
Войти
В информатике, обнаружение цикла или поиск цикла - это алгоритмическая проблема поиска цикла в последовательности значений повторяющейся функции.
Для любой функции f, которая отображает конечный набор S на себя, и любое начальное значение x 0 в S, последовательность повторенных значения функции

в конечном итоге должен использовать одно и то же значение дважды: должна существовать пара различных индексов i и j, такая, что x i = x j. Как только это произойдет, последовательность должна продолжаться периодически, повторяя ту же последовательность значений от x i до x j - 1. Обнаружение цикла - это проблема поиска i и j при заданных f и x 0.
Известно несколько алгоритмов для быстрого поиска циклов с небольшим объемом памяти. Алгоритм черепахи и зайца Роберта Флойда перемещает два указателя с разной скоростью через последовательность значений, пока они оба не укажут на равные значения. В качестве альтернативы алгоритм Брента основан на идее экспоненциального поиска. Алгоритмы как Флойда, так и Брента используют только постоянное количество ячеек памяти и выполняют ряд вычислений функций, которые пропорциональны расстоянию от начала последовательности до первого повторения. Некоторые другие алгоритмы жертвуют большим объемом памяти за меньшее количество вычислений функций.
Применения обнаружения цикла включают проверку качества генераторов псевдослучайных чисел и криптографических хеш-функций, алгоритмов теории чисел, обнаружение бесконечные циклы в компьютерных программах и периодические конфигурации в клеточных автоматах, автоматический анализ формы из структур данных связанного списка, обнаружение взаимоблокировок для управления транзакциями в СУБД.
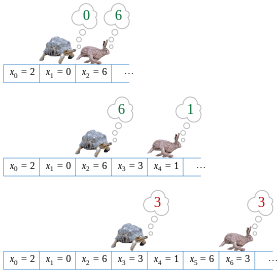
 Функция от и до множества {0,1,2,3,4,5,6,7,8} и соответствующий функциональный граф
Функция от и до множества {0,1,2,3,4,5,6,7,8} и соответствующий функциональный граф На рисунке показана функция f, которая отображает множество S = {0,1,2,3,4, 5,6,7,8} себе. Если начать с x 0 = 2 и многократно применить f, вы увидите последовательность значений
Цикл в этой последовательности значений равен 6, 3, 1.
Пусть S - любое конечное множество, f - любая функция от S до самой себя, и x 0 - любой элемент S. Для любого i>0 пусть x i = f (x i - 1). Пусть μ будет наименьшим индексом, так что значение x μ повторяется бесконечно часто в последовательности значений x i, и пусть λ (длина цикла) будет наименьшим положительным целым числом, таким, что x μ = x λ + μ. Задача обнаружения цикла - это задача нахождения λ и μ.
Можно рассмотреть ту же проблему теоретически, построив функциональный граф (то есть, ориентированный граф, в котором каждая вершина имеет одно исходящее ребро), вершины которого являются элементами S, а ребра которого отображают элемент на соответствующее значение функции, как показано на рисунке. Множество вершин , достижимых из начальной вершины x 0, образуют подграф с формой, напоминающей греческую букву ро (ρ): путь длиной μ от x От 0 до цикла из λ вершин.
Как правило, f не указывается в виде таблицы значений, так как показано на рисунке выше. Напротив, алгоритму обнаружения цикла может быть предоставлен доступ либо к последовательности значений x i, либо к подпрограмме для вычисления f. Задача состоит в том, чтобы найти λ и μ, исследуя как можно меньше значений из последовательности или выполняя как можно меньше вызовов подпрограмм. Как правило, также важна пространственная сложность алгоритма для задачи обнаружения цикла: мы хотим решить эту проблему, используя объем памяти, значительно меньший, чем потребуется для хранения всей последовательности.
В некоторых приложениях, и в частности в алгоритме ро Полларда для целочисленной факторизации, алгоритм имеет гораздо более ограниченный доступ к S и к f. В алгоритме Ро Полларда, например, S - это набор целых чисел по модулю неизвестного простого множителя числа, которое нужно разложить на множители, поэтому даже размер S неизвестен алгоритму. Чтобы позволить использовать алгоритмы обнаружения цикла с такими ограниченными знаниями, они могут быть разработаны на основе следующих возможностей. Первоначально предполагается, что алгоритм имеет в своей памяти объект, представляющий указатель на начальное значение x 0. На любом этапе он может выполнить одно из трех действий: он может скопировать любой указатель, который он имеет, на другой объект в памяти, он может применить f и заменить любой из своих указателей указателем на следующий объект в последовательности, или он может применить подпрограмма для определения, представляют ли два из ее указателя равные значения в последовательности. Действие проверки на равенство может включать в себя некоторые нетривиальные вычисления: например, в алгоритме ро Полларда оно реализуется путем проверки того, имеет ли разница между двумя сохраненными значениями нетривиальный наибольший общий делитель с числом, которое нужно факторизовать. В этом контексте, по аналогии с моделью вычислений машины указателя, алгоритм, который использует только копирование указателя, продвижение в последовательности и проверки равенства, может называться алгоритмом указателя.
