
Войти
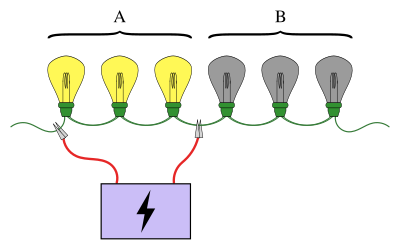 Иллюстрация проблемы с лампочкой, где среди шести лампочек ищут сломанную лампочку. Здесь первые три подключены к источнику питания, и они загораются (A). Это означает, что сломанная лампа должна быть одной из трех последних (B). Если бы вместо этого лампочки не загорелись, можно было быть уверенным, что сломанная лампочка была среди первых трех. Продолжая эту процедуру, можно найти сломанную лампу не более чем в трех тестах, по сравнению с максимум шестью тестами, если лампы проверяются индивидуально.
Иллюстрация проблемы с лампочкой, где среди шести лампочек ищут сломанную лампочку. Здесь первые три подключены к источнику питания, и они загораются (A). Это означает, что сломанная лампа должна быть одной из трех последних (B). Если бы вместо этого лампочки не загорелись, можно было быть уверенным, что сломанная лампочка была среди первых трех. Продолжая эту процедуру, можно найти сломанную лампу не более чем в трех тестах, по сравнению с максимум шестью тестами, если лампы проверяются индивидуально. В статистике и комбинаторной математике, групповое тестирование - это любая процедура, которая разбивает задачу идентификации определенных объектов на тесты по группам элементов, а не по отдельным. Групповое тестирование, впервые изученное Робертом Дорфманом в 1943 году, представляет собой относительно новую область прикладной математики, которая может применяться к широкому кругу практических приложений и является активной областью исследований сегодня.
Знакомый пример группового тестирования включает последовательность лампочек, соединенных последовательно, причем известно, что одна из ламп сломана. Цель состоит в том, чтобы найти сломанную лампочку с помощью наименьшего количества тестов (где тест - это когда некоторые из лампочек подключены к источнику питания). Простой подход - проверить каждую лампочку индивидуально. Однако при большом количестве луковиц гораздо эффективнее объединять луковицы в группы. Например, подключив первую половину ламп сразу, можно определить, в какой половине разбитая лампочка, исключив половину ламп всего за один тест.
Схемы для проведения группового тестирования могут быть простыми или сложными, и тесты, задействованные на каждом этапе, могут быть разными. Схемы, в которых тесты для следующего этапа зависят от результатов предыдущих этапов, называются адаптивными процедурами, а схемы, разработанные так, чтобы все тесты были известны заранее, называются неадаптивными процедурами. Структура схемы тестов, задействованных в неадаптивной процедуре, известна как план объединения.
Групповое тестирование имеет множество приложений, включая статистику, биологию, информатику, медицину, инженерию и кибербезопасность. Современный интерес к этим схемам тестирования возродился благодаря проекту Human Genome Project.
В отличие от многих областей математики происхождение группового тестирования можно проследить до одного отчета, написанного одним человеком: Роберт Дорфман. Мотивация возникла во время Второй мировой войны, когда Служба общественного здравоохранения США и Служба выборочного контроля приступили к крупномасштабному проекту по отсеиванию всех сифилитических мужчин. вызвали на индукцию. Тестирование человека на сифилис включает взятие у него образца крови, а затем анализ этого образца для определения наличия или отсутствия сифилиса. В то время выполнение этого теста было дорогостоящим, а тестирование каждого солдата по отдельности было бы очень дорогим и неэффективным.
Предположим, что есть 
Пункты, которые вызывают положительный результат теста в группе, обычно являются называются бракованными предметами (это сломанные лампочки, сифилитики и т. д.). Часто общее количество элементов обозначается как 
Есть две независимые классификации проблем группового тестирования; каждая проблема группового тестирования является либо адаптивной, либо неадаптивной, либо вероятностной, либо комбинаторной.
В вероятностных моделях предполагается, что дефектные элементы подчиняются некоторому распределению вероятностей, и цель состоит в том, чтобы свести к минимуму ожидаемое количество тестов, необходимых для выявления дефектности каждого элемента. С другой стороны, при комбинаторном групповом тестировании цель состоит в том, чтобы минимизировать количество тестов, необходимых в «наихудшем сценарии», то есть создать алгоритм minmax, и не знать распределения предполагается наличие дефектов.
Другая классификация, адаптивность, касается того, какую информацию можно использовать при выборе элементов для группировки в тест. Как правило, выбор элементов для тестирования может зависеть от результатов предыдущих тестов, как в случае с лампочкой выше. Алгоритм , который продолжает выполнение теста, а затем использует результат (и все прошлые результаты), чтобы решить, какой следующий тест выполнить, называется адаптивным. И наоборот, в неадаптивных алгоритмах все тесты решаются заранее. Эту идею можно обобщить на многоступенчатые алгоритмы, где тесты разделены на этапы, и каждый тест на следующем этапе должен быть решен заранее, только с учетом результатов тестов на предыдущих этапах. Хотя адаптивные алгоритмы предлагают гораздо больше свободы в разработке, известно, что алгоритмы адаптивного группового тестирования не улучшают неадаптивные алгоритмы более чем на постоянный коэффициент в количестве тестов, необходимых для выявления набора дефектных элементов. В дополнение к этому неадаптивные методы часто полезны на практике, потому что можно продолжить последовательные тесты без предварительного анализа результатов всех предыдущих тестов, что позволяет эффективно распределить процесс тестирования.
Есть много способов расширить проблему группового тестирования. Одно из наиболее важных - это групповое тестирование с шумом, и оно связано с большим предположением об исходной проблеме: это тестирование безошибочно. Проблема группового тестирования называется зашумленной, если есть некоторая вероятность того, что результат группового теста будет ошибочным (например, будет положительным, если тест не содержит дефектов). Модель шума Бернулли предполагает, что эта вероятность является некоторой константой, 
Групповое тестирование можно расширить, рассматривая сценарии, в которых существует более двух возможных результатов теста. Например, тест может иметь результаты 



