A Доля населения, обычно обозначается  или Греческая буква
или Греческая буква  - это параметр, который описывает процентное значение, связанное с генеральной совокупностью. Например, Перепись США 2010 года показала, что 83,7% американского населения были идентифицированы как не латиноамериканцы или латиноамериканцы. Значение 0,837 - это доля населения. В целом, доля населения и другие параметры популяции неизвестны. перепись может быть проведена для определения фактического значения параметра численности населения, но часто перепись нецелесообразна из-за ее затрат и затрат времени.
- это параметр, который описывает процентное значение, связанное с генеральной совокупностью. Например, Перепись США 2010 года показала, что 83,7% американского населения были идентифицированы как не латиноамериканцы или латиноамериканцы. Значение 0,837 - это доля населения. В целом, доля населения и другие параметры популяции неизвестны. перепись может быть проведена для определения фактического значения параметра численности населения, но часто перепись нецелесообразна из-за ее затрат и затрат времени.
Доля населения обычно оценивается с помощью несмещенной выборочной статистики, полученной в ходе наблюдательного исследования или эксперимента. Например, Национальная конференция по технологической грамотности провела национальный опрос 2000 взрослых, чтобы определить процент экономически неграмотных взрослых. Исследование показало, что 72% из 2000 отобранных взрослых не понимают, что такое валовой внутренний продукт. Значение 72% - это примерная пропорция. Образец пропорции обычно обозначается  , а в некоторых учебниках -
, а в некоторых учебниках -  .
.
Contents
- 1 Математическое определение
- 2 Оценка
- 2.1 Доказательство
- 2.2 Условия для вывода
- 2.3 Пример
- 2.4 Значение параметра в доверительном интервале
- 2.5 Общее ошибки и неверные интерпретации оценки
- 3 См. также
- 4 Ссылки
Математическое определение
Иллюстрация диаграммы Венна набора

и его подмножества

. Долю можно рассчитать, измерив, сколько из
находится в
.
A пропорция математически определяется как отношение значений в подмножестве до значений в наборе .
Таким образом, долю населения можно определить следующим образом :
 (где
(где  - количество успехов в генеральной совокупности, и
- количество успехов в генеральной совокупности, и  - размер совокупности)
- размер совокупности)
Это математическое определение можно обобщить, чтобы обеспечить определение доли выборки:
 (где
(где  - количество успехов в выборке, а
- количество успехов в выборке, а  - размер выборки, полученной из генеральной совокупности)
- размер выборки, полученной из генеральной совокупности)
Оценка
Одним из основных направлений исследований вывести Общая статистика определяет «истинное» значение параметра. Как правило, фактическое значение параметра никогда не будет найдено, если только не будет проведена перепись изучаемого населения. Однако существуют статистические методы, которые можно использовать для получения разумной оценки параметра. Эти методы включают доверительные интервалы и проверку гипотез.
Оценка стоимости доли населения может иметь большое значение в областях сельского хозяйства, бизнеса, экономика, образование, инженерия, экология, медицина, право, политология, психология и социология.
Доля населения может быть оценена с помощью доверительного интервала, известного как доля одной выборки в Z-интервал, формула которого приведена ниже:
 (где - пропорция выборки, - размер выборки, а
(где - пропорция выборки, - размер выборки, а  - верхнее
- верхнее  критическое значение стандартного стандартного дистрибутива ution для уровня достоверности
критическое значение стандартного стандартного дистрибутива ution для уровня достоверности  )
)
Proof
Чтобы вывести формулу для доли одной выборки в Z-интервале, необходимо учитывать распределение выборки пропорций выборки. Среднее значение выборочного распределения пропорций выборки обычно обозначается как  , а его стандартное отклонение обозначается как
, а его стандартное отклонение обозначается как  . Поскольку значение неизвестно, будет использоваться несмещенная статистика для . Среднее значение и стандартное отклонение переписываются как
. Поскольку значение неизвестно, будет использоваться несмещенная статистика для . Среднее значение и стандартное отклонение переписываются как  и
и  соответственно. Ссылаясь на центральную предельную теорему , выборочное распределение пропорций выборки приблизительно нормальное - при условии, что выборка достаточно велика и не перекручена.
соответственно. Ссылаясь на центральную предельную теорему , выборочное распределение пропорций выборки приблизительно нормальное - при условии, что выборка достаточно велика и не перекручена.
Предположим, вычислена следующая вероятность:

Выборочное распределение пропорций образца приблизительно нормально, когда оно удовлетворяет требованиям Центральной предельной теоремы.
Неравенство
Условия вывода
Как правило, формула, используемая для оценки доли населения, требует подстановки известных числовых значений. Однако эти числовые значения нельзя подставлять в формулу «вслепую», поскольку статистический вывод r требует, чтобы оценка неизвестного параметра была обоснованной. Чтобы оценка параметра была обоснованной, необходимо проверить три условия:
- Индивидуальное наблюдение данных должно быть получено из простой случайной выборки из представляющей интерес совокупности.
- Отдельные наблюдения данных должны отображать нормальность. Это можно проверить математически с помощью следующего определения:
- Пусть будет размером данной случайной выборки, и пусть - пропорция выборки. Если
 и
и  , то отдельные наблюдения данных отображают нормальность.
, то отдельные наблюдения данных отображают нормальность.
- Отдельные наблюдения данных должны быть независимыми друг от друга. Это можно проверить математически с помощью следующего определения:
- Пусть будет размером исследуемой совокупности, и пусть быть размером простой случайной выборки генеральной совокупности. Если
 , то отдельные наблюдения данных не зависят друг от друга.
, то отдельные наблюдения данных не зависят друг от друга.
Иногда упоминаются условия для SRS, нормальности и независимости в качестве условий для инструмента вывода в большинстве статистических учебников.
Пример
Предположим, что президентские выборы проходят в условиях демократии. Случайная выборка из 400 имеющих право голоса избирателей среди демократических избирателей показывает, что 272 избирателя поддерживают кандидата B. Политолог хочет определить, какой процент избирателей поддерживает кандидата B.
Чтобы ответить на вопрос политолога, a Одновыборочная пропорция в Z-интервале с уровнем достоверности 95% может быть построена для определения доли правомочных избирателей в этой демократии, которые поддерживают кандидата Б.
Решение
Из случайной выборки известно, что  с выборкой размер
с выборкой размер  . Перед построением доверительного интервала будут проверены условия вывода.
. Перед построением доверительного интервала будут проверены условия вывода.
- Поскольку случайная выборка из 400 избирателей была получена из голосующих, условие для простой случайной выборки было выполнено.
- Пусть и
 , будет проверяться, и
, будет проверяться, и
 и
и 
- Выполнено условие нормальности.
- Пусть будет численностью избирателей в этой демократии, и пусть . Если , тогда существует независимость.

- Можно предположить, что численность населения для избирателей этой демократии составляет не менее 4000. Следовательно, условие независимости выполнено.
После проверки условий вывода допустимо построить доверительный интервал.
Пусть  и
и 
Чтобы найти для , выражение .


Стандартная нормальная кривая с
, что дает площадь верхнего хвоста 0,0250 и площадь 0,9750 для

.
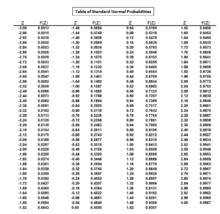
Таблица со стандартными нормальными вероятностями для

.
путем изучения стандартная нормальная колоколообразная кривая, значение для может быть определено путем определения того, какой стандартный балл дает стандартной нормальной кривой площадь верхнего хвоста 0,0250 или площадь из 1 - 0,0250 = 0,9750. Значение для также можно найти с помощью таблицы стандартных нормальных вероятностей.
Из таблицы стандартных нормальных вероятностей значение  , которое дает площадь 0,9750, составляет 1,96. Следовательно, значение для равно 1,96.
, которое дает площадь 0,9750, составляет 1,96. Следовательно, значение для равно 1,96.
Значения для , ,  теперь можно подставить в формулу для одновыборочной пропорции в интервале Z:
теперь можно подставить в формулу для одновыборочной пропорции в интервале Z:


Основываясь на условиях вывода и формуле для доли одной выборки в интервале Z, с уровнем достоверности 95% можно сделать вывод, что процент населения избирателя в этой демократии, поддерживающего кандидата B, составляет от 63,429% до 72,571%.
Значение параметра в диапазоне доверительного интервала
Часто задаваемый вопрос в выводной статистике: включен ли параметр в доверительный интервал. Единственный способ ответить на этот вопрос - провести перепись. Ссылаясь на пример, приведенный выше, вероятность того, что доля населения находится в диапазоне доверительного интервала, равна либо 1, либо 0. То есть, параметр включен в диапазон интервала или нет. Основная цель доверительного интервала - лучше проиллюстрировать, каким может быть идеальное значение параметра.
Распространенные ошибки и неверные интерпретации оценки
Очень распространенной ошибкой, возникающей при построении доверительного интервала, является убеждение в том, что уровень достоверности, например  , означает вероятность 95%. Это неверно. Уровень уверенности основан на степени достоверности, а не вероятности. Следовательно, значения находятся исключительно между 0 и 1.
, означает вероятность 95%. Это неверно. Уровень уверенности основан на степени достоверности, а не вероятности. Следовательно, значения находятся исключительно между 0 и 1.
См. Также
Литература

 Иллюстрация диаграммы Венна набора
Иллюстрация диаграммы Венна набора  Выборочное распределение пропорций образца приблизительно нормально, когда оно удовлетворяет требованиям Центральной предельной теоремы.
Выборочное распределение пропорций образца приблизительно нормально, когда оно удовлетворяет требованиям Центральной предельной теоремы.
 Стандартная нормальная кривая с
Стандартная нормальная кривая с  Таблица со стандартными нормальными вероятностями для
Таблица со стандартными нормальными вероятностями для