
Войти
Аварийное восстановление включает в себя набор политик, инструментов и процедур для обеспечения возможности восстановления или продолжения жизненно важной технологической инфраструктуры и систем после естественной или вызванной человеком катастрофы. Аварийное восстановление сосредотачивается на ИТ или технологических системах, поддерживающих критически важные бизнес-функции, в отличие от непрерывности бизнеса, которая включает в себя поддержание всех основных аспектов функционирования бизнеса, несмотря на серьезные разрушительные события. Таким образом, аварийное восстановление можно рассматривать как часть обеспечения непрерывности бизнеса. Аварийное восстановление предполагает, что первичный сайт не подлежит восстановлению (по крайней мере, в течение некоторого времени), и представляет собой процесс восстановления данных и сервисов на вторичном уцелевшем сайте, который противоположен процесс восстановления на прежнее место.
ИТ Непрерывность обслуживания (ITSC) - это подмножество планирования непрерывности бизнеса (BCP) и включает планирование ИТ аварийного восстановления и более широкое планирование устойчивости ИТ. Он также включает в себя те элементы ИТ-инфраструктуры и услуг, которые относятся к коммуникациям, такие как (голосовая) телефония и передача данных.
План ITSC отражает целевую точку восстановления (RPO - последние транзакции) и целевое время восстановления (RTO - временные интервалы).
Планирование включает организацию резервных сайтов, будь то горячие, теплые, холодные или резервные сайты, с оборудованием, необходимым для непрерывности.
В 2008 году Британский институт стандартов запустил специальный стандарт, связанный и поддерживающий Стандарт непрерывности бизнеса BS 25999 под названием BS25777, специально для согласования непрерывности работы компьютеров с непрерывностью бизнеса. Он был отозван после публикации в марте 2011 года стандарта ISO / IEC 27031 - Методы безопасности - Руководство по готовности информационных и коммуникационных технологий для обеспечения непрерывности бизнеса.
ITIL дал определение некоторых из этих терминов.
Целевое время восстановления (RTO ) является целевая продолжительность времени и уровень обслуживания, в пределах которого бизнес-процесс должен быть восстановлен после аварии (или сбоя), чтобы избежать неприемлемых последствий, связанных с нарушением непрерывности бизнеса.
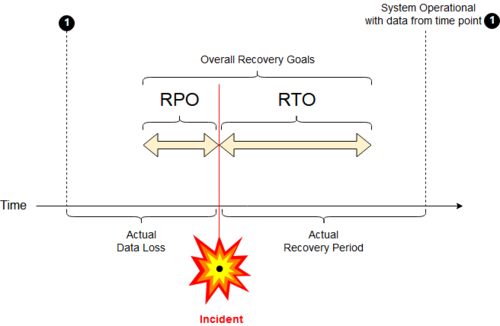 Схематическое изображение условий RPO и RTO. В этом примере согласованные значения RPO и RTO не выполняются.
Схематическое изображение условий RPO и RTO. В этом примере согласованные значения RPO и RTO не выполняются. В принятой методологии планирования непрерывности бизнеса RTO устанавливается во время анализа влияния на бизнес (BIA) владелец процесса, в том числе определение временных рамок вариантов для альтернативных или ручных обходных решений.
В значительной части литературы по этой теме RTO рассматривается как дополнение к цели точки восстановления (RPO) с двумя метриками, описывающими пределы приемлемого или «допустимого» «ITSC производительность с точки зрения потерянного времени (RTO) из-за нормального функционирования бизнес-процесса и с точки зрения потерянных данных или отсутствия резервной копии в течение этого периода времени (RPO) соответственно.
В обзоре Forbes отмечалось, что именно фактическое время восстановления (RTA) является «критическим показателем для непрерывности бизнеса и аварийного восстановления».
ДТП устанавливается во время учений или реальных событий. Группа обеспечения непрерывности бизнеса определяет время репетиций (или фактов) и вносит необходимые изменения.
A Целевая точка восстановления (RPO) определяется планированием непрерывности бизнеса. Это максимальный целевой период, в течение которого данные (транзакции) могут быть потеряны ИТ-службой из-за серьезного инцидента.
