
Войти
Британский национальный корпус (BNC ) состоит из 100 миллионов слов текстовый корпус образцов письменной и устной английского из широкого круга источников. Корпус охватывает британский английский конца 20-го века из самых разных жанров, с намерением сделать его репрезентативным образцом разговорного и письменного британского английского языка того времени.
Проект по созданию BNC участвовал в сотрудничестве трех издателей (с Oxford University Press в качестве ведущего сотрудника, Longman и W. R. Chambers ), двух университетов (the Университет Оксфордского и Ланкастерского университета ), а также Британской библиотеки. Создание BNC началось в 1991 году под управлением консорциума BNC, и проект был завершен к 1994 году. После 1994 года не было добавлений новых образцов, но BNC претерпел незначительные изменения перед выпуском второго издания BNC World. (2001) и третье издание BNC XML Edition (2007).
BNC был видением компьютерных лингвистов, целью которых было корпус современного (на момент создания корпуса), естественный язык в форме речи и текста или письма, которые могут быть проанализированы компьютером. Следовательно, он был составлен как общий корпус, чтобы открыть путь для автоматического поиска и обработки в области корпусной лингвистики. Одним из способов отличить BNC от существующих корпусов в то время было открытие данных не только для академических исследований, но также для коммерческого и образовательного использования.
Корпус был ограничен Британский английский, и не был распространен на всемирный английский. Отчасти это было связано с тем, что значительная часть стоимости проекта финансировалась британским правительством, которое было логически заинтересовано в сопроводительной документации своего собственного языкового разнообразия. Из-за своего потенциально беспрецедентного размера BNC требовал средств также от коммерческих и академических институтов. В свою очередь, данные BNC затем стали доступны для коммерческих и академических исследований.
BNC - это одноязычный корпус, поскольку он записывает образцы языка используйте только в британском английском, хотя иногда могут присутствовать слова и фразы из других языков. Это синхронный корпус, так как представлено только использование языка с конца 20 века; BNC не является историческим отчетом о развитии британского английского на протяжении веков. С самого начала те, кто участвовал в сборе письменных данных, стремились сделать BNC сбалансированным корпусом и, следовательно, искали данные на различных носителях.
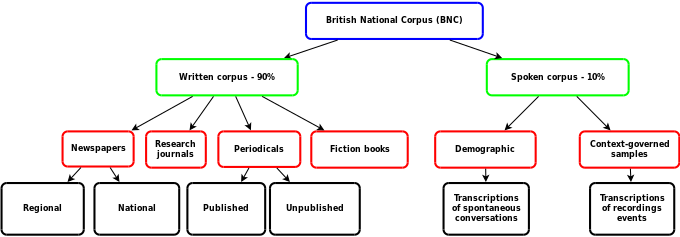 структура BNC
структура BNC 90% BNC - это образцы использования письменного корпуса. Эти образцы были взяты из региональных и национальных газет, опубликованных исследовательских журналов или периодических изданий из различных академических областей, художественной и научно-технической литературы, других опубликованных материалов и неопубликованных материалов, таких как листовки, брошюры, письма, эссе, написанные студентами разного академического уровня., речи, сценарии и многие другие типы текстов.
Остальные 10% BNC - это образцы разговорной речи. Они представлены и записаны в виде орфографической транскрипции. Разговорный корпус состоит из двух частей: одна часть - демографическая, содержащая транскрипции спонтанных естественных разговоров, произведенных добровольцами разных возрастных групп, социальных слоев и происходящих из разных регионов. Эти разговоры производились в различных ситуациях, включая официальные деловые или правительственные встречи, разговоры на радиошоу и телефонные разговоры. Они должны были учитывать как демографическое распределение разговорной речи, так и лингвистически значимые вариации из-за контекста.
Другая часть включает в себя образцы, управляемые контекстом, такие как транскрипции записей, сделанных на определенных типах встреч и мероприятий. Все оригинальные записи, расшифрованные для включения в BNC, депонированы в Звуковом архиве Британской библиотеки. Большая часть записей находится в свободном доступе в фонетической лаборатории Оксфордского университета.