Другое расширение - рассмотрение геометрических ограничений на то, какие наборы могут быть проверены. Вышеупомянутая проблема с лампочкой является примером такого ограничения: только лампочки, которые появляются последовательно, могут быть проверены. Аналогичным образом элементы могут быть расположены по кругу или, в общем, в виде сети, где тесты представляют собой доступные пути на графе. Другой вид геометрического ограничения - это максимальное количество элементов, которые могут быть протестированы в группе, или размеры групп могут быть одинаковыми и так далее. Подобным образом может быть полезно рассмотреть ограничение, согласно которому любой заданный элемент может появляться только в определенном количестве тестов.
Есть бесконечные способы продолжить переделывать базовую формулу группового тестирования. Следующие уточнения дадут представление о некоторых из наиболее экзотических вариантов. В модели «хорошо – посредственно – плохо» каждый элемент является одним из «хорошо», «посредственно» или «плохо», а результат теста является типом «худшего» элемента в группе. При пороговом групповом тестировании результат теста положительный, если количество дефектных элементов в группе превышает некоторое пороговое значение или пропорцию. Групповое тестирование с ингибиторами - это вариант с приложениями в молекулярной биологии. Здесь есть третий класс элементов, называемых ингибиторами, и результат теста положительный, если он содержит хотя бы один дефект и не содержит ингибиторов.
Концепция группового тестирования была впервые представлена Робертом Дорфманом в 1943 году в коротком отчете, опубликованном в разделе «Примечания» журнала Annals of Mathematical Statistics. Отчет Дорфмана - как и все ранние работы по групповому тестированию - был сосредоточен на вероятностной проблеме и был направлен на использование новой идеи группового тестирования, чтобы сократить ожидаемое количество тестов, необходимых для отсеивания всех сифилитических мужчин в данном пуле солдат. Метод был прост: разделите солдат на группы заданного размера и используйте индивидуальное тестирование (тестирование предметов в группах первого размера) на положительных группах, чтобы определить, какие из них были инфицированы. Дорфман свел в таблицу оптимальные размеры групп для этой стратегии с учетом уровня распространенности дефективности в популяции.
После 1943 года групповое тестирование оставалось в основном неизменным в течение ряда лет. Затем в 1957 году Стерретт улучшил процедуру Дорфмана. Этот новый процесс начинается с повторного индивидуального тестирования положительных групп, но останавливается, как только обнаруживается дефект. Затем остальные элементы в группе проверяются вместе, поскольку очень вероятно, что ни один из них не является дефектным.
Первое тщательное рассмотрение группового тестирования было дано Собелом и Гроллом в их формирующей статье 1959 года по этому вопросу. Они описали пять новых процедур - в дополнение к обобщениям для случаев, когда уровень распространенности неизвестен - и для наиболее оптимальной из них они предоставили явную формулу для ожидаемого количества тестов, которые она будет использовать. В статье также впервые была установлена связь между групповым тестированием и теорией информации, а также обсуждены некоторые обобщения проблемы группового тестирования и представлены некоторые новые приложения теории.
Групповое тестирование было впервые изучено в комбинаторном контексте Ли в 1962 году с введением Ли 


