 Закон Окуня
Закон Окуня в
макроэкономике является примером простой линейной регрессии. Здесь предполагается, что зависимая переменная (рост ВВП) находится в линейной зависимости от изменений уровня безработицы.
В статистике, простая линейная регрессия - это модель линейной регрессии с единственной независимой переменной. То есть он касается двумерных точек выборки с одной независимой переменной и одной зависимой переменной (обычно координаты x и y в декартовой системе координат ) и находит линейную функцию ( невертикальная прямая ), которая с максимально возможной точностью предсказывает значения зависимой переменной как функцию независимой переменной. Прилагательное просто относится к тому факту, что переменная результата связана с одним предиктором.
Обычно делается дополнительное условие, что следует использовать метод наименьших квадратов (OLS): точность каждого предсказанного значения измеряется его квадратом невязки (расстояние по вертикали между точкой набора данных и подобранной линией), и цель состоит в том, чтобы как можно меньше сумма этих квадратов отклонений. Другие методы регрессии, которые можно использовать вместо обычных наименьших квадратов, включают наименьших абсолютных отклонений (минимизация суммы абсолютных значений остатков) и оценка Тейла – Сена (которая выбирает линию наклон которого представляет собой медиана наклонов, определенных парами точек выборки). Регрессия Деминга (суммарные наименьшие квадраты) также находит линию, которая соответствует набору двумерных точек выборки, но (в отличие от обычных наименьших квадратов, наименьших абсолютных отклонений и регрессии среднего наклона) на самом деле это не пример простой линейной регрессии, потому что она не разделяет координаты на одну зависимую и одну независимую переменные и потенциально может вернуть вертикальную линию как подходящую.
Остальная часть статьи предполагает обычную регрессию наименьших квадратов. В этом случае наклон подобранной линии равен корреляции между y и x, скорректированной на отношение стандартных отклонений этих переменных. Пересечение подобранной линии таково, что линия проходит через центр масс (x, y) точек данных.
Содержание
- 1 Подгонка линии регрессии
- 1.1 Интуитивное объяснение
- 1.2 Простая линейная регрессия без члена пересечения (единственный регрессор)
- 2 Числовые свойства
- 3 Свойства на основе модели
- 3.1 Беспристрастность
- 3.2 Доверительные интервалы
- 3.3 Допущение нормальности
- 3.4 Асимптотическое предположение
- 4 Числовой пример
- 5 См. Также
- 6 Ссылки
- 7 Внешние ссылки
Подгонка линии регрессии
Рассмотрим функцию модели

, которая описывает линию с наклоном β и y-пересечение α. В общем, такая взаимосвязь может не соблюдаться в точности для большей части ненаблюдаемой совокупности значений независимых и зависимых переменных; мы называем ненаблюдаемые отклонения от приведенного выше уравнения ошибками. Предположим, мы наблюдаем n пар данных и называем их {(x i, y i), i = 1,..., n}. Мы можем описать лежащую в основе взаимосвязь между y i и x i с использованием этого члена ошибки ε i как

Эта связь между истинными (но ненаблюдаемыми) базовыми параметрами α и β и точками данных называется модель линейной регрессии.
Цель состоит в том, чтобы найти оценочные значения  и
и  для параметров α и β, которые в некотором смысле обеспечат "наилучшее" соответствие для точек данных. Как упоминалось во введении, в этой статье «наилучшее» соответствие будет пониматься как подход наименьших квадратов : линия, которая минимизирует сумму квадратов остатков
для параметров α и β, которые в некотором смысле обеспечат "наилучшее" соответствие для точек данных. Как упоминалось во введении, в этой статье «наилучшее» соответствие будет пониматься как подход наименьших квадратов : линия, которая минимизирует сумму квадратов остатков  (различия между фактическими и прогнозируемыми значениями зависимой переменной y), каждое из которых задается для любых значений параметров-кандидатов
(различия между фактическими и прогнозируемыми значениями зависимой переменной y), каждое из которых задается для любых значений параметров-кандидатов  и
и  ,
,

Другими словами, и решают следующую задачу минимизации:

Расширяя, чтобы получить квадратичное выражение в и  мы можем получить значения и , которые минимизировать целевую функцию Q (эти минимизирующие значения обозначаются и ):
мы можем получить значения и , которые минимизировать целевую функцию Q (эти минимизирующие значения обозначаются и ):
![{\ displaystyle {\ begin {align} {\ widehat {\ alpha}} = {\ bar {y}} - {\ widehat {\ beta}} \, {\ bar {x}}, \\ [5pt] {\ widehat {\ beta}} = {\ frac {\ sum _ {i = 1} ^ {n} (x_ {i} - {\ bar {x}}) (y_ {i} - {\ bar {y}})} {\ sum _ {i = 1} ^ {n} (x_ {i} - {\ bar {x}}) ^ {2}}} \\ [6pt] = {\ frac {s_ {x, y}} {s_ {x} ^ {2}}} \\ [5pt] = r_ {xy} {\ frac {s_ {y}} {s_ {x}}}. \\ [6pt] \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/944e96221f03e99dbd57290c328b205b0f04c803)
Здесь мы ввели
 и
и  как среднее значение x i и y i, соответственно
как среднее значение x i и y i, соответственно- rxyкак выборочная корреляция коэффициент между x и y
- sxи s y как нескорректированные стандартные отклонения выборки x и y
 и
и  как выборочная дисперсия и выборочная ковариация соответственно
как выборочная дисперсия и выборочная ковариация соответственно
Подставив приведенные выше выражения для и в

дает

Это показывает, что r xy - это наклон линии регрессии для стандартизованных точек данных (и что эта линия проходит через начало координат).
Обобщая нотацию , мы можем написать горизонтальную полосу над выражением, чтобы указать среднее значение этого выражения за набор образцов. Например:

Это обозначение позволяет нам краткая формула для r xy:

Коэффициент детерминации ("R в квадрате") равен  , когда модель линейна с единственной независимой переменной. См. коэффициент корреляции образца для получения дополнительных сведений.
, когда модель линейна с единственной независимой переменной. См. коэффициент корреляции образца для получения дополнительных сведений.
Интуитивное объяснение
Умножением всех элементов суммирования в числителе на:  (тем самым не меняя его):
(тем самым не меняя его):
![{\ displaystyle {\ begin {align} {\ widehat {\ бета}} = {\ frac {\ sum _ {i = 1} ^ {n} (x_ {i} - {\ bar {x}}) (y_ {i} - {\ bar {y}})} {\ sum _ {i = 1} ^ {n} (x_ {i} - {\ bar {x}}) ^ {2}}} = {\ frac {\ sum _ {i = 1} ^ {n} (x_ {i} - {\ bar {x}}) ^ {2} * {\ frac {(y_ {i} - {\ bar {y}})} {(x_ {i} - {\ bar {x }})}}} {\ sum _ {i = 1} ^ {n} (x_ {i} - {\ bar {x}}) ^ {2}}} \\ [6pt] \ end {align}} }](https://wikimedia.org/api/rest_v1/media/math/render/svg/e1ac1b7ef40d1c91a192327f20ae7ca88f4c4d37)
Мы видим, что наклон (тангенс угла) линии регрессии представляет собой средневзвешенное значение  это наклон (тангенс угла) линия, соединяющая i-ю точку со средним значением всех точек, взвешенная по
это наклон (тангенс угла) линия, соединяющая i-ю точку со средним значением всех точек, взвешенная по  , потому что чем дальше точка, тем она «важнее», потому что небольшие ошибки в ее положении меньше влияют на уклон, соединяющий ее с центральной точкой.
, потому что чем дальше точка, тем она «важнее», потому что небольшие ошибки в ее положении меньше влияют на уклон, соединяющий ее с центральной точкой.
![{\ displaystyle {\ begin {align} {\ widehat {\ alpha}} = {\ bar {y}} - {\ widehat {\ beta}} \, {\ bar {x}}, \\ [5pt] \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e5ec3259ace40cc2734621fc00464bc5b87bc3fc)
Учитывая  с
с  угол, под которым линия образует положительную ось x, мы имеем
угол, под которым линия образует положительную ось x, мы имеем 
Простая линейная регрессия без члена пересечения (единственный регрессор)
Иногда это подходит для принудительного прохождения линии регрессии через начало координат, поскольку предполагается, что x и y пропорциональны. Для модели без члена пересечения, y = βx, МНК-оценка для β упрощается до