Если RPO измеряется в минутах (или даже в несколько часов) то на практике удаленные зеркальные резервные копии должны постоянно поддерживаться ; ежедневного резервного копирования на ленту за пределами площадки будет недостаточно.
Восстановление, которое не является мгновенным, восстановит данные / транзакции в течение определенного периода времени и сделает это без значительных риски или значительные убытки.
RPO измеряет максимальный период времени, в течение которого последние данные могли быть безвозвратно потеряны в случае серьезного инцидента, и не является прямым показателем количества таких потерь. Например, если план BC - «восстановление до последней доступной резервной копии», то RPO - это максимальный интервал между такими резервными копиями, которые были безопасно сохранены за пределами площадки.
Анализ влияния на бизнес используется для определения RPO для каждой услуги, а RPO не определяется существующим режимом резервного копирования. Когда требуется какой-либо уровень подготовки внешних данных, период, в течение которого данные могут быть потеряны, часто начинается примерно с момента начала работы по подготовке резервных копий, а не с момента их создания за пределами площадки.
Хотя точка синхронизации данных - это момент времени, время для выполнения физического резервного копирования должно быть включено. Один из используемых подходов - остановить обработку очереди обновлений, пока выполняется копирование с диска на диск. Резервное копирование отражает более раннее время этой операции копирования, а не когда данные копируются на ленту или передаются в другое место.
RTO и RPO должны быть сбалансированы с учетом бизнес-рисков, а также всех других основных критериев проектирования системы.
RPO привязано к тому времени, когда резервные копии отправляются за пределы сайта. Перенос через синхронные копии на внешнее зеркало создает самые непредвиденные трудности. Использование физического транспорта для лент (или других переносных носителей) с комфортом покрывает некоторые потребности в резервном копировании при относительно низкой стоимости. Восстановление может быть выполнено в заранее определенном месте. Совместно используемое внешнее пространство и оборудование завершают необходимый пакет.
Для больших объемов данных транзакций высокой ценности оборудование может быть разделено между двумя или более сайтами; разделение по географическим областям повышает устойчивость.
Планирование аварийного восстановления и информационных технологий (ИТ) разработали в середине-конце 1970-х годов, когда менеджеры компьютерных центров начали осознавать зависимость своих организаций от своих компьютерных систем.
В то время большинство систем были пакетными -ориентированными мэйнфреймами. Другой внешний мэйнфрейм может быть загружен с резервных лент в ожидании восстановления первичного сайта; время простоя было относительно менее критичным.
Индустрия аварийного восстановления создана для создания резервных компьютерных центров. Один из первых таких центров был расположен в Шри-Ланке (Sungard Availability Services, 1978).
В 1980-х и 90-х годах как внутреннее корпоративное разделение времени, онлайн-ввод данных и обработка в реальном времени выросла потребность в доступности ИТ-систем.
Регулирующие органы начали участвовать еще до быстрого роста Интернета в течение 2000-х; Часто требовались цели 2, 3, 4 или 5 девяток (99,999%), и требовались решения с высокой доступностью для горячих точек объектов.
ИТ Непрерывность обслуживания важна для многих организаций при внедрении управления непрерывностью бизнеса (BCM) и управления информационной безопасностью (ICM), а также в рамках внедрения и управления информационной безопасностью, а также управления непрерывностью бизнеса, как указано в ISO / IEC 27001 и ISO. 22301 соответственно.
Рост облачных вычислений с 2010 года продолжает эту тенденцию: в настоящее время даже меньше имеет значение, где физически обслуживаются вычислительные услуги, при условии, что сама сеть достаточно надежна (отдельная проблема, и меньшая проблема поскольку современные сети очень устойчивы по своей конструкции). «Восстановление как услуга» (RaaS) - одна из функций безопасности или преимуществ облачных вычислений, продвигаемых Cloud Security Alliance.