Комбинаторное групповое тестирование в целом было позже более полно изучено Катоной в 1973 году. Катона представила матричное представление неадаптивного группового тестирования и разработала процедуру для поиска дефектов в неадаптивных -адаптивный 1-дефектный случай не более чем 
В общем, найти оптимальные алгоритмы для адаптивного комбинаторного группового тестирования сложно, и хотя вычислительная сложность группового тестирования не была определена, предполагается, что это сложно в каком-то классе сложности. Однако в 1972 году произошел важный прорыв с введением обобщенного алгоритма двоичного расщепления. Обобщенный алгоритм двоичного разделения работает, выполняя двоичный поиск в группах с положительным результатом теста, и представляет собой простой алгоритм, который находит один дефект не более чем в нижней границе информации количество тестов.
В сценариях, где есть два или более дефекта, обобщенный алгоритм двоичного разделения по-прежнему дает почти оптимальные результаты, требуя не более 



Остается открытым вопрос, когда индивидуальное тестирование составляет minmax. Ху, Хван и Ван показали в 1981 году, что индивидуальное тестирование минимально, когда 



Одним из ключевых выводов неадаптивного группового тестирования является то, что значительный выигрыш может быть получен путем устранения требования о том, что процедура группового тестирования b Он наверняка увенчается успехом («комбинаторная» проблема), но скорее позволит ему иметь некоторую низкую, но ненулевую вероятность неправильной маркировки каждого элемента («вероятностная» проблема). Известно, что по мере того, как количество дефектных элементов приближается к общему количеству элементов, точные комбинаторные решения требуют значительно большего количества тестов, чем вероятностные решения - даже вероятностные решения допускают только асимптотически малую вероятность ошибки.
В этом ключе Chan et al. (2011) представили COMP, вероятностный алгоритм, который требует не более 


Чан и др. (2011) также представили обобщение COMP до простой шумной модели и аналогичным образом получили явную границу производительности, которая снова была только константой (зависящей от вероятности неудачного теста) выше соответствующей нижней границы. В общем, количество тестов, требуемых в случае шума Бернулли, на постоянный коэффициент больше, чем в случае отсутствия шума.
Олдридж, Балдассини и Джонсон (2014) разработали расширение алгоритма COMP, которое добавило дополнительные пост- этапы обработки. Они показали, что производительность этого нового алгоритма, названного DD, строго превосходит производительность COMP, и что DD является «по существу оптимальным» в сценариях, где 
В этом разделе формально определены понятия и термины, относящиеся к групповому тестированию.
 , определяется как двоичный вектор длины (то есть
, определяется как двоичный вектор длины (то есть  ), причем j-й элемент называется дефектным тогда и только тогда, когда
), причем j-й элемент называется дефектным тогда и только тогда, когда  . Кроме того, любой исправный элемент называется «хорошим».
. Кроме того, любой исправный элемент называется «хорошим».
будет входным вектором. Набор,  называется тестом. При бесшумном тестировании результат теста положительный, если существует
называется тестом. При бесшумном тестировании результат теста положительный, если существует  такое, что , в противном случае результат будет отрицательным.
такое, что , в противном случае результат будет отрицательным.Таким образом, цель группового тестирования состоит в том, чтобы найти метод выбора «короткой» серии тестов, допускающих
 обозначает минимальное количество необходимых тестов. всегда находить дефектных элементов среди элементов с нулевой вероятностью ошибки с помощью любого алгоритма группового тестирования. Для того же количества, но с ограничением, что алгоритм является неадаптивным, обозначение
обозначает минимальное количество необходимых тестов. всегда находить дефектных элементов среди элементов с нулевой вероятностью ошибки с помощью любого алгоритма группового тестирования. Для того же количества, но с ограничением, что алгоритм является неадаптивным, обозначение 
Поскольку всегда можно прибегнуть к индивидуальному тестированию, установив 





В итоге (если принять 
Нижняя граница количества необходимых тестов может быть описана с использованием понятия пространства выборки, обозначенного 


