
Войти
 Обычный метод наименьших квадратов регрессия закона Окуня. Поскольку линия регрессии не сильно пропускает ни одну из точек, R регрессии относительно высок.
Обычный метод наименьших квадратов регрессия закона Окуня. Поскольку линия регрессии не сильно пропускает ни одну из точек, R регрессии относительно высок.  Сравнение оценки Тейла – Сена (черный) и простой линейной регрессии (синий) для набора точек с выбросами. Из-за большого количества выбросов ни одна из линий регрессии не соответствует данным хорошо, что измеряется тем фактом, что ни одна из них не дает очень высокого R.
Сравнение оценки Тейла – Сена (черный) и простой линейной регрессии (синий) для набора точек с выбросами. Из-за большого количества выбросов ни одна из линий регрессии не соответствует данным хорошо, что измеряется тем фактом, что ни одна из них не дает очень высокого R. В статистике коэффициент детерминации, обозначаемый R или r и произносимый как «R в квадрате», представляет собой долю дисперсии в зависимой переменной, которая может быть предсказана на основе независимых переменных.
Это статистика, используемая в контексте статистических моделей, основная цель которых - либо прогноз будущих результатов, либо тестирование гипотез на основе другой связанной информации. Он обеспечивает меру того, насколько хорошо наблюдаемые результаты воспроизводятся моделью, на основе доли общей вариации результатов, объясняемой моделью.
Существует несколько определений R, которые лишь иногда эквивалентны. Один класс таких случаев включает случай простой линейной регрессии, где r используется вместо R. Когда включен отрезок , тогда r - это просто квадрат корреляции выборки . коэффициент (т. е. r) между наблюдаемыми результатами и наблюдаемыми значениями предиктора. Если включены дополнительные регрессоры, R представляет собой квадрат коэффициента множественной корреляции. В обоих таких случаях коэффициент детерминации обычно находится в диапазоне от 0 до 1.
Есть случаи, когда вычислительное определение R может давать отрицательные значения, в зависимости от используемого определения. Это может возникнуть, когда прогнозы, которые сравниваются с соответствующими результатами, не были получены в результате процедуры подгонки модели с использованием этих данных. Даже если была использована процедура подгонки модели, R все еще может быть отрицательным, например, когда линейная регрессия проводится без включения точки пересечения или когда для подгонки данных используется нелинейная функция. В случаях, когда возникают отрицательные значения, среднее значение данных лучше соответствует результатам, чем значения подобранной функции, в соответствии с этим конкретным критерием. Поскольку наиболее общее определение коэффициента детерминации также известно как коэффициент эффективности модели Нэша – Сатклиффа, это последнее обозначение предпочтительнее во многих областях, поскольку обозначает показатель согласия, который может варьироваться от От −∞ до 1 (т. Е. Может давать отрицательные значения) с буквой в квадрате сбивает с толку.
При оценке степени соответствия смоделированных (Y pred) и измеренных (Y obs) значений, нецелесообразно основывать это на R линейной регрессии (т.е. Y obs = m · Y pred + b). R количественно определяет степень любой линейной корреляции между Y obs и Y pred, в то время как для оценки согласия следует принимать во внимание только одну конкретную линейную корреляцию: Y obs = 1 · Y pred + 0 (т. Е. Строка 1: 1).
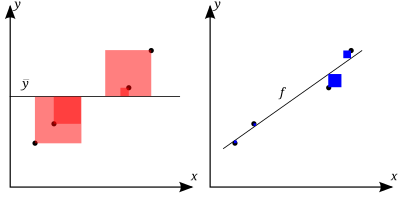
 . Чем лучше линейная регрессия (справа) соответствует данным по сравнению с простое среднее (на левом графике), чем ближе значение
. Чем лучше линейная регрессия (справа) соответствует данным по сравнению с простое среднее (на левом графике), чем ближе значение  к 1. Площади синих квадратов представляют собой квадраты остатков относительно к линейной регрессии. Области красных квадратов представляют собой квадраты остатков по отношению к среднему значению.
к 1. Площади синих квадратов представляют собой квадраты остатков относительно к линейной регрессии. Области красных квадратов представляют собой квадраты остатков по отношению к среднему значению. A набор данных имеет n значений, отмеченных y 1,..., y n (вместе известные как y i или как вектор y = [y 1,..., y n ]), каждый связанный с подобранным (или смоделированным, или прогнозируемым) значением f 1,..., f n (известный как f i, или иногда ŷ i, как вектор f ).
Определите остатки как e i = y i - f i (формируя вектор e ).
Если 

тогда изменчивость набора данных может быть измеряется с помощью двух формул суммы квадратов :


Наиболее общее определение коэффициента детерминации:

В лучшем В этом случае смоделированные значения точно соответствуют наблюдаемым, в результате получается 


В общем виде R можно рассматривать как связана с долей необъяснимой дисперсии (FVU), поскольку второй член сравнивает необъяснимую дисперсию (дисперсию ошибок модели) с общей дисперсией (данных):

