В статистике, коэффициент корреляции Пирсона (PCC, произносится как ), также упоминается как r Пирсона, коэффициент корреляции произведения-момента Пирсона (PPMCC ), или двумерная корреляция - это статистика, которая измеряет линейную корреляцию между двумя переменными X и Y. Она имеет значение от +1 до -1. Значение +1 - полная положительная линейная корреляция, 0 - отсутствие линейной корреляции, а -1 - полная отрицательная линейная корреляция.
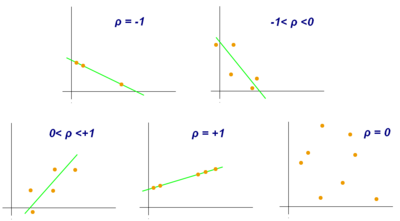
Примеры диаграмм разброса с разными значениями коэффициента корреляции (ρ)

Несколько наборов (x, y) точек с коэффициентом корреляции x и y для каждого набора. Обратите внимание, что корреляция отражает силу и направление линейной связи (верхняя строка), но не наклон этой связи (в середине) и не многие аспекты нелинейных отношений (внизу). NB: фигура в центре имеет наклон 0, но в этом случае коэффициент корреляции не определен, потому что дисперсия Y равна нулю.
Содержание
- 1 Именование и история
- 2 Определение
- 2.1 Для совокупность
- 2.2 Для выборки
- 2.3 Практические вопросы
- 3 Математические свойства
- 4 Интерпретация
- 4.1 Геометрическая интерпретация
- 4.2 Интерпретация величины корреляции
- 5 Заключение
- 5.1 Использование теста перестановки
- 5.2 Использование бутстрапа
- 5.3 Тестирование с использованием t-распределения Стьюдента
- 5.4 Использование точного распределения
- 5.5 Использование преобразования Фишера
- 6 Регрессионный анализ методом наименьших квадратов
- 7 Чувствительность к распределению данных
- 7.1 Существование
- 7.2 Размер выборки
- 7.3 Устойчивость
- 8 Варианты
- 8.1 Скорректированный коэффициент корреляции
- 8.2 Взвешенный коэффициент корреляции
- 8.3 Коэффициент отражающей корреляции
- 8,4 Масштабный коэффициент корреляции
- 8,5 Расстояние Пирсона
- 8,6 Коэффициент круговой корреляции
- 8,7 Частичная корреляция
- 9 Декорреляция n случайных величин
- 10 Программные реализации
- 11 См. Также
- 12 Сноски
- 13 Ссылки
- 14 Внешние ссылки
Именование и история
Он был разработан Карлом Пирсоном на основе связанной идеи, представленной Фрэнсисом Гальтоном в 1880-х годах, математическая формула для которой была выведена и опубликована Огюстом Браве в 1844 году. Таким образом, название коэффициента является примером закона Стиглера.
определения
Коэффициент корреляции Пирсона - это ковариация двух переменных, деленная на произведение их стандартные отклонения. Форма определения включает «момент продукта», то есть среднее значение (первый момент относительно начала координат) произведения случайных величин, скорректированных на среднее значение; отсюда и модификатор product-moment в названии.
Для генеральной совокупности
коэффициент корреляции Пирсона в применении к совокупности обычно представляется греческой буквой ρ (ро) и может называться совокупностью коэффициент корреляции или коэффициент корреляции Пирсона населения. Для пары случайных величин  формула для ρ имеет следующий вид:
формула для ρ имеет следующий вид:
 | | (Уравнение 1) |
где:
 - ковариация
- ковариация  - стандартное отклонение
- стандартное отклонение 
 - стандартное отклонение
- стандартное отклонение 
Формула для  может быть выражена в терминах среднего и математического ожидания. Поскольку
может быть выражена в терминах среднего и математического ожидания. Поскольку
![{\ displaystyle \ operatorname {cov} (X, Y) = \ operatorname {\ mathbb {E}} [(X- \ mu _ {X}) (Y- \ mu _ {Y})],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1e88bc4ba085b98d5cca09b958ad378d50127308)