Однако сама по себе нижняя граница информации обычно недостижима даже для небольших задач. Это связано с тем, что разделение
Фактически, нижняя граница информации может быть обобщена на случай, когда существует ненулевая вероятность того, что алгоритм совершит ошибку. В этой форме теорема дает нам верхнюю границу вероятности успеха, основанную на количестве тестов. Для любого алгоритма группового тестирования, который выполняет 


 Типичная установка для группового тестирования. Неадаптивный алгоритм сначала выбирает матрицу
Типичная установка для группового тестирования. Неадаптивный алгоритм сначала выбирает матрицу  , а затем получает вектор y . Тогда задача состоит в том, чтобы найти оценку для x.
, а затем получает вектор y . Тогда задача состоит в том, чтобы найти оценку для x.. Алгоритмы для неадаптивного группового тестирования состоят из двух отдельных фаз. Во-первых, решается, сколько тестов выполнить и какие элементы включить в каждый тест. На втором этапе, который часто называют этапом декодирования, результаты каждого группового теста анализируются, чтобы определить, какие элементы могут быть дефектными. Первый этап обычно кодируется в матрице следующим образом.
элементов состоит из тестов  для некоторых
для некоторых  . Матрица тестирования для этой схемы - это двоичная матрица
. Матрица тестирования для этой схемы - это двоичная матрица  , , где
, , где  тогда и только тогда, когда
тогда и только тогда, когда  (в противном случае - ноль).
(в противном случае - ноль).Таким образом, каждый столбец 




А также вектор
будет количеством тестов, выполненных неадаптивным алгоритмом. Вектор результата,  , является двоичным вектором длины (то есть
, является двоичным вектором длины (то есть  ) так, что
) так, что  тогда и только тогда, когда результат теста был положительным (т. е. содержал по крайней мере один дефект).
тогда и только тогда, когда результат теста был положительным (т. е. содержал по крайней мере один дефект).С этими определениями не- адаптивную задачу можно переформулировать следующим образом: сначала выбирается тестовая матрица 
в простейшем шумном в случае, когда существует постоянная вероятность, 



Матричное представление позволяет доказать некоторые границы для не- адаптивное групповое тестирование. Этот подход отражает подход многих детерминированных планов, где рассматриваются
, называется -разделимостью, если каждая логическая сумма (логическое ИЛИ) любого его столбцов различны. Кроме того, запись  -separable указывает, что каждая сумма любого из до из отличаются (это не то же самое, что быть
-separable указывает, что каждая сумма любого из до из отличаются (это не то же самое, что быть  -разделимым для каждого
-разделимым для каждого  .)
.)Когда
называется -разъединением, если логическая сумма любого не содержат других столбцов. (В этом контексте говорят, что столбец A содержит столбец B, если для каждого индекса, где B имеет 1, A также имеет 1.)Полезное свойство
Используя свойства матриц
 .
. .
. .
. Иллюстрация обобщенного алгоритма двоичного разбиения, где имеется 8 дефектных элементов и 135 элементов. Здесь
Иллюстрация обобщенного алгоритма двоичного разбиения, где имеется 8 дефектных элементов и 135 элементов. Здесь  , и первый тест дает отрицательный результат, поэтому каждый элемент считается исправным. Следовательно, осталось 119 элементов, поэтому
, и первый тест дает отрицательный результат, поэтому каждый элемент считается исправным. Следовательно, осталось 119 элементов, поэтому  . Эта вторая группа дает положительный результат, поэтому для поиска дефекта используется двоичный поиск. Как только это будет сделано, весь процесс повторяется, вычисляя новое
. Эта вторая группа дает положительный результат, поэтому для поиска дефекта используется двоичный поиск. Как только это будет сделано, весь процесс повторяется, вычисляя новое  , используя только те элементы, дефектность которых не была определена.
, используя только те элементы, дефектность которых не была определена. Обобщенный алгоритм двоичного разделения is an essentially-optimal adaptive group-testing algorithm that finds
 , test the items individually. Otherwise, set
, test the items individually. Otherwise, set  and
and  .
. . If the outcome is negative, every item in the group is declared to be non-defective; set
. If the outcome is negative, every item in the group is declared to be non-defective; set  and go to step 1. Otherwise, use a binary search to identify one defective and an unspecified number, called
and go to step 1. Otherwise, use a binary search to identify one defective and an unspecified number, called  , of non-defective items; set
, of non-defective items; set  and
and  . Go to step 1.
. Go to step 1.The generalised binary-splitting algorithm requires no more than 