Были выпущены два субкорпуса (подмножества данных BNC): BNC Baby и BNC Сэмплер. Оба этих субкорпуса можно заказать онлайн через веб-страницу BNC. BNC Baby - это подкорпус BNC, состоящий из четырех наборов выборок, каждый из которых содержит один миллион слов, помеченных, как и в самом BNC. Слова в каждом наборе примеров соответствуют определенной метке жанра. Один набор образцов содержит устную беседу, а три других набора образцов содержат письменный текст: академическая письменность, художественная литература и газеты соответственно. Последняя (третья) редакция выпущена в формате XML. BNC Sampler состоит из двух частей, каждая из которых предназначена для письменных и устных данных; каждая часть содержит миллион слов. Изначально BNC Sampler использовался в проекте, чтобы разработать, как улучшить процесс маркировки для BNC, что в конечном итоге привело к выпуску BNC World edition. На протяжении всего проекта BNC Sampler совершенствовался за счет увеличения опыта и знаний по тегированию, чтобы достичь его текущей формы.
Корпус BNC был помечен для грамматической информации (часть речи ). Система тегов, названная CLAWS, претерпела улучшения, в результате чего появилась последняя система CLAWS4, которая используется для тегирования BNC. CLAWS1 был основан на скрытой марковской модели и при использовании в автоматическом тегировании ему удавалось успешно тегировать от 96% до 97% каждого проанализированного текста. CLAWS1 был обновлен до CLAWS2, устранена необходимость в ручной обработке для подготовки текстов к автоматической маркировке. Последняя версия, CLAWS4, включает такие улучшения, как более мощные возможности устранения неоднозначности (WSD) и возможность работать с вариациями в орфографии и языке разметки. Позднее работа над системой тегов была направлена на повышение успешности автоматической маркировки и сокращение объема работы, необходимой для ручной обработки, при сохранении эффективности и результативности за счет внедрения программного обеспечения, которое заменит некоторую ручную работу. Впоследствии для корректирующей функции была представлена новая программа под названием «Template Tagger». Позже были добавлены теги, указывающие на неоднозначность. Ручная маркировка по-прежнему необходима, поскольку CLAWS4 все еще не может работать с иностранными словами.
Корпус размечен в соответствии с рекомендациями Text Encoding Initiative (TEI) и включает полную лингвистическую аннотацию и контекстную информацию. Чтобы использовать теггер, можно приобрести лицензию на теггер части речи CLAWS4. В качестве альтернативы услуги тегирования предлагаются в Ланкастерском университете. Сам BNC можно заказать с личной или институциональной лицензией. Доступна редакция BNC XML, которая поставляется с программным обеспечением поисковой системы Xaira. Заказ можно осуществить через сайт BNC. Онлайн-менеджер корпуса , BNCweb, был разработан для версии BNC XML. Интерфейс разработан так, чтобы быть простым в использовании, и программа предлагает функции запросов и функции для анализа корпуса. Пользователи могут получать результаты и данные в результате поиска и анализа.
BNC был первым текстовым корпусом такого размера, который стал широко доступным. Это может быть связано со стандартными формами соглашения между правообладателями и Консорциумом, с одной стороны, и между пользователями корпуса и Консорциумом, с другой. Владельцы прав интеллектуальной собственности разыскивались за их согласие со стандартной лицензией, включая готовность включать свои материалы в корпус без каких-либо комиссий. Этому расположению, возможно, способствовали оригинальность концепции и известность, связанная с проектом. Однако было непросто сохранить личность участников, не дискредитируя ценность их работы. Любой отчетливый намек на личность участников был в значительной степени удален; обсуждалось альтернативное решение замены личности участника другим именем, но оно не было сочтено возможным.
Кроме того, участников ранее просили только включить транскрибированные версии их речи и не речь. Хотя разрешение можно было снова запросить у первоначальных участников, отсутствие успеха в процессе анонимности означало, что будет сложно получить материалы у первоначальных участников. В то же время два фактора усугубляли нежелание правообладателей жертвовать свои материалы: полные тексты должны были быть исключены, и у них не было мотивации для распространения информации с использованием корпуса, тем более что корпус действует на некоммерческой основе..
К 2001 году в BNC все еще не было категоризации текста для письменных текстов за пределами домена, а также категоризации для устных текстов, кроме контекста и демографические или социально-экономические классы. Например, большое количество художественных текстов (романы, рассказы, стихи и драматические сценарии) были включены в BNC, но такие включения считались бесполезно, так как исследователи не могли легко найти поджанры, над которыми они хотели работать (например, стихи). Поскольку эти метаданные были опущены в заголовках файлов и во всей документации BNC, не было возможности узнать, действительно ли «образный» текст взят из романа, рассказа, драматического сценария или собрания стихотворения, если название действительно не включало такие слова, как «роман» или «стихотворение»).