формула для также может записывается как
![{\ displaystyle \ rho _ {X, Y} = {\ frac {\ operatorname {\ mathbb {E}} [(X- \ mu _ {X}) (Y- \ mu _ {Y})]} {\ sigma _ {X} \ sigma _ {Y}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/042c646e848d2dc6e15d7b5c7a5b891941b2eab6) | | (уравнение.2) |
где:
 и определены, как указано выше
и определены, как указано выше - это среднее значение для
- это среднее значение для  - это среднее из
- это среднее из  - это ожидание.
- это ожидание.
Формула для может быть выражена в терминах нецентрированных моментов. Поскольку
![{\ displaystyle \ mu _ {X} = \ operatorname {\ mathbb {E}} [\, X \, ]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1182bdcc66a113596e3ece07a0acbeda8d56d483)
![{\ displaystyle \ mu _ {Y} = \ operatorname {\ mathbb {E}} [\, Y \,]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b2f14f5eda9d726e57048a2c56889912a80a06b6)
![{\ displaystyle \ sigma _ {X} ^ {2} = \ operatorname {\ mathbb {E}} [\, \ left (X- \ operatorname {\ mathbb {E}} [X] \ right) ^ {2} \,] = \ operatorname {\ mathbb {E}} [\, X ^ {2} \,] - \ left (\ operatorname {\ mathbb {E}} [\, X \,] \ справа) ^ {2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/cbf27c91550c7c82ee7e9e948673eb99da1a7378)
![{\ displaystyle \ sigma _ {Y} ^ {2} = \ operatorname {\ mathbb {E}} [\, \ left (Y- \ operatorname {\ mathbb {E}} [Y] \ right) ^ {2 } \,] = \ operatorname {\ mathbb {E}} [\, Y ^ {2} \,] - \ left (\, \ operatorname {\ mathbb {E}} [\, Y \,] \ right) ^ {2}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ed498483dae15dbb86e957b5a1463f5536885902)
![{\ displaystyle \ operatorname {\ mathbb {E}} [\, \ left (X- \ mu _ {X} \ right) \ left (Y- \ mu _ {Y} \ right) \,] = \ operatorname {\ mathbb {E}} [\, \ left (X- \ operatorname {\ mathbb {E}} [\, X \,] \ right) \ left (Y- \ operatorname {\ mathbb {E}} [\, Y \,] \ right) \,] = \ operatorname {\ mathbb {E}} [\, X \, Y \,] - \ operatorname {\ mathbb {E}} [\, X \,] \ operatorn ame {\ mathbb {E}} [\, Y \,] \,,}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4443378e105084380438782ebd391f8cb0e8e048)
формулу для можно также записать как
![{\ displaystyle \ rho _ {X, Y} = {\ frac {\ operatorname {\ mathbb {E}} [\, X \, Y \,] - \ operatorname {\ mathbb { E}} [\, X \,] \ OperatorName {\ mathbb {E}} [\, Y \,]} {{\ sqrt {\ operatorname {\ mathbb {E}} [\, X ^ {2} \,] - \ left (\ operatorname {\ mathbb {E}} [\, X \,] \ right) ^ {2}}} ~ {\ sqrt {\ operatorname {\ mathbb {E}} [\, Y ^ {2} \,] - \ left (\ operatorname {\ mathbb {E}} [\, Y \,] \ right) ^ {2}}}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0a96c914bb811b84698b4d4118794cf4c8167ca7)
Для образца
Коэффициент корреляции Пирсона, примененный к образец, обычно представлен как  и может упоминаться как коэффициент корреляции выборки или коэффициент корреляции Пирсона выборки. Мы можем получить формулу для , подставив оценки ковариаций и дисперсий на основе выборки в формулу выше. Для парных данных
и может упоминаться как коэффициент корреляции выборки или коэффициент корреляции Пирсона выборки. Мы можем получить формулу для , подставив оценки ковариаций и дисперсий на основе выборки в формулу выше. Для парных данных  состоящий из
состоящий из  пар, определяется как:
пар, определяется как:
 | | (уравнение 3) |
где:
- - размер выборки
 - отдельные точки выборки, проиндексированные с i
- отдельные точки выборки, проиндексированные с i (образец означает ); и аналогично для
(образец означает ); и аналогично для 
перестановка дает нам эту формулу для :