For 





Non-adaptive group-testing algorithms tend to assume that the number of defectives, or at least a good upper bound on them, is known. This quantity is denoted
 Иллюстрация алгоритма COMP. COMP определяет элемент a как дефектный, а элемент b как исправный. Однако он ошибочно отмечает c как дефектный, поскольку он «скрывается» дефектными элементами в каждом тесте, в котором он появляется.
Иллюстрация алгоритма COMP. COMP определяет элемент a как дефектный, а элемент b как исправный. Однако он ошибочно отмечает c как дефектный, поскольку он «скрывается» дефектными элементами в каждом тесте, в котором он появляется. Комбинаторное ортогональное сопоставление преследований, или COMP, представляет собой простой неадаптивный алгоритм группового тестирования, который формирует основу для более сложных алгоритмов, которые следуют в этом разделе.
Сначала для каждой записи матрицы тестирования выбирается iid равным 
Этап декодирования выполняется по столбцам (то есть по элементам). Если все тесты, в которых появляется товар, являются положительными, то товар объявляется дефектным; в противном случае предполагается, что товар исправен. Или, что эквивалентно, если элемент появляется в любом тесте с отрицательным результатом, элемент объявляется исправным; в противном случае предполагается, что товар неисправен. Важным свойством этого алгоритма является то, что он никогда не создает ложных отрицательных результатов, хотя ложноположительных результатов возникает, когда все местоположения с единицами в j-м столбце
Алгоритм COMP требует не более 
В шумном случае ослабляется требование исходного алгоритма COMP, согласно которому набор местоположений единиц в любом столбце 
Определенные дефекты (DD) расширением алгоритма COMP, который пытается удалить любые ложные срабатывания. Было показано, что гарантии для DD строго превышают таковые для COMP.
На этапе декодирования используется полезное свойство алгоритма COMP: элемент, который COMP объявляет исправным, безусловно, исправен (т. Е. ложных негативов нет). Происходит это следующим образом.
Обратите внимание, что шаги 1 и 2 не допускают ошибок, поэтому алгоритм может сделать ошибку только в том случае, если он объявляет дефектный элемент не должен быть дефектным. Таким образом, алгоритм DD может создать только ложноотрицательные результаты.
SCOMP (Sequential COMP) - это алгоритм, который использует тот факт, что DD не допускает ошибок до последнего шага, где гарантированы оставшиеся элементы исправный. Пусть набор заявленных дефектов будет 
Алгоритм работает следующим образом.
, начальную оценку для набора дефектов.объясняет каждый положительный тест, завершите алгоритм: - окончательная оценка для набора дефектов.). Переходите к шагу 2.При моделировании было показано, что SCOMP работает близко к оптимальному.
Обобщенность теории группового тестирования позволяет использовать ее во многих приложениях, включая скрининг клонов, обнаружение коротких замыканий; высокоскоростные компьютерные сети; медицинское обследование, количественный поиск, статистика; машинное обучение, секвенирование ДНК; криптография; и судебная экспертиза данных. В этом разделе представлен краткий обзор небольшой подборки этих приложений.
 Иллюстрация множественного доступа, показывающая успешное сообщение и конфликт сообщений.
Иллюстрация множественного доступа, показывающая успешное сообщение и конфликт сообщений. A канал множественного доступа - это канал связи, который соединяет сразу несколько пользователей. Каждый пользователь может одновременно передавать и передавать передачу, сигналы сталкиваются и превращаются в неразборчивый шум. Каналы множественного доступа важны для различных приложений, особенно для беспроводных компьютерных сетей и телефонных сетей.
Важная проблема с форматами множественного доступа в том, как назначать время передачи пользователям, чтобы их сообщения не конфликтовали. Простой способ - предоставить каждому свой собственный временной интервал для передачи, что требует
В контексте группового тестирования эта проблема обычно решается путем разделения времени на «эпохи» следующим образом. Пользователь называется «активным», если у него есть сообщение в начале эпохи. (Если сообщение создается в течение эпохи, пользователь становится активным только в начале следующей.) Эпоха заканчивается, когда каждый активный пользователь успешно передал свое сообщение. Тогда проблема состоит в том, чтобы найти всех активных пользователей в заданную эпоху и запланировать для них время передачи (если они еще не сделали это успешно). Здесь тест на группе пользователей соответствует тем пользователям, которые выполняют передачу. Результатом теста является количество пользователей, которые пытались передать, 

