В статистика, эконометрика, эпидемиология и т.п. дисциплин, метод инструментальных чисел (IV) используется для оценки причинно-следственных связей, когда контролируемые эксперименты неосуществимы или когда лечение проводится успешно в каждом подразделении в рандомизированном эксперименте. Интуитивно IV используется, когда интересующаянезависимая переменная коррелирует с термином ошибки, и в этом случае обычный метод наименьших квадратов и ANOVA дает смещенные результаты. Действующий инструмент, влияющий на зависимую переменную, позволяющий исследователю выявить влияющую на зависимую переменную.
Методы инструментальных чисел позволяют выполнять согласованную оценку, когда независимые переменные (ковариаты) коррелированы с ошибками в регрессионноймодели . Такая корреляция может иметь место, когда:
- изменения в зависимой переменной изменяют значение по крайней мере одной из ковариат («обратная» причинность),
- есть пропущенные переменные, которые влияют на зависимые переменные,
- ковариаты подвержены неслучайной ошибке измерения.
Объясняющие переменные, которые страдают от одной или нескольких проблем в контексте регрессии, иногда называют эндогенной. В этой ситуацииобычный метод наименьших квадратов дает смещенные и непоследовательные оценки. Однако при наличии инструмента согласованные оценки все же могут быть получены. Инструмент - это переменная, которая сама по себе не входит в объясняющее уравнение, но коррелирует с эндогенными объясняющими переменными, при условии, что значения других ковариант.
В независимых моделях есть два основных требования для использования IV:
- Инструмент должен быть коррелирован сэндогеннымипеременными, при условии, что другие ковариаты. Если эта корреляция сильная, то говорят, что инструмент имеет сильную первую стадию . Слабая корреляция может привести к ошибочным выводам оценкам параметров и стандартных ошибок.
- Инструмент не может быть коррелирован с ошибкой в пояснительном уравнении, при условии, что другие ковариаты. Другими словами, инструмент не может иметь тех же проблем, что и исходная прогнозирующая переменная. Если это условиевыполнено, считается,что прибор удовлетворяет ограничению исключения .
Содержание
- 1 Введение
- 2 Пример
- 3 Графическое определение
- 3.1 Выбор подходящих инструментов
- 4 Оценка
- 5 Интерпретация двухэтапным методом наименьших квадратов
- 6 Непараметрический анализ
- 7 Интерпретация в условиях неоднородности воздействия лечения
- 8 Проблема слабых инструментов
- 8.1 Тестирование слабых инструментов
- 9 Статистический вывод и проверка гипотез
- 10Проверка ограниченияисключения
- 11 Применение к моделям со случайными и фиксированными эффектами
- 12 Методы для обобщенных линейных моделей
- 12.1 Пуассоновская регрессия
- 13 См. также
- 14 Ссылки
- 15 Дополнительная литература
- 16 Библиография
- 17 Ссылки
Введение
Концепция инструментальных постоянно получена Филипом Дж. Райтом, возможно, в соавторстве со своим сыном Сьюэлл Райт, в контексте одинаковых уравнений в егокниге 1928 года Тариф«Животные и растительные масла». В 1945 году Олав Рейерсол применил тот же подход в контексте моделей ошибок в том числе в своей диссертации, назвав этот метод своим именем.
Хотя идеи за IV распространяется на широкий класс моделей, очень распространенным контекстом для IV является линейная регрессия. Традиционно инструментальная переменная определяет как переменная Z, которая коррелирована с независимой переменной X и коррелирована с «членомошибки» U в линейномуравнении

 - вектор.
- вектор.  - матрица, обычно со столбцами и, возможно, дополнительными столбцами для других ковариат. Рассмотрим, как инструмент позволяет восстановить
- матрица, обычно со столбцами и, возможно, дополнительными столбцами для других ковариат. Рассмотрим, как инструмент позволяет восстановить  . Напомним, что OLS решает для
. Напомним, что OLS решает для  такое, что
такое, что  (когда мы минимизируем сумму квадратов ошибок,
(когда мы минимизируем сумму квадратов ошибок,  , условие первого порядка в точности равно
, условие первого порядка в точности равно  .) Если признана истинная модель имеет
.) Если признана истинная модель имеет  по любому из причин, перечисленных выше, например, если существует пропущенная переменная, которая влияет на оба и по отдельной - тогда эта процедура OLS не приведет к кному влиянию на . OLS просто выберет параметр, который заставляет результирующие ошибки казаться некоррелированнымис .
по любому из причин, перечисленных выше, например, если существует пропущенная переменная, которая влияет на оба и по отдельной - тогда эта процедура OLS не приведет к кному влиянию на . OLS просто выберет параметр, который заставляет результирующие ошибки казаться некоррелированнымис .
. Рассмотрим для простоты случай с одной типовой. Предположим, мы рассматриваем регрессию с той же константой (возможно, никакие другие ковариаты не нужны, или, возможно, мы частично исключили любые другие соответствующие ковариаты):