где  определены, как указано выше.
определены, как указано выше.
Эта формула предлагает удобный однопроходный алгоритм для вычисления выборочных корреляций, хотя, в зависимости от задействованных чисел, иногда он может быть численно нестабильным.
Повторное преобразование дает нам эту формулу для :

где  определены, как указано выше.
определены, как указано выше.
Эквивалентное выражение дает формулу для как среднее значение произведений стандартных оценок следующим образом:

где
- определены, как указано выше, а
 определены ниже
определены ниже  - стандартная оценка (и аналогично для стандартной оценки
- стандартная оценка (и аналогично для стандартной оценки  )
)
Альтернативные формулы для . Например, можно использовать следующую формулу для :

где:
- определены, как указано выше и:
 (образец стандартное отклонение ); и аналогично для
(образец стандартное отклонение ); и аналогично для 
Практические вопросы
В условиях сильного шума извлечение коэффициента корреляции между двумя наборами стохастических переменных нетривиально, в частности, если канонический корреляционный анализ сообщает о ухудшенных значениях корреляции из-за сильных шумов. Обобщение этого подхода дается в другом месте.
В случае отсутствия данных Гаррен получил оценку максимального правдоподобия.
Математические свойства
Абсолютные значения коэффициентов корреляции Пирсона выборки и генеральной совокупности равны или находятся между 0 и 1. Корреляции, равные +1 или -1, соответствуют точкам данных, лежащим точно на линии (в случае выборочной корреляции), или двумерному распределению полностью поддерживается на линии (в случае корреляции населения). Коэффициент корреляции Пирсона симметричен: corr (X, Y) = corr (Y, X).
Ключевым математическим свойством коэффициента корреляции Пирсона является то, что он инвариант при отдельных изменениях положения и масштаба двух переменных. То есть мы можем преобразовать X в a + bX и преобразовать Y в c + dY, где a, b, c и d - константы с b, d>0, без изменения коэффициента корреляции. (Это справедливо как для генеральных, так и для выборочных коэффициентов корреляции Пирсона.) Обратите внимание, что более общие линейные преобразования действительно изменяют корреляцию: см. § Декорреляция n случайных величин для применения этого.
Интерпретация
Коэффициент корреляции варьируется от -1 до 1. Значение 1 означает, что линейное уравнение идеально описывает взаимосвязь между X и Y, причем все точки данных лежат на строка, для которой Y увеличивается с увеличением X. Значение -1 означает, что все точки данных лежат на линии, для которой Y уменьшается с увеличением X. Значение 0 означает, что между переменными нет линейной корреляции.
В целом, обратите внимание, что (X i - X) (Y i - Y) положительна тогда и только тогда, когда X i и Y i лежат на одной стороне от своих соответствующих средних. Таким образом, коэффициент корреляции является положительным, если X i и Y i имеют тенденцию одновременно быть больше или одновременно меньше, чем их соответствующие средние значения. Коэффициент корреляции является отрицательным (антикорреляция ), если X i и Y i имеют тенденцию лежать на противоположных сторонах своих соответствующих средних. Более того, чем сильнее любая тенденция, тем больше абсолютное значение коэффициента корреляции.
Роджерс и Найсвандер каталогизировали тринадцать способов интерпретации корреляции:
- Функция исходных оценок и средних
- Стандартизованная ковариация
- Стандартизованный наклон линии регрессии
- Среднее геометрическое двух наклонов регрессии
- Квадратный корень из отношения двух дисперсий
- Среднее перекрестное произведение стандартизованных переменных
- Функция угла между двумя стандартизованными линиями регрессии
- Функция угла между двумя векторами переменных
- Измененная дисперсия разницы между стандартизованными оценками
- Оценка по правилу балуна
- Относится к двумерным эллипсам изоконцентрации
- Функция тестовой статистики из запланированных экспериментов
- Отношение двух средних
Геометрическая интерпретация
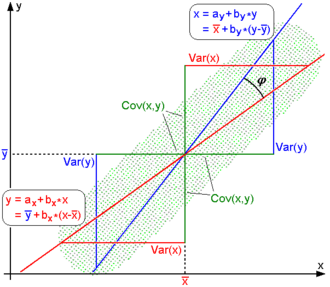
Линии регрессии для y = g X (x) [ красный] и x = g Y (y) [синий]
Для нецентрированных данных существует связь между коэффициентом корреляции и углом φ между двумя регрессиями. на линиях y = g X (x) и x = g Y (y), полученные путем регрессии y по x и x по y соответственно. (Здесь φ измеряется против часовой стрелки в первом квадранте, сформированном вокруг точки пересечения линий, если r>0, или против часовой стрелки от четвертого во второй квадрант, если r < 0.) One can show that if the standard deviations are equal, then r = sec φ − tan φ, where sec and tan are тригонометрические функции.
для центрированных данных (т. Е. Данных, которые были сдвинуты выборочными средними их соответствующих переменных, чтобы иметь нулевое среднее значение для каждой переменной), коэффициент корреляции также можно рассматривать как косинус угла угла θ между двумя наблюдаемыми векторами в N-мерном пространстве (для N наблюдений каждой переменной)
Для набора данных можно определить как нецентрированные (несовместимые с Пирсоном), так и центрированные коэффициенты корреляции. В качестве примера предположим, что установлено, что валовой национальный продукт пяти стран составляет 1, 2, 3, 5 и 8 миллиардов долларов соответственно. Предположим, что те же пять стран (в том же порядке) имеют 11%, 12 %, 13%, 15% и 18% бедности. Затем позвольте x и y быть упорядоченными 5-элементными векторами con с учетом приведенных выше данных: x = (1, 2, 3, 5, 8) и y = (0,11, 0,12, 0,13, 0,15, 0,18).
При обычной процедуре нахождения угла θ между двумя векторами (см. скалярное произведение ) нецентрированный коэффициент корреляции равен:

Этот нецентрированный коэффициент корреляции идентичен косинусу сходства . Обратите внимание, что приведенные выше данные были намеренно выбраны так, чтобы они идеально коррелировали: y = 0,10 + 0,01 x. Следовательно, коэффициент корреляции Пирсона должен быть равен единице. Центрирование данных (смещение x на (x ) = 3,8 и y на (y ) = 0,138) дает x = (−2,8, −1,8, −0,8, 1,2, 4,2) и y = (−0,028, −0,018, −0,008, 0,012, 0,042), откуда

как и ожидалось.
Интерпретация размера корреляции
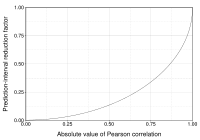
Этот рисунок дает представление о том, как полезность корреляции Пирсона для прогнозирования значений зависит от ее величины. Учитывая совместно нормальные X, Y с корреляцией ρ,