Машинное обучение - это область компьютерных наук, в которой есть набор программных приложений, таких как классификация ДНК, обнаружение мошенничества и таргетированная реклама. Одним из основных подразделов машинного обучения является проблема «обучения на примерах», где задача состоит в том, чтобы аппроксимировать некоторую неизвестную функцию, когда ей задано ее в некоторых точках. Как указано в этом разделе, эту проблему обучения функциям можно решить с помощью подхода группового тестирования.
В простой версии задачи есть неизвестная функция, 





В этой задаче восстановление 


На f: CN → C {\ displaystyle f: \ mathbb {C} ^ {N} \ to \ mathbb {C}}
В сжатом зондировании цель состоит в том, чтобы восстановить сигнал, 




Основная трудность при распознавании сжатых данных в том, чтобы определить, какие записи являются важными. Как только это будет сделано, существует множество методов для оценки фактических значений записей. К этойчести идентификации можно подойти с помощью простого группового тестирования. Здесь групповой тест дает комплексное число: сумма проверенных записей. Результат теста называется положительным, если он дает комплексное число с большой величиной, что при предположении, что значимые записи редки, указывает на то, что в крайней мере одна значимая запись.
Существуют явные детерминированные конструкции для этого типа комбинаторного алгоритма поиска, требующие 

Во время пандемии, такой как вспышка COVID-19 в 2020 году, тесты на обнаружение вирусов иногда запускаются с использованием неадаптивных групповых тестов. Один из примеров был предоставлен проект Origami Assays, который выпустил проекты группового тестирования с открытым исходным кодом для запуска на лабораторном стандартном 96-луночном планшете.
 Бумажный шаблон Origami Assay для дизайна группового тестирования
Бумажный шаблон Origami Assay для дизайна группового тестирования В лабораторных условиях одна проблема группового тестирования Строительство из смесей может занять много времени и его сложно выполнить вручную. Анализы Origami предоставили образцы для этой задачи с построением, предоставив бумажные шаблоны, которые помогли технику распределять образцы по лункам.
Используя самые большие схемы группового тестирования (XL3), можно было протестировать 1120 образцов в 94 пробирных лунках. Если количество истинно положительных результатов было достаточно низкое, то дополнительное тестирование не требовалось.
См. Также: Список стран, реализующих стратегию пулового тестирования на COVID-19.
Криминалистика данных - это область, посвященная поиску методов для сбора цифровых доказательств преступлений. Такие случаи обычно связаны с изменением злоумышленником данных, документов или баз данных жертвы, в том числе, например, изменение налоговой отчетности, вирус, скрывающий свое присутствие, или похититель данных, изменяющий личные данные.
Обычный инструмент в криминалистика данных - это односторонний криптографический хэш. Функция, которая принимает данные и с помощью труднообратимой процедуры выдает уникальный номер, называемый хешем. Хэши, которые часто намного короче, чем данные, позволяют без необходимости расточить полные копии информации: хэш для текущих данных можно сравнить с прошлым хешем, чтобы определить, есть ли какие-либо изменения произошли. Как узнать, каким образом определить, каким образом, каким образом, каким образом определить, каким образом были установлены данные, нет, каким образом невозможно восстановить, какая часть данных была изменена.
Один из способов обойти это ограничение - сохранить больше хэшей - теперь уже подмножеств структуры - чтобы сузить область, где произошла атака. Однако, чтобы найти точное место атаки с помощью наивного подхода, хэш должен быть сохранен для каждого элемента данных в структуре, что в первую очередь приведет к поражению точки хешей. (Можно также хранить обычную копию данных.) Групповое тестирование можно использовать для значительного уменьшения количества хэшей, которые необходимо сохранить. Тест становится сравнением сохраненных и текущих хэшей, которое является положительным при несоответствии. Это указывает на то, что по крайней мере одна отредактированная база данных (которая в данной модели считается дефектной) содержится в группе, которая сгенерировала текущий хэш.
Фактически, количество необходимых хешей настолько мало, что они могут использоваться вместе с матрицами, чтобы они могли храниться в организационной структуре самих себя. Это означает, что касается памяти, тест можно проводить «бесплатно». (Это верно за исключением мастер-ключа / пароля, который используется для тайного определения хэш-функций.)