Если ввод задан как подпрограмма для вычисления f, проблема обнаружения цикла может быть тривиально решена с использованием только приложений функции λ + μ, просто путем вычисления последовательности значений x i и с использованием структуры данных , такой как хэш-таблица, для хранения этих значений и проверки того, было ли уже сохранено каждое последующее значение. Однако пространственная сложность этого алгоритма пропорциональна λ + μ, что неоправданно велико. Кроме того, для реализации этого метода в виде алгоритма указателя потребуется применить проверку равенства к каждой паре значений, что приведет к квадратичному времени в целом. Таким образом, исследования в этой области сосредоточены на двух целях: использование меньшего пространства, чем этот наивный алгоритм, и поиск алгоритмов указателей, которые используют меньше тестов на равенство.
 Алгоритм обнаружения цикла «черепаха и заяц» Флойда, примененный к последовательности 2, 0, 6, 3, 1, 6, 3, 1,...
Алгоритм обнаружения цикла «черепаха и заяц» Флойда, примененный к последовательности 2, 0, 6, 3, 1, 6, 3, 1,... Флойда Алгоритм поиска цикла - это алгоритм указателя, который использует только два указателя, которые перемещаются по последовательности с разной скоростью. Его также называют "алгоритмом черепахи и зайца", отсылая к басне Эзопа Черепаха и Заяц.
. Алгоритм назван в честь Роберта У. Флойда, которому приписывают его изобретение Дональда Кнута. Однако алгоритм не появляется в опубликованной работе Флойда, и это может быть неправильной атрибуцией: Флойд описывает алгоритмы для перечисления всех простых циклов в ориентированном графе в статье 1967 года, но эта статья не описывает цикл -нахождение проблемы в функциональных графах, которой и посвящена данная статья. Фактически, заявление Кнута (1969 г.), приписывающее его Флойду, без цитирования, является первым известным печатным словом, и, таким образом, может быть народной теоремой, не относящейся к одному человеку <91.>
Ключевое понимание алгоритма заключается в следующем. Если цикл существует, то для любых целых чисел i ≥ μ и k ≥ 0 x i = x i + kλ, где λ - длина найденного цикла. а μ - номер первого элемента цикла. На основании этого можно затем показать, что i = kλ ≥ μ для некоторого k тогда и только тогда, когда x i = x 2i. Таким образом, алгоритму нужно только проверить повторяющиеся значения этой специальной формы, одно в два раза дальше от начала последовательности, чем другое, чтобы найти период ν повторения, кратный λ. Как только ν найдено, алгоритм повторяет последовательность от ее начала, чтобы найти первое повторяющееся значение x μ в последовательности, используя тот факт, что λ делит ν, и, следовательно, x μ = х μ + v. Наконец, как только значение μ известно, становится тривиальным найти длину λ кратчайшего повторяющегося цикла путем поиска первой позиции μ + λ, для которой x μ + λ = x μ.
Таким образом, алгоритм поддерживает два указателя на заданную последовательность, один (черепаха) в x i, а другой (заяц) в x 2i. На каждом шаге алгоритма он увеличивает i на единицу, перемещая черепаху на один шаг вперед, а зайца на два шага вперед по последовательности, а затем сравнивает значения последовательности на этих двух указателях. Наименьшее значение i>0, для которого черепаха и заяц указывают на равные значения, является искомым значением ν.
Следующий код Python показывает, как эту идею можно реализовать в виде алгоритма.
def floyd (f, x0): # Основная фаза алгоритма: поиск повторения x_i = x_2i. # Заяц движется вдвое быстрее черепахи и # расстояние между ними увеличивается на 1 с каждым шагом. # В конце концов они оба окажутся внутри цикла, а затем, # в какой-то момент, расстояние между ними будет # делиться на период λ. черепаха = f (x0) # f (x0) - это элемент / узел рядом с x0. hare = f (f (x0)) while tortoise! = hare: tortoise = f (tortoise) hare = f (f (hare)) # В этой точке положение черепахи, ν, которое также равно # расстоянию между зайцами и черепаха, делится на # период λ. Таким образом, заяц, перемещающийся по кругу по одному шагу за раз, # и черепаха (сброшен на x0), двигаясь к кругу, # пересекутся в начале круга. Поскольку # расстояние между ними постоянно и равно 2ν, кратно λ, # они согласятся, как только черепаха достигнет индекса μ. # Найдите позицию μ первого повторения. mu = 0 tortoise = x0 while tortoise! = hare: tortoise = f (tortoise) hare = f (hare) # Заяц и черепаха движутся с одинаковой скоростью mu + = 1 # Найдите длину самого короткого цикла, начиная с x_μ # Заяц делает шаг за шагом, пока черепаха неподвижна. # lam увеличивается до тех пор, пока не будет найдено λ. lam = 1 hare = f (черепаха) while tortoise! = hare: hare = f (hare) lam + = 1 return lam, mu
Этот код обращается к последовательности только путем сохранения и копирования указателей, оценок функций и тестов на равенство ; поэтому он квалифицируется как алгоритм указателя. Алгоритм использует O (λ + μ) операций этих типов и O (1) дискового пространства.