Предположим, R = 0,49. Это означает, что 49% изменчивости зависимой переменной было учтено, а остальные 51% изменчивости все еще не учтены. В некоторых случаях общая сумма квадратов равна сумме двух других сумм квадратов, определенных выше,
Если сумма квадратов регрессии, также называемая объясненной суммой квадратов, определяется по формуле:

, затем

См. раздел Разделение в общей модели OLS для получения этого результата для одного случая, когда соотношение выполняется. Когда это соотношение действительно выполняется, приведенное выше определение R эквивалентно

где n - количество наблюдений (наблюдений) по переменным.
В этой форме R выражается как отношение объясненной дисперсии (дисперсия прогнозов модели, которая равна SS reg / n) к общей дисперсии ( выборочная дисперсия зависимой переменной, которая составляет SS tot / n).
Это разделение суммы квадратов имеет место, например, когда значения модели ƒ i были получены с помощью линейной регрессии. Более мягкое достаточное условие выглядит следующим образом: Модель имеет вид

где q i - произвольные значения, которые могут зависеть или не зависеть от i или других свободных параметров (общий выбор q i = x i - это лишь один частный случай), а оценки коэффициентов 

Этот набор условий является важным и имеет ряд последствий для свойств подогнанных остатков и смоделированных значений. В частности, при этих условиях:

В линейных наименьших квадратах множественная регрессия с оценкой член перехвата, R равен квадрату коэффициента корреляции Пирсона между наблюдаемым 

В линейной регрессии методом наименьших квадратов с членом перехвата и одним объяснителем это также равно квадрату коэффициента корреляции Пирсона зависимой переменной
Его не следует путать с коэффициентом корреляции между двумя оценками, который определяется как

где ковариация между двумя оценками коэффициентов, а также их стандартные отклонения, получаются из ковариационной матрицы оценок коэффициентов.
В более общих условиях моделирования, когда прогнозируемые значения могут быть сгенерированы из модели, отличной от линейной регрессии наименьших квадратов, значение R может быть вычислено как квадрат коэффициента корреляции между исходные
R - статистика, которая дает некоторую информацию о степени соответствия модели. В регрессии коэффициент детерминации R является статистической мерой того, насколько хорошо предсказания регрессии соответствуют реальным точкам данных. R, равный 1, указывает на то, что прогнозы регрессии идеально соответствуют данным.
Значения R за пределами диапазона от 0 до 1 могут возникать, когда модель соответствует данным хуже, чем горизонтальная гиперплоскость. Это могло произойти, если была выбрана неправильная модель или по ошибке были применены бессмысленные ограничения. Если используется уравнение 1 Квалсета (это уравнение используется наиболее часто), R может быть меньше нуля. Если используется уравнение 2 Квалсета, R может быть больше единицы.
Во всех случаях, когда используется R, предикторы вычисляются с помощью обычной регрессии наименьших квадратов : то есть путем минимизации SS res. В этом случае R увеличивается по мере увеличения количества переменных в модели (R монотонно увеличивается с количеством включенных переменных - оно никогда не будет уменьшаться). Это иллюстрирует недостаток одного из возможных вариантов использования R, когда можно продолжать добавлять переменные (регрессия кухонной мойки ) для увеличения значения R. Например, если кто-то пытается спрогнозировать продажи модели автомобиля по расходу бензина, цене и мощности двигателя, можно включить такие несущественные факторы, как первая буква названия модели или рост ведущего инженера, занимающегося проектированием. автомобиль, потому что R никогда не будет уменьшаться при добавлении переменных и, вероятно, будет увеличиваться только благодаря случайности.
Это приводит к альтернативному подходу рассмотрения скорректированного R. Объяснение этой статистики почти такое же, как и у R, но оно ухудшает статистику, поскольку в модель включены дополнительные переменные. Для случаев, отличных от аппроксимации обычным методом наименьших квадратов, статистика R может быть рассчитана, как указано выше, и может быть полезной мерой. Если аппроксимация осуществляется с помощью взвешенных наименьших квадратов или обобщенных наименьших квадратов, альтернативные версии R могут быть рассчитаны в соответствии с этими статистическими структурами, в то время как "исходный" R может быть полезен, если он более легко интерпретируется. Значения R могут быть рассчитаны для любого типа прогнозной модели, которая не обязательно должна иметь статистическую основу.
Рассмотрим линейную модель с более чем одной независимой переменной в форме