Подстановка (x - h, y - k) вместо (x, y) дает регрессию через (h, k):
![{\ displaystyle {\ begin {align} {\ widehat {\ beta}} = {\ frac {\ overline {(xh) ( yk)}} {\ overline {(xh) ^ {2}}}} \\ [6pt] = {\ frac {{\ overline {xy}} - k {\ bar {x}} - h {\ bar {y}} + hk} {{\ overline {x ^ {2}}} - 2h {\ bar {x}} + h ^ {2}}} \\ [6pt] = {\ frac {{\ overline {xy}} - {\ bar {x}} {\ bar {y}} + ({\ bar {x}} - h) ({\ bar {y}} - k)} {{\ overline {x ^ {2}}} - {\ bar {x}} ^ {2} + ({\ bar {x}} - h) ^ {2}}} \\ [6pt] = {\ frac {\ operatorname {Cov } (x, y) + ({\ bar {x}} - h) ({\ bar {y}} - k)} {\ operatorname {Var} (x) + ({\ bar {x}} - h) ^ {2}} }, \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/79ac025da33096bef180900c9a0bf37ab356900b)
где Cov и Var относятся к ковариации и дисперсии выборочных данных (без поправки на смещение).
Последняя форма выше демонстрирует, как перемещение линии от центра масс точек данных влияет на наклон.
Числовые свойства
- Линия регрессии проходит через точку центра масс,
 , если модель включает член перехвата (т. е. не принудительно проходит через начало координат).
, если модель включает член перехвата (т. е. не принудительно проходит через начало координат). - Сумма остатков равна нулю, если модель включает член перехвата:

- остатки и значения x не коррелированы (независимо от того, есть ли в модели перехватывающий член), что означает:

Свойства на основе модели
Описание статистических свойств оценщиков простой линейной регрессии оценки требует использования статистической модели . Следующее основано на предположении о применимости модели, при которой оценки являются оптимальными. Также возможно оценить свойства при других предположениях, таких как неоднородность, но это обсуждается в другом месте.
Беспристрастность
Оценки и беспристрастны.
Формализовать В этом утверждении мы должны определить структуру, в которой эти оценки являются случайными величинами. Мы рассматриваем остатки ε i как случайные величины, полученные независимо от некоторого распределения с нулевым средним. Другими словами, для каждого значения x соответствующее значение y генерируется как средний отклик α + βx плюс дополнительная случайная величина ε, называемая членом ошибки, равная в среднем нулю. При такой интерпретации оценки методом наименьших квадратов и сами будут случайными величинами, средние значения которых будут равны «истинным значениям» α и β. Это определение беспристрастной оценки.
Доверительные интервалы
Формулы, приведенные в предыдущем разделе, позволяют вычислить точечные оценки α и β, то есть коэффициенты линии регрессии для данного набора данных. Однако эти формулы не говорят нам, насколько точны оценки, т.е. сколько оценок и варьируются от образца к образцу для указанного размера выборки. Доверительные интервалы были разработаны, чтобы дать правдоподобный набор значений для оценок, которые можно было бы получить, если повторить эксперимент очень большое количество раз.
Стандартный метод построения доверительных интервалов для коэффициентов линейной регрессии основывается на предположении нормальности, которое оправдано, если:
- ошибки в регрессии нормально распределены (так- называется классическим предположением регрессии), или
- количество наблюдений n достаточно велико, и в этом случае оценка приблизительно нормально распределена.
Последний случай оправдан центральной предельной теоремой.
Предположение о нормальности
При первом предположении, приведенном выше, о нормальности членов ошибки, оценка коэффициента наклона сама будет нормально распределена со средним β и дисперсией  где σ - дисперсия ошибочных членов (см. Доказательства с использованием обычных наименьших квадратов ). При этом сумма квадратов остатков Q распределяется пропорционально χ с n - 2 степенями свободы и независимо от . Это позволяет нам построить значение t
где σ - дисперсия ошибочных членов (см. Доказательства с использованием обычных наименьших квадратов ). При этом сумма квадратов остатков Q распределяется пропорционально χ с n - 2 степенями свободы и независимо от . Это позволяет нам построить значение t

где

- стандартная ошибка оценщика. .
Это значение t имеет t Стьюдента - распределение с n - 2 степенями свободы. Используя его, мы можем построить доверительный интервал для β:
![{\ displaystyle \ beta \ in \ left [{\ widehat {\ beta}} -s _ {\ widehat {\ beta}} t_ {n-2} ^ {*}, \ {\ widehat {\ beta}} + s _ {\ widehat {\ beta}} t_ {n-2} ^ {*} \ right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/98a15da255d6643725a6bd9b50d02b3f6c2c497f)
на уровне достоверности (1 - γ), где  - это
- это  квантиль распределения t n − 2. Например, если γ = 0,05, то уровень достоверности составляет 95%.
квантиль распределения t n − 2. Например, если γ = 0,05, то уровень достоверности составляет 95%.
Аналогичным образом доверительный интервал для коэффициента пересечения α определяется как
![{\ displaystyle \ alpha \ in \ left [{\ widehat {\ alpha}} - s _ {\ widehat {\ alpha}} t_ {n-2} ^ {*}, \ {\ widehat {\ alpha}} + s _ {\ widehat {\ alpha}} t_ {n-2} ^ {*} \ right],}](https://wikimedia.org/api/rest_v1/media/math/render/svg/6085d0ecef794ef2f78a3d3e0f9802acb9a4aada)
на уровне достоверности (1 - γ), где