Бедствия могут быть результатом трех широкие категории угроз и опасностей. Первая категория - это стихийные бедствия, которые включают стихийные бедствия, такие как наводнения, ураганы, торнадо, землетрясения и эпидемии. Вторая категория - это технологические опасности, которые включают аварии или отказы систем и конструкций, такие как взрывы трубопроводов, аварии на транспорте, сбои в работе коммунальных служб, разрушение плотин и аварийные выбросы опасных материалов. Третья категория - это антропогенные угрозы, которые включают умышленные действия, такие как активные нападения, химические или биологические атаки, кибератаки на данные или инфраструктуру и саботаж. Меры по обеспечению готовности ко всем категориям и типам бедствий подразделяются на пять основных задач: предотвращение, защита, смягчение последствий, реагирование и восстановление.
Недавние исследования подтверждают идею о том, что внедрение более целостного подхода к планированию до бедствий в долгосрочной перспективе более рентабельно. Каждый доллар, потраченный на устранение опасностей (например, план аварийного восстановления ), экономит обществу 4 доллара на реагирование и затраты на восстановление.
Статистика аварийного восстановления за 2015 год показывает, что простой продолжительностью один час может стоить
Поскольку ИТ-системы становятся все более важными для бесперебойной работы деятельности компании и, возможно, экономики в целом, важность обеспечения непрерывной работы этих систем и их быстрого восстановления возросла. Например, из компаний, у которых была большая потеря бизнес-данных, 43% никогда не открываются повторно, а 29% закрываются в течение двух лет. В результате к подготовке к продолжению работы или восстановлению систем нужно относиться очень серьезно. Это требует значительных затрат времени и денег с целью обеспечения минимальных потерь в случае разрушительного события.
Меры контроля - это шаги или механизмы, которые могут уменьшить или устранить различные угрозы для организаций. В план аварийного восстановления (DRP) могут быть включены различные типы мер.
Планирование аварийного восстановления - это часть более крупного процесса, известного как планирование непрерывности бизнеса, и включает в себя планирование возобновления работы приложений, данных, оборудования, электронных коммуникаций (например, сетей) и другой ИТ-инфраструктуры. План обеспечения непрерывности бизнеса (BCP) включает в себя планирование аспектов, не связанных с ИТ, таких как ключевой персонал, помещения, кризисное взаимодействие и защита репутации, и должен ссылаться на план аварийного восстановления (DRP) для восстановления / непрерывности ИТ-инфраструктуры.
Меры управления аварийным восстановлением ИТ могут быть разделены на следующие три типа:
Хорошие меры плана аварийного восстановления требуют, чтобы эти три типа мер контроля документировались и регулярно выполнялись с использованием так- называется «DR-тесты».
Перед тем, как выбрать стратегию аварийного восстановления, планировщик аварийного восстановления сначала обращается к плану обеспечения непрерывности бизнеса своей организации, в котором должны быть указаны ключевые показатели целевой точки восстановления и целевого времени восстановления. Затем метрики бизнес-процессов сопоставляются с их системами и инфраструктурой.
Неспособность правильно спланировать ситуацию может усилить последствия аварии. После того, как метрики нанесены на карту, организация проверяет ИТ-бюджет; Показатели RTO и RPO должны соответствовать доступному бюджету. Анализ затрат и выгод часто диктует, какие меры аварийного восстановления необходимо применить.
Добавление облачного резервного копирования к преимуществам локального и внешнего ленточного архивирования, как пишет New York Times, «добавляет уровень защиты данных».
Общие стратегии защиты данных включает:
Во многих случаях организация может решить использовать внешний подрядчик поставщика восстановления, чтобы предоставить резервный сайт и системы вместо использования собственных удаленных средств, все чаще с помощью облачных вычислений.
Помимо подготовки к необходимости восстановления систем, организации также принимают меры предосторожности с целью предотвращения это может быть катастрофа. Сюда могут входить:
Аварийное восстановление как услуга DRaaS - это договоренность с третьим лицом, продавцом. Обычно предлагается поставщиками услуг как часть их портфеля услуг.
Несмотря на то, что списки поставщиков были опубликованы, аварийное восстановление - это не продукт, а услуга, хотя несколько крупных поставщиков оборудования разработали мобильные / модульные предложения, которые можно установить и ввести в эксплуатацию в очень короткие сроки.
 Модульный центр обработки данных, подключенный к электросети на подстанции
Модульный центр обработки данных, подключенный к электросети на подстанции