С выпуском в 2002 году новой версии, BNC World Edition, BNC попыталась решить эту проблему. Помимо домена, теперь существует 70 категорий по жанрам как для устных, так и для письменных данных, и поэтому исследователи теперь могут извлекать тексты по жанрам. Однако даже после этих добавлений реализация по-прежнему остается сложной задачей, поскольку присвоить тексту жанр или поджанр непросто. Разделения для устных данных менее четкие, чем для письменных, поскольку было больше различий в тематике и исполнении. Также всегда будут возможные подмножества жанров каждого поджанра. Степень разделения жанров предварительно определяется по умолчанию, но исследователи могут сделать подразделения более общими или конкретными в соответствии со своими потребностями. Категоризация также является проблемой, поскольку определенные тексты, хотя и считаются принадлежащими к междисциплинарному жанру, например лингвистике, включают контент, который впоследствии классифицируется либо по категориям искусства, либо по естествознанию в силу характера их содержания.
Некоторые тексты были отнесены к неправильной категории, обычно из-за вводящего в заблуждение названия. Пользователи не всегда могут полагаться на названия файлов как на указание на их реальное содержание: например, многие тексты со словом «лекция» в названии на самом деле являются обсуждениями в классе или учебными семинарами с участием очень небольшой группы людей, или были популярными лекциями (адресованными для широкой аудитории, а не для студентов вузов). Одна из причин заключается в том, что метки жанра и поджанра могут быть присвоены только большинству текстов в категории. Внутри жанров есть поджанры, и содержание каждого текста может быть неоднородным и может охватывать несколько поджанров. Кроме того, производственное давление в сочетании с недостаточностью информации привело к поспешным решениям, что привело к неточности и непоследовательности в записях.
Соотношение письменного и устного материала в BNC составляет 10: 1, что делает устный материал недопредставленным. Это связано с тем, что стоимость сбора и расшифровки одного миллиона слов естественной речи как минимум в 10 раз выше, чем стоимость добавления еще одного миллиона слов газетного текста. Некоторые лингвисты утверждали, что это свидетельствует о недостатке корпуса, поскольку речь и письмо одинаково важны в языке. BNC не идеален для изучения многих особенностей устного дискурса, поскольку большинство его транскриптов орфографически. Паралингвистические функции указаны лишь приблизительно.
Несмотря на то, что BNC является отличным источником лексической информации, в действительности его можно использовать только для изучения ограниченного набора грамматических шаблонов, особенно тех, которые имеют отчетливые лексические корреляты. Хотя достаточно легко найти все вхождения слова «наслаждаться» и отсортировать их в соответствии с категорией части речи следующего слова, требуется дополнительная работа, чтобы найти все случаи употребления глаголов, за которыми следует на герундий, поскольку индекс SARA BNC не включает категории части речи, такие как «все глаголы» или «все формы V-ing».
Некоторые лексические корреляты также слишком неоднозначны, чтобы их можно было использовать в запросах: любой поиск ограничительных относительных предложений предоставит пользователю нерелевантные данные, учитывая количество других применений wh- местоимения и этого в языке (не говоря уже о невозможности отождествления относительных предложений с удалением местоимения, как в «человек, которого я видел»). Конкретные семантические и прагматические категории (сомнения, осведомленность, разногласия, резюме и т. Д.) Трудно найти по той же причине. Это означает, например, что, хотя можно сравнивать речь мужчин и женщин, нельзя сравнивать речь женщин и мужчин.
Природа BNC как большого смешанного корпуса делает его непригодным для исследования. очень специфических текстовых типов или жанров, поскольку любой из них, вероятно, будет неадекватно представлен и может быть не распознан по кодировке. Например, в BNC очень мало деловых писем и служебных встреч, и тем, кто желает изучить их конкретные соглашения, лучше составить небольшой корпус, включающий только тексты этих типов.
Существует два основных способа использования материала корпуса при обучении языку.
Во-первых, издатели и исследователи могут использовать образцы корпуса для создания справочников по изучению языка, учебных программ и другие связанные инструменты или материалы. Например, BNC использовалась группой японских исследователей в качестве инструмента при создании веб-сайта для изучения английского языка для изучающих английский язык для конкретных целей (ESP). Веб-сайт позволял изучающим английский язык загружать часто слышимые и используемые шаблоны предложений, а затем основывать их собственное использование английского языка на этих шаблонах предложений. BNC служил источником, из которого были извлечены часто используемые выражения. Таким образом, при использовании этого веб-сайта пользователи полагались на эталонные образцы из BNC, чтобы помочь им в изучении английского языка. Такое создание материалов, облегчающих изучение языка, обычно включает использование очень больших корпусов (сравнимых с размером BNC), а также передового программного обеспечения и технологий. В разработку такого материала для изучения языка вкладывается большое количество денег, времени и опыта в области компьютерной лингвистики.