(показано здесь как функция от ρ) - коэффициент, на который данный
интервал прогнозирования для Y может быть уменьшен при соответствующем значении X. Например, если ρ = 0,5, то 95% интервал прогнозирования Y | X будет быть примерно на 13% меньше 95% интервала прогноза Y.
Несколько авторов предложили рекомендации по интерпретации коэффициента корреляции. Однако все эти критерии в некотором смысле произвольны. Интерпретация коэффициента корреляции зависит от контекста и целей. Корреляция 0,8 может быть очень низкой, если кто-то проверяет физический закон с использованием высококачественных инструментов, но может считаться очень высокой в социальных науках, где может быть больший вклад усложняющих факторов.
Вывод
Статистический вывод, основанный на коэффициенте корреляции Пирсона, часто фокусируется на одной из следующих двух целей:
- Одна цель - проверить нулевую гипотезу о том, что истинная коэффициент корреляции ρ равен 0 на основе значения коэффициента корреляции выборки r.
- Другая цель состоит в том, чтобы вывести доверительный интервал, который при повторной выборке имеет заданную вероятность содержащего ρ.
Мы обсудим методы достижения одной или обеих этих целей ниже.
Использование теста перестановки
Тесты перестановки обеспечивают прямой подход к выполнению проверки гипотез и построению доверительных интервалов. Проверка перестановки для коэффициента корреляции Пирсона включает следующие два этапа:
- Используя исходные парные данные (x i, y i), случайным образом переопределите пары для создания новых данных set (x i, y i '), где i' является перестановкой набора {1,..., n}. Перестановка i 'выбирается случайным образом с равными вероятностями для всех n! возможные перестановки. Это эквивалентно отрисовке i ′ случайным образом без замены из набора {1,..., n}. В бутстрэппинге, тесно связанном подходе, i и i 'равны и выводятся с заменой из {1,..., n};
- Построить коэффициент корреляции r из рандомизированные данные.
Чтобы выполнить тест перестановки, повторите шаги (1) и (2) большое количество раз. p-значение для теста перестановки - это пропорция значений r, сгенерированных на этапе (2), которые больше, чем коэффициент корреляции Пирсона, который был рассчитан на основе исходных данных. Здесь «больше» может означать либо то, что значение больше по величине, либо больше по значению со знаком, в зависимости от того, требуется ли двусторонний или односторонний тест.
Использование бутстрапа
Бутстрап может использоваться для построения доверительных интервалов для коэффициента корреляции Пирсона. В «непараметрическом» бутстрапе n пар (x i, y i) повторно дискретизируются «с заменой» из наблюдаемого набора из n пар, а коэффициент корреляции r равен рассчитывается на основе данных повторной выборки. Этот процесс повторяется большое количество раз, и эмпирическое распределение повторно выбранных значений r используется для аппроксимации распределения выборки статистики. 95% доверительный интервал для ρ может быть определен как интервал, охватывающий от 2,5-го до 97,5-го процентиля повторно выбранных значений r.
Тестирование с использованием t-распределения Стьюдента
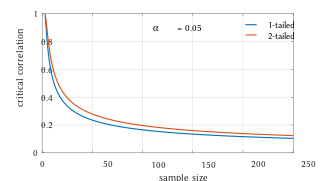
Критические значения коэффициента корреляции Пирсона, которые должны быть превышены, чтобы считаться значимо отличными от нуля на уровне 0,05.
Для пар из некоррелированного двумерного нормального распределения, выборочное распределение определенной функции коэффициента корреляции Пирсона следует t-распределению Стьюдента со степенями свободы n - 2. В частности, если базовые переменные белые и имеют двумерное нормальное распределение, переменная

имеет t-распределение Стьюдента в нулевом случае (нулевая корреляция). Это приблизительно справедливо в случае ненормальных наблюдаемых значений, если размеры выборки достаточно велики. Для определения критических значений r необходима обратная функция:

В качестве альтернативы можно использовать асимптотические подходы с большой выборкой.
В другой ранней статье представлены графики и таблицы для общих значений ρ для небольших размеров выборки и обсуждаются вычислительные подходы.
В случае, когда базовые переменные не белые, выборочное распределение коэффициента корреляции Пирсона следует t-распределению Стьюдента, но степени свободы уменьшены.
Использование точного распределения
Для данных, которые следуют двумерному нормальному распределению, точная функция плотности f (r) для выборочного коэффициента корреляции r нормального двумерного параметра равна

где  - гамма-функция и
- гамма-функция и  - гипергеометрическая функция Гаусса.
- гипергеометрическая функция Гаусса.
В особом случае когда  , точную функцию плотности f (r) можно записать как:
, точную функцию плотности f (r) можно записать как:

где  - это бета-функция, которая представляет собой один из способов записи плотности t-распределения Стьюдента, как указано выше.
- это бета-функция, которая представляет собой один из способов записи плотности t-распределения Стьюдента, как указано выше.
Использование преобразования Фишера
На практике доверительные интервалы и проверки гипотез, относящиеся к ρ, обычно выполняются с использованием преобразования Фишера.,  :
:

F (r) приблизительно следует нормальному распределению с
 и стандартная ошибка
и стандартная ошибка 
где n - размер выборки. Ошибка аппроксимации наименьшая для большого размера выборки и малого  и
и  и увеличивается в противном случае.
и увеличивается в противном случае.
Используя аппроксимацию, z-оценка равна
![z = {\ frac {x - {\ text {mean}}} {\ text {SE}}} = [F (r) -F (\ rho _ {0})] {\ sqrt {n-3 }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/da7a3d54a70f9005e3bf9a2accf62cbf0fa0ea71)
при нулевой гипотезе, что  , учитывая предположение, что пары выборок независимые и одинаково распределенные и следуют двумерному нормальному распределению. Таким образом, приблизительное p-значение может быть получено из нормальной таблицы вероятностей. Например, если наблюдается z = 2.2 и требуется двустороннее p-значение для проверки нулевой гипотезы о том, что
, учитывая предположение, что пары выборок независимые и одинаково распределенные и следуют двумерному нормальному распределению. Таким образом, приблизительное p-значение может быть получено из нормальной таблицы вероятностей. Например, если наблюдается z = 2.2 и требуется двустороннее p-значение для проверки нулевой гипотезы о том, что  , p-значение равно 2 · Φ (−2,2) = 0,028, где Φ - стандартная нормальная кумулятивная функция распределения.
, p-значение равно 2 · Φ (−2,2) = 0,028, где Φ - стандартная нормальная кумулятивная функция распределения.
Чтобы получить доверительный интервал для ρ, мы сначала вычисляем доверительный интервал для F ():
![{\ displaystyle 100 (1- \ alpha) \% {\ text {CI}}: \ operatorname {arctanh} (\ rho) \ in [\ operatorname { arctanh} (r) \ pm z _ {\ alpha / 2} {\ text {SE}}]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98ccdd57a6dba17340228d97aa9d37f00070c2f0)
Обратное преобразование Фишера возвращает интервал к шкале корреляции.
![{\ displaystyle 100 (1- \ alpha) \% {\ text {CI}}: \ rho \ in [\ operatorname {tanh} (\ operatorname {arctanh} (r) -z _ {\ alpha / 2} {\ text {SE}}), \ operatorname {tanh} (\ operatorname {arctanh} (r) + z _ {\ alpha / 2} {\ text {SE}})]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/068d979b7f0c30c080bf11249a2018addd71b067)
Например, предположим, что мы наблюдаем r = 0,3 с образцом размер n = 50, и мы хотим получить 95% доверительный интервал для ρ. Преобразованное значение - arctanh (r) = 0,30952, поэтому доверительный интервал на преобразованной шкале равен 0,30952 ± 1,96 / √47 или (0,023624, 0,595415). Возврат к шкале корреляции дает (0,024, 0,534).
В регрессионном анализе методом наименьших квадратов
Квадрат выборочного коэффициента корреляции обычно обозначается r и является частным случаем коэффициента детерминации. В этом случае он оценивает долю дисперсии Y, которая объясняется X в простой линейной регрессии. Итак, если у нас есть наблюдаемый набор данных  и подобранный набор данных
и подобранный набор данных  затем в качестве отправной точки общее изменение Y i вокруг их среднего значения можно разложить следующим образом:
затем в качестве отправной точки общее изменение Y i вокруг их среднего значения можно разложить следующим образом:

где  - это подогнанные значения из регрессионного анализа. Это можно изменить так, чтобы получить
- это подогнанные значения из регрессионного анализа. Это можно изменить так, чтобы получить

Два слагаемых выше представляют собой долю дисперсии в Y, которая объясняется X (справа), и это не объясняет X (слева).
Затем мы применяем свойство моделей регрессии по методу наименьших квадратов, согласно которому выборочная ковариация между и  равно нулю. Таким образом, можно записать выборочный коэффициент корреляции между наблюдаемыми и подобранными значениями отклика в регрессии (расчет не соответствует ожиданиям, предполагает гауссову статистику)
равно нулю. Таким образом, можно записать выборочный коэффициент корреляции между наблюдаемыми и подобранными значениями отклика в регрессии (расчет не соответствует ожиданиям, предполагает гауссову статистику)
![{\ displaystyle {\ begin {align} r (Y, {\ hat { Y}}) = {\ frac {\ sum _ {i} (Y_ {i} - {\ bar {Y} }) ({\ hat {Y}} _ {i} - {\ bar {Y}})} {\ sqrt {\ sum _ {i} (Y_ {i} - {\ bar {Y}}) ^ { 2} \ cdot \ sum _ {i} ({\ hat {Y}} _ {i} - {\ bar {Y}}) ^ {2}}}} \\ [6pt] = {\ frac {\ сумма _ {i} (Y_ {i} - {\ hat {Y}} _ {i} + {\ hat {Y}} _ {i} - {\ bar {Y}}) ({\ hat {Y} } _ {i} - {\ bar {Y}})} {\ sqrt {\ sum _ {i} (Y_ {i} - {\ bar {Y}}) ^ {2} \ cdot \ sum _ {i } ({\ hat {Y}} _ {i} - {\ bar {Y}}) ^ {2}}}} \\ [6pt] = {\ frac {\ sum _ {i} [(Y_ { i} - {\ hat {Y}} _ {i}) ({\ hat {Y}} _ {i} - {\ bar {Y}}) + ({\ hat {Y}} _ {i} - {\ bar {Y}}) ^ {2}]} {\ sqrt {\ sum _ {i} (Y_ {i} - {\ bar {Y}}) ^ {2} \ cdot \ sum _ {i} ({\ hat {Y}} _ {i} - {\ bar {Y}}) ^ {2}}}} \\ [6pt] = {\ frac {\ sum _ {i} ({\ hat { Y}} _ {i} - {\ bar {Y}}) ^ {2}} {\ sqrt {\ sum _ {i} (Y_ {i} - {\ bar {Y}}) ^ {2} \ cdot \ sum _ {i} ({\ hat {Y}} _ {i} - {\ bar {Y}}) ^ {2}}}} \\ [6pt] = {\ sqrt {\ frac {\ сумма _ {i} ({\ hat {Y}} _ {i} - {\ bar {Y}}) ^ {2}} {\ sum _ {i} (Y_ {i} - {\ bar {Y} }) ^ {2}}}}. \ End {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/d86595f3f77e8ee96952760d9176a5fa140cc562)
Таким образом,

