for each (u, v) in G.E ordered by weight(u, v), increasing do if FIND-SET(u) ≠ FIND-SET(v) then F:= F ∪ {(u, v)} ∪ {(v, u)} UNION(FIND-SET(u), FIND-SET(v)) return F Для графа с E ребрами и V вершинами можно показать, что алгоритм Крускала работает за время O ( E log E ) или, что эквивалентно, время O ( E log V ), и все это с простыми структурами данных. Эти времена работы эквивалентны, потому что:
Мы можем достичь этой границы следующим образом: сначала отсортируем ребра по весу, используя сортировку сравнения за время O ( E log E ); это позволяет шагу «удалить край с минимальным весом из S » работать с постоянным временем. Затем мы используем структуру данных с непересекающимися наборами, чтобы отслеживать, какие вершины находятся в каких компонентах. Мы помещаем каждую вершину в ее собственное непересекающееся множество, которое требует O ( V ) операций. Наконец, в худшем случае нам нужно перебрать все ребра, и для каждого ребра нам нужно выполнить две операции поиска и, возможно, одно объединение. Даже простая структура данных с непересекающимся множеством, такая как леса с непересекающимся множеством с объединением по рангу, может выполнять O ( E ) операций за время O ( E log V ). Таким образом, общее время O ( E log E ) = O ( E log V ).
При условии, что ребра либо уже отсортированы, либо могут быть отсортированы за линейное время (например, с помощью сортировки с подсчетом или сортировки по основанию ), алгоритм может использовать более сложную структуру данных с непересекающимися наборами для работы за время O ( E α ( V ))., где α - чрезвычайно медленно растущая обратная функция однозначной функции Аккермана.
| Изображение | Описание |
|---|---|
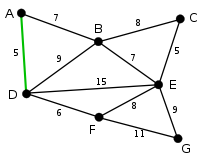 | AD и CE - самые короткие ребра, их длина равна 5, а AD было выбрано произвольно, поэтому оно выделено. |
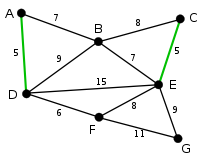 | CE теперь является самым коротким ребром, не образующим цикла, длиной 5, поэтому оно выделено как второе ребро. |
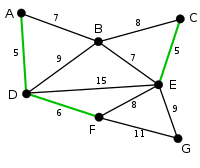 | Следующее ребро, DF длиной 6, выделяется почти таким же способом. |
 | Следующие по длине ребра - это AB и BE, обе длины 7. AB выбирается произвольно и выделяется. Ребро BD было выделено красным, потому что уже существует путь (зеленый) между B и D, поэтому, если бы он был выбран, он образовал бы цикл ( ABD ). |
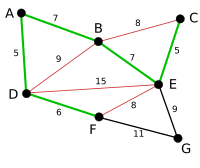 | Процесс продолжает выделять следующее наименьшее ребро, BE с длиной 7. На этом этапе красным цветом выделено гораздо больше ребер: BC, потому что он будет формировать цикл BCE, DE, потому что он будет формировать цикл DEBA, и FE, потому что он будет форма FEBAD. |
 | Наконец, процесс заканчивается ребром EG длиной 9, и минимальное остовное дерево найдено. |
Доказательство состоит из двух частей. Во-первых, доказывается, что алгоритм создает остовное дерево. Во-вторых, доказано, что построенное остовное дерево имеет минимальный вес.
Позвольте быть связным, взвешенным графом и пусть быть подграфом, созданным алгоритмом. не может иметь цикла, так как по определению ребро не добавляется, если оно приводит к циклу. не может быть отключен, так как первое встреченное ребро, которое соединяет два компонента, было бы добавлено алгоритмом. Таким образом, остовное дерево.
Мы показываем, что следующее предложение P истинно по индукции : если F - множество ребер, выбранных на любом этапе алгоритма, то существует некоторое минимальное остовное дерево, которое содержит F и ни одно из ребер не отклоняется алгоритмом.
Алгоритм Крускала по своей сути является последовательным, и его трудно распараллелить. Однако можно выполнить начальную сортировку ребер параллельно или, в качестве альтернативы, использовать параллельную реализацию двоичной кучи для извлечения ребра с минимальным весом на каждой итерации. Поскольку на процессорах возможна параллельная сортировка по времени, время выполнения алгоритма Крускала можно сократить до O ( E α ( V)), где α снова является обратной по отношению к однозначной функции Аккермана.
Вариант алгоритма Краскала, названный Фильтр-Краскал, был описан Осиповым и др. и лучше подходит для распараллеливания. Основная идея Filter-Kruskal состоит в том, чтобы разделить ребра аналогично быстрой сортировке и отфильтровать ребра, которые соединяют вершины одного дерева, чтобы снизить стоимость сортировки. Следующий псевдокод демонстрирует это.
function filter_kruskal(G) is if |G.E| lt; kruskal_threshold: return kruskal(G) pivot = choose_random(G.E) , = partition(G.E, pivot) A = filter_kruskal() = filter() A = A ∪ filter_kruskal() return A function partition(E, pivot) is = ∅, = ∅ foreach (u, v) in E do if weight(u, v) lt;= pivot then = ∪ {(u, v)} else = ∪ {(u, v)} return , function filter(E) is = ∅ foreach (u, v) in E do if find_set(u) ≠ find_set(v) then = ∪ {(u, v)} return
Filter-Kruskal лучше подходит для распараллеливания, поскольку сортировку, фильтрацию и разбиение можно легко выполнять параллельно, распределяя границы между процессорами.
Наконец, были изучены другие варианты параллельной реализации алгоритма Крускала. Примеры включают схему, в которой используются вспомогательные потоки для удаления ребер, которые определенно не являются частью MST в фоновом режиме, и вариант, который запускает последовательный алгоритм на p подграфах, а затем объединяет эти подграфы до тех пор, пока не останется только один, последний MST.







 ,
,  = partition(G.E, pivot) A = filter_kruskal(
= partition(G.E, pivot) A = filter_kruskal( = ∅ foreach (u, v) in E do if find_set(u) ≠ find_set(v) then
= ∅ foreach (u, v) in E do if find_set(u) ≠ find_set(v) then