В этом случае коэффициент на интересующем регрессоре равенстве  . Замена на
. Замена на  дает
дает
![{\ displaystyle {\ begin{align} {\ widehat {\ beta}} = {\ frac {\ operatorname {cov} ( x, y)} {\ operatorname {var} (x)}} = {\ frac {\ operatorname {cov} (x, \ alpha + \ beta x + u)} {\ operatorname {var} (x)}} \\ [6pt] = {\ frac {\ operatorname {cov} (x, \ alpha + \beta x)} {\ operatorname {var} (x)}} + {\ frac {\ operatorname {cov} (x, u)} {\ operatorname {var} (x)}} = \ beta ^ {*} + {\ frac {\ operatorname {cov} (x, u)}{\ operatorname {var} (х)}}, \ конец {выровнено}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c0fa71a1544a7e0714dae657ee944feb5cc4a02a)
где  - это то, чем был бы оценочный коэффициент коэффициентов, если бы x не коррелировал с u. В этом случае можно показать, что являетсянесмещенной оцененной
- это то, чем был бы оценочный коэффициент коэффициентов, если бы x не коррелировал с u. В этом случае можно показать, что являетсянесмещенной оцененной  Если
Если  в Базовая модель, в которую мы верим, то OLS дает коэффициент, который не отражает лежащий в основе эффекта интереса. IV помогает решить эту проблему, определяя параметры
в Базовая модель, в которую мы верим, то OLS дает коэффициент, который не отражает лежащий в основе эффекта интереса. IV помогает решить эту проблему, определяя параметры  не в зависимости от,
не в зависимости от,  не коррелирует с
не коррелирует с  , но зависит от того, некоррелирует ли другую переменную
, но зависит от того, некоррелирует ли другую переменную  с . Если теория предполагает, что связано с (первая стадия), но не коррелирует с (ограничение исключения), тогда IV может идентифицировать интересующий причинный параметр, когда OLS не работает. Существует несколько способов использования оценок IV даже влинейном случае (IV, 2SLS, GMM), мы сохраняем дальнейшее обсуждение для раздела Оценка ниже.
с . Если теория предполагает, что связано с (первая стадия), но не коррелирует с (ограничение исключения), тогда IV может идентифицировать интересующий причинный параметр, когда OLS не работает. Существует несколько способов использования оценок IV даже влинейном случае (IV, 2SLS, GMM), мы сохраняем дальнейшее обсуждение для раздела Оценка ниже.
Пример
Неформально, испытать влияние одной X на другую Y, инструментальное влияние на Y, которое влияет на Y только через свое на X. Например, Предположим, исследователь хочет испытать влияние на Y только через свое влияние на X. оценить влияние курения на общее состояние здоровья. Корреляция между здоровьем и курением означает, что курение вызывает здоровье, потому чтоэто может влиять на здоровье, так ина курение, потому что это может влиять на курение. В лучшем случае и дорого проводят контролируемые эксперименты по изучению статуса курения среди населения в целом. Исследователь может попытаться оценить влияние курения на здоровье на основе наблюдений, используя налоги на табачные изделия в качестве инструмента для курения. Ставка налога на табачные изделия - разумный выбор для инструмента, поскольку исследователь предполагает, что ее можно соотнести создоровьем через ее влияние на курение.Если исследователь обнаружит, это можно рассматривать как доказательство того, что курение вызывает изменения в здоровье.
Angrist и Krueger (2001) представляют обзор истории и использования методов инструментальных чисел.
Графическое определение
Конечно, методы IV были разработаны среди гораздо более широкого класса нелинейных моделей. Общие определения инструментальных средств с использованием контрфактического играфического формализма были даны Перлом (Pearl, 2000; с. 248). Графическое определение требует, чтобы удовлетворить следующие условия:

где  означает d-разделение и
означает d-разделение и  обозначает график, накотором все стрелки, входящие в X, обрезаны.
обозначает график, накотором все стрелки, входящие в X, обрезаны.
Контрфактическое определение требует, чтобы удовлетворяла

где Y x обозначает значение, которое Y получил бы, если бы X был x и означает независимость.
Если есть дополнительные ковариаты W, то приведенные выше определениямодифицируются так, что Z квалифицируется как инструмент,если данные выполняются условно на W.
Суть определения Перла такова:
- Представляющие интересующие уравнения являются «Структурными», а не «регрессионными».
- Параметр ошибки U обозначает все внешние факторы, влияющие на Y, когда X остается постоянным.
- Инструмент Z должен быть независимым от U.
- Инструмент Z не должен влиять на Y, когда X остается постоянным (ограничение исключения).
- Инструмент Z не должен быть независимым от X.
Эти условияне зависят от конкретной формулы функциональной и применимы к нелинейным уравнениям, где U может быть неаддитивным (см. Непараметрический анализ). Они также применимы к системе местного использования, в которой X (и другие факторы) влияют на Y через несколько промежуточных чисел. Инструментальная переменная не должна обязательно быть причиной X; может также доверить доверенное лицо такой причины, если оно удовлетворяет условиям 1-5.Ограничение исключения (условие 4) является избыточным; этоследует из условий 2 и 3.
Выбор подходящих инструментов
Временное положение не требуется, чтобы Z не зависело от U, не может быть выведено из структур модели, т.е. процесс генерации данных. Причинно-следственные диаграммы представляют эту структуру, и приведенное выше графическое определение можно использовать для быстрого определения, чтобы получить квалифицирующую переменную Z как инструментальнуюпеременную с учетом набора ковариат W. увидеть, как это сделать,рассмотрим следующий пример.
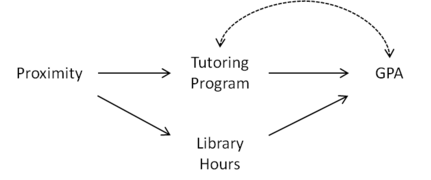
Рисунок 1: Близость квалифицируется как инструментальная переменная с учетом часов библиотеки

Рисунок 2: , который используется для определения является ли близость инструментальной альтернативы.

Рисунок 3: Близость не квалифицируется как инструментальная переменная с учетом часов библиотеки

Рисунок 4: Близостьквалифицируется как инструментальная переменная, если мы не включаем часы работыбиблиотеки в качестве ковариаты.
Предположим, хотим оценить влияние программы репетиторства в университете среднего балл (GPA ). Взаимосвязь между посещением программы репетиторства и средним баллом успеваемости может быть нарушена рядом факторов. Учащиеся, посещающие программу репетиторства, могут больше заботиться о своих оценках или испытывать трудности с работой. Это смешение показано нарисунках 1-3 справа через двунаправленную дугу между программой обучения и средним баллом.Если студентов распределяют по общежитиям наугад, близость студенческого общежития к программе репетиторства является альтернативным кандидатом на роль инструментальной альтернативы.
Но что, если программа репетиторства находится в библиотеке колледжа? В этом случае может также побудить учащихся больше времени в библиотеке, в свою очередь, улучшить их средний балл (см. Рисунок 1). Используяпричинный граф, изображенный на рисунке 2, мы видим, что Proximity не квалифицируется какинструментальная переменная, потому что она связывает с GPA через путь Proximity  Часы работы библиотеки GPA в . Однако если мы контролируем часы работы библиотеки, добавляя их в качестве ковариаты, то Proximity становится инструментальной, близостьотделяется от GPA с учетом количества часов библиотеки в .
Часы работы библиотеки GPA в . Однако если мы контролируем часы работы библиотеки, добавляя их в качестве ковариаты, то Proximity становится инструментальной, близостьотделяется от GPA с учетом количества часов библиотеки в .
Теперь предположим, что мы замечаем, что «естественные способности» студента влияют на его количество часов в библиотеке, а также на его или ее средний балл, как показано на рисунке 3. Используя причинно-следственный график, мы видим, что количество часов библиотеки является коллайдером. и кондиционирование на нем открывает путь Proximity Часы работы библиотеки  GPA. В результатеблизостьне может быть в качестве инструментальной альтернативы.
GPA. В результатеблизостьне может быть в качестве инструментальной альтернативы.
Наконец, предположим, что часы работы библиотеки на самом деле не имеют значения на средний балл, потому что студенты, которые не учатся в другом месте, как показано на рисунке 4. В случае контроль часов библиотека по-прежнему открывает ложный путь от близости к GPA. Однако, если мы не контролируем часы работы библиотеки иудаляем его как ковариату, то близость снова можно использовать в качестве инструментальнойальтернативы.
Оценка
Теперь мы вернемся к механике IV и подробнее остановимся на ней. Предположим, что данные генерируются процесса вида