. где
 - пропорция дисперсии по Y, объясняемая линейной функцией от X.
- пропорция дисперсии по Y, объясняемая линейной функцией от X.
В приведенном выше выводе, тот факт, что

можно доказать, заметив, что частные производные остаточной суммы квадратов (RSS) над β 0 и β 1 равны 0 в модели наименьших квадратов, где
 .
.
В конце концов, уравнение может записывается как:

где


Символ  называется регрессионной суммой квадратов, также называемой объясненной суммой квадратов, и
называется регрессионной суммой квадратов, также называемой объясненной суммой квадратов, и  : общая сумма квадратов (пропорциональна дисперсии данных).
: общая сумма квадратов (пропорциональна дисперсии данных).
Чувствительность к распределению данных
Существование
Популяционный коэффициент корреляции Пирсона определяется в терминах моментов и, следовательно, существует для любой двумерной переменной распределение вероятностей, для которого определена популяция ковариация и определены предельные дисперсии генеральной совокупности, которые не равны нулю. Некоторые распределения вероятностей, такие как распределение Коши, имеют неопределенную дисперсию, и, следовательно, ρ не определяется, если X или Y следуют такому распределению. В некоторых практических приложениях, например, в тех, где предполагается, что данные подчиняются распределению с тяжелым хвостом, это важное соображение. Однако наличие коэффициента корреляции обычно не вызывает беспокойства; например, если диапазон распределения ограничен, всегда определяется ρ.
Размер выборки
- Если размер выборки средний или большой, а генеральная совокупность нормальная, то в случае двумерного нормального распределения коэффициент корреляции выборки будет оценка максимального правдоподобия коэффициента корреляции совокупности, и является асимптотически несмещенным и эффективным, что примерно означает, что невозможно построить более точный
- Если размер выборки большой, а совокупность ненормальна, то коэффициент корреляции выборки остается примерно несмещенным, но может быть неэффективным.
- Если выборка размер большой, то выборочный коэффициент корреляции является согласованной оценкой коэффициента корреляции совокупности, пока выборочные средние, дисперсии и ковариация согласованы (что гарантируется, когда закон больших чисел может применяться).
- Если размер выборки небольшой, то sa Полный коэффициент корреляции r не является несмещенной оценкой ρ. Вместо этого следует использовать скорректированный коэффициент корреляции: см. Определение в другом месте этой статьи.
- Корреляции могут быть разными для несбалансированных дихотомических данных, если в выборке есть ошибка дисперсии.
Устойчивость
Как и многие часто используемые статистики, статистика выборки r не надежна, поэтому ее значение может вводить в заблуждение, если присутствуют выбросы. В частности, PMCC не является ни устойчивым с точки зрения распределения, ни устойчивостью к выбросам (см. Надежная статистика # Определение ). Проверка диаграммы разброса между X и Y обычно выявляет ситуацию, когда отсутствие устойчивости может быть проблемой, и в таких случаях может быть целесообразно использовать надежную меру ассоциации. Однако обратите внимание, что, хотя большинство надежных оценок ассоциации каким-то образом измеряют статистическую зависимость , они, как правило, не поддаются интерпретации в той же шкале, что и коэффициент корреляции Пирсона.
Статистический вывод для коэффициента корреляции Пирсона чувствителен к распределению данных. Точные тесты и асимптотические тесты, основанные на преобразовании Фишера, могут применяться, если данные приблизительно нормально распределены, но в противном случае могут вводить в заблуждение. В некоторых ситуациях бутстрап может применяться для построения доверительных интервалов, а тесты перестановки могут применяться для выполнения тестов гипотез. Эти непараметрические подходы могут дать более значимые результаты в некоторых ситуациях, когда двумерная нормальность не выполняется. Однако стандартные версии этих подходов полагаются на возможность обмена данных, что означает отсутствие упорядочения или группировки анализируемых пар данных, которые могли бы повлиять на поведение оценки корреляции.
Стратифицированный анализ - это один из способов либо учесть отсутствие двумерной нормальности, либо изолировать корреляцию, возникающую из-за одного фактора, с учетом другого. Если W представляет принадлежность к кластеру или другой фактор, который желательно контролировать, мы можем стратифицировать данные на основе значения W, а затем вычислить коэффициент корреляции в пределах каждой страты. Затем оценки на уровне страты могут быть объединены для оценки общей корреляции при контроле W.
Варианты
Вариации коэффициента корреляции могут вычисляться для различных целей. Вот несколько примеров.
Скорректированный коэффициент корреляции
Выборочный коэффициент корреляции r не является несмещенной оценкой ρ. Для данных, которые соответствуют двумерному нормальному распределению , математическое ожидание E [r] для выборочного коэффициента корреляции r нормальной двумерной переменной составляет
![{\ displaystyle \ operatorname {\ mathbb {E}} \ left [r \ right] = \ rho - {\ frac {\ rho \ left ( 1- \ rho ^ {2} \ right)} {2n}} + \ cdots, \ quad}](https://wikimedia.org/api/rest_v1/media/math/render/svg/683b838e709e3b32a3c22dfec4fa665a593f42ad) , поэтому r является смещенной оценкой
, поэтому r является смещенной оценкой 
Уникальная несмещенная оценка минимальной дисперсии r adj равна задано