где для i-го случая 



R часто интерпретируется как доля вариации ответа, «объясняемая» регрессорами в модели. Таким образом, R = 1 указывает, что подобранная модель объясняет всю изменчивость в
Предупреждение, которое применяется к R, как и к другим статистическим описаниям корреляции и ассоциации, состоит в том, что «корреляция не подразумевает причинно-следственную связь ». Другими словами, хотя корреляции могут иногда давать ценные ключи к раскрытию причинно-следственных связей между переменными, ненулевая оценочная корреляция между двумя переменными сама по себе не свидетельствует о том, что изменение значения одной переменной приведет к изменениям в значениях переменных. другие переменные. Например, практика ношения спичек (или зажигалки) коррелирует с заболеваемостью раком легких, но ношение спичек не вызывает рак (в стандартном смысле слова «причина»).
В случае единственного регрессора, подобранного методом наименьших квадратов, R является квадратом коэффициента корреляции продукта Пирсона, связывающего регрессор и переменную отклика. В более общем смысле R - это квадрат корреляции между построенным предиктором и переменной ответа. С более чем одним регрессором R может называться коэффициентом множественной детерминации.
В регрессии наименьших квадратов с использованием типичных данных R находится на наименее слабо увеличивается с увеличением количества регрессоров в модели. Поскольку увеличение количества регрессоров увеличивает значение R, само по себе R не может использоваться для значимого сравнения моделей с очень разным количеством независимых переменных. Для значимого сравнения двух моделей можно выполнить F-тест на остаточной сумме квадратов, аналогично F-тестам в причинно-следственной связи Грейнджера, хотя это не всегда уместно. Напомним, что некоторые авторы обозначают R как R q, где q - количество столбцов в X (количество пояснителей, включая константу).
Чтобы продемонстрировать это свойство, сначала напомним, что цель линейной регрессии наименьших квадратов составляет

где X i - вектор-строка значений независимых переменных для случая i, а b - вектор-столбец коэффициентов соответствующих элементов X i.
Оптимальное значение цели немного меньше, чем более пояснительное добавляются переменные, и, следовательно, добавляются дополнительные столбцы 

Интуитивно понятная причина того, что использование дополнительной независимой переменной не может снизить R, заключается в следующем: Минимизация 
R не указывает, являются ли:
Использование скорректированного R (одно общее обозначение 




где p - общее количество независимых переменных в модели (не включая постоянный член), а n - размер выборки. Его также можно записать как:

где df t - это степени свободы n - 1 оценки дисперсии генеральной совокупности зависимой переменной, а df e - это степени свободы n - p - 1 оценки. основной дисперсии ошибки генеральной совокупности.
Скорректированное R может быть отрицательным, и его значение всегда будет меньше или равно значению R. В отличие от R, скорректированное R увеличивается только при увеличении R (из-за включения новой пояснительной переменная) больше, чем можно было бы ожидать увидеть случайно. Если набор объясняющих переменных с заранее определенной иерархией важности вводится в регрессию по одной, при каждом вычислении скорректированного R, уровень, на котором скорректированный R достигает максимума и впоследствии уменьшается, будет регрессией с идеальное сочетание наличия оптимального соответствия без лишних / лишних сроков.
Скорректированный R можно интерпретировать как несмещенную (или менее смещенную) оценку совокупности R, тогда как наблюдаемая выборка R представляет собой положительно смещенную оценку значения совокупности. Скорректированный R более уместен при оценке соответствия модели (дисперсия в зависимой переменной, учитываемой независимыми переменными) и при сравнении альтернативных моделей на этапе выбора характеристик построения модели.
Принцип, лежащий в основе скорректированной статистики R, можно увидеть, переписав обычное R как

где 



Коэффициент частичной детерминации можно определить как долю вариации, которая не может быть объяснена в сокращенной модели, но могут быть объяснены предикторами, указанными в полной (er) модели. Этот коэффициент используется для понимания того, могут ли один или несколько дополнительных предикторов быть полезными в более полностью определенной регрессионной модели.
Вычисление частичного R является относительно простым после оценки двух моделей и создания для них таблиц ANOVA. Расчет частичного R:

который аналогичен обычному коэффициенту детерминации:

Как объяснено выше, эвристика выбора модели, такая как критерий Скорректированный
 Геометрическое представление
Геометрическое представление  .
.В качестве альтернативы можно разложить обобщенную версию

Предполагается, что матрица 


Индивидуальный эффект отклонения от гипотезы на 

где 





В случае логистической регрессии, которая обычно соответствует максимальной вероятности, существует несколько вариантов псевдо -R.
Один из них - это обобщенное R, первоначально предложенное Cox Snell и независимо от Magee:

где 


где D - статистика теста критерия отношения правдоподобия.
Нагелькерке отметил, что он имел следующие свойства:
Однако в случае логистической модели, где 

Иногда норма остатков используется для указания степени соответствия. Этот член вычисляется как квадратный корень из суммы квадратов остатков :

И R, и норма остатков имеют свои относительные достоинства. Для анализа методом наименьших квадратов R изменяется от 0 до 1, при этом большие числа указывают на лучшее соответствие, а 1 представляет собой идеальное соответствие. Норма остатков варьируется от 0 до бесконечности, меньшие числа указывают на лучшее соответствие, а ноль - на идеальное соответствие. Одним из преимуществ и недостатков R является действие члена 

R = 0,998, а норма остатков = 0,302. Если все значения y умножаются на 1000 (например, при изменении префикса SI ), то R остается прежним, но норма остатков = 302.
Другой однопараметрический индикатор соответствия - это RMSE остатков или стандартное отклонение остатков. This would have a value of 0.135 for the above example given that the fit was linear with an unforced intercept.
The creation of the coefficient of determination has been attributed to the geneticist Sewall Wright and was first published in 1921.