Ричард П. Брент описал альтернативный алгоритм обнаружения цикла, который, как и Алгоритм черепахи и зайца требует только двух указателей в последовательности. Однако он основан на другом принципе: поиск наименьшей степени двойки 2, которая больше, чем λ и μ. Для i = 0, 1, 2,... алгоритм сравнивает x 2−1 с каждым последующим значением последовательности до следующей степени двойки и останавливается, когда находит совпадение. Он имеет два преимущества по сравнению с алгоритмом черепахи и зайца: он находит правильную длину цикла λ напрямую, вместо того, чтобы искать ее на следующем этапе, и его шаги включают только одну оценку f, а не три.
Следующий код Python более подробно показывает, как этот метод работает.
def brent (f, x0): # основная фаза: поиск последовательных степеней двойки power = lam = 1 tortoise = x0 hare = f (x0) # f (x0) - это элемент / узел рядом с x0. while tortoise! = hare: if power == lam: # пора начинать новую силу двойки? tortoise = hare power * = 2 lam = 0 hare = f (hare) lam + = 1 # Найти позицию первого повторения длины λ tortoise = hare = x0 для i in range (lam): # range (lam) производит список со значениями 0, 1,..., lam-1 hare = f (hare) # Теперь расстояние между зайцем и черепахой равно λ. # Затем заяц и черепаха движутся с одинаковой скоростью, пока не согласятся, что mu = 0, а черепаха! = Hare: tortoise = f (tortoise) hare = f (hare) mu + = 1 return lam, mu
Как черепаха и hare алгоритм, это алгоритм указателя, который использует O (λ + μ) тестов и оценок функций и O (1) дискового пространства. Нетрудно показать, что количество вычислений функций никогда не может быть больше, чем для алгоритма Флойда. Брент утверждает, что в среднем его алгоритм поиска циклов работает примерно на 36% быстрее, чем алгоритм Флойда, и что он ускоряет алгоритм Полларда примерно на 24%. Он также выполняет анализ среднего случая для рандомизированной версии алгоритма, в которой последовательность индексов, отслеживаемых более медленным из двух указателей, не является степенью двойки, а скорее рандомизированным кратным степеням. из двух. Хотя его основное предполагаемое применение было в алгоритмах целочисленной факторизации, Брент также обсуждает приложения для тестирования генераторов псевдослучайных чисел.
R. Алгоритм У. Госпера находит период 



Основная особенность алгоритма Госпера заключается в том, что он никогда не выполняет резервное копирование для переоценки генератора функции и экономичен как в пространстве, так и во времени. Это можно примерно описать как параллельную версию алгоритма Брента. В то время как алгоритм Брента постепенно увеличивает разрыв между черепахой и зайцем, алгоритм Госпера использует несколько черепах (сохраняются несколько предыдущих значений), которые расположены примерно по экспоненте. Согласно примечанию в элементе 132 HAKMEM, этот алгоритм обнаружит повторение перед третьим появлением любого значения, например. цикл будет повторяться не более двух раз. В этом примечании также говорится, что достаточно сохранить 


После 






Ряд авторов изучили методы обнаружения цикла, которые используют больше памяти, чем методы Флойда и Брента, но обнаруживают циклы быстрее. Как правило, эти методы хранят несколько ранее вычисленных значений последовательности и проверяют, равно ли каждое новое значение одному из ранее вычисленных значений. Чтобы сделать это быстро, они обычно используют хэш-таблицу или аналогичную структуру данных для хранения ранее вычисленных значений и, следовательно, не являются алгоритмами указателя: в частности, они обычно не могут быть применены к алгоритму rho Полларда.. Эти методы различаются тем, как они определяют, какие значения хранить. Следуя Nivasch, мы кратко рассмотрим эти методы.
 оценки функции для некоторой константы c, которая, по их мнению, является оптимальной. Этот метод включает поддержание числового параметра d, сохранение в таблице только тех позиций в последовательности, которые кратны d, очистку таблицы и удвоение d всякий раз, когда было сохранено слишком много значений.
оценки функции для некоторой константы c, которая, по их мнению, является оптимальной. Этот метод включает поддержание числового параметра d, сохранение в таблице только тех позиций в последовательности, которые кратны d, очистку таблицы и удвоение d всякий раз, когда было сохранено слишком много значений.Любой алгоритм обнаружения цикла, который хранит не более M значений из входной последовательности, должен выполнить не менее 
Обнаружение цикла использовалось во многих приложениях.
* print-circle *обнаруживает кольцевую структуру списка и печатает ее компактно.