где:
 определены, как указано выше,
определены, как указано выше,- - гипергеометрическая функция Гаусса.
Приблизительно несмещенная оценка r adj может быть получена путем усечения E [r] и решения этого усеченного уравнения:
![{\ displaystyle (2) \ qquad r = \ operatorname {\ mathbb {E}} [r] \ приблизительно r _ {\ text {adj}} - {\ frac {r _ {\ text {adj}} (1-r _ {\ text {adj}} ^ {2})} {2n }}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/356efd2f9fb8f8d5ca3e49ff49bca1b73f6efd63)
Приблизительное решение уравнения (2):
![{\ displaystyle (3) \ qquad r _ {\ text {adj}} \ приблизительно r \ left [1 + {\ frac {1-r ^ {2}} {2n}} \ right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/ffae18e6ffe588be6a1fb06552e4a5dd28b6a425)
где в (3):
- определены, как указано выше,
- radj - субоптимальная оценка,
- radj может также может быть получен путем максимизации log (f (r)),
- radj имеет минимальную дисперсию для больших значений n,
- radj имеет смещение порядка ⁄ (n - 1).
Другой предлагаемый скорректированный коэффициент корреляции:

Обратите внимание, что r adj ≈ r для больших значений n.
Взвешенный коэффициент корреляции
Предположим, что коррелируемые наблюдения имеют разную степень важности, которая может быть выражена с помощью весового вектора w. Чтобы вычислить корреляцию между векторами x и y с вектором весов w (все длины n),
- Средневзвешенное значение:



Коэффициент отражающей корреляции
Отражающая корреляция - это вариант корреляции Пирсона, при котором данные не центрируются вокруг их средних значений. Отражательная корреляция населения равна
![{\ displaystyle \ operatorname {corr} _ {r} (X, Y) = {\ frac {\ operatorname {\ mathbb {E}} [\, X \, Y \,]} {\ sqrt {\ operatorname {\ mathbb {E}} [\, X ^ {2} \,] \ cdot \ operatorname { \ mathbb {E}} [\, Y ^ {2} \,]}}}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6d897e4b303a062ed14cc9f88f35f5c8ffc91f7)
Отражательная корреляция симметрично, но не инвариантно относительно трансляции:

Примерная корреляция отражений эквивалентна косинусному сходству <530∑>rrixy (∑ xi 2) (∑ yi 2). {\ Displaystyle rr_ {xy} = {\ frac {\ sum x_ {i} y_ {i}} {\ sqrt {(\ sum x_ {i} ^ {2}) (\ sum y_ {i} ^ {2})}}}.}
Взвешенная версия выборки отражающей корреляции:

Масштабированный коэффициент корреляции
Масштабированная корреляция - это вариант корреляции Пирсона, в котором диапазон данных намеренно ограничен и контролируемым образом для выявления корреляции s между быстрыми компонентами во временном ряду. Масштабированная корреляция определяется как средняя корреляция между короткими сегментами данных.
Пусть  будет количеством сегментов, которые могут уместиться в общую длину сигнала
будет количеством сегментов, которые могут уместиться в общую длину сигнала  для данного масштаба
для данного масштаба  :
:

Масштабированная корреляция по всем сигналам  затем вычисляется как
затем вычисляется как

где  - коэффициент корреляции Пирсона для сегмента
- коэффициент корреляции Пирсона для сегмента  .
.
. При выборе параметра диапазон значений уменьшается, а корреляции на больших временных масштабах отфильтровываются, выявляются только корреляции на коротких временных масштабах. Таким образом, вклад медленных компонентов удаляется, а вклад быстрых компонентов сохраняется.
Расстояние Пирсона
Метрика расстояния для двух переменных X и Y, известная как расстояние Пирсона, может быть определена по их коэффициенту корреляции как

Учитывая, что коэффициент корреляции Пирсона находится между [-1, +1], расстояние Пирсона лежит в [0, 2 ]. Расстояние Пирсона использовалось в кластерном анализе и обнаружении данных для связи и хранения с неизвестным усилением и смещением
Коэффициент круговой корреляции
Для переменных X = {x 1,..., x n } и Y = {y 1,..., y n }, которые определены на единичный круг [0, 2π), можно определить круговой аналог коэффициента Пирсона. Это делается путем преобразования точек данных в X и Y с помощью функции sine таким образом, что коэффициент корреляции задается как:

где  и - это круговые средние X и Y. Эта мера может быть полезна в таких областях, как метеорология, где угловое направление данных важно.
и - это круговые средние X и Y. Эта мера может быть полезна в таких областях, как метеорология, где угловое направление данных важно.
Частичная корреляция
Если генеральная совокупность или набор данных характеризуются более чем двумя переменными, коэффициент частичной корреляции измеряет силу зависимости между парой переменных, которые не учитывается тем, как они оба изменяются в ответ на изменения в выбранном подмножестве других переменных.
Декорреляция n случайных величин
Всегда можно удалить корреляции между всеми парами произвольного числа случайных величин с помощью преобразования данных, даже если связь между переменными является нелинейной. Представление этого результата для распределений совокупности дано Cox Hinkley.
Соответствующий результат существует для уменьшения корреляций выборки до нуля. Предположим, что вектор из n случайных величин наблюдается m раз. Пусть X - матрица, где  - j-я переменная наблюдения i. Пусть
- j-я переменная наблюдения i. Пусть  будет квадратной матрицей размера m на m с каждым элементом 1. Тогда D - это данные, преобразованные так, что каждая случайная величина имеет нулевое среднее, и T - данные, преобразованные таким образом, что все переменные имеют нулевое среднее значение и нулевую корреляцию со всеми другими переменными - выборочная матрица корреляции для T будет единичной матрицей. Это должно быть дополнительно разделено на стандартное отклонение, чтобы получить единичную дисперсию. Преобразованные переменные не будут коррелированы, даже если они не могут быть независимыми.
будет квадратной матрицей размера m на m с каждым элементом 1. Тогда D - это данные, преобразованные так, что каждая случайная величина имеет нулевое среднее, и T - данные, преобразованные таким образом, что все переменные имеют нулевое среднее значение и нулевую корреляцию со всеми другими переменными - выборочная матрица корреляции для T будет единичной матрицей. Это должно быть дополнительно разделено на стандартное отклонение, чтобы получить единичную дисперсию. Преобразованные переменные не будут коррелированы, даже если они не могут быть независимыми.


где показатель степени - ⁄ 2 представляет квадратный корень матрицы из обратного матрицы. Корреляционная матрица T будет единичной матрицей. Если новое наблюдение данных x представляет собой вектор-строку из n элементов, то то же преобразование можно применить к x, чтобы получить преобразованные векторы d и t:


Эта декорреляция связана с анализом основных компонентов для многомерных данных.
Программные реализации
- R в статистическом пакете base-package реализует тест
cor.test (x, y, method = "pearson") в своей "stats "пакет (также cor (x, y, method =" pearson ")будет работать, но без возврата p-значения). Поскольку по умолчанию используется pearson, аргумент метода также может быть опущен. - Модуль статистических функций Python реализует тест
pearsonr (x, y) в своем " scipy.stats "и возвращает коэффициент корреляции r и p-значение как (r, p-value).
См. также
 Математический портал
Математический портал
Сноски
Ссылки
Внешние ссылки
- «кокор». comparingcorrelations.org. - бесплатный веб-интерфейс и пакет R для статистического сравнения двух зависимых или независимых корреляций с перекрывающимися или неперекрывающимися переменными.
- «Корреляция». nagysandor.eu. - интерактивное Flash-моделирование по корреляции двух нормально распределенных переменных.
- «Калькулятор коэффициентов корреляции». hackmath.net. Линейная регрессия. –
- «Критические значения для коэффициента корреляции Пирсона» (PDF). frank.mtsu.edu/~dkfuller.– большая таблица.
- «Угадай корреляцию».- игра, в которой игроки угадывают, насколько коррелированы две переменные на диаграмме рассеяния, чтобы получить лучшее понимание концепции корреляции.

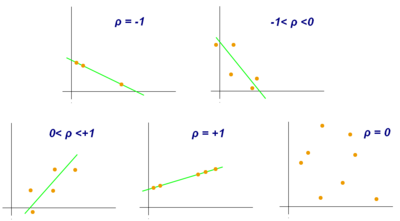 Примеры диаграмм разброса с разными значениями коэффициента корреляции (ρ)
Примеры диаграмм разброса с разными значениями коэффициента корреляции (ρ)  Несколько наборов (x, y) точек с коэффициентом корреляции x и y для каждого набора. Обратите внимание, что корреляция отражает силу и направление линейной связи (верхняя строка), но не наклон этой связи (в середине) и не многие аспекты нелинейных отношений (внизу). NB: фигура в центре имеет наклон 0, но в этом случае коэффициент корреляции не определен, потому что дисперсия Y равна нулю.
Несколько наборов (x, y) точек с коэффициентом корреляции x и y для каждого набора. Обратите внимание, что корреляция отражает силу и направление линейной связи (верхняя строка), но не наклон этой связи (в середине) и не многие аспекты нелинейных отношений (внизу). NB: фигура в центре имеет наклон 0, но в этом случае коэффициент корреляции не определен, потому что дисперсия Y равна нулю.  Линии регрессии для y = g X (x) [ красный] и x = g Y (y) [синий]
Линии регрессии для y = g X (x) [ красный] и x = g Y (y) [синий]  Этот рисунок дает представление о том, как полезность корреляции Пирсона для прогнозирования значений зависит от ее величины. Учитывая совместно нормальные X, Y с корреляцией ρ,
Этот рисунок дает представление о том, как полезность корреляции Пирсона для прогнозирования значений зависит от ее величины. Учитывая совместно нормальные X, Y с корреляцией ρ,  Критические значения коэффициента корреляции Пирсона, которые должны быть превышены, чтобы считаться значимо отличными от нуля на уровне 0,05.
Критические значения коэффициента корреляции Пирсона, которые должны быть превышены, чтобы считаться значимо отличными от нуля на уровне 0,05.