Во-вторых, может быть включен анализ корпуса непосредственно в языковую среду преподавания и обучения. С помощью этого метода учащимся, изучающим язык, предоставляется возможность классифицировать языковые данные из корпуса и впоследствии формировать выводы о шаблонах и особенностях своего изучаемого языка на основе их категорий. Этот метод предполагает больший объем работы со стороны тех, кто занимается языком, и Тим Джонс назвал его «обучение на основе данных». Корпус данных, используемых для обучения на основе данных, относительно меньше, и, следовательно, обобщения, сделанные в отношении целевого языка, могут иметь ограниченную ценность. В общем, BNC полезен как справочный источник для создания и восприятия текста. BNC можно использовать в качестве справочного источника при изучении использования отдельных слов в различных контекстах, чтобы учащиеся познакомились с различными способами использования определенных слов в подходящих контекстах. Помимо языковой информации, в BNC также можно найти энциклопедическую информацию. Учащиеся, просматривающие данные из BNC, также знакомятся с особенностями британской культуры и стереотипами.
BNC был источником более 12 000 слов и фраз, используемых для создания ряд двуязычных словарей в Индии в 2012 году с переводом 22 местных языков на английский. Это было частью более крупного движения, направленного на улучшение образования, сохранение местных языков Индии и развитие переводческой работы. Большой размер BNC предоставляет крупномасштабный ресурс для тестирования программ. Он использовался в качестве испытательного стенда для руководящих принципов Text Encoding Initiative (TEI). BNC также использовался для предоставления 20 миллионов слов для оценки английских систем получения подкатегорий для инициативы Senseval по вычислительному анализу значения.
Hoffman Lehmann (2000) исследовали механизмы, лежащие в основе способности говорящих манипулировать своим большим набором словосочетаний, которые готовы к использованию и могут быть легко расширены грамматически или синтаксически для адаптации к текущей речевой ситуации. Сочетания слов, встречающиеся с низкой частотой, были извлечены из BNC, чтобы дать некоторое представление о нем.
Пирс (2008) исследовал представительство мужчин и женщин в этом корпусе. с помощью Sketch Engine. Инструмент корпусного запроса был использован для изучения грамматического поведения существительных лемм «мужчина» и «женщина» (т.е. существительных «мужчина» / «мужчины» и «женщина» / «женщины»). 79>
Fernandez Ginzburg (2002) исследовали диалоги, которые включали бессмысленные высказывания, с использованием BNC.
Lee Swales (2006) разработали экспериментальный курс основанного на корпусе английского языка для академических целей (EAP) для докторантов в Институте английского языка (ELI) Мичиганского университета в США.
Участники использовали три основных корпуса в качестве основы своих исследований: Корпус научных статей Хайленда, Мичиганский корпус академического разговорного английского языка (MICASE) и академические тексты от BNC.
В рамках текущей работы по морфологической обработке, ключевой области Обработка естественного языка (NLP), данные из BNC был использован для проверки точности, надежности и скорости вычислительных инструментов, разработанных для облегчения анализа и обработки морфологических маркеров в британском английском. Вычислительные инструменты включали программу, которая позволяла анализировать флексивную морфологию в британском английском (известную как анализатор), и программу, которая генерировала морфологические маркировки на основе анализа с помощью анализатора. Данные из BNC также использовались для создания обширного хранилища информации о морфологических маркерах британского английского языка. В частности, примерно 1100 лемм были извлечены из BNC и скомпилированы в контрольный список, который был проверен морфологическим генератором до того, как глаголы, допускающие удвоение согласных, были точно изменены. Поскольку BNC представляет собой заметную попытку собрать и впоследствии обработать такой большой объем данных, он стал влиятельным предшественником в этой области и моделью или образцом, на котором основывалась разработка более поздних корпусов.
В июле 2014 года издательство Кембриджского университета и Центр корпусных подходов к социальным наукам (CASS) объявили в Ланкастерском университете, что новый Британский национальный корпус - BNC2014 - находится на стадии компиляции. Первым этапом совместного проекта между двумя учреждениями было создание нового разговорного корпуса британского английского языка с начала до середины 2010-х годов. Британский национальный корпус 2014 года на 11,5 миллионов слов был выпущен для всеобщего ознакомления 25 сентября 2017 года. Компонент BNC2014 на 100 миллионов слов в письменной форме в настоящее время находится в процессе компиляции, и его публикация запланирована на осень 2016 года. 2018.