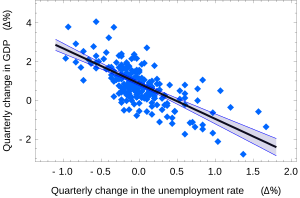
Американская регрессия «изменения безработицы - рост ВВП» с 95% доверительными диапазонами.
Доверительные интервалы для α и β дают нам общее представление где эти коэффициенты регрессии наиболее вероятны. Например, в приведенной здесь регрессии закона Окуня точечные оценки равны

95% доверительный интервал для этих оценок:
![{\ displaystyle \ alpha \ in \ left [\, 0.76,0.96 \ right], \ qquad \ beta \ in \ left [-2.06, -1.58 \, \ right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/aca739a7d1ecc8fdddffbdea549b9acba00b464d)
Для графического представления этой информации, в виде доверительных полос вокруг линии регрессии, нужно действовать осторожно и учитывать совместное распределение оценок. Можно показать, что на уровне достоверности (1 - γ) доверительный интервал имеет гиперболический вид, задаваемый уравнением
![{\ displaystyle (\ alpha + \ beta \ xi) \ in \ left [\, {\ widehat {\ alpha}} + {\ widehat {\ beta}} \ xi \ pm t_ {n-2} ^ {*} {\ sqrt {\ left ({\ frac {1} {n-2}} \ sum {\ widehat {\ varepsilon}} _ {i} ^ {\, 2} \ справа) \ cdot \ left ({\ frac {1} {n}} + {\ frac {(\ xi - {\ bar {x}}) ^ {2}} {\ sum (x_ {i} - {\ bar {x}) }) ^ {2}}} \ right)}} \, \ right].}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7007e876b527e8f59c394898488fd150df4b9f61)
Асимптотическое предположение
Альтернативное второе предположение гласит, что когда количество точек в наборе данных «достаточно велико», закон больших чисел и центральная предельная теорема становятся применимыми, и тогда распределение оценок становится приблизительно нормальным. При этом предположении все формулы, полученные в предыдущем разделе, остаются в силе, за единственным исключением, что квантиль t * n − 2 распределения Стьюдента t заменяется квантилем q * стандартное нормальное распределение. Иногда дробь 1 / n − 2 заменяется на 1 / n. При большом n такое изменение существенно не меняет результаты.
Числовой пример
Этот набор данных дает среднюю массу тела женщин как функцию их роста в выборке американских женщин в возрасте 30–39 лет. Хотя в статье OLS утверждается, что для этих данных было бы более подходящим запустить квадратичную регрессию, здесь вместо этого применяется простая модель линейной регрессии.
| Высота (м), x i | 1,47 | 1,50 | 1,52 | 1,55 | 1,57 | 1,60 | 1,63 | 1,65 | 1,68 | 1,70 | 1,73 | 1,75 | 1,78 | 1.80 | 1,83 |
|---|
| Масса (кг), y i | 52,21 | 53,12 | 54,48 | 55,84 | 57,20 | 58,57 | 59,93 | 61,29 | 63,11 | 64,47 | 66,28 | 68,10 | 69,92 | 72,19 | 74,46 |
|---|
 |  |  |  |  |  |
|---|
| 1 | 1.47 | 52.21 | 2.1609 | 76.7487 | 2725.8841 |
| 2 | 1.50 | 53,12 | 2.2500 | 79.6800 | 2821.7344 |
| 3 | 1.52 | 54.48 | 2.3104 | 82.8096 | 2968.0704 |
| 4 | 1.55 | 55.84 | 2.4025 | 86.5520 | 3118.1056 |
| 5 | 1.57 | 57.20 | 2.4649 | 89.8040 | 3271.8400 |
| 6 | 1.60 | 58.57 | 2.5600 | 93.7120 | 3430.4449 |
| 7 | 1.63 | 59.93 | 2.6569 | 97.6859 | 3591.6049 |
| 8 | 1.65 | 61.29 | 2.7225 | 101.1285 | 3756.4641 |
| 9 | 1.68 | 63.11 | 2.8224 | 106.0248 | 3982.8721 |
| 10 | 1.70 | 64.47 | 2.8900 | 109.5990 | 4156.3809 |
| 11 | 1.73 | 66.28 | 2.9929 | 114.6644 | 4393.0384 |
| 12 | 1.75 | 68.10 | 3.0625 | 119.1750 | 4637.6100 |
| 13 | 1,78 | 69.92 | 3.1684 | 124.4576 | 4888.8064 |
| 14 | 1.80 | 72.19 | 3.2400 | 129.9420 | 5211.3961 |
| 15 | 1.83 | 74.46 | 3.3489 | 136.2618 | 5544.2916 |
 | 24,76 | 931.17 | 41.0532 | 1548.2453 | 58498.5439 |