где
- i индексирует наблюдения,
 - i-е зависимой переменной,
- i-е зависимой переменной, - вектор i-го значениянезависимой (ов) и константы,
- вектор i-го значениянезависимой (ов) и константы, - я-е значениененаблюдаемой термин,представляющий все причины кроме и
- я-е значениененаблюдаемой термин,представляющий все причины кроме и- - это ненаблюдаемый вектор параметров.
Вектор параметров - причинный эффект на изменений на одну единицу в каждом элементе , все остальные причины константа.Эконометрическая цель - оценить . Для простоты предположим, что значения e не коррелированы взяты из распределений с одинаковой дисперсией (то есть, что последовательно некоррелированы ошибки и гомоскедастичны ).
Предположим также, предложенный регрессионная модель номинально такой же формы. Учитывая случайную выборку Tнаблюдений из этого процесса, оценка обычным методом наименьших квадратов равна

где X, y и e обозначают указание-столбцы длины T. Это уравнение на уравнение с участием  во введении (это матричная версия этой версии уравнения). Когда X и e некоррелированы, приопределенных условиях регулярности второй член имеет ожидаемое значение, обусловленное нулем X, и сходится к нулю в пределе, поэтому оценка несмещена и согласована. Когда X и другие неизмеряемые, вызывают переменные, свернутые в члене, коррелируются, однако, оценка МНК обычно смещена и непоследовательна для β. В этом случае допустимо использовать оценку для прогнозированиязначений y при заданных значениях X, но оценка не восстанавливает причинное влияние Xна y.
во введении (это матричная версия этой версии уравнения). Когда X и e некоррелированы, приопределенных условиях регулярности второй член имеет ожидаемое значение, обусловленное нулем X, и сходится к нулю в пределе, поэтому оценка несмещена и согласована. Когда X и другие неизмеряемые, вызывают переменные, свернутые в члене, коррелируются, однако, оценка МНК обычно смещена и непоследовательна для β. В этом случае допустимо использовать оценку для прогнозированиязначений y при заданных значениях X, но оценка не восстанавливает причинное влияние Xна y.
Чтобывосстановить базовый параметр , мы вводим набор Z, который сильно коррелирует с каждым эндогенным компонентом X, но (в нашей модели) не коррелирует с e. Для простоты можно рассматривать X как матрицу T × 2, состоящую из столбца констант и одной эндогенной переменной, а Z как матрицу T × 2, состоящую из столбца констант и однойинструментальной переменной. Однако этот метод обобщается на X, являющийся матрицей констант и,скажем, 5 эндогенныхчисел, причем Z - это матрица, состоящая из константы и 5 инструментов. В последующем обсуждении мы будем предполагать, что X является матрицей размера T × K, и оставим это значение K неопределенным. Оценщик, в котором X и Z являются матрицами T × K, называется только что идентифицированным.
Предположим, что взаимосвязь между эндогенным компонентом x i иинструментами задается как

Наиболеераспространенная спецификация IV использует следующую оценку:

Эта спецификация подходит истинный параметр по мере увеличения выборки, если  в истинной модели:
в истинной модели:

Пока в базовом процессе, который генерирует данные, соответствующее использование оценщика IV будет опр еделят ь этот параметр. Это работает, потому что IV вычисляет уникальный параметр, который удовлетворяет , и, следовательно,оттачивает истинный базовый параметр по мере увеличения размера выборки.
Теперь расширение:предположим, чтосуществует больше инструментов, чем ковариат в интересующем уравнении, так что Z является матрицей размером T × M с M>K. Это часто называют случаем чрезмерной идентификации . В этом случае можно использовать обобщенный метод моментов (GMM). Оценка GMM IV:

где  относится к матрице проекции
относится к матрице проекции  .
.
Это выражение сворачивается до первого, когда количество инструментов равно количеству ковариат в интересующем уравнении. Таким образом, чрезмерно идентифицированная IV является обобщением только что идентифицированной IV.
Доказательство того, что β GMM коллапсирует до β IV в только что указанном случае
Разработка  выражение:
выражение:

В только что указанном случае у нас столько инструментов как ковариаты, так что размерность X такая же, каку Z. Следовательно,  и
и  - все квадратные матрицы одного измерения. Мы можем расширить обратное, используя тот факт, что для любых обратимых матриц размера n на n A и B, (AB ) = BA( см. Обратимая матрица # Свойства ):
- все квадратные матрицы одного измерения. Мы можем расширить обратное, используя тот факт, что для любых обратимых матриц размера n на n A и B, (AB ) = BA( см. Обратимая матрица # Свойства ):

Ссылка: см. Davidson and Mackinnnon (1993)
Существует эквивалентная недоидентифицированная оценка для случая,когда m < k. Since the parameters are the solutions to a set of linear equations, an under-identified model using the set of equations  не имеет единственного решения.
не имеет единственного решения.
Интерпретация как двухэтапный метод наименьших квадратов
Одним из вычислительных методов, который можно использовать для вычисления оценок IV, является двухэтапный метод наименьших квадратов (2SLS или TSLS). На первом этапе каждая независимая переменная, котораяявляется эндогенной ковариатой в интересующем уравнении, подвергается регрессиипо всем экзогенным переменным в модели, включаякак экзогенные ковариаты в интересующем уравнении, так и исключенные инструменты. Прогнозируемые значения из этих регрессий получают:
Этап 1: Регрессируйте каждый столбец X на Z, ( ):
):

и сохраните предсказанныезначения:

На втором этапе интересующая регрессия оценивается как обычно, за исключением того, что на этом этапе каждая эндогенная ковариата заменяется с предсказанными значениями из первогоэтапа:
Этап 2: Регресс Y по прогнозируемым значениям из первогоэтапа:

, что дает

Доказательство: вычисление оценки 2SLS
Обычная оценка OLS:  . Заменив
. Заменив  и отметив, что - симметричная и идемпотентная матрица, так что
и отметив, что - симметричная и идемпотентная матрица, так что 

Результирующая оценка численно идентична приведенному выше выражению. Необходимо внести небольшую поправку в суммуквадратов остатков в подобранной модели второго этапа, чтобы ковариационная матрица рассчитываласьправильно.
Непараметрический анализ
Когда форма структурных уравнений неизвестна, инструментальная переменная  все еще может быть определена через уравнения:
все еще может быть определена через уравнения:


где  и
и  - две произвольные функции, а не зависит от
- две произвольные функции, а не зависит от  . Однако, в отличие от линейных моделей, измерения
. Однако, в отличие от линейных моделей, измерения  и не позволяют идентифицировать средний причинный эффект на , обозначенный ACE
и не позволяют идентифицировать средний причинный эффект на , обозначенный ACE
![{\ text {ACE}} = \ Pr (y \ mid {\ text {do}} (x)) = \ operatorname {E} _ {u} [f (x, u)].](https://wikimedia.org/api/rest_v1/media/math/render/svg/e6ea36b8f79d0df3bb0e66e1b9273b9c9ae67edb)
Balke и Pearl [1997] получили жесткие границыдля ACE и показали, что они могут предоставить ценную информацию о знаке и размере ACE.
В линейном анализе нет теста, опровергающего предположение, что является инструментом относительно пары  . Это не тот случай, когда дискретный. Перл (2000) показал, что для всех и следующее ограничение, называемое«Инструментальное неравенство "должно выполняться всякий раз, когда удовлетворяет двум приведенным выше уравнениям:
. Это не тот случай, когда дискретный. Перл (2000) показал, что для всех и следующее ограничение, называемое«Инструментальное неравенство "должно выполняться всякий раз, когда удовлетворяет двум приведенным выше уравнениям:
![\ max _ {x}\ sum _ {y} [\ max _ {z} \ Pr (y, x \ mid z)] \ leq 1.](https://wikimedia.org/api/rest_v1/media/math/render/svg/b089badc50cd6306cc6c673f45027813e1ebc23e)
Интерпретация при неоднородности воздействия обработки
Изложение выше предполагает, что интересующий причинный эффект не меняется в зависимости отнаблюдений, то есть является константой. Как правило, разные субъекты по-разному реагируют на изменения в «лечении» x. Когда эта возможность признается, средний эффект изменения x на y в популяции может отличаться от эффекта в данной подгруппе населения. Например, средний эффект программы профессионального обучения может существенно различаться для группылюдей, которые факт ически проходят обучение, и для группы, которая решает не проходить обучение. Поэтим причинам методы IV используют неявные предположения оповеденческой реакции или, в более общем плане, предположения о корреляции между реакцией на лечение и склонностью к лечению.
Стандартная оценка IV может восстановить локальные средние эффекты лечения (ПОЗДНЕЕ), а не средний эффект лечения (ATE). Имбенс и Ангрист (1994) демонстрируют, что линейная оценка IVможет быть интерпретирована в слабых условиях как средневзвешенное значение локальных среднихэффектов лечения, где веса зависят от эластичности эндогенногорегрессора к изменениям инструментальных переменных. Грубо говоря, это означает, что влияние переменной выявляется только для субпопуляций, затронутых наблюдаемыми изменениями в инструментах, и что субпопуляции, которые больше всего реагируют на изменения в инструментах, будут иметь наибольшее влияние на величину оценки IV.
Например, если исследователь использует наличие колледжа, предоставившего землю, в качествеинструмента для получения высшего образования в регрессии доходов, онопределяет влияние колледжа на заработки в подгруппе населения, которая получила бы высшее образование, если бы колледж присутствует, но который не получил бы степени, если колледж отсутствует. Этот эмпирический подход без дополнительных предположений ничего не говорит исследователю о влиянии колледжа на людей, которые либо всегда,либо никогда не получат его, независимо от того, существует ли местный колледж.
Проблема со слабыми инструментами
Как отмечают Bound, Jaeger и Baker (1995), проблема вызвана выбором «слабых» инструментов, плохих инструментов предикторы предиктора эндогенного вопроса в уравнении первого этапа. В этом случае инструмент прогнозирования вопроса будет плохим, и прогнозируемые значения будут иметь очень небольшие вариации. Следовательно, они вряд ли добьются большогоуспеха в предсказании окончательного результата, если они используются для замены предикторавопроса в уравнении второго этапа.
В контексте рассмотренного вышепримера курения и здоровья, налоги на табак являются слабым инструментом для курения, если статус курения в значительной степени не реагирует на изменения налогов. Если более высокие налоги не побуждают людей бросить курить (или не начать курить), то изменение налоговых ставок ничего не говорит нам о влиянии курения наздоровье. Если налоги влияют на здоровье по каналам, отличным от их воздействия на курение, тогдаинструменты недействительны, и подход с использованием инструментальныхпеременных может привести к неверным результатам. Например, места и время с относительно заботящимся о своем здоровье населением могут как ввести высокие налоги на табак, так и продемонстрировать лучшее здоровье, даже при сохранении постоянного уровня курения, поэтому мы наблюдали бы корреляцию между налогами на здоровье итабачными изделиями, даже если бы курение не имело эффекта на здоровье. В этом случае было бы ошибкойсделать вывод о причинном влиянии курения на здоровье на основенаблюдаемой корреляции между налогами на табак и здоровьем.
Тестирование слабых инструментов
Сила инструментов может быть оценена напрямую, потому что и эндогенные ковариаты, и инструменты наблюдаемы. Общее практическое правило для моделей с одним эндогенным регрессором: F-статистика против null, что исключенные инструменты не имеют отношения к регрессии на первом этапе, должно быть больше10.
Статистический вывод и проверка гипотез
Когда ковариаты являются экзогенными, свойства малой выборки оценщика МНК могут быть получены прямым способом путем вычисления моментов оценщика, обусловленного X. Когда некоторые из ковариат являются эндогенными, так что оценка инструментальных переменных реализуется, простые выражения для моментов оценки не могут быть полученытаким образом. Generally, instrumental variables estimators only have desirable asymptotic, not finiteвыборка, свойства и вывод основаны на асимптотической аппроксимации, которая обычно далеко от истинного значения параметра.
Проверка ограничения исключения
Предположение, что инструменты не коррелированы с член ошибки в интересующем уравнении не поддается проверке в точно идентифицированных моделях. Если модель переопределена, имеется информация, которая может бытьиспользована для проверки этого предположения. Самый распространенный тест этих ограничений на сверхидентификацию, cal Тест Саргана – Хансена основан на наблюдении, что остатки не должны коррелировать с набором экзогенных переменных, если инструменты действительно экзогенные. Статистику критерия Саргана – Хансена можно рассчитать как  (количество наблюдений, умноженное на коэффициент детерминации ) из МНК-регрессия остатков намножество экзогенных переменных. Эта статистика будет асимптотически вычислена хи-квадрат с m - k степеней свободы при нулевом значении, когда ошибка не коррелирует с приборами.
(количество наблюдений, умноженное на коэффициент детерминации ) из МНК-регрессия остатков намножество экзогенных переменных. Эта статистика будет асимптотически вычислена хи-квадрат с m - k степеней свободы при нулевом значении, когда ошибка не коррелирует с приборами.
Применение к моделям со случайными и фиксированными эффектами
В стандартных моделях случайных эффектов (RE) и с фиксированными эффектами (FE) для панельные данные, предполагается, что независимые переменные не коррелируют с ошибками. При наличии действительныхинструментов методы RE и FE распространяются на случай, когда некоторым независимым переменным разрешено быть эндогенными. x i t {\displaystyle x_{it}} can be correlated with
can be correlated with for s possibly different from t. Suppose there exists a set of valid instruments
for s possibly different from t. Suppose there exists a set of valid instruments  .
.
In REIV setting, key assumptions include that  is uncorrelated wit h
is uncorrelated wit h  as well as
as well as  для
для  . Фактически, длятого, чтобы оценка REIV была эффективной, необходимы условия более сильные, чем некоррелированность между инструментами и ненаблюдаемый эффект.
. Фактически, длятого, чтобы оценка REIV была эффективной, необходимы условия более сильные, чем некоррелированность между инструментами и ненаблюдаемый эффект.
С другой стороны, оценщик FEIV требует только, чтобы инструменты были экзогенными с ошибочными членами после обусловливания ненаблюдаемого эффекта, т.е. ![{\ displaystyleE [u_ {it} \ mid z_ {i}, c_ {i}] = 0 [1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b666ac512b37eb9b633068404cb5c21dba18ef14) . Условие FEIV допускаетпроизвольную корреляцию между инструментами и ненаблюдаемым эффектом.Однако эта общность не дается даром: не допускаются инвариантные во времени объясняющие и инструментальные переменные. Как и в обычном методе FE, оценщик использует зависимые от времени переменные, чтобы удалить ненаблюдаемый эффект. Следовательно, оценка FEIV будет иметь ограниченное применение, еслиинтересующие нас переменные будут включать переменные, не зависящие от времени.
. Условие FEIV допускаетпроизвольную корреляцию между инструментами и ненаблюдаемым эффектом.Однако эта общность не дается даром: не допускаются инвариантные во времени объясняющие и инструментальные переменные. Как и в обычном методе FE, оценщик использует зависимые от времени переменные, чтобы удалить ненаблюдаемый эффект. Следовательно, оценка FEIV будет иметь ограниченное применение, еслиинтересующие нас переменные будут включать переменные, не зависящие от времени.
Вышеупомянутое обсуждение имеетпараллель с экзогенным случаем моделей RE и FE. В экзогенном случае REпредполагает некоррелированность между независимыми переменными и ненаблюдаемым эффектом, а FE допускает произвольную корреляцию между ними. Подобно стандартному случаю, REIV имеет тенденцию быть более эффективным, чем FEIV, при условии, что выполняются соответствующие предположения.
Методы дляобобщенных линейных моделей
Были разработаны методы для расширения оценки инструментальных чисел до обобщенных линейных моделей.
регрессия Пуассона
Вулдридж и Терцапредоставят методологию как для работы, так и для тестирования для эндогенности в рамках экспоненциальной регрессии, в которой следует последующее обсуждение. Хотя в данном случае особое внимание уделяется модели регрессии Пуассона, ее можно обобщить на другие модели экспоненциальнойрегрессии, хотя это может происходить за счет предположений (например, для моделей двоичного ответа или цензурированныхмоделей данных).
Предположим следующая модель экспоненциальной регрессии,где  - это ненаблюдаемый член в скрытой переменной. Мы допускаем корреляцию между и
- это ненаблюдаемый член в скрытой переменной. Мы допускаем корреляцию между и  (подразумевается , возможно, эндогенный),но не допускает такую корреляции между и .
(подразумевается , возможно, эндогенный),но не допускает такую корреляции между и .
![{\ displaystyle \ operatorname {E} [y_ {i} \ mid x_ {i}, z_ {i}, a_ {i}] = \ exp (x_ {i} b_ {0} + z_ {i} c_ {0} + a_ {i})}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8ff01de7f917789d3637c2304b07103fea678810)
Переменные Найти инструментальными переменными для раннего эндогенного . Можно предположить линейную зависимостьмежду этими двумя переменными или альтернативно, спроецировать эндогенную переменную на инструменты, чтобы получить следующее уравнение сокращенной формы:
 | | (1) |
Обычное условие ранжирования необходимо для определения личности. Эндогенность моделируется следующим образом, где  определяет серьезность эндогенности, а
определяет серьезность эндогенности, а  независимым от .
независимым от .