В этом наборе данных n = 15 точек. Ручные вычисления будут начаты с нахождения следующих пяти сумм:
![{\ displaystyle {\ begin {align} S_ {x} = \ sum x_ {i} \, = 24.76, \ qquad S_ {y} = \ sum y_ {i} \, = 931.17, \\ [5pt] S_ {xx} = \ sum x_ {i} ^ {2 } = 41,0532, \; \; \, S_ {yy} = \ sum y_ {i} ^ {2} = 58498,5439, \\ [5pt] S_ {xy} = \ sum x_ {i} y_ {i} = 1548.2453 \ конец {выровненный}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a239d81a6a9897b666146526c8252a18d2603adf)
Эти величины будут использоваться для вычисления оценок коэффициентов регрессии и их стандартных ошибок.
![{\ displaystyle {\ begin {align} {\ widehat {\ beta}} = { \ frac {nS_ {xy} -S_ {x} S_ {y}} {nS_ {xx} -S_ {x} ^ {2}}} = 61,272 \\ [8pt] {\ widehat {\ alpha}} = {\ frac {1} {n}} S_ {y} - {\ widehat {\ beta}} {\ frac {1} {n}} S_ {x} = - 39,062 \\ [8pt] s _ {\ varepsilon} ^ {2} = {\ frac {1} {n (n-2)}} \ left [nS_ {yy} -S_ {y} ^ {2} - {\ widehat {\ beta}} ^ {2} (nS_ {xx} -S_ {x} ^ {2}) \ right] = 0,5762 \\ [8pt] s _ {\ widehat {\ beta}} ^ {2} = {\ frac {ns _ {\ varepsilon} ^ {2}} {nS_ {xx} -S_ {x} ^ {2}}} = 3,1539 \\ [8pt] s _ {\ widehat {\ alpha}} ^ {2} = s _ {\ widehat {\ beta} } ^ {2} {\ frac {1} {n}} S_ {xx} = 8.63185 \ end {align}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/1c171ecde06fcbcb38ea0c3e080b7c14efcfdd96)
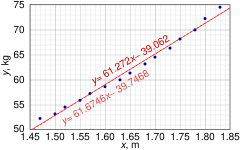
График точек и линий наименьших квадратов в числовом примере простой линейной регрессии
Квантиль t-распределения Стьюдента 0,975 с 13 степенями свободы равен t 13 = 2,1604, и, таким образом, 95% доверительные интервалы для α и β равны
![{\ displaystyle {\ begin {align} \ alpha \ in [\, {\ widehat {\ alpha}} \ mp t_ {13} ^ {*} s _ {\ alpha} \,] = [\, {- 45.4}, \ {-32.7} \,] \\ [5pt] \ beta \ in [\, {\ widehat {\ beta}} \ mp t_ {13} ^ {*} s _ {\ бета} \,] = [\, 57.4, \ 65.1 \,] \ конец {выровнено}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f1e96281c93edfc8cb8e830744328f62081c8010)
Также можно вычислить коэффициент корреляции продукт-момент :

Этот пример также демонстрирует, что сложные вычисления не преодолеть использование плохо подготовленных данных. Первоначально высота была дана в дюймах и была преобразована в ближайший сантиметр. Поскольку преобразование привело к ошибке округления, это не точное преобразование. Исходные дюймы можно восстановить с помощью функции Round (x / 0,0254), а затем повторно преобразовать в метрическую систему без округления: если это будет сделано, результаты станут

Таким образом, кажущееся небольшое изменение данных имеет реальный эффект.
См. Также
Ссылки
Внешние ссылки

 Закон Окуня в макроэкономике является примером простой линейной регрессии. Здесь предполагается, что зависимая переменная (рост ВВП) находится в линейной зависимости от изменений уровня безработицы.
Закон Окуня в макроэкономике является примером простой линейной регрессии. Здесь предполагается, что зависимая переменная (рост ВВП) находится в линейной зависимости от изменений уровня безработицы.  Американская регрессия «изменения безработицы - рост ВВП» с 95% доверительными диапазонами.
Американская регрессия «изменения безработицы - рост ВВП» с 95% доверительными диапазонами.  График точек и линий наименьших квадратов в числовом примере простой линейной регрессии
График точек и линий наименьших квадратов в числовом примере простой линейной регрессии