Принятие этих допущений при условии, что модели указаны, и нормализация![{\displaystyle \ operatorname {E} [\ exp (e_ {i})] = 1}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3912b3e85e13bb100eafd60edab35a891aeb502a) , мы можем правильно переписать условное среднее следующим образом:
, мы можем правильно переписать условное среднее следующим образом:
![{\ displaystyle \ operatorname {E} [y_ {i} \ mid x_ {i}, z_ {i}, v_ {i}] = \ exp (x_ {i} b_ {0} + z_ {i} c_ {0} + v_ {i } \ rho)}](https://wikimedia.org/api/rest_v1/media/math/render/svg/431ba1ffd3b32996c73b63b194356ac439489e46) | | (2) |
Если бы был известен в этот момент, можно было бы оценить соответствующие параметры с квази -Оценка верхнего правдоподобия (QMLE). Следуя двухшаговой методике, Вулдридж и Терца постановление оценки (1) с помощью обыкновенных наименьших квадратов. Подобные остатки этой регрессии могут быть включены в уравнение оценки (2), и QMLE приведут ксогласованным оценкам интересующих параметров. Затем можно использовать тесты значимости для  для проверки эндогенности в модели.
для проверки эндогенности в модели.
См. Также
Ссылки
Дополнительная литература
- Грин, Уильям Х. (2008). Эконометрический анализ (Шестое изд.). Река Аппер Сэдл: ПирсонПрентис-Холл. Стр. 314 –353. ISBN 978-0-13-600383-0.
- Гуджарати, Дамодар Н. ; Портер, Доун С. (2009).Основы эконометрики (Пятое изд.). Нью-Йорк: Макгроу-Хилл Ирвин. Стр.711 –736. ISBN 978-0-07-337577-9.
- Сарган, Денис (1988). Лекции по углубленной эконометрической теории. Оксфорд: Бэзил Блэквелл. С. 42–67. ISBN 978-0-631-14956-9.
- Вулдридж, Джеффри М. (2013). Вводная эконометрика: современныйподход (Пятое международное издание). Мейсон, Огайо: Юго-запад. С. 490–528. ISBN 978-1-111-53439-4.
Библиография
- Вулдридж, Дж. (1997): Методы квази-правдоподобия для подсчета данных, Справочник поприкладной эконометрике, Том 2, изд. М. Х. Песаран и П. Шмидт, Оксфорд, Блэквелл, стр. 352–406
- Терца, Дж. В. (1998): «Оценка подсчета с эндогенным переключением: отбор образцов и эндогенные эффекты лечения». Journal of Econometrics (84), стр. 129–154
- Вулдридж, Дж. (2002): «Эконометрический анализ данных поперечного сечения и панелей», MIT Press, Кембридж, Массачусетс.
Внешние ссылки
